Flink、Yarn架构,以Flink on Yarn部署原理详解
Flink、Yarn架构,以Flink on Yarn部署原理详解
Flink 架构概览
Apache Flink是一个开源的分布式流处理框架,它可以处理实时数据流和批处理数据。Flink的架构原理是其实现的基础,架构原理可以分为以下四个部分:JobManager、TaskManager、JobGraph、Checkpoint。
-
JobManager
JobManager是Flink集群的控制节点,负责接收用户提交的任务,将任务分配给TaskManager进行执行,并监控任务的执行状态。JobManager还负责保存和恢复Flink应用程序的状态信息,以及维护JobGraph,对任务进行调度和优化。
-
TaskManager
TaskManager是Flink集群的工作节点,负责执行由JobManager分配的任务。每个TaskManager可以执行多个任务,每个任务对应一个或多个并行的TaskSlot。TaskSlot是TaskManager中的一个线程池,它负责执行任务的具体业务逻辑。TaskManager还负责将任务的状态信息发送给JobManager,以便JobManager能够监控任务的执行状态。
-
JobGraph
JobGraph是Flink应用程序的执行图,它描述了任务之间的依赖关系和数据流向。JobGraph由JobManager维护,它包含了所有任务的信息,包括任务的输入输出、并行度、任务类型等等。JobManager在接收到用户提交的任务后,会将任务解析成JobGraph,然后对JobGraph进行调度和优化,最终将任务分配到TaskManager上执行。
-
Checkpoint
Checkpoint是Flink用于实现容错机制的重要组成部分。Flink支持两种类型的Checkpoint:精确一次(Exactly Once)和至少一次(At Least Once)。Checkpoint会在任务执行过程中周期性地将任务状态信息保存到持久化存储中,以确保在任务失败或系统故障时能够恢复任务状态。在Flink中,Checkpoint的实现采用了异步快照机制,即在Checkpoint过程中不会阻塞任务的执行,从而保证任务的高吞吐量和低延迟。
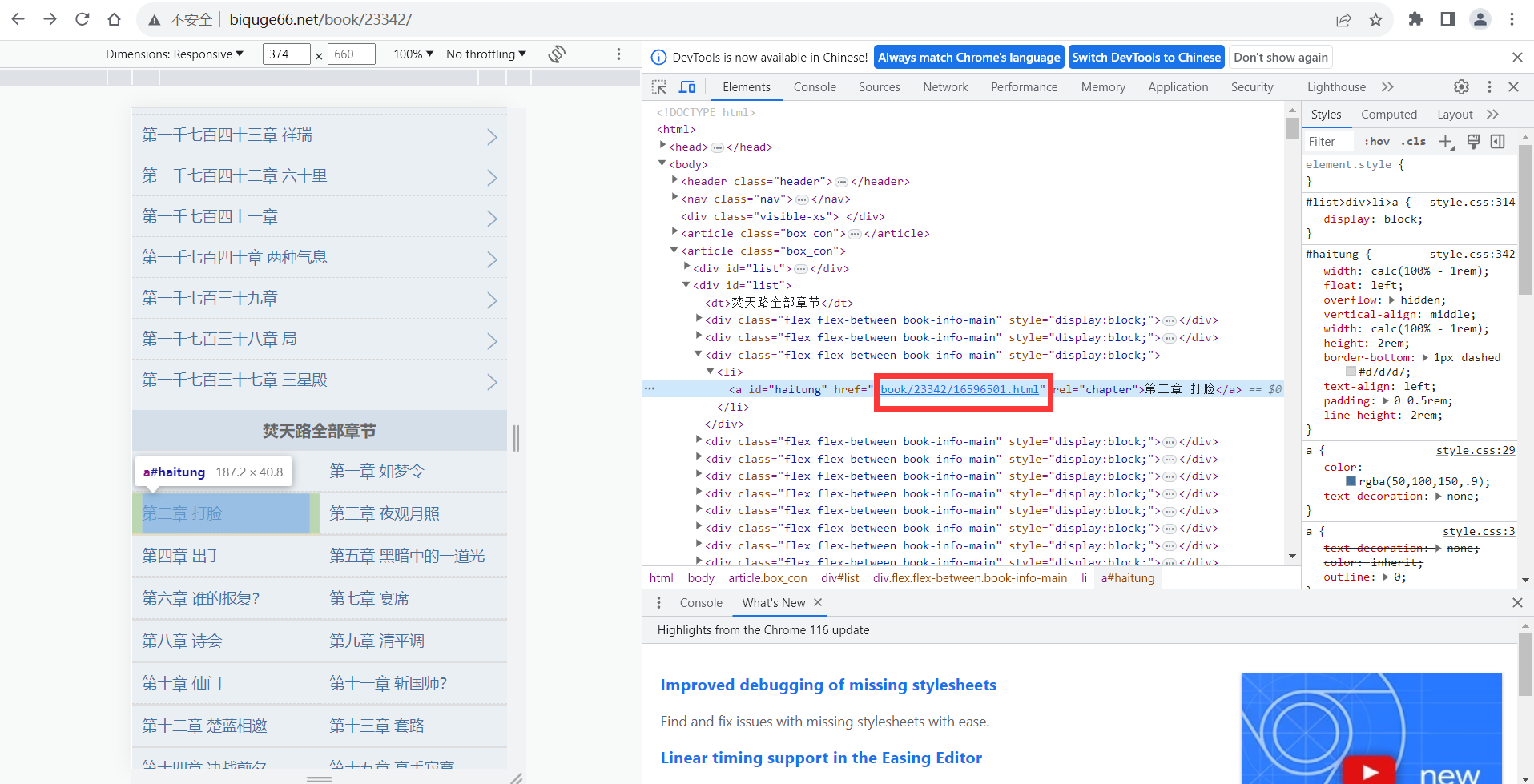
用户通过 DataStream API、DataSet API、SQL 和 Table API 编写 Flink 任务,它会生成一个 JobGraph。JobGraph 是由 source、map()、keyBy()、window()、apply()和 sink 等算子组成的。当 JobGraph 提交给 Flink 集群后,能够以 Local、Standalone、Yarn 和kubernetes 四种模型运行。

