Python中的字符串与字符编码
Hello,这里是Token_w的博客,欢迎您的到来
今天文章讲解的是Python中的字符串与字符编码,其中有基础的理论知识讲解,也有实战中的应用讲解,希望对你有所帮助
整理不易,如对你有所帮助,希望能得到你的点赞、收藏支持。感谢
目录
- 一. 前言
- 二. 相关概念
- 2.1 字符与字节
- 2.2 编码与解码
- 三. Python中的默认编码
- 3.1 Python源代码文件的执行过程
- 3.2 默认编码
- 3.3 最佳实践
- 四. Python2与Python3中对字符串的支持
- (1) Python2
- (2) Python3
- 五. 字符编码转换
- 附六.字符编码
- 1. ASCII码
- 2. 扩展ASCII码(Extended ASCII)
- 3. Unicode
- 4. GB2312
- 5. GBK
- 6. GB18030
- 7. UTF(UCS Transfer Format)
- 8. 简单总结
一. 前言
Python中的字符编码是个老生常谈的话题,同行们都写过很多这方面的文章。有的人云亦云,也有的写得很深入。近日看到某知名培训机构的教学视频中再次谈及此问题,讲解的还是不尽人意,所以才想写这篇文字。一方面,梳理一下相关知识,另一方面,希望给其他人些许帮助。
Python2的 默认编码 是ASCII,不能识别中文字符,需要显式指定字符编码;Python3的 默认编码 为Unicode,可以识别中文字符。
相信大家在很多文章中都看到过类似上面这样“对Python中中文处理”的解释,也相信大家在最初看到这样的解释的时候确实觉得明白了。可是时间久了之后,再重复遇到相关问题就会觉得貌似理解的又不是那么清楚了。如果我们了解上面说的默认编码的作用是什么,我们就会更清晰的明白那句话的含义。
二. 相关概念
2.1 字符与字节
一个字符不等价于一个字节,字符是人类能够识别的符号,而这些符号要保存到计算的存储中就需要用计算机能够识别的字节来表示。一个字符往往有多种表示方法,不同的表示方法会使用不同的字节数。这里所说的不同的表示方法就是指字符编码,比如字母A-Z都可以用ASCII码表示(占用一个字节),也可以用UNICODE表示(占两个字节),还可以用UTF-8表示(占用一个字节)。字符编码的作用就是将人类可识别的字符转换为机器可识别的字节码,以及反向过程。
UNICDOE才是真正的字符串,而用ASCII、UTF-8、GBK等字符编码表示的是字节串。关于这点,我们可以在Python的官方文档中经常可以看到这样的描述"Unicode string" , " translating a Unicode string into a sequence of bytes"
我们写代码是写在文件中的,而字符是以字节形式保存在文件中的,因此当我们在文件中定义个字符串时被当做字节串也是可以理解的。但是,我们需要的是字符串,而不是字节串。一个优秀的编程语言,应该严格区分两者的关系并提供巧妙的完美的支持。JAVA语言就很好,以至于了解Python和PHP之前我从来没有考虑过这些不应该由程序员来处理的问题。遗憾的是,很多编程语言试图混淆“字符串”和“字节串”,他们把字节串当做字符串来使用,PHP和Python2都属于这种编程语言。最能说明这个问题的操作就是取一个包含中文字符的字符串的长度:
- 对字符串取长度,结果应该是所有字符串的个数,无论中文还是英文
- 对字符串对应的字节串取长度,就跟编码(encode)过程使用的字符编码有关了(比如:UTF-8编码,一个中文字符需要用3个字节来表示;GBK编码,一个中文字符需要2个字节来表示)
注意:Windows的cmd终端字符编码默认为GBK,因此在cmd输入的中文字符需要用两个字节表示
# Python2
a = 'Hello,中国' # 字节串,长度为字节个数 = len('Hello,')+len('中国') = 6+2*2 = 10
b = u'Hello,中国' # 字符串,长度为字符个数 = len('Hello,')+len('中国') = 6+2 = 8
c = unicode(a, 'gbk') # 其实b的定义方式是c定义方式的简写,都是将一个GBK编码的字节串解码(decode)为一个Uniocde字符串print(type(a), len(a))
# (<type 'str'>, 10)
print(type(b), len(b))
# (<type 'unicode'>, 8)
print(type(c), len(c))
# (<type 'unicode'>, 8)
Python3中对字符串的支持做了很大的改动,具体内容会在下面介绍。
2.2 编码与解码
先做下科普:UNICODE字符编码,也是一张字符与数字的映射,但是这里的数字被称为代码点(code point), 实际上就是十六进制的数字。
Python官方文档中对Unicode字符串、字节串与编码之间的关系有这样一段描述:
Unicode字符串是一个代码点(code point)序列,代码点取值范围为0到0x10FFFF(对应的十进制为1114111)。这个代码点序列在存储(包括内存和物理磁盘)中需要被表示为一组字节(0到255之间的值),而将Unicode字符串转换为字节序列的规则称为编码。
