13.推荐系统的性能优化
接下来我们将学习推荐系统的性能优化。推荐系统的性能优化对于提升推荐结果的生成速度和系统的可扩展性至关重要,尤其是在处理大规模数据和高并发请求时。在这一课中,我们将介绍以下内容:
- 性能优化的重要性
- 常见的性能优化方法
- 实践示例
1. 性能优化的重要性
推荐系统的性能优化主要体现在以下几个方面:
- 响应速度:提高推荐结果的生成速度,减少用户等待时间,提升用户体验。
- 系统可扩展性:支持大规模用户和数据,确保系统在高并发请求下的稳定性和性能。
- 资源利用率:优化资源使用,降低计算和存储成本,提高系统效率。
2. 常见的性能优化方法
推荐系统的性能优化方法主要包括以下几类:
-
数据预处理与缓存:
- 数据预处理:提前处理和存储用户和项目的特征,减少实时计算开销。
- 缓存:将常用的推荐结果和中间计算结果缓存起来,减少重复计算。
-
模型压缩与加速:
- 模型压缩:通过剪枝、量化等技术,减少模型参数量,提高推理速度。
- 模型加速:通过使用高效的推理引擎(如TensorRT)和硬件加速(如GPU、TPU),提升模型推理性能。
-
分布式计算与存储:
- 分布式计算:通过分布式计算框架(如Spark、Flink),并行处理大规模数据,提高计算效率。
- 分布式存储:通过分布式存储系统(如HDFS、Cassandra),高效存储和访问大规模数据。
-
在线学习与更新:
- 在线学习:通过在线学习算法,实时更新模型参数,保持推荐结果的实时性。
- 增量更新:通过增量更新技术,仅更新变化的数据,减少全量计算开销。
3. 实践示例
我们将通过几个简单的示例,展示如何进行推荐系统的性能优化。
数据预处理与缓存
以下示例展示了如何进行数据预处理和缓存。
import pandas as pd
import numpy as np
import pickle# 假设我们有用户评分数据
ratings_data = {'user_id': [1, 1, 1, 2, 2, 3, 3, 4, 4],'movie_id': [1, 2, 3, 1, 4, 2, 3, 3, 4],'rating': [5, 3, 4, 4, 5, 5, 2, 3, 3]
}
ratings_df = pd.DataFrame(ratings_data)# 数据预处理:计算用户和项目的平均评分
user_mean_ratings = ratings_df.groupby('user_id')['rating'].mean().to_dict()
movie_mean_ratings = ratings_df.groupby('movie_id')['rating'].mean().to_dict()# 将预处理结果缓存到文件中
with open('user_mean_ratings.pkl', 'wb') as f:pickle.dump(user_mean_ratings, f)
with open('movie_mean_ratings.pkl', 'wb') as f:pickle.dump(movie_mean_ratings, f)# 读取缓存的预处理结果
with open('user_mean_ratings.pkl', 'rb') as f:cached_user_mean_ratings = pickle.load(f)
with open('movie_mean_ratings.pkl', 'rb') as f:cached_movie_mean_ratings = pickle.load(f)print("Cached User Mean Ratings:", cached_user_mean_ratings)
print("Cached Movie Mean Ratings:", cached_movie_mean_ratings)
模型压缩与加速
以下示例展示了如何进行模型压缩和加速。
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的神经网络模型
class SimpleNN(nn.Module):def __init__(self, input_dim, hidden_dim):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, 1)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.sigmoid(self.fc2(x))return x# 初始化模型
input_dim = 10
hidden_dim = 5
model = SimpleNN(input_dim, hidden_dim)# 模型压缩:剪枝
def prune_model(model, pruning_ratio=0.5):for name, module in model.named_modules():if isinstance(module, nn.Linear):num_prune = int(module.weight.nelement() * pruning_ratio)weight_flat = module.weight.view(-1)_, idx = torch.topk(weight_flat.abs(), num_prune, largest=False)weight_flat[idx] = 0module.weight.data = weight_flat.view_as(module.weight)prune_model(model)# 模型加速:使用GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)# 模型推理示例
input_data = torch.randn(1, input_dim).to(device)
output = model(input_data)
print("Model Output:", output)
分布式计算与存储
以下示例展示了如何使用Spark进行分布式计算。
from pyspark.sql import SparkSession# 初始化SparkSession
spark = SparkSession.builder.appName("RecommenderSystem").getOrCreate()# 假设我们有用户评分数据
ratings_data = [(1, 1, 5), (1, 2, 3), (1, 3, 4),(2, 1, 4), (2, 4, 5),(3, 2, 5), (3, 3, 2),(4, 3, 3), (4, 4, 3)
]
ratings_df = spark.createDataFrame(ratings_data, ["user_id", "movie_id", "rating"])# 分布式计算:计算用户和项目的平均评分
user_mean_ratings = ratings_df.groupBy("user_id").avg("rating").collect()
movie_mean_ratings = ratings_df.groupBy("movie_id").avg("rating").collect()print("User Mean Ratings:", user_mean_ratings)
print("Movie Mean Ratings:", movie_mean_ratings)# 停止SparkSession
spark.stop()
总结
在这一课中,我们介绍了推荐系统的性能优化的重要性、常见的性能优化方法,并通过实践示例展示了如何进行数据预处理与缓存、模型压缩与加速、分布式计算与存储。通过这些内容,你可以初步掌握推荐系统的性能优化方法。
下一步学习
在后续的课程中,你可以继续学习以下内容:
-
推荐系统的多领域应用:
- 学习推荐系统在不同领域(如电商、社交媒体、音乐、新闻等)的应用和优化方法。
-
推荐系统的实验设计与评估:
- 学习如何设计和评估推荐系统的实验,确保推荐系统的效果和用户体验。
-
推荐系统的个性化与多样性:
- 学习如何提高推荐系统的个性化和多样性,提升用户满意度。
希望这节课对你有所帮助,祝你在推荐算法的学习中取得成功!
相关文章:

