分布式定时任务系列5:XXL-job中blockingQueue的应用
传送门
分布式定时任务系列1:XXL-job安装
分布式定时任务系列2:XXL-job使用
分布式定时任务系列3:任务执行引擎设计
分布式定时任务系列4:任务执行引擎设计续
Java并发编程实战1:java中的阻塞队列
引子
这篇文章的主要目不是讨论XXL-job的使用,而是要通过它的任务线程实现机制来分析java中阻塞队列的应用!
而这一切要从上周某天,公司一个普通的下午说起。
当时一个同事要添加任务,就随口问了一句:“阻塞处理策略选啥?”,我心里一惊,以前没注意过这个地方,每次都是默认的,也就是单机串行。
就是下图这个:
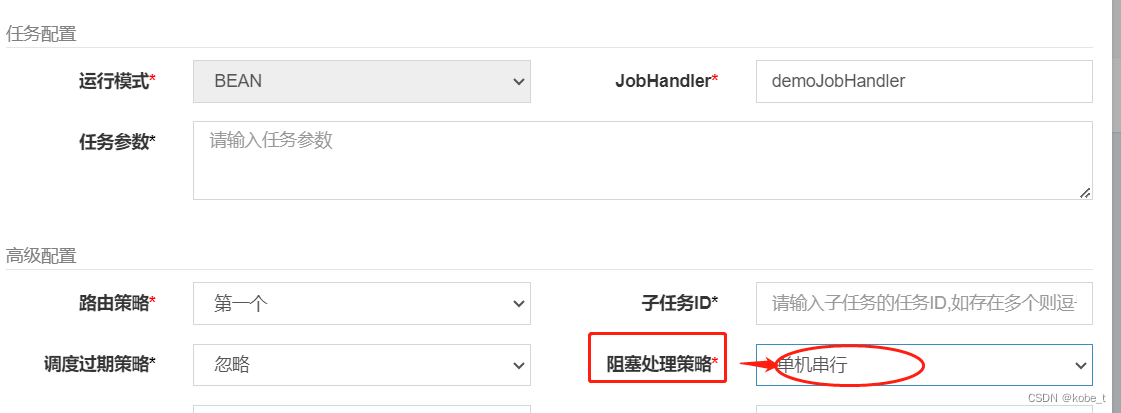
这里面有3个选项:
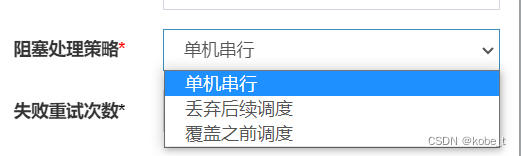
众人先是侃侃讨论了半天,后面再去翻了源码来查看,发现了下面的blockingQueue

阻塞队列
什么是阻塞队列
关于java阻塞队列,可以看看java中的阻塞队列。里面例子用到的是有界队列ArrayBlockingQueue,XXL-job里面用的是无界队列LinkedBlockingQueue。不论它们的相似及区别点,最重要的都是拥有阻塞特性。
要分析XXL-job是怎么使用阻塞队列的,就从XXL-job的调度触发机制入手!
什么是XXL-job任务
前面在分布式定时任务系列2:XXL-job使用里面介绍过XXL-job的使用,注册一个任务也很简单,只要在业务代码方法中打上@XxlJob注解即可!下面是官方提供的demo:
/*** 1、简单任务示例(Bean模式)*/@XxlJob("demoJobHandler")public void demoJobHandler() throws Exception {XxlJobHelper.log("XXL-JOB, Hello World.");for (int i = 0; i < 5; i++) {XxlJobHelper.log("beat at:" + i);TimeUnit.SECONDS.sleep(2);}// default success}开发步骤
1、任务开发:在Spring Bean实例中,开发Job方法;
2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;
4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;
任务注册
对于XXL-job来说,是怎么注册并管理这些任务的呢?
在程序启动的时候,xxl-job-core包中的XxlJobSpringExecutor类由于实现了接口SmartInitializingSingleton,在Bean实例化完成时会调用afterSingletonsInstantiated()方法:
@Overridepublic void afterSingletonsInstantiated() {// init JobHandler Repository (for method)initJobHandlerMethodRepository(applicationContext);// refresh GlueFactoryGlueFactory.refreshInstance(1);// super starttry {super.start();} catch (Exception e) {throw new RuntimeException(e);}}在initJobHandlerMethodRepository(applicationContext)方法中,现在看一下这个方法的代码:该方法会提取所有SpringBean的实例中方法上添加了XxlJob注解的方法,并进行注册!
private void initJobHandlerMethodRepository(ApplicationContext applicationContext) {if (applicationContext == null) {return;}// init job handler from methodString[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, false, true);for (String beanDefinitionName : beanDefinitionNames) {Object bean = applicationContext.getBean(beanDefinitionName);Map<Method, XxlJob> annotatedMethods = null; // referred to :org.springframework.context.event.EventListenerMethodProcessor.processBeantry {annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(),new MethodIntrospector.MetadataLookup<XxlJob>() {@Overridepublic XxlJob inspect(Method method) {return AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class);}});} catch (Throwable ex) {logger.error("xxl-job method-jobhandler resolve error for bean[" + beanDefinitionName + "].", ex);}if (annotatedMethods==null || annotatedMethods.isEmpty()) {continue;}for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) {Method executeMethod = methodXxlJobEntry.getKey();XxlJob xxlJob = methodXxlJobEntry.getValue();// registregistJobHandler(xxlJob, bean, executeMethod);}}// ---------------------- job handler repository ----------------------private static ConcurrentMap<String, IJobHandler> jobHandlerRepository = new ConcurrentHashMap<String, IJobHandler>();public static IJobHandler loadJobHandler(String name){return jobHandlerRepository.get(name);}public static IJobHandler registJobHandler(String name, IJobHandler jobHandler){logger.info(">>>>>>>>>>> xxl-job register jobhandler success, name:{}, jobHandler:{}", name, jobHandler);return jobHandlerRepository.put(name, jobHandler);}注册的方法就是registJobHandler(name, new MethodJobHandler(bean, executeMethod, initMethod, destroyMethod)),会将XxlJob注解标记的方法,提取出对应的方法名,通过反射得到Method信息并实例为对应的MethodJobHandler,最后通过ConcurrentMap来管理,其中key是注任务名称,value为JobHandler实例。
看到这里,不知你有没有一个疑问:这里的JobHandler里面并没有阻塞队列BlockingQueue,它们是怎么关联起来的呢?所以这里就要讨论一下XXL-job的任务执行!
XXL-job的任务执行
在后台管理手动触发一下测试任务,并把代码打上debug断点:
首先会发送后台请求:

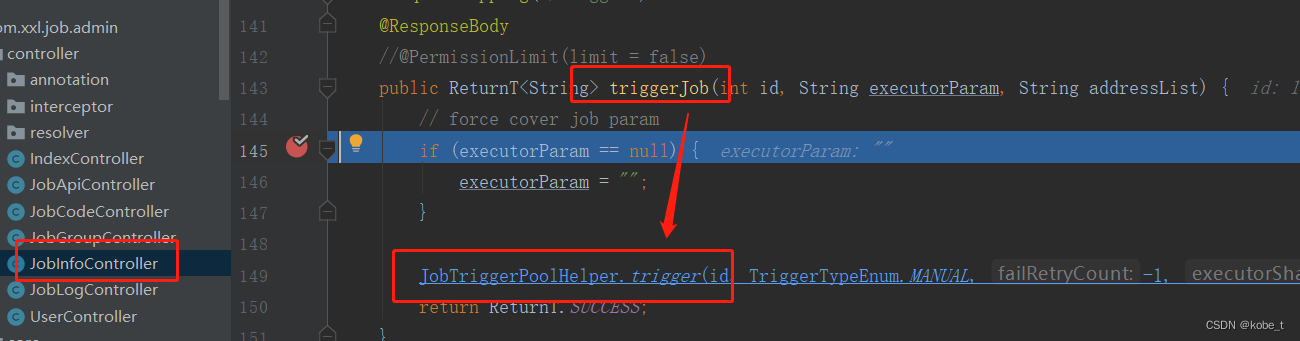 一路跟踪下去,会进入到XxlJobExecutor.runExecutor(TriggerParam triggerParam, String address)方法,最终是到ExecutorBizImpl.run(TriggerParam triggerParam)方法:
一路跟踪下去,会进入到XxlJobExecutor.runExecutor(TriggerParam triggerParam, String address)方法,最终是到ExecutorBizImpl.run(TriggerParam triggerParam)方法:
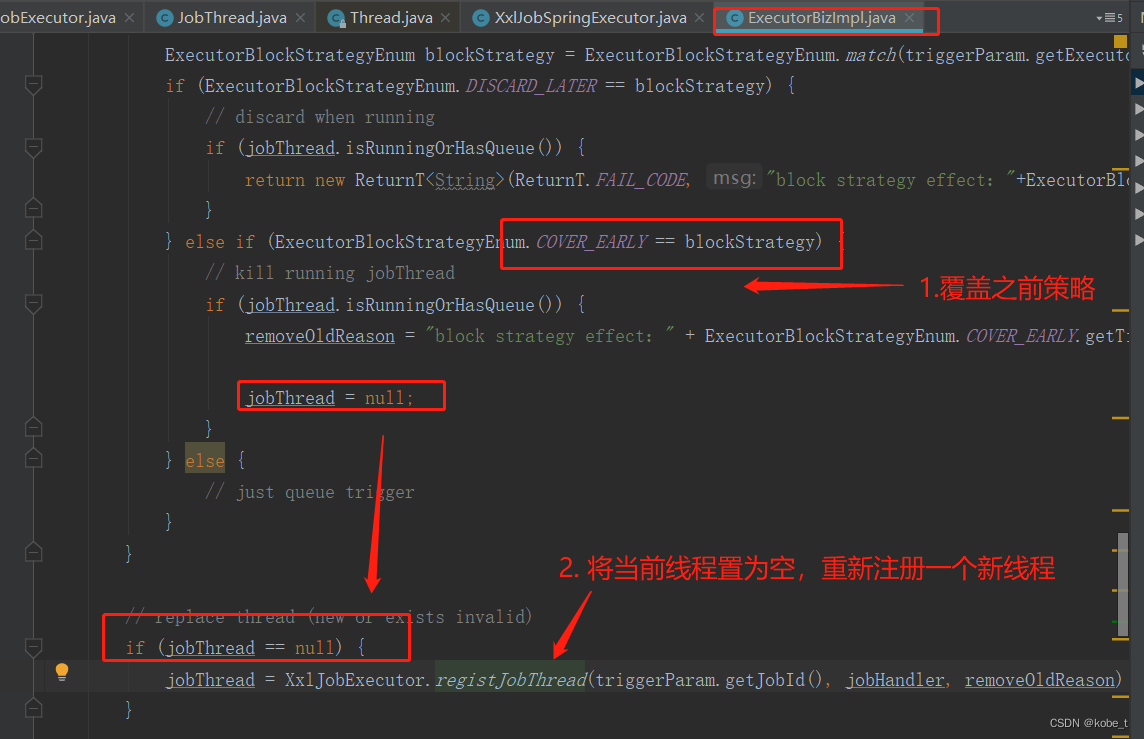
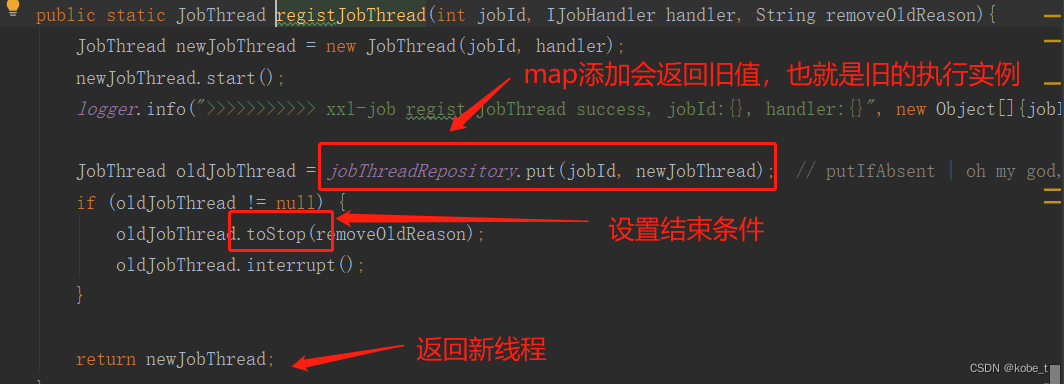
public ReturnT<String> run(TriggerParam triggerParam) {// load old:jobHandler + jobThreadJobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;String removeOldReason = null;// valid:jobHandler + jobThreadGlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());if (GlueTypeEnum.BEAN == glueTypeEnum) {// new jobhandlerIJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler());// valid old jobThreadif (jobThread!=null && jobHandler != newJobHandler) {// change handler, need kill old threadremoveOldReason = "change jobhandler or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {jobHandler = newJobHandler;if (jobHandler == null) {return new ReturnT<String>(ReturnT.FAIL_CODE, "job handler [" + triggerParam.getExecutorHandler() + "] not found.");}}} else if (GlueTypeEnum.GLUE_GROOVY == glueTypeEnum) {// valid old jobThreadif (jobThread != null &&!(jobThread.getHandler() instanceof GlueJobHandler&& ((GlueJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {// change handler or gluesource updated, need kill old threadremoveOldReason = "change job source or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {try {IJobHandler originJobHandler = GlueFactory.getInstance().loadNewInstance(triggerParam.getGlueSource());jobHandler = new GlueJobHandler(originJobHandler, triggerParam.getGlueUpdatetime());} catch (Exception e) {logger.error(e.getMessage(), e);return new ReturnT<String>(ReturnT.FAIL_CODE, e.getMessage());}}} else if (glueTypeEnum!