YOLOv7如何提高目标检测的速度和精度,基于优化算法提高目标检测速度

目录
- 一、学习率调度
- 二、权重衰减和正则化
- 三、梯度累积和分布式训练
- 1、梯度累积
- 2、分布式训练
- 四、自适应梯度裁剪
大家好,我是哪吒。
上一篇介绍了YOLOv7如何提高目标检测的速度和精度,基于模型结构提高目标检测速度,本篇介绍一下基于优化算法提高目标检测速度。
🏆本文收录于,目标检测YOLO改进指南。
本专栏为改进目标检测YOLO改进指南系列,🚀均为全网独家首发,打造精品专栏,专栏持续更新中…
一、学习率调度
学习率是影响目标检测精度和速度的重要因素之一。合适的学习率调度策略可以加速模型的收敛和提高模型的精度。在YOLOv7算法中,可以使用基于余弦函数的学习率调度策略(Cosine Annealing Learning Rate Schedule)来调整学习率。该策略可以让学习率从初始值逐渐降低到最小值,然后再逐渐增加到初始值。这样可以使模型在训练初期快速收敛,在训练后期保持稳定,并且不容易陷入局部最优解。
以下是使用基于余弦函数的学习率调度策略在PyTorch中实现的示例代码:
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler# 定义优化器和学习率调度器
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=200)# 训练模型
for epoch in range(num_epochs):for i, (inputs, labels) in enumerate(train_loader):# 前向传播和计算损失函数outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化器更新optimizer.zero_grad()loss.backward()optimizer.step()# 更新学习率scheduler.step()# 输出训练信息if i % print_freq == 0:print('Epoch [{}/{}], Iter [{}/{}], Learning Rate: {:.6f}, Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), scheduler.get_last_lr()[0], loss.item()))

在这个示例代码中,我们首先定义了一个基于随机梯度下降(SGD)算法的优化器,然后使用CosineAnnealingLR类定义了一个基于余弦函数的学习率调度器,其中T_max表示一个周期的迭代次数。在每个迭代周期中,我们首先进行前向传播和计算损失函数,然后进行反向传播和优化器更新。最后,我们调用学习率调度器的step方法来更新学习率,并输出训练信息,包括当前学习率和损失函数值。
二、权重衰减和正则化
权重衰减和正则化是减少过拟合和提高模型泛化能力的有效方法。在YOLOv7算法中,可以使用L2正则化来控制模型的复杂度,并且使用权重衰减来惩罚较大的权重值。这样可以避免模型过于复杂和过拟合,并且提高模型的泛化能力。
以下是使用PyTorch实现权重衰减和L2正则化的代码示例:
import torch
import torch.nn as nn
import torch.optim as optimclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.pool = nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = nn.Linear(64 * 16 * 16, 512)self.fc2 = nn.Linear(512, 10)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.conv2(x)x = self.bn2(x)x = self.relu(x)x = self.pool(x)x = x.view(-1, 64 * 16 * 16)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return xmodel = MyModel()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, weight_decay=0.0005)# 训练过程中的每个epoch
for epoch in range(num_epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = dataoptimizer.zero_grad()# 前向传播和反向传播outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 更新损失值running_loss += loss.item()# 输出每个epoch的损失值print('[Epoch %d] loss: %.3f' % (epoch + 1, running_loss / len(trainloader)))

在这个例子中,我们在SGD优化器中设置了weight_decay参数来控制L2正则化的强度。该参数越大,正则化强度越大。同时,我们还定义了损失函数为交叉熵损失函数,用于衡量模型预测结果与实际结果之间的差距。
三、梯度累积和分布式训练
梯度累积和分布式训练是提高目标检测速度和准确率的重要方法之一。梯度累积可以减少显存的占用,从而可以使用更大的批量大小进行训练,加快训练速度,并且提高模型的精度。分布式训练可以加速模型的训练,并且可以使用更多的计算资源进行模型的训练和推断。
以下是使用PyTorch进行梯度累积和分布式训练的示例代码:
1、梯度累积
import torch
import torch.nn as nn
import torch.optim as optimbatch_size = 8
accumulation_steps = 4# define model and loss function
model = nn.Linear(10, 1)
criterion = nn.MSELoss()# define optimizer
optimizer = optim.SGD(model.parameters(), lr=0.01)# define input and target tensors
inputs = torch.randn(batch_size, 10)
targets = torch.randn(batch_size, 1)# forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)# backward pass and gradient accumulation
loss = loss / accumulation_steps
loss.backward()
if (i + 1) % accumulation_steps == 0:optimizer.step()optimizer.zero_grad()

