DBSCAN聚类算法及Python实现
DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,可以将数据点分成不同的簇,并且能够识别噪声点(不属于任何簇的点)。
DBSCAN聚类算法的基本思想是:在给定的数据集中,根据每个数据点周围其他数据点的密度情况,将数据点分为核心点、边界点和噪声点。核心点是周围某个半径内有足够多其他数据点的数据点,边界点是不满足核心点要求,但在某个核心点的半径内的数据点,噪声点则是不满足任何条件的点。接着,从核心点开始,通过密度相连的数据点不断扩张,形成一个簇。
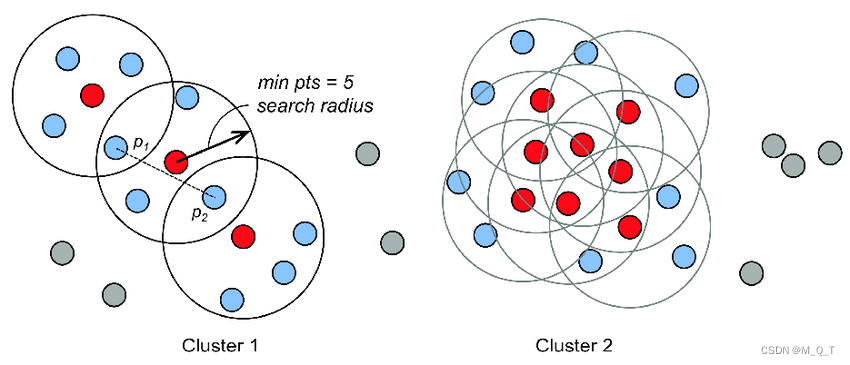
DBSCAN算法的优点是能够处理任意形状的簇,不需要先预先指定簇的个数,能够自动识别噪声点并将其排除在聚类之外。然而,该算法的缺点是对于密度差异较大的数据集,可能无法有效聚类。此外,算法的参数需要根据数据集的特性来合理选择,如半径参数和密度参数。
例子
假设我们有以下的数据点集合:[(1,1), (1,2), (2,1), (8,8), (8,9), (9,8), (15,15)]
我们可以使用DBSCAN算法来将这些点分成不同的簇。首先,我们需要设置两个参数:半径a和最小样本数minPts。这里我们设置 a=2 ,minPts=3。
接下来,我们从数据集中选取一个点,比如第一个点(1,1)作为种子点,并将该点标记为“核心点”,因为它周围有超过 minPts 个点在半径 a 的范围内。然后,我们找到与该点距离在 a 内的所有点,将它们标记为与该点“密度可达”(density-reachable),并将这些点加入同一个簇中。这里包括(1,2)和(2,1)。
接着,我们选取下一个未被分类的点,这里是(8,8),将其标记为“核心点”,并将与它距离在 内的所有点加入同一簇中,这里包括(8,9)和(9,8)。
最后,我们选取最后一个未被分类的点,(15,15),但该点只有1个点在 a 内,不足以满足minPts 的要求,因此该点被标记为噪声点。
于是,最终的聚类结果为:
Cluster 1: [(1,1), (1,2), (2,1)]
Cluster 2: [(8,8), (8,9), (9,8)]
Noise: [(15,15)]可以看出,DBSCAN算法成功地将数据点分成了两个簇,并且将噪声点(15,15)排除在聚类之外。
Python实现
例1
我们还是以上面例子为例,进行Python实现:
from sklearn.cluster import DBSCAN
import numpy as np# 输入数据
X = np.array([(1,1), (1,2), (2,1), (8,8), (8,9), (9,8), (15,15)])# 创建DBSCAN对象,设置半径和最小样本数
dbscan = DBSCAN(eps=2, min_samples=3)# 进行聚类
labels = dbscan.fit_predict(X)# 输出聚类结果
for i in range(max(labels)+1):print(f"Cluster {i+1}: {list(X[labels==i])}")
print(f"Noise: {list(X[labels==-1])}")结果为:
Cluster 1: [array([1, 1]), array([1, 2]), array([2, 1])]
Cluster 2: [array([8, 8]), array([8, 9]), array([9, 8])]
Noise: [array([15, 15])]与手算结果一致。
以上Python实现中,首先我们定义了一个数据集X,它包含了7个二维数据点。然后,我们创建了一个DBSCAN对象,将半径设置为2,最小样本数设置为3。这里我们使用scikit-learn库提供的DBSCAN算法实现。
