ElasticSearch学习篇17_《检索技术核心20讲》最邻近检索-局部敏感哈希、乘积量化PQ思路
目录
场景在搜索引擎和推荐引擎中,对相似文章去重是一个非常重要的环节,另外是拍照识花、摇一摇搜歌等场景都可以使用它快速检索。
基于敏感性哈希的检索更擅长处理字面上的相似而不是语义上的相似。
- 向量空间模型
- ANN检索加速思路
- 局部敏感哈希编码
- 随机超平面划分哈希编码思路
- Google的SimHash编码思路以及抽屉原理
- 聚类
- 乘积量化
- 局部敏感哈希编码
ANN与向量空间模型
对于高纬度数据近邻检索常见方式

将所有文档中的关键词都提取出来,如果总共n个关键词,那么就是一个n纬度的向量。具体到一篇文章,假如文档包含关键词数量是k,其中(0<=k<=n),如果文档包含的第k个关键词的权重为w,那么权重向量k位置的元素就是w,这个权重w一般是根据TF-IDF计算得出,如果文档不包含第k个关键词,那么权重w就是0。
关于TF-IDF词频-逆文档频率参考往期:
ElasticSearch学习篇15_《检索技术核心20讲》进阶篇之TopK检索-CSDN博客
本质就转化为计算两个向量的相似度,可用余弦相似度、欧式距离等计算,另外n纬向量放入到空间中就是一个点,也可理解为空间中的近邻检索ANN,在十几维量级的低维空间中,我们可以使用 k-d 树进行 k 维空间的近邻检索,这种思路就是前面说的精确检索的思路,它的性能还是不错的,但是纬度上来之后,因为基础k-d树特点当纬度大于20的时候可能出现线性灾难,搜索大量的邻域导致性能很慢。
关于KD树、KDB、BKD树参考往期:
ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树(论文Bkd-Tree: A Dynamic Scalable kd-Tree)_bkd树-CSDN博客
向量空间模型可用来表示文字、图片等内容,从而进行文本、图像近邻搜索ANN,一些常见的ANN加速算法思想基本分为两类
- 缩小候选集
- 压缩向量存储空间
ANN搜索加速技术思想
局部敏感哈希-缩小候选集数量
借助非精确检索的思路,可以将高纬空间中的点进行区域划分,然后给每个区域生成一个较短的编码,查询的时候先根据规则定位区域,达到缩小候选集的目的,再从该区域高效近邻检索。
这个规则就类似哈希,但是普通的哈希函数值不太可控,文章中变化很少的关键词就会导致哈希值很大的变动。
因此必须找出一个特殊的哈希规则,使得相似的数据哈希之后,得到的哈希值也是相近的,被称为局部敏感性哈希(Locality-Sensitive Hashing)
随机超平面划分哈希编码
以二维空间举例,找出一条线,将区域划分为两部分,处在区域1的点编码为1,处在另外区域的点编码为0,这条线需要尽可能合理,因此可以随机找出n条线,一条线切分下,会对点增加一位编码,这样n条线就会给一个点产生n位的编码。
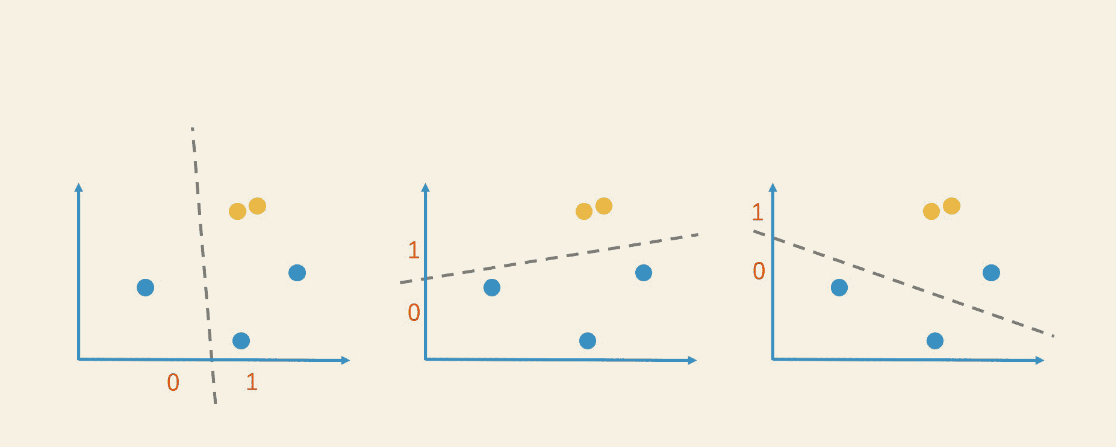
对于多维空间,就需要找超平面,如n个纬度就找n个超平面,然后这些超平面将空间中的点切割,位于超平面两侧的点(通过超平面法向量的余弦相似度计算)分别被编码0、1,这样可以将高维空间的点映射为一纬的编码。
如果两个点的哈希值是一样的,那么两个点大概率距离的非常近,即使哈希值不一样,只要他们在n个比特位中大大部分是相同的(具体的计算算法如海明距离),说明他们大概率相近。举个例子如果两篇文章内容是100%相同的,那么他们的哈希值就是相同的,也就相当于编码相同。
这种一般哈希编码有个缺点就是随着超线、超平面的划分编码,会丢失某些纬度权重信息。
SimHash编码
谷歌提出的局部敏感哈希策略,简化哈希函数,保留多维数据(点)项的权重信息。
它使用一个普通的哈希函数代替了n次随机超平面划分,这个哈希函数作用对象不是整体所有的高纬度数据项,而是一个个处理高纬度数据项,通过数据项哈希值编码与数据项权重计算的时候就能保留权重。

