目标检测常用的数据集格式
在目标检测领域,有三种常用的数据集:
| 数据集 | 标注文件格式 | bbox格式 |
|---|---|---|
| voc | xml | xmin, ymin, xmax, ymax: bbox左上角(xmin, ymin)和右下角(xmax, ymax)的坐标 |
| coco | json | x, y, w, h: bbox左上角坐标(x, y)以及宽(w)和高(h) |
| yolo | txt | xcenter, ycenter, w, h: bbox的中心x坐标(xcenter)、y坐标(ycenter)以及宽度(w)和高度(h) xcenter, w相对图片实际宽度W做了归一化,即:xcenter/W, w/W ycenter, h相对图片图片高度H做了归一化,即:ycenter/H, h/H |
1. voc格式
1.1 文件结构
该文件结构指的是从 voc 官网下载的数据的文件结构(不同年份的数据集略有不同,但结构大致相同)。
VOCdevkit # 根目录
- VOCXXXX # 不同年份的数据集,目前有 2005 年到 2012 年的
- Annotations # 存放 xml 格式的标注文件,与 JPEGImages 下的图片一一对应,每个 xml 文件都描述一张图片的信息
- ImageSets # 存放的是 txt 文件,文件中每一行包含一张图片的名称以及 ±1 表示正负样本
- Layout # 可用于检测人体部位的数据(train.txt 用于训练的图片、trainval.txt用于训练和验证的图片合集、val.txt 用于验证的图片,下同)
- Main # 可用于目标检测的数据
- Segmentation # 可用于图像分割的数据
- JPEGImages # 存放图片
- SegmentationClass # 存放按照类别分割的图片,可用于语义分割
- SegmentationObject # 存放按照个体分割的图片,可用于实例分割
1.2 标注文件
voc格式的数据集使用 xml 文件标注图片及其bbox信息,一张图片对应个xml文件,以 Main 中其中一个xml文件的部分内容为例:
<annotation><folder>VOC2007</folder> <!--图片所在文件夹(实际用不到)--><filename>000005.jpg</filename> <!--图片文件名--><source> <!--图片来源--><database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image><flickrid>325991873</flickrid></source><owner> <!--图片拥有者--><flickrid>archintent louisville</flickrid><name>?</name></owner><size> <!--图片宽度、高度、通道数量--><width>500</width><height>375</height><depth>3</depth></size><segmented>0</segmented> <!--是否用于分割--><object> <!--标注目标1--><name>chair</name> <!--物体类别--><pose>Rear</pose> <!--拍摄角度: front, rear, left, right, unspecified--><truncated>0</truncated> <!--目标是否被截断--><difficult>0</difficult> <!--检测难易程度--><bndbox> <!--标注目标1的 bbox--><xmin>263</xmin><ymin>211</ymin><xmax>324</xmax><ymax>339</ymax></bndbox></object><object> <!--标注目标2的 bbox--><name>chair</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>165</xmin><ymin>264</ymin><xmax>253</xmax><ymax>372</ymax></bndbox></object><!--其余标注信息结构同上-->
</annotation>
2. coco格式
2.1 文件结构
该文件结构指的是从 coco 官网下载的数据的文件结构。
- annotations_XXXX # 存放 json 格式的标注文件,一个 json 文件里面包含了多张图片的相关信息
- annotations
- caption_xxxx.json # 存储图像标注用于描述图像
- instances_xxxx.json # 用于目标检测的标注信息
- person_keypoints_xxxx.json # 目标上的关键点信息
