lamda表达式
lamda表达式
- 一. lamda表达式的特性
- 二.常用匿名函数式接口
- 2.1 Supplier接口
- 2.2 Consumer接口
- 2.3 Predicate接口
- 2.4 Function接口
- 2.5 BiFunction接口
- 三.stream流传递先后顺序
- 四.表达式
- 4.1 ForEach
- 4.2 Collect
- 4.3 Filter
- 4.4 Map
- 4.5 MapToInt
- 4.6 Distinct
- 4.7 Sorted
- 4.8 groupingBy
- 4.9 FindFirst
- 4.10 Reduce
- 4.11 Peek
- 4.12 Limit
- 4.13 Max,Min
- 4.14 partitioningBy
- 末尾
一. lamda表达式的特性
1.匿名函数
与匿名内部类的区别:Lamda对应的接口只能有一个方法。匿名内部类对应的接口可以有多个方法
2.可传递性
可传递性理解:Lambda表达式传递给其他的函数,它当做参数例如:list.stream().map(s -> Integer.valueOf(s)).distinct().collect(Collectors.toList());
lamda表达式的格式
三要素:形式参数,箭头,代码块
形如:(形参)->代码块
形参如果多个参数,参数之间逗号隔开,如果没有参数,留空括号,不用留空格
-> 一定的是英文,固定写法,表示执行
代码块:具体要做的事情
使用前提:使用接口:接口当中有且只有一个抽象方法
二.常用匿名函数式接口
2.1 Supplier接口
作用:Supplier接口是对象实例的提供者,定义了一个名叫get的抽象方法,它没有任何入参,并返回一个泛型T对象
源码如下:
package java.util.function;@FunctionalInterface //注释:@FunctionalInterface写不写都可以。// 此注解主要用于编译级错误检查:当接口不符合函数式接口定义的时候,编译器会报错。
public interface Supplier<T> {T get();
}举例:
/*** 口罩类*/
public class Mask {public Mask(String brand, String type) {this.brand = brand;this.type = type;}/*** 品牌*/private String brand;/*** 类型*/private String type;public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}public String getType() {return type;}public void setType(String type) {this.type = type;}
}//创建实例与获取对象
Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建实例
Mask mask = supplier.get(); ---获取对象2.2 Consumer接口
Consumer接口是一个类似消费者的接口,定义了一个名叫accept的抽象方法,它的入参是一个泛型T对象,没有任何返回(void)
源码:
package java.util.function;@FunctionalInterface
public interface Consumer<T> {void accept(T t);
}Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建supplier实例
Consumer<Mask> consumer = (Mask mask) -> {System.out.println("Brand: " + mask.getBrand() + ", Type: " + mask.getType());
}; ----创建Consume实例
consumer.accept(supplier.get()); ---consume实例消费supplier实例
2.3 Predicate接口
Predicate接口是判断是与否的接口,定义了一个名叫test的抽象方法,它的入参是一个泛型T对象,并返回一个boolean类型
源码:
package java.util.function;@FunctionalInterface
public interface Predicate<T> {boolean test(T t);
}Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建supplier实例
Predicate<Mask> n95 = (Mask mask) -> "N95".equals(mask.getType()); ---用于判断是否为N95口罩
Predicate<Mask> kn95 = (Mask mask) -> "KN95".equals(mask.getType());
System.out.println("是否为N95口罩:" + n95.test(supplier.get()));
System.out.println("是否为KN95口罩:" + kn95.test(supplier.get()));2.4 Function接口
Function接口是对实例进行处理转换的接口,定义了一个名叫apply的抽象方法,它的入参是一个泛型T对象,并返回一个泛型R对象
源码:
package java.util.function;@FunctionalInterface
public interface Function<T, R> {R apply(T t);
}Supplier<Mask> supplier = () -> new Mask("3M", "N95"); ---创建一个supplier对象
Function<Mask, String> brand = (Mask mask) -> mask.getBrand(); ---Function对象获取Mask 转换为String 类型的值
Function<Mask, String> type = (Mask mask) -> mask.getType();
System.out.println("口罩品牌:" + brand.apply(supplier.get()));
System.out.println("口罩类型:" + type.apply(supplier.get()));
2.5 BiFunction接口
Function接口的入参只有一个泛型对象,JDK还为我们提供了两个泛型对象入参的接口:BiFunction接口
源码:
package java.util.function;@FunctionalInterface
public interface BiFunction<T, U, R> {R apply(T t, U u);
}//创建BiFunction实例---实现Mask对象
BiFunction<String,String,Mask> biFunction = (String brand, String type) -> new Mask(brand, type);
Mask mask = biFunction.apply("3M", "N95"); //赋值
System.out.println("Brand: " + mask.getBrand() + ", Type: " + mask.getType());三.stream流传递先后顺序
允许你以声明式的方式处理数据集合,可以把 它看作是遍历数据集的高级迭代器。此外与 stream 与 lambada 表达示结合后 编码效率与大大提高,并且可读性更强。
流更偏向于数据处理和计算,比如 filter、map、find、sort 等。简单来说,我们通过一个集合的 stream 方法获取一个流,然后对流进行一 系列流操作,最后再构建成我们需要的数据集合