构造SimHash的具体过程,以一篇文档进行局部敏感哈希编码来说明
- 文档分词,关键词项带权重:分词并计算每个关键词的权重w。
- 生成Hash值:使用一般的Hash函数,针对每个关键词生成如64位的0、1哈希值编码。
- 每个关键词哈希值变化:将哈希值的0改为-1,如10110 -> 1 -1 1 1 -1
- 每个关键词哈希值按位乘上词权重:如词权重3,变为 3 -3 3 3 -3。
- 按位相加所有关键词的哈希值:计算文档所有关键词哈希值按位加的结果。
- 文档哈希值编码转换:将编码转为0、1。
这样,文档的最终哈希编码是收到权重比较大的词影响比较多的,另外就是哈希函数比较简单,代替了复杂的随机选取超平面方式。
抽屉原理
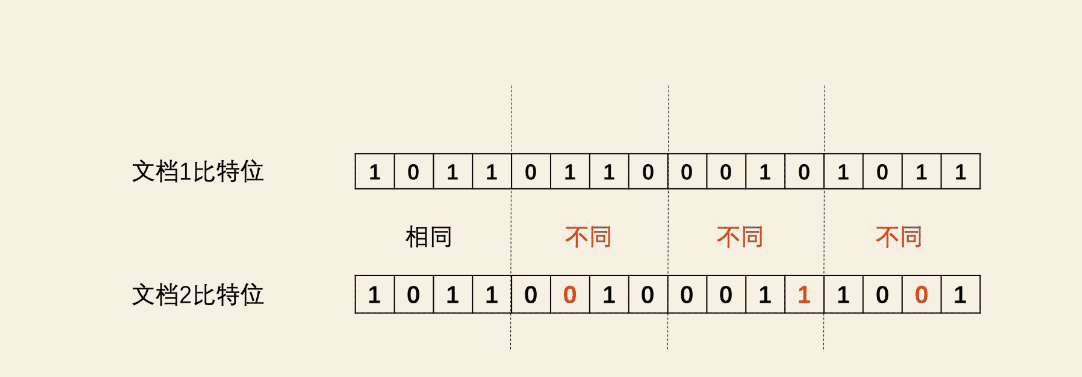
对于文章查重领域,如果两个文章的SimHash编码的距离(使用汉明距离计算)小于k,那么就认为它们是相似的。举个例子当k=3的时候,需要找出k小于3的文章,然后遍历逐一计算对比,效率比较低,有没有加速方案?
一个直观的想法,使用SimHash编码某一位bit作为key,使用文章内容作为value构建倒排索引,以64位的SimHash编码为例,key的数量为128个,构造的倒排索引key如
- 1xxxxx、0xxxxx
- x1xxxx、x0xxxx
- …
查找的时候,逐位查找64次,将第n为比特位对应key对应的文章全部取出来,然后计算对比。
这种方式效率不是很高,因为即使两篇文章64位bit任意两个位置的bit相同的话就会被召回,即使不太相似。
Google提出优化的抽屉原理:将文章的SimHash编码分4段,如果想找出和此文章bit位差异不超过3个的文章,那么4个段其中一定至少有一个段的bit是完全一致的。因此查询就被转化为了4段中有一段完全相同的文章会被召回。
按照这个思路,
- 分段构建倒排索引:将每个文档的SimHash编码划分为四段,每段的16位bit作为一个倒排索引,
- 分段查询:查询的时候,当前文档的SimHash编码也会被划分为四段,如果找出汉明距离k<3的文档,只需召回四段中任一段完全相同的文档即可,然后从四段倒排索引找回的结果合并。
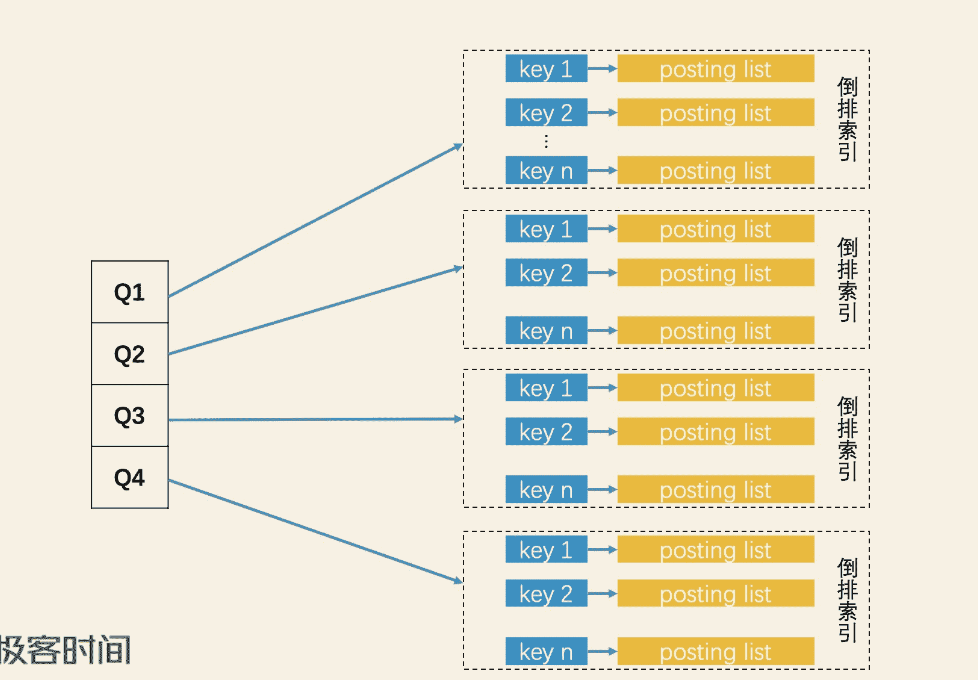
通过使用 SimHash 函数和分段检索(抽屉原理),使得 Google 能在百亿级别的网页中快速完成过滤相似网页的功能,从而保证搜索结果的数量。
思考1:对于 SimHash,如果将海明距离在 4 之内的文章都定义为相似的,那我们应该将哈希值分为几段进行索引和查询呢?分为5段,因为4为不同的bit位最多能影响四段,虽然除不尽,每段可以是12或者13,查询的时候也按照这种规则划分5段即可。
对比编辑距离、杰卡德算法计算文本相似性
对比杰卡德、莱文斯坦、SimHash三种计算文章相似度的效果,总结特点以及适用场景。
SimHash的一种实现参考:SimHash结合汉明距离判断文本相似性
下面选取一套初中语文的试卷,试卷包含大概20道试题,大概1w字符
手动创造不同的CASE,以下是包含完整CASE描述的表格:
| CASE | 描述 | 原文内容长度 | 内容长度 | simHash相似度 | simHash耗时 | levenshtein相似度 | levenshtein耗时 | jaccard相似度 | jaccard耗时 |
|---|---|---|---|---|---|---|---|---|---|
| CASE1 | 将21题和22题互相换位置 | 8556 | 8556 | 100.0 | 274ms | 0.84 | 298ms | 1.0 | 7ms |
| CASE2 | 删除试卷中间的11题 | 8556 | 8401 | 96.88 | 102ms | 0.98 | 274ms | 1.0 | 1ms |