- trainXXX # 存放训练集图片
- valXXXX # 存放验证集图片
2.2 标注文件
coco格式的数据集使用 json 文件标注图片及其 bbox 信息,与voc格式一张图片对应一个xml文件不同,coco格式中一个 json 文件里面存放了若干张图片的信息。以 instances_xxxx.json 中的部分内容为例:
{"info": { #数据集描述信息"description": "COCO 2017 Dataset", # 数据集描述"url": "http://cocodataset.org", # 数据集地址"version": "1.0", # 数据集版本"year": 2017, # 数据集年份"contributor": "COCO Consortium", # 数据集提供者"date_created": "2017/09/01" # 数据集创建日期},"licenses": [ # 许可协议{"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/", # 协议链接"id": 1, # 协议 id ,下面将会用到"name": "Attribution-NonCommercial-ShareAlike License" # 协议名称}# 其他许可协议格式同上],"images": [ # 图片信息{"license": 4, # 使用的许可协议"file_name": "000000397133.jpg", # 图片文件名"coco_url": "http://images.cocodataset.org/val2017/000000397133.jpg", # 图片在 coco 上的url"height": 427, # 图片高度"width": 640, # 图片宽度"date_captured": "2013-11-14 17:02:52", # 图片获取日期"flickr_url": "http://farm7.staticflickr.com/6116/6255196340_da26cf2c9e_z.jpg", 图片在 flickr 上的url"id": 397133 # 图片 id}# 其他图片信息格式同上],"annotations": [ # 标注信息{"segmentation": [ # 实例分割时的边界点坐标[x1, y1, x2, y2 …… xn, yn][510.66,423.01,……,510.45,423.01]],"area": 702.1057499999998, # 区域面积"iscrowd": 0, # 目标是否被遮盖"image_id": 289343, # 标注所在的图片的 id 编号(与上面 images 中的对应)"bbox": [ # bbox框 [左上角x, 左上角y, 宽度, 高度]473.07,395.93,38.65,28.67],"category_id": 18, # 被标注物体对应的类别 id 编号(与下面 categories 中的对应)"id": 1768 # 该标注的 id 编号(唯一)}# 其他标注信息格式同上],"categories": [ # 类别描述{"supercategory": "person", # 该类别所属的大类"id": 1, # 类别 id 编号"name": "person" # 类别名字}# 其他标注信息格式同上]
}
3. yolo格式
3.1 文件结构
使用yolo时,默认的文件结构如下(不同数据集会略有不同,但结构大致相同):
XXXX # 根目录,视使用的数据集决定
- images # 存放图片,已划分为训练集、验证集、测试集(部分数据集无测试集)
- train
- val
- test
- labels # 存放的是 txt 文件,每个txt文件对应一张图片,文件中每一行包含一个bbox的相关信息
- train
- val
- test
3.2 标注文件
yolo格式的数据集使用 txt 文件标注图片bbox信息,一张图片对应一个txt文件,txt文件中的每一行都标注了一个bbox的相关信息。标注格式如下:
<类别索引> <bbox的中心x坐标> <bbox的中心y坐标> <bbox的宽度> <bbox的高度>
- 信息之间以空格分割
- bbox的中心xy坐标以及宽度、高度都相对于图片的实际宽度W和高度H做了归一化
以其中一个txt文件的部分内容为例:
45 0.479492 0.688771 0.955609 0.5955
# 标注目标1的 bbox的类别索引是45,中心x坐标是0.479492, 中心y坐标是0.688771, 宽度是0.955609, 高度是0.5955
45 0.736516 0.247188 0.498875 0.476417
# 标注目标2的 bbox
# 其余标注信息结构同上
相关文章:

目标检测常用的数据集格式
在目标检测领域,有三种常用的数据集: 数据集标注文件格式bbox格式vocxmlxmin, ymin, xmax, ymax:bbox左上角(xmin, ymin)和右下角(xmax, ymax)的坐标cocojsonx, y, w, h:bbox左上角坐标(x, y)以及宽(w)和高(h)yolotxtxcenter, ycenter, w, h:bbox的中心…...

chrome插件开发实例03-使用 chrome.storage API永久保存数据
目录 防止数据丢失 使用chrome.storage API 功能 功能演示 源代码 manifest.json popup.html...
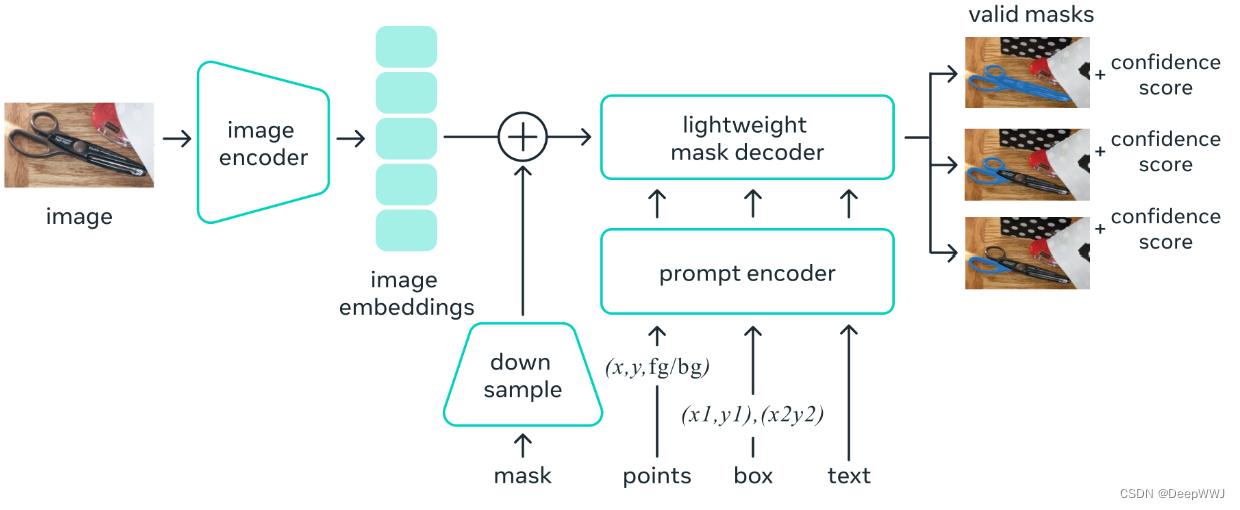
Segment Anything(SAM) 计算过程
给定输入图像 I ∈ R 3 H W I \in R^{3 \times H \times W} I∈R3HW。给定需要的prompts: M ∈ R 1 H W M \in R^{1 \times H \times W} M∈R1HW,代表图片的前背景信息。 P ∈ R N 2 P \in R^{N \times 2} P∈RN2,其中 N N N 是点的个数…...

Nacos配置文件读取源码解析
Nacos配置文件读取 本篇文章是探究,springboot启动时nacos是如何将配置中心的配置读取到springboot环境中的 PropertySourceLocator org.springframework.cloud.bootstrap.config.PropertySourceLocator 是 springcloud 定义的一个顶级接口,用来定义所…...

Linux0.11内核源码解析-fcntl.c/iotcl.c/stat.c
fcntl fcntl.c实现了文件控制系统调用fcntl和两个文件句柄描述符的复制系统调用dup()和dup2()。 dup返回当前值最小的未用句柄,dup2返回指定新句柄的数值,句柄的复制操作主要用在文件的标准输入、输出重定向和管道方面。 dupfd 复制文件句柄ÿ…...

OpenStack简介
OpenStack简介 目录 OpenStack简介 1、云计算模式2、云计算 虚拟化 openstack之间的关系?3、OpenStack 中有哪些组件?4、计算节点负责虚拟机运行5、网络节点负责对外网络与内网之间的通信 5.1 网络节点仅包含Neutron服务5.2 网络节点包含三个网络端口6、…...
二分法的应用
文章目录 什么是二分法🎮二分查找的优先级二分查找的步骤💥图解演示🧩 代码演示🫕python程序实现🐈⬛C程序实现🐕🦺C程序实现🐯Java程序实现🐳 非常规类二分查找&…...

ChatGPT在大规模数据处理和信息管理中的应用如何?
ChatGPT作为一种强大的自然语言处理模型,在大规模数据处理和信息管理领域有着广泛的应用潜力。它可以利用其文本生成、文本理解和问答等能力,为数据分析、信息提取、知识管理等任务提供智能化的解决方案。以下将详细介绍ChatGPT在大规模数据处理和信息管…...
【算法篇C++实现】五大常规算法
文章目录 🚀一、分治法⛳(一)算法思想⛳(二)相关代码 🚀二、动态规划算法⛳(一)算法思想⛳(二)相关代码 🚀三、回溯算法⛳(一…...

