Stable Diffusion 硬核生存指南:WebUI 中的 VAE
本篇文章聊聊 Stable Diffusion 生态中呼声最高、也是最复杂的开源模型管理图形界面 “stable-diffusion-webui” 中和 VAE 相关的事情。
写在前面
Stable Diffusion 生态中有一个很重要的项目,它对于 SD 生态繁荣做出的贡献可以说居功至伟,自去年八月下旬推出后,至今狂揽近十万颗 Stars,足以说明社区用户对它的认同和感激,它就是 AUTOMATIC1111/stable-diffusion-webui。
目前项目中已累计收到了来自全球 465 位开源玩家的代码提交,积累了 5300+ 提交记录,项目代码库开始变的非常庞大、许多功能的设计和运行原理也变的不是那么的清晰。
在最近顺带研究 SDXL 和适配 SDXL 和 WebUI 的过程中,正好要走读代码,就从一个大家可能经常看到,但是大概率不清楚项目中调用流程和作用原理的功能开始吧。
在之前的内容中,我提起过多次 Stable Diffusion 相关的内容,如果你对它还不了解,可以自行翻阅。
VAE 相关的前置知识点
Stable Diffusion 和 VAE 涉及非常非常多有趣的知识点。
不过,这篇文章中,我不想过多展开学术相关的内容。所以,我会尽量简单的列举和 VAE 相关的,我们需要知道的内容,方便后续我们阅读代码中相关的部分和进行理解。
VAE 是什么?为什么需要它?
Stable Diffusion(稳定扩散)基于 Latent Diffusion(潜在扩展)提出,最出名的一篇论文:《High-Resolution Image Synthesis with Latent Diffusion Models》。使用的神经网络架构是基于《U-Net: Convolutional Networks for Biomedical Image Segmentation》这篇研究工作中提出的 U-Net。

简单来说是通过生成一副用户指定大小的充满随机噪声的图片(可以想象为充满雪花点的图),通过上面的算法,将噪音中的元素(蓝天、建筑物、草地)一步步的还原成我们想要的内容,并进行组装,最终成为图片(晴天广阔的草地上有一座建筑物)。
这个图片还原过程中,需要大量的重复、连续的计算,所以通常需要花费大量的时间,并且需要消耗大量的内存或显存资源。图片像素内容越丰富、图片尺寸越大,所需要的计算资源就越多、甚至非常夸张。譬如,如果不采取任何算法手段优化性能,想要生成一张 512x512 的图片,我们可能需要一台至少有 128G 显存的设备。
Latent Diffusion 有一个“多快好省”的妙用:可以通过在低维空间上进行高效的计算,来替代在真实空间对实际图片像素进行计算,减少大量的计算资源和内存资源的消耗。通俗理解,它可以对我们要生成的图像内容进行压缩和解压缩,压缩后的数据,还可以参与计算。譬如,当我们的“压缩工具”的压缩倍数是 8 的话,上面例子中,我们需要的显存资源就能够从 128G 减少到 16G 啦。
VAE 就是这个神奇的“压缩/解压缩工具”。
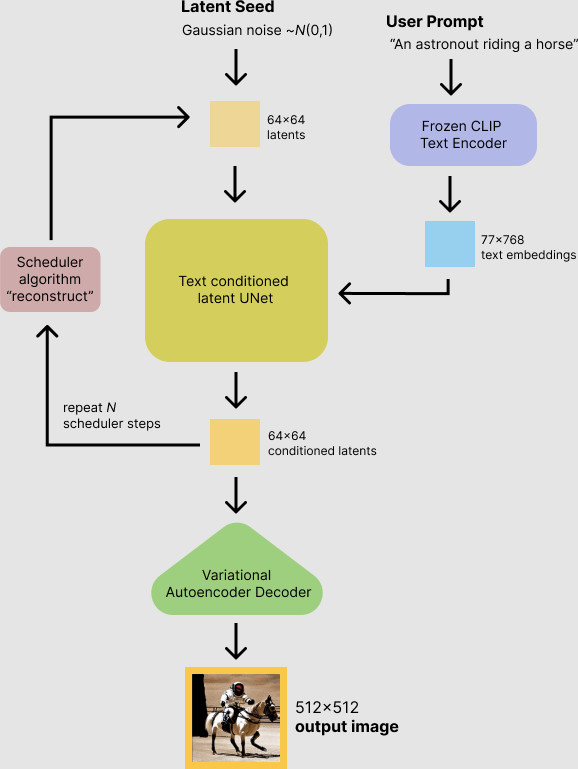
当我们想使⽤ Stable Diffusion ⽣成⼀张图⽚时(推理过程),VAE 起到的是解压缩过程,⼀ 般称之为“解码器”;当我们想将各种图⽚训练为图⽚⽣成模型时(训练过程),VAE 充当的 ⾓⾊就是编码器了,将图⽚或图⽚中的元素转换为低维空间向量表⽰,并传球给上⽂中提到的 U-Net ⽹络使⽤。
常见 VAE 模型类型
一般情况下,我们只需要重点关注 Stability AI 推出的 EMA (Exponential Moving Average)和 MSE (Mean Square Error )两个类型的 VAE 模型即可。
- stabilityai/sd-vae-ft-ema
- stabilityai/sd-vae-ft-mse
在上面的链接中有这两个模型在辅助生成图片时的效果对比。就使用经验而言,EMA 会更锐利、MSE 会更平滑。
除此之外,还有两个比较知名的 VAE 模型,主要用在动漫风格的图片生成中:
- WarriorMama777/OrangeMixs
- hakurei/waifu-diffusion-v1-4
除了上面的几种 VAE 模型之外,有一些模型会自带自己的 VAE 模型,比如最近发布的 SDXL 模型,在项目中,我们能够看到模型自己的 VAE 模型。
- stabilityai/stable-diffusion-xl-refiner-1.0/vae
