【转】Generative Pretrained Transformer
原文链接:https://www.cnblogs.com/yifanrensheng/p/13167796.html
一、GPT简介
1.1 背景
目前大多数深度学习方法依靠大量的人工标注信息,这限制了在很多领域的应用。此外,即使在可获得相当大的监督语料情况下,以无监督学习的方式学到的表示也可以提供显着的性能提升。到目前为止,最引人注目的证据是广泛使用预训练词嵌入来提高一系列NLP任务的性能。
1.2 简介
GPT主要出论文《Improving Language Understanding by Generative Pre-Training》,GPT 是"Generative Pre-Training"的简称,从名字看其含义是指的生成式的预训练。
GPT 采用两阶段过程,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。
回到顶部
二、GPT模型概述
2.1 第一阶段
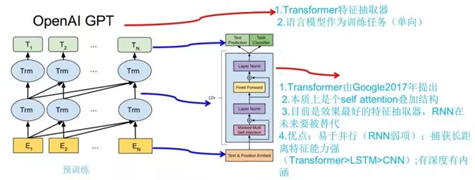
上图展示了 GPT 的预训练过程,其实和 ELMO 是类似的,主要不同在于两点:
特征抽取器不是用的 RNN,而是用的 Transformer,上面提到过它的特征抽取能力要强于 RNN,这个选择很明显是很明智的;
ELMO使用上下文对单词进行预测,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
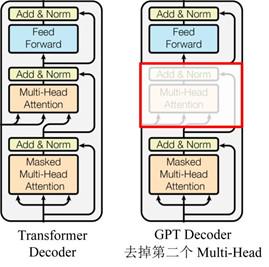
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
2.2 第二阶段
上面讲的是 GPT 如何进行第一阶段的预训练,那么假设预训练好了网络模型,后面下游任务怎么用?它有自己的个性,和 ELMO 的方式大有不同。

上图展示了 GPT 在第二阶段如何使用。
对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向 GPT 的网络结构看齐,把任务的网络结构改造成和 GPT 的网络结构是一样的。
在做下游任务的时候,利用第一步预训练好的参数初始化 GPT 的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了,这是个非常好的事情。再次,你可以用手头的任务去训练这个网络,对网络参数进行 Fine-tuning,【类似图像领域预训练的过程】
那怎么改造才能靠近 GPT 的网络结构呢?
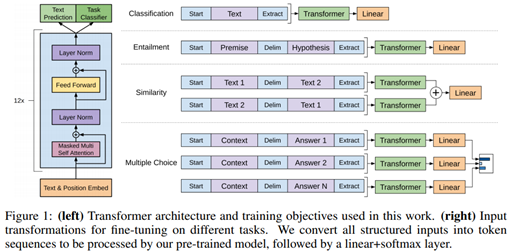
GPT 论文给了一个改造施工图如上:
对于分类问题,不用怎么动,加上一个起始和终结符号即可;
对于句子关系判断问题,比如 Entailment,两个句子中间再加个分隔符即可;
对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
2.3 效果
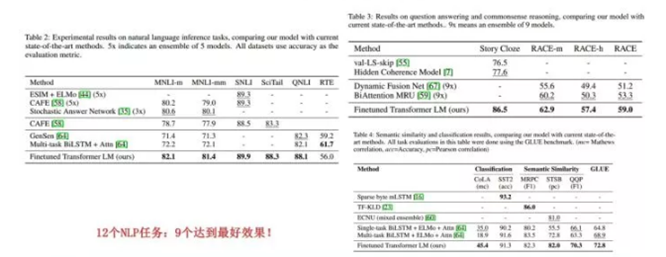
在GPT出来之时:效果是非常令人惊艳的,在 12 个任务里,9 个达到了最好的效果,有些任务性能提升非常明显。
回到顶部
三、GPT模型解析
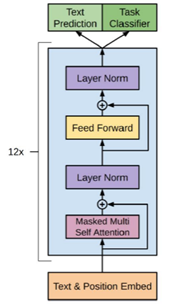
GPT 训练过程分为两个部分,无监督预训练语言模型和有监督的下游任务 fine-tuning。
3.1 预训练语言模型
给定句子 U=[u1, u2, ..., un],GPT 训练语言模型时需要最大化下面的似然函数。
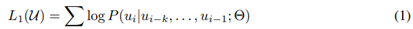
文章中使用的是多层Transformer的decoder的语言模型。这个多层的结构应用multi-headed self-attention在处理输入的文本加上位置信息的前馈网络,输出是词的概念分布。
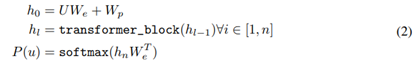
h0 表示GPT 的输入,Wp 是单词位置的 Embedding,We 是单词的 Embedding。得到输入 h0 之后,需要将 h0 依次传入 GPT 的所有 Transformer Decoder 里,最终得到 ht。最后送到softmax得到 ht 再预测下个单词的概率。
用V表示词汇表大小,L表示最长的句子长度,dim 表示 Embedding 维度,则 Wp 是一个 L×dim 的矩阵,We 是一个V×dim 的矩阵。
3.2 下游任务 fine-tuning
GPT 经过预训练之后,会针对具体的下游任务对模型进行微调。微调的过程采用的是有监督学习,训练样本包括单词序列 [x1, x2, ..., xm] 和 类标 y。GPT 微调的过程中根据单词序列 [x1, x2, ..., xm] 预测类标 y。