在上述代码中,我们首先定义了批量大小为8,累积梯度的步数为4。接着定义了模型和损失函数,使用随机输入和目标张量进行一次前向传播和反向传播,并在累积梯度步数达到4时执行一次梯度更新和梯度清零操作。
2、分布式训练
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.utils.data.distributed import DistributedSampler# initialize distributed training
dist.init_process_group(backend='nccl', init_method='env://')# define model and loss function
model = nn.Linear(10, 1)
criterion = nn.MSELoss()# define optimizer and wrap model with DistributedDataParallel
optimizer = optim.SGD(model.parameters(), lr=0.01)
model = nn.parallel.DistributedDataParallel(model)# define distributed sampler and data loader
dataset = ...
sampler = DistributedSampler(dataset)
loader = torch.utils.data.DataLoader(dataset, batch_size=8, sampler=sampler)# training loop
for epoch in range(num_epochs):for inputs, targets in loader:# forward passoutputs = model(inputs)loss = criterion(outputs, targets)# backward pass and updateoptimizer.zero_grad()loss.backward()optimizer.step()# synchronize model parametersfor param in model.parameters():dist.all_reduce(param.data, op=dist.ReduceOp.SUM)param.data /= dist.get_world_size()

在上述代码中,我们首先使用dist.init_process_group方法初始化分布式训练环境,设置通信方式为NCCL。接着定义模型、损失函数和优化器,使用nn.parallel.DistributedDataParallel对模型进行分布式包装,将其分布到多个GPU上进行训练。然后定义分布式采样器和数据加载器,在训练循环中对每个批次执行前向传播、反向传播和梯度更新。最后,我们需要在训练结束后同步模型参数,使用dist.all_reduce方法对所有参数进行求和,并除以进程数来计算平均值,从而保证所有进程上的模型参数都是一致的。
四、自适应梯度裁剪
自适应梯度裁剪是一种可以避免梯度爆炸和消失的技术,在目标检测任务中可以提高模型的训练效率和准确率。梯度裁剪的原理是通过对梯度进行缩放来限制其范围,从而避免梯度过大或过小的情况。
在YOLOv7算法中,自适应梯度裁剪的方法是基于梯度的范数进行缩放,将梯度的范数限制在一个预定的范围内。具体地,可以定义一个阈值,当梯度的范数超过该阈值时,将梯度进行缩放,使其范数在该阈值内。通过这种方式,可以避免梯度爆炸和消失的问题,从而提高模型的训练效率和准确率。
以下是使用PyTorch实现自适应梯度裁剪的示例代码:
import torch
from torch.nn.utils import clip_grad_norm_# 定义阈值
threshold = 1.0# 计算梯度并进行自适应梯度裁剪
optimizer.zero_grad()
loss.backward()
grad_norm = clip_grad_norm_(model.parameters(), threshold)
optimizer.step()

在上述代码中,clip_grad_norm_()函数可以计算梯度的范数并进行缩放,使其范数不超过预定的阈值。在模型训练的过程中,可以在每个批次结束时进行自适应梯度裁剪,从而提高模型的训练效率和准确率。

🏆本文收录于,目标检测YOLO改进指南。
本专栏为改进目标检测YOLO改进指南系列,🚀均为全网独家首发,打造精品专栏,专栏持续更新中…
🏆哪吒多年工作总结:Java学习路线总结,搬砖工逆袭Java架构师。
相关文章:
YOLOv7如何提高目标检测的速度和精度,基于优化算法提高目标检测速度
目录 一、学习率调度二、权重衰减和正则化三、梯度累积和分布式训练1、梯度累积2、分布式训练 四、自适应梯度裁剪 大家好,我是哪吒。 上一篇介绍了YOLOv7如何提高目标检测的速度和精度,基于模型结构提高目标检测速度,本篇介绍一下基于优化算…...