这里说的编码不是指字符编码,而是指编码的过程以及这个过程中所使用到的Unicode字符的代码点与字节的映射规则。这个映射不必是简单的一对一映射,因此编码过程也不必处理每个可能的Unicode字符,例如:
将Unicode字符串转换为ASCII编码的规则很简单–对于每个代码点:
-
如果代码点数值<128,则每个字节与代码点的值相同
-
如果代码点数值>=128,则Unicode字符串无法在此编码中进行表示(这种情况下,Python会引发一个UnicodeEncodeError异常)
将Unicode字符串转换为UTF-8编码使用以下规则: -
如果代码点数值<128,则由相应的字节值表示(与Unicode转ASCII字节一样)
-
如果代码点数值>=128,则将其转换为一个2个字节,3个字节或4个字节的序列,该序列中的每个字节都在128到255之间。
简单总结: -
编码(encode):将Unicode字符串(中的代码点)转换特定字符编码对应的字节串的过程和规则
-
解码(decode):将特定字符编码的字节串转换为对应的Unicode字符串(中的代码点)的过程和规则
可见,无论是编码还是解码,都需要一个重要因素,就是特定的字符编码。因为一个字符用不同的字符编码进行编码后的字节值以及字节个数大部分情况下是不同的,反之亦然。
三. Python中的默认编码
3.1 Python源代码文件的执行过程
我们都知道,磁盘上的文件都是以二进制格式存放的,其中文本文件都是以某种特定编码的字节形式存放的。对于程序源代码文件的字符编码是由编辑器指定的,比如我们使用Pycharm来编写Python程序时会指定工程编码和文件编码为UTF-8,那么Python代码被保存到磁盘时就会被转换为UTF-8编码对应的字节(encode过程)后写入磁盘。当执行Python代码文件中的代码时,Python解释器在读取Python代码文件中的字节串之后,需要将其转换为UNICODE字符串(decode过程)之后才执行后续操作。
上面已经解释过,这个转换过程(decode,解码)需要我们指定文件中保存的字节使用的字符编码是什么,才能知道这些字节在UNICODE这张万国码和统一码中找到其对应的代码点是什么。这里指定字符编码的方式大家都很熟悉,如下所示:
# -*- coding:utf-8 -*-
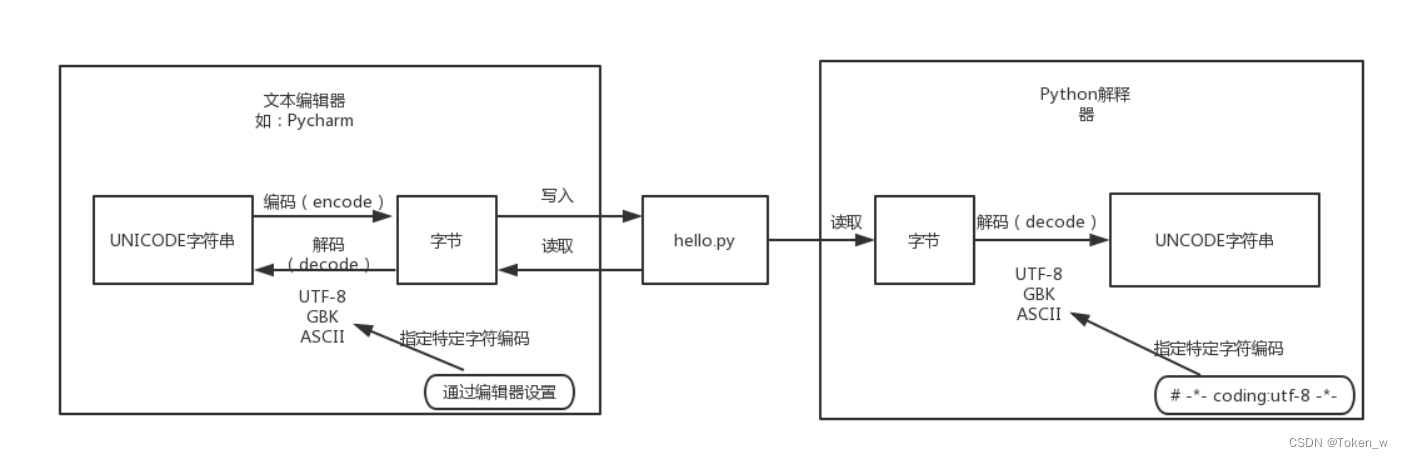
3.2 默认编码
那么,如果我们没有在代码文件开始的部分指定字符编码,Python解释器就会使用哪种字符编码把从代码文件中读取到的字节转换为UNICODE代码点呢?就像我们配置某些软件时,有很多默认选项一样,需要在Python解释器内部设置默认的字符编码来解决这个问题,这就是文章开头所说的“默认编码”。因此大家所说的Python中文字符问题就可以总结为一句话:当无法通过默认的字符编码对字节进行转换时,就会出现解码错误(UnicodeEncodeError)。
Python2和Python3的解释器使用的默认编码是不一样的,我们可以通过sys.getdefaultencoding()来获取默认编码:
# Python2
import sys
print(sys.getdefaultencoding() )
# 'ascii'# Python3
import sys
print(sys.getdefaultencoding() )
# 'utf-8'
因此,对于Python2来讲,Python解释器在读取到中文字符的字节码尝试解码操作时,会先查看当前代码文件头部是否有指明当前代码文件中保存的字节码对应的字符编码是什么。如果没有指定则使用默认字符编码"ASCII"进行解码导致解码失败,导致如下错误:
SyntaxError: Non-ASCII character '\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
对于Python3来讲,执行过程是一样的,只是Python3的解释器以"UTF-8"作为默认编码,但是这并不表示可以完全兼容中文问题。比如我们在Windows上进行开发时,Python工程及代码文件都使用的是默认的GBK编码,也就是说Python代码文件是被转换成GBK格式的字节码保存到磁盘中的。Python3的解释器执行该代码文件时,试图用UTF-8进行解码操作时,同样会解码失败,导致如下错误:
SyntaxError: Non-UTF-8 code starting with '\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
3.3 最佳实践
- 创建一个工程之后先确认该工程的字符编码是否已经设置为UTF-8
- 为了兼容Python2和Python3,在代码头部声明字符编码:-- coding:utf-8 --
四. Python2与Python3中对字符串的支持