我们将数据集X输入到DBSCAN对象中,调用fit_predict()方法进行聚类,返回的结果是每个数据点所属的簇标签。标签为-1表示该点为噪声点。
最后,我们遍历所有簇标签,输出每个簇中的数据点。在输出簇标签时,我们将标签从0开始,因此需要加上1。
输出结果显示,数据点被分成了两个簇和一个噪声点,与前面手动计算的结果一致。
算法参数详解
下面对sklearn.cluster模块中的参数进行说明.该函数的调用方法为DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
该算法提供了多个可调参数,以控制算法的聚类效果。下面对常用的参数进行详细说明:
-
eps: 控制着半径的大小,是判断两个数据点是否属于同一簇的距离阈值。默认值为0.5。
-
min_samples: 控制着核心点周围所需的最小数据点数。默认值为5。
-
metric: 用于计算距离的度量方法,可以选择的方法包括欧式距离(euclidean)、曼哈顿距离(manhattan)等。默认值为欧式距离。
-
algorithm: 用于计算距离的算法,可以选择的算法包括Ball Tree(ball_tree)、KD Tree(kd_tree)和brute force(brute)。Ball Tree和KD Tree算法适用于高维数据,brute force算法适用于低维数据。默认值为auto,自动选择算法。
-
leaf_size: 如果使用Ball Tree或KD Tree算法,这个参数指定叶子节点的大小。默认值为30。
-
p: 如果使用曼哈顿距离或闵可夫斯基距离(minkowski),这个参数指定曼哈顿距离的p值。默认值为2,即欧式距离。
-
n_jobs: 指定并行运算的CPU数量。默认值为1,表示单CPU运算。如果为-1,则使用所有可用的CPU。
-
metric_params: 如果使用某些度量方法需要设置额外的参数,可以通过这个参数传递这些参数。默认值为None。
这些参数对于控制DBSCAN算法的聚类效果非常重要,需要根据具体的数据集和需求进行选择和调整。在使用DBSCAN算法时,我们通常需要对这些参数进行多次实验和调整,以达到最佳的聚类效果。
例2:鸢尾花数据集
再以著名的鸢尾花数据集为例进行Python实现
from sklearn.cluster import DBSCAN
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler# 加载数据集
iris = load_iris()
X = iris.data# 数据预处理,标准化数据
scaler = StandardScaler()
X = scaler.fit_transform(X)# 使用DBSCAN聚类算法
dbscan = DBSCAN(eps=0.5, min_samples=5)
y_pred = dbscan.fit_predict(X)# 输出聚类结果
print('聚类结果:', y_pred)上述代码首先使用load_iris()函数加载了iris数据集,然后使用StandardScaler()对数据进行标准化处理。使用DBSCAN类创建了一个DBSCAN对象,并传递了eps和min_samples参数的值。最后,使用fit_predict()方法对数据进行聚类,并将聚类结果存储在y_pred变量中,最后打印聚类结果。
结果如下:
聚类结果: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -1 -1 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 -1 -1 0 0 0 0 0 0 0 -1 0 0 0 0 0 00 0 1 1 1 1 1 1 -1 -1 1 -1 -1 1 -1 1 1 1 1 1 -1 1 1 1-1 1 1 1 1 1 1 1 1 1 1 1 1 -1 1 -1 1 1 1 1 1 -1 1 11 1 -1 1 -1 1 1 1 1 -1 -1 -1 -1 -1 1 1 1 1 -1 1 1 -1 -1 -11 1 -1 1 1 -1 1 1 1 -1 -1 -1 1 1 1 -1 -1 1 1 1 1 1 1 11 1 1 1 -1 1]
不过这次结果中将很多点设置为了噪声点(当然我们可以将噪声点归为一类),如果觉得现在的结果不满意,可以进一步调整算法中的参数。
参考资料:
【1】https://mp.weixin.qq.com/s/z6AgcvUP3-FwtwCyyQHgPg
【2】sklearn.cluster.DBSCAN — scikit-learn 1.2.2 documentation
相关文章:
DBSCAN聚类算法及Python实现
DBSCAN聚类算法 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,可以将数据点分成不同的簇,并且能够识别噪声点(不属于任何簇的点)。 DBSCAN聚类算法的基…...
风光及负荷多场景随机生成与缩减
目录 1 主要内容 计算模型 场景生成与聚类方法应用 2 部分程序 3 程序结果 4 程序链接 1 主要内容 该程序方法复现了《融合多场景分析的交直流混合微电网多时间尺度随机优化调度策略》3.1节基于多场景技术的随机性建模部分,该部分是随机优化调度的重要组成部分…...
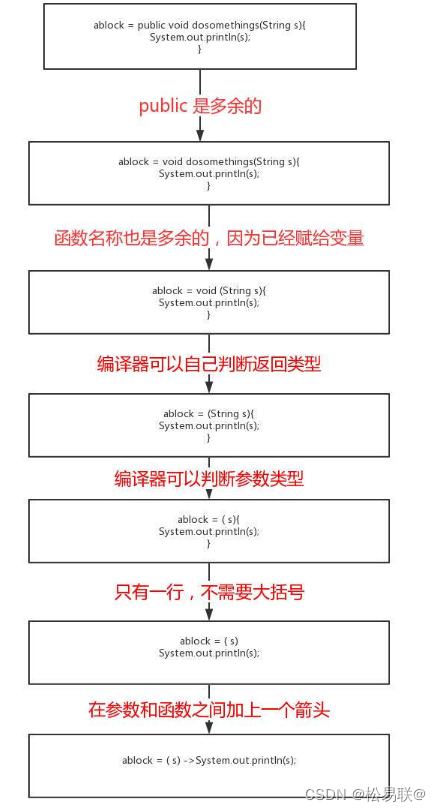
lamda表达式
lamda表达式一. lamda表达式的特性二.常用匿名函数式接口2.1 Supplier接口2.2 Consumer接口2.3 Predicate接口2.4 Function接口2.5 BiFunction接口三.stream流传递先后顺序四.表达式4.1 ForEach4.2 Collect4.3 Filter4.4 Map4.5 MapToInt4.6 Distinct4.7 Sorted4.8 groupingBy4…...
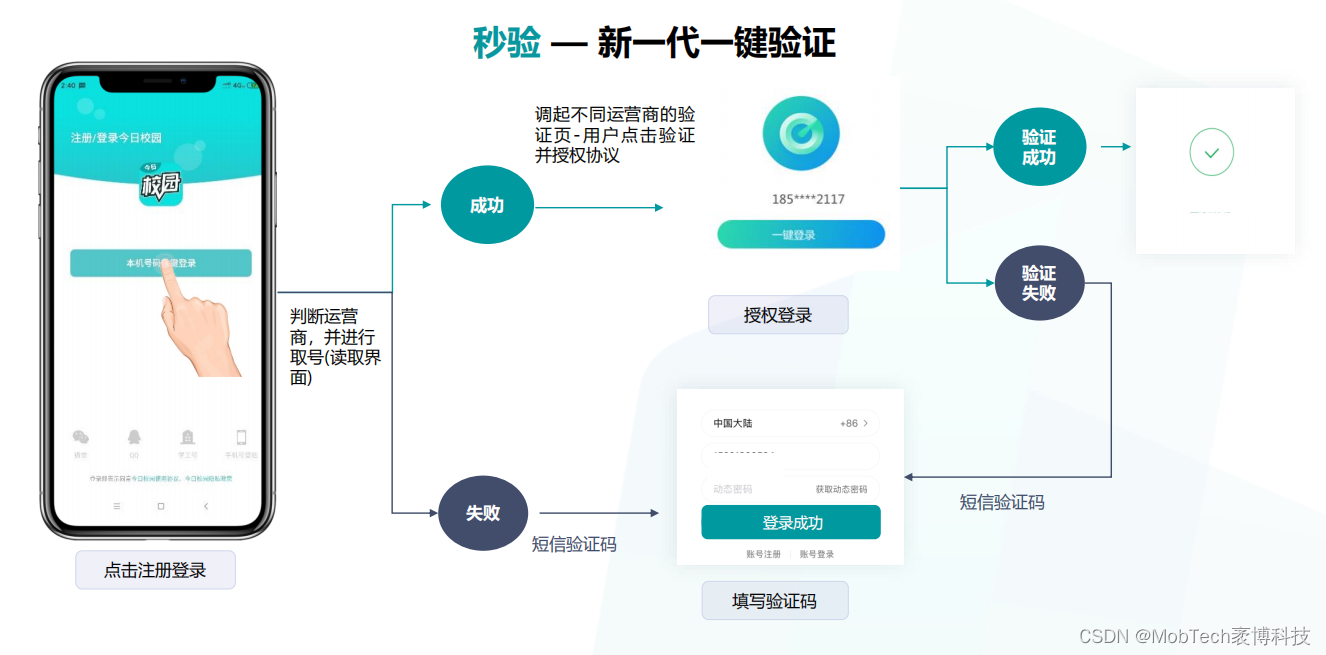
MobTech 秒验|极速验证,拉新无忧
一、运营拓展新用户的难题 运营拓展新用户是每个应用都需要面对的问题,但是在实际操作中,往往会遇到一些困难。其中一个主要的难题就是注册和登录的繁琐性。用户在使用一个新的应用时,通常需要填写手机号、获取验证码、输入验证码等步骤&…...
大模型混战,阿里百度华为谁将成就AI时代的“新地基”?
从算力基础到用户生态,群雄逐鹿大模型 自2022年stable diffusion模型的进步推动AIGC的快速发展后,年底,ChatGPT以“破圈者”的姿态,快速“吸粉”亿万,在全球范围内掀起了一股AI浪潮,也促使了众多海外巨头竞…...
干翻Hadoop系列之:Hadoop前瞻之分布式知识
前言 一:海量数据价值 二:海量数据两个棘手问题 1:海量数据如何存储? 掌握分布式存储数据的思想。 A:方案1:单机存储磁盘不够加磁盘 限制问题: 1:一台计算机不能无限制拓充 2&a…...
MAE论文阅读《Masked Autoencoders Are Scalable Vision Learners》
文章目录动机方法写作方面参考Paper: https://arxiv.org/pdf/2111.06377.pdf 动机 首先简要介绍下BERT,NLP领域的BERT是基于Transformer架构,并采取无监督预训练的方式去训练模型。它提出的预训练方法在本质上是一种masked autoencoding,也就…...