Wy 表示预测输出时的参数,微调时候需要最大化以下函数。

GPT 在微调的时候也考虑预训练的损失函数,所以最终需要优化的函数为:

回到顶部
四、总结
GPT 预训练时利用上文预测下一个单词,ELMO和BERT (下一篇将介绍)是根据上下文预测单词,因此在很多 NLP 任务上,GPT 的效果都比 BERT 要差。但是 GPT 更加适合用于文本生成的任务,因为文本生成通常都是基于当前已有的信息,生成下一个单词。
优点
RNN所捕捉到的信息较少,而Transformer可以捕捉到更长范围的信息。
计算速度比循环神经网络更快,易于并行化
实验结果显示Transformer的效果比ELMo和LSTM网络更好
缺点
对于某些类型的任务需要对输入数据的结构作调整
对比bert,没有采取双向形式,削弱了模型威力
相关文章:
【转】Generative Pretrained Transformer
原文链接:https://www.cnblogs.com/yifanrensheng/p/13167796.html一、GPT简介1.1 背景目前大多数深度学习方法依靠大量的人工标注信息,这限制了在很多领域的应用。此外,即使在可获得相当大的监督语料情况下,以无监督学习的方式学…...
day34|343. 整数拆分、96.不同的二叉搜索树
343. 整数拆分 给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k > 2 ),并使这些整数的乘积最大化。 返回 你可以获得的最大乘积 。 示例 1: 输入: n 2 输出: 1 解释: 2 1 1, 1 1 1。 示例 2: 输入: n 10 输出: 36 解…...
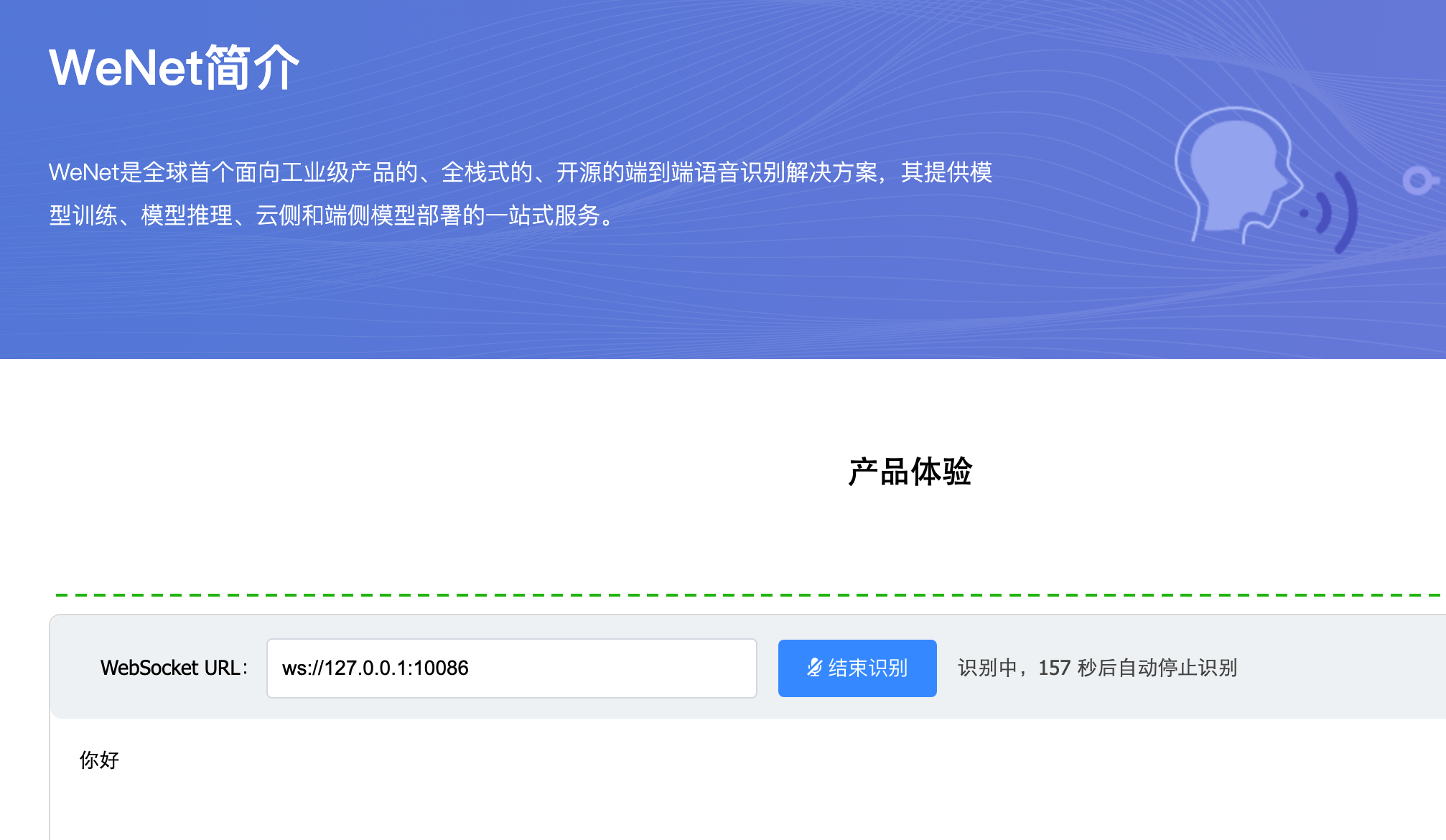
WeNet - 初识
文章目录关于 WeNet快速上手识别训练环境准备训练关于 WeNet Production First and Production Ready End-to-End Speech Recognition Toolkit github: https://github.com/wenet-e2e/wenet官方中文说明:https://github.com/wenet-e2e/wenet/blob/main/README_CN.md…...
为什么各个企业都在创建FAQ、常见问题页面?
常见问题解答页面是您可能已经为您的公司考虑过的东西,作为帮助客户回答有关您的产品和服务的常见问题的一种方式。但是您不知道最好的方法;肯定这只是一个问题清单吗?常见问题解答在整个购买过程中为客户提供支持,并减少客户需要与贵公司的联…...

