力扣-94、144、145-前中后序遍历
二叉树遍历方法总结
二叉树的遍历总体上分为深度优先遍历和广度优先遍历。常见的前中后序三种遍历方式就属于深度优先遍历,遍历过程中是顺着一条路径一直遍历到空节点然后向上回溯继续顺着遍历上一个节点的其他方向。层序遍历属于广度优先遍历,先遍历完同一层的节点,再接着遍历下一层节点。
本文主要介绍二叉树三种深度优先遍历方式的实现方式:递归方式和非递归方式。
递归方式实现如下。
前序遍历-力扣144:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public List<Integer> preorderTraversal(TreeNode root) {List<Integer> result = new LinkedList<>();if (root == null) {return result;}preOrder(root,result);return result;}private void preOrder(TreeNode current,List<Integer> result) {if (current != null) {result.add(current.val);preOrder(current.left,result);preOrder(current.right,result);}}
}
中序遍历-力扣94,就是把前序中的处理节点的顺序调整一下。
private void inOrder(TreeNode current,List<Integer> result) {if (current != null) { inOrder(current.left,result);result.add(current.val);inOrder(current.right,result);}
}
后序遍历-力扣145,将节点处理顺序调整到最后:
private void inOrder(TreeNode current,List<Integer> result) {if (current != null) { inOrder(current.left,result); inOrder(current.right,result);result.add(current.val);}
}
非递归方式实现如下。
前序遍历-力扣144,利用栈保存访问过的节点,每访问一个节点,就处理一个。
class Solution {public List<Integer> preorderTraversal(TreeNode root) {List<Integer> result = new LinkedList<>();if (root == null) {return result;}Deque<TreeNode> stack = new LinkedList<>();stack.push(root);while (!stack.isEmpty()) {TreeNode tempNode = stack.pop();result.add(tempNode.val);if (tempNode.right != null) {stack.push(tempNode.right);}if (tempNode.left != null) {stack.push(tempNode.left);}}return result;}
}
中序遍历-力扣94
class Solution {public List<Integer> inorderTraversal(TreeNode root) {List<Integer> result = new LinkedList<>();if (root == null) {return result;}Deque<TreeNode> stack = new LinkedList<>();TreeNode current = root;while (!stack.isEmpty() || current != null) {if (current != null) {stack.push(current);current = current.left;} else {TreeNode tempNode = stack.pop();result.add(tempNode.val);current = tempNode.right;}}return result;}
}
后序遍历-力扣145,后序遍历可以当成是把前序遍历顺序改变一下,从前序的中左右变成中右左,然后再把结果倒置。
class Solution {//后序遍历public List<Integer> postorderTraversal(TreeNode root) {List<Integer> result = new LinkedList<>();if (root == null) {return result;}Deque<TreeNode> stack = new LinkedList<>();stack.push(root);TreeNode cur = root;while (!stack.isEmpty()) {TreeNode tempNode = stack.pop();result.add(tempNode.val);if (tempNode.left != null) {stack.push(tempNode.left);}if (tempNode.right != null) {stack.push(tempNode.right);}}Collections.reverse(result);return result;}}
相关文章:

力扣-94、144、145-前中后序遍历
二叉树遍历方法总结 二叉树的遍历总体上分为深度优先遍历和广度优先遍历。常见的前中后序三种遍历方式就属于深度优先遍历,遍历过程中是顺着一条路径一直遍历到空节点然后向上回溯继续顺着遍历上一个节点的其他方向。层序遍历属于广度优先遍历,先遍历完同…...