这里分为 3 步 :
获得流—>中间操作---->终端操作
中间操作
往往对数据进行筛选
filter:过滤流中的某些元素,
sorted(): 自然排序,流中元素需实现 Comparable 接口
distinct: 去除重复元素
limit(n): 获取 n 个元素
skip(n): 跳过 n 元素,配合 limit(n)可实现分页
map(): 将其映射成一个新的元素
终端操作
往往对结果集进行处理
forEach: 遍历流中的元素
toArray:将流中的元素倒入一个数组
Min:返回流中元素最小值 Max:返回流中元素最大值
count:返回流中元素的总个数
Reduce:所有元素求和
anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足条件则返回 true,否则返回
falseallMatch:接收一个 Predicate 函数,当流中每个元素都符合条件时才返回 true,否则返回 false
findFirst:返回流中第一个元素
collect:将流中的元素倒入一个集合,Collection 或 Map
四.表达式
4.1 ForEach
集合的遍历
public void testForEach(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.forEach(s-> System.out.println(s));}
4.2 Collect
将操作后的对象转化为新的对象
public void testCollect(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};//转换为新的listList newList = list.stream().map(s -> Integer.valueOf(s)).collect(Collectors.toList());}
4.3 Filter
Filter 为过滤的意思,只要满足 Filter 表达式的数据就可以留下来,不满足的数据被过滤掉
public void testFilter() {List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}}; list.stream()// 过滤掉我们希望留下来的值// 表示我们希望字符串是 1 能留下来// 其他的过滤掉.filter(str -> "1".equals(str)).collect(Collectors.toList());}
4.4 Map
map 方法可以让我们进行一些流的转化,比如原来流中的元素是 A,通过 map 操作,可以使返回的流中的元素是 B
public void testMap() {List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};//通过 map 方法list中元素转化成 小写List<String> strLowerList = list.stream().map(str -> str.toLowerCase()).collect(Collectors.toList());}
4.5 MapToInt
mapToInt 方法的功能和 map 方法一样,只不过 mapToInt 返回的结果已经没有泛型,已经明确是 int 类型的流
public void testMapToInt() {List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().mapToInt(s->Integer.valueOf(s))// 一定要有 mapToObj,因为 mapToInt 返回的是 IntStream,因为已经确定是 int 类型了// 所有没有泛型的,而 Collectors.toList() 强制要求有泛型的流,所以需要使用 mapToObj// 方法返回有泛型的流.mapToObj(s->s).collect(Collectors.toList());list.stream().mapToDouble(s->Double.valueOf(s))// DoubleStream/IntStream 有许多 sum(求和)、min(求最小值)、max(求最大值)、average(求平均值)等方法.sum();}
4.6 Distinct
distinct 方法有去重的功能
public void testDistinct(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};list.stream().map(s -> Integer.valueOf(s)).distinct().collect(Collectors.toList());}
4.7 Sorted
Sorted 方法提供了排序的功能,并且允许我们自定义排序
public void testSorted(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s))// 等同于 .sorted(Comparator.naturalOrder()) 自然排序.sorted().collect(Collectors.toList());// 自定义排序器list.stream().map(s -> Integer.valueOf(s))// 反自然排序.sorted(Comparator.reverseOrder()).collect(Collectors.toList());}
4.8 groupingBy
groupingBy 是能够根据字段进行分组,toMap 是把 List 的数据格式转化成 Map 的格式
public void testGroupBy(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};Map<String, List<String>> strList = list.stream().collect(Collectors.groupingBy(s -> {if("2".equals(s)) {return "2";}else {return "1";}}));}
