2022年AI顶级论文 —生成模型之年(上)
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理

过去十年来,人工智能技术在持续提高和飞速发展,并不断冲击着人类的认知。
-
2012年,在ImageNet图像识别挑战赛中,一种神经网络模型(AlexNet)首次展现了明显超越传统方法的能力。
-
2016年,AlphaGo在围棋这一当时人们认为其复杂性很难被人工智能系统模拟的围棋挑战赛中战胜了世界冠军。
-
2017年,Google的Ashish Vaswani等人提出了 Transformer 深度学习新模型架构,奠定了当前大模型领域主流的算法架构基础。
-
2018年,谷歌提出了大规模预训练语言模型 BERT,该模型是基于 Transformer 的双向预训练模型,其模型参数首次超过了3亿(BERT-Large约有3.4个参数);同年,OpenAI提出了生成式预训练 Transformer 模型——GPT,大大地推动了自然语言处理领域的发展。
-
2018年,人工智能团队OpenAI Five战胜了世界顶级的Dota 2人类队伍,人工智能在复杂任务领域树立了一个新的里程碑;此后在2018年底,Google DeepMind团队提出的AlphaFold以前所未有的准确度成功预测了人类蛋白质结构,突破了人们对人工智能在生物学领域的应用的想象。
-
2019年,一种人工智能系统AlphaStar在2019年击败了世界顶级的StarCraft II人类选手,为人工智能在复杂任务领域的未来发展提供了有力的证明和支持。
-
2020年,随着OpenAI GPT-3模型(模型参数约1750亿)的问世,在众多自然语言处理任务中,人工智能均表现出超过人类平均水平的能力。
-
2021年1月,Google Brain提出了Switch Transformer模型,以高达1.6万亿的参数量成为史上首个万亿级语言模型;同年12月,谷歌还提出了1.2亿参数的通用稀疏模型GLaM,在多个小样本学习任务的性能超过GPT-3。
-
2022年2月,人工智能生成内容(AIGC)技术被《MIT Technology Review》评选为2022年全球突破性技术之一。同年8月,Stability AI开源了文字转图像的Stable Diffusion模型。也是在8月,艺术家杰森·艾伦(Jason Allen)利用AI工具制作的绘画作品《太空歌剧院》(Théâtre D’opéra Spatial),荣获美国科罗拉多州艺术博览会艺术竞赛冠军,相关技术于年底入选全球知名期刊《Science》年度科技突破(Breakthrough of the Year 2022)第2名。
今年,我们看到生成模型领域取得了重大进展。Stable Diffusion 🎨 创造超现实主义艺术。ChatGPT 💬 回答关于生命意义的问题。Galactica🧬 学习人类科学知识的同时也揭示了大型语言模型的局限性。本文涵盖了 2022 年 20 篇最具影响力的 AI 论文,但是这篇文章绝不是详尽无遗的,今年有很多很棒的论文——我最初想列出 10 篇论文,但最后却列出了 20 篇,其中涵盖不同主题的论文,例如生成模型(稳定扩散、ChatGPT)、AI 代理(MineDojo、Cicero)、3D 视觉(即时NGP、Block-NeRF)和新的state-of-the-基本 AI 任务中的艺术(YOLOv7,Whisper)。
1. Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL-E 2)
具有 CLIP 潜能的分层文本条件图像生成 (DALL-E 2)
作者:Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen
文章链接:https://arxiv.org/abs/2204.06125


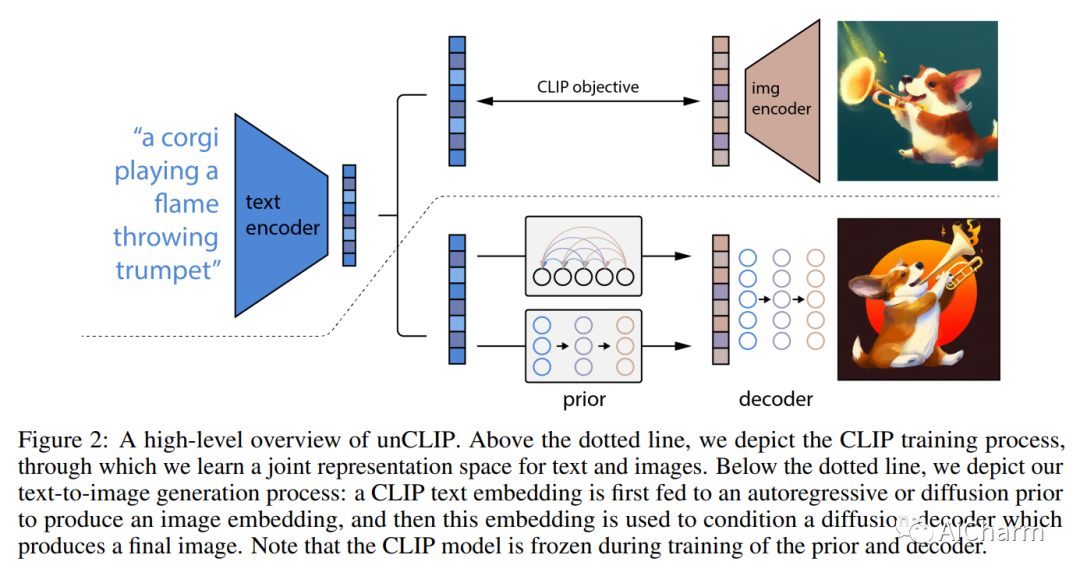
简介
CLIP 等对比模型已被证明可以学习捕获语义和风格的图像的稳健表示。为了利用这些表示来生成图像,我们提出了一个两阶段模型:一个在给定文本标题的情况下生成 CLIP 图像嵌入的先验模型,以及一个以图像嵌入为条件生成图像的解码器。我们表明,显式生成图像表示可以提高图像多样性,同时将真实感和字幕相似性的损失降到最低。我们以图像表示为条件的解码器还可以生成图像的变体,同时保留其语义和风格,同时改变图像表示中不存在的非必要细节。此外,CLIP 的联合嵌入空间能够以零样本的方式进行语言引导的图像操作。我们对解码器使用扩散模型,并对先验模型使用自回归模型和扩散模型进行实验,发现后者在计算上更高效并产生更高质量的样本。
DALL-E 2 通过使用两阶段模型提高了 DALL-E 文本到图像生成功能的真实性、多样性和计算效率。DALL-E 2 首先在给定文本标题的情况下生成 CLIP 图像嵌入,然后使用基于扩散的解码器生成以图像嵌入为条件的图像。
2. High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion)
具有潜在扩散模型的高分辨率图像合成(稳定扩散)
作者:Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
文章链接:https://arxiv.org/abs/2112.10752