| CASE3 | 删除10题之后的所有内容 | 8556 | 1921 | 65.63 | 30ms | 0.22 | 41ms | 1.0 | 2ms |
| CASE4 | 完全打乱试题顺序 | 8556 | 8560 | 100.0 | 45ms | 0.45 | 183ms | 1.0 | 1ms |
| CASE5 | 删除11题之前的所有内容 | 8556 | 6635 | 92.19 | 40ms | 0.77 | 143ms | 1.0 | 1ms |
| CASE6 | 前11道题内容不相同,后面内容相同 | 8556 | 9184 | 89.06 | 40ms | 0.74 | 194ms | 0.9035971223021583 | 1ms |
| CASE7 | 在11题后面中间加入一道试题 | 8556 | 8741 | 98.44 | 37ms | 0.97 | 186ms | 1.0 | 1ms |
绘制成图表
在选取初中语文试卷内容1w字符文本相似度计算场景下,综合CASE分析文本相似度计算效率以及严格程度
- 效率:杰卡德 > SimHash > 莱文斯坦编辑距离
- 严格程度:莱文斯坦编辑距离 > SimHash > 杰卡德
针对CASE2、CASE3分析,即使试卷内容1和试卷内容2相差了一道或者十多道试题,但是杰卡德计算的文本相似度仍为100,SimHash计算的文本相似度较为准确,但是效率又要比莱文斯坦效率要高,使用SimHash可以避免查重中将不是完全一致的试卷内容(差别几道试题)误查,同时又兼顾相似度计算效率。
SimHash、杰卡德(Jaccard)和莱文斯坦(Levenshtein)是三种常用的文本相似度计算算法,它们各有特点和适用场景:
- SimHash:局部敏感性哈希
- 特点:SimHash是一种局部敏感哈希算法,主要用于快速计算大规模文本数据的相似性。它通过将文本转换为一个固定长度的二进制哈希值来表示文本特征。SimHash的优点是计算速度快,适合处理大规模数据。
- 适用场景:SimHash常用于海量数据的去重、近似重复检测和相似文档查找等场景。由于其计算效率高,特别适合需要快速处理和比较大量文本的应用。
- 杰卡德(Jaccard)相似系数:
- 特点:杰卡德相似系数用于衡量两个集合的相似度,定义为两个集合交集的大小除以并集的大小。对于文本相似性,通常将文本分割成词或字符的集合,然后计算这些集合的杰卡德相似度。
- 适用场景:杰卡德相似度适合用于比较短文本或关键词集合的相似性,如文档分类、标签推荐等。由于其计算简单,适合用于需要快速评估文本相似性的场合。
- 莱文斯坦(Levenshtein)距离:
- 特点:莱文斯坦距离,又称编辑距离,表示将一个字符串转换为另一个字符串所需的最小编辑操作次数(插入、删除、替换)。它能够精确地衡量两个字符串之间的差异。
- 适用场景:莱文斯坦距离适合用于需要精确比较字符串差异的场合,如拼写检查、DNA序列比对、文本纠错等。由于其计算复杂度较高,通常用于较短文本的比较。
总结来说,SimHash适合大规模文本的快速相似性检测,杰卡德相似度适合集合间的相似性比较,而莱文斯坦距离适合精确的字符串差异分析。选择合适的算法需要根据具体的应用场景和数据特征来决定。
汉明距离
主要是计算等长的两个二进制字符串之间差别的位数
def hamming_distance(str1, str2):if len(str1) != len(str2):raise ValueError("Strings must be of the same length")distance = 0for ch1, ch2 in zip(str1, str2):if ch1 != ch2:distance += 1return distance# 示例