4.9 FindFirst
findFirst 表示匹配到第一个满足条件的值就返回
public void testFindFirst(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};list.stream().filter(s->"2".equals(s)).findFirst().get();// 防止空指针list.stream().filter(s->"2".equals(s)).findFirst()// orElse 表示如果 findFirst 返回 null 的话,就返回 orElse 里的内容.orElse("3");Optional<String> str= list.stream().filter(s->"2".equals(s)).findFirst();// isPresent 为 true 的话,表示 value != nullif(str.isPresent()){return;}}
4.10 Reduce
reduce 方法允许我们在循环里面叠加计算值
public void testReduce(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s))// s1 和 s2 表示循环中的前后两个数.reduce((s1,s2) -> s1+s2).orElse(0);list.stream().map(s -> Integer.valueOf(s))// 第一个参数表示基数,会从 100 开始加.reduce(100,(s1,s2) -> s1+s2);}
4.11 Peek
peek 方法很简单,我们在 peek 方法里面做任意没有返回值的事情,比如打印日志
public void testPeek(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s)).peek(s -> System.out.println(s)).collect(Collectors.toList());}
4.12 Limit
limit 方法会限制输出值个数,入参是限制的个数大小
public void testLimit(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("3");}};list.stream().map(s -> Integer.valueOf(s)).limit(2L).collect(Collectors.toList());}
4.13 Max,Min
通过max、min方法,可以获取集合中最大、最小的对象
public void testMaxMin(){List<String> list = new ArrayList<String>() {{add("1");add("2");add("2");}};list.stream().max(Comparator.comparing(s -> Integer.valueOf(s))).get();list.stream().min(Comparator.comparing(s -> Integer.valueOf(s))).get();}
4.14 partitioningBy
partitioningBy要求传入一个Predicate,会按照满足条件和不满足条件分成两组,得到的结果是Map<Boolean, List>结构
Map<Boolean, List<Person>> personsByAge = persons.stream().collect(Collectors.partitioningBy(p -> p.getAge() > 18));
System.out.println(JSON.toJSONString(personsByAge));
末尾
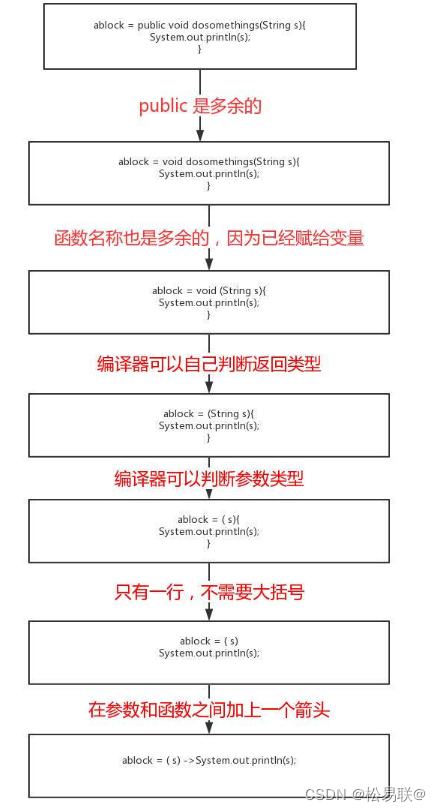
lamda不带类型的原因
相关文章:
lamda表达式
lamda表达式一. lamda表达式的特性二.常用匿名函数式接口2.1 Supplier接口2.2 Consumer接口2.3 Predicate接口2.4 Function接口2.5 BiFunction接口三.stream流传递先后顺序四.表达式4.1 ForEach4.2 Collect4.3 Filter4.4 Map4.5 MapToInt4.6 Distinct4.7 Sorted4.8 groupingBy4…...
MobTech 秒验|极速验证,拉新无忧
一、运营拓展新用户的难题 运营拓展新用户是每个应用都需要面对的问题,但是在实际操作中,往往会遇到一些困难。其中一个主要的难题就是注册和登录的繁琐性。用户在使用一个新的应用时,通常需要填写手机号、获取验证码、输入验证码等步骤&…...
大模型混战,阿里百度华为谁将成就AI时代的“新地基”?
从算力基础到用户生态,群雄逐鹿大模型 自2022年stable diffusion模型的进步推动AIGC的快速发展后,年底,ChatGPT以“破圈者”的姿态,快速“吸粉”亿万,在全球范围内掀起了一股AI浪潮,也促使了众多海外巨头竞…...
干翻Hadoop系列之:Hadoop前瞻之分布式知识
前言 一:海量数据价值 二:海量数据两个棘手问题 1:海量数据如何存储? 掌握分布式存储数据的思想。 A:方案1:单机存储磁盘不够加磁盘 限制问题: 1:一台计算机不能无限制拓充 2&a…...
MAE论文阅读《Masked Autoencoders Are Scalable Vision Learners》
文章目录动机方法写作方面参考Paper: https://arxiv.org/pdf/2111.06377.pdf 动机 首先简要介绍下BERT,NLP领域的BERT是基于Transformer架构,并采取无监督预训练的方式去训练模型。它提出的预训练方法在本质上是一种masked autoencoding,也就…...

