第06讲:为何各大开源框架专宠 SPI 技术?
在此前的内容中,已经详细介绍了 SkyWalking Agent 用到的多种基础技术,例如,Byte Buddy、Java Agent 以及 OpenTracing 中的核心概念。本课时将深入介绍 SkyWalking Agent 以及 OAP 中都会使用到的 SPI 技术。
JDK SPI 机制
SPI(Service Provider Interface)主要是被框架开发人员使用的一种技术。例如,使用 Java 语言访问数据库时我们会使用到 java.sql.Driver 接口,每个数据库厂商使用的协议不同,提供的 java.sql.Driver 实现也不同,在开发 java.sql.Driver 接口时,开发人员并不清楚用户最终会使用哪个数据库,在这种情况下就可以使用 Java SPI 机制为 java.sql.Driver 接口寻找具体的实现。
当服务的提供者提供了一种接口的实现之后,需要在 Classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,此文件记录了该 jar 包提供的服务接口的具体实现类。当某个应用引入了该 jar 包且需要使用该服务时,JDK SPI 机制就可以通过查找这个 jar 包的 META-INF/services/ 中的配置文件来获得具体的实现类名,进行实现类的加载和实例化,最终使用该实现类完成业务功能。
下面通过一个简单的示例演示 JDK SPI 的基本使用方式,示例如下:

首先我们需要创建一个 Log 接口,来模拟日志打印的功能:
public interface Log {void log(String info);
}
接下来提供两个实现 —— Logback 和 Log4j,分别代表两个不同日志框架的实现,如下所示:
public class Logback implements Log {@Overridepublic void log(String info) {System.out.println("Logback:" + info);}
}
public class Log4j implements Log {
public void log(String info) {
System.out.println(“Log4j:” + info);
}
}
在项目的 resources/META-INF/services 目录下添加一个名为 com.xxx.Log 的文件,这是 JDK SPI 需要读取的配置文件,具体内容如下:
com.xxx.impl.Log4j
com.xxx.impl.Logback
最后创建 main() 方法,其中会加载上述配置文件,创建全部 Log 接口实现的实例,并执行其 log() 方法,如下所示:
public class Main {public static void main(String[] args) {ServiceLoader<Log> serviceLoader = ServiceLoader.load(Log.class);Iterator<Log> iterator = serviceLoader.iterator();while (iterator.hasNext()) {Log log = iterator.next();log.log("JDK SPI"); }}
}
// 输出如下:
// Log4j:JDK SPI
// Logback:JDK SPI
JDK SPI源码分析
通过上述示例,我们可以看到 JDK SPI 的入口方法是 ServiceLoader.load() 方法,接下来我将对其具体实现进行深入分析。
在 ServiceLoader.load() 方法中,首先会尝试获取当前使用的 ClassLoader(获取当前线程绑定的 ClassLoader,查找失败后使用 SystemClassLoader),然后调用 reload() 方法,调用关系如下图所示:

在 reload() 方法中首先会清理 providers 缓存(LinkedHashMap 类型的集合),该缓存用来记录 ServiceLoader 创建的实现对象,其中 Key 为实现类的完整类名,Value 为实现类的对象。之后创建 LazyIterator 迭代器,该迭代器用于读取 SPI 配置文件并实例化实现类对象。
ServiceLoader.reload() 方法的具体实现,如下所示:
// 缓存,用来缓存 ServiceLoader创建的实现对象
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
public void reload() {
providers.clear(); // 清空缓存
lookupIterator = new LazyIterator(service, loader); // 迭代器
}
在前面的示例中,main() 方法中使用的迭代器底层就是调用了 ServiceLoader.LazyIterator 实现的。Iterator 接口有两个关键方法:hasNext() 方法和 next() 方法,这里的 LazyIterator 中的next() 方法最终调用的是其 nextService() 方法,hasNext() 方法最终调用的是 hasNextService() 方法,调用关系如下图所示:

首先来看 LazyIterator.hasNextService() 方法,该方法主要负责查找 META-INF/services 目录下的 SPI 配置文件,并进行遍历,大致实现如下所示:
private static final String PREFIX = "META-INF/services/";
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs null) {
// PREFIX前缀与服务接口的名称拼接起来,就是META-INF目录下定义的SPI配
// 置文件(即示例中的META-INF/services/com.xxx.Log)
String fullName = PREFIX + service.getName();
// 加载配置文件
if (loader null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
}
// 按行SPI遍历配置文件的内容
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析配置文件
pending = parse(service, configs.nextElement());
}
nextName = pending.next(); // 更新 nextName字段
return true;
}
接下来,在 hasNextService() 方法中完成 SPI 配置文件的解析之后,再来看 LazyIterator.nextService() 方法,该方法负责实例化 hasNextService() 方法读取到的实现类,其中会将实例化的对象放到 providers 集合中缓存起来,核心实现如下所示:
private S nextService() {String cn = nextName;nextName = null;// 加载 nextName字段指定的类Class<?> c = Class.forName(cn, false, loader);if (!service.isAssignableFrom(c)) { // 检测类型fail(service, "Provider " + cn + " not a subtype");}S p = service.cast(c.newInstance()); // 创建实现类的对象providers.put(cn, p); // 将实现类名称以及相应实例对象添加到缓存return p;
}
在 main() 方法中使用的迭代器的底层实现介绍完了,我们再来看一下其使用的真正迭代器,核心实现如下:
public Iterator<S> iterator() {return new Iterator<S>() {// knownProviders用来迭代 providers缓存Iterator<Map.Entry<String,S>> knownProviders= providers.entrySet().iterator();
public boolean hasNext() {
// 先走查询缓存,缓存查询失败,再通过 LazyIterator加载
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
// 先走查询缓存,缓存查询失败,再通过 LazyIterator加载
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
// 省略remove()方法
};
JDK SPI 在 JDBC 中的应用
了解了 JDK SPI 实现的原理之后,我们来看实践中 JDBC 是如何使用 JDK SPI 机制加载不同数据库厂商的实现类。
JDK 中只定义了一个 java.sql.Driver 接口,具体的实现是由不同数据库厂商来提供的。这里以 MySQL 提供的 JDBC 实现包为例进行分析。
在 mysql-connector-java-*.jar 包中的 META-INF/services 目录下,有一个 java.sql.Driver 文件中只有一行内容,如下所示:
com.mysql.cj.jdbc.Driver
在使用 mysql-connector-java-*.jar 包连接 MySQL 数据库的时候,我们会用到如下语句创建数据库连接:
String url = "jdbc:xxx://xxx:xxx/xxx";
Connection conn = DriverManager.getConnection(url, username, pwd);
DriverManager 是 JDK 提供的数据库驱动管理器,其中的代码片段,如下所示:
static {loadInitialDrivers();println("JDBC DriverManager initialized");
}
在调用 getConnection() 方法的时候,DriverManager 类会被 Java 虚拟机加载、解析并触发 static 代码块的执行,在 loadInitialDrivers() 方法中通过 JDK SPI 扫描 Classpath 下 java.sql.Driver 接口实现类并实例化,核心实现如下所示:
private static void loadInitialDrivers() {String drivers = System.getProperty("jdbc.drivers")// 使用 JDK SPI机制加载所有 java.sql.Driver实现类ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);Iterator<Driver> driversIterator = loadedDrivers.iterator();while(driversIterator.hasNext()) {driversIterator.next();}String[] driversList = drivers.split(":");for (String aDriver : driversList) { // 初始化Driver实现类Class.forName(aDriver, true,ClassLoader.getSystemClassLoader());}
}
在 MySQL 提供的 com.mysql.cj.jdbc.Driver 实现类中,同样有一段 static 静态代码块,这段代码会创建一个 com.mysql.cj.jdbc.Driver 对象并注册到 DriverManager.registeredDrivers 集合中( CopyOnWriteArrayList 类型),如下所示:
static {java.sql.DriverManager.registerDriver(new Driver());
}
在 getConnection() 方法中,DriverManager 从该 registeredDrivers 集合中获取对应的 Driver 对象创建 Connection,核心实现如下所示:
private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException {// 省略 try/catch代码块以及权限处理逻辑for(DriverInfo aDriver : registeredDrivers) {Connection con = aDriver.driver.connect(url, info);return con;}
}
Dubbo 对 JDK SPI 的改进
通过前面的分析可以发现,JDK SPI 在查找具体实现类的过程中,需要遍历 SPI 配置文件中定义的所有实现类,该过程中会将这些实现类全部实例化。如果 SPI 配置文件中定义了多个实现类,而我们只需要其中一个实现类时,就会生成不必要的对象。
Dubbo 为了解决上述问题,自己设计了一套 SPI 实现,但是思想与 JDK SPI 机制类似。作为思路的扩展,这里简单介绍一下 Dubbo SPI 的实现原理(SkyWalking 使用是 JDK SPI 而不是 Dubbo SPI )。
首先,Dubbo 将 SPI 配置文件改成了 KV 格式,例如:
dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol
其中 key 就是一个简单的标记,当我们在为一个接口查找具体实现类时,可以指定 key 来选择具体实现,例如,这里指定 key 为 dubbo,Dubbo SPI 就知道我们要的是:org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol 这个实现类。
Dubbo SPI 核心实现是 ExtensionLoader(位于 dubbo-common 模块中的 extension 包中),功能类似于 JDK SPI 中的 java.util.ServiceLoader,其使用方式如下所示:
Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getExtension("dubbo");
// 很明显,在查找 Protocol这个接口的实现类时,还指定了"dubbo"这个key
ExtensionLoader.getExtensionLoader() 方法会根据接口类型从缓存中查找相应的 ExtensionLoader 实现,核心实现如下:
private static final ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<>();
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
ExtensionLoader<T> loader =
(ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type,
new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
查找到接口对应的 ExtensionLoader 对象之后,会调用 getExtension() 方法,再根据传入的 key 查找相应的实现类,最终将其实例化后返回:
// 缓存,记录了 key到实现类对象Holder之间的映射关系
private final ConcurrentMap<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();
public T getExtension(String name) {
Holder<Object> holder = getOrCreateHolder(name);
Object instance = holder.get();
if (instance null) { // double-check防止并发问题
synchronized (holder) {
instance = holder.get();
if (instance null) {
// createExtension()方法中完成了 SPI配置文件的查找以及实现类
// 的实例化,具体实现与 JDK SPI原理类似,其中还会处理 Dubbo中
// 自定义的一些注解,不再展开分析
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}
总结
本课时首先介绍了 JDK SPI 机制的原理,并通过 Log 示例演示了 JDK SPI 的使用方式,然后深入到 ServiceLoader 的源码中分析了 JDK SPI 的实现方式,接下来介绍了 JDBC 4.0 如何使用 JDK SPI 机制加载数据库驱动类,最后介绍了 Dubbo 对 JDK SPI 的改进。
相关文章:
第06讲:为何各大开源框架专宠 SPI 技术?
在此前的内容中,已经详细介绍了 SkyWalking Agent 用到的多种基础技术,例如,Byte Buddy、Java Agent 以及 OpenTracing 中的核心概念。本课时将深入介绍 SkyWalking Agent 以及 OAP 中都会使用到的 SPI 技术。 JDK SPI 机制 SPI(…...