str1 = "1101"
str2 = "1001"
print(hamming_distance(str1, str2)) # 输出: 1聚类-缩小候选集数量
图片如何相似性检索,检索图片和检索文章一样,首先要先用向量空间模型将图片表示出来,这样图像就变成了高纬度空间的一个点,搜素图片转化为了高纬度空间的ANN。
如何从图片抽取向量空间模型,如果把图像的每个像素看作一个纬度,像素上的RGB值作为纬度值,是一种思路,但是一张图片的纬度大概是百万级别,检索起来很复杂,因此另外一种方式就是使用CNN等进行图像特征提取,转为一个512或者1024纬度的向量空间模型。
如何加速ANN检索效率,有了向量空间模型,就可以使用ANN加速技术比如SimHash来加速检索,比如将高纬空间的点划分到有限区域,从而达到缩小候选集的目的。但是SimHash哈希函数比较简单,更适合计算字面上的相似性而不是语义上的相似性,同时SimHash是一种粒度很粗的非精确检索方案,他能将上百万的纬度压缩为64位bit,损失不少精度。因此一般使用聚类方案加速ANN检索,常见的一种是K-Means(K-平均算法)方案
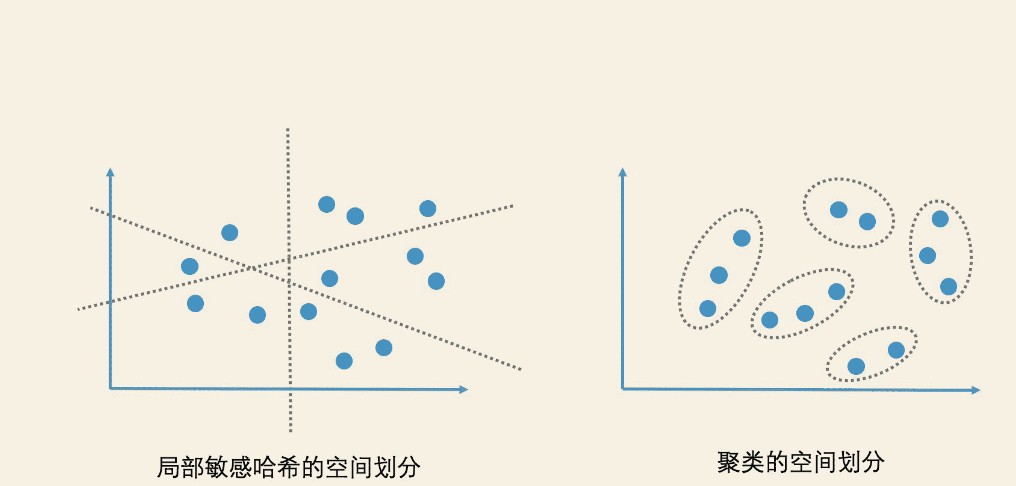
K-Means聚类算法构建聚类计算步骤
- 初始聚类中心:随机从数据中选取k个数据作为初始聚类中心
- 计算距离:计算其他数据与ki 的距离,加入到最邻近的ki 聚类中
- 根据距离均值重新选取聚类中心:根据聚类中的点到聚类中心距离的均值,重新选一个聚类中心
重复2-3步,即重新计算其他还数据到聚类中心的距离,然后将节点划分到最近的聚类中,然后在更新聚类中心。
K-Means 聚类算法的优化目标是,类内的点到类中心的距离均值总和最短。构建好之后,以聚类中心数据ID作为key,单个聚类的数据创建倒排索引。
K-Means查询的时候,直接找出待查询数据距离最近的聚类中心ki 然后从倒排索引取出topK候选集,
- 如果不足topK数量,那么可以再查询邻近聚类的候选集。
- 如果数量很多同时topK又取得非常大,那么一个一个计算和待查询数据距离代价也很大,可以采用层级子聚类来继续缩小候选集。
乘积量化-压缩向量模型存储空间
对于向量的相似检索,除了检索算法本身,优化向量存储空间也是一个优化方向,因为向量的相似度计算需要加载进内存。
以一个1024纬度的向量距离,每个向量纬度是一个浮点数占4 Bytes = 32 bits,那么一个向量占用1KB空间,如果是上亿级的数据,存储向量需要占几百个G。(100 000 000 KB = 100 GB)
为了更好的将向量加载进去内存,需要对向量存储空间优化,一种思路是使用上面的聚类思想,减少加载进内存的数量,只把查询向量和聚类向量加载进内存,而不是聚类下所有向量,这样可能会损失结果粒度。另外一种思路就是使用向量量化-乘积量化来压缩。
乘积量化的概念
- 乘积:高纬空间向量可以看作是多个低纬空间向量相乘的结果,可以理解为笛卡尔集,如数轴的x、y轴分别表示一纬空间,数轴区域中的点(xi.yi)就是二维空间的点,假如xi的值为1、2、3,yi的值为5、6、7,那么组合笛卡尔集的二纬空间的点个数为9个。
- 量化:将区域划分为子区域,然后在编码,这样就能将区域转为1纬编码,上面聚类就是一种量化方式。
乘积量化就是将高纬空间划分为多个子空间,然后对子空间编码,针对子空间在进行聚类技术分为多个子区域,然后给每个子区域编码即聚类ID。好处:省空间,二纬空间存储的点数量为9,但是只存储一纬空间x、y的话,只需要存储的数量为6个一纬点。
举例假设一组1024纬度的向量进行乘积量化
- 首先将1024纬度向量拆分为4个256纬度子向量
- 在每一个256纬度子向量进行聚类,找出1-256和聚类ID,因此只使用8 bits就能表示1-256的聚类ID。