- stabilityai/stable-diffusion-xl-base-1.0/vae
当然,Stability AI 也单独发布了一个名为 stabilityai/sdxl-vae 的项目,虽然项目更新时间比两个 SDXL 绘图模型晚一天,但是其中的 VAE模型的版本,却比绘图模型中内置的 VAE 模型要老一个版本,推测这里应该是一个乌龙。
此外,在一些陈旧的文章中,可能会指引你使用:
https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt
但其实,这两个项目早已被新版本模型取代,我们只需要使用前面提到的 EMA 和 MSE 仓库中的模型即可。
VAE 可以组合工作吗?
结合前文中,我们不难理解 UNET 这种接近于原始数据的内容,是比较好组合(合并)在一起进行计算的,而将 VAE 进行组合(合并)就不一定了,比如数据分别被压缩成了 rar 和 7z 格式,在解压缩的时候,我们需要分别进行这两种格式的数据处理。
VAE 的工作方式类似,如果我们需要套用多种模型,那么可选的操作是针对每一个模型应用和它“兼容”的 VAE 模型,而不能够将模型合并成一个,或者使用一个 VAE 模型“一条路走到黑”。
为什么有 VAE 可以“美颜” 的说法
在 Stable Diffusion 的世界,修复人脸主要依赖的是下面两个项目的能力:
- TencentARC/GFPGAN
- sczhou/CodeFormer
不过,前文提到的 Stability AI 推出的常用的 VAE 模型,是基于 LAION-Aesthetics和 LAION-Humans,对 CompVis/latent-diffusion 项目进行了模型微调而来的模型。而这两个数据集特别针对人对于图片的喜爱程度进行了整理,其中后者包含大量的人脸。
所以,在经过高质量的图片、大量人脸数据的训练后,VAE 模型对于改善图片色调,以及轻微修正图片中的人脸,也具备了一些能力。
好了,前置知识到此为止,已经足够我们阅读和理解代码啦。
Stable Diffusion WebUI 代码走读
VAE 的引用和定义散落在项目的许多地方,我们就主要场景进行展开。
VAE 模型和算法调用方式
WebUI 项目中涉及 VAE 定义主要有三个文件:
sd_vae.py获取存在的 VAE 模型文件列表、管理 VAE 模型的加载,文件位于:modules/sd_vae.py。
其中最重要的两个函数方法是 resolve_vae 和 reload_vae_weights。前者会将程序启动或用户手动触发 refresh_vae_list 函数后,寻找匹配绘图模型的 VAE 模型。后者,则会将匹配的模型在合适的时间点,一起装载到内存或显存中,用于图片生成计算。
sd_vae_taesd.py 使用了项目 madebyollin/taesd/ 作为 VAE 实现,核心目标是快速呈现图像,所以会损失一些质量细节,出现“捏造”数据的问题:modules/sd_vae_taesd.py。
sd_vae_approx.py 定义了核心类 VAE Approx,使用 8 个卷积层来实现图片的降噪和还原,以及 cheap_approximation,用来将潜在向量映射到 RGB 空间,这个算法参考了帖子中的做法,效率得到了巨大的提升:modules/sd_vae_approx.py。
如果我们使用的是 SDXL 模型,则会从 releases/v1.0.0-pre/ 发布页面中下载预构建模型 vaeapprox-sdxl.pt,反之则使用项目中的 model.pt 模型。
WebUI 启动,如果缺少上述模型,则会报一些因为读取不到文件出现的奇奇怪怪的问题,所以建议自行下载,提前放在项目代码要读取的位置。
VAE 模型文件查找逻辑
网上经常有人在项目开源社区或各种教程帖子中询问正确的 VAE 模型加载路径。其实这个问题很好回答,源码中查找模型路径的定义在这里:
def refresh_vae_list():