13.推荐系统的性能优化
接下来我们将学习推荐系统的性能优化。推荐系统的性能优化对于提升推荐结果的生成速度和系统的可扩展性至关重要,尤其是在处理大规模数据和高并发请求时。在这一课中,我们将介绍以下内容: 性能优化的重要性常见的性能优化方法实践示例 1. 性…...

Grafana-使用Button修改MySQL数据库
背景 众所周知,Grafana是一个用来展示数据的平台,但是有时候还是会有需求说能不能有一个按钮,点击的时候再对数据库进行修改,从而达到更新数据的效果 经过多方查证,终于实现了一个简单的,点击button执行sq…...

飞科FH6218电吹风异响维修
前言 本文仅记录一次普通的维修经历,解决方案也都是从网上查找资料得来,仅供参考,如有不对请指出,谢谢! 现象 使用时出现异响,风速越大越响 参考视频 https://www.bilibili.com/video/BV1dD4y1x7hH/?…...

分治下的快速排序(典型算法思想)—— OJ例题算法解析思路
目录 一、75. 颜色分类 - 力扣(LeetCode) 运行代码: 一、算法核心思想 二、指针语义与分区逻辑 三、操作流程详解 四、数学正确性证明 五、实例推演(数组[2,0,2,1,1,0]) 六、工程实践优势 七、对比传统实现 八、潜在问题与解决方案 九、性能测试数据 十、扩展…...

Unity3D实现显示模型线框(shader)
系列文章目录 unity工具 文章目录 系列文章目录👉前言👉一、效果展示👉二、第一种方式👉二、第二种方式👉壁纸分享👉总结👉前言 在 Unity 中显示物体线框主要基于图形渲染管线和特定的渲染模式。 要显示物体的线框,通常有两种常见的方法:一种是利用内置的渲染…...

深度剖析责任链模式
一、责任链模式的本质:灵活可扩展的流水线处理 责任链模式(Chain of Responsibility Pattern)是行为型设计模式的代表,其核心思想是将请求的发送者与接收者解耦,允许多个对象都有机会处理请求。这种模式完美解决了以下…...

基于 openEuler 构建 LVS-DR 群集
一、 对比 LVS 负载均衡群集的 NAT 模式和 DR 模式,比较其各自的优势 。 二、 基于 openEuler 构建 LVS-DR 群集。 一 NAT 模式 部署简单:NAT 模式下,所有的服务器节点只需要连接到同一个局域网内,通过负载均衡器进行网络地址转…...