所以经过上述过程,1024纬度的向量使用 4 * 8 bits = 32 bit就能表示。

乘积量化PQ过程思想
乘积量化向量相似查询的时候,涉及到三个向量
- 样本向量:1024纬度,乘积量化过程会被压缩为4段,每段进行聚类,每段会得到一个聚类中心ID,范围为1-256,最后所有样本处理完后,大概会得到 256 * 4 个聚类中心向量。
- 聚类中心向量:每段都有256个聚类中心ID,256 * 4 个聚类中心向量。
- 查询向量:1024纬度,查询过程会被压缩4段。
构造的时候,样本向量会被压缩为4段,会得到256 * 4的聚类中心向量,而样本向量也从1024纬度被压缩为32纬,1024 => 4 * 256 => 4 * 2 ^ 8,压缩含义就是以每段聚类中心ID的8为bit编码代替当前子向量段。
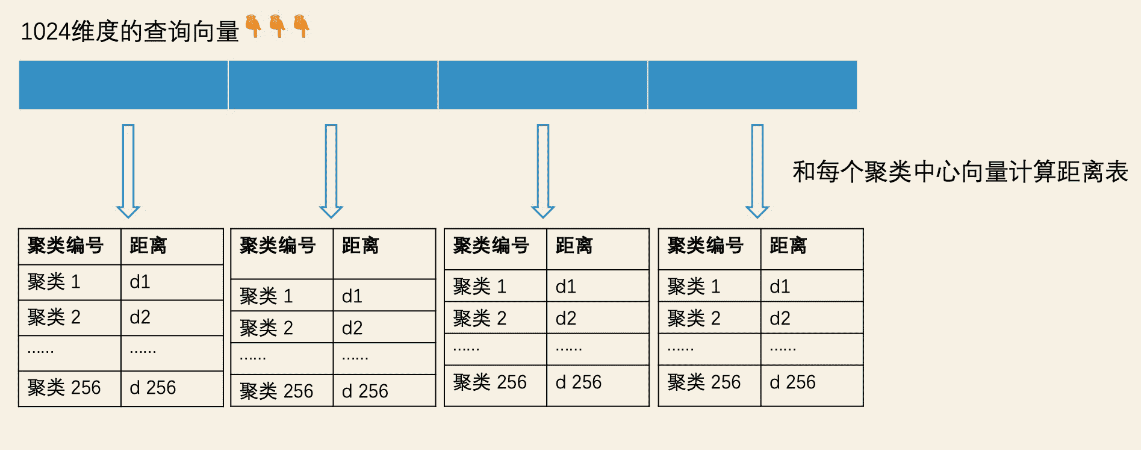
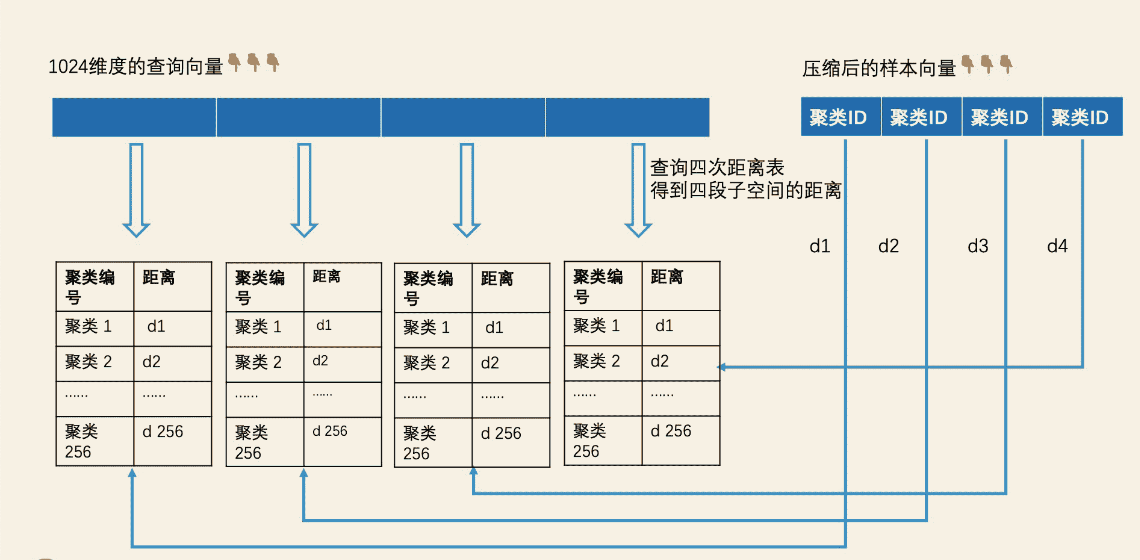
当计算查询向量和样本向量的距离时,
- 向量切分子空间:我们将查询向量和样本向量都分为 4 段子空间。
- 子空间计算聚类ID:计算查询向量切分的4段子空间的聚类ID,生成压缩向量。然后预生成一个距离表,该距离表纬度是256 * 4,记录了查询子向量和 子空间各个中心向量的距离。
- 遍历全部样本数量计算查询向量距离:根据预处理阶段的距离表可以查询出查询向量每段到各个聚类ID的距离,数据库中全部的样本向量属于哪个聚类ID也可以计算出,然后就是求出每段距离:d1、d2、d3、d4,最终通过相关运算如欧式距离等计算两个向量的距离,进而返回topK。
PQ主要是为了压缩空间,计算距离算法不太关注。
其他参考:理解 product quantization 算法
这样,求查询子向量和样本子向量的距离,就转换为求查询子向量和对应的聚类中心向量的距离。那我们只需要将样本子向量所属的聚类中心的聚类 ID 作为 key 去查距离表,就能在 O(1) 的时间代价内知道这个距离了。
这里讲述的只是大致思想,具体的如何计算找出紧邻的topK向量还有 基于倒排的乘积量化IVFPQ缩小遍历全部样本空间向量,以及SDC、ADC向量相似检索算法还有很多小细节。
基于倒排索引的IVFPQ思想
上面说的计算查询向量和所有样本向量之间的距离是遍历全部的样本空间,还有一种维护样本向量倒排索引的方式加速检索。
构建倒排索引的具体的思路
- 样本向量切分子空间:1024纬切分为4段,每段256纬度
- 计算子空间聚类ID:可以采用KMeans聚类算法,最终每个子空间(段)聚类256个,每个子空间使用聚类ID代表当前样本子空间特征,最终每个子空间得到8位的聚类ID
- 建立倒排索引:得到的32位新向量,为每个子空间创建一个倒排索引,每个倒排索引的key可以设置为当前段的聚类ID,value设置为在当前段被聚类到该ID的所有样本数量。
查询的时候,查询向量进行切分子空间,PQ,然后逐段查倒排,这样将四个段的样本数量就是最有可能相近的样本数量,在进行距离计算找出TopK。
另外还有一种根据聚类ID向量残差创建倒排索引的做法,这样做精度会高一些。
思考
如果二维空间中有 16 个点,它们是由 x 轴的 1、2、3、4 四个点,以及 y 轴的 1、2、3、4 四个点两两相乘组合成的。那么,对于二维空间中的这 16 个样本点,如果使用乘积量化的思路,你会怎么进行压缩存储?当我们新增了一个点 (17,17) 时,它的查询过程又是怎么样的?
主要的思想就是使用两纬位置代替真实的二维点值,对于16个样本点,首先是定义x、y轴两个集合,然后将点的x、y轴的值压缩为对应x、y轴集合的索引值,索引值数值相对于点的值是比较小的,通过PQ可以节省存储空间。当新增了一个点(17,17),只需要向x、y轴集合添加17,查询的时候,先判断x、y轴集合是否有值17,若都有的话索引为(xi=5,yi=5),索引对应的点就是要找的(17,17)
相关文章:
ElasticSearch学习篇17_《检索技术核心20讲》最邻近检索-局部敏感哈希、乘积量化PQ思路
目录 场景在搜索引擎和推荐引擎中,对相似文章去重是一个非常重要的环节,另外是拍照识花、摇一摇搜歌等场景都可以使用它快速检索。 基于敏感性哈希的检索更擅长处理字面上的相似而不是语义上的相似。 向量空间模型ANN检索加速思路 局部敏感哈希编码 随…...

