pytorch进阶学习(四):使用不同分类模型进行数据训练(alexnet、resnet、vgg等)
课程资源:5、帮各位写好了十多个分类模型,直接运行即可【小学生都会的Pytorch】_哔哩哔哩_bilibili
目录
一、项目介绍
1. 数据集准备
2. 运行CreateDataset.py
3. 运行TrainModal.py
4. 如何切换显卡型号
二、代码
1. CreateDataset.py
2.TrainModal.py
3. 运行结果
一、项目介绍
1. 数据集准备
数据集在data文件夹下

2. 运行CreateDataset.py
运行CreateDataset.py来生成train.txt和test.txt的数据集文件。
3. 运行TrainModal.py
进行模型的训练,从torchvision中的models模块import了alexnet, vgg, resnet的多个网络模型,使用时直接取消注释掉响应的代码即可,比如我现在训练的是vgg11的网络。
# 不使用预训练参数# model = alexnet(pretrained=False, num_classes=5).to(device) # 29.3%''' VGG系列 '''model = vgg11(weights=False, num_classes=5).to(device) # 23.1%# model = vgg13(weights=False, num_classes=5).to(device) # 30.0%# model = vgg16(weights=False, num_classes=5).to(device)''' ResNet系列 '''# model = resnet18(weights=False, num_classes=5).to(device) # 43.6%# model = resnet34(weights=False, num_classes=5).to(device)# model = resnet50(weights= False, num_classes=5).to(device)#model = resnet101(weights=False, num_classes=5).to(device) # 26.2%# model = resnet152(weights=False, num_classes=5).to(device)同时需要注意的是, vgg11中的weights参数设置为false,我们进入到vgg的定义页发现weights即为是否使用预训练参数,设置为FALSE说明我们不使用预训练参数,因为vgg网络的预训练类别数为1000,而我们自己的数据集没有那么多类,因此不使用预训练。

