Spring Batch 概览
Spring Batch 是什么?
Spring Batch 是 Spring 生态系统中的一个轻量级批处理框架,专门用于处理大规模数据任务。它特别适合企业级应用中需要批量处理数据的场景,比如数据迁移、报表生成、ETL(Extract-Transform-Load)流程等。它的核心目标是提供一个健壮、可扩展的解决方案,让开发者能高效地定义和执行批处理作业,同时处理大量数据时保证可靠性。
Spring Batch 的设计基于 Spring 框架,继承了 Spring 的依赖注入和面向切面编程(AOP)等特性,再结合批处理领域的常见模式(如分块处理、事务管理、错误重试等),形成了一套完整的批处理体系。
Spring Batch 的核心原理
Spring Batch 的工作原理可以用“作业(Job)”和“步骤(Step)”这两个概念来概括。它的架构围绕着批处理的经典模式:读取数据(Read)、处理数据(Process)、写入数据(Write)。以下是它的核心原理和关键组件的拆解:
1. 作业(Job)和步骤(Step)
- 作业(Job):一个完整的批处理任务称为“作业”。比如“从 CSV 文件读取用户数据,处理后存入数据库”就是一个 Job。Job 是 Spring Batch 的顶层概念,它由一个或多个步骤(Step)组成。
- 步骤(Step):作业的具体执行单元。每个 Step 通常包含读取、处理和写入数据的逻辑。Step 是 Job 的子任务,可以串行执行,也可以并行执行。
Spring Batch 通过 JobRepository(作业仓库)来管理和持久化 Job 和 Step 的状态。每次运行 Job 时,框架会记录它的执行情况(比如开始时间、结束时间、成功或失败状态),以便支持重启、监控等功能。
2. 分块处理(Chunk-Oriented Processing)
Spring Batch 的核心执行模式是“分块处理”(Chunk-Oriented Processing),这是它区别于传统逐条处理的关键:
- 读取(ItemReader):从数据源(如文件、数据库、消息队列)读取数据,每次读取一条记录。
- 处理(ItemProcessor):对读取到的每条数据进行加工,比如格式转换、过滤、计算等。这一步是可选的,如果不需要加工可以跳过。
- 写入(ItemWriter):将处理后的数据批量写入目标(如数据库、文件)。Spring Batch 不是逐条写入,而是攒够一定数量(称为“Chunk Size”,比如 100 条)后一次性提交,这样能显著提升性能。
这种分块处理的原理类似于“攒一波再干活”,通过批量操作减少 I/O 开销,同时结合事务管理,确保数据一致性。如果某个 Chunk 处理失败,Spring Batch 会回滚这个 Chunk 的事务,而不会影响其他 Chunk。
3. 任务执行与调度
Spring Batch 不直接负责调度(比如定时运行),但它提供了 JobLauncher(作业启动器)来触发 Job 的执行。开发者可以通过 Spring Boot 的 @Scheduled 注解或其他调度工具(如 Quartz)结合 JobLauncher,实现定时或手动启动 Job。
执行时,Spring Batch 会:
- 从
JobRepository检查 Job 的状态,决定是新建执行还是重启之前的失败作业。 - 按顺序(或并行)执行每个 Step。
- 在每个 Step 内,按 Chunk Size 分块处理数据。
4. 元数据管理
Spring Batch 需要一个数据库来存储批处理的元数据(Metadata),比如:
BATCH_JOB_INSTANCE:记录每个 Job 实例。BATCH_JOB_EXECUTION:记录每次 Job 的执行情况。BATCH_STEP_EXECUTION:记录每个 Step 的执行情况。
这些元数据不仅用于监控和日志,还支持“重启”(Restart)和“跳过”(Skip)功能。如果 Job 中途失败,Spring Batch 可以从上一次成功的点继续执行,而不会重复处理已完成的部分。
5. 容错与扩展
Spring Batch 内置了强大的容错机制:
- 重试(Retry):如果某条记录处理失败,可以配置重试次数和目标异常。