接下来,深入关注Flink中两个关键组件:JobManager和TaskManager
JobManager架构

JobManager是Flink集群的控制节点,负责接收用户提交的任务,将任务分配给TaskManager进行执行,并监控任务的执行状态。
Flink JobManager架构原理的核心是JobMaster和ResourceManager,其中JobMaster负责任务的调度和监控,ResourceManager负责集群资源的管理。JobMaster和ResourceManager之间通过RPC通信进行交互。
JobMaster主要负责以下几个方面:
- 任务管理
JobMaster负责接收用户提交的任务,并将任务转换为JobGraph。JobGraph是Flink应用程序的执行图,它描述了任务之间的依赖关系和数据流向。JobMaster会对JobGraph进行优化和调度,并将任务分配给TaskManager进行执行。
- 任务监控
JobMaster会监控任务的执行状态,包括任务的启动、暂停、恢复和取消等操作。如果任务执行失败,JobMaster会重新分配任务,或者通知用户进行处理。
- 状态管理
Flink支持任务的状态管理和恢复,JobMaster负责保存和恢复任务的状态信息。在任务执行过程中,JobMaster会周期性地将任务状态信息保存到持久化存储中,以确保在任务失败或系统故障时能够恢复任务状态。
- 高可用性
为了保证JobMaster的高可用性,Flink采用了主备模式。即在Flink集群中,有一个主JobMaster和若干备JobMaster。当主JobMaster发生故障时,备JobMaster会接管任务的管理和调度。
TaskManager架构