CentOS 7中安装配置Nginx的教程指南
1. 安装Nginx 在终端中执行以下命令以安装Nginx: sudo yum install epel-release sudo yum install nginx安装完成后的 Nginx 内容通常会被安装在以下目录下: /etc/nginx: 该目录包含 Nginx 的配置文件,包括 nginx.conf 和 conf.d 目录下的…...

Vicuna- 一个类 ChatGPT开源 模型
Meta 开源 LLaMA(大羊驼)系列模型为起点,研究人员逐渐研发出基于LLaMA的Alpaca(羊驼)、Alpaca-Lora、Luotuo(骆驼)等轻量级类 ChatGPT 模型并开源。 google提出了一个新的模型:Vicuna(小羊驼)。该模型基于LLaMA,参数量13B。Vicuna-13B 通过微调 LLaMA 实现了高性能…...

5.1 数值微分
学习目标: 作为数值分析的基础内容,我建议你可以采取以下步骤来学习数值微分: 掌握微积分基础:数值微分是微积分中的一个分支,需要先掌握微积分基础知识,包括导数、极限、微分等。 学习数值微分的概念和方…...
云计算服务安全评估办法
云计算服务安全评估办法 2019-07-22 14:46 来源: 网信办网站【字体:大 中 小】打印 国家互联网信息办公室 国家发展和改革委员会 工业和信息化部 财政部关于发布《云计算服务安全评估办法》的公告 2019年 第2号 为提高党政机关、关键信息基础设施运营者…...
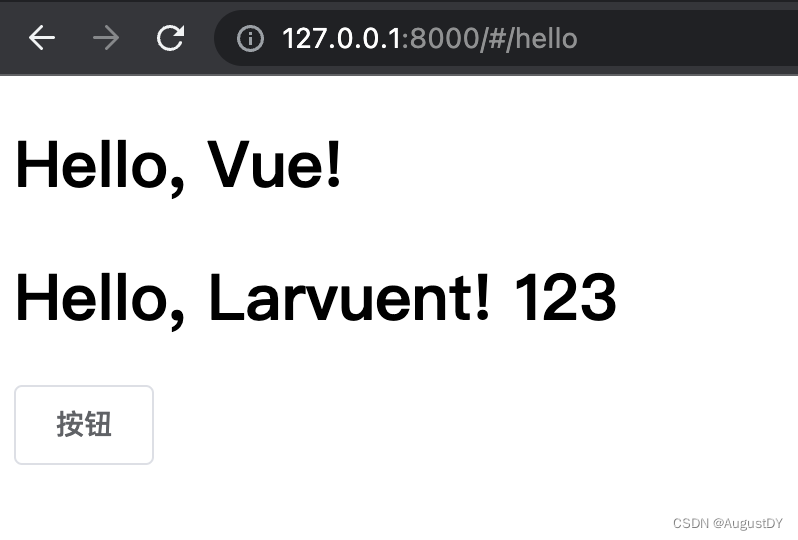
laravel5.6.* + vue2 创建后台
本地已经安装好了composer 1.新建 Laravel5.6.*项目 composer create-project --prefer-dist laravel/laravel laravel5vue2demo 5.6.* 2. cd laravel5vue2demo 3. npm install /routes/web.php 路由文件中, 修改 Route::get(/, function () {return view(index); });新建…...
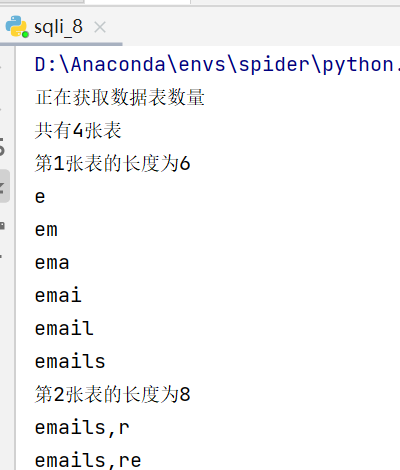
Python自动化sql注入:布尔盲注
在sql注入时,使用python脚本可以大大提高注入效率,这里演示一下编写python脚本实现布尔盲注的基本流程: 演示靶场:sqli-labs 布尔盲注 特点:没有回显没有报错,但根据sql语句正常与否返回不同结果&#x…...