代码随想录算法训练营第三十四天-贪心算法3| 1005.K次取反后最大化的数组和 134. 加油站 135. 分发糖果
1005. Maximize Sum Of Array After K Negations 参考视频:贪心算法,这不就是常识?还能叫贪心?LeetCode:1005.K次取反后最大化的数组和_哔哩哔哩_bilibili 贪心🔍 的思路,局部最优ÿ…...
)
比较系统的学习 pandas (2)
pandas 数据读取与输出方法和常用参数 1、读取 CSV文件 pd.read_csv("pathname",step,encoding"gbk",header"infer",name[],skip_blank_linesTrue,commentNone) path : 文件路径 step : 指定分隔符,默认为 逗号 enco…...

怎么查看电脑主板最大支持多少内存?
很多电脑,内存不够用,但应速度慢;还有一些就是买了很大的内存条,但是还是反应慢;这是为什么呢?我今天明白了,原来每个电脑都有自己的适配内存,就是每个电脑能支持多大的内存…...

数据结构——线段树
线段树的结构 线段树是一棵二叉树,其结点是一条“线段”——[a,b],它的左儿子和右儿子分别是这条线段的左半段和右半段,即[a, (ab)/2 ]和[(ab)/2 ,b]。线段树的叶子结点是长度为1的单位线段[a,a1]。下图就是一棵根为[1,10]的线段树࿱…...

【C++进阶】实现C++线程池
文章目录1. thread_pool.h2. main.cpp1. thread_pool.h #pragma once #include <iostream> #include <vector> #include <queue> #include <thread> #include <mutex> #include <condition_variable> #include <future> #include &…...

Redis常用五种数据类型
一、Redis String字符串 1.简介 String类型在redis中最常见的一种类型 string类型是二制安全的,可以存放字符串、数值、json、图像数据 value存储最大数据量是512M 2. 常用命令 set < key>< value>:添加键值对 nx:当数据库中…...
)
C++ Primer第五版_第十一章习题答案(1~10)
文章目录练习11.1练习11.2练习11.3练习11.4练习11.5练习11.6练习11.7练习11.8练习11.9练习11.10练习11.1 描述map 和 vector 的不同。 map 是关联容器, vector 是顺序容器。 练习11.2 分别给出最适合使用 list、vector、deque、map以及set的例子。 list:…...