- 跳过(Skip):如果重试仍失败,可以跳过这条记录,继续处理后续数据。
- 分区(Partitioning):对于超大数据量,Spring Batch 支持将数据分成多个分区(Partition),交给多个线程或进程并行处理,提升吞吐量。
这些特性让 Spring Batch 在面对复杂场景时也能保持稳定性和高性能。
Spring Batch 的工作流程
以一个简单例子说明原理:假设我们要从 CSV 文件读取 1000 条用户记录,过滤掉年龄小于 18 的用户,然后存入数据库。Spring Batch 的工作流程如下:
-
定义 Job 和 Step:
- 配置一个 Job,包含一个 Step。
- Step 中指定
ItemReader(读取 CSV)、ItemProcessor(过滤年龄)、ItemWriter(写入数据库)。
-
分块执行:
- 设置 Chunk Size 为 100。
ItemReader从 CSV 读取一条记录,交给ItemProcessor。ItemProcessor检查年龄,如果小于 18 返回 null(表示过滤掉),否则返回处理后的数据。- 攒够 100 条有效记录后,
ItemWriter一次性写入数据库。
-
事务管理:
- 每个 Chunk 是一个独立的事务。如果第 3 个 Chunk(201-300 条)写入失败,Spring Batch 会回滚这个 Chunk,但不会影响已成功的 1-200 条。
-
元数据记录:
- Job 和 Step 的执行状态存入数据库。如果任务中断,下次重启时从第 201 条开始处理。
-
结果:
- 最终数据库中存储了年龄大于等于 18 的用户记录,CSV 中的无效数据被过滤。
核心组件详解
以下是 Spring Batch 的关键组件及其作用:
- Job:批处理的顶层容器,定义整个任务。
- Step:Job 的执行单元,可以是分块处理(Chunk-Oriented)或简单任务(Tasklet)。
- ItemReader:数据读取器,支持多种来源(如 CSV、XML、数据库、JMS)。
- ItemProcessor:数据处理器,负责转换或过滤(可选)。
- ItemWriter:数据写入器,支持多种目标(如文件、数据库、消息队列)。
- JobRepository:存储元数据的仓库,通常基于关系型数据库(如 H2、MySQL)。
- JobLauncher:启动 Job 的工具,可以手动调用或通过调度触发。
- ExecutionContext:执行上下文,用于在 Step 或 Job 间传递数据,支持重启时恢复状态。
Spring Batch 的优势
- 模块化:通过 Reader、Processor、Writer 分离职责,代码结构清晰,易于维护。
- 高性能:分块处理和分区机制大幅提升大数据处理的效率。
- 容错性:重试、跳过、重启等功能保证任务的可靠性。
- 生态集成:与 Spring Boot、Spring Data 等无缝整合,减少配置成本。
- 可扩展性:支持并行处理和分布式部署,适应企业级需求。
实际应用中的原理示例
假设一个金融系统需要每天凌晨处理前一天的交易记录:
- Job:名为“DailyTransactionJob”。
- Step 1:从 CSV 文件读取交易记录(ItemReader),过滤无效交易(ItemProcessor),写入临时表(ItemWriter)。
- Step 2:从临时表读取数据,计算汇总统计,写入最终报表表。
- 调度:通过 Spring Boot 的
@Scheduled在凌晨 1 点启动。 - 容错:如果某条记录格式错误,跳过并记录日志,不影响整体任务。
Spring Batch 会将数据分成每 1000 条一个 Chunk,逐块处理。如果中途宕机,下次启动时从上次成功的 Chunk 继续,避免重复计算。
总结
Spring Batch 的原理可以用一句话概括:通过分块处理和元数据管理,将大规模数据任务分解为可控的步骤,提供高效、可靠的批处理能力。它的核心在于“分而治之”和“健壮性”,通过 Job 和 Step 的结构化设计,结合 Reader-Processor-Writer 的流程,再加上事务、容错和扩展机制,让开发者能轻松应对复杂的批处理需求。
相关文章:

Spring Batch 概览
Spring Batch 是什么? Spring Batch 是 Spring 生态系统中的一个轻量级批处理框架,专门用于处理大规模数据任务。它特别适合企业级应用中需要批量处理数据的场景,比如数据迁移、报表生成、ETL(Extract-Transform-Load)…...

用Deepseek写一个五子棋微信小程序
在当今快节奏的生活中,休闲小游戏成为了许多人放松心情的好选择。五子棋作为一款经典的策略游戏,不仅规则简单,还能锻炼思维。最近,我借助 DeepSeek 的帮助,开发了一款五子棋微信小程序。在这篇文章中,我将…...

AF3 squeeze_features函数解读
AlphaFold3 data_transforms 模块的 squeeze_features 函数的作用去除 蛋白质特征张量中不必要的单维度(singleton dimensions)和重复维度,以使其适配 AlphaFold3 预期的输入格式。 源代码: def squeeze_features(protein):&qu…...

Python 远程抓取服务器日志最后 1000行
哈喽,大家好,我是木头左! 一、神奇的 Python 工具箱 1. SSH 连接的密钥——paramiko paramiko 库提供了丰富的方法来处理 SSH 连接的各种细节。从创建连接对象,到执行远程命令,再到获取命令输出,它都能有…...
vue3+screenfull实现部分页面全屏(遇到的问题会持续更新)
需求:除了左侧菜单,右侧主体部分全部全屏 首先下载screenfull全屏插件 npm install screenfull --save页面引入 import screenfull from screenfull;我这里是右上角全屏图标 <el-iconref"elIconRef"color"#ffffff"size"2…...
)
Ubuntu 下 nginx-1.24.0 源码分析 (1)
main 函数在 src\core\nginx.c int ngx_cdecl main(int argc, char *const *argv) {ngx_buf_t *b;ngx_log_t *log;ngx_uint_t i;ngx_cycle_t *cycle, init_cycle;ngx_conf_dump_t *cd;ngx_core_conf_t *ccf;ngx_debug_init(); 进入 main 函数 最…...

2025数据存储技术风向标:解析数据湖与数据仓库的实战效能差距
一、技术演进的十字路口 当前全球数据量正以每年65%的复合增长率激增,IDC预测到2027年企业将面临日均处理500TB数据的挑战。在这样的背景下,传统数据仓库与新兴数据湖的博弈进入白热化阶段。Gartner最新报告显示,采用混合架构的企业数据运营效…...

探索高性能AI识别和边缘计算 | NVIDIA Jetson Orin Nano 8GB 开发套件的全面测评
随着边缘计算和人工智能技术的迅速发展,性能强大的嵌入式AI开发板成为开发者和企业关注的焦点。NVIDIA近期推出的Jetson Orin Nano 8GB开发套件,凭借其40 TOPS算力、高效的Ampere架构GPU以及出色的边缘AI能力,引起了广泛关注。本文将从配置性…...

数据结构 常见的排序算法
🌻个人主页:路飞雪吖~ 🌠专栏:数据结构 目录 🌻个人主页:路飞雪吖~ 一、插入排序 🌟直接插入排序 🌟希尔排序 二、选择排序 🌟选择排序 🌟堆排序…...

ES索引知识
索引是数据的载体,存储了文档和映射的信息 索引是具有相同结构的文档的合集体。 设置索引,不仅仅是设置索引名字,还有索引的一些配置,比如:分片和副本,刷新频率,搜索结果的最大参数,…...

FreeRTOS第17篇:FreeRTOS链表实现细节05_MiniListItem_t:FreeRTOS内存优化
文/指尖动听知识库-星愿 文章为付费内容,商业行为,禁止私自转载及抄袭,违者必究!!! 文章专栏:深入FreeRTOS内核:从原理到实战的嵌入式开发指南 1 为什么需要迷你列表项? 在嵌入式系统中,内存资源极其宝贵。FreeRTOS为满足不同场景需求,设计了标准列表项(ListItem_…...
)
Golang | Gin(简洁版)
文章目录 安装使用RESTful API响应页面获取请求参数路由讲解中间件 安装使用 Gin 是一个 golang 的微框架,封装比较优雅,API 友好,源代码比较明确。具有快速灵活,容错方便等特点。其实对于 golang 而言,web 框架的依赖…...

