大模型混战,阿里百度华为谁将成就AI时代的“新地基”?
从算力基础到用户生态,群雄逐鹿大模型
自2022年stable diffusion模型的进步推动AIGC的快速发展后,年底,ChatGPT以“破圈者”的姿态,快速“吸粉”亿万,在全球范围内掀起了一股AI浪潮,也促使了众多海外巨头竞相发布属于自己的大模型。
而在国内,实际上很久之前,阿里、华为、腾讯等公司便早已有所布局:2019年,阿里开始布局大模型研发,去年9月发布“通义”大模型系列的众多大模型;华为在2021年基于昇腾AI与鹏城实验室联合发布了鹏程盘古大模型;而腾讯的思路也与阿里相似,发布了混元AI大模型;第二梯队的京东、网易、360、字节跳动等企业,也纷纷官宣了自己在AI大模型方面的布局。
而进入2023年以来,随着文心一言的发布,成为了中国第一个类ChatGPT产品后,各家的大模型也纷纷亮相,一时间,国内仿佛陷入了“大模型之战”中。
截至目前,百度文心大模型、华为盘古大模型、商汤大模型、阿里大模型都已亮相,而后还有许多大模型正在准备粉墨登场。
那么,在这匆匆发布的背后,是真的技术成熟,还是鱼龙混杂?各个大模型的实力又是怎样?
本文将从语言大模型、算力与技术底座与具体应用层面状况三大角度,来分析和研究目前已经发布的大模型的技术基础、应用场景和用户生态,看看哪些大模型更有可能在这混战中成功突围。
01 | ChatGPT不该止于C端
ChatGPT,作为最早出圈的大模型产品应用,其问答的流畅程度与准确程度,可以很好地体现NLP模型的水平。
而目前,国内厂商百度、阿里也都发布了类似模型,那么,相比之下,文心一言与通义千问的表现如何?
首先是最近对话式AI们经常出现的一个典型问题,面对自己知识库中没有,或本身就是错误的提问时,仍能对着错误描述侃侃而谈,简称一本正经的胡说八道。
于是,我先问了通义千问这样一个问题:你知道唐僧为什么要上梁山吗?
通义千问在思考后,给出了这样的回答:它首先简单对唐僧进行了介绍,然后将其带入了《水浒传》中宋江的角色,但最后却又回到了《西游记》中,还讲“这一情节体现了唐僧的坚定和决心,也反映了他作为一个有信仰的人物的形象。”

而同样的问题给了文心一言,却得到了一个更加简短但同样荒谬的答案:唐僧上梁山的原因是因为他被迫出走,被唐朝通缉,无路可走,只能上梁山。

本次测试中,通义千问与文心一言都犯了同样的错误,不过,在我指正之后,通义千问也进行了积极地认错,展现出了良好的连续问答能力,而文心一言则并没有“听懂”我的指正。
接下来,我又问了它们一个经典的数学问题——鸡兔同笼,“鸡兔同笼,头共10,足共28,鸡兔各几只?”
通义千问在得到提问后,快速做出了回答,为我列出了计算该问题所需要的方程式,还贴心地在后面备注上了方程式的由来。

而文心一言就显得更加直接,回答了我的问题。

而在这两个问题之外,我还让它们两个一起编写了代码、赏析了诗词、撰写了文章。
总得来说,在面对用户提出的问题时,通义千问与文心一言在绝大多数情况都可以给出较为正确的回答,在面对C端用户的提问时,两个产品显示出了不相上下的实力。
而在C端的势均力敌之下,阿里却祭出了同类竞品难以比拟的B端服务能力。
通义千问在C端用户之外,专门针对企业用户发出了邀请共测,企业可基于通义千问打造专属大模型,在企业专属的大模型空间中,既可以调动通义千问的全部能力,也可以结合企业自己的行业知识和应用场景,训练自己的企业大模型。
具体而言,除了通用场景之外,企业由于业务特性的不同,对于大模型服务有特殊需求和要求,希望让通用的大模型变成企业专属的大模型,支撑企业各式各样的应用与服务。
阿里云希望通过产品化的方式,满足企业专属大模型从生成到部署全生命周期的需求。