CSS3+动画
浏览器内核以及其前缀 css标准中各个属性都要经历从草案到推荐的过程,css3中的属性进展都不一样,浏览器厂商在标准尚未明确的情况下提前支持会有风险,浏览器厂商对新属性的支持情况也不同,所有会加厂商前缀加以区分。如果某个属性…...

使用DeepSeek和Kimi快速自动生成PPT
目录 步骤1:在DeepSeek中生成要制作的PPT主要大纲内容。 (1)在DeepSeek网页端生成 (2)在本地部署DeepSeek后,使用chatBox生成PPT内容 步骤2:将DeepSeek成的PPT内容复制到Kimi中 步骤3&…...

DeepSeek使用最佳实践
一、核心使用原则 任务结构化设计 明确目标:例如用“我需要生成包含5个功能的Python计算器代码”而非简单“帮我写代码”。分步拆解:复杂任务可拆成“需求分析->框架搭建->代码生成->测试验证”等阶段。格式约束:明确输出格式&…...

机器学习 - 进一步理解最大似然估计和高斯分布的关系
一、高斯分布得到的是一个概率吗? 高斯分布(也称为正态分布)描述的是随机变量在某范围内取值的概率分布情况。其概率密度函数(PDF)为: 其中,μ 是均值,σ 是标准差。 需要注意的是…...

Oracle常用导元数据方法
1 说明 前两天领导发邮件要求导出O库一批表和索引的ddl语句做国产化测试,涉及6个系统,6千多张表,还好涉及的用户并不多,要不然很麻烦。 如此大费周折原因,是某国产库无法做元数据迁移。。。额,只能我手动导…...

linux安装jdk 许可证确认 user did not accept the oracle-license-v1-1 license
一定要接受许可证,不然会出现 一、添加 ppa第三方软件源 sudo add-apt-repository ppa:ts.sch.gr/ppa二、更新系统软件包列表 sudo apt-get update三、接受许可证 echo debconf shared/accepted-oracle-license-v1-1 select true | sudo debconf-set-selection…...

Spring基于文心一言API使用的大模型
有时做项目我们可能会遇到要在项目中对接AI大模型 本篇文章是对使用文心一言大模型的使用总结 前置任务 在百度智能云开放平台中注册成为开发者 百度智能云开放平台 进入百度智能云官网进行登录,点击立即体验 点击千帆大模型平台 向下滑动,进入到模型…...