什么是线程?为什么需要线程?和进程的区别?
目录 前言 一.线程是什么? 1.1.为什么需要线程 1.2线程的概念 1.3线程和进程的区别 二.线程的生命周期 三.认识多线程 总结 🎁个人主页:tq02的博客_CSDN博客-C语言,Java,Java数据结构领域博主 🎥 本文由 tq02 原创…...
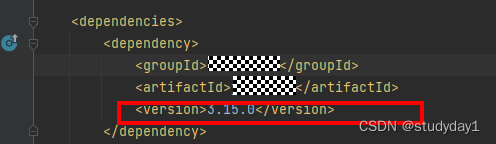
【业务功能篇61】SpringBoot项目流水线 dependencyManagement 标签整改依赖包版本漏洞问题
业务场景:当前我们项目引入了公司自研的一些公共框架组件,比如SSO单点登录jar包,文件上传服务jar包等公共组件,开发新功能,本地验证好之后,部署流水线,报出一些jar包版本的整改漏洞问题…...
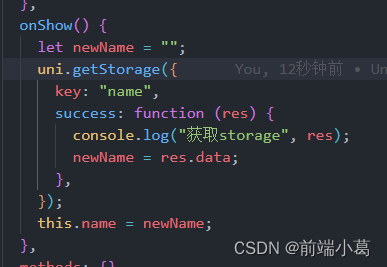
uniapp使用getStorage对属性赋值无效
1正常set(get)storage都是可以正常使用的 2.但对属性进行赋值的时候,却发现this.name并没有发生变化 3. 在里面打印this发现,在set*getStorage中并不能拿到this. 4.优化代码 这样就可以给this.name成功赋值...
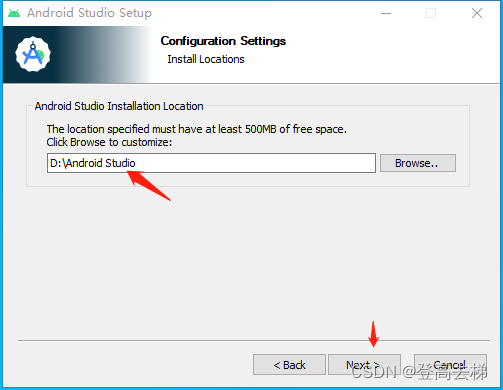
20230802-下载并安装android-studio
下载 android-studio 安装包 https://developer.android.google.cn/studio/ 安装android-studio 双击安装包 D:\Android Studio...
)
python 第九章 —— GUI界面开发(tkinter详解)
文章目录 前言一、GUI与CLI对比二、GUI原理三、tkinter基本使用1.主窗口2.控件(1)button(2)布局(3)Frame(以微信布局为例)(4)Label(5)Entry(6)Text(7)Checkbutton(8)Radiobutton(9)Listbox(10)Scrollbar(11)Canvas...

线段树合并例题
https://www.luogu.com.cn/problem/P3224 1. 永无乡 题意: 给 n 个岛屿,每个岛有一个标号,初始修有 m 条路,有两个操作,操作1 为 给两个岛屿之间修路,操作2为求出 所有能从当前岛屿到达的岛 中标号第k小的…...
Stable Diffusion 硬核生存指南:WebUI 中的 VAE
本篇文章聊聊 Stable Diffusion 生态中呼声最高、也是最复杂的开源模型管理图形界面 “stable-diffusion-webui” 中和 VAE 相关的事情。 写在前面 Stable Diffusion 生态中有一个很重要的项目,它对于 SD 生态繁荣做出的贡献可以说居功至伟,自去年八月…...
)
vue项目 前端加前缀(包括页面及静态资源)
具体步骤 Vue 中配置 (1)更改router模式,添加前缀 位置:router文件夹下面的index.js const router new Router({base: /nhtjfx/, // 路由前缀mode: history, // 采用history模式URL的路径才跟配置的对应上,不然UR…...
使用文心一言等智能工具指数级提升嵌入式/物联网(M5Atom/ESP32)和机器人操作系统(ROS1/ROS2)学习研究和开发效率
以M5AtomS3为例,博客撰写效率提升10倍以上: 0. Linux环境Arduino IDE中配置ATOM S3_zhangrelay的博客-CSDN博客 1. M5ATOMS3基础01按键_zhangrelay的博客-CSDN博客 2. M5ATOMS3基础02传感器MPU6886_zhangrelay的博客-CSDN博客 3. M5ATOMS3基础03给RO…...

【Rust 基础篇】Rust动态大小类型:理解动态大小类型与编写安全的代码
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。在Rust中,动态大小类型(DST)是一种特殊的类型,它的大小在编译时无法确定&#x…...