在发布会当天,阿里云就宣布将与OPPO安第斯智能云联合打造OPPO大模型基础设施,基于通义千问完成大模型的持续学习、精调及前端提示工程,未来建设服务于其海量终端用户的AI服务。
同时,中兴通讯、吉利汽车、智己汽车、奇瑞新能源、毫末智行、太古可口可乐、波司登、掌阅科技等多家企业也表示,将与阿里云在大模型相关场景展开技术合作的探索和共创。
或许,在竞争激烈的C端之外,面向企业端的大模型构建能力,才是通义千问真正的优势所在。
而相关专家也在交流中表示,通义千问将会在企业各自深耕的领域中为他们提供构建大模型方面的帮助,带来更好的生态系统与商业模式。
02 | 大模型背后的算力之争,谁占先机?
纵观国内发布的大模型,可以发现,相对于国外尖端的AI企业来说,国内还像是蹒跚学步的孩童,在这条道路上刚刚起步。
而在大模型发展的道路上,最重要的实际上还是最基础的算力资源的多少与怎样利用算力的能力,那么国内顶尖大模型企业在算力上的储备几何?
首先是近日同样发布了大模型的商汤科技,在前段时间的交流中,商汤科技内部的相关专家对公司的算力情况进行了交流。
国内能拿到最尖端的显卡是来自英伟达的A100 GPU,商汤科技在美国对华禁售之前,便提前囤积了上万张A100芯片,是国内算力资源比较充足的厂商。
除了来自英伟达的显卡之外,商汤还在采购国内的GPU,并且专家表示,早在去年以前,就已经在大装置中适配了许多寒武纪与海光信息的GPU卡,但在当下商汤仍旧面临着如何将国产GPU卡进行大模型训练适配的问题。
在商汤之外,华为的盘古大模型也引起了众人瞩目,但在算力资源方面,华为却略显窘迫。
因为受到美国的长期制裁,华为只得使用全部国产的加速芯片,而目前昇腾系列最先进大幅使用的型号昇腾910,也只有A100 70%的性能,从长期来看,将会制约大模型的发展。
而算力的短缺也直接影响了华为的发展策略,选择性地放弃了C端的发展,主攻B端工业大模型应用。
而说起算力资源储备最多的企业,莫过于云时代中独占鳌头的阿里。
但从阿里云上的角度来看,当前云上至少拥有上万片的A100 GPU,从整体来说,阿里云的算力资源至少能够达到10万片以上。如果继续抬眼,从整个集团的算力资源来说,将会是阿里云5倍的这样的一个量级。
而在英伟达的芯片之外,阿里云也拥有众多国产化的GPU芯片,而最近的项目中,便选择了寒武纪MLU370,其性能基本过关(A100的60-70%),检测合格,厂商态度积极,愿意与阿里对接,并且已经用在了CV等小模型的训练和推理上。
在2023年,阿里云算力资源的增速也将达到30%-50%。
得益于云时代的绝对领先,让阿里拥有了远超其他企业的算力资源,也让其在AI时代里天生就占得了上风。
但是,动辄超千亿参数的大模型研发,并不能靠简单堆积GPU就能实现,这是囊括了底层算力、网络、存储、大数据、AI框架、AI模型等复杂技术的系统性工程,需要AI-云计算的全栈技术能力。
而阿里是全球少数在这几个领域都有深度布局、长久积累的科技公司之一,也是为数不多拥有超万亿参数大模型研发经验的机构。
在AI算法方面,阿里达摩院是国内最早启动大模型研究的机构之一,2019年便开始投入大模型研发,在中文大模型领域一直处于引领地位,2021年阿里先后发布国内首个超百亿参数的多模态大模型及语言大模型,此后还训练实现了全球首个10万亿参数AI模型。
在智能算力方面,阿里建成了国内最大规模的智算中心“飞天智算平台”,千卡并行效率达90%,自研网络架构可对万卡规模的AI集群提供无拥塞、高性能的集群通讯能力。基于飞天智算的阿里云深度学习平台PAI,可将计算资源利用率提高3倍以上,AI训练效率提升11倍,推理效率提升6倍,覆盖全链路AI开发工具与大数据服务,深度支持了通义大模型的研发。
阿里云全栈AI技术体系,更是从机器学习平台、大模型即服务、产业智能三个层面,不断丰富AI服务,并通过全栈技术驱动千行百业的AI发展与应用。