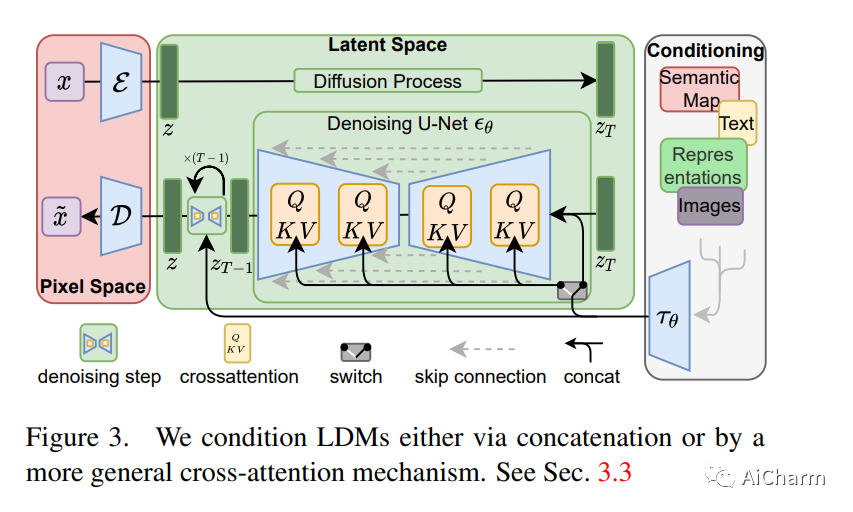

简介
通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型 (DM) 在图像数据及其他数据上实现了最先进的合成结果。此外,他们的公式允许一种引导机制来控制图像生成过程而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,因此强大的 DM 的优化通常会消耗数百个 GPU 天,并且由于顺序评估,推理非常昂贵。为了在有限的计算资源上启用 DM 训练,同时保持其质量和灵活性,我们将它们应用于强大的预训练自动编码器的潜在空间。与以前的工作相比,在这种表示上训练扩散模型首次允许在复杂性降低和细节保留之间达到接近最佳点,从而大大提高了视觉保真度。通过在模型架构中引入交叉注意力层,我们将扩散模型转变为强大而灵活的生成器,用于一般条件输入(例如文本或边界框),并且以卷积方式进行高分辨率合成成为可能。我们的潜在扩散模型 (LDM) 实现了图像修复的最新技术水平和在各种任务上的极具竞争力的性能,包括无条件图像生成、语义场景合成和超分辨率,同时与基于像素的 DM 相比显着降低了计算要求。
Stable Diffusion 使用扩散概率模型实现程式化和逼真的文本到图像生成。凭借其开源的模型和权重,Stable Diffusion 启发了无数文本到图像的社区和初创公司。
3. LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models
LAION-5B:用于训练下一代图像文本模型的开放式大规模数据集
作者:Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, Jenia Jitsev
文章链接:https://arxiv.org/abs/2210.08402
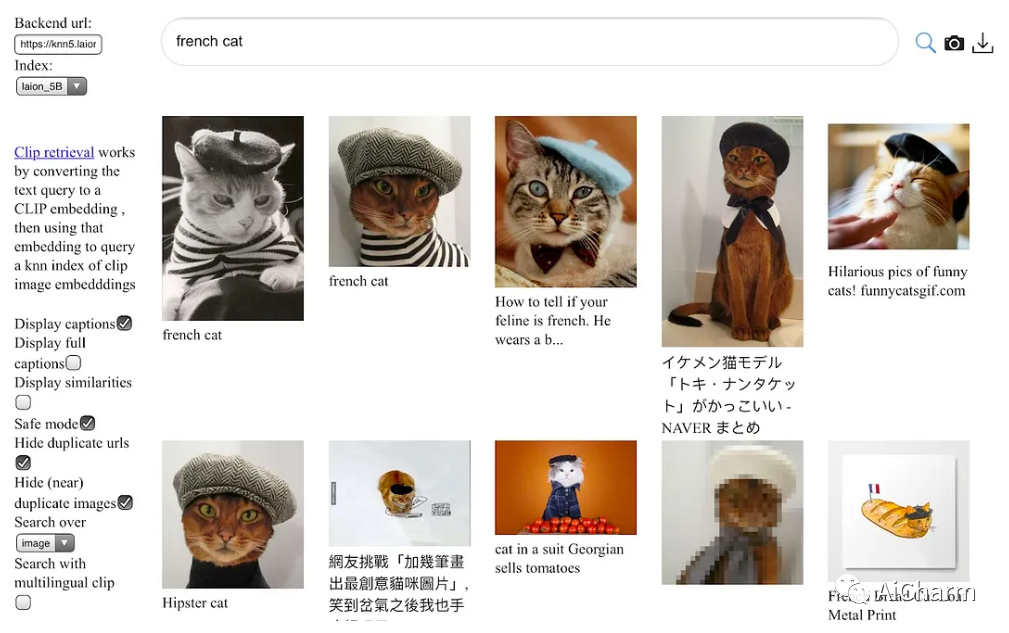
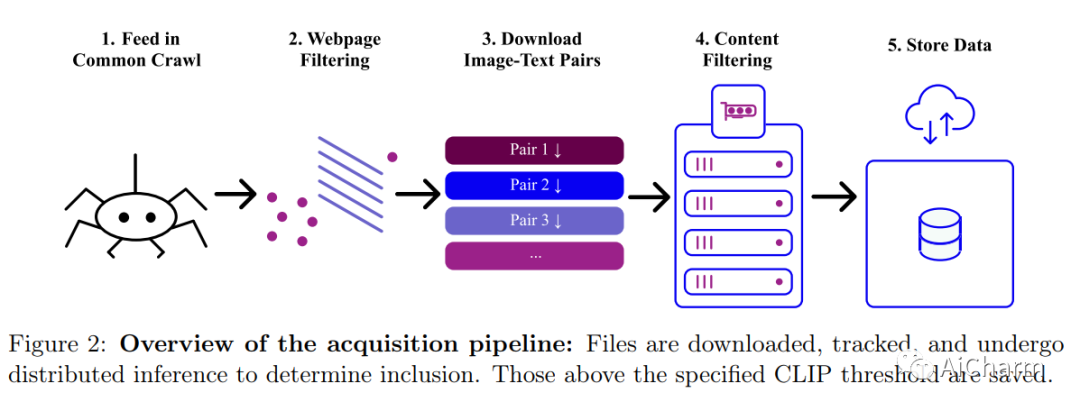

