【2.1】Java微服务:详解Hystrix
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。
🍎个人主页:Meteors.的博客
💞当前专栏: Java微服务
✨特色专栏: 知识分享
🥭本文内容:【2.1】Java微服务:详解Hystrix
📚 ** ps ** : 阅读这篇文章如果有问题或者疑惑,欢迎各位在评论区提问或指出!
----------------------------------------------------- 目录 ---------------------------------------------------------
目录
一、基本介绍
1. 基本介绍
2. 实现原理
二、相关功能
1. 请求缓存
概述
缺点
Redis的方式
1) 导入依赖
2) 添加配置文件
3) 增加Redis 配置
4)增加缓存注解
5) 接口实现类增加缓存注解
6)结果
2. 请求合并实现
1). pom文件添加依赖
2). 在实现类进行请求合并
3)开启熔断注解
4)模拟同时发起多个请求
3.线程池隔离
1)介绍
2)优点
3)缺点
4)代码示例
4. 信号量隔离
1)介绍
2)代码示例
3) 线程池颗粒与信号隔离对比
5.服务熔断
1)介绍
2)调用
其他
参考文献:
---------------------------------------------------------------------------------------------------------------------------------
一、基本介绍
1. 基本介绍
Hystix是一个延迟和容错库,旨在隔离对远程系统、服务和第三方库的访问点,停止级联故障,并在不可避免发生故障的复杂分布式系统中实现快速恢复。主要靠Spring的AOP实现
2. 实现原理
- 正常情况下,断路器关闭,服务消费者正常请求微服务
- 一段时间内,失败率达到一定阈值,断路器将断开,此时不在请求服务提供者,而只是快速失败的方法(断路方法)
- 断路器打开一段时间,自动进入“半开”状态,此时,断路器可允许一个请求方法服务提供者,如果请求调用成功,则关闭断路器,否则将保持断路器打开状态
断路器hystrix是保证了局部发生的错误,不会错扩展到整个系统, 从而保证系统 的即便出现局部问题也不会造成系统雪崩
二、相关功能
1. 请求缓存
概述
Hystirx为了降低访问服务的评率,支持将一个q8ingqiu与返回接口做缓存处理。如果再次请求的URL没有变化,nameHystrix不会请求服务,而是直接从请求中将结果放回。这样可以大大降低访问服务的压力。
缺点
- 本地缓存,集群模式下缓存无法同步
- 不支持第三方缓存容器,如Redis、MemCache
(现在一般都是使用Redis集成方案)
Redis的方式
1) 导入依赖
<!-- spring boot data redis 依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!-- commons-pool2 对象池依赖 1 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency>2) 添加配置文件
# redis缓存redis:timeout: 10000 #设置连接超时时间host: 127.0.0.1port: 6379database: 0lettuce:pool:max-active: 8 # 最大连接数,默认8max-wait: 10000 # 最大连接阻塞时间,单位毫秒,默认-1max-idle: 200 #最大空闲连接,默认8min-idle: 5 #最小空闲连接默认 03) 增加Redis 配置
package cn.itmeteors.order.config;/*** Redis 配置类*/import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.cache.RedisCacheConfiguration; import org.springframework.data.redis.cache.RedisCacheManager; import org.springframework.data.redis.cache.RedisCacheWriter; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.RedisSerializationContext; import org.springframework.data.redis.serializer.StringRedisSerializer;import java.time.Duration;@Configuration public class RedisConfig {// 重写 RedisTemplate 序列化@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> template = new RedisTemplate<>();// 为 String 类型 key 设置序列化器template.setKeySerializer(new StringRedisSerializer());// 为 String 类型 value 设置序列化器template.setValueSerializer(new GenericJackson2JsonRedisSerializer());// 为 Hash 类型 key 设置序列化器template.setHashKeySerializer(new StringRedisSerializer());// 为 Hash 类型 value 设置序列化器template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());template.setConnectionFactory(redisConnectionFactory);return template;}// 重写 Cache 序列化@Beanpublic RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisTemplate.getConnectionFactory());RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()// 设置默认过期时间 30 min.entryTtl(Duration.ofMinutes(30))// 设置 key 和 value 的序列化.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisTemplate.getKeySerializer())).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisTemplate.getValueSerializer()));return new RedisCacheManager (redisCacheWriter, redisCacheConfiguration);}}4)增加缓存注解
5) 接口实现类增加缓存注解
@Cacheable(cacheNames = "orderService:order:select")public Order selectOrderById(Long orderId) { // 调用list// 1.查询订单Order order = orderMapper.findById(orderId);// 2.利用RestTemplate发起http请求,查询用户// 2.1.url路径String url = "http://userservice/user/list";// 2.2.发送http请求,实现远程调用List<User> userList = restTemplate.getForObject(url, List.class);assert userList != null;order.setUser(userList);return order;}6)结果