在 Sublime Text 中直接预览 Markdown 文件
在 Sublime Text 中直接预览 Markdown 文件需要借助插件实现。以下是详细步骤: 1. 安装 Markdown Preview 插件 按下快捷键 CtrlShiftP (或 macOS 上的 CmdShiftP),打开命令面板。输入 Install Package 并选择 Package Control: Install Package。等待包…...

分词器的概念(通俗易懂版)
什么是分词器?简单点说就是将字符序列转化为数字序列,对应模型的输入。 通常情况下,Tokenizer有三种粒度:word/char/subword word: 按照词进行分词,如: Today is sunday. 则根据空格或标点进行分割[today, is, sunda…...

速通前端篇 —— CSS
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程程(ಥ_ಥ)-CSDN博客 所属专栏:速通前端 目录 CSS的介绍 基本语法规范 CSS选择器 标签选择器 class选择器 id选择器 复合选择器 通配符选择器 CSS常见样式 颜…...

数据库表设计范式
华子目录 MYSQL库表设计:范式第一范式(1NF)第二范式(2NF)第三范式(3NF)三范式小结巴斯-科德范式(BCNF)第四范式(4NF)第五范式(5NF&…...
经济增长初步
1.人均产出 人均产出,通常指的是一个国家、地区或组织在一定时期内,每个劳动人口平均创造的生产总值。它是衡量一个地区或国家经济效率和劳动生产率的重要指标。具体来说,人均产出可以通过以下公式计算: 人均产出总产出/劳动人口…...

