爬虫ip池越大越好吗?
作为一名资深的程序员,今天我要给大家分享一些关于爬虫ip池的知识。关于ip代理池的问题,答案是肯定的,池子越大越好。下面跟我一起来盘点一下ip池大的好处吧!

1、提高稳定性
爬虫ip池越大,意味着拥有更多可用的爬虫ip资源。当一个爬虫ip不可用或被封时,你可以随时切换到另一个可用的IP,保持爬虫的稳定运行。这样的稳定性将直接影响爬取成功率。
2、规避反爬虫策略
当你只有几个爬虫ip可供选择时,你的爬虫行为更容易被反爬虫策略所识别和封禁。但如果有一个庞大的爬虫ip池,你可以随机使用不同的IP地址,模拟真实用户的操作,降低被封禁的风险。
3、提高访问速度
爬虫ip池越大,你的爬虫就有更多机会选择速度更快的IP地址。快速的访问速度是保证爬取效率的关键。通过选择快速的爬虫ip,你可以更快地获取到目标网页的数据,提高爬取的效率和速度。
4、多样化访问路径
大型的爬虫ip池可以提供各种地理位置、网络环境的IP地址。这样,你可以在不同地区或不同网络环境下模拟用户访问,获取更多的数据样本,增加你的数据分析广度和深度。
5、方便应对需求增长
当你的爬虫需求不断增长时,拥有一个大的爬虫ip池将让你更容易扩展。你不需要额外投资来增加爬虫ip,只需要从现有的池子中获取更多的IP资源。这样能够节约成本,提高效率。
综上所述,大型的爬虫ip池带来的好处是显而易见的。它提高了稳定性、规避了反爬虫策略、提高了访问速度、多样化了访问路径,并方便了应对需求增长。当然,选择信誉好、质量高的爬虫ip供应商也是至关重要的。
希望这些建议对你在使用爬虫ip时有所帮助!
相关文章:
爬虫ip池越大越好吗?
作为一名资深的程序员,今天我要给大家分享一些关于爬虫ip池的知识。关于ip代理池的问题,答案是肯定的,池子越大越好。下面跟我一起来盘点一下ip池大的好处吧! 1、提高稳定性 爬虫ip池越大,意味着拥有更多可用的爬虫ip…...

目标检测常用的数据集格式
在目标检测领域,有三种常用的数据集: 数据集标注文件格式bbox格式vocxmlxmin, ymin, xmax, ymax:bbox左上角(xmin, ymin)和右下角(xmax, ymax)的坐标cocojsonx, y, w, h:bbox左上角坐标(x, y)以及宽(w)和高(h)yolotxtxcenter, ycenter, w, h:bbox的中心…...

chrome插件开发实例03-使用 chrome.storage API永久保存数据
目录 防止数据丢失 使用chrome.storage API 功能 功能演示 源代码 manifest.json popup.html...
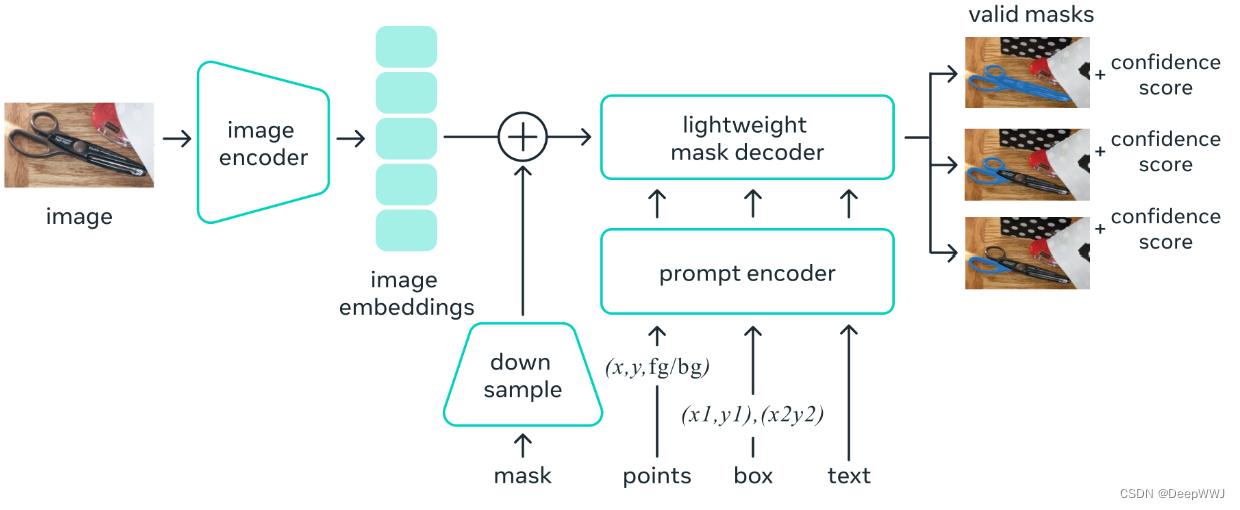
Segment Anything(SAM) 计算过程
给定输入图像 I ∈ R 3 H W I \in R^{3 \times H \times W} I∈R3HW。给定需要的prompts: M ∈ R 1 H W M \in R^{1 \times H \times W} M∈R1HW,代表图片的前背景信息。 P ∈ R N 2 P \in R^{N \times 2} P∈RN2,其中 N N N 是点的个数…...