可以说,阿里在云时代的成功,在一定程度上延续到了AI时代,与那些算力资源相对不足的竞争者来说,阿里在算力与技术底座方面,有着无可比拟的巨大优势。
03 | 大模型带来业务集合式飞跃
在拥有了算力资源与技术底座后,大模型能力若想要普惠大众,触达到每一个人,就需要应用层面的生态建设,而这,也正是众多厂商“刺刀见红”的战场,众多厂商也依据企业发展的不同,做出了不同的选择。
比如,华为盘古大模型,受算力资源不足与公司业务导向的影响,选择了指向B端的打法。
在盘古大模型发布会上,华为没有着墨于NLP模型,而是着重强调了CV大模型与科学计算大模型的应用范例。
盘古CV大模型主要应用于智能巡检、智慧物流等场景。
例如,在与能源公司合作的盘古矿山大模型中案例中,矿井现场是一个40米长的采掘机,宽度仅2米左右,传统相机很难一下子捕捉到全部画面,只能用图中的九宫格视频画面。而通过5G+AI全景视频拼接综采画面卷,传输到地面,地面工作人员将来可以实现地面控制机器进行采矿,实现矿下无人少人安全作业。
而盘古气象大模型,也在气象预测方向上超过了传统数值的计算方法。
盘古气象大模型在气象预报的关键要素和常用时间范围上精度均超过当前最先进的预报方法,同时速度相比传统方法提升 1000 倍以上。如在台风路径预测任务上,相比传统数值气象预报方法,盘古气象大模型可以降低 20%以上的位置误差。
而对阿里而言,其在国内领先的大模型能力与众多的业务板块,让阿里大模型在各个领域都能一展拳脚。
阿里云智能集团CEO张勇在峰会上表示,阿里巴巴所有产品未来都将接入“通义千问”大模型,进行全面改造,包括天猫、钉钉、高德地图、淘宝、优酷、盒马等。