Flink TaskManager架构原理的核心是TaskExecutor和Slot,其中TaskExecutor是Flink集群中的工作节点,负责执行任务,Slot是TaskExecutor中的任务执行单元,用于执行任务的并发执行。
TaskExecutor是Flink集群中的工作节点,它是执行Flink任务的基本单元。一个Flink TaskExecutor节点可以运行多个Slot,每个Slot是TaskExecutor中的任务执行单元,用于执行任务的并发执行。
在Flink任务启动时,JobManager会将任务的JobGraph分配给一组TaskManager节点,每个TaskManager节点会启动一个或多个TaskExecutor进程。在TaskExecutor进程启动时,会为每个Slot创建一个独立的线程池,用于执行任务。
Slot是TaskExecutor中的任务执行单元,每个Slot都可以同时执行一个任务。任务被分配给Slot后,Slot会启动一个线程来执行任务,从输入数据流中读取数据,并将处理结果输出到输出数据流中。
每个Slot都有自己的资源限制,包括CPU、内存、网络等资源。任务的执行会根据资源限制进行调度,以达到最优的资源利用率。当任务执行结束后,Slot会释放资源,以供其他任务使用。
Flink支持任务的动态调整,包括任务的扩容和缩容。当任务需要更多的资源时,Flink可以动态地增加TaskExecutor节点来满足任务的需求。反之,当任务执行结束后,Flink会回收空闲的TaskExecutor节点,以节省资源。
TaskManager主要负责以下功能:
-
执行任务
TaskManager负责接收来自JobManager的任务,并将任务分配到Task执行器中执行。每个TaskManager可以运行一个或多个任务。
-
管理任务状态
TaskManager负责管理任务的状态和执行上下文,并向JobManager报告任务的状态。
-
数据交换
TaskManager中的网络组件负责数据交换。它负责将数据从一个TaskManager发送到另一个TaskManager,并将数据发送到JobManager。
-
管理资源
TaskManager负责管理其本地资源,例如内存和CPU资源,并确保任务在可用资源范围内运行。
-
高可用性
TaskManager支持高可用性。如果一个TaskManager失败,Flink会将其上运行的任务重新分配到其他TaskManager上,以确保任务继续执行。
Yarn架构概览
Yarn 架构原理 - 总览