=null && glueTypeEnum.isScript()) {// valid old jobThreadif (jobThread != null &&!(jobThread.getHandler() instanceof ScriptJobHandler&& ((ScriptJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {// change script or gluesource updated, need kill old threadremoveOldReason = "change job source or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {jobHandler = new ScriptJobHandler(triggerParam.getJobId(), triggerParam.getGlueUpdatetime(), triggerParam.getGlueSource(), GlueTypeEnum.match(triggerParam.getGlueType()));}} else {return new ReturnT<String>(ReturnT.FAIL_CODE, "glueType[" + triggerParam.getGlueType() + "] is not valid.");}// executor block strategyif (jobThread != null) {ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {// discard when runningif (jobThread.isRunningOrHasQueue()) {return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());}} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {// kill running jobThreadif (jobThread.isRunningOrHasQueue()) {removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();jobThread = null;}} else {// just queue trigger}}// replace thread (new or exists invalid)if (jobThread == null) {jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);}// push data to queueReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);return pushResult;}任务执行过程中,如果发现XXL-job对应的执行线程不存在,会创建一个新new Thread实例,并绑定前面的JobHandler实例,这样对于每一个任务都有一个单独的线程,也就将执行线程JobThread跟任务关联起来了:
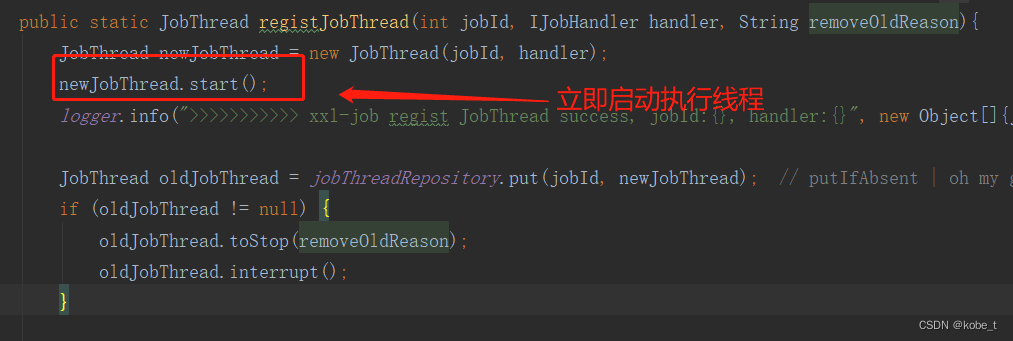