简介
CLIP 和 DALL-E 等开创性的语言视觉架构证明了在大量嘈杂的图像文本数据上进行训练的实用性,而不依赖于标准视觉单峰监督学习中使用的昂贵的准确标签。由此产生的模型显示出强大的文本引导图像生成和传输到下游任务的能力,同时在零样本分类方面表现出色,具有值得注意的分布外鲁棒性。此后,ALIGN、BASIC、GLIDE、Flamingo 和 Imagen 等大型语言视觉模型有了进一步的改进。研究此类模型的训练和功能需要包含数十亿图像文本对的数据集。到目前为止,还没有这种规模的数据集可供更广泛的研究社区公开使用。为了解决这个问题并使大规模多模态模型的研究民主化,我们提出了 LAION-5B——一个由 58.5 亿个 CLIP 过滤的图像文本对组成的数据集,其中 2.32B 包含英语。我们使用数据集展示了 CLIP、GLIDE 和 Stable Diffusion 等基础模型的成功复制和微调,并讨论了使用这种规模的公开可用数据集启用的进一步实验。此外,我们还提供了几个最近邻索引、用于数据集探索和子集生成的改进 Web 界面,以及水印、NSFW 和有毒内容检测的检测分数。
4. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
一张图片胜过一个字:使用文本反转个性化文本到图像的生成
作者:Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or
文章链接:https://arxiv.org/abs/2208.01618

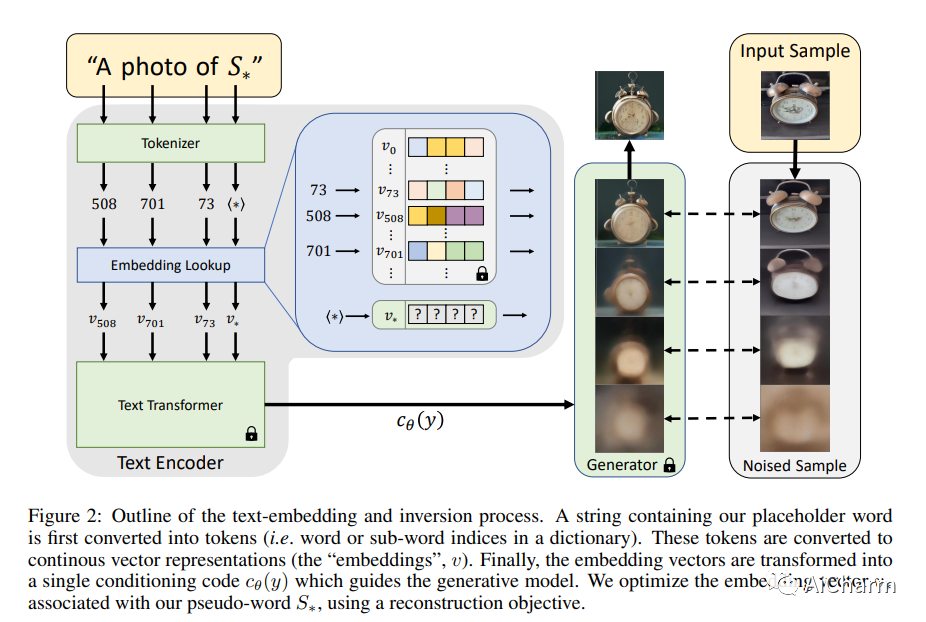

简介
文本到图像模型提供了前所未有的自由度,可以通过自然语言来指导创作。然而,尚不清楚如何行使这种自由来生成特定独特概念的图像、修改它们的外观或将它们组合成新角色和新场景。换句话说,我们问:我们如何使用语言引导模型将我们的猫变成一幅画,或者根据我们最喜欢的玩具想象一个新产品?在这里,我们提出了一种允许这种创造性自由的简单方法。仅使用用户提供的概念(如对象或样式)的 3-5 张图像,我们学习通过冻结文本到图像模型的嵌入空间中的新“词”来表示它。这些“词”可以组合成自然语言的句子,以直观的方式指导个性化创作。值得注意的是,我们发现有证据表明单个词嵌入足以捕获独特而多样的概念。我们将我们的方法与广泛的基线进行比较,并证明它可以更忠实地描绘一系列应用程序和任务中的概念。
5. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
DreamBooth:为主题驱动生成微调文本到图像扩散模型
作者:Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
文章链接:https://arxiv.org/abs/2208.12242