Microsoft Defender for Office 365部署方案
目录 前言 一、Microsoft Defender for Office 365 部署架构 1、部署环境 2、Microsoft Defender for Office 365 核心服务...

字节岗位薪酬体系曝光,看完感叹:不服真不行
曾经的互联网是PC的时代,随着智能手机的普及,移动互联网开始飞速崛起。而字节跳动抓住了这波机遇,2015年,字节跳动全面加码短视频,从那以后,抖音成为了字节跳动用户、收入和估值的最大增长引擎。 自从字节…...

华为OD机试-高性能AI处理器-2022Q4 A卷-Py/Java/JS
某公司研发了一款高性能AI处理器。每台物理设备具备8颗AI处理器,编号分别为0、1、2、3、4、5、6、7。 编号0-3的处理器处于同一个链路中,编号4-7的处理器处于另外一个链路中,不同链路中的处理器不能通信。 现给定服务器可用的处理器编号数组…...
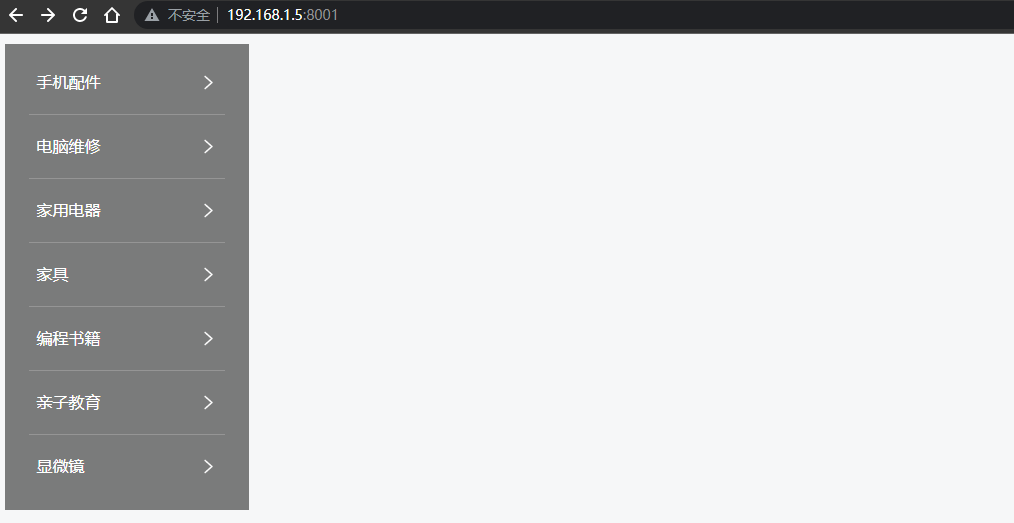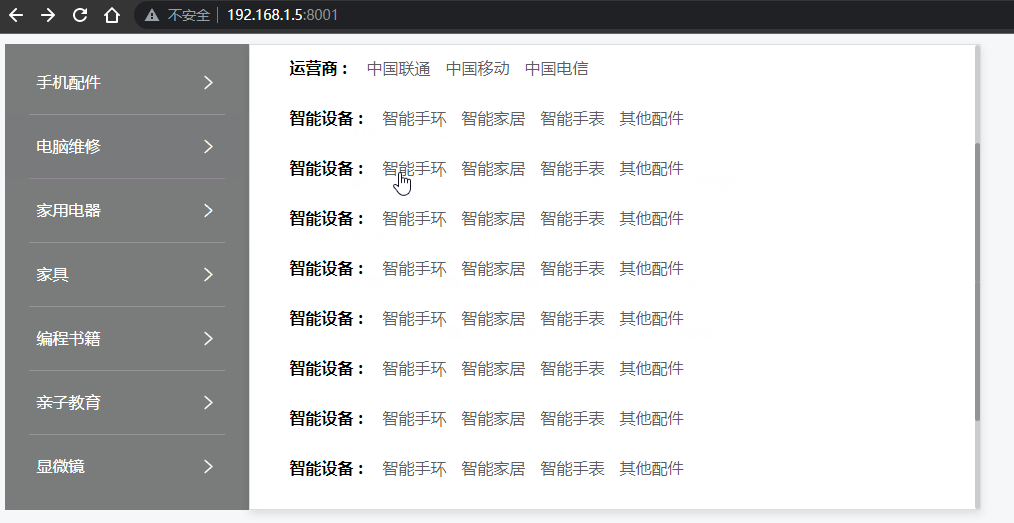