把最后一行中产生的pth的文件名称改成对应网络的名称,如model_vgg11.pth。
# 保存训练好的模型torch.save(model.state_dict(), "model_vgg11.pth")print("Saved PyTorch Model Success!")4. 如何切换显卡型号
我在运行过程中遇到了“torch.cuda.OutOfMemoryError”的问题,显卡的显存不够,在服务器中使用查看显卡占用情况命令:
nvidia -smi
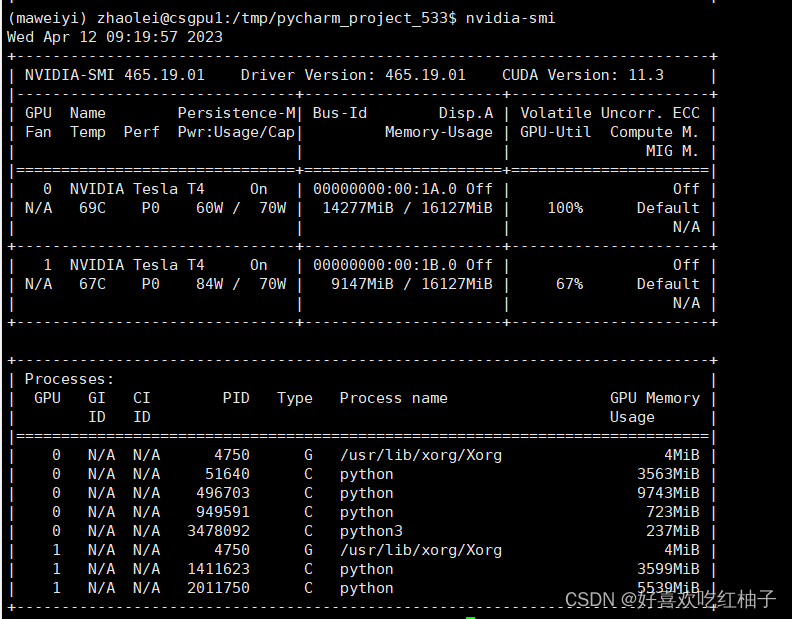
可以看到我一直用的是默认显卡0,使用情况已经到了100%,但是显卡1使用了67%,还用显存使用空间,所以使用以下代码来把显卡0换成显卡1.
# 设置显卡型号为1
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
二、代码
1. CreateDataset.py
'''
生成训练集和测试集,保存在txt文件中
'''
##相当于模型的输入。后面做数据加载器dataload的时候从里面读他的数据
import os
import random#打乱数据用的# 百分之60用来当训练集
train_ratio = 0.6# 用来当测试集
test_ratio = 1-train_ratiorootdata = r"data" #数据的根目录train_list, test_list = [],[]#读取里面每一类的类别
data_list = []#生产train.txt和test.txt
class_flag = -1
for a,b,c in os.walk(rootdata):print(a)for i in range(len(c)):data_list.append(os.path.join(a,c[i]))for i in range(0,int(len(c)*train_ratio)):train_data = os.path.join(a, c[i])+'\t'+str(class_flag)+'\n'train_list.append(train_data)for i in range(int(len(c) * train_ratio),len(c)):test_data = os.path.join(a, c[i]) + '\t' + str(class_flag)+'\n'test_list.append(test_data)class_flag += 1print(train_list)
random.shuffle(train_list)#打乱次序
random.shuffle(test_list)with open('train.txt','w',encoding='UTF-8') as f:for train_img in train_list:f.write(str(train_img))with open('test.txt','w',encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)2.TrainModal.py
'''加载pytorch自带的模型,从头训练自己的数据
'''
import time
import torch
from torch import nn
from torch.utils.data import DataLoader
from utils import LoadDataimport os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'from torchvision.models import alexnet #最简单的模型
from torchvision.models import vgg11, vgg13, vgg16, vgg19 # VGG系列
from torchvision.models import resnet18, resnet34,resnet50, resnet101, resnet152 # ResNet系列
from torchvision.models import inception_v3 # Inception 系列# 定义训练函数,需要
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。for batch, (X, y) in enumerate(dataloader):# 将数据存到显卡X, y = X.cuda(), y.cuda()# 得到预测的结果predpred = model(X)# 计算预测的误差# print(pred,y)loss = loss_fn(pred, y)# 反向传播,更新模型参数optimizer.zero_grad()loss.backward()optimizer.step()# 每训练10次,输出一次当前信息if batch % 10 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test(dataloader, model):size = len(dataloader.dataset)# 将模型转为验证模式model.eval()# 初始化test_loss 和 correct, 用来统计每次的误差test_loss, correct = 0, 0# 测试时模型参数不用更新,所以no_gard()# 