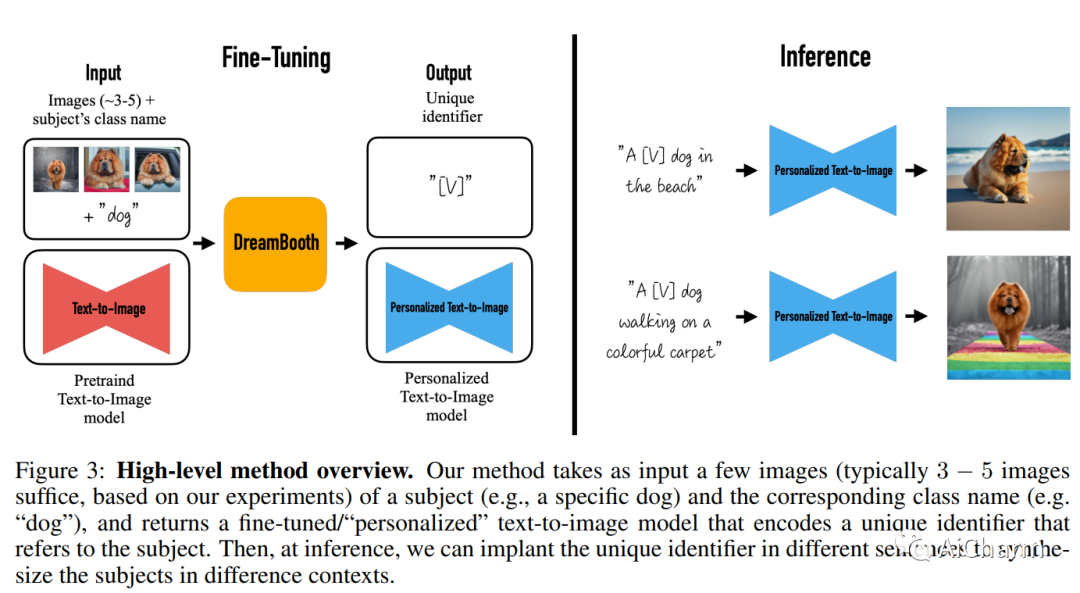
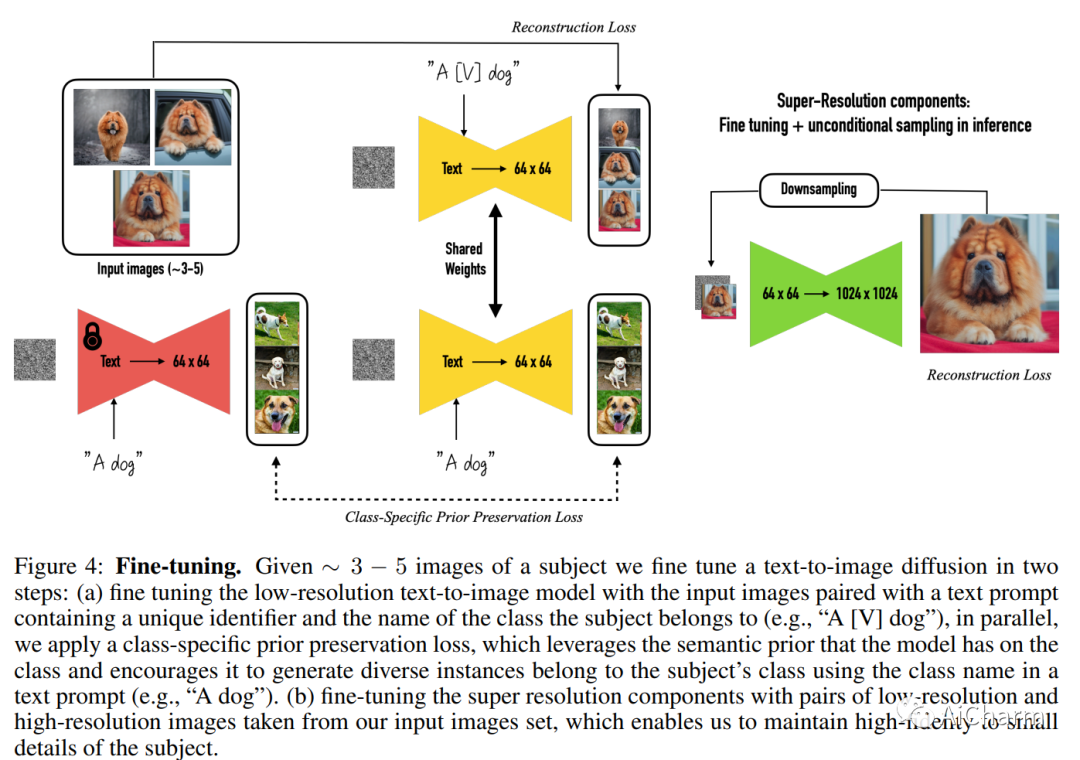
简介
大型文本到图像模型实现了 AI 发展的显着飞跃,能够根据给定的文本提示合成高质量和多样化的图像。然而,这些模型缺乏在给定参考集中模仿对象外观以及在不同上下文中合成它们的新颖演绎的能力。在这项工作中,我们提出了一种新的文本到图像扩散模型的“个性化”方法(根据用户的需求对其进行专门化)。给定主题的几张图像作为输入,我们微调预训练的文本到图像模型(Imagen,尽管我们的方法不限于特定模型),以便它学会将唯一标识符与该特定主题绑定.一旦主体被嵌入到模型的输出域中,唯一标识符就可以用于合成主体在不同场景中的全新逼真图像。通过利用模型中嵌入的语义先验和新的自生类特定先验保存损失,我们的技术能够在参考图像中没有出现的不同场景、姿势、视图和光照条件下合成主体。我们将我们的技术应用于几个以前无懈可击的任务,包括主题重新上下文化、文本引导视图合成、外观修改和艺术渲染(同时保留主题的关键特征)。
DreamBooth 是一种微调文本到图像模型以了解特定主题的技术,以便生成包含该主题的新图像。例如,用户可以让文本到图像模型了解他们的小狗,并生成他们的小狗理发的新图像。
6. Make-A-Video: Text-to-Video Generation without Text-Video Data
制作视频:没有文本视频数据的文本到视频生成
作者:Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, Yaniv Taigman
文章链接:https://arxiv.org/abs/2209.14792