其实Python3中对字符串支持的改进,不仅仅是更改了默认编码,而是重新进行了字符串的实现,而且它已经实现了对UNICODE的内置支持,从这方面来讲Python已经和JAVA一样优秀。下面我们来看下Python2与Python3中对字符串的支持有什么区别:
(1) Python2
Python2中对字符串的支持由以下三个类提供
class basestring(object)class str(basestring)class unicode(basestring)
执行help(str)和help(bytes)会发现结果都是str类的定义,这也说明Python2中str就是字节串,而后来的unicode对象对应才是真正的字符串。
#!/usr/bin/env python
# -*- coding:utf-8 -*-a = '你好'
b = u'你好'print(type(a), len(a))
print(type(b), len(b))
输出结果:
(<type 'str'>, 6)
(<type 'unicode'>, 2)
(2) Python3
Python3中对字符串的支持进行了实现类层次的上简化,去掉了unicode类,添加了一个bytes类。从表面上来看,可以认为Python3中的str和unicode合二为一了。
class bytes(object)
class str(object)
实际上,Python3中已经意识到之前的错误,开始明确的区分字符串与字节。因此Python3中的str已经是真正的字符串,而字节是用单独的bytes类来表示。也就是说,Python3默认定义的就是字符串,实现了对UNICODE的内置支持,减轻了程序员对字符串处理的负担。
#!/usr/bin/env python
# -*- coding:utf-8 -*-a = '你好'
b = u'你好'
c = '你好'.encode('gbk')print(type(a), len(a))
print(type(b), len(b))
print(type(c), len(c))
输出结果:
<class 'str'> 2
<class 'str'> 2
<class 'bytes'> 4
五. 字符编码转换
上面提到,UNICODE字符串可以与任意字符编码的字节进行相互转换,如图:
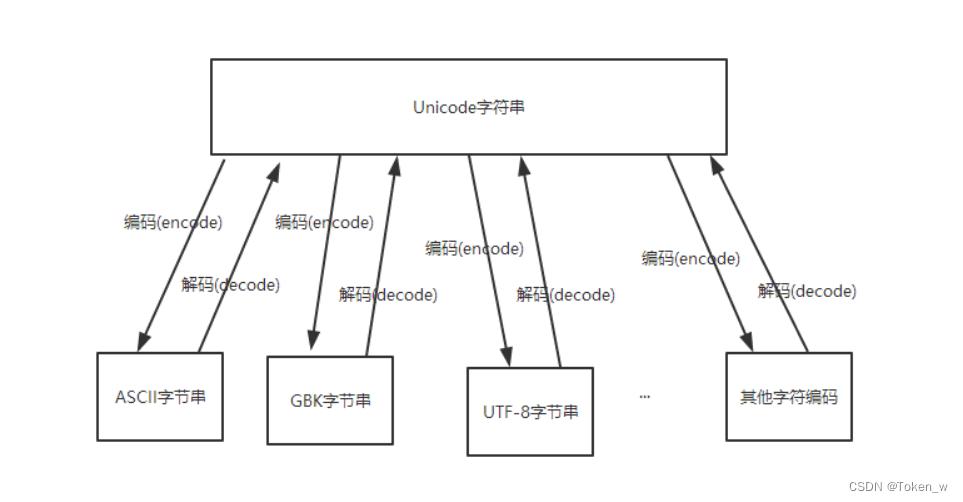
那么大家很容易想到一个问题,就是不同的字符编码的字节可以通过Unicode相互转换吗?答案是肯定的。
Python2中的字符串进行字符编码转换过程是:
字节串–>decode(‘原来的字符编码’)–>Unicode字符串–>encode(‘新的字符编码’)–>字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-utf_8_a = '我爱中国'
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
Python3中定义的字符串默认就是unicode,因此不需要先解码,可以直接编码成新的字符编码:
字符串–>encode(‘新的字符编码’)–>字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-utf_8_a = '我爱中国'
gbk_a = utf_8_a.encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
最后需要说明的是,Unicode不是有道词典,也不是google翻译器,它并不能把一个中文翻译成一个英文。正确的字符编码的转换过程只是把同一个字符的字节表现形式改变了,而字符本身的符号是不应该发生变化的,因此并不是所有的字符编码之间的转换都是有意义的。怎么理解这句话呢?比如GBK编码的“中国”转成UTF-8字符编码后,仅仅是由4个字节变成了6个字节来表示,但其字符表现形式还应该是“中国”,而不应该变成“你好”或者“China”。
前面花了很大的篇幅介绍概念和理论,后面注重实践,希望对您有所帮助。
附六.字符编码
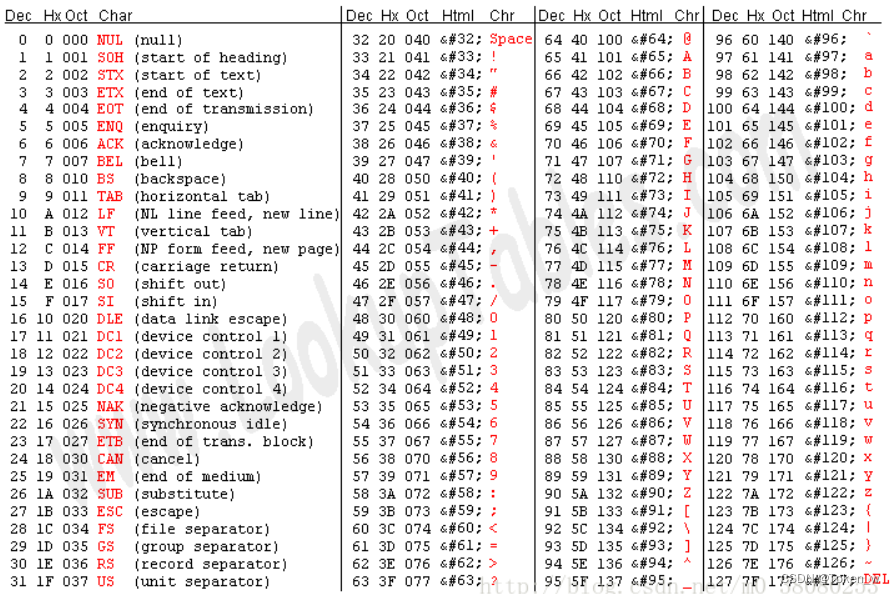
1. ASCII码
ASCII码是美国早期制定的编码规范,只能表示128个字符,包括英文字符、阿拉伯数字、西文字符以及32个控制字符。简单来说,就是下面这个表:
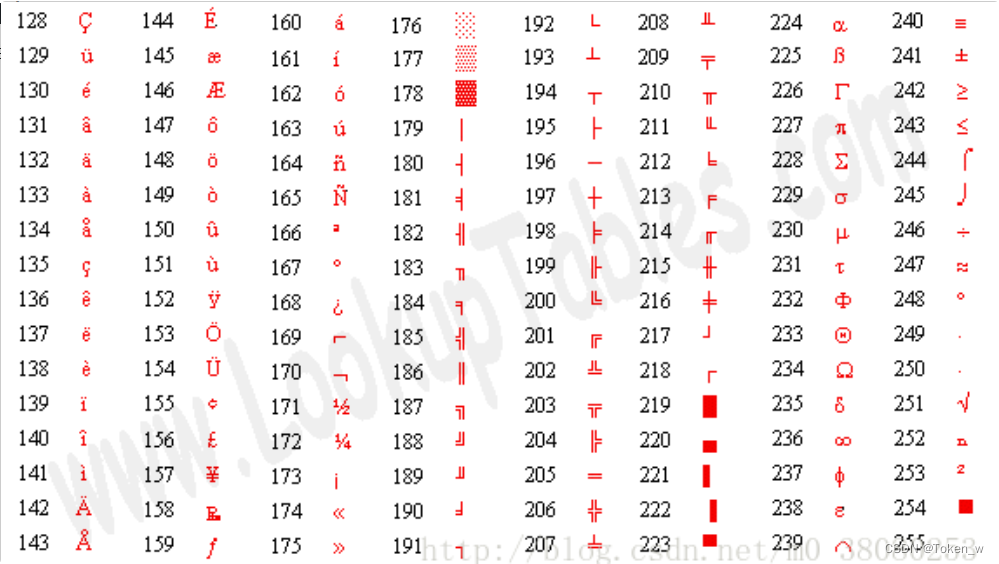
2. 扩展ASCII码(Extended ASCII)
简单而言,扩展ASCII码的出现是因为ASCII不够用,所以向ASCII表继续扩充到256个符号。 但是因为对于扩展ASCII,不同的国家有不同的标准,于是促使了Unicode编码的诞生。 扩展ASCII码表如下:
3. Unicode
准确来说,Unicode不是编码格式,而是字符集。这个字符集包含了世界上目前所有的符号。 另外,在原来有些字符可以用一个字节即8位来表示的,在Unicode将所有字符的长度全部统一为16位,因此字符是定长的。 Unicode是长这样的:
\u4f60\u597d\u4e2d\u56fd\uff01\u0068\u0065\u006c\u006c\u006f\uff0c\u0031\u0032\u0033
上面这段Unicode的意思是“你好中国!hello,123”。
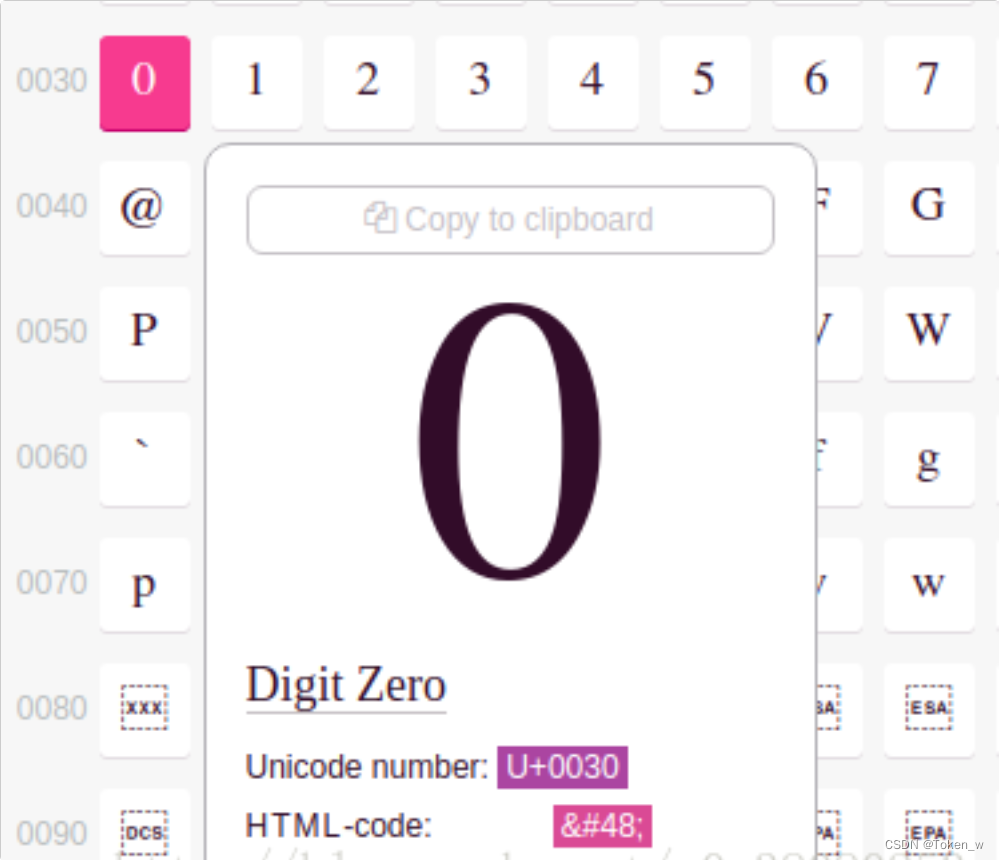
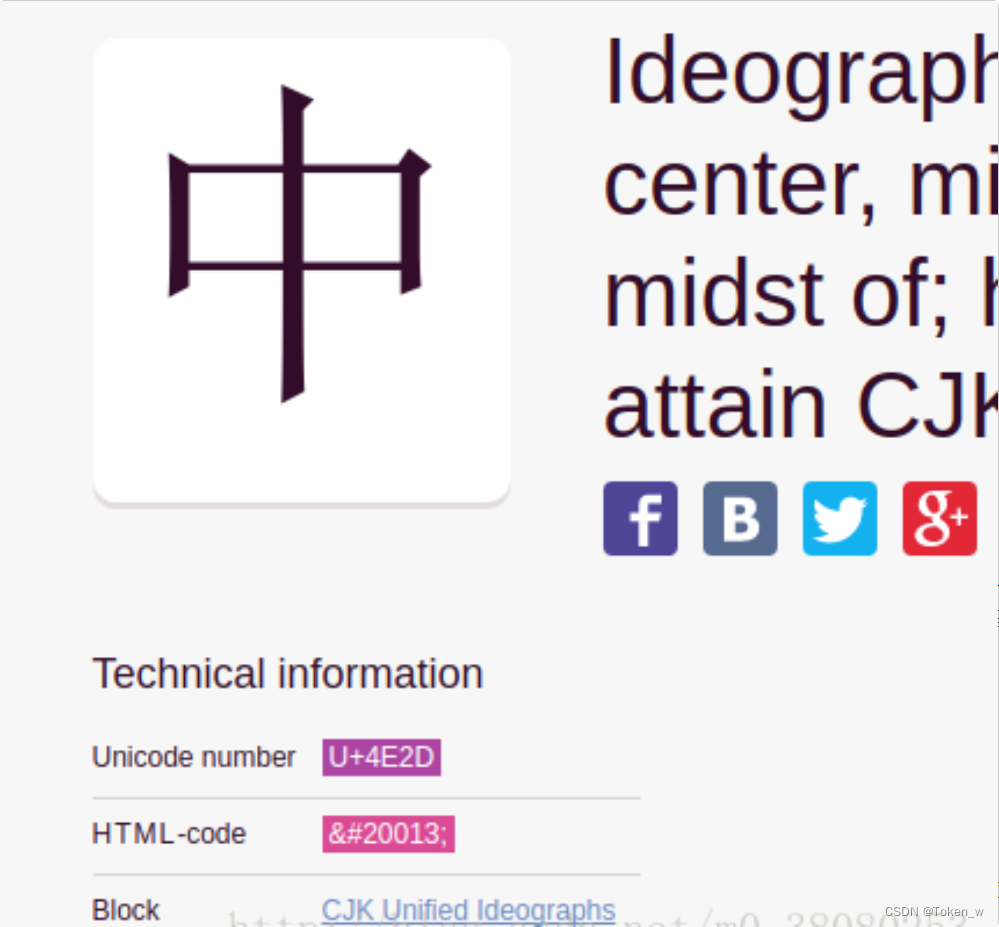
关于Unicode,可在这个网站查到所有字符: https://unicode-table.com/en/
4. GB2312
当国人得到计算机后,那就要对汉字进行编码。在ASCII码表的基础上,小于127的字符意义与原来相同;而将两个大于127的字节连在一起,来表示汉字,前一个字节从0xA1(161)到0xF7(247)共87个字节,称为高字节,后一个字节从0xA1(161)到0xFE(254)共94个字节,称为低字节,两者可组合出约8000种组合,用来表示6763个简体汉字、数学符号、罗马字母、日文字等。 在重新编码的数字、标点、字母是两字节长的编码,这些称为“全角”字符;而原来在ASCII码表的127以下的称为“半角”字符。 简单而言,GB2312就是在ASCII基础上的简体汉字扩展。
gb2312码表: http://www.fileformat.info/info/charset/GB2312/list.htm
5. GBK
简单而言,GBK是对GB2312的进一步扩展(K是汉语拼音kuo zhan(扩展)中“扩”字的声母), 收录了21886个汉字和符号,完全兼容GB2312。
6. GB18030
GB18030收录了70244个汉字和字符,更加全面,与 GB 2312-1980 和 GBK 兼容。 GB18030支持少数民族的汉字,也包含了繁体汉字和日韩汉字。 其编码是单、双、四字节变长编码的。
7. UTF(UCS Transfer Format)
UTF是在互联网上使用最广的一种Unicode的实现方式。我们最常用的是UTF-8,表示每次8个位传输数据,除此之外还有UTF-16。
UTF-8长这样,“你好中国!hello,123”:
你好中国!hello,123
8. 简单总结
- 中国人民通过对 ASCII 编码的中文扩充改造,产生了 GB2312 编码,可以表示6000多个常用汉字。
- 汉字实在是太多了,包括繁体和各种字符,于是产生了 GBK 编码,它包括了 GB2312 中的编码,同时扩充了很多。
- 中国是个多民族国家,各个民族几乎都有自己独立的语言系统,为了表示那些字符,继续把 GBK 编码扩充为 GB18030 编码。
- 每个国家都像中国一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想表达的内容。
- 终于,有个叫 ISO 的组织看不下去了。他们一起创造了一种编码 UNICODE ,这种编码非常大,大到可以容纳世界上任何一个文字和标志。所以只要电脑上有 UNICODE 这种编码系统,无论是全球哪种文字,只需要保存文件的时候,保存成 UNICODE 编码就可以被其他电脑正常解释。
- UNICODE 在网络传输中,出现了两个标准 UTF-8 和 UTF-16,分别每次传输 8个位和 16个位。于是就会有人产生疑问,UTF-8 既然能保存那么多文字、符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码体积比较大,占电脑空间比较多,如果面向的使用人群绝大部分都是中国人,用 GBK 等编码也可以。
相关文章:
Python中的字符串与字符编码
Hello,这里是Token_w的博客,欢迎您的到来 今天文章讲解的是Python中的字符串与字符编码,其中有基础的理论知识讲解,也有实战中的应用讲解,希望对你有所帮助 整理不易,如对你有所帮助,希望能得到…...
图数据库_Neo4j学习cypher语言_使用CQL命令002_删除节点_删除属性_结果排序Order By---Neo4j图数据库工作笔记0006
然后我们再来看如何删除节点 可以看到首先 我们这里 比如我要删除张三 可以看到 match (n:student) where n.name = "张三" delete n 这样就是删除了student集合中,name是张三的节点 然后我们再来看 如何来删除关系 match (n:student)-[r]->(m:student) where…...
C语言学习笔记---数据的存储详解
C语言程序设计笔记---015 C语言数据的存储1、数据类型的意义1.1、unsigned与signed数据类型例程11.2、补码与原码相互转换例程2 2、大小端的介绍2.1、大小端的例程12.2、大小端的例程2 --- 判断当前编译器环境属于大端或小端 3、综合练习题探究数据的存储3.1、练习题13.2、练习…...
)
js中的常见事件(鼠标事件,键盘事件,表单事件......)
JavaScript中的事件(Event)是指在网页中发生的某些特定操作(例如单击、加载页面等),可以被JavaScript代码捕获和处理。常见的事件有: 鼠标事件:单击(click)、双击(dblclickÿ…...