非训练, 推理期用到with torch.no_grad():# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)for X, y in dataloader:# 将数据转到GPUX, y = X.cuda(), y.cuda()# 将图片传入到模型当中就,得到预测的值predpred = model(X)# 计算预测值pred和真实值y的差距test_loss += loss_fn(pred, y).item()# 统计预测正确的个数correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= sizecorrect /= sizeprint(f"correct = {correct}, Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")if __name__=='__main__':batch_size = 8# # 给训练集和测试集分别创建一个数据集加载器train_data = LoadData("train.txt", True)valid_data = LoadData("test.txt", False)train_dataloader = DataLoader(dataset=train_data, num_workers=4, pin_memory=True, batch_size=batch_size, shuffle=True)test_dataloader = DataLoader(dataset=valid_data, num_workers=4, pin_memory=True, batch_size=batch_size)# 如果显卡可用,则用显卡进行训练device = "cuda" if torch.cuda.is_available() else "cpu"print(f"Using {device} device")'''随着模型的加深,需要训练的模型参数量增加,相同的训练次数下模型训练准确率起来得更慢'''# 不使用预训练参数# model = alexnet(pretrained=False, num_classes=5).to(device) # 29.3%''' VGG系列 '''model = vgg11(weights=False, num_classes=5).to(device) # 23.1%# model = vgg13(weights=False, num_classes=5).to(device) # 30.0%# model = vgg16(weights=False, num_classes=5).to(device)''' ResNet系列 '''# model = resnet18(weights=False, num_classes=5).to(device) # 43.6%# model = resnet34(weights=False, num_classes=5).to(device)# model = resnet50(weights= False, num_classes=5).to(device)#model = resnet101(weights=False, num_classes=5).to(device) # 26.2%# model = resnet152(weights=False, num_classes=5).to(device)print(model)# 定义损失函数,计算相差多少,交叉熵,loss_fn = nn.CrossEntropyLoss()# 定义优化器,用来训练时候优化模型参数,随机梯度下降法optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # 初始学习率# 一共训练1次epochs = 1for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")time_start = time.time()train(train_dataloader, model, loss_fn, optimizer)time_end = time.time()print(f"train time: {(time_end-time_start)}")test(test_dataloader, model)print("Done!")# 保存训练好的模型torch.save(model.state_dict(), "model_vgg11.pth")print("Saved PyTorch Model Success!")3. 运行结果
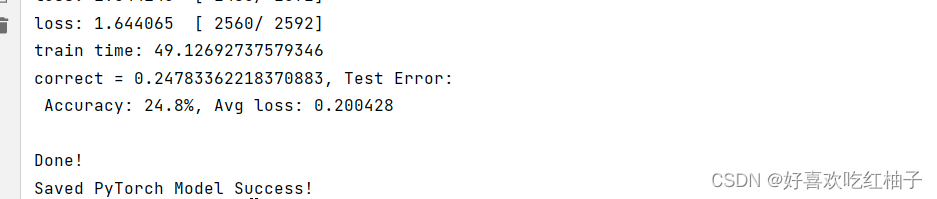
vgg11的运行结果:,可以看到最后的准确率是24.8%,因为没有用预训练模型,所以准确率很低。
相关文章:
pytorch进阶学习(四):使用不同分类模型进行数据训练(alexnet、resnet、vgg等)
课程资源:5、帮各位写好了十多个分类模型,直接运行即可【小学生都会的Pytorch】_哔哩哔哩_bilibili 目录 一、项目介绍 1. 数据集准备 2. 运行CreateDataset.py 3. 运行TrainModal.py 4. 如何切换显卡型号 二、代码 1. CreateDataset.py 2.Train…...