【React-Router】路由传参,路由嵌套,手动导航,路由文件配置
文章目录React-RouterURL的hashHTML5的HistoryRouter的基本使用路由映射配置路由的嵌套路由配置和跳转Link和NavLink:手动路由的跳转路由参数传递Navigate导航Not Found页面配置路由的配置文件React-Router 前端路由是如何做到URL和内容进行映射呢?怎么…...
)
面向对象分析与设计(OOAD)
面向对象分析与设计(OOAD)概述人是怎么认识事物的分类与分层的两种思维问题域到解空间的映射软件生命周期要解决的问题三个一致性面向对象分析与设计过程对象从哪里来发现对象的方法组织对象结构职责是怎么来的分配职责的逻辑验证职责分配的合理性GRASP设…...

数据库调优
目录 硬件层面 操作系统层面 数据库层面 硬件层面 1.CPU(运算):48核CPU。 2.内存:96G-256G,跑3-4个实例。 3.disk(磁盘IO):机械盘:选SAS,数量越多越好。性能:SSD(高并发)>SAS(普通业务线上)>SATA(线下) 选SSD:使用SSD或者PCIe SSD设备,可提升上千倍的IOPS…...
 | 部署Glance)
OpenStack云平台搭建(3) | 部署Glance
目录 1、登录数据库授权 2、安装glance 3、测试一下 安装部署Glance镜像服务 Image Service 镜像服务:代号:Glance:为云平台虚拟机提供镜像服务,例如:上传镜像、删除镜像等。说明:镜像:磁盘…...

软件评测师考试总结
软件评测师是软考中级考试项,每年一次考试机会,2022年的是在11月份举行,具体事项需查看软考官网。 分享一下个人的备考经验,以及总结一下这个学习的过程,有需要的可以酌情参考。 一、方法策略 获取信息 官网&#x…...

小白系列Vite-Vue3-TypeScript:009-屏幕适配
上一篇我们介绍了ViteVue3TypeScript项目中mockjs的安装和配置。本篇我们来介绍屏幕适配方案,简单说来就是要最大程度上保证我们的界面在各种各样的终端设备上显示正常。通用的屏幕适配方案有两种:① 基于rem 适配(推荐,也是本篇要…...