2. 请求合并实现
1). pom文件添加依赖
<!-- spring-cloud netflix hystrix 依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency>2). 在实现类进行请求合并
3)开启熔断注解
@EnableCaching // 开启熔断器注解 2 选 1,@EnableHystrix 封装了 @EnableCircuitBreaker // @EnableHystrix @EnableCircuitBreaker @EnableFeignClients(clients = UserClient.class,defaultConfiguration = DefaultFeignConfiguration.class) public class OrderApplication {4)模拟同时发起多个请求
public Order queryOrderById(Long orderId) {// 1.查询订单Order order = orderMapper.findById(orderId);// 2.利用RestTemplate发起http请求,查询用户// 2.1.url路径String url = "http://userservice/user/1";String url2 = "http://userservice/user/2";String url3 = "http://userservice/user/3";String url4 = "http://userservice/user/4";String url5 = "http://userservice/user/5";// 2.2.发送http请求,实现远程调用Future<User> user = (Future<User>) restTemplate.getForObject(url, User.class);Future<User> user2 = (Future<User>) restTemplate.getForObject(url2, User.class);Future<User> user3 = (Future<User>) restTemplate.getForObject(url3, User.class);Future<User> user4 = (Future<User>) restTemplate.getForObject(url4, User.class);Future<User> user5 = (Future<User>) restTemplate.getForObject(url5, User.class);// 3.封装user到OrderList<User> userList = new ArrayList<>(1);try {userList.add(user.get());userList.add(user2.get());userList.add(user3.get());userList.add(user4.get());userList.add(user5.get());} catch (InterruptedException e) {throw new RuntimeException(e);} catch (ExecutionException e) {throw new RuntimeException(e);}order.setUser(userList);// 4.返回return order;}