public static JobThread registJobThread(int jobId, IJobHandler handler, String removeOldReason){JobThread newJobThread = new JobThread(jobId, handler);newJobThread.start();logger.info(">>>>>>>>>>> xxl-job regist JobThread success, jobId:{}, handler:{}", new Object[]{jobId, handler});JobThread oldJobThread = jobThreadRepository.put(jobId, newJobThread); // putIfAbsent | oh my god, map's put method return the old value!!!if (oldJobThread != null) {oldJobThread.toStop(removeOldReason);oldJobThread.interrupt();}return newJobThread;}public JobThread(int jobId, IJobHandler handler) {this.jobId = jobId;this.handler = handler;// 初始化阻塞队列this.triggerQueue = new LinkedBlockingQueue<TriggerParam>();this.triggerLogIdSet = Collections.synchronizedSet(new HashSet<Long>());// assign job thread namethis.setName("xxl-job, JobThread-"+jobId+"-"+System.currentTimeMillis());}而执行任务的最后一步,就是将当前任务入队到刚才的执行线程的BlockingQueue中:
// push data to queueReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);而这也就跟文章最前面的代码关联起来了:
/*** new trigger to queue** @param triggerParam* @return*/public ReturnT<String> pushTriggerQueue(TriggerParam triggerParam) {// avoid repeatif (triggerLogIdSet.contains(triggerParam.getLogId())) {logger.info(">>>>>>>>>>> repeate trigger job, logId:{}", triggerParam.getLogId());return new ReturnT<String>(ReturnT.FAIL_CODE, "repeate trigger job, logId:" + triggerParam.getLogId());}triggerLogIdSet.add(triggerParam.getLogId());triggerQueue.add(triggerParam);return ReturnT.SUCCESS;}BlockingQueue的应用
消息入队
至此,就可以看出任务触发的大致逻辑了,用户在admin手工触发任务之后最终会放入到任务对应的队列之中:通过add方法将当前执行参数入队(FIFO),不阻塞队列,如果满了就抛出异常(这也是一个比较大的隐患,如果触了过于频繁,可能会导致OOM,而这也就是为什么要设计不同阻塞策略的原因)。
消息消费
而这些触发的任务怎么消费的呢?其实也是在上面的提到的执行线程JobThread:
- 当实例化一个线程的时候(com.xxl.job.core.executor.XxlJobExecutor类),会立即启动:调用线程的start()方法
- 启动之后会调用线程的run()方法(com.xxl.job.core.thread.JobThread类)
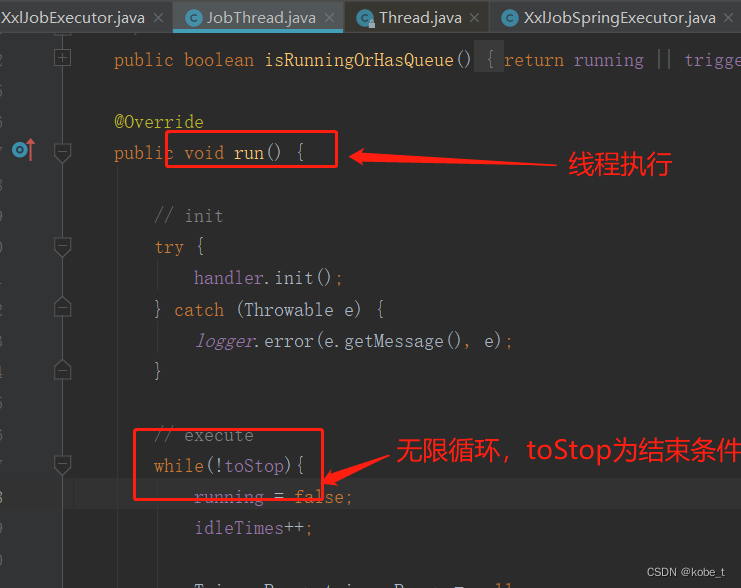
- 在执行线程中,会写一个while的无限循环来不停的从阻塞队列中取出任务