【Python】使用nuitka打包Python程序为EXE可执行程序
1.说明 写好的Python程序如果想要拿到其他电脑上运行,那还得安装一下Python环境和各种库,这是比较麻烦的,所以有必要把它打包成一个可执行的exe文件。可以打包exe的库有好多个,比如说pyinstaller、cx_Freeze等。 pyinstaller打包…...
背景图片及精灵图
.picture {width: 48px;height: 48px;background-image: url(../images/精灵图-侧边功能.png); }为一个有宽高的div设置了背景图片,背景图片只作用在div的content区域内,不作用在padding和border上。 知识点: 背景图使用精灵图(…...
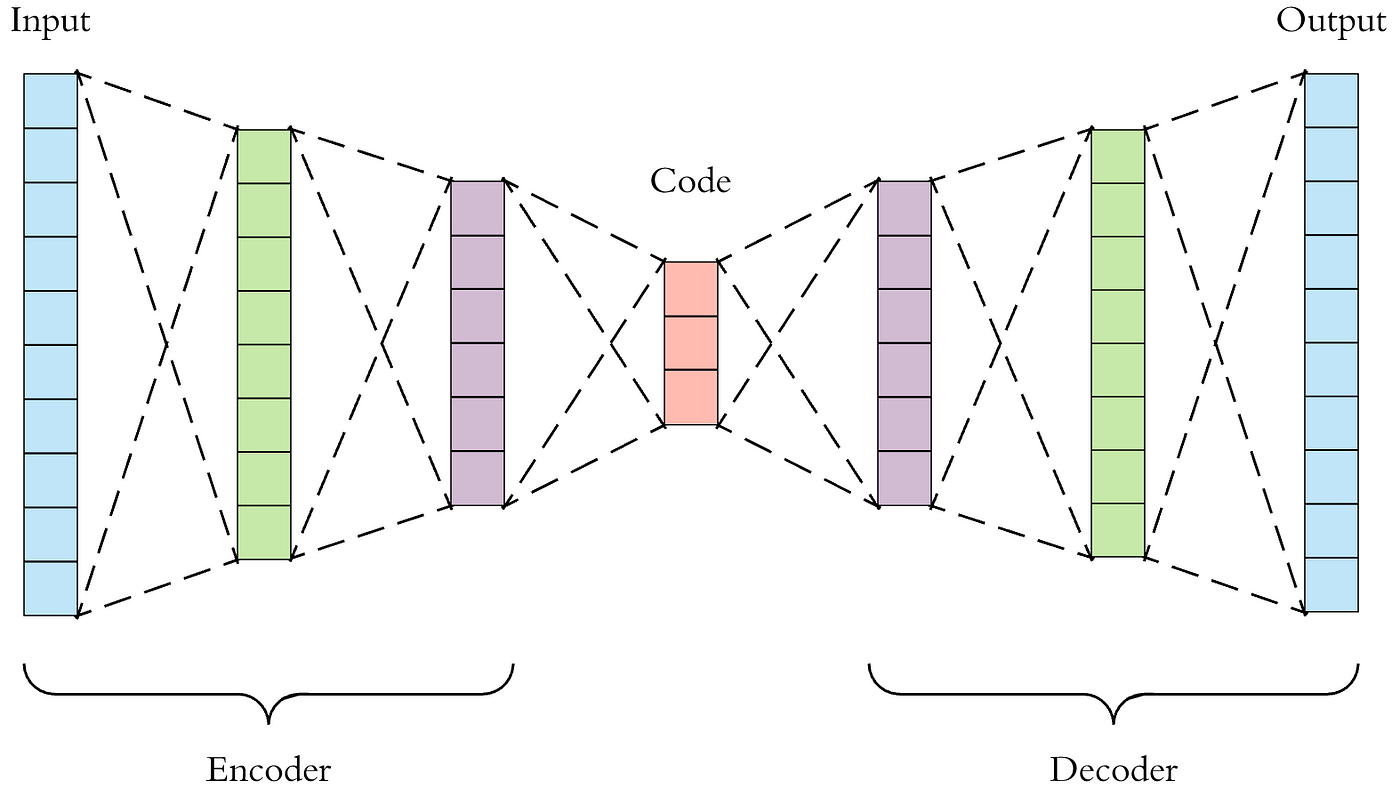
简要介绍 | 生成模型的演进:从自编码器(AE)到变分自编码器(VAE)和生成对抗网络(GAN),再到扩散模型
注1:本文系“简要介绍”系列之一,仅从概念上对生成模型(包括AE, VAE, GAN,以及扩散模型)进行非常简要的介绍,不适合用于深入和详细的了解。 生成模型的演进:从自编码器(AE)到变分自编码器(VAE)和生成对抗网络(GAN),再到扩散模型 一、背景介绍 生成模型在机器学习领域…...
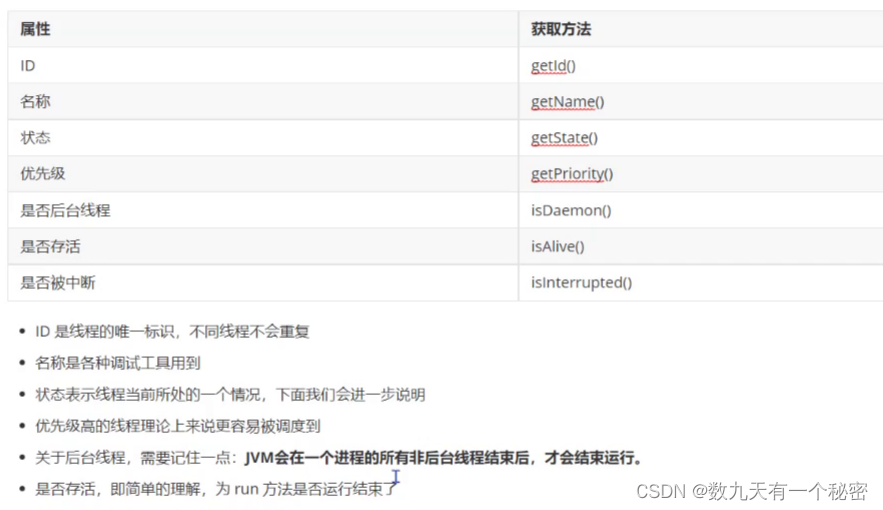
8.2Thread类的常见属性
1. 2.前台线程和后台线程 前台线程:影响进程结束(如果前台线程没有执行完,进程不结束). 后台线程(守护线程):不影响线程结束. 创建线程默认是前台线程. 修改成后台线程:thread.setDaetrue);...