YARN(Yet Another Resource Negotiator)是Hadoop生态系统中的一个重要组件,它是一个资源管理系统,负责管理Hadoop集群中的资源和任务。本文将详细介绍YARN中ResourceManager、NodeManager、ApplicationMaster和Container组件的实现原理。
- ResourceManager
ResourceManager是YARN中最重要的组件之一。它是集群资源的总管,负责处理客户端应用程序的资源请求,以及为应用程序分配资源。ResourceManager主要有以下几个组件:
- Scheduler:Scheduler负责为应用程序分配资源,它根据应用程序的需求和集群的可用资源进行调度。Scheduler会考虑各个应用程序的优先级,以及应用程序对资源的需求量等因素。
- ApplicationManager:ApplicationManager负责管理应用程序的生命周期,包括应用程序的提交、启动、停止和监控等。它还负责向Scheduler提交应用程序的资源请求,并获取Scheduler分配的资源。
- NodeManager
NodeManager是YARN中运行在每台机器上的组件,它负责管理单个节点上的资源。NodeManager主要有以下几个组件:
- ContainerExecutor:ContainerExecutor负责启动和管理容器。容器是YARN中运行应用程序的基本单位,每个容器包含一个或多个任务。
- ApplicationMasterLauncher:ApplicationMasterLauncher负责启动ApplicationMaster。ApplicationMaster是应用程序的管理器,它负责协调应用程序的各个任务,以及与ResourceManager交互。
- NodeStatusUpdater:NodeStatusUpdater负责向ResourceManager汇报节点的状态,包括节点的可用资源、健康状况等。
- ApplicationMaster
ApplicationMaster是YARN中应用程序的管理器,运行在 Slave 上,它负责数据切分,申请资源和分配、任务监控和容错,以及与ResourceManager交互。
- Container
Container是YARN中运行应用程序的基本单位,每个容器包含一个或多个任务。Container 负责对资源进行抽象,包括内存、CPU、磁盘、网络等资源。
其中,最重要的角色是 ResourceManager,主要用来负责整个资源的管理,Client 端是负责向 ResourceManager 提交任务。
Yarn 架构原理 - 任务提交
当用户提交一个任务到YARN时,任务的提交过程可以分为以下几个步骤:
- 应用程序提交
用户首先需要将应用程序提交到YARN中。这可以通过命令行工具或API接口完成,用户需要指定应用程序的名称、资源需求和启动命令等信息。
- 申请资源
一旦应用程序提交成功,它将会向ResourceManager发送资源请求。ResourceManager会根据集群中的可用资源和其他应用程序的需求,为这个应用程序分配一定数量的资源。
- 分配容器
一旦ResourceManager为应用程序分配了资源,它将会向NodeManager发出请求,要求它在一台或多台机器上启动容器。NodeManager接收到请求后,将会为每个容器分配一定数量的资源,并启动容器。
- 下载依赖文件
在容器启动之前,NodeManager需要下载应用程序的依赖文件(例如JAR文件)到容器中。这是通过Localizer来完成的。Localizer会从HDFS中下载应用程序的依赖文件,并将它们解压到容器的本地文件系统中。
- 启动ApplicationMaster
一旦容器启动并准备好运行应用程序,NodeManager将会启动ApplicationMaster。ApplicationMaster是应用程序的管理器,负责协调应用程序的各个任务,以及与ResourceManager交互。
- 分配任务
一旦ApplicationMaster启动成功,它将会向ResourceManager请求更多的资源,以分配应用程序的任务。ResourceManager会根据应用程序的需求和集群的可用资源,为每个任务分配一个容器。
- 执行任务
一旦任务被分配到容器中,TaskExecutor将会从容器中获取任务,并在本地执行任务。执行完成后,TaskExecutor会向ApplicationMaster报告任务的状态。
总之,任务提交到YARN的过程涉及多个组件之间的协作和通信。其中ResourceManager负责管理集群资源,NodeManager负责管理单个节点上的资源,ApplicationMaster负责协调应用程序的各个任务,而Container则是运行应用程序的基本单位。 任务的执行和状态监控也涉及多个组件之间的协作和通信。在这个过程中,YARN通过将资源管理和任务管理分离,实现了高效的资源利用和任务协调。
Flink on Yarn 部署原理剖析
Flink on Yarn Per-Job

Flink on Yarn 中 PerJob 模式是指每次提交一个任务,然后任务运行完成之后资源就会被释放。在了解了Yarn 的原理之后,PerJob 的流程也就比较容易理解了,具体如下:
- 首先 Client 提交 Yarn App,比如 JobGraph 或者 JARS。
- 接下来 Yarn 的 ResourceManager 会申请第一个 Container。这个 Container 通过 ApplicationMaster 启动进程,ApplicationMaster 里面运行的是 FLink 程序,即 Flink-Yarn ResourceManager 和 JobManager。
- 最后 Flink-Yarn ResourceManager 向 Yarn ResourceManager 申请资源。当分配到资源后,启动 TaskManager。TaskManager 启动后向 Flink-Yarn ResourceManager 进行注册,注册成功后 JobManager 就会分配具体的任务给 TaskManager 开始执行。
在Flink on Yarn的Per-Job模式中,每个Flink任务实现资源隔离的主要方式如下:
- 独立的Yarn应用程序:每个Flink作业都会被打包成一个独立的Yarn应用程序,包括一个JobManager进程和若干个TaskManager进程。这样可以保证每个Flink作业都运行在一个独立的应用程序中,避免了不同作业之间的资源冲突和干扰。
- 动态资源分配:在Flink on Yarn Per-Job模式中,Flink作业会根据实际资源需求向Yarn资源管理器请求所需的资源,并在作业执行期间动态调整资源使用情况。这样可以避免Flink作业占用过多资源,导致其他作业无法正常执行。
- 容器隔离:在Yarn中,每个应用程序都运行在一个独立的容器中,容器之间是相互隔离的。Flink作业也是运行在Yarn的容器中,这样可以保证每个Flink作业之间的资源隔离性。
- 任务隔离:Flink作业中的每个任务都是独立执行的,它们之间不会共享任何资源,包括内存、CPU、网络等。同时,Flink还提供了TaskExecutor的资源管理机制,可以根据每个任务的资源需求动态调整资源分配情况,从而保证每个任务都能够得到足够的资源。
Flink on Yarn Session