- 循环结束的条件就是上面的阻塞队列:如果是覆盖之前调度将会结束循环(com.xxl.job.core.biz.impl.ExecutorBizImpl类)
相关文章:
分布式定时任务系列5:XXL-job中blockingQueue的应用
传送门 分布式定时任务系列1:XXL-job安装 分布式定时任务系列2:XXL-job使用 分布式定时任务系列3:任务执行引擎设计 分布式定时任务系列4:任务执行引擎设计续 Java并发编程实战1:java中的阻塞队列 引子 这篇文章的…...

QT网络编程之TCP
QT网络编程之TCP TCP 编程需要用到俩个类: QTcpServer 和 QTcpSocket。 #------------------------------------------------- # # Project created by QtCreator 2023-08-...
《游戏编程模式》学习笔记(四) 观察者模式 Observer Pattern
定义 观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。 这是定义,看不懂就看不懂吧,我接下来举个例子慢慢说 为什么我们需要观察者模式 我们看一个很简…...
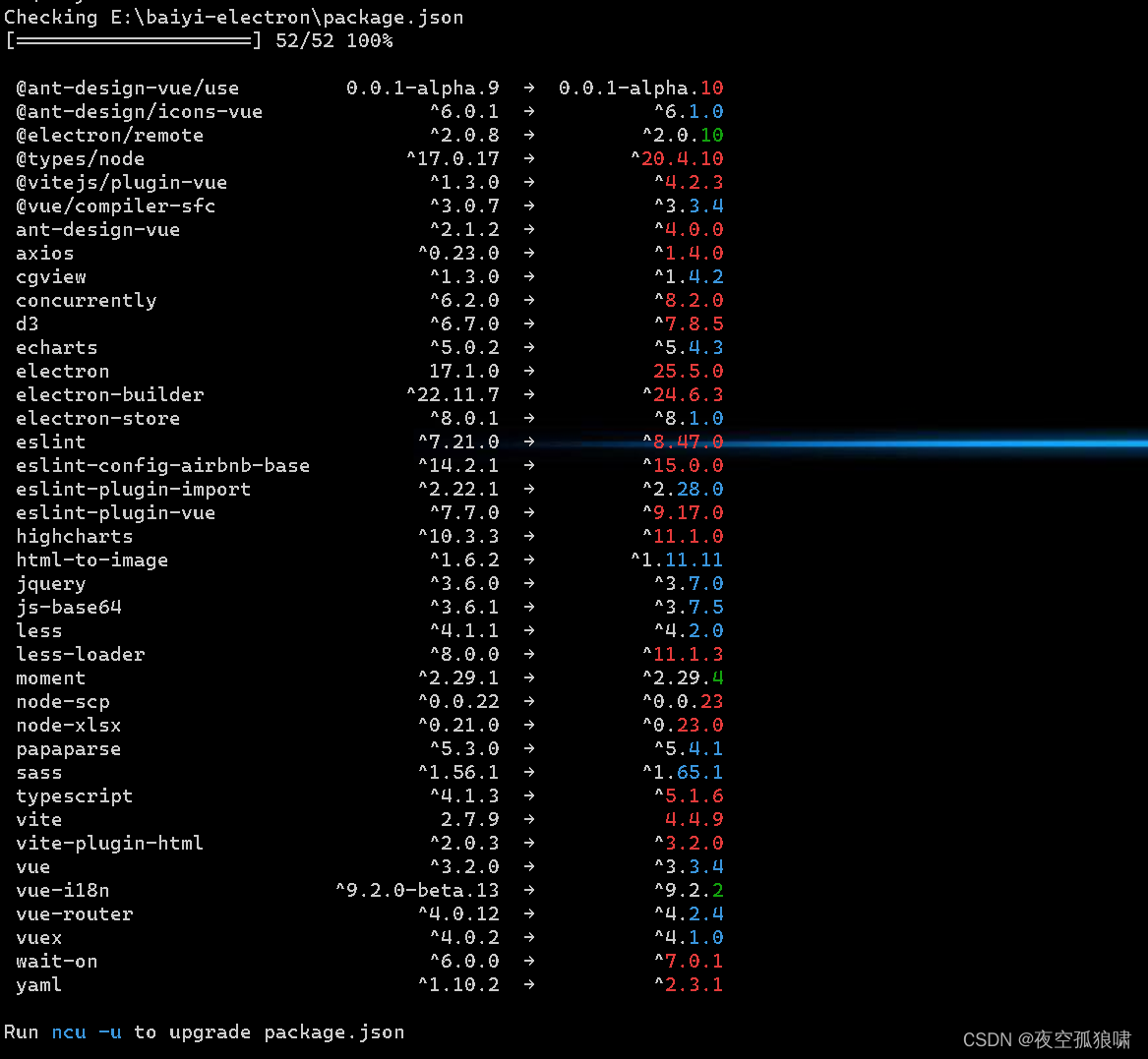
前端一键升级 package.json里面的依赖包管理
升级需谨慎 前端一键升级 package.json里面的依赖包管理 安装:npm-check-updates npm i npm-check-updates -g缩写 ncu 在项目根目录里面执行 ncu 如图:...
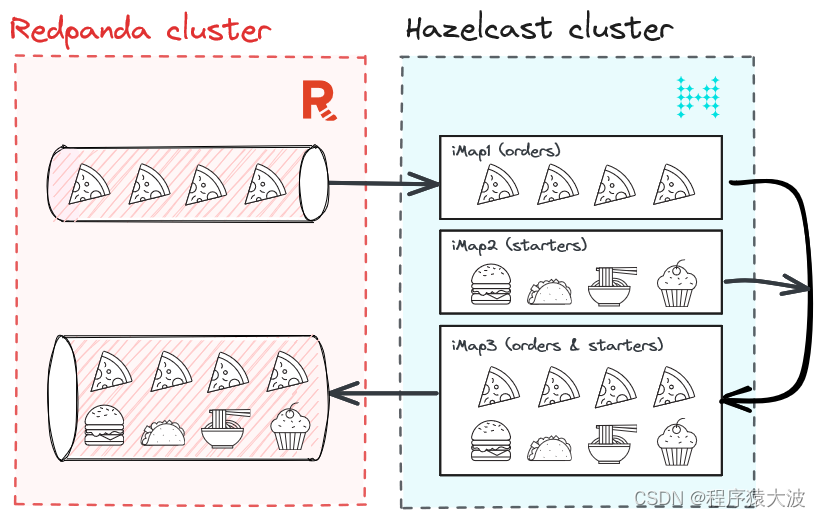
当速度很重要时:使用 Hazelcast 和 Redpanda 进行实时流处理
在本教程中,了解如何构建安全、可扩展、高性能的应用程序,以释放实时数据的全部潜力。 在本教程中,我们将探索 Hazelcast 和 Redpanda 的强大组合,以构建对实时数据做出反应的高性能、可扩展和容错的应用程序。 Redpanda 是一个流…...