[Unity] No.1 Single单例模式
单例模式 1. 基础 定义:单例模式是指在内存中只会创建且仅创建一次对象的设计模式。在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地…...

【chatGPT知识分享】Flutter web 性能优化基础入门
简介 Flutter 是 Google 在这里插入代码片公司推出的跨平台移动应用开发框架,支持 Android、iOS 和 Web 等多个平台。Flutter Web 是 Flutter 在 Web 平台上的应用,可以开发具有良好用户体验的网站。但是,由于 Web 环境的特殊性,…...

探索Qt折线图之美:一次详尽的多角度解析
探索Qt折线图之美:一次详尽的多角度解析 第一章:Qt折线图的基本概念与应用场景(Basic Concepts and Applications of Qt Line Charts)1.1 Qt折线图简介(Introduction to Qt Line Charts)1.2 Qt折线图的应用…...

minio集群部署,4台服务器+1台nginx
4台主机1台nginx负载均衡 分布式Minio里所有的节点需要有同样的access秘钥和secret秘钥,即:用户名和密码 分布式Minio存放数据的磁盘目录必须是空目录 分布式Minio官方建议生产环境最少4个节点,因为有N个节点,得至少保证有N/2的节…...
实例分割算法BlendMask
实例分割算法BlendMask 论文地址:https://arxiv.org/abs/2001.00309 github代码:https://github.com/aim-uofa/AdelaiDet 我的个人空间:我的个人空间 密集实例分割 密集实例分割主要分为自上而下top-down与自下而上bottom-up两类方法…...

多线程、智能指针以及工厂模式
目录 一、unique_lock 二、智能指针 (其实是一个类) 三、工厂模式 一、unique_lock 参考文章【1】,了解unique_lock与lock_guard的区别。 总结:unique_lock使用起来要比lock_guard更灵活,但是效率会第一点,内存的…...

初探 VS Code + Webview
本文作者为 360 奇舞团前端开发工程师 介绍 VSCode 是一个非常强大的代码编辑器,而它的插件也非常丰富。在开发中,我们经常需要自己编写一些插件来提高开发效率。本文将介绍如何开发一个 VSCode 插件,并在其中使用 Webview 技术。首先介绍一下…...