【架构】主流企业架构Zachman、ToGAF、FEA、DoDAF介绍
文章目录 前言一、Zachman架构二、ToGAF架构三、FEA架构四、DoDAF 前言 企业架构(Enterprise Architecture,EA)是指企业在信息技术和业务流程方面的整体设计和规划。 最近接触到“企业架构”这个概念,转念一想必定和我们软件架构…...

时间请求参数、响应
(7)时间请求参数 1.默认格式转换 控制器 RequestMapping("/commonDate") ResponseBody public String commonDate(Date date){System.out.println("默认格式时间参数 date > "date);return "{module : commonDate}"; }…...

PyTorch图像预处理:计算均值和方差以实现标准化
在深度学习中,图像数据的预处理是一个关键步骤,它直接影响模型的训练效果和收敛速度。PyTorch提供的transforms.Normalize()函数允许我们对图像数据进行标准化处理,即减去均值并除以方差。这一步骤对于提高模型性能至关重要。 为什么需要标准…...
slice介绍slice查看器
Android Jetpack架构组件(十)之Slices - 阅读清单 - 腾讯云开发者社区-腾讯云 slice 查看器apk 用adb intall 安装 Releases android/user-interface-samples GitHubMultiple samples showing the best practices in the user interface on Android. - Releases android/u…...

Android音频采集
在 Android 开发领域,音频采集是一项非常重要且有趣的功能。它为各种应用程序,如语音聊天、音频录制、多媒体内容创作等提供了基础支持。今天我们就来深入探讨一下 Android 音频采集的两大类型:Mic 音频采集和系统音频采集。 1. Mic音频采集…...
通过轻易云平台实现聚水潭数据高效集成到MySQL的技术方案
聚水潭数据集成到MySQL的技术案例分享 在本次技术案例中,我们将详细探讨如何通过轻易云数据集成平台,将聚水潭的数据高效、可靠地集成到MySQL数据库中。具体方案为“聚水谭-店铺查询单-->BI斯莱蒙-店铺表”。这一过程不仅需要处理大量数据的快速写入…...

类和对象( 中 【补充】)
目录 一 . 赋值运算符重载 1.1 运算符重载 1.2 赋值运算符重载 1.3 日期类实现 1.3.1 比较日期的大小 : 1.3.2 日期天数 : 1.3.3 日期 - 天数 : 1.3.4 前置/后置 1.3.5 日期 - 日期 1.3.6 流插入 << 和 流提取 >> 二 . 取地址运算符重载 2.1 const…...
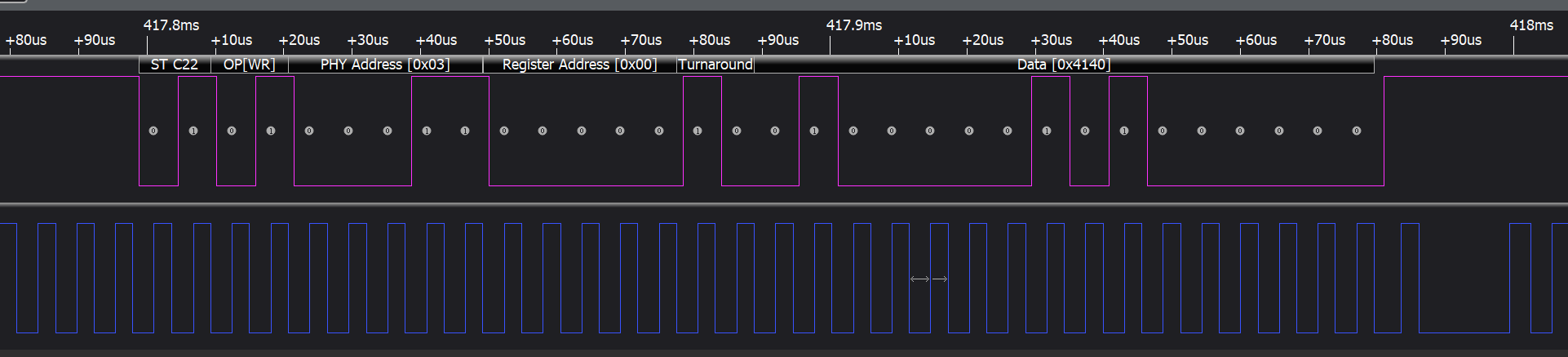
如何使用gpio模拟mdio通信?
一、前言 实际项目开发中,由于设计原因,会将phy的mdio引脚连接到SoC的2个空闲gpio上, 这样就无法通过Gmac自有的架构实现修改phy, 因此只能通过GPIO模拟的方式实现MDIO, 好在Linux支持MDIO via GPIO功能。 该功能…...

C# 中的事件和委托:构建响应式应用程序
C#中的事件和委托。事件和委托是C#中用于实现观察者模式和异步回调的重要机制,它们在构建响应式和交互式应用程序中发挥着重要作用。以下是一篇关于C#中事件和委托的文章。 引言 事件和委托是C#语言中非常重要的特性,它们允许你实现观察者模式和异步回…...