以阿里起家的电商赛道来说,大模型就有许多应用场景。
对商家而言,大模型最切合实际的应用场景莫过于智能客服。随着电商行业逐渐成熟,消费者对服务质量的要求日益提高,客服这个岗位有着极为巨大的降本增效需求。
而经过通义千问的改造后,能听懂消费者的话、明白消费者诉求的聪明客服机器人也将上线,将基于机器学习、大数据、、语义分析和理解等多项人工智能技术,为消费者提供最优质的服务。
对于平台而言,大模型可以有效提升用户的购物体验。比如,用户可能有时不清楚自己的明确需求,但通过与AI导购员交流,可以得到相当多的指引信息以及购物清单,比如开一个生日party需要哪些方面的准备,化妆需要购买哪些工具等。
在电商场景之外,接入通义千问后的办公场景,也将实现多项全新功能。
例如在钉钉文档中,可借助通义千问自动配图、创作文章、撰写邮件、生成方案;在会议中,可以完成记录、总结、生产待办事项;甚至还能帮助总结未读群聊信息中的要点......
可以说,无论是对B端的企业还是C端的用户,只要有阿里系产品存在的地方,在接入通义千问后,其智能水平与易用水平,都将快速提升一个档次。
而对阿里来说,作为国内最大的商业集团之一,有了通义千问的加持,得到的提升将不会仅仅局限于某个业务线或是某个方向,而将是整体实力的飞跃。
04 | 结语
AI大模型的浪潮,开启了一个新的时代,将所有的互联网厂商都重新拉到了同一起跑线上。
在2023阿里云峰会上,阿里巴巴集团董事会主席兼CEO、阿里云智能集团CEO张勇也说出,“面对AI时代,所有产品都值得用大模型重做一次。”
而在一切应用重建后的AI时代里,核心竞争力究竟是什么?也成为了厂商们需要思考的首要问题。
在我看来,坚实的算力基础与良好的用户生态,将成为AI时代里成功的两个必要条件。
而国内,谁拥有最多高端算力资源与强大的算法进化能力,在这场大模型之战中,就有着其他企业无法比拟、得天独厚的优势。
相关文章:
大模型混战,阿里百度华为谁将成就AI时代的“新地基”?
从算力基础到用户生态,群雄逐鹿大模型 自2022年stable diffusion模型的进步推动AIGC的快速发展后,年底,ChatGPT以“破圈者”的姿态,快速“吸粉”亿万,在全球范围内掀起了一股AI浪潮,也促使了众多海外巨头竞…...
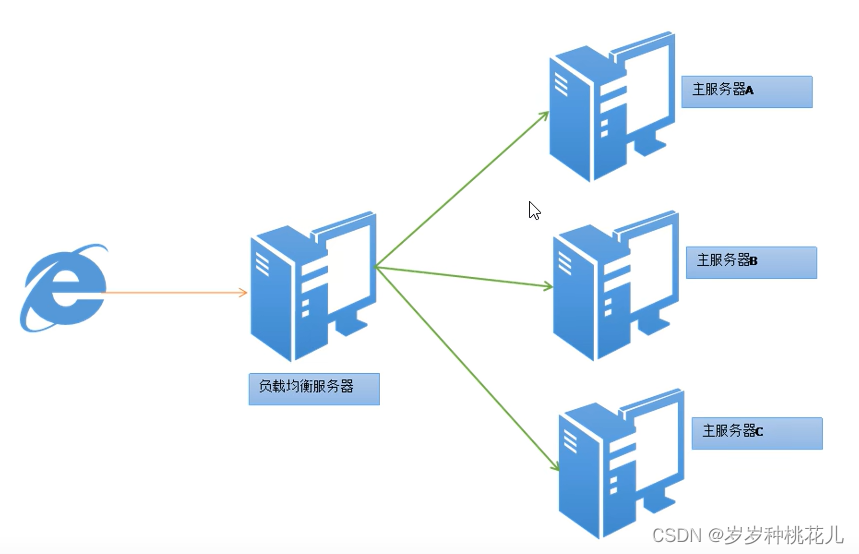
干翻Hadoop系列之:Hadoop前瞻之分布式知识
前言 一:海量数据价值 二:海量数据两个棘手问题 1:海量数据如何存储? 掌握分布式存储数据的思想。 A:方案1:单机存储磁盘不够加磁盘 限制问题: 1:一台计算机不能无限制拓充 2&a…...
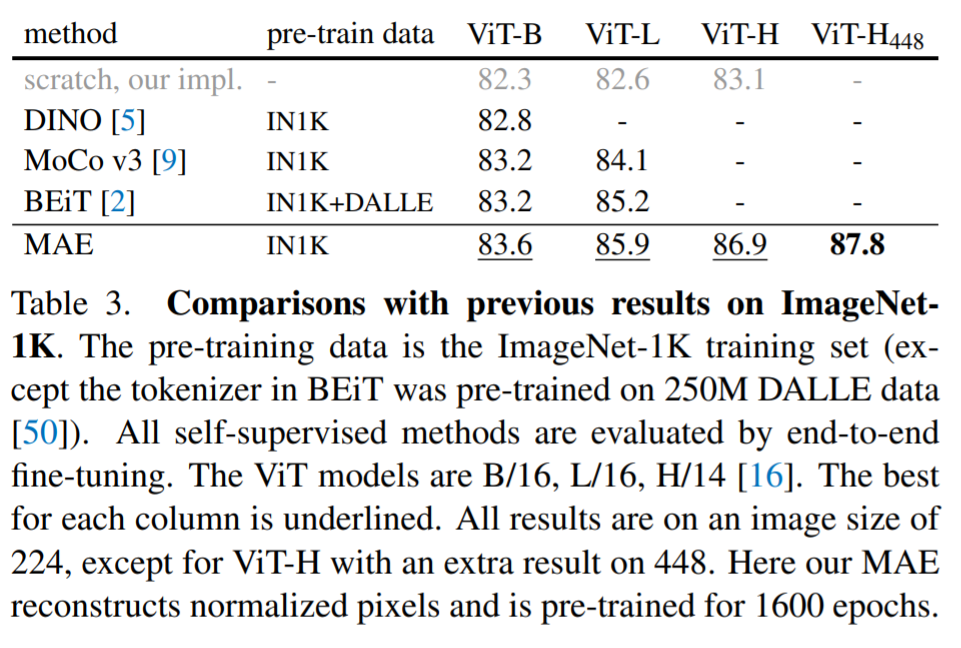
MAE论文阅读《Masked Autoencoders Are Scalable Vision Learners》
文章目录动机方法写作方面参考Paper: https://arxiv.org/pdf/2111.06377.pdf 动机 首先简要介绍下BERT,NLP领域的BERT是基于Transformer架构,并采取无监督预训练的方式去训练模型。它提出的预训练方法在本质上是一种masked autoencoding,也就…...