代码随想录算法训练营第三十四天-贪心算法3| 1005.K次取反后最大化的数组和 134. 加油站 135. 分发糖果
1005. Maximize Sum Of Array After K Negations 参考视频:贪心算法,这不就是常识?还能叫贪心?LeetCode:1005.K次取反后最大化的数组和_哔哩哔哩_bilibili 贪心🔍 的思路,局部最优ÿ…...
)
比较系统的学习 pandas (2)
pandas 数据读取与输出方法和常用参数 1、读取 CSV文件 pd.read_csv("pathname",step,encoding"gbk",header"infer",name[],skip_blank_linesTrue,commentNone) path : 文件路径 step : 指定分隔符,默认为 逗号 enco…...

怎么查看电脑主板最大支持多少内存?
很多电脑,内存不够用,但应速度慢;还有一些就是买了很大的内存条,但是还是反应慢;这是为什么呢?我今天明白了,原来每个电脑都有自己的适配内存,就是每个电脑能支持多大的内存…...

数据结构——线段树
线段树的结构 线段树是一棵二叉树,其结点是一条“线段”——[a,b],它的左儿子和右儿子分别是这条线段的左半段和右半段,即[a, (ab)/2 ]和[(ab)/2 ,b]。线段树的叶子结点是长度为1的单位线段[a,a1]。下图就是一棵根为[1,10]的线段树࿱…...

【C++进阶】实现C++线程池
文章目录1. thread_pool.h2. main.cpp1. thread_pool.h #pragma once #include <iostream> #include <vector> #include <queue> #include <thread> #include <mutex> #include <condition_variable> #include <future> #include &…...