查找企业微信聊天记录,会话存档有多重要
会话存档是基于企业微信API插口而开发设计的聊天记录查询专用工具。运用会话存档能不能找到误删除、到期的聊天记录呢?实际上能否通过会话存档找到企业微信中的聊天记录分两种状况,大家一起来看看吧:开启会话存档前的聊天记录没法找到和开启会…...
C语言经典编程题100例(1-20)
1、练习2-1 Programming in C is fun!本题要求编写程序,输出一个短句“Programming in C is fun!”。输入格式:本题目没有输入。输出格式:在一行中输出短句“Programming in C is fun!”。代码:#include<stdio.h> int main() {printf("Progra…...
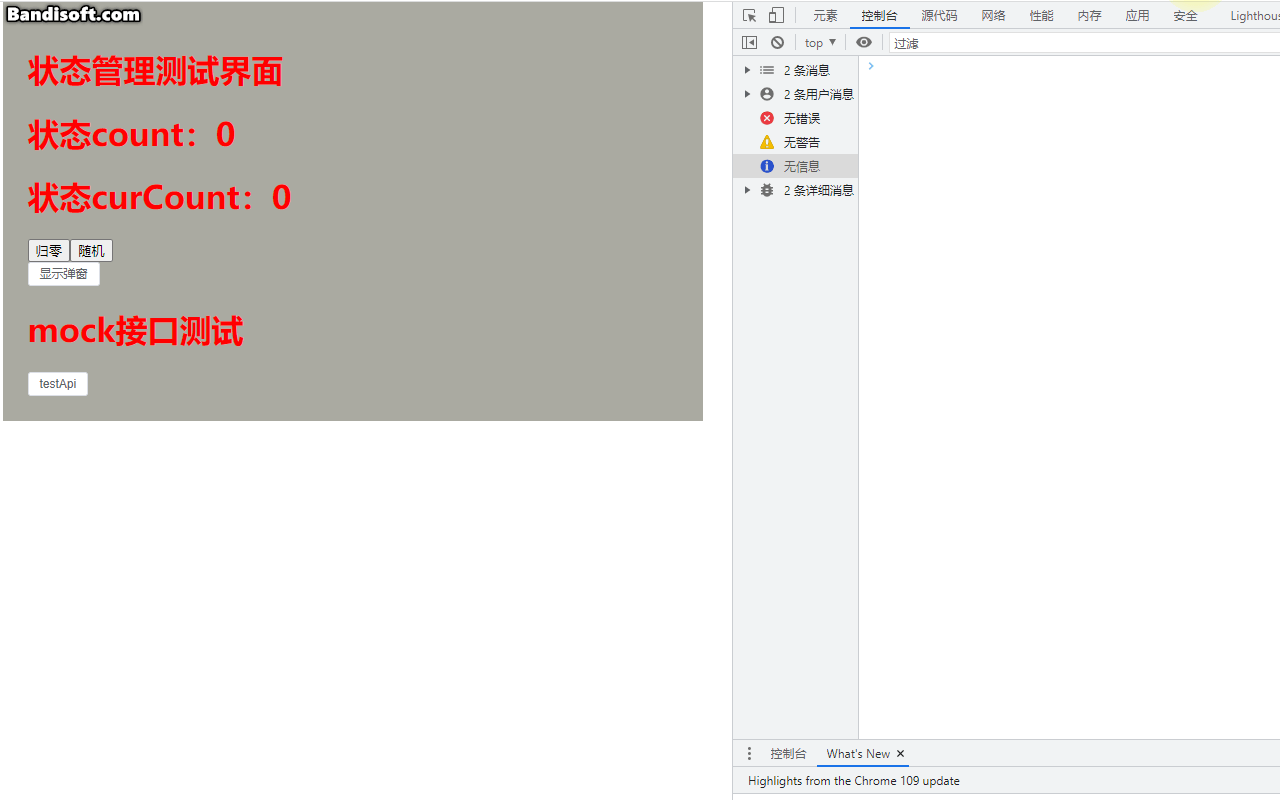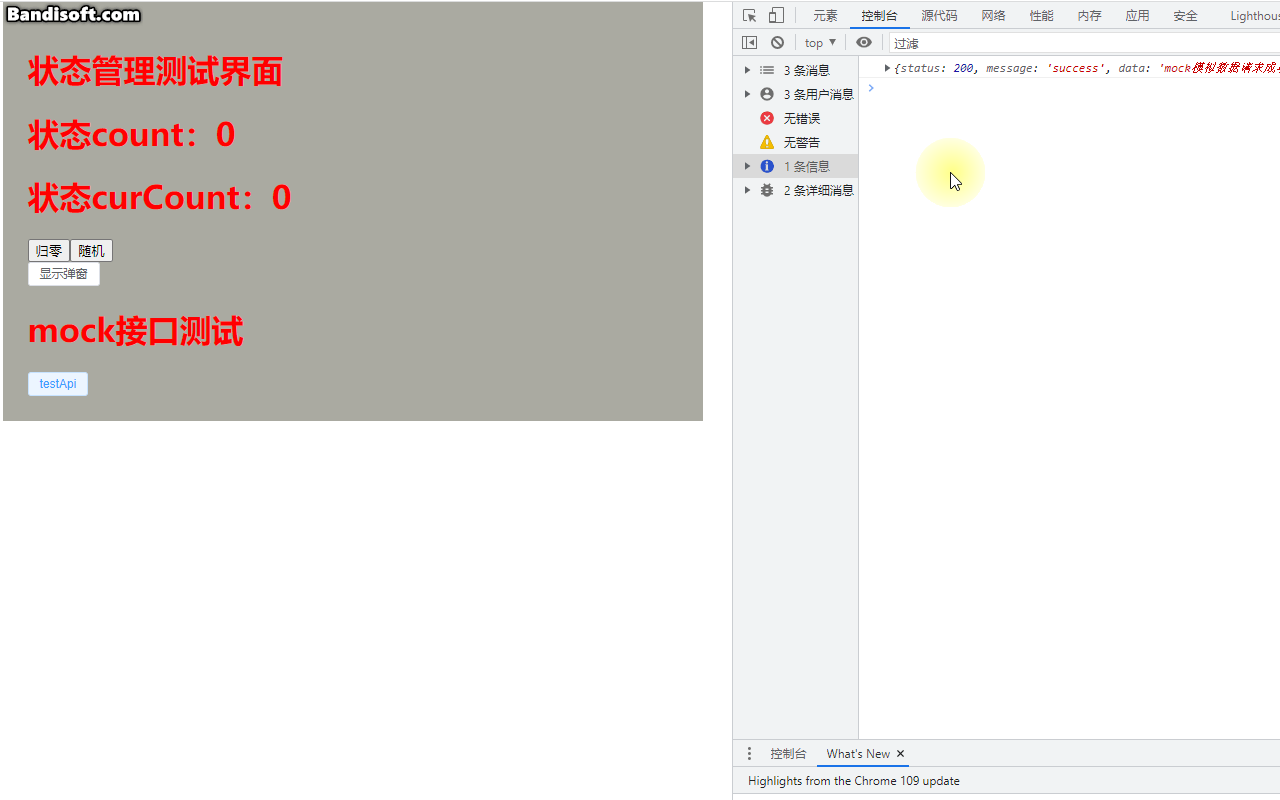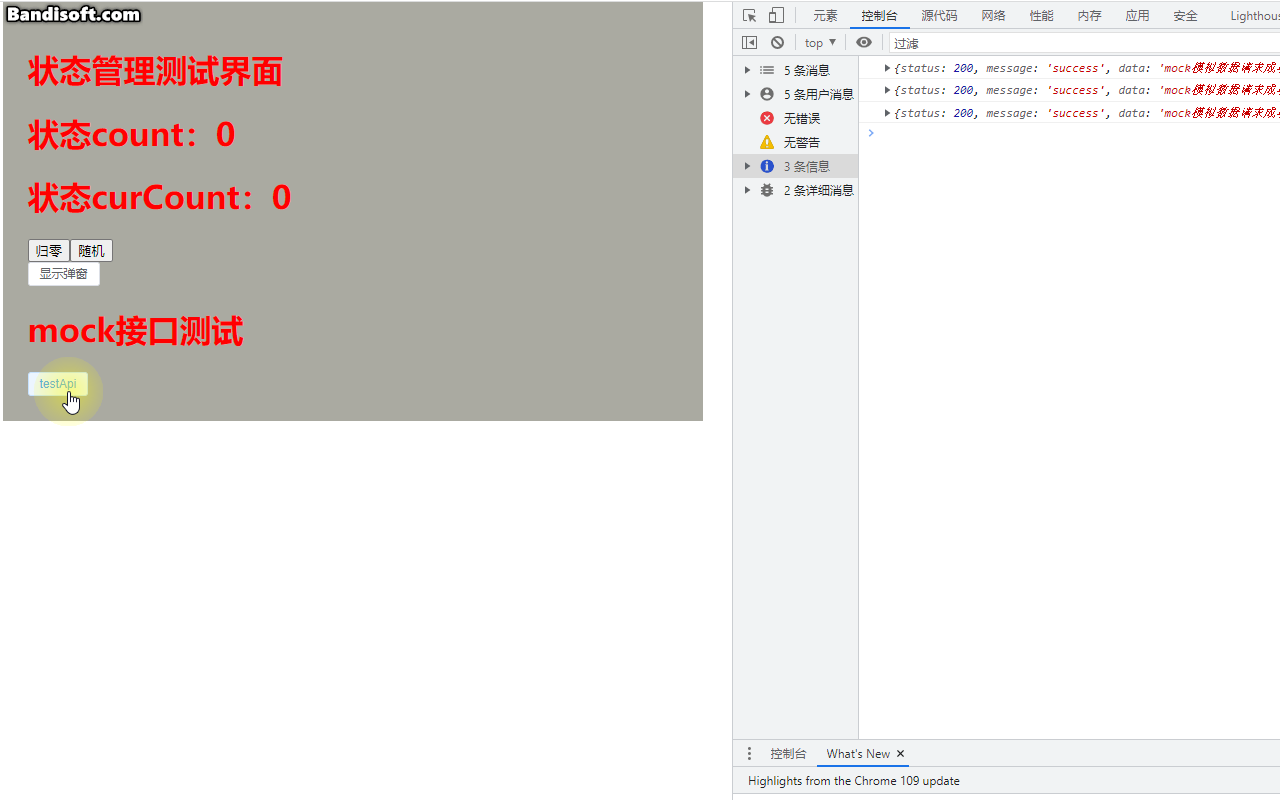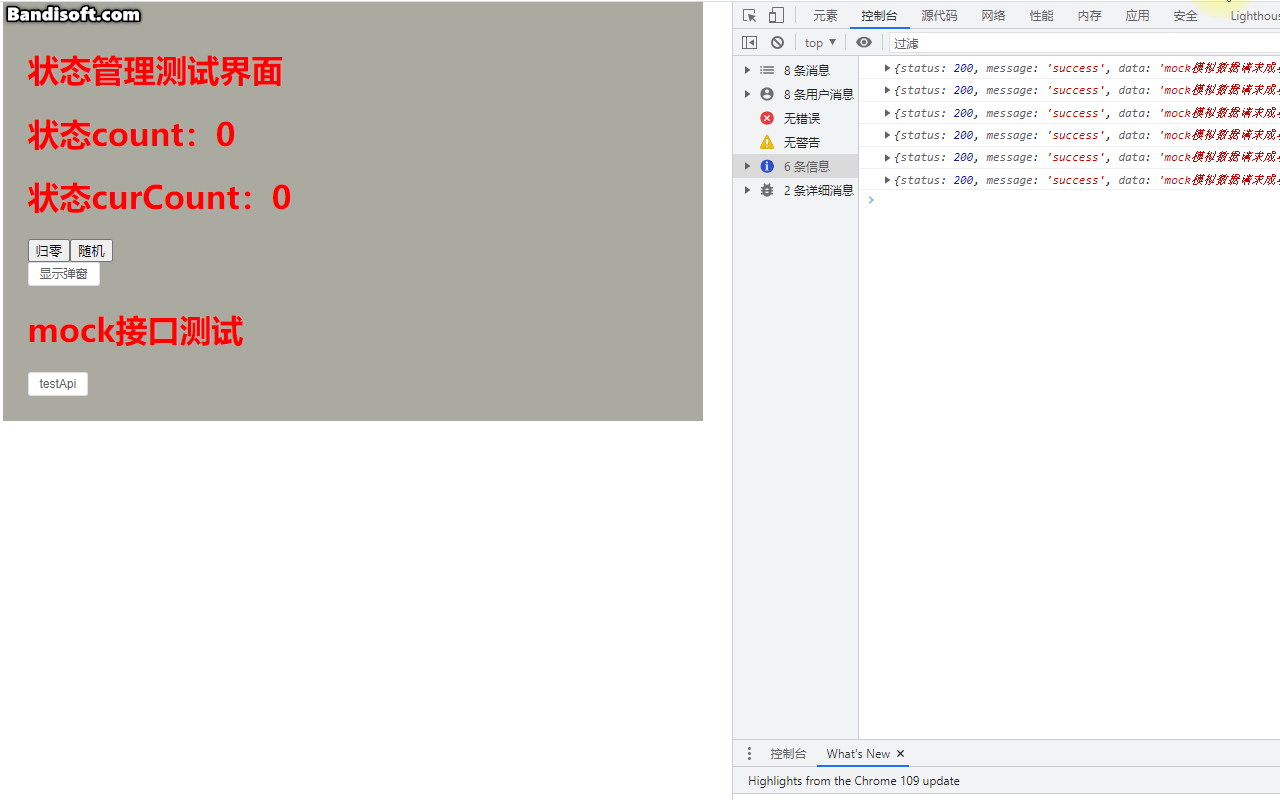
小白系列Vite-Vue3-TypeScript:008-安装配置mock
上一篇我们介绍了ViteVue3TypeScript项目中axios的安装和配置,并手动封装了api。本篇我们来在上篇基础上介绍如何引入mock,并在本地模拟后台接口请求来达到本地测试的目的。在现在前后端分离的开发模式中,前端页面很多渲染的数据都需要通过ht…...