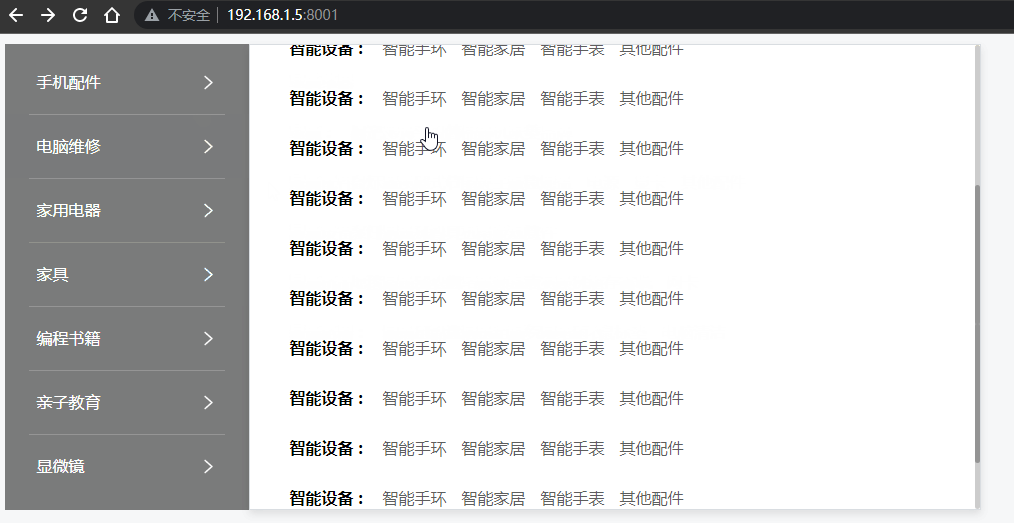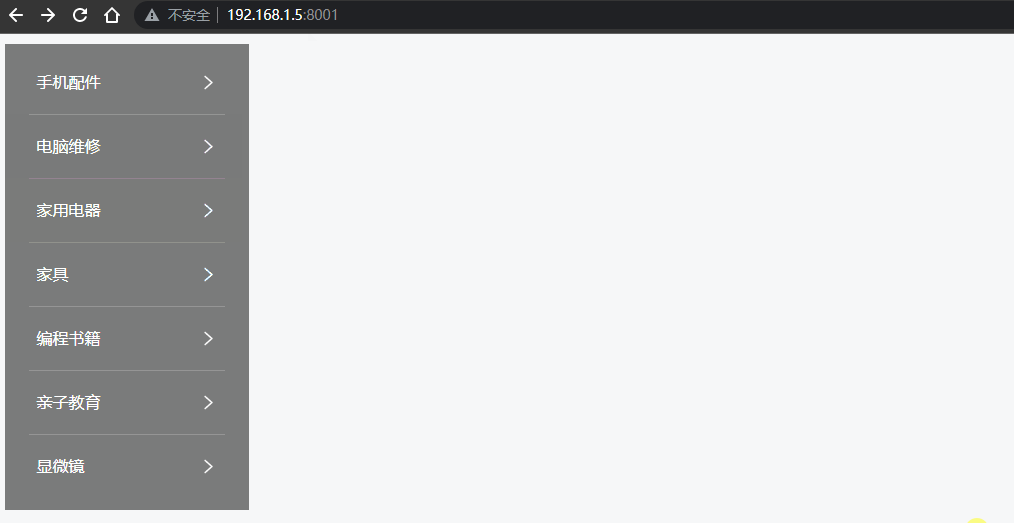
Vue - 实现垂直菜单分类栏目,鼠标移入后右侧出现悬浮二级菜单容器效果(完整示例源码,详细代码注释,一键复制开箱即用)
前言 网上的教程都太乱了,各种杂乱无注释代码、图片资源丢失、一堆样式代码,根本无法改造后应用到自己的项目中。 本文实现了 在 Vue / Nuxt 项目中,垂直分类菜单项,当用户鼠标移入菜单后,右侧自动出现二级分类悬浮容器盒子效果, 您可以直接复制源码,然后按照您的需求再…...
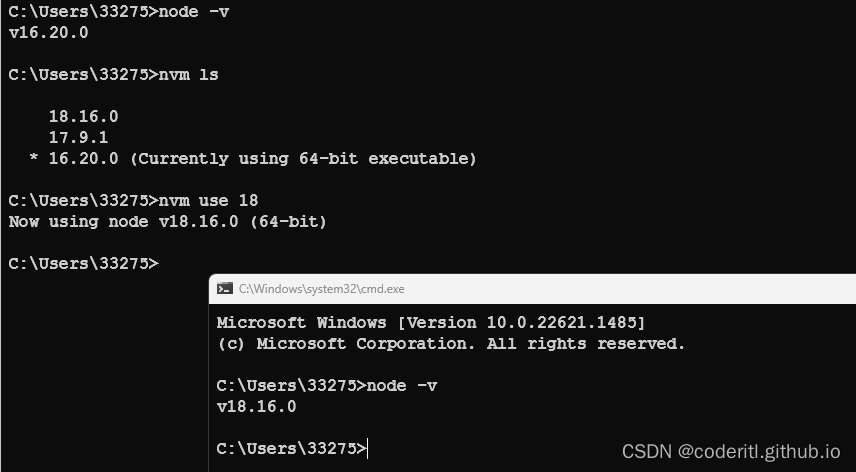
NVM-无缝切换Node版本
NVM-无缝切换Node版本 如果未使用nvm之前已经下载了node,并且配置了环境变量,那么此时删除这些配置(Node的环境以及Node软件),使用nvm是为了在某些项目中使用低版本的node NVM下载 进入github的nvm readme: https://github.com/coreybutler/nvm-windows…...