代码随想录算法训练营第三十四天-贪心算法3| 1005.K次取反后最大化的数组和 134. 加油站 135. 分发糖果
1005. Maximize Sum Of Array After K Negations 参考视频:贪心算法,这不就是常识?还能叫贪心?LeetCode:1005.K次取反后最大化的数组和_哔哩哔哩_bilibili 贪心🔍 的思路,局部最优ÿ…...
)
比较系统的学习 pandas (2)
pandas 数据读取与输出方法和常用参数 1、读取 CSV文件 pd.read_csv("pathname",step,encoding"gbk",header"infer",name[],skip_blank_linesTrue,commentNone) path : 文件路径 step : 指定分隔符,默认为 逗号 enco…...

怎么查看电脑主板最大支持多少内存?
很多电脑,内存不够用,但应速度慢;还有一些就是买了很大的内存条,但是还是反应慢;这是为什么呢?我今天明白了,原来每个电脑都有自己的适配内存,就是每个电脑能支持多大的内存…...

数据结构——线段树
线段树的结构 线段树是一棵二叉树,其结点是一条“线段”——[a,b],它的左儿子和右儿子分别是这条线段的左半段和右半段,即[a, (ab)/2 ]和[(ab)/2 ,b]。线段树的叶子结点是长度为1的单位线段[a,a1]。下图就是一棵根为[1,10]的线段树࿱…...

【C++进阶】实现C++线程池
文章目录1. thread_pool.h2. main.cpp1. thread_pool.h #pragma once #include <iostream> #include <vector> #include <queue> #include <thread> #include <mutex> #include <condition_variable> #include <future> #include &…...

Redis常用五种数据类型
一、Redis String字符串 1.简介 String类型在redis中最常见的一种类型 string类型是二制安全的,可以存放字符串、数值、json、图像数据 value存储最大数据量是512M 2. 常用命令 set < key>< value>:添加键值对 nx:当数据库中…...
)
C++ Primer第五版_第十一章习题答案(1~10)
文章目录练习11.1练习11.2练习11.3练习11.4练习11.5练习11.6练习11.7练习11.8练习11.9练习11.10练习11.1 描述map 和 vector 的不同。 map 是关联容器, vector 是顺序容器。 练习11.2 分别给出最适合使用 list、vector、deque、map以及set的例子。 list:…...