3.线程池隔离
1)介绍
对调用的接口进行隔离,一个接口因为并发过高瘫痪时,掉用的另一个接口不会瘫痪
2)优点
使用线程池隔离可以安全「隔离依赖的服务」,减少所依赖服务发生故障时的影响面。比如 A 服务发生异常,导致请求大量超时,对应的线程池被打满,这时并不影响 C、D 服务的调用。
当失败的服务再次变得可用时,线程池将清理并立即恢复,而不需要一个长时间的恢复。
独立的线程池「提高了并发性」。
3)缺点
请求在线程池中执行,肯定会带来任务调度、排队和上下文切换带来的 CPU 开销。
因为涉及到跨线程,那么就存在 ThreadLocal 数据的传递问题,比如在主线程初始化的 ThreadLocal 变量,在线程池线程中无法获取。
4)代码示例
// 声明需要服务容错的方法// 线程池隔离@HystrixCommand(groupKey = "order-userService-listPool",// 服务名称,相同名称使用同一个线程池commandKey = "getList",// 接口名称,默认为方法名threadPoolKey = "order-userService-listPool",// 线程池名称,相同名称使用同一个线程池commandProperties = {// 超时时间,默认 1000ms@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "5000")},threadPoolProperties = {// 线程池大小@HystrixProperty(name = "coreSize", value = "6"),// 队列等待阈值(最大队列长度,默认 -1)@HystrixProperty(name = "maxQueueSize", value = "100"),// 线程存活时间,默认 1min@HystrixProperty(name = "keepAliveTimeMinutes", value = "2"),// 超出队列等待阈值执行拒绝策略@HystrixProperty(name = "queueSizeRejectionThreshold", value = "100")}, fallbackMethod = "selectUserListFallback")public List<User> getList() {return userMapper.getAll();}// 托底数据private List<User> selectUserListFallback() {System.out.println("-----获得托底数据-----");return Arrays.asList(new User(1L, "A", "地点1"),new User(2L, "B", "地点2"),new User(3L, "C", "地点3"));}
4. 信号量隔离
1)介绍
每次调用线程,当前请求通过计数信号量进行限制,当信号量大于了最大请求数
maxConcurrentRequests时,进行限制,调用fallback接口快速返回。信号量的调用是同步的,也就是说,每次调用都得阻塞调用方的线程,直到结果返回。这样就导致了无法对访问做超时(只能依靠调用协议超时,无法主动释放)2)代码示例
// 声明需要服务容错的方法// 信号量隔离@HystrixCommand(commandProperties = {// 超时时间,默认 1000ms@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "5000"),// 信号量隔离@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY,value = "SEMAPHORE"),// 信号量最大并发,调小一些方便模拟高并发@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS,value = "6")}, fallbackMethod = "selectUserListFallback")public List<User> getList() {return userMapper.getAll();}// 托底数据private List<User> selectUserListFallback() {System.out.println("-----获得托底数据-----");return Arrays.asList(new User(1L, "A", "地点1"),new User(2L, "B", "地点2"),new User(3L, "C", "地点3"));}3) 线程池颗粒与信号隔离对比
隔离方式 是否支持超时 是否支持熔断 隔离原理 是否是异步调用 资源消耗 线程池隔离 支持 支持 每个服务单独用线程池 支持同步或异步 大 信号量隔离 不支持 支持 通过信号量的计数器 同步调用,不支持异步 小
5.服务熔断
1)介绍
服务熔断是一种机制,用于在出现服务故障、超时或异常情况时,阻止请求继续发送到故障的服务上。当达到一定的失败阈值时,熔断器会打开,后续的请求将被快速失败,而不再去调用故障的服务。当故障情况得到修复后,熔断器会尝试关闭,恢复对服务的正常调用。
2)调用
在上面的代码执行fallbackMethod就会执行服务熔断
其他
除了上述功能,Hystrix还有实时监控、指标收集、恢复等功能,这里会留到后面的时候进行更新,大家如果现在要学习的话,可以从官网或其它地方得到相关的介绍和代码
参考文献:
GitHub - Netflix/Hystrix: Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable. - GitHub - Netflix/Hystrix: Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.
https://github.com/Netflix/Hystrix
最后,
后续文章会陆续更新,希望文章对你有所帮助..!
相关文章:
【2.1】Java微服务:详解Hystrix
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。 🍎个人主页:Meteors.的博客 💞当前专栏: Java微服务 ✨特色专栏: 知识分享 &am…...
Apache2.4源码安装与配置
环境准备 openssl-devel pcre-devel expat-devel libtool gcc libxml2-devel 这些包要提前安装,否则httpd编译安装时候会报错 下载源码、解压缩、软连接 1、wget下载[rootnode01 ~]# wget https://downloads.apache.org/httpd/httpd-2.4.57.tar.gz --2023-07-20 …...
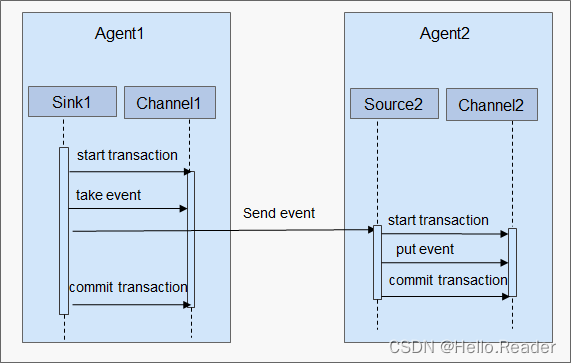
Flume原理剖析
一、介绍 Flume是一个高可用、高可靠,分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制&…...
)
【leetcode】202. 快乐数(easy)
编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果这个过程 结果为 1,…...
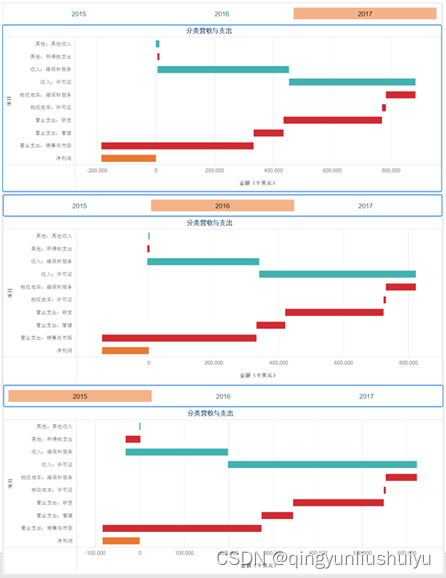
如何用瀑布图分析公司年报
原创: MicroStrategy微策略中国 , Jiping Sun 微策略企业级数据分析与移动应用9月21日2018年 摘要:利用达析报告开箱即用的瀑布图来展示各个度量值如何增加或减少。下载MicroStrategy Desktop 10.11以上版本,自己动手创建瀑布图。 瀑布图是由…...
Asynq: 基于Redis实现的Go生态分布式任务队列和异步处理库
Asynq[1]是一个Go实现的分布式任务队列和异步处理库,基于redis,类似Ruby的sidekiq[2]和Python的celery[3]。Go生态类似的还有machinery[4]和goworker 同时提供一个WebUI asynqmon[5],可以源码形式安装或使用Docker image, 还可以和Prometheus…...