OnGUI Box 控件||Unity 3D OnGUI 常用控件
OnGUI Box 控件Unity 3D Box 控件用于在屏幕上绘制一个图形化的盒子。Box 控件中既可以显示文本内容,也可以绘制图片,或两者同时存在。GUIContent 和 GUIStyle 对于 Box 控件同样适用,既可以用来修饰 Box 控件的文本颜色,也可以用…...
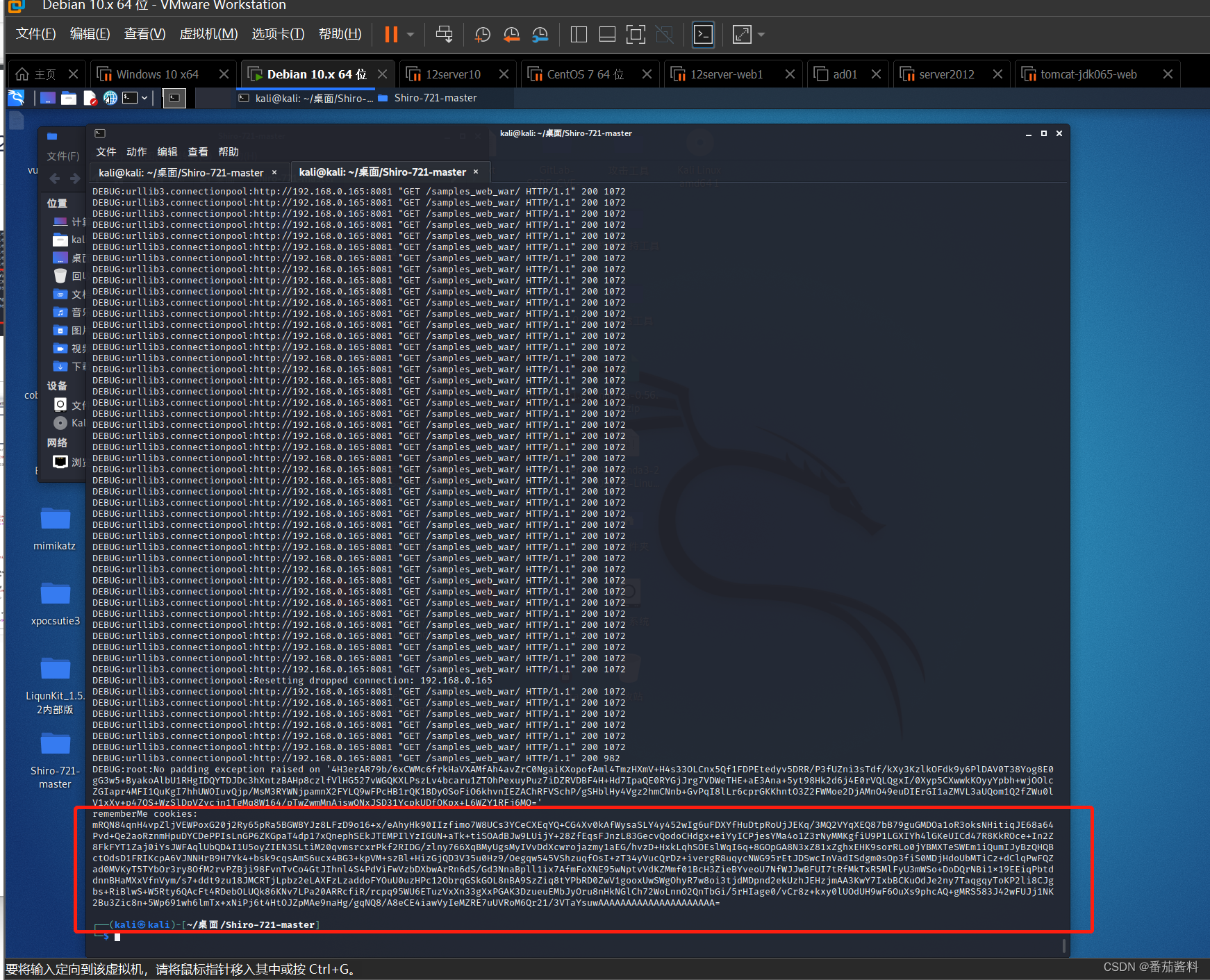
shiro721——CVE-2019-12422
这两个漏洞主要区别在于Shiro550使⽤已知密钥碰撞,后者Shiro721是使⽤ 登录后rememberMe {value}去爆破正确的key值 进⽽反序列化,对⽐Shiro550条件只要有 ⾜够密钥库 (条件⽐较低)、Shiro721需要登录(要求⽐较⾼鸡肋 …...
爬虫JS逆向思路 - - 扣JS(data解密)
网络上几千块都学不到的JS逆向思路这里全都有👏🏻👏🏻👏🏻 本系列持续更新中,三连关注不迷路👌🏻 干货满满不看后悔👍👍👍 ❌注意…...
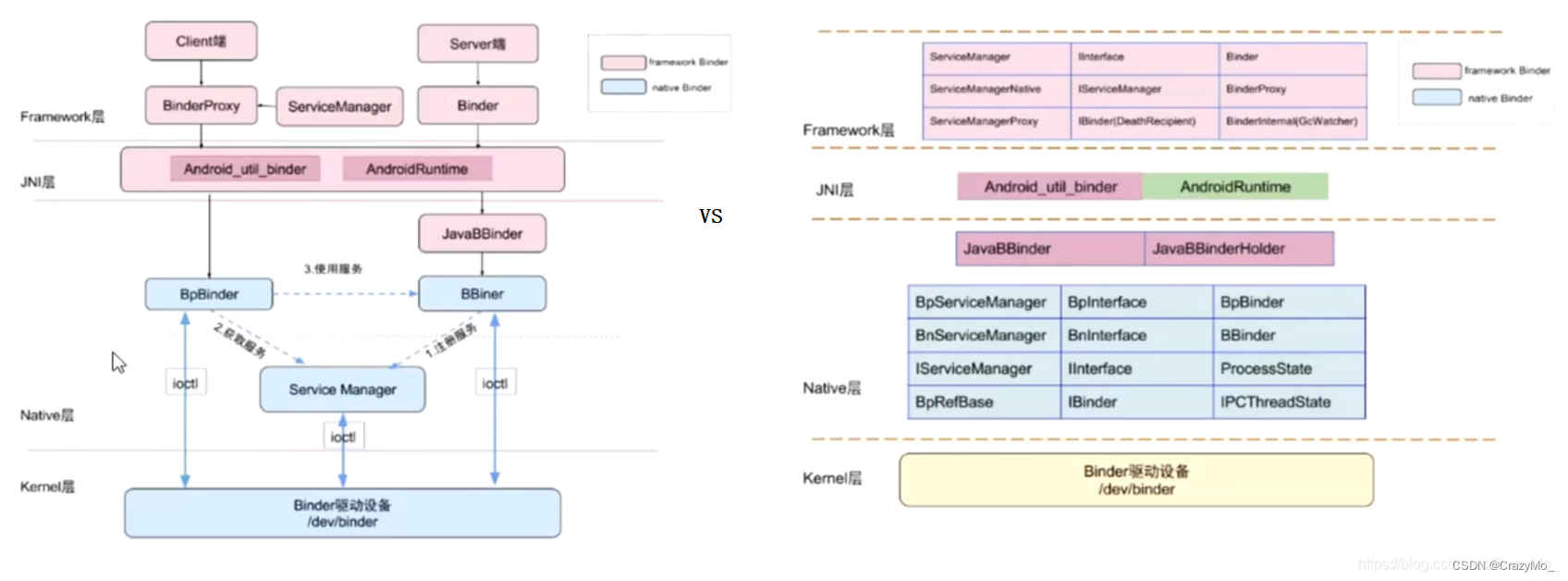
Android 进阶——Framework 核心之Binder 相关预备理论(一)
文章大纲引言一、进程的内存空间和进程隔离二、Linux 系统内存的用户空间和内核空间1、用户空间(User Space)2、内核空间(Kernel Space)三、Linux IPC 原理1、内核态和用户态2、IPC 步骤四、内核模块和驱动五、Binder1、Binder IP…...