GEE:使用LandTrendr进行森林变化检测详解
作者:_养乐多_ 本文介绍了一段用于地表变化监测的代码,该代码主要使用谷歌地球引擎(GEE)中的 Landsat 时间序列数据,采用了 Kennedy 等人(2010) 发布的 LandTrendr 算法,对植被指数进行分割,通过计算不同时间段内植被指数的变化来检测植被变化。 目录 一、加入矢量边界 …...
docker项目实施
鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器_闭关苦炼内功的技术博客_51CTO博客鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器,本文是基于之前这篇文章鲲鹏920架构arm64版本centos7安装docker下面开始先来看下系统版本卸载旧版本旧版本…...
springboot实现邮箱验证码功能
引言 邮箱验证码是一个常见的功能,常用于邮箱绑定、修改密码等操作上,这里我演示一下如何使用springboot实现验证码的发送功能; 这里用qq邮箱进行演示,其他都差不多; 准备工作 首先要在设置->账户中开启邮箱POP…...
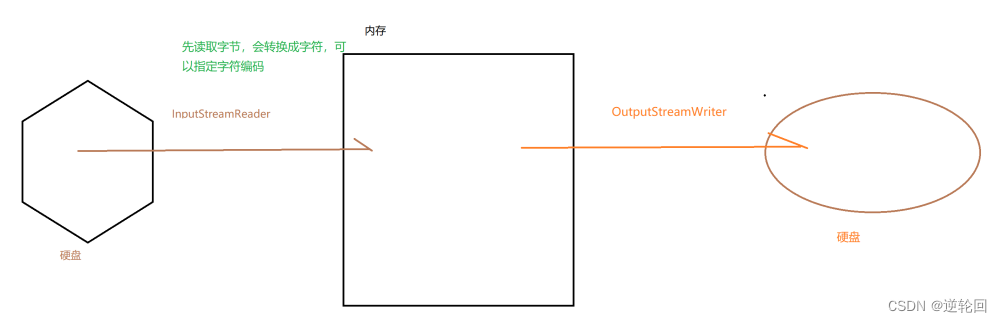
Java 进阶(5) Java IO流
⼀、File类 概念:代表物理盘符中的⼀个⽂件或者⽂件夹。 常见方法: 方法名 描述 createNewFile() 创建⼀个新文件。 mkdir() 创建⼀个新⽬录。 delete() 删除⽂件或空⽬录。 exists() 判断File对象所对象所代表的对象是否存在。 getAbsolute…...
“终于我从字节离职了...“一个年薪40W的测试工程师的自白...
”我递上了我的辞职信,不是因为公司给的不多,也不是因为公司待我不好,但是我觉得,我每天看中我憔悴的面容,每天晚上拖着疲惫的身体躺在床上,我都不知道人生的意义,是赚钱吗?是为了更…...

设计模式之策略模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、策略模式是什么? 策略模式是一种行为型的软件设计模式,针对某个行为,在不同的应用场景下&…...

从工厂普工到Python女程序员,聊聊这一路我是如何逆袭的?
我来聊聊我是如何从一名工厂普工,到国外程序员的过程,这里面充满了坎坷。过去我的工作是在工厂的流水线上,我负责检测电池的正负极。现如今我每天从早上6:20起床,6点四五十分出发到地铁站,7:40到公司。我会给自己准备一…...

全国青少年信息素养大赛2023年python·选做题模拟二卷
目录 打印真题文章进行做题: 全国青少年电子信息智能创新大赛 python选做题模拟二卷 一、单选题 1. numbers = [1, 11, 111, 9], 运行numbers.sort() 后,运行numbers.reverse() numbers会变成?( )...

分布式事务Seata原理
Seata 是一款开源的分布式事务解决方案,致力于提供高性能与简单易用的分布式事务服务,为用户提供了 AT、TCC、SAGA 和 XA 几种不同的事务模式。Seata AT模式是基于XA事务演进而来,需要数据库支持。AT 模式的特点就是对业务无入侵式࿰…...
用ChatGPT怎么赚钱?普通人用这5个方法也能赚到生活费
ChatGPT在互联网火得一塌糊涂,因为它可以帮很多人解决问题。比如:帮编辑人员写文章,还可以替代程序员写代码,帮策划人员写文案策划等等。ChatGPT这么厉害,能否用它来赚钱呢?今天和大家分享用ChatGPT赚钱的5…...