...paths = [os.path.join(sd_models.model_path, '**/*.vae.ckpt'),os.path.join(sd_models.model_path, '**/*.vae.pt'),os.path.join(sd_models.model_path, '**/*.vae.safetensors'),os.path.join(vae_path, '**/*.ckpt'),os.path.join(vae_path, '**/*.pt'),os.path.join(vae_path, '**/*.safetensors'),]if shared.cmd_opts.ckpt_dir is not None and os.path.isdir(shared.cmd_opts.ckpt_dir):paths += [os.path.join(shared.cmd_opts.ckpt_dir, '**/*.vae.ckpt'),os.path.join(shared.cmd_opts.ckpt_dir, '**/*.vae.pt'),os.path.join(shared.cmd_opts.ckpt_dir, '**/*.vae.safetensors'),]if shared.cmd_opts.vae_dir is not None and os.path.isdir(shared.cmd_opts.vae_dir):paths += [os.path.join(shared.cmd_opts.vae_dir, '**/*.ckpt'),os.path.join(shared.cmd_opts.vae_dir, '**/*.pt'),os.path.join(shared.cmd_opts.vae_dir, '**/*.safetensors'),]...for path in paths:candidates += glob.iglob(path, recursive=True)
...
程序启动后,会首先寻找 models/具体模型目录 中的 *.vae.ckpt、*.vae.pt、*.vae.safetensors 三种后缀的 VAE 模型。接着,如果我们指定了应用启动的模型目录,则会追加查找 指定模型目录 下的三种后缀的 VAE 模型。最后,会搜索 models/VAE 目录下,三种后缀的 VAE 模型。
上述所有的操作,都支持子目录查找。
我们只需要将模型文件防止在上述任一位置即可,程序都能正常加载使用。
额外需要注意的是,有的帖子会让用户随意修改 VAE 模型后缀类型,比如将 pt 修改为 safetensors,这样做是错的。
VAE 模块的调用逻辑
在modules/sd_samplers_common.py程序中,定义了四种模型的加载方式:
approximation_indexes = {"Full": 0, "Approx NN": 1, "Approx cheap": 2, "TAESD": 3}def single_sample_to_image(sample, approximation=None):if approximation is None:approximation = approximation_indexes.get(opts.show_progress_type, 0)if approximation == 2:x_sample = sd_vae_approx.cheap_approximation(sample) * 0.5 + 0.5elif approximation == 1:x_sample = sd_vae_approx.model()(sample.to(devices.device, devices.dtype).unsqueeze(0))[0].detach() * 0.5 + 0.5elif approximation == 3:x_sample = sample * 1.5x_sample = sd_vae_taesd.model()(x_sample.to(devices.device, devices.dtype).unsqueeze(0))[0].detach()else:x_sample = processing.decode_first_stage(shared.sd_model, sample.unsqueeze(0))[0] * 0.5 + 0.5x_sample = torch.clamp(x_sample, min=0.0, max=1.0)x_sample = 255. * np.moveaxis(x_sample.cpu().numpy(), 0, 2)x_sample = x_sample.astype(np.uint8)return Image.fromarray(x_sample)
调用上面函数的主要方法有两个,目标都是将采样数据转换为一张或者多张图片:
def sample_to_image(samples, index=0, approximation=None):return single_sample_to_image(samples[index], approximation)def samples_to_image_grid(samples, approximation=None):return images.image_grid([single_sample_to_image(sample, approximation) for sample in samples])