RAG外挂知识库
目录 RAG的工作流程 python实现RAG 1.引入相关库及相关准备工作 函数 1. 加载并读取文档 2. 文档分割 3. embedding 4. 向集合中添加文档 5. 用户输入内容 6. 查询集合中的文档 7. 构建Prompt并生成答案 主流程 附录 函数解释 1. open() 函数语法 2.client.embe…...

Rust语言:开启高效编程之旅
目录 一、Rust 语言初相识 二、Rust 语言的独特魅力 2.1 内存安全:消除隐患的护盾 2.2 高性能:与 C/C++ 并肩的实力 2.3 强大的并发性:多线程编程的利器 2.4 跨平台性:适配多环境的优势 三、快速上手 Rust 3.1 环境搭建:为开发做准备 3.2 第一个 R…...

蓝桥杯备考:图论初解
1:图的定义 我们学了线性表和树的结构,那什么是图呢? 线性表是一个串一个是一对一的结构 树是一对多的,每个结点可以有多个孩子,但只能有一个父亲 而我们今天学的图!就是多对多的结构了 V表示的是图的顶点集…...

Codeforces Round 502 E. The Supersonic Rocket 凸包、kmp
题目链接 题目大意 平面上给定两个点集,判定两个点集分别形成的凸多边形能否通过旋转、平移重合。 点集大小 ≤ \leq ≤ 1 0 5 10^{5} 105,坐标范围 [0, 1 0 8 10^{8} 108 ]. 思路 题意很明显,先求出凸包再判断两凸包是否同构。这里用…...

机器人匹诺曹机制,真话假话平衡机制
摘要: 本文聚焦于机器人所采用的一种“匹诺曹机制”,该机制旨在以大概率保持“虚拟鼻子”(一种象征虚假程度的概念)不会过长,通过在对话中夹杂真话与假话来实现。文章深入探讨了这一机制的原理,分析其背后的…...

用Python分割并高效处理PDF大文件
在处理大型PDF文件时,将它们分解成更小、更易于管理的块通常是有益的。这个过程称为分区,它可以提高处理效率,并使分析或操作文档变得更容易。在本文中,我们将讨论如何使用Python和为Unstructured.io库将PDF文件划分为更小的部分。…...
【RAG】混合检索(Hybrid Search) 提高检索精度
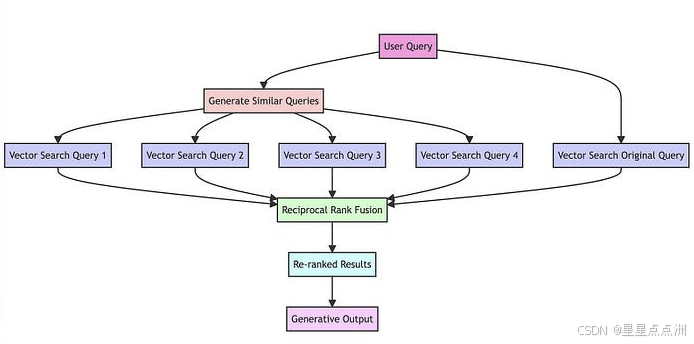
1.问题:向量检索也易混淆,而关键字会更精准 在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有利弊。 举个具体例子,比如文档中包含很长的专有名词, 关…...

CTFHub-FastCGI协议/Redis协议
将木马进行base64编码 <?php eval($_GET[cmd]);?> 打开kali虚拟机,使用虚拟机中Gopherus-master工具 Gopherus-master工具安装 git clone https://github.com/tarunkant/Gopherus.git 进入工具目录 cd Gopherus 使用工具 python2 "位置" --expl…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...