Redis常用五种数据类型
一、Redis String字符串 1.简介 String类型在redis中最常见的一种类型 string类型是二制安全的,可以存放字符串、数值、json、图像数据 value存储最大数据量是512M 2. 常用命令 set < key>< value>:添加键值对 nx:当数据库中…...
)
C++ Primer第五版_第十一章习题答案(1~10)
文章目录练习11.1练习11.2练习11.3练习11.4练习11.5练习11.6练习11.7练习11.8练习11.9练习11.10练习11.1 描述map 和 vector 的不同。 map 是关联容器, vector 是顺序容器。 练习11.2 分别给出最适合使用 list、vector、deque、map以及set的例子。 list:…...

GEE:使用LandTrendr进行森林变化检测详解
作者:_养乐多_ 本文介绍了一段用于地表变化监测的代码,该代码主要使用谷歌地球引擎(GEE)中的 Landsat 时间序列数据,采用了 Kennedy 等人(2010) 发布的 LandTrendr 算法,对植被指数进行分割,通过计算不同时间段内植被指数的变化来检测植被变化。 目录 一、加入矢量边界 …...
docker项目实施
鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器_闭关苦炼内功的技术博客_51CTO博客鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器,本文是基于之前这篇文章鲲鹏920架构arm64版本centos7安装docker下面开始先来看下系统版本卸载旧版本旧版本…...
springboot实现邮箱验证码功能
引言 邮箱验证码是一个常见的功能,常用于邮箱绑定、修改密码等操作上,这里我演示一下如何使用springboot实现验证码的发送功能; 这里用qq邮箱进行演示,其他都差不多; 准备工作 首先要在设置->账户中开启邮箱POP…...
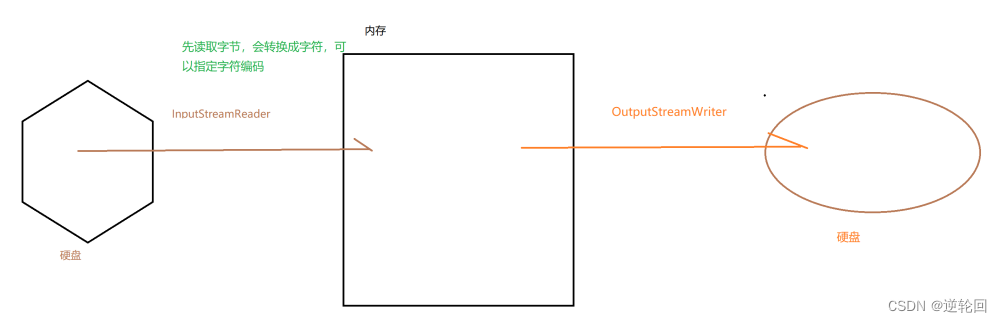
Java 进阶(5) Java IO流
⼀、File类 概念:代表物理盘符中的⼀个⽂件或者⽂件夹。 常见方法: 方法名 描述 createNewFile() 创建⼀个新文件。 mkdir() 创建⼀个新⽬录。 delete() 删除⽂件或空⽬录。 exists() 判断File对象所对象所代表的对象是否存在。 getAbsolute…...
“终于我从字节离职了...“一个年薪40W的测试工程师的自白...
”我递上了我的辞职信,不是因为公司给的不多,也不是因为公司待我不好,但是我觉得,我每天看中我憔悴的面容,每天晚上拖着疲惫的身体躺在床上,我都不知道人生的意义,是赚钱吗?是为了更…...

设计模式之策略模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、策略模式是什么? 策略模式是一种行为型的软件设计模式,针对某个行为,在不同的应用场景下&…...

从工厂普工到Python女程序员,聊聊这一路我是如何逆袭的?
我来聊聊我是如何从一名工厂普工,到国外程序员的过程,这里面充满了坎坷。过去我的工作是在工厂的流水线上,我负责检测电池的正负极。现如今我每天从早上6:20起床,6点四五十分出发到地铁站,7:40到公司。我会给自己准备一…...

全国青少年信息素养大赛2023年python·选做题模拟二卷
目录 打印真题文章进行做题: 全国青少年电子信息智能创新大赛 python选做题模拟二卷 一、单选题 1. numbers = [1, 11, 111, 9], 运行numbers.sort() 后,运行numbers.reverse() numbers会变成?( )...