Java面向对象高级【注解和反射】
目录 注解 什么是注解? 自定义注解 元注解 反射 什么是反射 静态语言和动态语言 动态语言 静态语言 对比 Class类 Java内存分析 类加载过程 类加载器 获取运行时类的完整结构 通过Class对象实例化对象 1.调用Class对象的newInstance 2.Constructor…...
 和 torch.repeat())
Pytorch基础 - 4. torch.expand() 和 torch.repeat()
目录 1. torch.expand(*sizes) 2. torch.repeat(*sizes) 3. 两者内存占用的区别 在PyTorch中有两个函数可以用来扩展某一维度的张量,即 torch.expand() 和 torch.repeat() 1. torch.expand(*sizes) 【含义】将输入张量在大小为1的维度上进行拓展,…...
《LeetCode》——LeetCode刷题日记
本期,将给大家带来的是关于 LeetCode 的关于二叉树的题目讲解。 目录 (一)606. 根据二叉树创建字符串 💥题意分析 💥解题思路 (二)102. 二叉树的层序遍历 💥题意分析 &#…...
)
mysql数据库审计(1)
1.数据库审计工具介绍及选择 1.1. 数据库审计工具介绍 MySQL 分支的审计功能包含在企业版中,社区版可以使用其他分支提供的工具。目前已知的审计工具,社区版本有 Percona 的 Percona Server Audit Log 、MariaDB 的 MariaDB Audit Plugin 和 McAfee 的…...
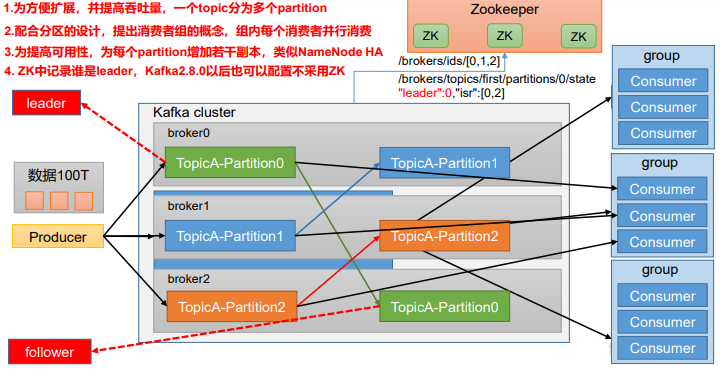
Kafka---kafka概述和kafka基础架构
kafka概述和kafka基础架构 文章目录kafka概述和kafka基础架构Kafka定义消息队列传统消息队列应用场景缓存/消峰解耦异步通信消息队列的两种模式点对点模式发布/订阅模式kafka基础架构producerConsumerConsumer Group(CG)BrokerTopicPartitionReplicaLead…...