Codeforces Round 864 (Div. 2)(A~D)
A. Li Hua and Maze 给出两个不相邻的点,最少需要堵上几个方格,才能使得两个方格之间不能互相到达。 思路:显然,对于不邻任何边界的方格来说,最少需要的是4,即上下左右都堵上;邻一个边界就-1&a…...
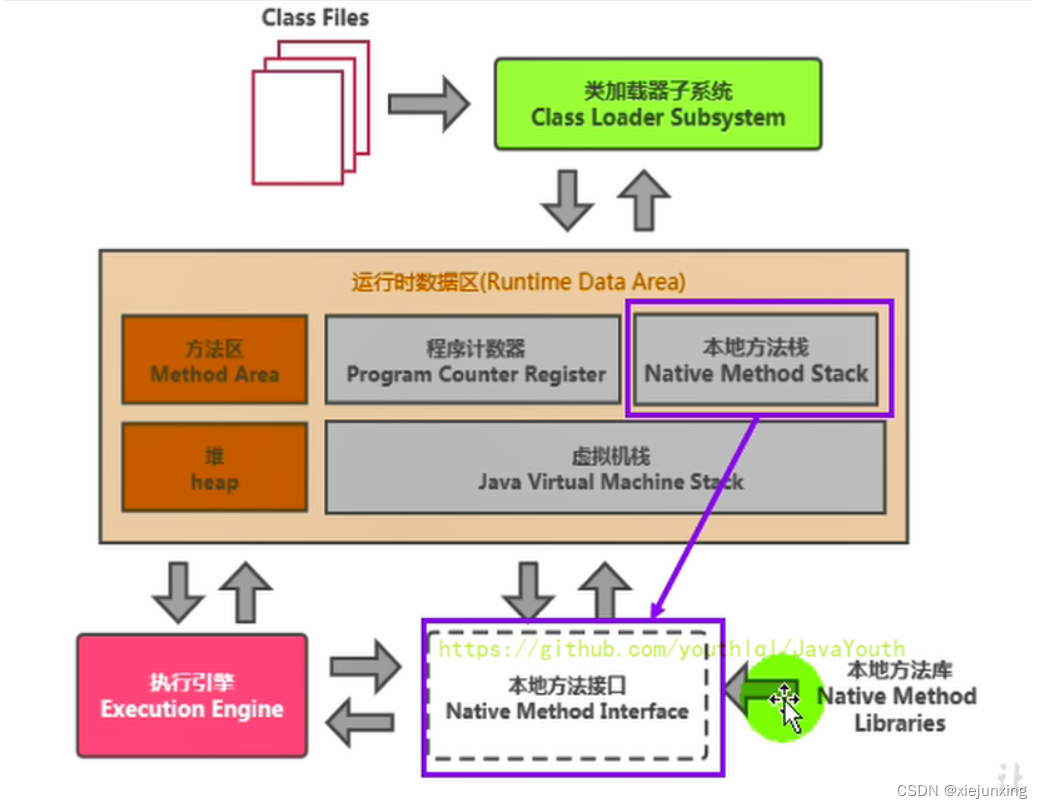
第3章-运行时数据区
此章把运行时数据区里比较少的地方讲一下。虚拟机栈,堆,方法区这些地方后续再讲。 转载https://gitee.com/youthlql/JavaYouth/tree/main/docs/JVM。 运行时数据区概述及线程 前言 本节主要讲的是运行时数据区,也就是下图这部分,…...