【Elasticsearch】derivative聚合
1.定义与用途 derivative聚合是一种管道聚合(pipeline aggregation),用于计算指定度量(metric)的变化率。它通过计算当前值与前一个值之间的差异来实现这一点。这种聚合特别适用于分析时间序列数据,例如监…...
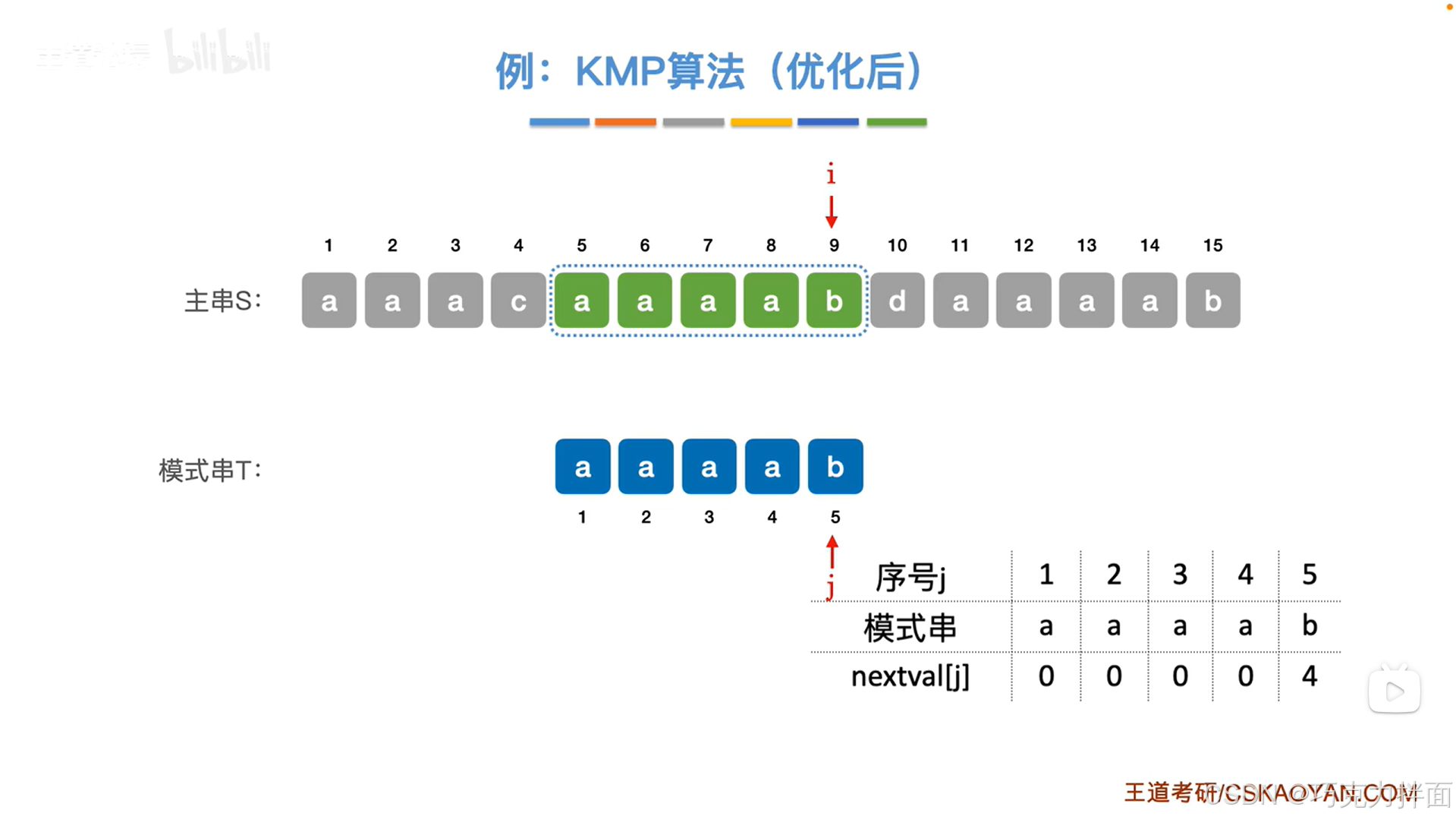
4.7.KMP算法(新版)
一.回顾:KMP算法基于朴素模式匹配算法优化而得来的 朴素模式匹配算法核心思想:把主串中所有长度与模式串长度相等的子串与模式串进行对比,直到找到第一个完全匹配的子串为止,如果当前尝试匹配的子串在某一个位置匹配失败…...

iOS AES/CBC/CTR加解密以及AES-CMAC
感觉iOS自带的CryptoKit不好用,有个第三方库CryptoSwift还不错,好巧不巧,清理过Xcode缓存后死活下载不下来,当然也可以自己编译个Framework,但是偏偏不想用第三方库了,于是研究了一下,自带的Com…...

错误报告:WebSocket 设备连接断开处理问题
错误报告:WebSocket 设备连接断开处理问题 项目背景 设备通过自启动的客户端连接到服务器,服务器将设备的 mac_address 和设备信息存入 Redis。前端通过 Redis 接口查看设备信息并展示。 问题描述 设备连接到服务器后,前端无法立即看到设…...

点云配准网络
【论文笔记】点云配准网络 PCRNet: Point Cloud Registration Network using PointNet Encoding 2019_pcr-net-CSDN博客 【点云配准】【深度学习】Windows11下PCRNet代码Pytorch实现与源码讲解-CSDN博客 【点云配准】【深度学习】Windows11下GCNet代码Pytorch实现与源码讲解_…...