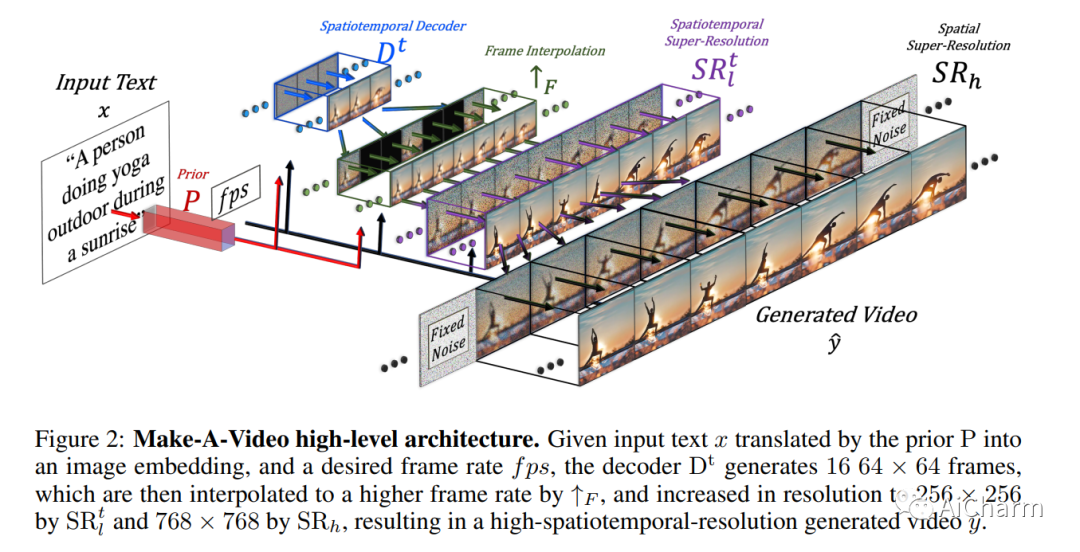
简介
我们提出制作视频——一种直接将文本到图像 (T2I) 生成的巨大最新进展转化为文本到视频 (T2V) 的方法。我们的直觉很简单:从成对的文本图像数据中了解世界是什么样子以及它是如何描述的,并从无监督的视频片段中了解世界是如何移动的。Make-A-Video 具有三个优点:(1)它加速了 T2V 模型的训练(它不需要从头开始学习视觉和多模态表示),(2)它不需要成对的文本视频数据,以及(3 ) 生成的视频继承了当今图像生成模型的广泛性(审美多样性、奇幻描绘等)。我们设计了一种简单而有效的方法来构建具有新颖有效的时空模块的 T2I 模型。首先,我们分解完整的时间 U-Net 和注意力张量,并在空间和时间上对它们进行近似。其次,我们设计了一个时空管道来生成高分辨率和帧率视频,其中包含一个视频解码器、插值模型和两个超分辨率模型,可以实现除 T2V 之外的各种应用。在空间和时间分辨率、对文本的忠实度和质量的所有方面,Make-A-Video 都设置了文本到视频生成的最新技术水平,这由定性和定量指标决定。
7. FILM: Frame Interpolation for Large Motion
电影:大运动的帧插值
作者:Fitsum Reda, Janne Kontkanen, Eric Tabellion, Deqing Sun, Caroline Pantofaru, Brian Curless
文章链接:https://arxiv.org/abs/2202.04901