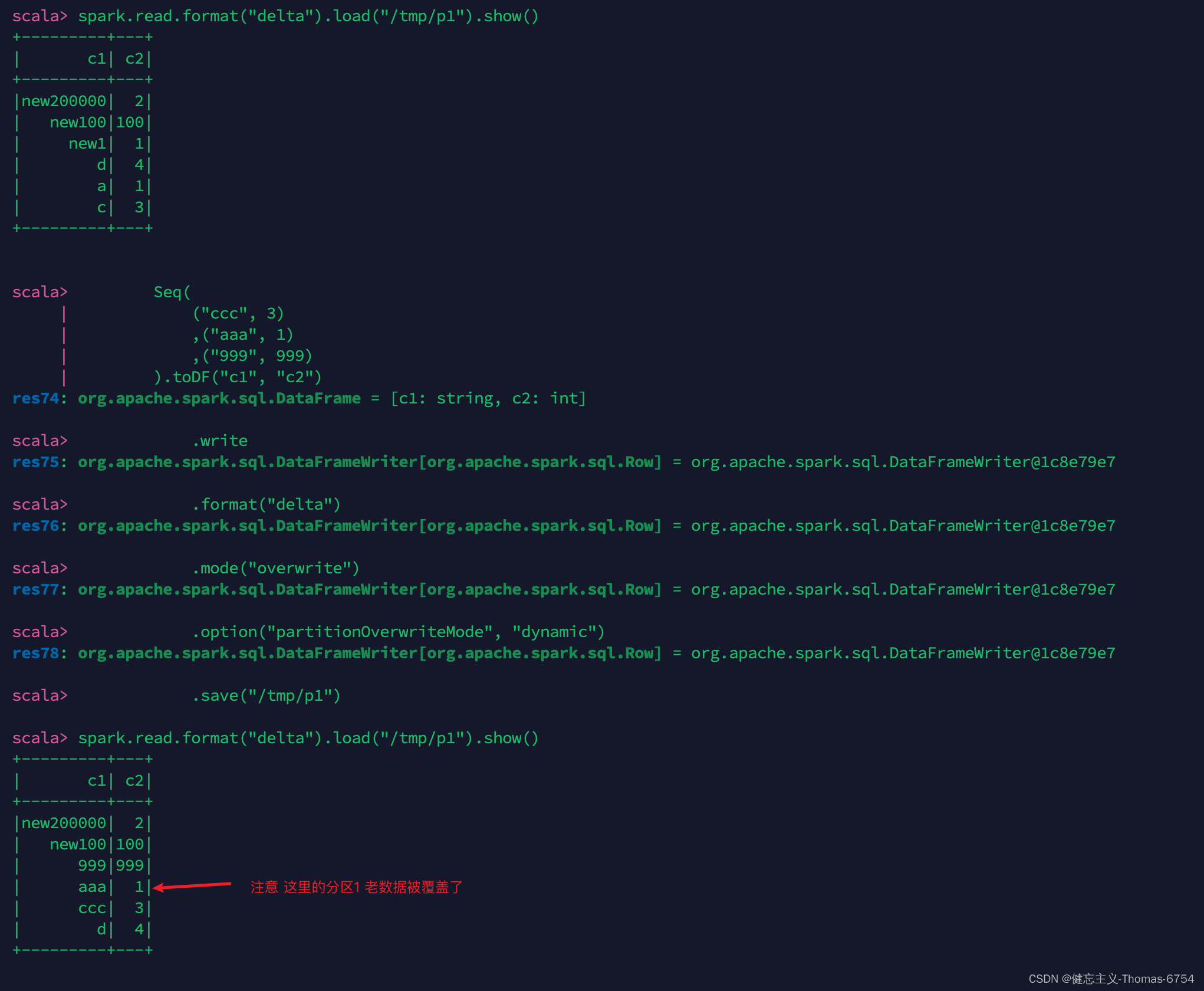
delta.io 参数 spark.databricks.delta.replaceWhere.constraintCheck.enabled
总结 默认值true 你写入的df分区字段必须全部符合覆盖条件 .option("replaceWhere", "c2 == 2") false: df1 overwrite tb1: df1中每个分区的处理逻辑: - tb1中存在(且谓词中匹配)的分区,则覆盖 - tb1中存在(谓词中不匹配)的分区,则append - tb1中不存…...