MySQL和钉钉单据接口对接
MySQL和钉钉单据接口对接 数据源系统:钉钉 钉钉(DingTalk)是阿里巴巴集团打造的企业级智能移动办公平台,是数字经济时代的企业组织协同办公和应用开发平台。钉钉将IM即时沟通、钉钉文档、钉闪会、钉盘、Teambition、OA审批、智能人事、钉工牌…...

layui的基本使用-日期控件的业务场景使用入门实战案例一
效果镇楼; 1 前端UI层面; <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport&…...

【2.1】Java微服务:详解Hystrix
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。 🍎个人主页:Meteors.的博客 💞当前专栏: Java微服务 ✨特色专栏: 知识分享 &am…...
Apache2.4源码安装与配置
环境准备 openssl-devel pcre-devel expat-devel libtool gcc libxml2-devel 这些包要提前安装,否则httpd编译安装时候会报错 下载源码、解压缩、软连接 1、wget下载[rootnode01 ~]# wget https://downloads.apache.org/httpd/httpd-2.4.57.tar.gz --2023-07-20 …...
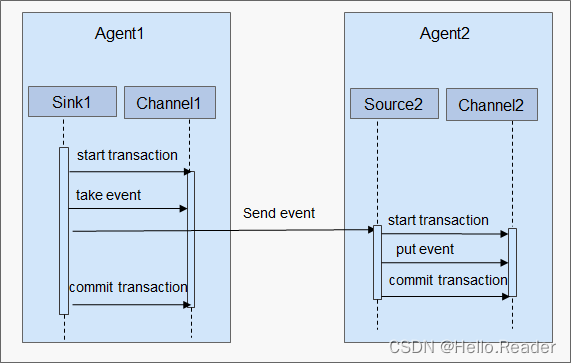
Flume原理剖析
一、介绍 Flume是一个高可用、高可靠,分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制&…...
)
【leetcode】202. 快乐数(easy)
编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果这个过程 结果为 1,…...
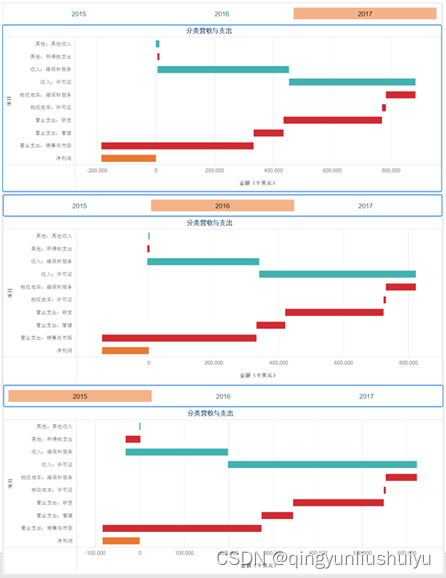
如何用瀑布图分析公司年报
原创: MicroStrategy微策略中国 , Jiping Sun 微策略企业级数据分析与移动应用9月21日2018年 摘要:利用达析报告开箱即用的瀑布图来展示各个度量值如何增加或减少。下载MicroStrategy Desktop 10.11以上版本,自己动手创建瀑布图。 瀑布图是由…...
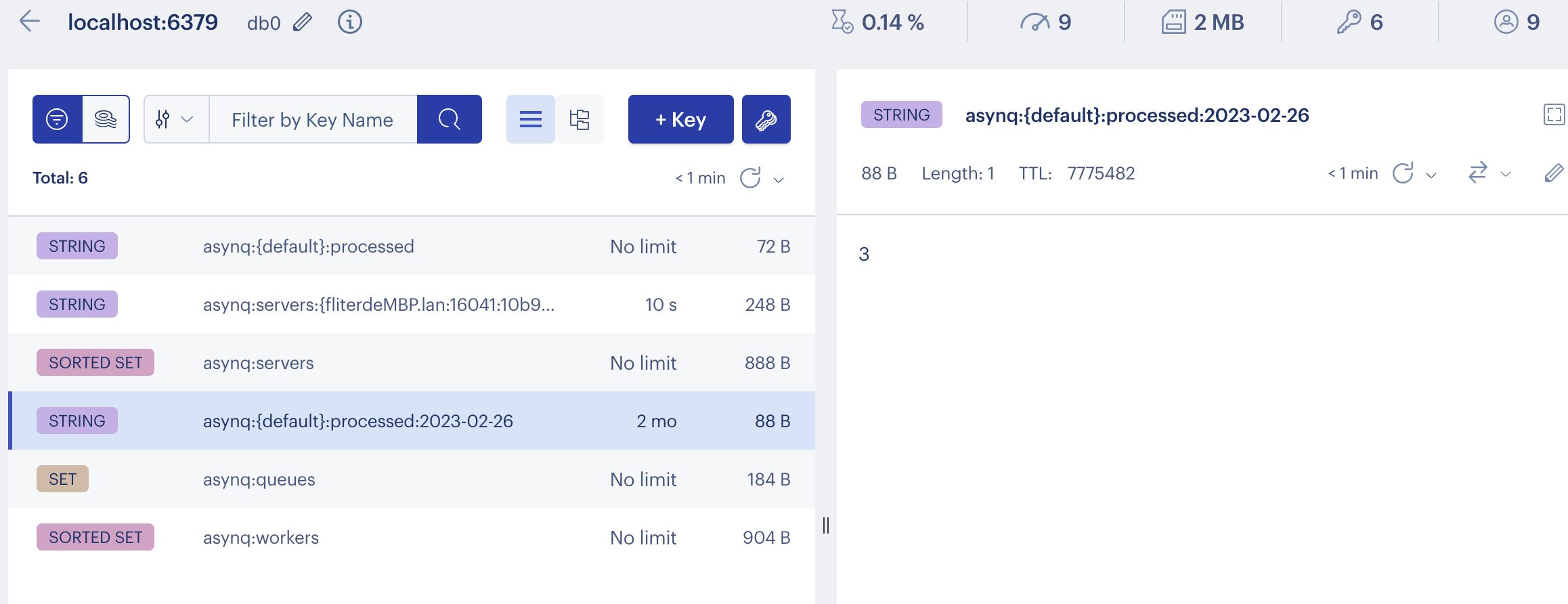
Asynq: 基于Redis实现的Go生态分布式任务队列和异步处理库
Asynq[1]是一个Go实现的分布式任务队列和异步处理库,基于redis,类似Ruby的sidekiq[2]和Python的celery[3]。Go生态类似的还有machinery[4]和goworker 同时提供一个WebUI asynqmon[5],可以源码形式安装或使用Docker image, 还可以和Prometheus…...