在模型处理图片的过程中的各种功能,会根据具体情况设置 approximation ,来调用不同的模型和算法,来生成图片。
全局参数定义
WebUI 项目中,和 VAE 相关最重要的参数最重要的只有一个:dtype_vae。
这个变量最初被定义在modules/devices.py:
dtype_vae = torch.float16
当程序代码跑起来之后,modules/shared.py 中会根据当前显卡支持的数据类型,自动调整数值:
devices.dtype = torch.float32 if cmd_opts.no_half else torch.float16
devices.dtype_vae = torch.float32 if cmd_opts.no_half or cmd_opts.no_half_vae else torch.float16
这个数值的改变,正常情况只能够通过命令行参数 no_half_vae 和 no_half 来改变。但也有意外,在 modules/processing.py 中:
def decode_latent_batch(model, batch, target_device=None, check_for_nans=False):
...for i in range(batch.shape[0]):sample = decode_first_stage(model, batch[i:i + 1])[0]if check_for_nans:try:devices.test_for_nans(sample, "vae")except devices.NansException as e:if devices.dtype_vae == torch.float32 or not shared.opts.auto_vae_precision:raise eerrors.print_error_explanation("A tensor with all NaNs was produced in VAE.\n""Web UI will now convert VAE into 32-bit float and retry.\n""To disable this behavior, disable the 'Automaticlly revert VAE to 32-bit floats' setting.\n""To always start with 32-bit VAE, use --no-half-vae commandline flag.")devices.dtype_vae = torch.float32model.first_stage_model.to(devices.dtype_vae)batch = batch.to(devices.dtype_vae)
...return samples
在批量处理潜在向量、检查张量,用来“还原”图片时,假如我们指定了 VAE 模型的精度不为 auto_vae_precision,且 dtype_vae 为全精度时,则强制指定 devices.dtype_vae = torch.float32 并输出错误提醒告知用户。
通过 Model 合并对 VAE 进行 “Bake”
在项目的modules/extras.py程序中,当选择将 VAE Bake 到模型内时,将会把绘图模型和 VAE 打包成一个文件:
...
bake_in_vae_filename = sd_vae.vae_dict.get(bake_in_vae, None)
if bake_in_vae_filename is not None:print(f"Baking in VAE from {bake_in_vae_filename}")shared.state.textinfo = 'Baking in VAE'vae_dict = sd_vae.load_vae_dict(bake_in_vae_filename, map_location='cpu')for key in vae_dict.keys():theta_0_key = 'first_stage_model.' + keyif theta_0_key in theta_0:theta_0[theta_0_key] = to_half(vae_dict[key], save_as_half)
...