【23种设计模式】结构型模式详细介绍
前言 本文为 【23种设计模式】结构型模式 相关内容介绍,下边将对适配器模式,桥接模式,组合模式,装饰模式,外观模式,亨元模式,代理模式,具体包括它们的特点与实现等进行详尽介绍~ &a…...
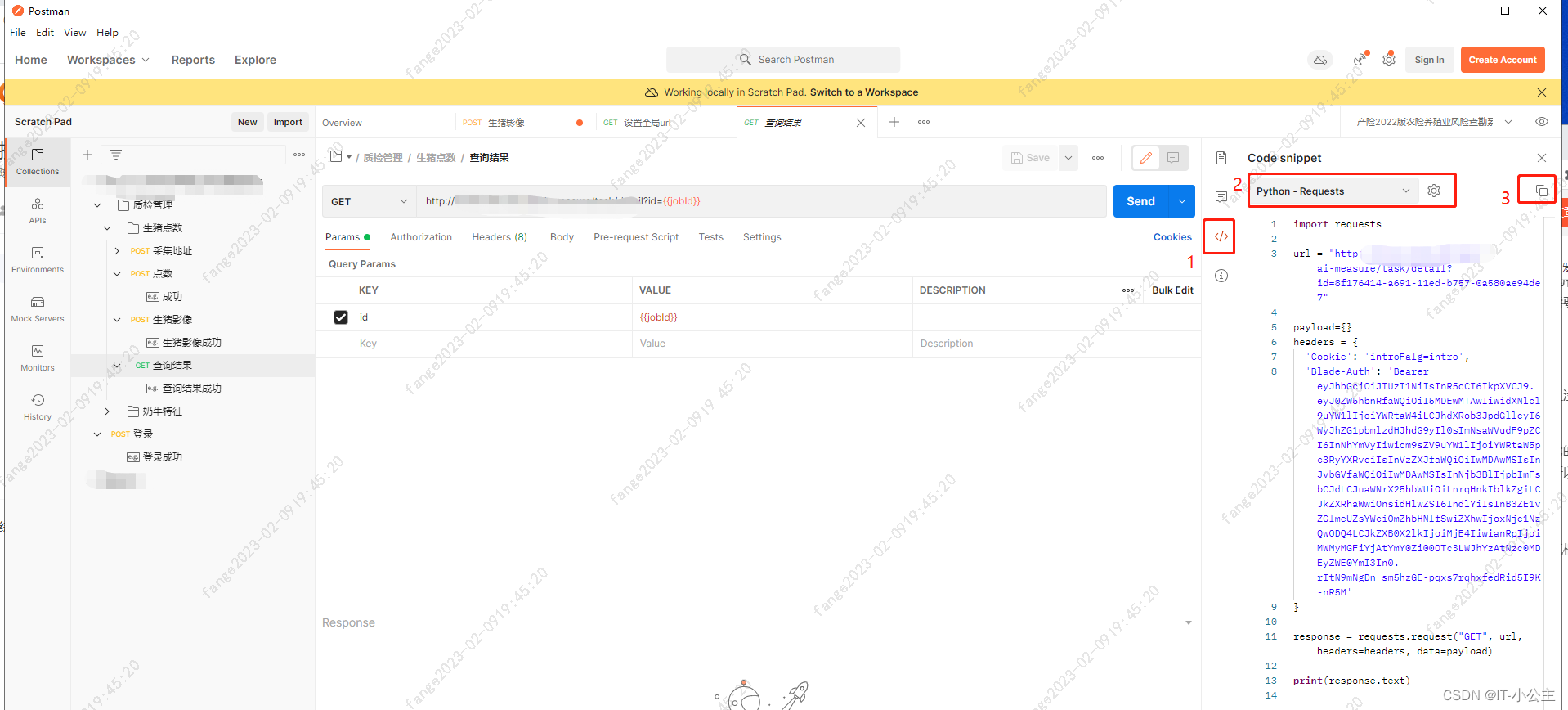
接口自动化实战-postman
1.测试模型 单元测试并非测试工程师的本职工作,它属于开发工程师的工作,开发进行单元测试的情况我们不知道,为了确保系统尽可能没有Bug,于是接口测试在测试工程师这里就变得由为重要了。实际工作中为菱形模型。 接口测试能更早的…...