PCB 设计避坑指南|从基础规范到制造验证,一文吃透所有核心规则
1 设计基础规范1.1 文件命名与管理PCB 命名遵循 “产品型号 功能代码 设计序号 版本” 格式,例如 “AIP25-Lab-V1.0” 。严禁直接覆盖旧版文件,确保设计版本的可追溯性和规范性。1.2 材料与工艺选择1.2.1.基材采用 FR4 环氧玻璃布。 1.2.2 板厚厚度范…...

基于RAG与LLM的智能文献分析工具OpenResearcher:从部署到实战全解析
1. 项目概述:一个为研究者量身打造的AI驱动开源工具箱 如果你是一名科研工作者、学术写手,或者任何需要深度处理文献、进行系统性知识梳理的人,那么你大概率经历过这样的场景:面对海量的PDF文献,手动下载、整理、阅读、…...

AI驱动编辑预设生成:从风格迁移到创意工作流的自动化实践
1. 项目概述:AI驱动的编辑预设库最近在折腾视频和图片后期,发现一个挺有意思的项目,叫kaushalrao/ai-editor-presets。这名字听起来有点技术范儿,但说白了,它就是一个用人工智能技术来生成和优化各类编辑软件预设文件的…...

ChatGPT购物功能支持平台速查表,含响应延迟、支付闭环率、商品图识别准确率等5项硬指标实测数据
更多请点击: https://intelliparadigm.com 第一章:ChatGPT购物功能支持哪些平台 截至2024年,ChatGPT原生并不直接集成电商交易能力,但通过官方插件(Plugins)和第三方API集成,可在特定授权环境…...

Go语言WebSocket服务器tocket:轻量级高性能实时通信方案
1. 项目概述:一个轻量级、高性能的WebSocket服务器 最近在折腾一个需要实时双向通信的物联网项目,传统的HTTP轮询方案在延迟和服务器开销上都不太理想,WebSocket自然就成了首选。在技术选型时,我习惯性地会去GitHub上搜罗一番&…...

开源RPA工具Clawless:本地化低代码自动化实战与核心原理
1. 项目概述:从“无爪”到“有手”,一个开源RPA项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Clawless”,直译过来是“无爪”。初看这个标题,你可能会有点摸不着头脑,这跟自动化…...

《魔兽世界》怀旧服:纳克萨玛斯教官拉苏维奥斯战术详解与实战心得
1. 教官拉苏维奥斯战斗机制解析 教官拉苏维奥斯作为纳克萨玛斯军事区的守门BOSS,其战斗核心在于学员控制循环与仇恨管理的双重考验。这个BOSS战最特别的地方在于,你需要同时应对教官本体的高伤害和四名学员的协同作战。很多团队第一次开荒时容易忽略学员…...

热门的牙齿矫正正畸李杨哪个好
在社交媒体上,关于“牙齿矫正哪家好”、“李杨医生靠谱吗”的讨论热度居高不下。许多粉丝在评论区留言,想知道这位在网络红人榜上经常出现的正畸专家,是否真的值得托付那长达一两年的矫正周期。作为一个长期关注口腔健康领域的观察者…...

移步皆海景处处可停留,读懂大连海岸的松弛质感
沿着大连的滨海路漫步,你会遇见这座城市最从容的一面。这条贯穿海滨风景线的道路,串联起星海广场、森林动物园、老虎滩海洋公园等多个开放型景观区域,核心特点在于它并不急于展示某个单一景点,而是将城市生活与自然海岸融为一体—…...

Arm Neoverse CMN-650架构与缓存一致性协议解析
1. Arm Neoverse CMN-650架构概述在现代多核处理器设计中,缓存一致性互连网络是决定系统扩展性和性能的关键组件。Arm Neoverse CMN-650作为第二代Coherent Mesh Network解决方案,采用了创新的分布式目录协议和优化的传输机制,能够支持多达12…...