保证率计算公式 正态分布
在正态分布中,如果我们要计算一个给定区间内的保证率,可以使用下面的计算公式: 找到给定保证率对应的标准正态分布的z值。可以使用标准正态分布表或计算器进行查询。例如,对于95%的保证率,对应的z值为1.96。 使用z值和…...
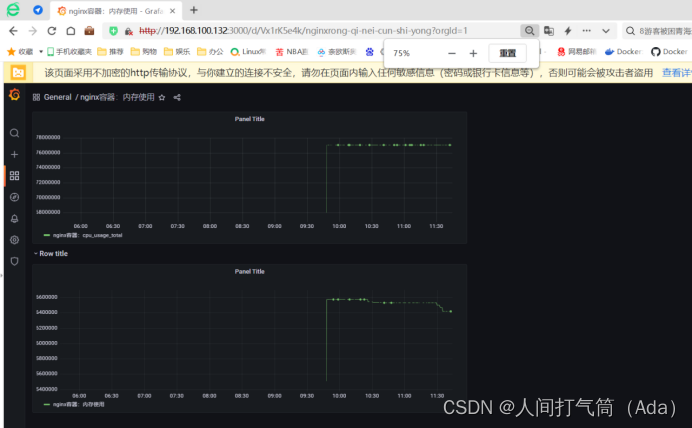
docker容器监控:Cadvisor+InfluxDB+Grafana的安装部署
目录 CadvisorInfluxDBGrafan安装部署 1、安装docker-ce 2、阿里云镜像加速器 3、下载组件镜像 4、创建自定义网络 5、创建influxdb容器 6、创建Cadvisor 容器 7、查看Cadvisor 容器: (1)准备测试镜像 (2)通…...

论文讲解——TPU-MLIR: A Compiler For TPU Using MLIR
论文讲解——TPU-MLIR: A Compiler For TPU Using MLIR https://arxiv.org/pdf/2210.15016.pdf概览模型转换TranslationCanonicalizeLoweringLayerGroup BufferizationCalibration QuantizationCorrectness Check相关资料 https://arxiv.org/pdf/2210.15016.pdf 本文将对TPU…...
基于最新导则下生态环评报告编制技术暨报告篇、制图篇、指数篇、综合应用篇系统性实践技能提升
查看原文>>>基于最新导则下生态环评报告编制技术暨报告篇、制图篇、指数篇、综合应用篇系统性实践技能提升 目录 专题一、生态环评报告编制规范 专题二、土地利用图 专题三、植被类型及植被覆盖度图 专题四、物种适宜生境分布图 专题五、生物多样性测定 专题六…...