学校如何公布录取情况?源代码公布了
作为一名负责公布学生录取情况的老师,对于录取查询公布工作我们可以按照以下流程来进行公布: 1. 录取结果准备:首先,你需要确保录取结果的准确性和完整性。与招生办公室或相关部门核对录取名单,确保没有遗漏或错误。如…...
JAVA基础知识(一)——Java语言描述、变量和运算符
TOC(Java语言描述、变量和运算符) 一、JAVA语言描述 1.1 java语言描述 JDK、JRE、jVM三者之间的关系,以及JDK、JRE包含的主要结构有哪些? JDKJre java的开发工具(javac.exe java.exe javadoc.exe) jre jvmjava的核心类库 为什…...

时序预测 | MATLAB实现基于KNN K近邻的时间序列预测-递归预测未来(多指标评价)
时序预测 | MATLAB实现基于KNN K近邻的时间序列预测-递归预测未来(多指标评价) 目录 时序预测 | MATLAB实现基于KNN K近邻的时间序列预测-递归预测未来(多指标评价)预测结果基本介绍程序设计参考资料 预测结果 基本介绍 基于KNN K近邻的时间序列预测-递归预测未来(多指标评价) …...
冉冉升起的星火,再度升级迎来2.0时代!
文章目录 前言权威性评测结果 星火大模型多模态功能插件功能简历生成文档问答PPT生成 代码能力 福利 前言 前几天从技术群里看到大家都在谈论《人工智能大模型体验报告2.0》里边的内容,抱着好奇和学习的态度把报告看了一遍。看完之后瞬间被里边提到的科大讯飞的星火…...