_, extension = os.path.splitext(output_modelname)
if extension.lower() == ".safetensors":safetensors.torch.save_file(theta_0, output_modelname, metadata=metadata)
else:torch.save(theta_0, output_modelname)
性能优化,量化计算相关
项目的内置“超分插件 LDSR”中,包含了 VAE 量化相关的功能,extensions-builtin/LDSR/vqvae_quantize.py。这段代码改写自“官方项目”CompVis/taming-transformers/taming/modules/vqvae/quantize.py,但是做了大量的精简。
原始程序中,定义了四个量化计算的“工具人”,包括:
- VectorQuantizer类:对原始向量进行离散化处理,解决计算瓶颈。
- GumbelQuantize类:使用Gumbel Softmax 重参数化技巧处理向量,将原始向量转换为概率分布。
- VectorQuantizer2类:更高效的VectorQuantizer 的实现,避免使用昂贵的矩阵乘法操作。
- EmbeddingEMA类:使用 EMA(Exponential Moving Average)的方式对数据进行平滑。
新的实现中,实现了一个更精简的模块,可以在保留输入向量梯度信息的前提下,对原始向量进行高效的离散处理。
macOS 和小显存设备相关
WebUI 默认没有全局启用半精度,但是考虑到 macOS 设备资源有限,所以在默认提供的启动脚本中,尤其是针对 macOS 设备,默认添加了 --no-half-vae 启动参数。
export COMMANDLINE_ARGS="--skip-torch-cuda-test --upcast-sampling --no-half-vae --use-cpu interrogate"
所以,如果你的设备显存比较少,也可以考虑默认添加这个启动参数,来让资源有限的设备能够将模型程序跑起来。
其他
感谢在 WebUI 项目发布的同期,HuggingFace 团队发布了一篇详尽的技术博客:《Stable Diffusion with 🧨 Diffusers》。
感谢 @史业民 博士,中文 Llama2 7B 项目发起人,针对本文学术内容部分进行勘误。
最后
折腾完前两篇文章《使用 Docker 快速上手 Stability AI 的 SDXL 1.0 正式版》、《基于 Docker 的深度学习环境:Windows 篇》后,昨天尝试将 SDXL 1.0 适配到了本文中提到的 WebUI 项目。
虽然能够正常生成图片,但是感觉执行效率相比之前文章中的方法,有 20% 左右的性能下降,为了清清楚楚的使用项目,于是就有了这篇内容。
接下来有空的时候,我会继续阅读这个项目的代码,改进模型适配,期待在这个项目中,图片生成效率能够变的更高。
–EOF
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年07月30日
统计字数: 11485字
阅读时间: 23分钟阅读
本文链接: https://soulteary.com/2023/07/30/stable-diffusion-hardcore-survival-guide-vae-in-webui.html
相关文章:
Stable Diffusion 硬核生存指南:WebUI 中的 VAE
本篇文章聊聊 Stable Diffusion 生态中呼声最高、也是最复杂的开源模型管理图形界面 “stable-diffusion-webui” 中和 VAE 相关的事情。 写在前面 Stable Diffusion 生态中有一个很重要的项目,它对于 SD 生态繁荣做出的贡献可以说居功至伟,自去年八月…...
)
vue项目 前端加前缀(包括页面及静态资源)
具体步骤 Vue 中配置 (1)更改router模式,添加前缀 位置:router文件夹下面的index.js const router new Router({base: /nhtjfx/, // 路由前缀mode: history, // 采用history模式URL的路径才跟配置的对应上,不然UR…...
使用文心一言等智能工具指数级提升嵌入式/物联网(M5Atom/ESP32)和机器人操作系统(ROS1/ROS2)学习研究和开发效率
以M5AtomS3为例,博客撰写效率提升10倍以上: 0. Linux环境Arduino IDE中配置ATOM S3_zhangrelay的博客-CSDN博客 1. M5ATOMS3基础01按键_zhangrelay的博客-CSDN博客 2. M5ATOMS3基础02传感器MPU6886_zhangrelay的博客-CSDN博客 3. M5ATOMS3基础03给RO…...

【Rust 基础篇】Rust动态大小类型:理解动态大小类型与编写安全的代码
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。在Rust中,动态大小类型(DST)是一种特殊的类型,它的大小在编译时无法确定&#x…...

【Python】使用nuitka打包Python程序为EXE可执行程序
1.说明 写好的Python程序如果想要拿到其他电脑上运行,那还得安装一下Python环境和各种库,这是比较麻烦的,所以有必要把它打包成一个可执行的exe文件。可以打包exe的库有好多个,比如说pyinstaller、cx_Freeze等。 pyinstaller打包…...
背景图片及精灵图
.picture {width: 48px;height: 48px;background-image: url(../images/精灵图-侧边功能.png); }为一个有宽高的div设置了背景图片,背景图片只作用在div的content区域内,不作用在padding和border上。 知识点: 背景图使用精灵图(…...