Nacos配置文件读取源码解析
Nacos配置文件读取 本篇文章是探究,springboot启动时nacos是如何将配置中心的配置读取到springboot环境中的 PropertySourceLocator org.springframework.cloud.bootstrap.config.PropertySourceLocator 是 springcloud 定义的一个顶级接口,用来定义所…...

Linux0.11内核源码解析-fcntl.c/iotcl.c/stat.c
fcntl fcntl.c实现了文件控制系统调用fcntl和两个文件句柄描述符的复制系统调用dup()和dup2()。 dup返回当前值最小的未用句柄,dup2返回指定新句柄的数值,句柄的复制操作主要用在文件的标准输入、输出重定向和管道方面。 dupfd 复制文件句柄ÿ…...

OpenStack简介
OpenStack简介 目录 OpenStack简介 1、云计算模式2、云计算 虚拟化 openstack之间的关系?3、OpenStack 中有哪些组件?4、计算节点负责虚拟机运行5、网络节点负责对外网络与内网之间的通信 5.1 网络节点仅包含Neutron服务5.2 网络节点包含三个网络端口6、…...
二分法的应用
文章目录 什么是二分法🎮二分查找的优先级二分查找的步骤💥图解演示🧩 代码演示🫕python程序实现🐈⬛C程序实现🐕🦺C程序实现🐯Java程序实现🐳 非常规类二分查找&…...

ChatGPT在大规模数据处理和信息管理中的应用如何?
ChatGPT作为一种强大的自然语言处理模型,在大规模数据处理和信息管理领域有着广泛的应用潜力。它可以利用其文本生成、文本理解和问答等能力,为数据分析、信息提取、知识管理等任务提供智能化的解决方案。以下将详细介绍ChatGPT在大规模数据处理和信息管…...
【算法篇C++实现】五大常规算法
文章目录 🚀一、分治法⛳(一)算法思想⛳(二)相关代码 🚀二、动态规划算法⛳(一)算法思想⛳(二)相关代码 🚀三、回溯算法⛳(一…...

MySQL和钉钉单据接口对接
MySQL和钉钉单据接口对接 数据源系统:钉钉 钉钉(DingTalk)是阿里巴巴集团打造的企业级智能移动办公平台,是数字经济时代的企业组织协同办公和应用开发平台。钉钉将IM即时沟通、钉钉文档、钉闪会、钉盘、Teambition、OA审批、智能人事、钉工牌…...

layui的基本使用-日期控件的业务场景使用入门实战案例一
效果镇楼; 1 前端UI层面; <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport&…...