Redis知识点
1. Redis-常用数据结构 Redis提供了一些数据结构供我们往Redis中存取数据,最常用的的有5种,字符串(String)、哈希(Hash)、列表(list)、集合(set)、有序集合(zset…...
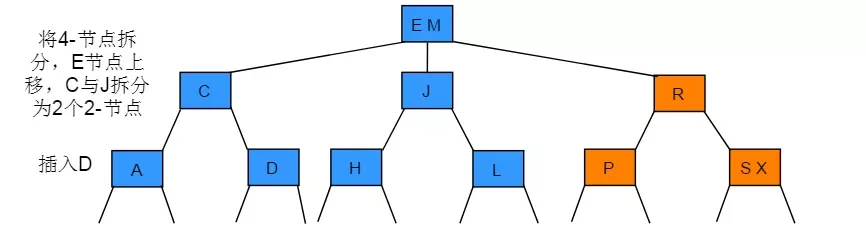
经典数据结构之2-3树
2-3树定义 2-3树,是最简单的B-树,其中2、3主要体现在每个非叶子节点都有2个或3个子节点,B-树即是平衡树,平衡树是为了解决不平衡树查询效率问题,常见的二叉平衡书有AVL树,它虽然提高了查询效率,…...

Numpy从入门到精通——节省内存|通用函数
这个专栏名为《Numpy从入门到精通》,顾名思义,是记录自己学习numpy的学习过程,也方便自己之后复盘!为深度学习的进一步学习奠定基础!希望能给大家带来帮助,爱睡觉的咋祝您生活愉快! 这一篇介绍《…...
Docker-compose 启动 lnmp 开发环境
GitHub传送阵 docker-lnmp 项目帮助开发者快速构建本地开发环境,包括Nginx、PHP、MySQL、Redis 服务镜像,支持配置文件和日志文件映射,不限操作系统;此项目适合个人开发者本机部署,可以快速切换服务版本满足学习服务新…...

《android源码阅读四》Android系统源码整编、单编并运行到虚拟机
1、编译环境 《安装Ubuntu系统》《android源码下载》 2、整编源码 进入Android源码根目录 cd AOSP初始化环境 source build/envsetup.sh清除缓存 make clobber选择编译目标 // 选择编译目标 lunch // 因为本次是在虚拟机中运行,这里使用x86 lunch aosp_x86_6…...

深度学习技巧应用8-各种数据类型的加载与处理,并输入神经网络进行训练
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用8-各种数据类型的加载与处理,并输入神经网络进行训练。在模型训练中,大家往往对各种的数据类型比较难下手,对于非结构化数据已经复杂的数据的要进行特殊处理,这里介绍一下我们如何进行数据处理才能输入到模型中,进…...