《JavaEE初阶》多线程基础
《JavaEE初阶》多线程基础 文章目录《JavaEE初阶》多线程基础前言:多线程的概念简单创建线程并运行:简述Thread中run方法与start方法的区别创建线程的几种方法:探讨串行执行与并行执行的执行时间多线程的使用场景:Thread类简单介绍:构造方法:获取线程的常见属性:线程的常用方法…...

技术分享 | OMS 初识
作者:高鹏 DBA,负责项目日常问题排查,广告位长期出租 。 本文来源:原创投稿 *爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 本文主要贡献者:进行OMS源码分析的…...
【Elastic (ELK) Stack 实战教程】10、ELK 架构升级-引入消息队列 Redis、Kafka
目录 一、ELK 架构面临的问题 1.1 耦合度过高 1.2 性能瓶颈 二、ELK 对接 Redis 实践 2.1 配置 Redis 2.1.1 安装 Redis 2.1.2 配置 Redis 2.1.3 启动 Redis 2.2 配置 Filebeat 2.3 配置 Logstash 2.4 数据消费 2.5 配置 kibana 三、消息队列基本概述 3.1 什么是…...

优先、双端队列-我的基础算法刷题之路(八)
本篇博客旨在整理记录自已对优先队列、双端队列的一些总结,以及刷题的解题思路,同时希望可给小伙伴一些帮助。本人也是算法小白,水平有限,如果文章中有什么错误之处,希望小伙伴们可以在评论区指出来,共勉 &…...
 方法、Python 质数判断)
Python3 os.symlink() 方法、Python 质数判断
Python3 os.symlink() 方法 概述 os.symlink() 方法用于创建一个软链接。 语法 symlink()方法语法格式如下: os.symlink(src, dst)参数 src -- 源地址。 dst -- 目标地址。 返回值 该方法没有返回值。 实例 以下实例演示了 symlink() 方法的使用࿱…...