保证率计算公式 正态分布
在正态分布中,如果我们要计算一个给定区间内的保证率,可以使用下面的计算公式: 找到给定保证率对应的标准正态分布的z值。可以使用标准正态分布表或计算器进行查询。例如,对于95%的保证率,对应的z值为1.96。 使用z值和…...
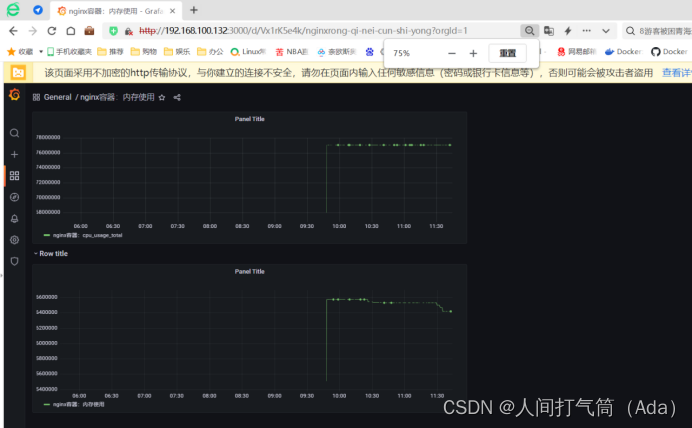
docker容器监控:Cadvisor+InfluxDB+Grafana的安装部署
目录 CadvisorInfluxDBGrafan安装部署 1、安装docker-ce 2、阿里云镜像加速器 3、下载组件镜像 4、创建自定义网络 5、创建influxdb容器 6、创建Cadvisor 容器 7、查看Cadvisor 容器: (1)准备测试镜像 (2)通…...