黑马Redis详细笔记(实战篇---短信登录)
目录 一.短信登录 1.1 导入项目 1.2 Session 实现短信登录 1.3 集群的 Session 共享问题 1.4 基于 Redis 实现共享 Session 登录 一.短信登录 1.1 导入项目 数据库准备 -- 创建用户表 CREATE TABLE user (id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT 用户ID,phone …...

深入解析74181芯片中Cn+1的进位逻辑与实现原理
1. 74181芯片与Cn1进位的基础认知 第一次接触74181这块经典ALU芯片时,我被它内部精巧的进位逻辑设计震撼到了。这块诞生于上世纪60年代的4位算术逻辑单元,至今仍是理解计算机运算基础的绝佳教学案例。其中最精妙的部分莫过于Cn1进位信号的生成机制——它…...

深入RealReachability FSM引擎:有限状态机在iOS网络检测中的终极应用指南
深入RealReachability FSM引擎:有限状态机在iOS网络检测中的终极应用指南 【免费下载链接】RealReachability We need to observe the REAL reachability of network. Thats what RealReachability do. 项目地址: https://gitcode.com/gh_mirrors/re/RealReachabi…...
)
Maven项目实战:用Apache PDFBox 2.0.27实现PDF批量转PNG(附完整代码)
Maven项目实战:用Apache PDFBox 2.0.27实现PDF批量转PNG(附完整代码) 在Java开发者的日常工作中,PDF文档处理是一个高频需求场景。无论是电子合同归档、报表生成还是文档预览,将PDF转换为图片都是刚需功能。Apache PDF…...

别再只盯着高分框了!手把手教你用ByteTrack的‘两次匹配’搞定遮挡目标跟踪
ByteTrack实战:如何用两次匹配机制解决遮挡目标跟踪难题 在智慧交通路口,一辆公交车缓缓驶过摄像头,紧随其后的摩托车因完全被遮挡而"消失"在系统中;商场监控画面里,密集人群中突然蹲下系鞋带的顾客被算法判…...

UE5 Python远程执行:利用UDP组播实现高效命令分发
1. 为什么需要UE5 Python远程执行? 想象一下这个场景:你正在开发一个大型UE5项目,团队里有10个设计师需要同时修改场景参数。传统做法是每个人手动操作编辑器,或者通过RPC一个个连接。这种方式的效率有多低,相信每个开…...

网站外部 SEO 优化有哪些策略_SEO 网络推广与传统推广有什么区别
<h2>网站外部 SEO 优化有哪些策略</h2> <p>在当今的数字营销领域,外部 SEO 优化已经成为提升网站排名和流量的关键策略。外部 SEO(Search Engine Optimization)优化是一项通过外部手段提升网站在搜索引擎结果页面ÿ…...

人形机器人强化学习实战:从奖励设计到PPO算法优化
1. 人形机器人强化学习入门:为什么奖励设计是关键 第一次接触人形机器人强化学习时,我被一个简单问题困扰了很久:为什么同样的算法,换个任务就要重新调参?后来发现问题的核心在于奖励函数设计。就像教小孩学走路&#…...
- 部署实践篇)
Kubernetes集群的搭建与DevOps实践(下)- 部署实践篇
需求清单: 100张数据表要迁移(还要支持后续动态新增) 双链路同步:MySQL到MySQL、MongoDB到PostgreSQL 不能写死配置,要能灵活扩展 工期不到1个月 技术约束: 源环境(塔外)和目标环境&…...
)
别再纠结了!手把手教你根据团队规模和技术栈选对存储方案(Ceph vs MinIO实战对比)
技术选型实战:Ceph与MinIO的团队适配决策框架 当技术负责人面对存储方案选型时,往往陷入"功能强大"与"简单易用"的两难抉择。我曾见证过一家50人规模的AI创业公司,因盲目选择Ceph导致三个月后不得不重构基础设施——他们…...

韩式健康板供应商筛选:企业采购决策策略深度解析
韩式健康板供应商筛选:企业采购决策6步策略,避开80%行业坑点“韩式健康板供应商筛选不是只看价格,掌握6个关键步骤才能选到靠谱伙伴”——这是行业内资深采购的共识。本文针对企业采购韩式健康板的核心痛点,从需求梳理到持续监控&…...