P1972 [SDOI2009] HH的项链
[SDOI2009] HH的项链 题目描述 HH 有一串由各种漂亮的贝壳组成的项链。HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义。HH 不断地收集新的贝壳,因此,他的项链变得越来…...
力扣解法汇总1026. 节点与其祖先之间的最大差值
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣 描述: 给定二叉树的根节点 root,找出存在于 不同 节点 A 和 B 之间的最大值…...
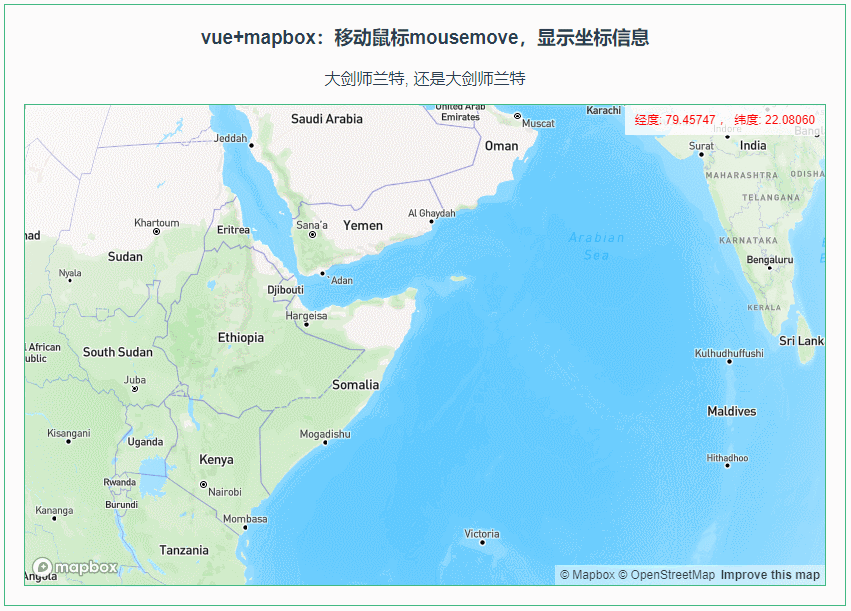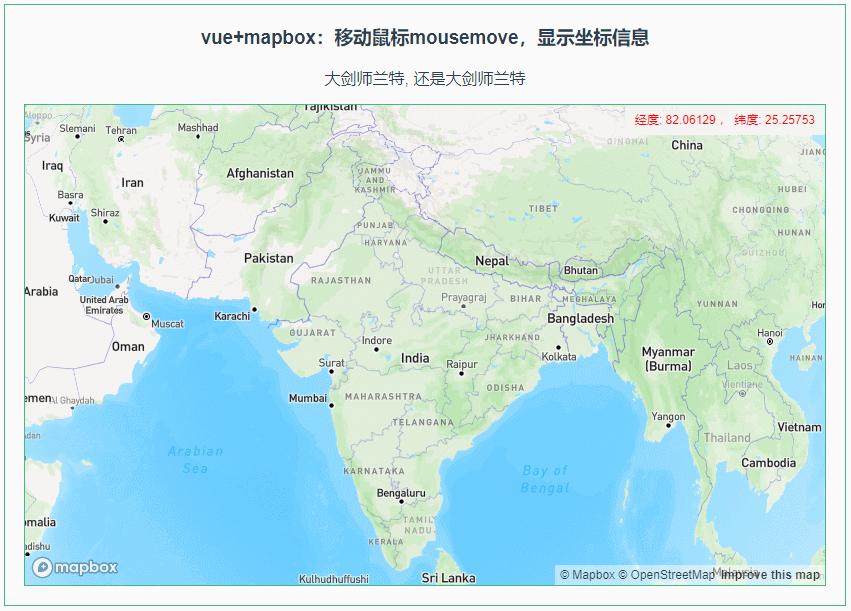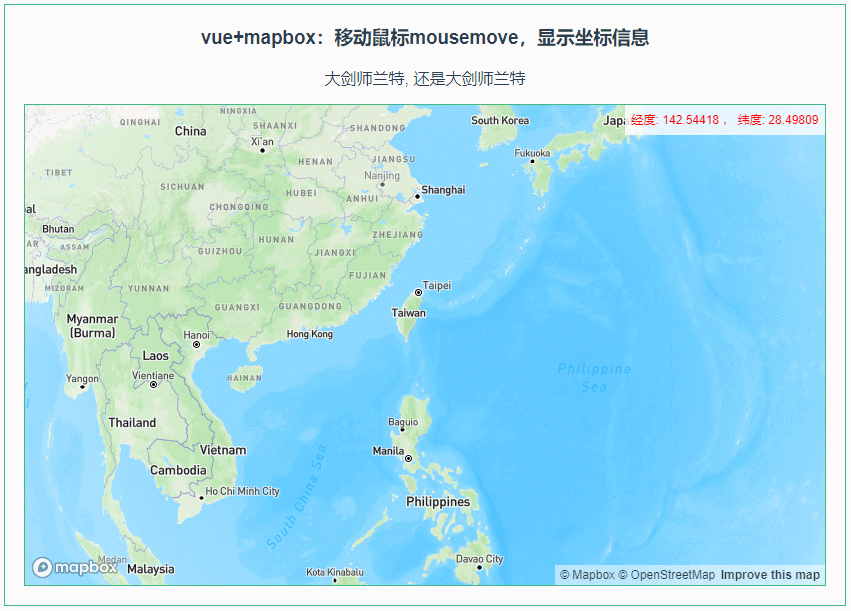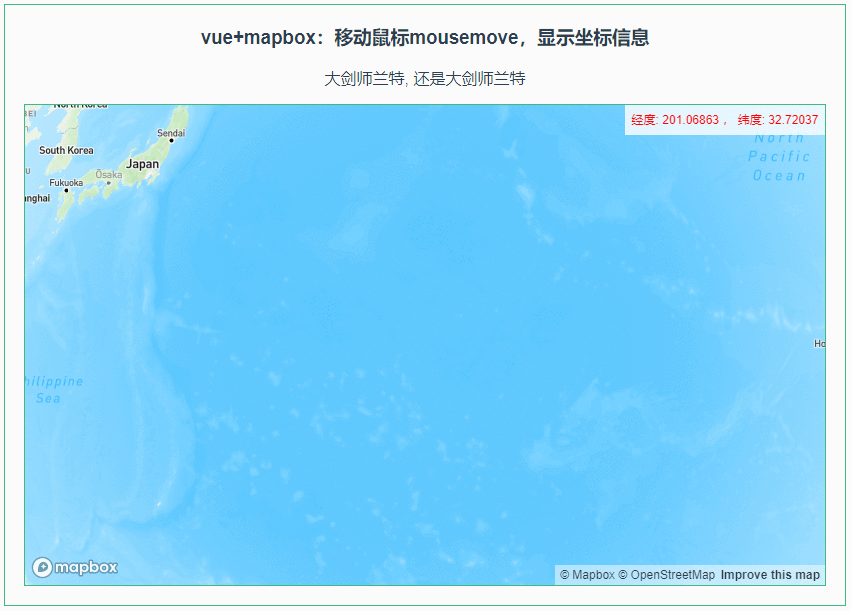
010:Mapbox GL移动鼠标mousemove,显示坐标信息
第010个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+mapbox中移动鼠标mousemove,显示坐标信息。 直接复制下面的 vue+mapbox源代码,操作2分钟即可运行实现效果 文章目录 示例效果配置方式示例源代码(共81行)相关API参考:专栏目标示例效果 配置方式 1)查看基础…...