在 PerJob 模式中,执行完任务后整个资源就会释放,包括 JobManager、TaskManager 都全部退出。而 Session 模式则不一样,它的 Dispatcher 和 ResourceManager 是可以复用的。
Session模式的Flink任务部署过程跟Per-Job类似,两者之间的区别在于:
- 部署方式:Session模式是一种长期运行的Flink集群模式,用户可以通过Flink客户端连接到集群中的一个或多个JobManager,提交多个Flink作业,而PerJob模式则是每个Flink作业都会创建一个独立的Yarn应用程序,并在该应用程序中启动JobManager和TaskManager进程。
- 资源使用:Session模式是预分配资源的,也就是提前根据指定的资源参数初始化一个Flink集群,并常驻在YARN系统中,拥有固定数量的JobManager和TaskManager,该资源中JobManager有且只有一个。
- 作业隔离:Session模式下由于是预分配资源(资源总量有限),多个作业之间又不是隔离的,故可能会造成资源的争用,如果有一个作业因为异常导致TaskManager宕机,则它上面承载着的所有作业也都会受到影响。而在PerJob模式下,由于每个Flink作业都会创建一个独立的Yarn应用程序,因此不同作业之间也是相互隔离的。
- 适用场景:PerJob模式适用于长期运行的Flink集群场景,适合处理大量的实时数据,例如流处理、复杂事件处理等;而Session模式适用于短期的、需要单独调度的Flink作业。

Flink on Yarn Application
application模式,在该模式下会为每个提交的应用创建一个集群,用户程序的 main 方法将在JobManager集群中而不是客户端运行。
Application模式的会话集群,仅在特定应用程序的作业之间共享,并在应用程序完成时终止。
在这种体系结构中,Application 模式在不同应用之间提供了资源隔离和负载平衡保证。在特定一个应用程序上,JobManager 执行 main() 可以节省所需的 CPU 周期,还可以节省本地下载依赖项所需的带宽。

附官网的模式区分如下所示:

相关文章:
Flink、Yarn架构,以Flink on Yarn部署原理详解
Flink、Yarn架构,以Flink on Yarn部署原理详解 Flink 架构概览 Apache Flink是一个开源的分布式流处理框架,它可以处理实时数据流和批处理数据。Flink的架构原理是其实现的基础,架构原理可以分为以下四个部分:JobManager、TaskM…...

软考高级系统架构设计师系列论文八十三:论软件设计模式的应用
软考高级系统架构设计师系列论文八十三:论软件设计模式的应用 一、软件设计模式相关知识点二、摘要三、正文四、总结一、软件设计模式相关知识点 软考高级系统架构设计师系列之:面向构件的软件设计,构件平台与典型架构...

CDH集群离线配置python3环境,并安装pyhive、impyla、pyspark
背景: 项目需要对数仓千万级数据进行分析、算法建模。因数据安全,数据无法大批量导出,需在集群内进行分析建模,但CDH集群未安装python3 环境,需在无网情况下离线配置python3环境及一系列第三方库。 采取策略…...
)
python并行操作(基于concurrent.futures.ThreadPoolExecutor)
文章目录 一、明确自身cpu可并行的核数二、根据所有任务计算在各个核上平均跑多少任务三、最后把任务划分在不同的核上跑四、拿来主义 此为利用cpu并行计算的能力,充分利用cpu在循环时并行计算。其实也是受C并行操作的影响,如果需要C版,可以移…...