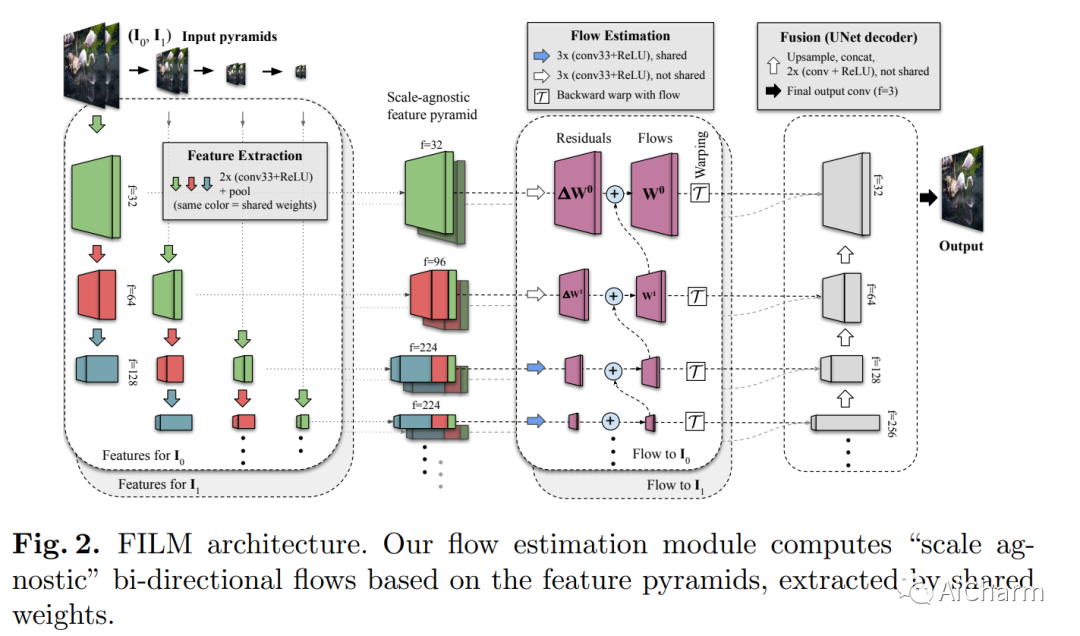

简介
我们提出了一种帧插值算法,该算法从具有大中间运动的两个输入图像合成多个中间帧。最近的方法使用多个网络来估计光流或深度,并使用一个专用于帧合成的单独网络。这通常很复杂,需要稀缺的光流或深度地面实况。在这项工作中,我们提出了一个单一的统一网络,以多尺度特征提取器为特征,该特征提取器在所有尺度上共享权重,并且可以单独从帧进行训练。为了合成清晰悦目的帧,我们建议使用衡量特征图之间相关性差异的 Gram 矩阵损失来优化我们的网络。我们的方法在 Xiph 大运动基准测试中优于最先进的方法。与使用感知损失的方法相比,我们在 Vimeo-90K、Middlebury 和 UCF101 上也取得了更高的分数。我们研究了权重共享和使用增加运动范围的数据集进行训练的效果。最后,我们展示了我们的模型在具有挑战性的近乎重复的照片数据集上合成高质量和时间连贯视频的有效性。此 https URL 提供代码和预训练模型。
相关文章:
2022年AI顶级论文 —生成模型之年(上)
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 过去十年来,人工智能技术在持续提高和飞速发展,并不断冲击着人类的认知。 2012年,在ImageNet图像识别挑战赛中,一种神经网络模型(AlexNet&…...
Linux下程序调试的方法【GDB】GDB相关命令和基础操作(命令收藏)
目录 1、编译 2、启动gdb调试 2.1 直接运行 2.2 运行gdb后使用run命令 2.3 调试已运行的程序 3、图形界面提示 4、调试命令 1、查看源码 2、运⾏程序/查看运⾏信息 3、设置断点 5、单步/跳步执⾏ 6、分割窗口 7、其他命令 8、相关参数 1、编译 在编译时要加上-g选…...
使用frp配置内网机器访问
frp简介 frp 是一个开源、简洁易用、高性能的内网穿透和反向代理软件,支持 tcp, udp, http, https等协议。frp 项目官网是 https://github.com/fatedier/frp,软件下载地址为https://github.com/fatedier/frp/releases frp工作原理 服务端运行…...

简述7个流行的强化学习算法及代码实现!
目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。这些算法已被用于在游戏、机器人和决策制定等各种应用中,并且这些流行的算法还在不断发展和改进,本文我们将对其做一个简单的介绍。1、Q-learningQ-learning:Q-…...

朗润国际期货招商:地方政府工作报告中对于促进消费
地方政府工作报告中对于促进消费 北京:把恢复和扩大消费摆在优先位置。加紧推进国际消费中心城市建设、深化商圈改造提升行动、统筹推进物流基地规划建设,强化新消费地标载体建设、试点建设80个“一刻钟便民生活圈”,提高生活性服务重品质。…...

前端性能优化的一些技巧(90% chatGpt生成)
终于弄好了chatGpt的账号,赶紧来体验一波。先来一波结论,这篇文章的主要内容来源,90%是用chatGpt生成的。先上chatGpt的生成的结果:作为一名懒惰的程序员,chatGpt会帮助我变得更懒...,好了下面开始文章的正…...
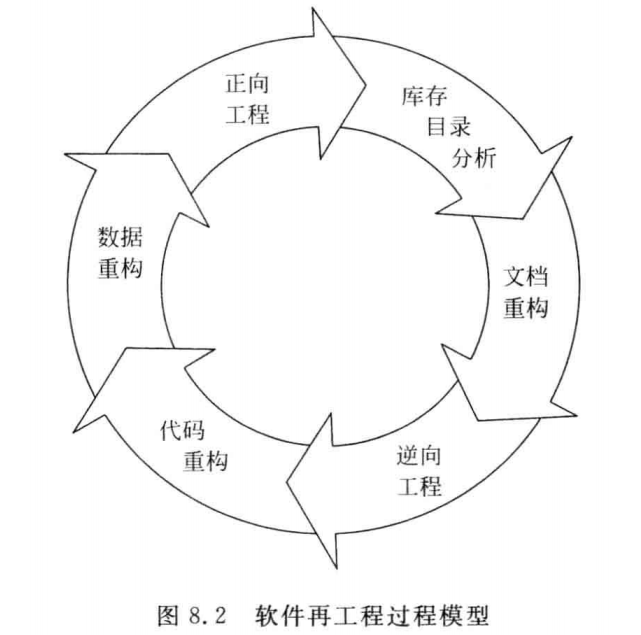
[软件工程导论(第六版)]第8章 维护(复习笔记)
文章目录8.1 软件维护的定义8.2 软件维护的特点8.3 软件维护过程8.4 软件的可维护性8.5 预防性维护8.6 软件再工程过程维护的基本任务:保证软件在一个相当长的时期能够正常运行软件工程的主要目的就是要提高软件的可维护性,减少软件维护所需要的工作量&a…...
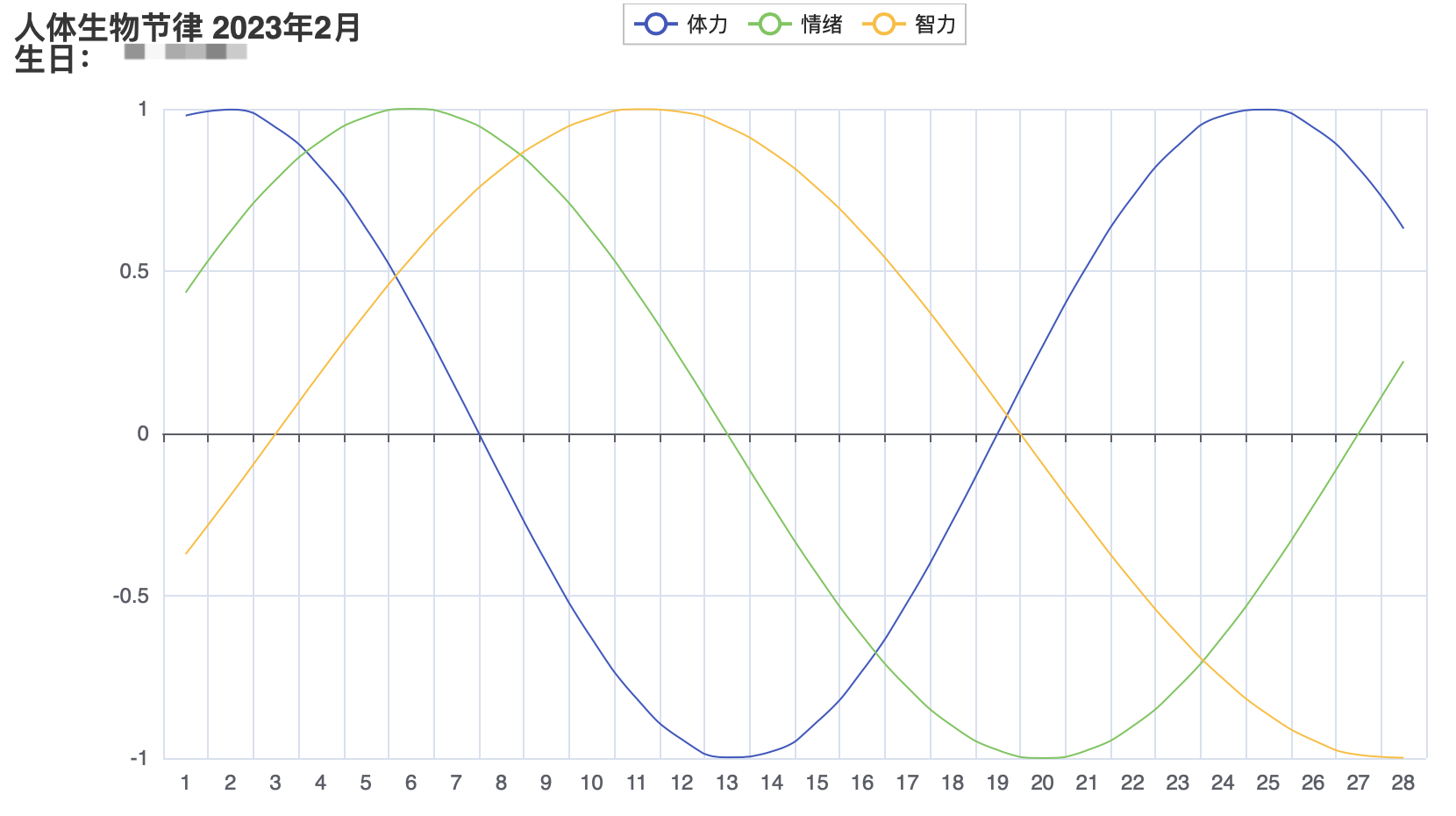
Python - 绘制人体生物节律
文章目录项目说明关于人体生物节律用到的技术代码实现获取每月有多少天计算每天到生日过了多少天计算节律绘图结果项目说明 这里仿照 http://www.4qx.net/The_Human_Body_Clock.php 做一个人体生物节律的计算和展示 关于人体生物节律 百度/维基百科 解释 https://zh.wikiped…...