NGZORRO:动态表单/模型驱动 的相关问题
官网的demo的[nzFor]"control.controlInstance",似乎是靠[formControlName]"control.controlInstance"来关联的。 <form nz-form [formGroup]"validateForm" (ngSubmit)"submitForm()"><nz-form-item *ngFor&quo…...

第十七次CCF计算机软件能力认证
第一题:小明种苹果 n , m map(int , input().split()) t , k , p 0 , 0 , -1 for _ in range(n):l list(map(int , input().split()))t sum(l)x -sum(l[i] for i in range(1 , len(l)))if x > p:p xk _ 1 print(t , k , p) 第二题:小明种苹…...

ApplicationContext在Spring Boot中是如何创建的?
一、ApplicationContext在Spring Boot中是如何创建的? 1. SpringApplication ApplicationContextFactory有三个实现类,分别是AnnotationConfigReactiveWebServerApplicationContext.Factory、AnnotationConfigServletWebServerApplicationContext.Facto…...
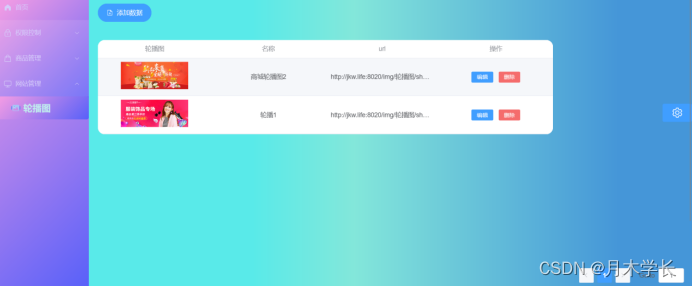
后端开发7.轮播图模块【mongdb开发】
概述 轮播图模块数据库采用mongdb开发 效果图 数据库设计 创建数据库 use sc; 添加数据 db.banner.insertMany([ {bannerId:"1",bannerName:"商城轮播图1",bannerUrl:"http://xx:8020/img/轮播图/shop1.png"}, {bannerId:"2"…...

Linux常用命令(一):创建文件目录
一、touch: 1、作用: 1). 改变已有文件的时间戳属性,修改文件时间戳时,用户必须的文件的属主,或者拥有写文件的权限 2). 创建新的空文件 2、语法: touch [option] 文件名 ,后面可跟多个文件名3、示例 …...

如何创建一个Vue组件?如何在父组件和子组件之间传递数据?如何在子组件中向父组件发送消息?
1、如何创建一个Vue组件? 要创建一个Vue组件,可以按照以下步骤进行: 安装Vue CLI(如果还没有安装): npm install -g vue/cli创建一个新的Vue组件: vue create my-component在 src/component…...
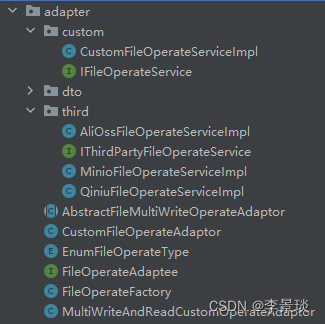
设计模式之适配器模式
一、概述 将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 二、适用性 1.你想使用一个已经存在的类,而它的接口不符合你的需求。 2.你想创建一个可以复用的类,该类可以与其他不…...
)
让ChatGPT介绍一下ChatGPT(ChatGPT的自我介绍)
ChatGPT是这样介绍自己的: ChatGPT是由OpenAI开发的一种基于大规模预训练的语言模型。它是建立在GPT(Generative Pre-trained Transformer)架构的基础上,经过大量的数据训练而成。 ChatGPT旨在通过对话与用户进行交互࿰…...

CentOS 7 构建 LVS-DR 群集
一、LVS-DR集群摘要 LVS(Linux Virtual Server)是一个用于构建可扩展和高可用性的负载均衡集群的软件。它基于Linux操作系统,并提供了一种将网络流量分发到多个后端服务器的机制。 二、基本工作原理 配置负载均衡器:在LVS集群中…...