博客摘录「 mvvm框架工作原理及优缺」2023年7月31日
mvvm 的核心是数据劫持、数据代理、数据编译和"发布订阅模式"。 1、数据劫持——就是给对象属性添加get,set钩子函数。 ● 1、观察对象,给对象增加 Object.defineProperty ● 2、vue的特点就是新增不存在的属性不会给该属性添加 get 、 set 钩子函数。…...
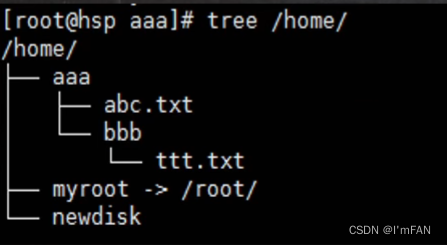
第12章 Linux 实操篇-Linux磁盘分区、挂载
12.1 Linux 分区 12.1.1 原理介绍 (1) Linux来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构, Linux中每个分区都是用来组成整个文件系统的一部分。 (2) Linux采用了一种叫“载入”的处理方法,…...

使用express搭建后端服务
目录 1 创建工程目录2 初始化3 安装express依赖4 启动服务5 访问服务总结 上一篇我们利用TDesign搭建了前端服务,现在的开发讲究一个前后端分离,后端的话需要单独搭建服务。后端服务的技术栈还挺多,有java、php、python、nodejs等。在众多的技…...
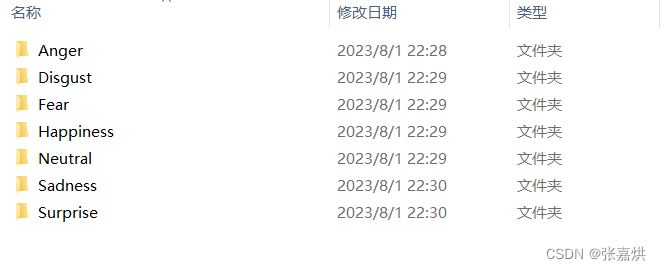
深度学习——划分自定义数据集
深度学习——划分自定义数据集 以人脸表情数据集raf_db为例,初始目录如下: 需要经过处理后返回 train_images, train_label, val_images, val_label 定义 read_split_data(root: str, val_rate: float 0.2) 方法来解决,代码如下:…...
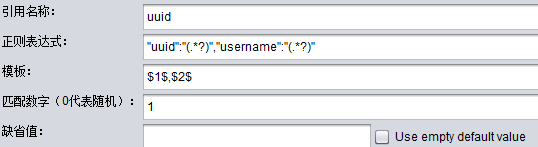
Jmeter性能测试之正则表达式提取器
目录 前言 1. Jmeter正则表达式提取器 2. 入门实例 3. 进阶实例 前言 Jmeter正则表达式提取器属于Jmeter后置处理器(post processors)的一种,用于将取样器请求到的结果以正则表达式的方式读取出来。 1. Jmeter正则表达式提取器 1. 作用…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...
)
Sora 2原生MP4输出不兼容Premiere Pro?揭秘H.264/H.265封装层4大隐性缺陷(附MediaInfo诊断模板+自动修复脚本)
更多请点击: https://codechina.net 第一章:Sora 2原生MP4输出不兼容Premiere Pro的根源定位 Sora 2生成的原生MP4文件虽符合ISO/IEC 14496-14规范,但其底层封装结构与Adobe Premiere Pro对时间码、元数据及视频流编码参数的严格校验逻辑存在…...

地理空间机器学习库全解析:从TorchGeo到Raster Vision的实战指南
1. 项目概述:为什么我们需要专门的地理空间机器学习库?如果你尝试过用标准的PyTorch或TensorFlow去处理一张卫星影像,大概率会在第一步就卡住。不是模型写不出来,而是数据根本读不进去,或者读进去了却对不上位置。一张…...

终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧
终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

如何快速配置虚拟显示器:面向初学者的完整指南
如何快速配置虚拟显示器:面向初学者的完整指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否在为游戏串流画质不佳而烦恼?或者需要为无显示器主机…...

8大网盘文件直链一键获取:LinkSwift让你的下载速度突破限速瓶颈
8大网盘文件直链一键获取:LinkSwift让你的下载速度突破限速瓶颈 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...