前端跨域方案简单总结
1、什么是跨域 【】跨域是一种浏览器同源安全策略,也即浏览器单方面限制脚本的跨域访问。很多人可能误认为资源跨域时无法请求,实质上请求是可以正常发起的(指通常情况下,部分浏览器存在部分特例),后端也可…...

观察 Taotoken 在多地域请求下的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在多地域请求下的延迟与稳定性表现 对于依赖大模型 API 进行开发的团队而言,服务的延迟与稳定性是影响开…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

技术视角:Sketchfab数据提取工具深度解析3D模型下载机制
技术视角:Sketchfab数据提取工具深度解析3D模型下载机制 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在WebGL技术日益成熟的今天,Sketch…...

UEFITool深度解析:实战指南与高效使用技巧
UEFITool深度解析:实战指南与高效使用技巧 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款专为UEFI固件分析设计的开源工具,能够将复杂的二进制固件映像…...

Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南
Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的对局中,BP(禁选英雄)阶段往往是决定胜负的关…...

Biomni:生物医学图像分析从入门到精通,AI与传统CV融合实战
1. 项目概述:当AI学会“看”懂生物医学图像如果你在生物医学研究、药物发现或者临床诊断领域工作,大概率会和我一样,对海量的生物医学图像数据感到既兴奋又头疼。兴奋的是,这些图像——无论是显微镜下的细胞切片、组织病理学玻片&…...

模拟电路布局优化:多智能体强化学习实践
1. 模拟电路布局优化的挑战与机遇在集成电路设计领域,模拟电路布局一直是个令人头疼的问题。作为一名从业十余年的模拟电路设计师,我深刻体会到传统布局方法在面对现代工艺挑战时的局限性。每次手工调整晶体管位置时,那种"差之毫厘&…...

Lingoose框架实战:构建智能客服工单处理AI工作流
1. 项目概述:从“Lingo”到“Goose”,一个AI应用编排框架的诞生如果你最近在折腾大语言模型应用,尤其是想把OpenAI、Anthropic这些API的能力整合到自己的业务流程里,那你大概率已经体会过那种“胶水代码”的烦恼了。今天要聊的这个…...

AXI交叉开关IP核:SoC内部高并发数据传输的核心枢纽设计与实战
1. 项目概述:一个高效、可配置的片上总线交叉开关在复杂的数字系统设计,尤其是片上系统(SoC)领域,多个主设备(如CPU、DMA控制器)需要同时访问多个从设备(如内存、外设控制器…...