centos7安装erlang及rabbitMQ
下载前注意事项: 第一:自己的系统版本,centos中uname -a指令可以查看,el8,el7,rabbitMQ的包不一样! 第二:根据rabbitMQ中erlang version找到想要下载rabbitMQ对应erlang版本&#x…...
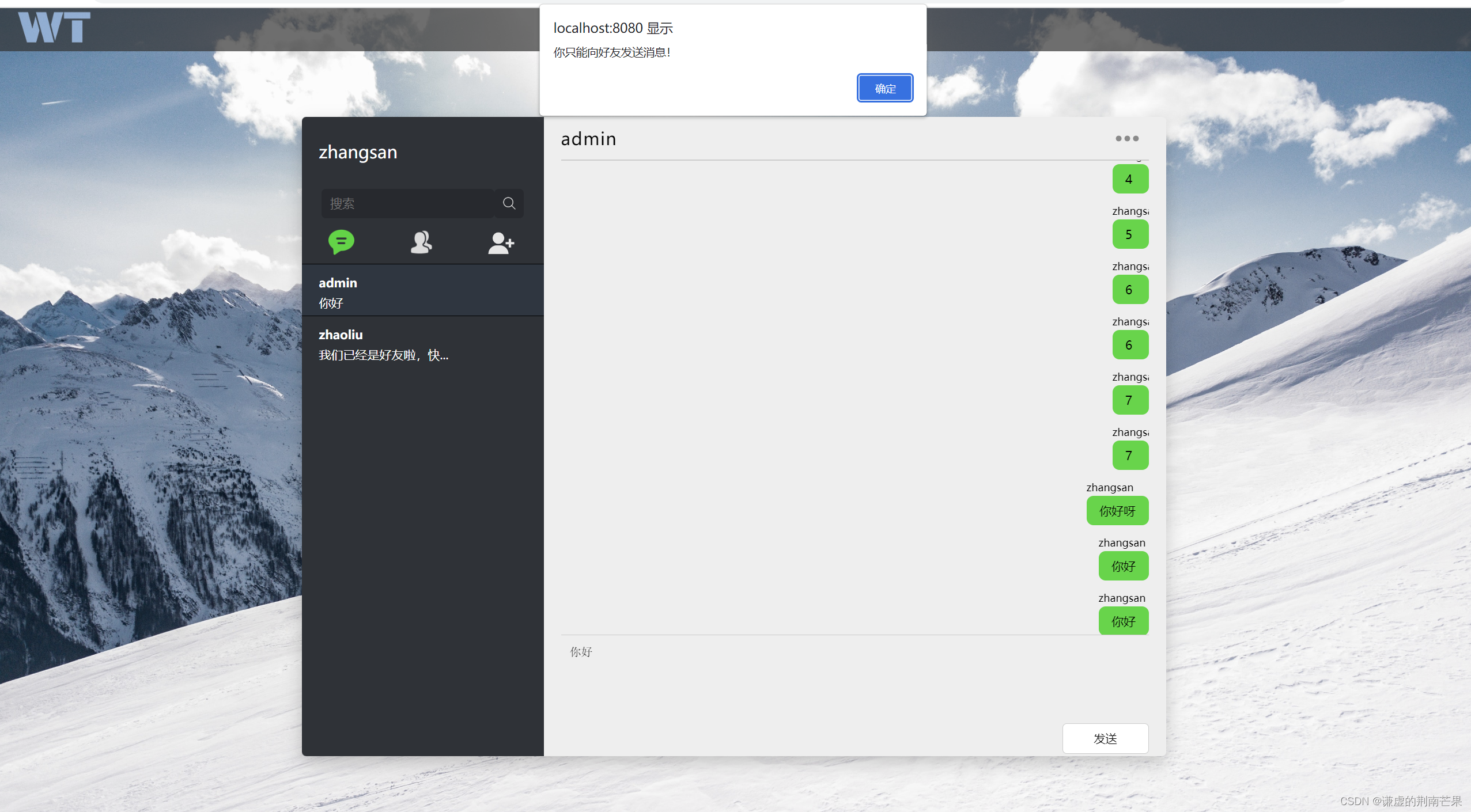
项目介绍:《WeTalk》网页聊天室 — Spring Boot、MyBatis、MySQL和WebSocket的奇妙融合
目录 引言: 前言: 技术栈: 主要功能: 功能详解: 1. 用户注册与登录: 2. 添加好友 3. 实时聊天 4. 消息未读 5. 删除聊天记录 6. 删除好友 未来展望: 项目地址: 结语&am…...
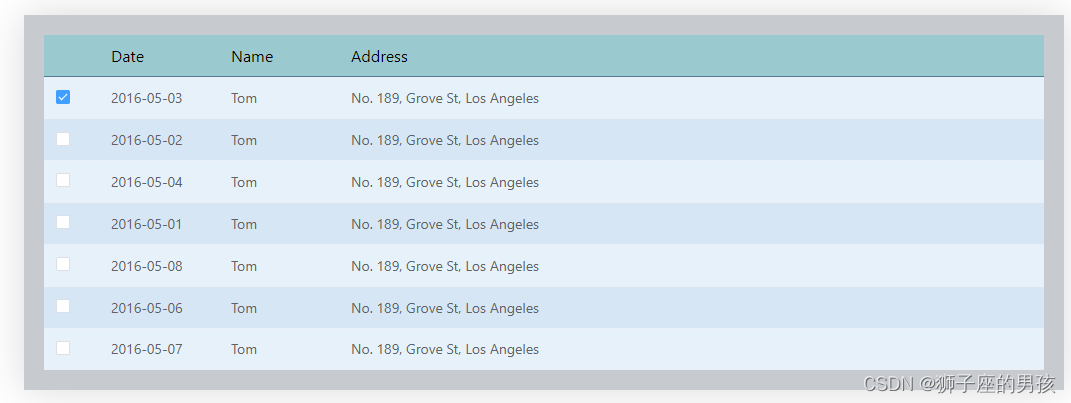
(el-Table)操作(不使用 ts):Element-plus 中Table 表格组件:多选修改成支持单选及表格相关样式的调整
Ⅰ、Element-plus 提供的 Table 表格组件与想要目标情况的对比: 1、Element-plus 提供 Table 组件情况: 其一、Element-ui 自提供的 Table 代码情况为(示例的代码): // Element-plus 自提供的代码: // 此时是使用了 ts 语言环境…...