Leetcode.73矩阵置零
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法 class Solution {public void setZeroes(int[][] matrix) {int m matrix.length, n matrix[0].length;boolean[] row new boolean[m];boolean[] col…...

jdk 04 stream的collect方法
01.收集(collect) collect,收集,可以说是内容最繁多、功能最丰富的部分了。 从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。 collect主要依赖java.util.stream.Collectors类内置的静态方…...

介绍REST API
REST (Representational State Transfer) 是一种基于 web 架构的 API 设计风格, 允许客户端应用程序通过 HTTP 请求与服务器进行交互。RESTful API就是按照REST风格设计的API。 RESTful API 的设计原则包括:使用统一资源标识符 (URI) 标识资源ÿ…...
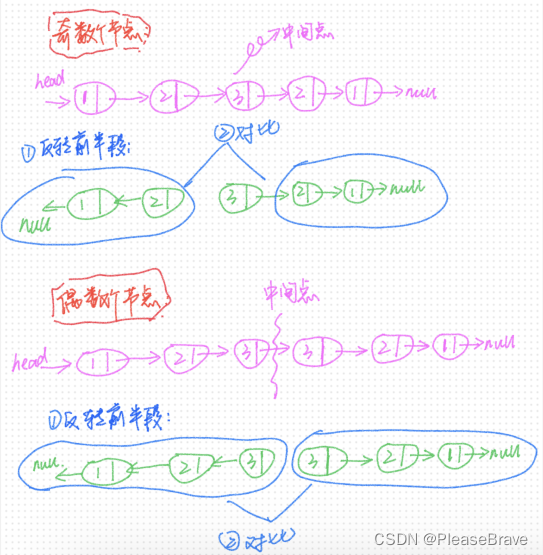
【leetcode 力扣刷题】反转链表+递归求解
反转链表递归求解 206. 反转链表解法①:取下一个节点在当前头节点前插入解法②:反转每个节点next的指向解法③:递归 92.反转链表Ⅱ反转left到right间节点的next指向 234.回文链表解法①:将链表元素存在数组中,在数组上…...

一文读懂Redis配置,史上真香配置
文章目录 基本配置项AOF持久化配置项RDB持久化配置项淘汰策略配置项主从复制配置项鸣谢 让那些总为redis连接异常的小白指引明灯,少走弯路。为那些不知道如何进行高级配置的大佬整一杯小酒。 基本配置项 bind:用于设置Redis绑定的IP地址。默认情况下&…...

maven打出jar中动态替换占位符
使用场景: maven打出的jar中pom.xml动态替换占位符 有些时候某些公共工具jar包被项目引用后发现公共jar的pom.xml中的version依然还是占位符,例如下面 <dependency><groupId>org.projectlombok</groupId><artifactId>lombok<…...

【Git游戏】通过游戏重新学习Git
在提交树上移动 HEAD HEAD:一个标志符号(通常情况下指向当前分支,间接指向当前最新的提交记录) 可以通过git checkout commitID从而指向提交记录 commitID 本身是一串哈希值(基于 SHA-1,共 40 位) 我们在…...

如何通过以太坊JSON-RPC方式获取ERC-20代币的信息?
目录 一、ERC-20介绍 二、ERC-20代币标准功能 1、可选功能 2、标准功能 三、获取代币信息...

线性代数的学习和整理4: 求逆矩阵的多种方法汇总
目录 原始问题:如何求逆矩阵? 1 EXCEL里,直接可以用黑盒表内公式 minverse() 数组公式求A- 2 非线性代数方法:解方程组的方法 3 增广矩阵的方法 4 用行列式的方法计算(未验证) 5 A-1/|A|*A* &…...