【2.1】Java微服务:详解Hystrix
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。 🍎个人主页:Meteors.的博客 💞当前专栏: Java微服务 ✨特色专栏: 知识分享 &am…...
Apache2.4源码安装与配置
环境准备 openssl-devel pcre-devel expat-devel libtool gcc libxml2-devel 这些包要提前安装,否则httpd编译安装时候会报错 下载源码、解压缩、软连接 1、wget下载[rootnode01 ~]# wget https://downloads.apache.org/httpd/httpd-2.4.57.tar.gz --2023-07-20 …...
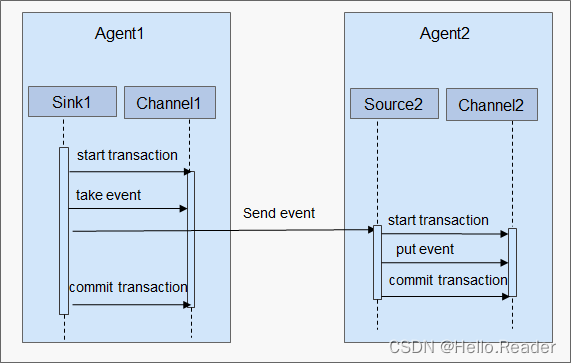
Flume原理剖析
一、介绍 Flume是一个高可用、高可靠,分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制&…...
)
【leetcode】202. 快乐数(easy)
编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果这个过程 结果为 1,…...
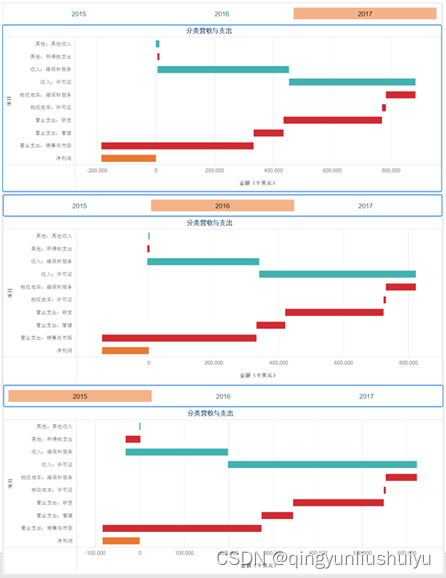
如何用瀑布图分析公司年报
原创: MicroStrategy微策略中国 , Jiping Sun 微策略企业级数据分析与移动应用9月21日2018年 摘要:利用达析报告开箱即用的瀑布图来展示各个度量值如何增加或减少。下载MicroStrategy Desktop 10.11以上版本,自己动手创建瀑布图。 瀑布图是由…...
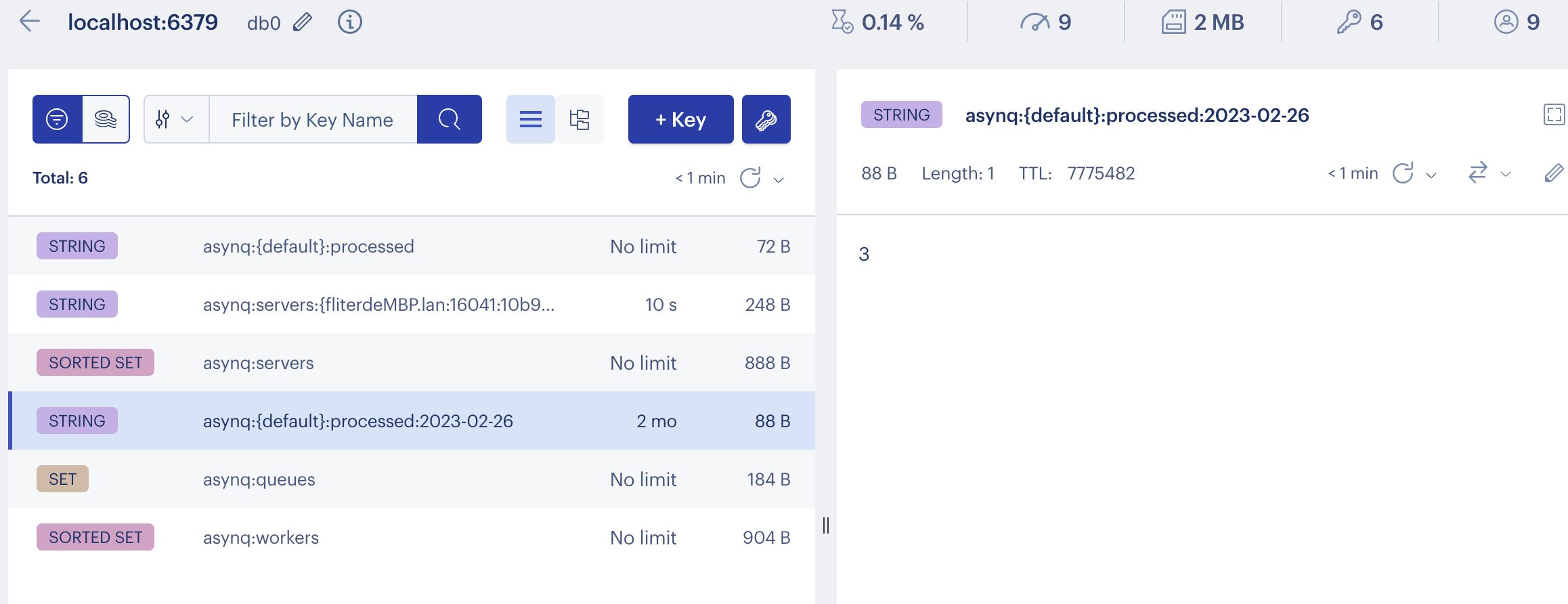
Asynq: 基于Redis实现的Go生态分布式任务队列和异步处理库
Asynq[1]是一个Go实现的分布式任务队列和异步处理库,基于redis,类似Ruby的sidekiq[2]和Python的celery[3]。Go生态类似的还有machinery[4]和goworker 同时提供一个WebUI asynqmon[5],可以源码形式安装或使用Docker image, 还可以和Prometheus…...