【JAVA】变量的作用域与生存周期
个人主页:【😊个人主页】 系列专栏:【❤️初识JAVA】 文章目录 前言变量的作用域变量的生命周期局部变量全局变量 前言 变量,我们学习过程中逃不掉的知识,无论在哪种语言中我们都需要学会去合理的运用它,今…...

中科亿海微FIFO使用
引言 FPGA(现场可编程门阵列)是一种可编程逻辑器件,具有灵活性和可重构性,广泛用于数字电路设计和嵌入式系统开发。在FPGA中,FIFO(First-In, First-Out)是一种常见的存储器结构,用于…...

使用maven打包时如何跳过test,有三种方式
方式一 针对spring项目: <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <configuration> <skipTests>true</skipTests> </configuration> …...
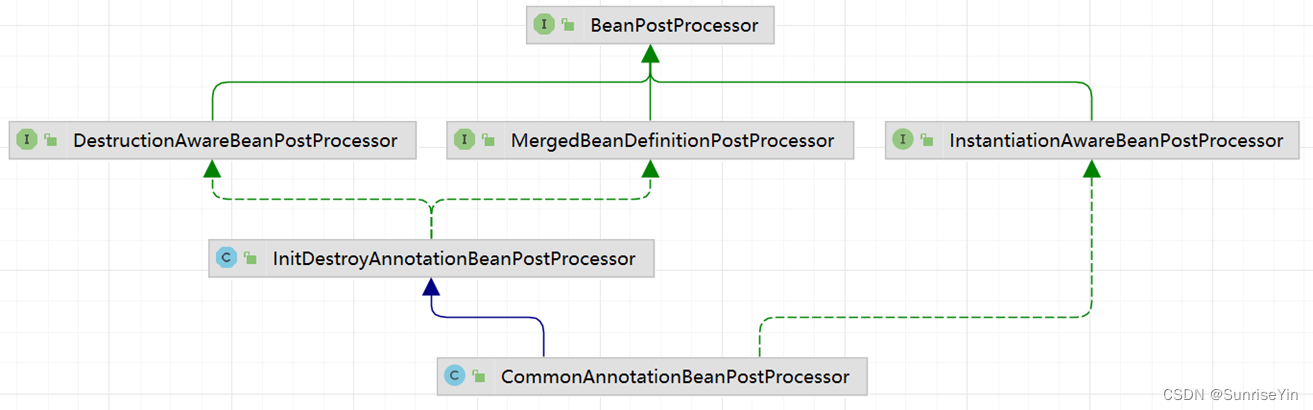
005-Spring 扩展点 :PostProcess
目录 Spring 扩展点 :PostProcess介绍PostProcess大纲文字明细使用方法示例Autowired 功能实现Resource 功能实现 后记 Spring 扩展点 :PostProcess 介绍 Spring 核心做的事情其实很简单就是:控制反转和依赖注入 也就是把 Class 解析为 Bea…...