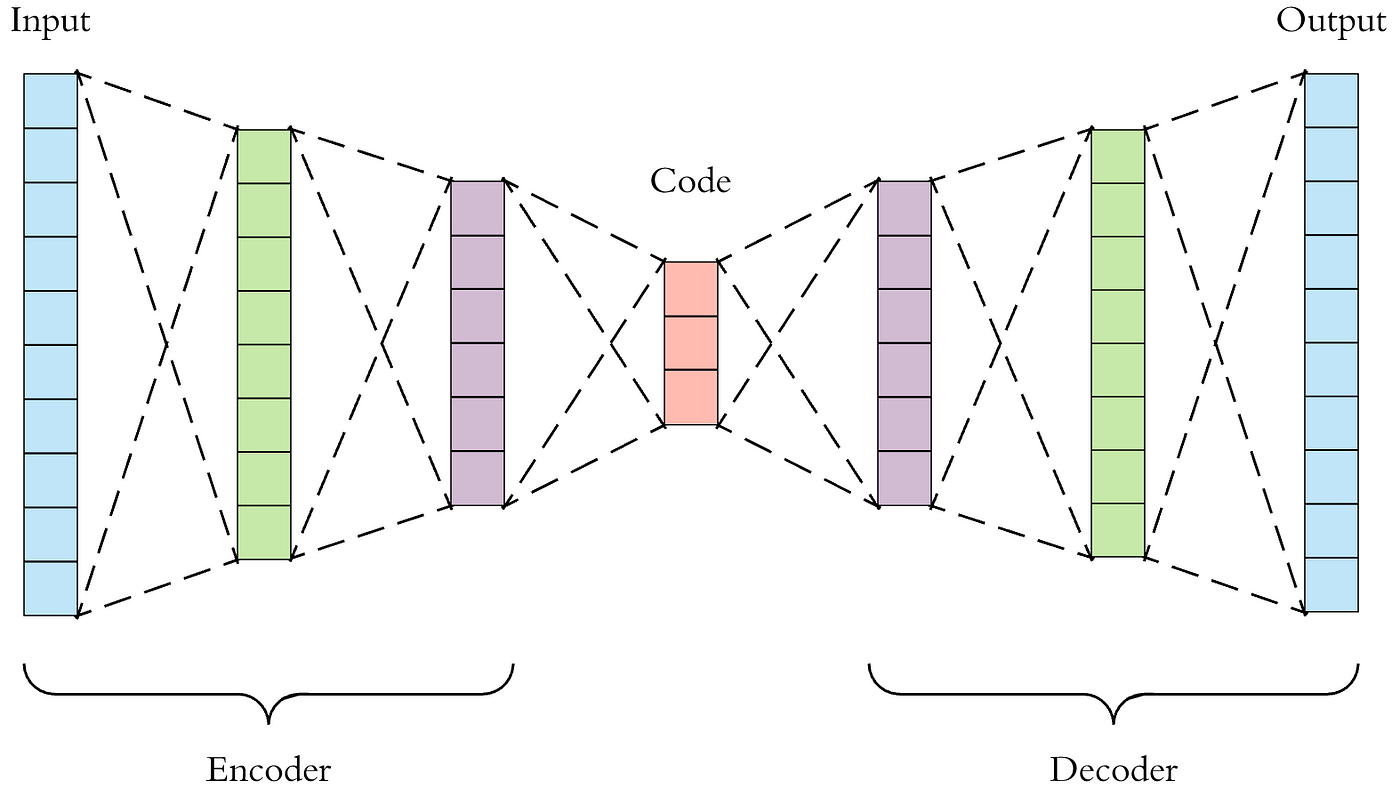
简要介绍 | 生成模型的演进:从自编码器(AE)到变分自编码器(VAE)和生成对抗网络(GAN),再到扩散模型
注1:本文系“简要介绍”系列之一,仅从概念上对生成模型(包括AE, VAE, GAN,以及扩散模型)进行非常简要的介绍,不适合用于深入和详细的了解。 生成模型的演进:从自编码器(AE)到变分自编码器(VAE)和生成对抗网络(GAN),再到扩散模型 一、背景介绍 生成模型在机器学习领域…...