MySQL8.0.33二进制包安装与部署
官方文档 https://downloads.mysql.com/archives/community/https://dev.mysql.com/doc/refman/8.1/en/binary-installation.html官方文档操作步骤 # Preconfiguration setup $> groupadd mysql $> useradd -r -g mysql -s /bin/false mysql # Beginning of source-build…...

AI大模型岗位全解析:小白也能入行的收藏指南!
本文全面解析AI大模型行业岗位,涵盖核心技术岗(高薪、高壁垒)、工程与平台岗(落地关键、需求大)、产品与应用岗(懂业务、好入行)以及入门与服务岗(零基础友好)。详细介绍…...

万字拆解 LLM 运行机制:Token、上下文与采样参数影
springboot自动配置 自动配置了大量组件,配置信息可以在application.properties文件中修改。 当添加了特定的Starter POM后,springboot会根据类路径上的jar包来自动配置bean(比如:springboot发现类路径上的MyBatis相关类ÿ…...
)
C99新特性:变长数组(VLA)
文章目录C99新特性:变长数组(VLA) 🚀什么是变长数组? 🤔为什么需要变长数组? 💡VLA的基本语法和用法 📝在函数内部使用VLAVLA作为函数参数多维VLAVLA的工作原理和内存分配…...

LeetCode刷题实战:从Hot100到代码随想录的进阶之路
LeetCode刷题实战:从Hot100到代码随想录的进阶之路 在技术面试的战场上,算法题就像是一道道必须攻克的堡垒。无论是硅谷的科技巨头还是国内的互联网大厂,算法能力始终是衡量工程师基本功的重要标尺。对于准备秋招或技术面试的开发者来说&…...

从Prompt CI到Agent CD:2026奇点大会披露的4层AI原生交付架构图,已获CNCF官方收录为参考模型
第一章:2026奇点智能技术大会:AI原生持续交付 2026奇点智能技术大会(https://ml-summit.org) AI原生持续交付(AI-Native Continuous Delivery)正重新定义软件工程的生命周期边界——它不再仅关注代码构建与部署,而是将…...

别再只盯着复现了!从CVE-2022-10270看企业内网向日葵客户端的隐形风险与排查指南
企业内网向日葵客户端隐形风险排查实战手册 向日葵远程控制软件在企业内网中的广泛使用,为IT运维带来了便利,同时也埋下了安全隐患。2022年曝光的CVE-2022-10270漏洞让企业安全团队意识到,仅依靠终端用户自主更新远远不够。本文将系统性地介绍…...
)
Anaconda Navigator打不开?三步搞定‘str‘ object has no attribute ‘get‘报错(附详细文件修改指南)
Anaconda Navigator启动报错深度修复指南:从原理到实战 当你满心期待地双击Anaconda Navigator图标,准备开始一天的数据分析工作,却迎面撞上"str object has no attribute get"这个晦涩的错误提示——这种挫败感我太熟悉了。作为P…...
32天GPU测试从入门到精通-图像分类模型性能对比day13)
(十五)32天GPU测试从入门到精通-图像分类模型性能对比day13
目录 引言主流图像分类模型模型架构对比精度 - 速度权衡不同 GPU 型号性能对比选型建议实战:模型对比 Benchmark总结与建议 引言 在实际 AI 项目中,选择合适的模型往往比优化单个模型更重要。不同的图像分类模型在精度、速度、资源消耗上有显著差异。 …...

Midscene Chrome扩展:如何用AI快速实现零代码浏览器自动化?
Midscene Chrome扩展:如何用AI快速实现零代码浏览器自动化? 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 还在为重复的浏览器操作而烦恼…...

【R 4.5地理空间分析终极指南】:20年GIS专家亲授——仅限新版sf+terra+stars生态的7大实战跃迁路径
第一章:R 4.5地理空间分析新范式与生态演进全景R 4.5 版本标志着地理空间分析从“数据可视化辅助”迈向“原生空间计算范式”的关键跃迁。核心变化体现在对 sf(simple features)标准的深度内化、对 PROJ 9 坐标参考系统(CRS&#…...