【NVMEM子系统】二、NVMEM驱动框架
个人主页:董哥聊技术我是董哥,嵌入式领域新星创作者创作理念:专注分享高质量嵌入式文章,让大家读有所得!文章目录1、前言2、驱动框架3、源码目录结构4、用户空间下的目录结构1、前言 NVMEM SUBSYSTEM,该子系…...
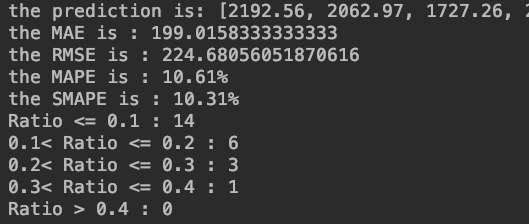
小波神经网络(WNN)的实现(Python,附源码及数据集)
文章目录一、理论基础1、小波神经网络结构2、前向传播过程3、反向传播过程4、建模步骤二、小波神经网络的实现1、训练过程(WNN.py)2、测试过程(test.py)3、测试结果4、参考源码及实验数据集一、理论基础 小波神经网络(…...

商标干货!所有企业都值得收藏!
商标,是用于识别和区分不同商品或服务来源的标志,代表了企业的产品质量和服务保证,可以说,商标承载了一个企业的信誉,是企业参与市场竞争的重要工具,对于企业及其产品的重要性不言而喻。 根据《商标法》四十…...

4次迭代,让我的 Client 优化 100倍!泄漏一个 人人可用的极品方案!
4次迭代,让我的HttpClient提速100倍 在大家的生产项目中,经常需要通过Client组件(HttpClient/OkHttp/JDK Connection)调用第三方接口。 尼恩的一个生产项目也不例外。 在一个高并发的中台生产项目中。有一个比较特殊的请求,一次…...

并查集(高级数据结构)-蓝桥杯
一、并查集并查集(Disioint Set):一种非常精巧而实用的数据结构用于处理不相交集合的合并问题。用于处理不相交集合的合并问题。经典应用:连通子图。最小生成树Kruskal算法。最近公共祖先。二、应用场景有n个人,他们属于不同的帮派。 已知这些…...
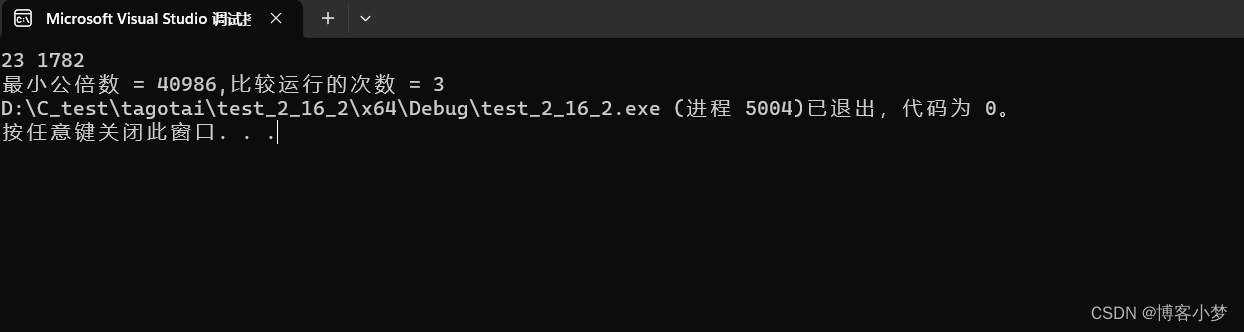
你是真的“C”——C语言详解求两个正数最小公倍数的3种境界
C语言详解求两个正数最小公倍数的3种境界~😎前言🙌必备小知识~😘求最小公倍数境界1~ 😊求最小公倍数境界2~ 😊求最小公倍数境界3~ 😊总结撒花💞博客昵称:博客小梦😊 最喜…...