核心代码编程-社交网络相同爱好好友查询-200分
题目描述:在一个社交网络中,用户之间通过"关注"关系形成有向图。每个用户有两个属性 ﹣用户ID(整数字符串) ﹣兴趣标列表(字符串数组) 现在需要实现一个函数,查询…...

PADS Layout老手进阶:Gerber文件生成背后的‘负片’、‘钻孔图’与制造工艺解读
PADS Layout老手进阶:Gerber文件生成背后的‘负片’、‘钻孔图’与制造工艺解读 在PCB设计领域,Gerber文件是连接设计与制造的桥梁。对于使用PADS Layout的中高级工程师而言,仅仅掌握操作步骤远远不够。当面对四层或以上的复杂PCB板ÿ…...

智能体技能库构建指南:从基础工具到复杂工作流编排
1. 项目概述:智能体技能库的构建与价值最近在探索AI智能体(Agent)的开发与应用时,我一直在思考一个问题:一个真正“智能”的智能体,其核心能力究竟体现在哪里?是背后的大语言模型(LL…...

别再被VS2019的CMake报错劝退!从‘RC命令失败’看Windows C++开发环境那些坑
破解Windows C开发环境迷局:从CMake报错到系统级解决方案 当你在Visual Studio 2019中满怀期待地点击"生成解决方案",却看到控制台突然弹出"RC命令失败"的红色错误时,那种挫败感每个C开发者都深有体会。这不仅仅是一个简…...
)
【信息科学与工程学】计算机科学与自动化 第十篇 芯片设计04(5)
载流子统计与输运函数方程式详表 1. 载流子统计基础 (zailiu-1 ~ zailiu-100) 序号 名称 数学表达式/核心描述 参数说明 物理意义 应用场景 条件描述 zailiu-1 麦克斯韦-玻尔兹曼分布 f(E)=Ae−E/(kBT)或 f(v)=(2πkBTm)3/2e−mv2/(2kBT) E: 能量, v: 速度,…...
:make与makefile)
第9课:Linux开发工具(四):make与makefile
第9课:Linux开发工具(四):make与makefile 一、为什么我们需要 Makefile? 1.1 IDE 背后的秘密 在使用 Visual Studio 等 IDE 时,我们只需按下 F5 或点击"编译"按钮,程序就会自动完成编…...

【Microsystems Nanoengineering】利用多功能液晶偏振光栅抑制微型光学泵浦磁力计中的激光功率噪声
【Microsystems &Nanoengineering】利用多功能液晶偏振光栅抑制微型光学泵浦磁力计中的激光功率噪声 摘要 传统单光束光泵磁力仪(OPM)依赖分立偏振光学元件,体积大、装调复杂,且易受激光功率噪声限制。 本文提出 ** 多功能液晶…...

基于Playwright的Instagram自动化技能包:原理、实现与智能体集成
1. 项目概述与核心价值最近在折腾个人智能助理,想让它能帮我处理一些社交媒体上的琐事,比如自动查看Instagram上的新动态、给特定帖子点赞或者保存一些有趣的图片。在网上搜了一圈,发现了一个叫adamanz/instagram-skill的开源项目,…...

告别NuWriter!手把手教你用命令行打包新唐NUC980 SPI NAND完整系统镜像
新唐NUC980 SPI NAND量产化镜像构建实战指南 在嵌入式设备量产过程中,传统烧录方式往往成为效率瓶颈。当面对新唐NUC980这类基于SPI NAND的工控设备时,产线工程师常需要反复切换工具链、分步烧录不同组件,不仅耗时费力,还容易因人…...

【Unity进阶实战】将PC端EXE打包与压缩一体化:从项目设置到单文件发布
1. Unity项目打包前的关键设置 第一次用Unity打包PC端应用时,我踩过不少坑。记得有个项目打包后死活运行不起来,折腾半天才发现是场景没正确添加。所以打包前的准备工作特别重要,咱们一步步来。 打开Build Settings窗口(File >…...