科技赋能健康:多商户Java版商城系统引领亚健康服务数字化变革
在当今社会,随着生活节奏的加快和工作压力的增大,越来越多的人处于亚健康状态。据《The Lancet》期刊2023年的统计数据显示,全球亚健康状态的人群比例已高达82.8%,这一数字背后,隐藏着巨大的健康风险和社会成本。亚健康…...
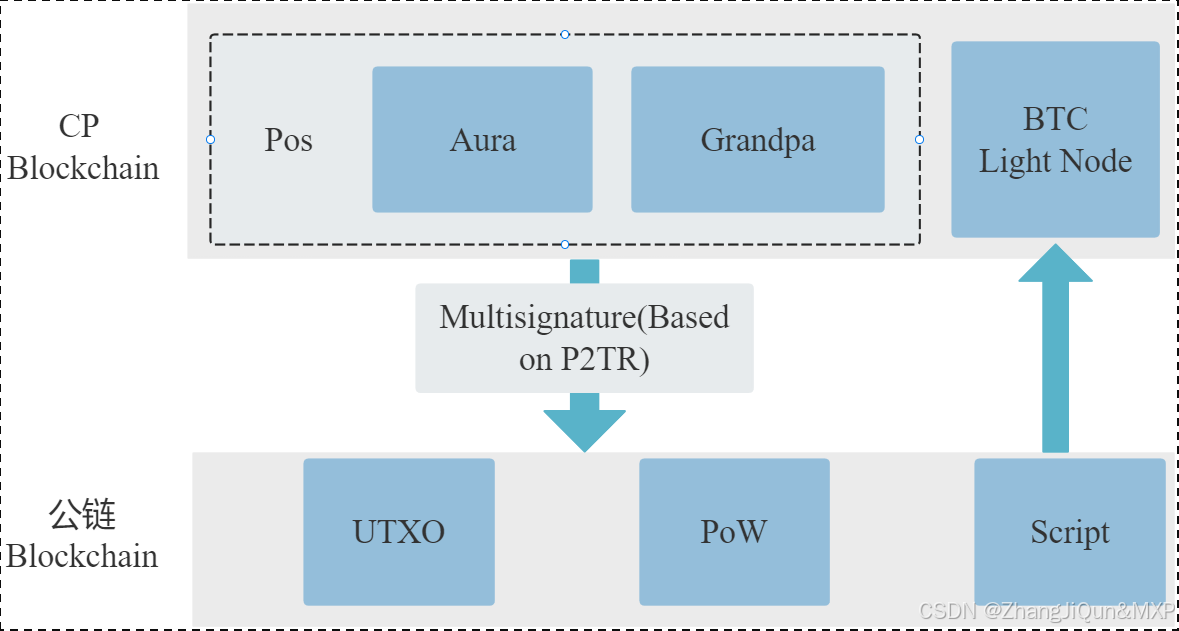
区块链网络示意图;Aura共识和Grandpa共识(BFT共识)
目录 区块链网络示意图 Aura共识和Grandpa共识(BFT共识) Aura共识 Grandpa共识(BFT共识) Aura与Grandpa的结合 区块链网络示意图 CP Blockchain:这是中央处理区块链(或可能指某种特定的处理单元区块链)的缩写。它可能代表了该区块链网络的主要处理或存储单元。在这…...
Javaweb梳理18——JavaScript
今日目标 掌握 JavaScript 的基础语法掌握 JavaScript 的常用对象(Array、String)能根据需求灵活运用定时器及通过 js 代码进行页面跳转能通过DOM 对象对标签进行常规操作掌握常用的事件能独立完成表单校验案例 18.1 JavaScript简介 JavaScript 是一门跨…...

面向对象-接口的使用
1. 接口的概述 为什么有接口? 借口是一种规则,对于继承而言,部分子类之间有共同的方法,为了约束方法的使用,使用接口。 接口的应用: 接口不是一类事物,它是对行为的抽象。 2. 接口的定义和使…...
)
失落的Apache JDBM(Java Database Management)
简介 Apache JDBM(Java Database Management)是一个轻量级的、基于 Java 的嵌入式数据库管理系统。它主要用于在 Java 应用程序中存储和管理数据。这个项目已经过时了,只是发表一下以示纪念,现在已经大多数被SQLite和Derby代替。…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...
)
【独家首发】DeepSeek官方未公开的集成测试Checklist(含23项生产环境准入阈值与压测基线)
更多请点击: https://codechina.net 第一章:DeepSeek集成测试方案 DeepSeek模型的集成测试需覆盖推理服务稳定性、多模态输入兼容性、上下文长度边界及API协议一致性四大核心维度。测试环境基于Kubernetes集群部署,采用PrometheusGrafana监控…...

为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍
为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.com/g…...

ESP32屏幕项目救星:用TFT_eSPI库的Touch_calibrate例程,5分钟搞定LittleVGL触摸校准
ESP32屏幕开发实战:5分钟完成LittleVGL触摸校准的高效方法论 当一块全新的ILI9341XPT2046电阻屏摆在你面前时,大多数开发者会迫不及待地跳进LittleVGL的配置深渊。但真正高效的硬件开发者知道,在编写任何图形界面代码之前,有一个关…...

模型越强,Bug越隐?DeepSeek代码生成评测:12个真实项目踩坑案例,速查避雷清单
更多请点击: https://kaifayun.com 第一章:模型越强,Bug越隐?DeepSeek代码生成评测:12个真实项目踩坑案例,速查避雷清单 当大模型在代码补全、函数生成和单元测试编写中表现愈发惊艳,一个反直觉…...