【C#学习笔记】匿名函数和lambda表达式
文章目录 匿名函数匿名函数的定义匿名函数作为参数传递匿名函数的缺点 lambda表达式什么是lambda表达式闭包 匿名函数 为什么我们要使用匿名函数?匿名函数存在的意义是为了简化一些函数的定义,特别是那些定义了之后只会被调用一次的函数,与其…...

百度Apollo:引领自动驾驶技术创新的先锋
文章目录 前言一、内容总结 前言 大家好,我是萝卜头不吃萝卜头,今天和大家分享一下我学习百度Apollo自动驾驶的心得。 在七月份的时候,我收到了Apollo开发者社区的邀请,进行学习Apollo自动驾驶汽车的2023星火培训训练,…...
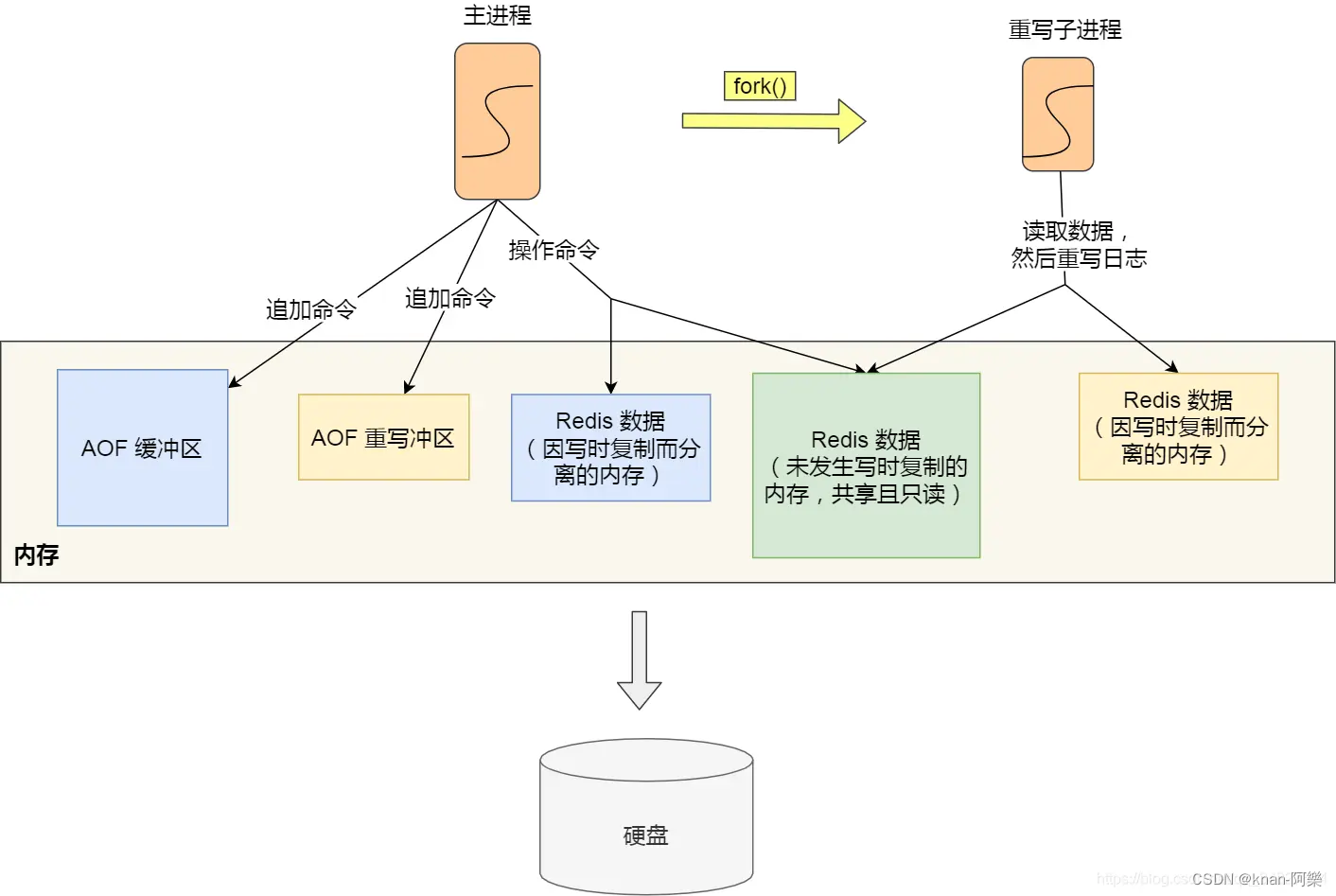