【两阶段鲁棒优化】利用列-约束生成方法求解两阶段鲁棒优化问题(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

百度暑期实习 C++ 一面
1.数组 链表 数组是一种线性数据结构,其中相同类型的元素连续存储在一段内存中,并且可以通过索引来访问每个元素。数组的优点是随机访问元素非常快速,但缺点是插入或删除元素可能需要移动其他元素。 链表也是一种线性数据结构,但…...

计算机网络第一章(概述)【湖科大教书匠】
1. 各种网络 网络(Network)由若干**结点(Node)和连接这些结点的链路(Link)**组成多个网络还可以通过路由器互连起来,这样就构成了一个覆盖范围更大的网络,即互联网(互连网)。因此,互联网是"网络的网络(Network of Networks)"**因特…...

【JS】vis.js使用之vis-timeline使用攻略,vis-timeline在vue3中实现时间轴、甘特图
vis.js使用之vis-timeline使用攻略,vis-timeline实现时间轴、甘特图1、vis-timeline简介2、安装插件及依赖3、简单示例4、疑难问题集合1. 中文zh-cn本地化2. 关于自定义class样式无法被渲染3. 关于双向数据绑定vis.js是一个基于浏览器的可视化库,它提供了…...

机器学习——数据处理
机器学习简介 机器学习是人工智能的一个实现途径深度学习是机器学习的一个方法发展而来 机器学习:从数据中自动分析获得模型,并利用模型对未知数据进行预测。 数据集的格式: 特征值目标值 比如上图中房子的各种属性是特征值,然…...
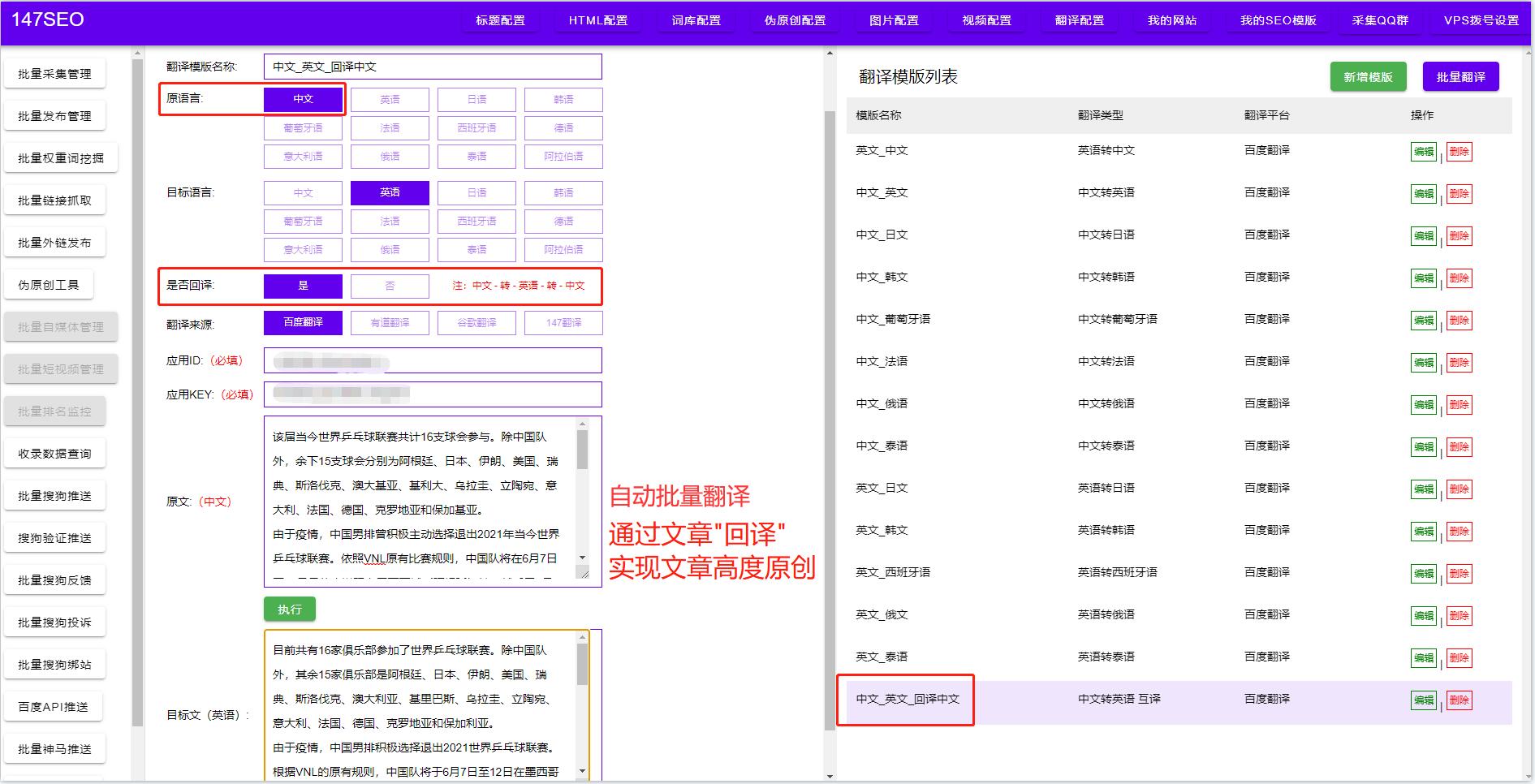
多种文字翻译软件-翻译常用软件
整篇文档翻译软件 整篇文档翻译软件是一种实现全文翻译的自动翻译工具,它能够快速、准确地将整篇文档的内容翻译成目标语言。与单词、句子翻译不同,整篇文档翻译软件不仅需要具备准确的语言识别和翻译技术,还需要考虑上下文语境和文档格式等多…...