MFC中的窗体绘制事件函数:OnCtlColor、OnPaint、OnNcPaint、OnDrawItem、OnEraseBkgnd、OnDraw
文章目录 CWnd::OnCtlColorCWnd::OnPaintCWnd::OnNcPaintCWnd::OnDrawItemCWnd::OnEraseBkgndCWnd::InvalidateRectCView::OnDraw 参考:https://learn.microsoft.com/ CWnd::OnCtlColor 即将绘制子控件时,框架会调用此成员函数。 afx_msg HBRUSH OnCt…...

dialogbot:开箱即用的对话机器人解决方案,涵盖问答型对话、任务型对话和聊天型对话等多种场景,为您提供全方位的对话交互体验。
dialogbot:开箱即用的对话机器人解决方案,涵盖问答型对话、任务型对话和聊天型对话等多种场景,支持网络检索问答、领域知识问答、任务引导问答和闲聊问答,为您提供全方位的对话交互体验。 人机对话系统一直是AI的重要方向…...

TCP服务器—实现数据通信
目录 前言 1.接口介绍 2.编写服务器 3.编写客户端 4.编译链接 5.测试 6.总结 前言 今天我们要介绍的是使用TCP协议实现数据通信,相比于之前写的UDP服务器实现数据信,在主体逻辑上并没有差别。客户端向服务器发送信息,服务器接受信息并回…...

基于SpringBoot实现MySQL备份与还原
基于SpringBoot实现MySQL备份与还原,需求是在页面上对所有的平台数据执行备份和恢复操作,那么就需要使用代码去调用MySQL备份和恢复的指令,下面是具体实现步骤; MySQL备份表设计 CREATE TABLE IF NOT EXISTS mysql_backups (id …...

【VUE 监听用户滑动】
监听滑动方法 一. touchstart、touchmove、touchend二.v-touch三. 自定义指令 一. touchstart、touchmove、touchend 在 Vue 中监听用户往哪个方向滑动可以通过添加事件监听器,然后在事件回调函数中判断滑动方向。常用的事件监听器有touchstart、touchmove、touche…...

禾赛季报图解:营收6.8亿 新业务今年将贡献1亿收入 拿下奔驰大单
雷递网 雷建平 5月20日禾赛科技(纳斯达克:HSAI;港交所:2525)日前公布其截至2026年3月31日止三个月的未经审计财务业绩。财报显示,禾赛2026年第一季度实现营收6.8亿,同比增长29.6%。禾赛本季度宣…...

UniApp地图开发避坑指南:在nvue页面里搞定iconfont、动态缩放和点聚合的完整流程
UniApp地图开发实战:nvue页面中的高级技巧与性能优化 1. 引言:为什么选择nvue进行地图开发? 在移动应用开发领域,地图功能已经成为许多应用的核心组件。UniApp作为跨平台开发框架,提供了map组件来实现地图功能…...

告别FreeRTOS:在乐鑫ESP32-C3上为RT-Thread打上‘内核补丁’的完整指南
从FreeRTOS到RT-Thread:ESP32-C3内核替换的工程实践 在嵌入式开发领域,操作系统的选择往往决定了项目的技术栈和生态边界。对于习惯了ESP-IDF和FreeRTOS的开发者来说,RT-Thread以其模块化设计和丰富的中间件支持正成为颇具吸引力的替代方案。…...
)
别再只会用RC了!手把手教你用运放搭建一个75Hz低通滤波器(附Multisim仿真文件)
从RC到运放:实战75Hz低通滤波器设计与Multisim验证 在电子信号处理领域,滤波器设计是每个工程师必须掌握的硬核技能。当你需要从嘈杂的传感器信号中提取有效信息,或者在音频系统中消除恼人的高频噪声时,一个性能优异的低通滤波器往…...

美股api的WebSocket偶尔断连,心跳间隔设多少秒最合适?
做美股相关的数据服务时,我碰到一个小烦恼:WebSocket连接偶尔断开。尤其是实时tick数据,程序明明还在跑,提示“断开”,有时候还挺突然的。我自己测试了不少方法,发现心跳设置是最容易影响稳定性的一个点。 …...

权限管理测试
在 RuoYi(若依)系统中,要实现一个自定义接口的权限验证,通常需要遵循 “后端定义 -> 前端配置 -> 角色分配 -> 测试验证” 的流程。以下是具体的实施步骤及详细解析:第一步:后端定义接口并添加注解…...
》)
好书推荐《VirtualLab Fusion入门与进阶实用教程(第二版)》
目 录第一章 VirtualLab Fusion理论基础 1 1.1 几何光学和光线追迹 1 1.2 物理光学和光场追迹 1 1.2.1 统一场追迹 3 1.2.2 第二代场追迹 6 第二章 VirtualLab Fusion安装与更新 10 2.1 VirtualLab 版本说明及系统配置要求 10 2.2 VirtualLab安装与更新 11 2.3 安装过程中可能遇…...
)
【物联网专业】案例9_2:控制数码管(定时器中断)
文章目录0 文章介绍1 仿真图2 效果图3 不完整代码4 思考题0 文章介绍 对应定时器/计数器案例目标的实现 用计数器中断0(P3^4)控制数码管段选 P1^6)控制数码位选 1 仿真图 2 效果图 3 不完整代码 复制该代码,其中有7个补充点&#…...

独立开发者如何借助Taotoken管理多个AI侧项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken管理多个AI侧项目 作为一名独立开发者,同时维护多个使用大模型的小型项目是常态。你可能有…...

全息三维空间孪生,全域无感精准智位系列:UWB:多路径干扰精度失稳|镜像:多源时空误差融合
在全域空间数字化、实景虚实融合与空间智能快速演进的产业周期中,镜像视界(浙江)科技有限公司持续深耕视频原生三维重构、时空AI像素解算、全域无感精准定位、跨镜轨迹智能推演底层核心领域,依托八大自主可控核心引擎构筑全栈技术…...