CCF-CSP真题《202303-1 田地丈量》思路+python,c++满分题解
想查看其他题的真题及题解的同学可以前往查看:CCF-CSP真题附题解大全 试题编号:202303-1试题名称:田地丈量时间限制:1.0s内存限制:512.0MB问题描述: 问题描述 西西艾弗岛上散落着 n 块田地。每块田地可视为…...

Autosar-软件架构
文章目录 一、Autosar软件架构分层图二、应用层三、RTE层四、BSW层1、微控制器抽象层2、ECU抽象层I/O硬件抽象COM硬件抽象Memory硬件抽象Onboard Device Abstraction3、复杂驱动层4、服务层系统服务通信服务CAN一、Autosar软件架构分层图 架构分层是实现软硬件分离的关键,它也…...

8年测开年薪30W,为什么从开发转型为测试?谈谈这些年的心路历程……
谈谈我的以前,从毕业以来从事过两个多月的Oracle开发后转型为软件测试,到现在已近过去8年成长为一个测试开发工程师,总结一下之间的心路历程,希望能给徘徊在开发和测试之前的同学一点小小参考。 一、测试之路伏笔 上学偷懒&#…...
滑动奇异频谱分析:数据驱动的非平稳信号分解工具(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

updateByPrimaryKey和updateByPrimaryKeySelective的区别
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl MyBatis Generator概述 MyBatis Generator是一个专门为MyBatis框架使用者定制的代码生成器,它可以快速的根据表生成对应的映射文件、接口文件、POJO。而且&#…...

【ARM Coresight 4 - Rom Table 介紹】
文章目录 1.1 ROM Table1.1.1 Entry 寄存器 1.2 ROM Table 例子 1.1 ROM Table 在一个SoC中,有多个Coresight 组件,但是软件怎么去识别这些 Coresight 组件,去获取这些Coresight 组件的信息了?这个时候,就需要靠 Core…...