筛法求欧拉函数
思路: (1)若要分别求1~n每个数的欧拉函数值,则复杂度O(n*n^0.5),超时; (2)于是考虑用欧拉筛进行求取; (3)欧拉筛:基于线…...

consul限制注册的ip
假设当前服务器的ip是:192.168.56.130 1、允许 所有ip 注册(验证可行) consul agent -server -ui -bootstrap-expect1 -data-dir/usr/local/consul -nodedevmaster -advertise192.168.56.130 -bind0.0.0.0 -client0.0.0.0 2、只允许 当前ip 注册 consul agent -…...
用AI攻克“智能文字识别创新赛题”,这场大学生竞赛掀起了什么风潮?
文章目录 一、前言1.1 大赛介绍1.2 项目背景 二、基于智能文字场景个人财务管理创新应用2.1 作品方向2.2 票据识别模型2.2.1 文本卷积神经网络TextCNN2.2.2 Bert 预训练微调2.2.3 模型对比2.2.4 效果展示 2.3 票据文字识别接口 三、未来展望 一、前言 1.1 大赛介绍 中国大学生…...

EJB基本概念和使用
一、EJB是什么? EJB是sun的JavaEE服务器端组件模型,是一种规范,设计目标与核心应用是部署分布式应用程序。EJB2.0过于复杂,EJB3.0的推出减轻了开发人员进行底层开发的工作量,它取消或最小化了很多(以前这些是必须实现)…...

神经网络基础-神经网络补充概念-09-m个样本的梯度下降
概念 当应用梯度下降算法到具有 m 个训练样本的逻辑回归问题时,我们需要对每个样本计算梯度并进行平均,从而更新模型参数。这个过程通常称为批量梯度下降(Batch Gradient Descent)。 代码实现 import numpy as npdef sigmoid(z…...

分布式 - 消息队列Kafka:Kafka消费者分区再均衡(Rebalance)
文章目录 01. Kafka 消费者分区再均衡是什么?02. Kafka 消费者分区再均衡的触发条件?03. Kafka 消费者分区再均衡的过程?04. Kafka 如何判定消费者已经死亡?05. Kafka 如何避免消费者的分区再均衡?06. Kafka 消费者分区再均衡有什…...
BIO、NIO和AIO
一.引言 何为IO 涉及计算机核心(CPU和内存)与其他设备间数据迁移的过程,就是I/O。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。 I/O 描述了计算机系统…...
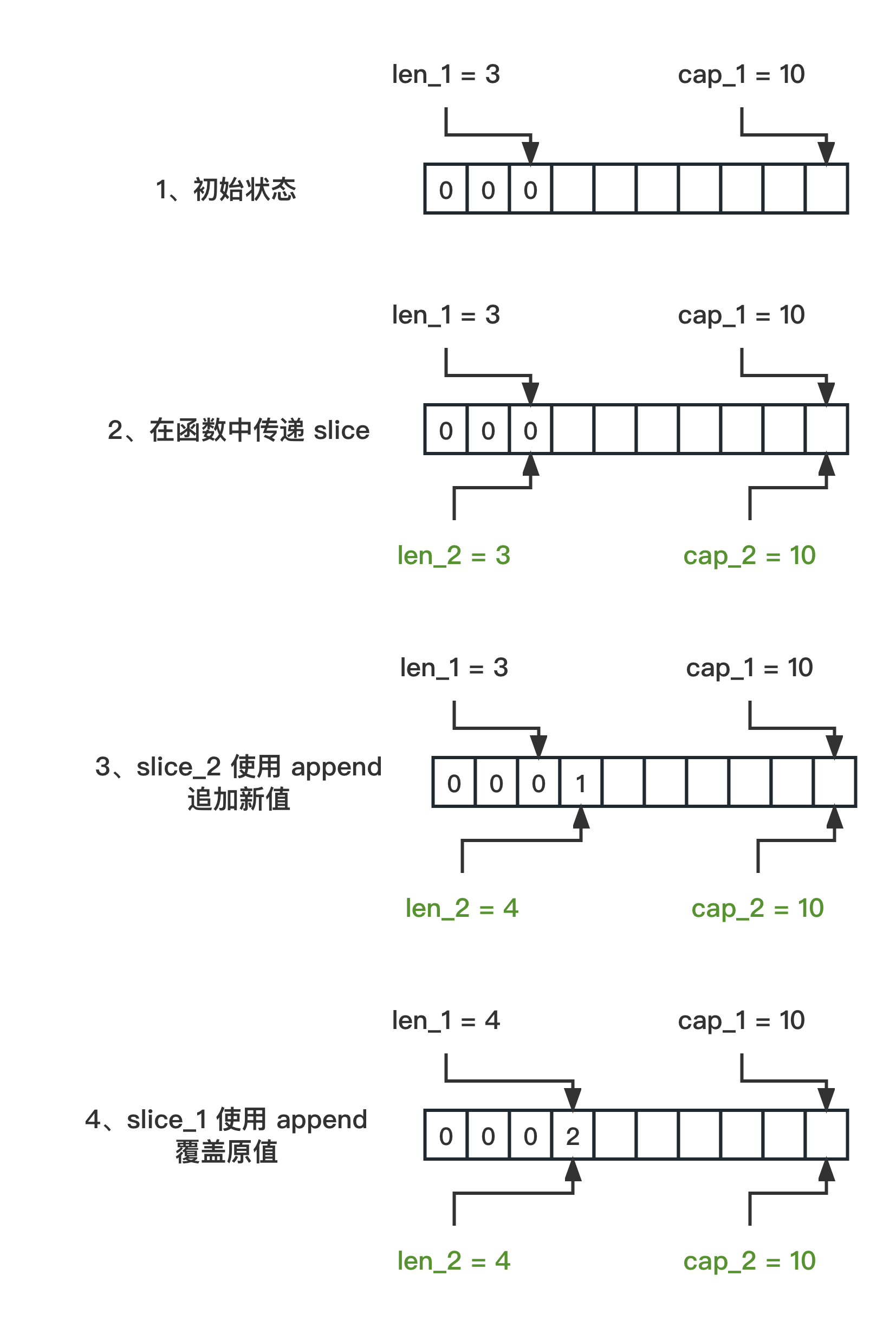
理解 Go 中的切片:append 操作的深入分析(篇1)
理解 Go 语言中 slice 的性质对于编程非常有益。下面,我将通过两个代码示例来解释切片在不同函数之间传递并执行 append 操作时的具体表现。 本篇为第 1 篇,当切片的容量 cap 充足时 第一份代码 slice1 的初始长度为 3,容量为 10 func main()…...
由于找不到mfc140u.dll,无法继续执行代码怎么修复?
当我在使用某个应用程序时遇到了mfc140u.dll缺失的错误提示时,我意识到这是由于该动态链接库文件丢失或损坏所引起的。mfc140u.dll是MFC的一部分,它包含了许多与用户界面、窗口管理、控件等相关的函数和类。这个文件通常用于支持使用MFC开发的应用程序的…...