GEE:使用LandTrendr进行森林变化检测详解
作者:_养乐多_ 本文介绍了一段用于地表变化监测的代码,该代码主要使用谷歌地球引擎(GEE)中的 Landsat 时间序列数据,采用了 Kennedy 等人(2010) 发布的 LandTrendr 算法,对植被指数进行分割,通过计算不同时间段内植被指数的变化来检测植被变化。 目录 一、加入矢量边界 …...
docker项目实施
鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器_闭关苦炼内功的技术博客_51CTO博客鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器,本文是基于之前这篇文章鲲鹏920架构arm64版本centos7安装docker下面开始先来看下系统版本卸载旧版本旧版本…...
springboot实现邮箱验证码功能
引言 邮箱验证码是一个常见的功能,常用于邮箱绑定、修改密码等操作上,这里我演示一下如何使用springboot实现验证码的发送功能; 这里用qq邮箱进行演示,其他都差不多; 准备工作 首先要在设置->账户中开启邮箱POP…...
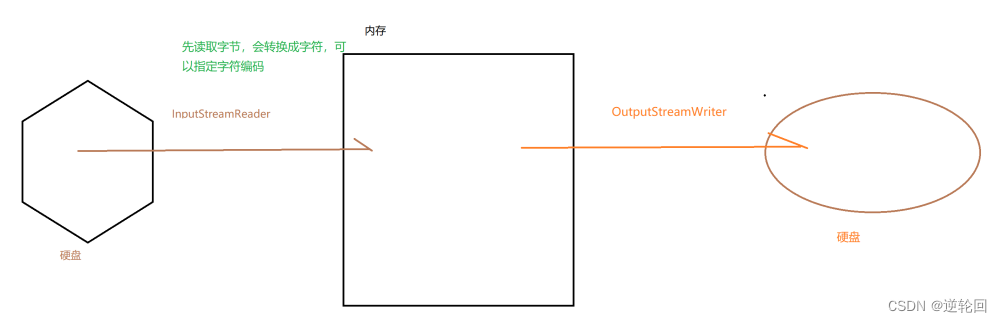
Java 进阶(5) Java IO流
⼀、File类 概念:代表物理盘符中的⼀个⽂件或者⽂件夹。 常见方法: 方法名 描述 createNewFile() 创建⼀个新文件。 mkdir() 创建⼀个新⽬录。 delete() 删除⽂件或空⽬录。 exists() 判断File对象所对象所代表的对象是否存在。 getAbsolute…...
“终于我从字节离职了...“一个年薪40W的测试工程师的自白...
”我递上了我的辞职信,不是因为公司给的不多,也不是因为公司待我不好,但是我觉得,我每天看中我憔悴的面容,每天晚上拖着疲惫的身体躺在床上,我都不知道人生的意义,是赚钱吗?是为了更…...

设计模式之策略模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、策略模式是什么? 策略模式是一种行为型的软件设计模式,针对某个行为,在不同的应用场景下&…...

WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题
WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经在关键时刻被…...

AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控
AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...

Arm Neoverse CMN-650时钟与电源管理架构解析
1. Arm Neoverse CMN-650时钟与电源管理架构解析在现代SoC设计中,时钟与电源管理子系统如同城市的水电供应网络,其设计优劣直接决定了系统性能与能耗效率的平衡。Arm Neoverse CMN-650作为新一代互连架构,通过创新的时钟域划分和电源域管理机…...

GPT-Image-2 老是生成失败?完整排查和修复指南,5 个真根因逐个击破
GPT-Image-2 老是生成失败?完整排查和修复指南,5 个真根因逐个击破GPT-Image-2 的处理时间比文字模型长很多——高质量 1024px 需要 145-280 秒。大多数所谓的"生成失败"其实不是模型问题,而是网络链路(CDN、反代、SDK&…...
开源清理工具OpenClearn:透明可控的数字垃圾管理方案
1. 项目概述:一个开源的“清洁工”如何重塑你的数字生活如果你和我一样,是个在数字世界里摸爬滚打了十几年的老鸟,那你电脑里肯定也有一堆“数字垃圾”。这些垃圾不是指那些过时的文件,而是那些你明明已经删除了,但操作…...

历史学博士生紧急避坑指南:NotebookLM误用导致的3类史料误读及权威校验方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM在历史学研究中的定位与风险图谱 NotebookLM 是 Google 推出的基于用户上传文档构建语义理解模型的实验性工具,其核心能力在于对私有史料(如扫描PDF、OCR文本、手稿转…...
)
认识Python网络套接字编程之流式套接字(一)
流式套接字当你需要使用 TCP 协议进行通信时,需要创建流式套接字。这是套接字编程中最常用的一种。光谈这些概念显得很抽象,还是举送外卖的这个例子,假设你点了一份烤鸭,外卖骑手需要先去店铺取餐,然后送到你的家门口&…...

从棋盘格到精准感知:ROS camera_calibration实战单目与双目相机标定
1. 为什么相机标定是机器人视觉的"体检报告"? 想象一下你新配了一副眼镜,但镜片度数不准——看东西要么变形要么模糊。相机标定就是给机器人的"眼睛"做验光,确保它看到的图像能真实反映物理世界。我在做视觉SLAM项目时&a…...

GSE魔兽世界宏编辑器:高级序列化技术与智能战斗自动化解决方案
GSE魔兽世界宏编辑器:高级序列化技术与智能战斗自动化解决方案 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macr…...

Ruoyi微服务全家桶:从零到一的部署启动实战指南
1. 环境准备:搭建基础服务 第一次接触Ruoyi微服务全家桶时,我花了整整两天时间才把环境跑通。现在回想起来,如果当时有人告诉我这些关键步骤,至少能节省80%的时间。我们先从最基础的环境搭建开始,这是整个项目能够正常…...