【笔试】备战秋招,每日一题|20230415携程研发岗笔试
前言 最近碰到一个专门制作大厂真题模拟题的网站 codefun2000,最近一直在上面刷题。今天来进行2023.04.15携程研发岗笔试,整理了一下自己的思路和代码。 比赛地址 A. 找到you 题意: 给定一个仅包含小写字母的 n n n\times n nn 的矩阵…...
【unity专题篇】—GUI(IMGUI)思维导图详解
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...

【C++ Metaprogramming】0. 在C++中实现类似C#的泛型类
两年前,笔者因为项目原因刚开始接触C,当时就在想,如果C有类似C#中的泛型限定就好了,能让代码简单许多。我也一度认为: 虽然C有模板类,但是却没办法实现C#中泛型特有的 where 关键词: public c…...

专业解密QQ音乐加密格式:QMCDecode让音乐文件重获自由播放权
专业解密QQ音乐加密格式:QMCDecode让音乐文件重获自由播放权 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,…...

基于SpringBoot的咖啡馆会员营销系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的咖啡馆会员营销系统以解决传统会员管理方式中存在的信息孤岛现象与运营效率低下问题该系统通过整合现代信息技术手…...

AI测试的现状与未来:AI会取代人工测试吗
在软件测试领域,AI技术的崛起正掀起一场深刻变革。从自动化测试用例生成到智能缺陷检测,AI的应用场景不断拓展,效率提升显著。这让众多软件测试从业者不禁心生焦虑:AI是否会彻底取代人工测试?要解答这个问题࿰…...

为内部ai工具平台集成taotoken实现多模型灵活切换的方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部AI工具平台集成Taotoken实现多模型灵活切换的方案 在企业内部开发AI工具平台时,一个常见的挑战是如何为不同的业…...

Langchain自定义LLM实战:我把一个简单的Python函数变成了AI模型接口
LangChain自定义LLM实战:从Python函数到智能接口的魔法变形记 在AI应用开发的世界里,大型语言模型(LLM)正以前所未有的速度改变着技术格局。但你是否想过,那些看似神秘的AI接口背后,其实隐藏着一个惊人的简单本质?今天…...

从Launcher到输入法:拆解Android 13窗口栈,看你的App窗口到底在第几层
从Launcher到输入法:Android 13窗口栈深度解析与应用实战 当你在Android设备上点击一个应用图标时,背后发生了什么?为什么输入法总是能浮现在应用之上?系统UI元素又是如何确保不被应用遮挡的?这些问题都指向Android窗口…...

CentOS 7服务器部署:NFS共享、Nginx-RTMP流媒体与Qt无GUI环境全攻略
1. 项目概述与核心思路最近在华为云的一台CentOS 7.4 64位服务器版ECS上,完整部署了一套用于音视频处理和后台服务的开发环境。这个环境的核心目标,是为一个需要处理视频流、提供Web服务,并能方便地进行跨机文件共享和Qt程序编译的后台系统打…...

Vivado用户必看:中文用户名导致Vscode关联失效?手把手教你修改vivado.xml文件
Vivado与Vscode联动的终极解决方案:彻底攻克中文路径兼容性问题 在FPGA开发领域,Vivado作为Xilinx推出的旗舰级开发工具,与轻量级代码编辑器Vscode的联动已经成为提升开发效率的标准配置。然而,许多中文用户在实际操作中常常遇到…...
)
Perplexity体育搜索冷启动难题终结方案:从数据源注册到热点事件自动聚类,全程12分钟极速上线(含CLI脚本)
更多请点击: https://intelliparadigm.com 第一章:Perplexity体育新闻搜索 Perplexity 是一款以实时网络检索与精准问答能力见长的 AI 搜索工具,其在体育新闻领域的应用显著区别于传统搜索引擎——它不依赖静态索引,而是动态调用…...

从ADC采样到FFT分析:手把手教你用STM32F407的DSP库搞定频谱计算
从ADC采样到FFT分析:手把手教你用STM32F407的DSP库搞定频谱计算 在工业振动监测、音频信号处理和电源质量分析等场景中,频谱分析是理解信号特征的关键技术。STM32F407凭借其Cortex-M4内核和硬件FPU,配合CMSIS-DSP库,能够高效实现实…...