【0.1】lubancat鲁班猫4刷入debian网络ping 域名不通问题
目录 1. 环境2. 操作步骤 1. 环境 lubancat4鲁班猫4 (4G0)不带emmc系统镜像lubancat-rk3588-debian11-gnome-20230807_update.img官方资料地址https://doc.embedfire.com/products/link/zh/latest/linux/ebf_lubancat.html 2. 操作步骤 从官网给的百度网盘下载linux系统全部…...
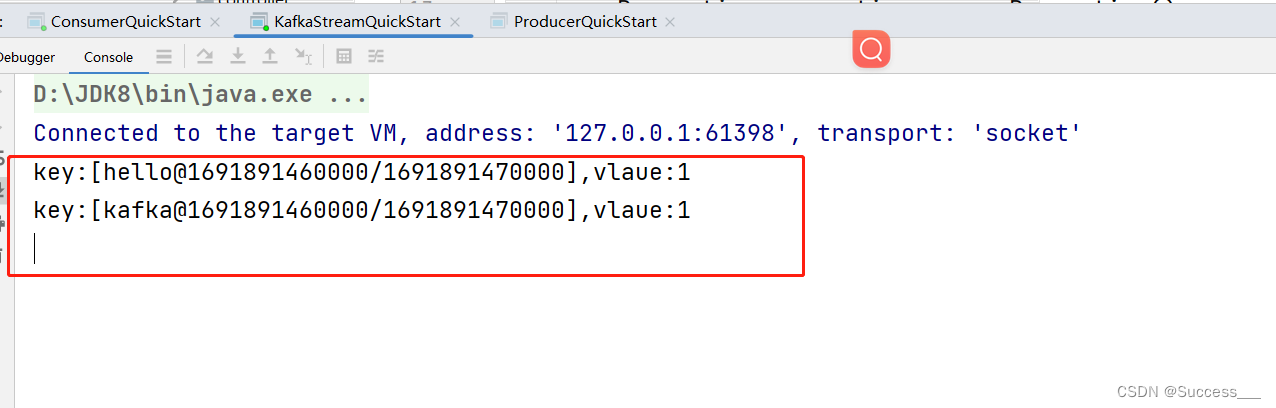
KafkaStream:基本使用
简介: kafkaStream:提供了对存储在kafka中的数据进行流式处理和分析的功能 特点: KafkasSream提供了一个非常简单轻量的Library,它可以非常方便的嵌入到java程序中,也可以任何方式打包部署 入门案例: 1、…...
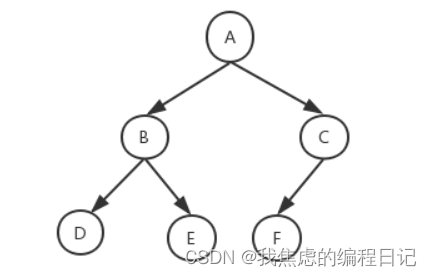
【数据结构】二叉树
完全二叉树 是指所有结点度数小于等于2的树 所以这种情况也是: 几条性质 一个具有n个结点的完全二叉树的深度为: log 2 ( n 1 ) 的结果向上取整。 \\\log_{2}(n1) \ \ 的结果向上取整。 log2(n1) 的结果向上取整。设度为0的结点个数是n0&#…...
基于灰狼优化(GWO)、帝国竞争算法(ICA)和粒子群优化(PSO)对梯度下降法训练的神经网络的权值进行了改进(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
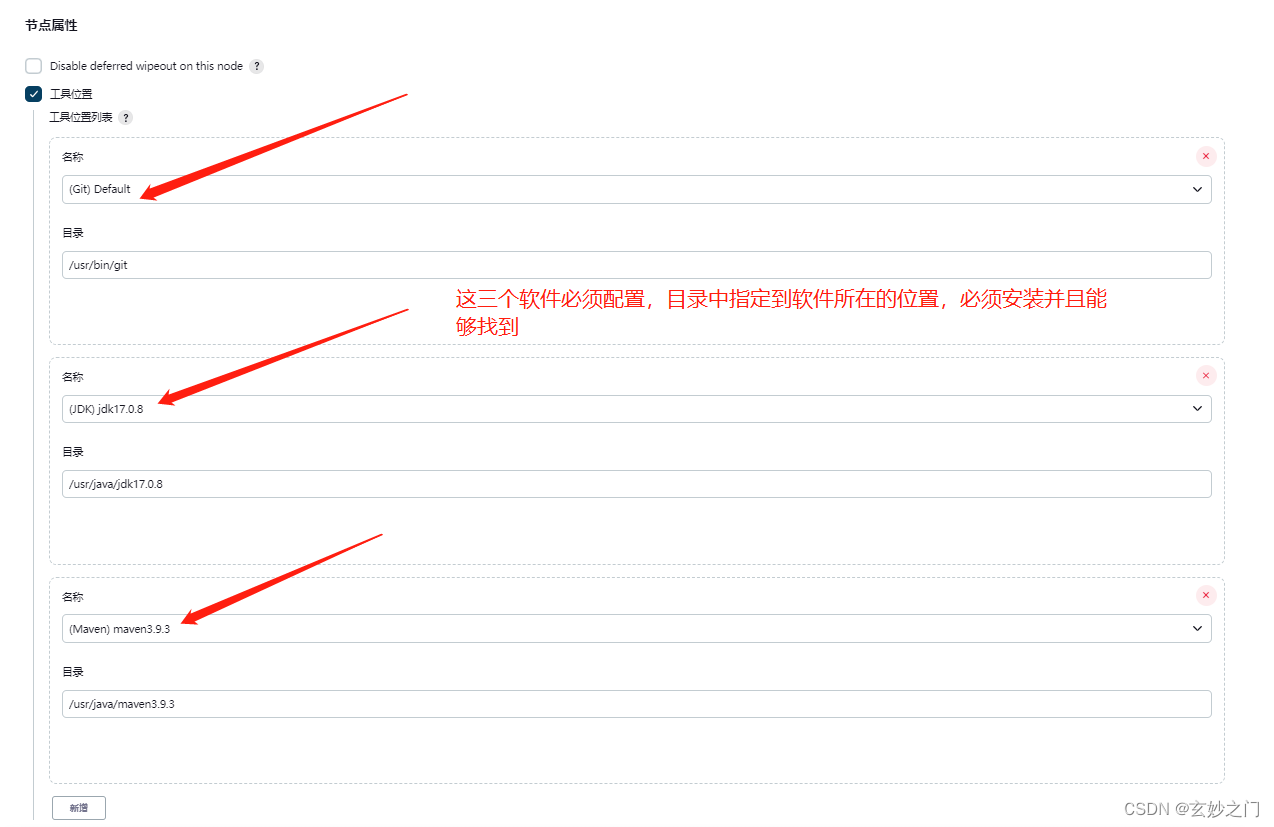
jenkins自动化构建保姆级教程(持续更新中)
1.安装 1.1版本说明 访问jenkins官网 https://www.jenkins.io/,进入到首页 点击【Download】按钮进入到jenkins下载界面 左侧显示的是最新的长期支持版本,右侧显示的是最新的可测试版本(可能不稳定),建议使用最新的…...