【java】Spring Cloud --Feign Client超时时间配置以及单独给某接口设置超时时间方法
文章目录feign配置(最常用)ribbon配置hystrix配置单独给某接口设置超时时间FeignClient面对服务级有三种超时时间配置feign配置(最常用) feign:sentinel:enabled: trueclient:config:default://全部服务配置connectTimeout: 5000…...

spark代码
RDD Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80 该系总共有多少学生; val lines sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt") val par lines.map(ro…...
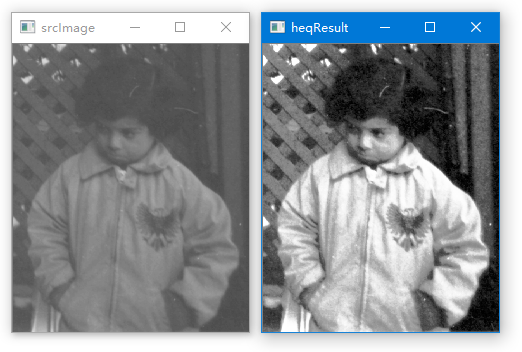
利用OpenCV的函数equalizeHist()对图像作直方图均衡化处理
如果一幅图像的灰度值集中在某个比较窄的区域,则图像的对比度会显得比较小,不便于对图像的分析和处理。 图像的直方图均衡化可以实现将原图像的灰度值范围扩大,这样图像的对比度就得到了提高,从而方便对图像进行后续的分析和处理…...

星河智联Android开发
背景:朋友内推,过了一周约面。本人 2019年毕业 20230208一面 1.自我介绍 2.为啥换工作 3.项目经历(中控面板、智能音箱、语音问的比较细) 4.问题 Handler机制原理?了解同步和异步消息吗?View事件分发…...

【C++】关联式容器——map和set的使用
文章目录一、关联式容器二、键值对三、树形结构的关联式容器1.set2.multiset3.map4.multimap四、题目练习一、关联式容器 序列式容器📕:已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C11)等,这些容器统称为…...

Promise的实现原理
作用:异步问题同步化解决方案,解决回调地狱、链式操作原理: 状态:pending、fufilled reject构造函数传入一个函数,resolve进入then,reject进入catch静态方法:resolve reject all any react ne…...

AI的恶意使用
AI 生成的内容与犯罪活动:人工智能系统正被滥用于生成诈骗、欺诈、敲诈勒索及未经同意的私密影像。尽管此类伤害的发生已有充分记录,但关于其发生率和严重程度的系统性数据仍然有限。 影响和操纵:在实验环境中,AI 生成的内容在改变…...

3大核心功能解锁植物大战僵尸无限可能:PvZ Toolkit完全指南
3大核心功能解锁植物大战僵尸无限可能:PvZ Toolkit完全指南 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 你是否曾在植物大战僵尸的生存模式中苦于资源不足?是否想过保存完…...

如何用Mask2Former实现通用图像分割:从单一模型到多任务实战
如何用Mask2Former实现通用图像分割:从单一模型到多任务实战 【免费下载链接】Mask2Former Code release for "Masked-attention Mask Transformer for Universal Image Segmentation" 项目地址: https://gitcode.com/gh_mirrors/ma/Mask2Former 图…...

当FileZilla遇见AI:用快马平台打造能听懂人话的智能文件传输助手
今天想和大家分享一个有趣的实践:如何用AI给传统的FTP工具FileZilla"装上大脑",让它变成一个能听懂人话的智能文件传输助手。这个想法源于我日常工作中频繁的文件传输需求,每次手动分类、压缩、检查敏感内容实在太费时间了。 智能文…...

OpenClaw+SecGPT-14B技能扩展:自动化渗透测试报告生成
OpenClawSecGPT-14B技能扩展:自动化渗透测试报告生成 1. 为什么需要自动化渗透测试报告 每次红队演练结束后,最让我头疼的就是整理渗透测试报告。传统流程需要手动整理Nmap扫描结果、Burp Suite截图、漏洞验证步骤,再粘贴到Word模板里调整格…...

PixEz-flutter全链路网络可靠性架构实战:从数据同步到动态优化
PixEz-flutter全链路网络可靠性架构实战:从数据同步到动态优化 【免费下载链接】pixez-flutter 一个支持免代理直连及查看动图的第三方Pixiv flutter客户端 项目地址: https://gitcode.com/gh_mirrors/pi/pixez-flutter 在移动应用开发中,网络请求…...

广州SEO优化服务有哪些
广州SEO优化服务:全面提升网站排名的关键策略 在当前竞争激烈的互联网环境中,广州SEO优化服务显得尤为重要。搜索引擎优化(SEO)不仅能够提高网站在搜索结果中的排名,还能有效地吸引更多的潜在客户。广州SEO优化服务有…...

企业SEO网站推广的优势和劣势有哪些
企业SEO网站推广的优势分析 在当今互联网时代,企业SEO网站推广已经成为一种必不可少的数字营销手段。无论是中小企业还是大型企业,都在竞争激烈的市场中寻找最佳的方式来提升品牌知名度和销售额。企业SEO网站推广究竟有哪些优势呢?以下将从几…...

别再手动算坐标了!用Python的coord-convert库5分钟搞定高德/百度/WGS84互转
别再手动算坐标了!用Python的coord-convert库5分钟搞定高德/百度/WGS84互转 你是否曾在处理地理数据时,被不同地图平台的坐标系搞得焦头烂额?GPS设备采集的WGS84坐标无法直接在高德地图上显示,百度地图的坐标又和微信小程序不兼容…...

告别重复劳动:用快马平台集成codex,自动生成模型与api代码提升效率
作为一名经常需要开发用户管理系统的开发者,我深刻体会到重复编写基础代码的繁琐。最近在InsCode(快马)平台尝试了集成codex模型的功能,发现它能显著提升开发效率。下面分享我的实践过程: 用户数据模型生成 传统方式需要手动定义每个字段类型…...