论文讲解——TPU-MLIR: A Compiler For TPU Using MLIR
论文讲解——TPU-MLIR: A Compiler For TPU Using MLIR https://arxiv.org/pdf/2210.15016.pdf概览模型转换TranslationCanonicalizeLoweringLayerGroup BufferizationCalibration QuantizationCorrectness Check相关资料 https://arxiv.org/pdf/2210.15016.pdf 本文将对TPU…...

PyTorch 2.8虚拟机开发环境:VMware中配置Ubuntu并连接云端GPU
PyTorch 2.8虚拟机开发环境:VMware中配置Ubuntu并连接云端GPU 1. 为什么选择这种开发方式? 对于深度学习开发者来说,本地开发环境配置往往是个头疼的问题。特别是当你的笔记本显卡性能有限,又不想完全依赖云端开发时,…...

Kandinsky-5.0-I2V-Lite-5s环境部署详解:JDK与依赖库的完整安装配置
Kandinsky-5.0-I2V-Lite-5s环境部署详解:JDK与依赖库的完整安装配置 1. 准备工作 在开始部署Kandinsky-5.0-I2V-Lite-5s之前,我们需要确保服务器具备运行该模型所需的基础环境。这个由文本生成视频的AI模型需要特定的Java运行环境和视频处理工具才能正…...

PUBG雷达系统:3分钟搭建您的专属战场指挥中心
PUBG雷达系统:3分钟搭建您的专属战场指挥中心 【免费下载链接】PUBG-maphack-map this is a working copy online-map from jussihi/PUBG-map-hack, use nodejs webserver instead of firebase. 项目地址: https://gitcode.com/gh_mirrors/pu/PUBG-maphack-map …...

4步快速上手:用APK-Installer在Windows上轻松安装安卓应用,告别模拟器烦恼
4步快速上手:用APK-Installer在Windows上轻松安装安卓应用,告别模拟器烦恼 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑…...

如何高效处理生命科学图像数据:Bio-Formats完全实战指南
如何高效处理生命科学图像数据:Bio-Formats完全实战指南 【免费下载链接】bioformats Bio-Formats is a Java library for reading and writing data in life sciences image file formats. It is developed by the Open Microscopy Environment. Bio-Formats is re…...

nRF Connect 介绍和操作入门
nRF Connect 介绍和操作入门 一、nRF Connect 简介 nRF Connect 是由 Nordic Semiconductor 开发的一套强大的低功耗蓝牙(BLE)开发工具集合,主要面向开发者、测试人员以及蓝牙技术爱好者。它分为三个主要版本: 1.1 主要版本版本平…...

intv_ai_mk11行业落地案例:教育内容总结、电商文案生成、开发需求转代码
intv_ai_mk11行业落地案例:教育内容总结、电商文案生成、开发需求转代码 1. 教育内容总结应用实践 1.1 教育场景痛点分析 教育工作者经常面临海量教学资料的整理和提炼工作。传统人工总结方式存在效率低下、主观性强、格式不统一等问题。以某在线教育平台为例&am…...

终极指南:如何在Windows上完美使用PS4手柄玩游戏
终极指南:如何在Windows上完美使用PS4手柄玩游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 想在Windows电脑上畅玩所有游戏却苦于PS4手柄兼容性问题?DS4Windo…...

[具身智能-322]:词向量的含义与发展历史、趋势
词向量(Word Embedding)是自然语言处理(NLP)领域的基石技术,它的核心思想是将人类语言中的词汇转换为计算机能够理解和计算的数学形式——即稠密的低维实数向量。简单来说,词向量技术让机器不再把词语看作孤…...

GraphRAG 安装与使用教程
一、GraphRAG 简介 GraphRAG(Graph Retrieval-Augmented Generation)是由微软研究院开发的基于知识图谱的检索增强生成框架。它通过构建结构化的知识图谱来增强大语言模型(LLM)的推理能力,相比传统 RAG 方法在处理复杂…...