保证率计算公式 正态分布
在正态分布中,如果我们要计算一个给定区间内的保证率,可以使用下面的计算公式: 找到给定保证率对应的标准正态分布的z值。可以使用标准正态分布表或计算器进行查询。例如,对于95%的保证率,对应的z值为1.96。 使用z值和…...
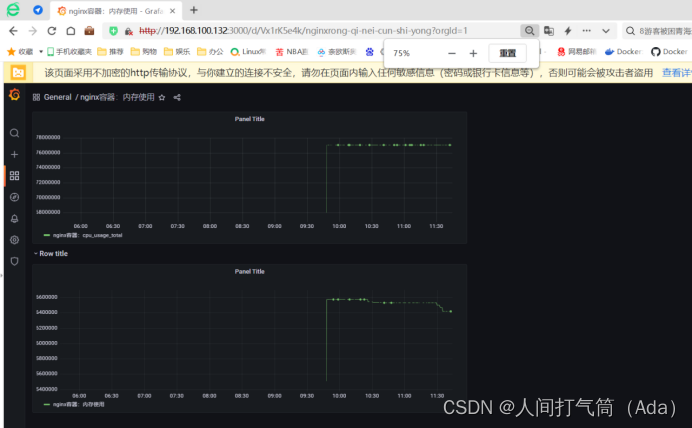
docker容器监控:Cadvisor+InfluxDB+Grafana的安装部署
目录 CadvisorInfluxDBGrafan安装部署 1、安装docker-ce 2、阿里云镜像加速器 3、下载组件镜像 4、创建自定义网络 5、创建influxdb容器 6、创建Cadvisor 容器 7、查看Cadvisor 容器: (1)准备测试镜像 (2)通…...

亲测有效!Xinference-v1.17.1部署避坑指南与性能调优
亲测有效!Xinference-v1.17.1部署避坑指南与性能调优 1. 引言 最近在项目里折腾AI模型服务,从零开始部署开源大模型,踩了不少坑。试过几个平台,要么配置复杂,要么性能拉胯,直到遇到了Xinference-v1.17.1。…...
)
告别代码复制:用GD32F3x0固件库V2.2.0优雅配置PWM互补输出(Keil MDK环境)
告别代码复制:用GD32F3x0固件库V2.2.0优雅配置PWM互补输出(Keil MDK环境) 在嵌入式开发中,PWM(脉冲宽度调制)技术广泛应用于电机控制、电源管理等领域。对于GD32F3x0系列微控制器,官方提供的固件…...

**deepseek-v3.2写小说软件2025解析,揭秘AI辅助创作如何提升故事连贯性与角色深度**
deepseek-v3.2写小说软件2025解析,揭秘AI辅助创作如何提升故事连贯性与角色深度据中国作家协会网络文学中心发布的《2025年中国网络文学创作生态报告》显示,2025年国内网络文学市场规模预计突破680亿元,但日均更新量超过8000字的全职作者中&a…...
Pixel Dimension Fissioner 版本管理实战:Git协作开发工作流
Pixel Dimension Fissioner 版本管理实战:Git协作开发工作流 1. 为什么需要版本管理 在团队开发Pixel Dimension Fissioner这类AI项目时,代码、模型配置和Prompt模板的变更非常频繁。没有版本管理就像在走钢丝——一个不小心的修改可能导致整个项目崩溃…...

Retrieval-based-Voice-Conversion-WebUI:终极AI语音变声指南,10分钟打造专属音色
Retrieval-based-Voice-Conversion-WebUI:终极AI语音变声指南,10分钟打造专属音色 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Tren…...

芯轴-心轴毕业设计论文含CAD图纸
芯轴的设计需严格匹配被连接零件的孔径尺寸,其圆柱度与同轴度误差需控制在极小范围内,否则会引发振动或加速磨损。CAD图纸的绘制是设计过程中的重要环节。工程图则需标注关键尺寸、形位公差及表面处理要求。例如,芯轴的键槽设计需明确宽度、深…...

互联网大厂为啥不把研发迁到二三线城市?
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事上…...

OpenCore Legacy Patcher:让老款Mac焕发新生的完整实战教程
OpenCore Legacy Patcher:让老款Mac焕发新生的完整实战教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台2008年的MacBook Pro&…...

数字孪生案例|港口海运模拟可视化,电子海图与船舶动态3D实景呈现
在智慧港口、船舶调度与海事监管领域,构建一个高保真、可交互的港口海运数字孪生系统,正成为提升港口运营效率、保障航行安全的关键需求。 然而,多数开发者在搭建港口海运可视化项目时,常面临技术门槛高、多源数据(如A…...

2026年爆款论文降重软件实测TOP5,AIGC率最低降至5%,实测超实用!
【博主摘要】 又是一年提交盲审的生死时速阶段。后台私信里“查重过了,但AI率依然红得发紫”的求救声不绝于耳。在各大高校全面封堵AI代写的2026年,找对一款能够同时“降重去AI痕迹”的神仙软件,直接决定了你能否按时拿到双证。 本期博主自费…...