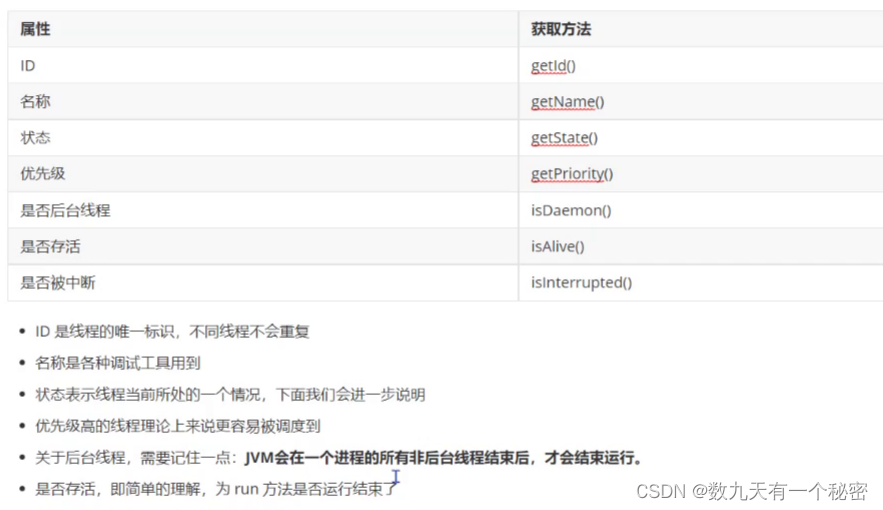
8.2Thread类的常见属性
1. 2.前台线程和后台线程 前台线程:影响进程结束(如果前台线程没有执行完,进程不结束). 后台线程(守护线程):不影响线程结束. 创建线程默认是前台线程. 修改成后台线程:thread.setDaetrue);...

博客摘录「 mvvm框架工作原理及优缺」2023年7月31日
mvvm 的核心是数据劫持、数据代理、数据编译和"发布订阅模式"。 1、数据劫持——就是给对象属性添加get,set钩子函数。 ● 1、观察对象,给对象增加 Object.defineProperty ● 2、vue的特点就是新增不存在的属性不会给该属性添加 get 、 set 钩子函数。…...
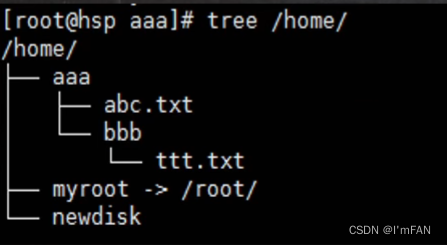
第12章 Linux 实操篇-Linux磁盘分区、挂载
12.1 Linux 分区 12.1.1 原理介绍 (1) Linux来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构, Linux中每个分区都是用来组成整个文件系统的一部分。 (2) Linux采用了一种叫“载入”的处理方法,…...

使用express搭建后端服务
目录 1 创建工程目录2 初始化3 安装express依赖4 启动服务5 访问服务总结 上一篇我们利用TDesign搭建了前端服务,现在的开发讲究一个前后端分离,后端的话需要单独搭建服务。后端服务的技术栈还挺多,有java、php、python、nodejs等。在众多的技…...
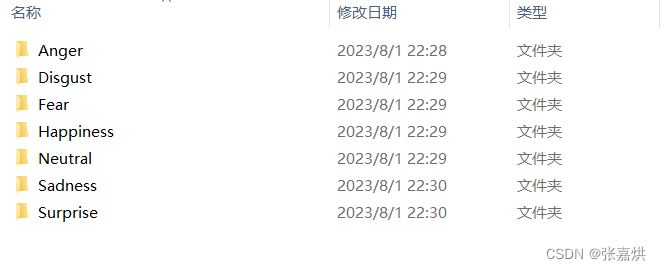
深度学习——划分自定义数据集
深度学习——划分自定义数据集 以人脸表情数据集raf_db为例,初始目录如下: 需要经过处理后返回 train_images, train_label, val_images, val_label 定义 read_split_data(root: str, val_rate: float 0.2) 方法来解决,代码如下:…...