5分钟掌握碧蓝航线自动化脚本:解放双手的智能游戏助手终极指南
5分钟掌握碧蓝航线自动化脚本:解放双手的智能游戏助手终极指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你…...

XLink 和 XPointer 语法详解
XLink 和 XPointer 语法详解 概述 XLink(XML Linking Language)和 XPointer(XML Pointer Language)是XML文档中处理链接和定位信息的语言。本文将详细解释XLink和XPointer的语法及其应用。 XLink 语法 XLink定义了一种标准的方法,允许在XML文档内部和之间建立链接。以…...

会议纪要整理不清?如何将会议成果转化为可落地任务
身边不少HR朋友都有过纪要整理的困扰,一场会议或面谈后,花费大量时间整理,最终产出的纪要却零散杂乱,无法提炼可落地的任务,导致会议效果大打折扣。结合半年多的实测体验,整理出一套零基础也能上手的高效方…...

化工行业节能改造数据监测系统方案
针对工厂存在能源利用不足、设备利用率偏低、人工抄表粗放等痛点,某化工企业通过落实多项节能数字化改造措施,实现变废为宝、节能增效等多种能源效益。主要举措包括:通过回收高温蒸汽驱动闲置汽轮机实现发电、通过回收富余蒸汽为生产提供热源…...
原理与实现解析)
量子卷积神经网络(QCNN)原理与实现解析
1. 量子卷积神经网络(QCNN)概述量子卷积神经网络(QCNN)是近年来量子计算与深度学习交叉领域最具突破性的研究方向之一。作为经典CNN的量子版本,QCNN通过在量子线路中实现卷积、池化等操作,充分利用量子态的叠加性和纠缠特性,在希尔伯特空间中…...

芯片HAST测试:通电工作下如何精准模拟极端环境挑战?
为了确保产品在高温、高湿等恶劣条件下仍能正常工作,HAST(Highly Accelerated Stress Test)测试成为不可或缺的一部分。本文将深入解析HAST测试,并探讨如何在通电工作状态下进行精准模拟,以应对极端环境挑战。什么是HA…...

告别驱动烦恼:用TI官方CCS开发MSP430,为什么比第三方IAR更省心?
嵌入式开发者的效率革命:为什么TI官方CCS是MSP430开发的最优解? 在嵌入式开发领域,工具链的选择往往决定了项目的启动速度和开发体验。对于MSP430系列微控制器的开发者而言,面对IAR、GCC和TI官方的Code Composer Studio(CCS)等多种…...

Lenovo Legion Toolkit 终极指南:如何让你的拯救者笔记本性能提升30%
Lenovo Legion Toolkit 终极指南:如何让你的拯救者笔记本性能提升30% 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...

WebPlotDigitizer技术架构深度解析:计算机视觉驱动的图表数据提取引擎
WebPlotDigitizer技术架构深度解析:计算机视觉驱动的图表数据提取引擎 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 在科…...

桌面Z箍缩实验:从等离子体原理到聚变中子探测的DIY实践
1. 项目概述:从“人造太阳”到桌面实验的能源狂想“如何通过聚变制造能源及如何实现”,这个标题背后,是无数工程师和科学家为之奋斗终身的终极能源梦想。它听起来宏大得像是国家实验室的专属课题,但今天我想从一个更接地气的、带有…...