11111111
单选题 1、某地上2层的仪表装配厂房,耐火等级二级,每层建筑面积10000m2,该厂 房二层设有800m2的金属零件抛光工段,采用耐火极限为2.00h的防火隔墙与其他区域分隔,该厂房的火灾危险性为( )。 正确答案:B A.甲类 B.乙类 C.丙…...
JavaWeb——TCP协议的相关特性
目录 一、TCP 1、特性 2、确认应答 (1)、定义 (2)、原理 (3)、接收缓冲区 3、超时重传 (1)、丢包 (2)、定义 (3)、分类 二、…...

Unity编辑器日志调试革命:Editor Console Pro深度解析
1. 为什么我删掉了Unity默认控制台的全部自定义脚本——从Editor Console Pro第一次启动说起 刚接手一个三年前的老项目,打开Unity编辑器第一件事就是点开Console窗口——结果满屏红色报错里混着几十条黄色警告,还有十几条被折叠的“Log”信息藏在层层嵌…...

企业网盘怎么选?从同步效率、权限、安全合规到协作:2025横评清单
随着企业数字化办公深化,企业网盘承载的内容从项目文件扩展到合同、投研材料、设计源文件、制度文档与交付归档。选型时如果只看容量和下载速度,往往会忽略更关键的管理问题:越权共享如何追责、误删误改如何恢复、离职交接如何确保资料不丢、…...

在OpenClaw Agent工作流中无缝接入Taotoken调用多模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw Agent工作流中无缝接入Taotoken调用多模型能力 对于使用OpenClaw构建智能体工作流的开发者而言,能够灵活调…...
)
突发环境事件怎么模拟?用Python+GIS实现高斯烟团模型(附完整代码)
突发污染事件动态模拟:Python与GIS融合的高斯烟团建模实战 化工泄漏、危险品运输事故等突发环境事件往往需要快速响应与精准评估。传统烟羽模型在瞬态污染场景中存在局限性,而高斯烟团模型凭借其动态扩散模拟能力成为应急决策的利器。本文将手把手带您实…...

WeChatFerry:微信机器人自动化框架的终极技术指南
WeChatFerry:微信机器人自动化框架的终极技术指南 【免费下载链接】WeChatFerry 微信机器人,可接入DeepSeek、Gemini、ChatGPT、ChatGLM、讯飞星火、Tigerbot等大模型。微信 hook WeChat Robot Hook. 项目地址: https://gitcode.com/GitHub_Trending/w…...

别再死记硬背了!用Spark实战电影评分分析,手把手教你搞定Join操作与数据清洗
用Spark实战电影评分分析:从数据清洗到Join操作的完整指南 每次看到电影评分网站上的"Top 100"榜单,你有没有好奇过背后的数据处理逻辑?作为Spark初学者,你可能已经啃了不少官方文档,但面对真实数据集时依然…...

星露谷物语SMAPI模组加载器:从新手到专家的终极指南
星露谷物语SMAPI模组加载器:从新手到专家的终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾梦想为星露谷物语添加全新的游戏体验?SMAPI模组加载器正是实现这…...

智能数据上下文层:让AI代理真正理解您的企业数据价值
智能数据上下文层:让AI代理真正理解您的企业数据价值 【免费下载链接】WrenAI Turn any AI Agents into world-class data analysts through the open context layer that gives AI agents grounded, governed memory, context, SQL across 20 data sources, that h…...

非标系统控制柜制造:从特殊工况到定制控制的完整解析
一、什么是非标系统控制柜制造?非标系统控制柜制造,是指针对常规PLC控制柜、变频器控制柜、低压配电柜、防爆控制柜之外的特殊控制需求,根据设备工艺、现场环境、控制逻辑、通讯协议、安全要求和安装空间,对柜体结构、电气元件、控…...

深度解析游戏资源加密机制:构建安全增强模块的完整实现
深度解析游戏资源加密机制:构建安全增强模块的完整实现 【免费下载链接】wuwa-mod Wuthering Waves pak mods 项目地址: https://gitcode.com/GitHub_Trending/wu/wuwa-mod WuWa-Mod作为《鸣潮》(Wuthering Waves)游戏模组开发项目,通过AES加密解…...