Jmeter性能测试之正则表达式提取器
目录 前言 1. Jmeter正则表达式提取器 2. 入门实例 3. 进阶实例 前言 Jmeter正则表达式提取器属于Jmeter后置处理器(post processors)的一种,用于将取样器请求到的结果以正则表达式的方式读取出来。 1. Jmeter正则表达式提取器 1. 作用…...
)
浅谈Kubernetes中Service网络实现(服务发现)
目录 CoreDNS(Kube-DNS) Kube-proxy kube-proxy的三种实现模式 iptables模式 IPVS模式 之前的文章介绍了Kubernetes中基于service实现了集群内部的网络通信,这篇文章详细聊一下Kubernetes中的Service网络本身又是如何实现的。...

【重造轮子】golang实现可重入锁
造个可重入锁的轮子 介绍目标 正文sync.Mutexsync.Mutex介绍多协程计数器demo多协程计数器加锁 源码剖析Mutex数据结构Lock()加锁核心逻辑 UnLock() 重入锁与可重入锁魔改 sync.Mutex 参考文档 介绍 开新坑啦!! 从这篇文章开始,尝试造轮子&a…...

torch显存分析——对生成模型清除显存
torch显存分析——对生成模型清除显存 1. 问题介绍2. 应对方法 1. 问题介绍 本文主要针对生成场景下,如何方便快捷地清除当前进程占用的显存。文章的重点不止是对显存的管理,还包括怎样灵活的使用自定义组件来控制生成过程。 在之前的文章torch显存分析…...

electron+vue+ts窗口间通信
文章目录 一. 目的二.逻辑分析三. 代码示例 "types/node": "^20.3.1","vitejs/plugin-vue": "^4.1.0","vueuse/electron": "^10.2.1","electron": "^25.2.0","electron-packager":…...
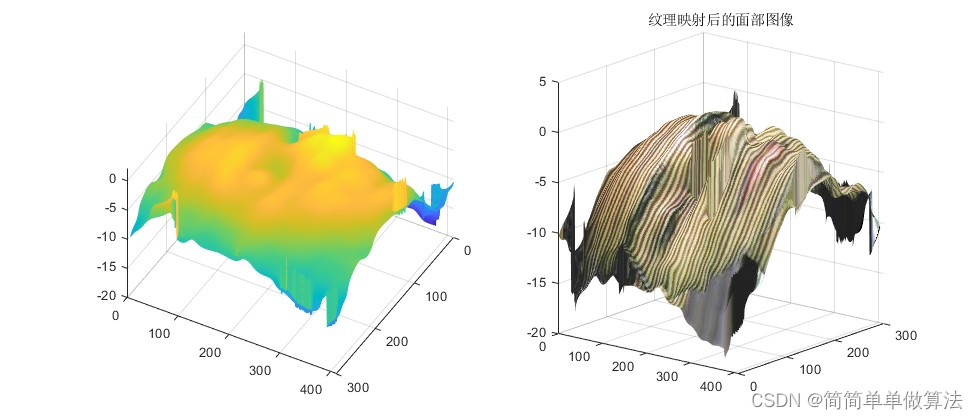
基于Fringe-Projection环形投影技术的人脸三维形状提取算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 .................................................................... figure; imshow(Im…...

如何使用Webman框架实现多语言支持和国际化功能?
如何使用Webman框架实现多语言支持和国际化功能? Webman是一款轻量级的PHP框架,提供了丰富的功能和扩展性,使得开发人员能够更加高效地开发Web应用程序。其中,多语言支持和国际化功能是Web应用程序中非常重要的一项功能ÿ…...

接受平庸,特别是程序员
目录 方向一:简述自己的感受 方向二:聊聊你想怎么做 方向三:如何调整自己的心态 虽然清楚知识需要靠时间沉淀,但在看到自己做不出来的题别人会做,自己写不出的代码别人会写时还是会感到焦虑怎么办? 你是…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...