HTTPS 的加密流程
目录 一、HTTPS是什么? 二、为什么要加密 三、"加密" 是什么 四、HTTPS 的工作过程 1.对称加密 2.非对称加密 3.中间人攻击 4.证书 总结 一、HTTPS是什么? HTTPS (Hyper Text Transfer Protocol Secure) 是基于 HTTP 协议之上的安全协议&…...

一键切换语境+保留术语一致性+上下文感知翻译,Perplexity翻译查询功能的3大颠覆性能力,现在不用就落后了
更多请点击: https://codechina.net 第一章:Perplexity翻译查询功能的全景概览 Perplexity 的翻译查询功能并非传统意义上的“文本翻译器”,而是一种融合语义理解、上下文感知与多语言知识检索的智能问答增强机制。它允许用户以任意自然语言…...

3大AI创作效率瓶颈的模块化解法:ComfyUI企业级工作流自动化实践
3大AI创作效率瓶颈的模块化解法:ComfyUI企业级工作流自动化实践 【免费下载链接】ComfyUI The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI …...

OpCore-Simplify:如何30分钟完成专业级黑苹果配置
OpCore-Simplify:如何30分钟完成专业级黑苹果配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置而烦恼吗&#x…...

OpenArm开源机械臂终极指南:从零开始构建你的7自由度人形手臂
OpenArm开源机械臂终极指南:从零开始构建你的7自由度人形手臂 【免费下载链接】openarm A fully open-source humanoid arm for physical AI research and deployment in contact-rich environments. 项目地址: https://gitcode.com/GitHub_Trending/op/openarm …...
)
别再只会用torchvision.models了!手把手教你从零理解ResNet18的PyTorch实现(附完整代码)
从零构建ResNet18:深入理解PyTorch实现与模型定制技巧 在深度学习领域,ResNet已经成为计算机视觉任务中不可或缺的基础架构。许多开发者习惯于直接调用torchvision.models.resnet18()这一行魔法代码,却对背后的实现细节知之甚少。本文将带你从…...
)
基于 SOFAJRaft + Spring Boot 构建高可用 KV 存储集群(完整源码)
基于 SOFAJRaft + Spring Boot 构建高可用 KV 存储集群(完整源码) 引言 在分布式系统中,一致性 是核心难题。Raft 是比 Paxos 更易于理解的共识算法,而 SOFAJRaft 是蚂蚁集团开源的 Java 高性能 Raft 实现。 本文带你从零构建一个 3 节点高可用 KV 存储集群,包含完整源码、…...

LeetCode 数据流中第K大元素题解
LeetCode 数据流中第K大元素题解 题目描述 设计一个数据流,找到数据流中第 k 大的元素。 示例: 输入:k 3, arr [4,6,5]输出:5 解题思路 方法:堆 思路: 使用最小堆维护前 k 大的元素。遍历数据流ÿ…...

通过Taotoken CLI工具一键配置开发环境中的多工具API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境中的多工具API密钥 在团队协作开发或需要同时使用多个AI工具的项目中,手动为每个…...
)
别再手动折腾了!用Buildroot一键生成你的嵌入式Linux交叉工具链(附musl/glibc选型指南)
嵌入式Linux开发者的终极效率工具:Buildroot自动化工具链构建实战 在嵌入式Linux开发的世界里,搭建一个稳定可靠的交叉编译工具链往往是项目启动的第一道门槛。传统的手动配置方式不仅耗时费力,还容易因版本兼容性问题导致各种"玄学&quo…...

储能BMS HiL测试:原理、价值与工程实践全解析
1. 储能BMS HiL测试:为什么它是研发验证的“必选项”?在储能系统,尤其是大规模电池储能电站的研发过程中,电池管理系统(BMS)的可靠性与安全性是决定整个项目成败的基石。然而,传统的BMS测试方法…...