Redis 重写 AOF 日志期间,主进程可以正常处理命令吗?
重写 AOF 日志的过程是怎样的? Redis 的重写 AOF 过程是由后台子进程 bgrewriteaof 来完成的,这么做有以下两个好处。 子进程进行 AOF 重写期间,主进程可以继续处理命令请求,从而避免阻塞主进程子进程带有主进程的数据副本。这里…...
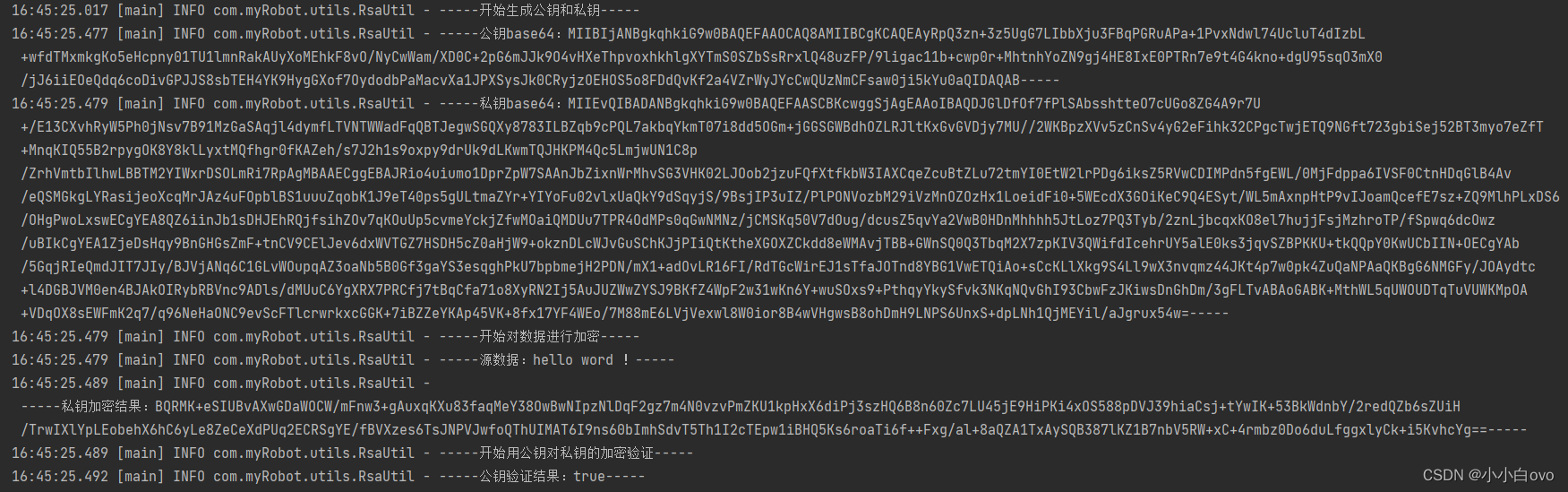
java实现生成RSA公私钥、SHA256withRSA加密以及验证工具类
前言: RSA属于非对称加密。所谓非对称加密,需要两个密钥:公钥 (publickey) 和私钥 (privatekey)。公钥和私钥是一对,如果用公钥对数据加密,那么只能用对应的私钥解密。如果用私钥对数据加密,只能用对应的公…...
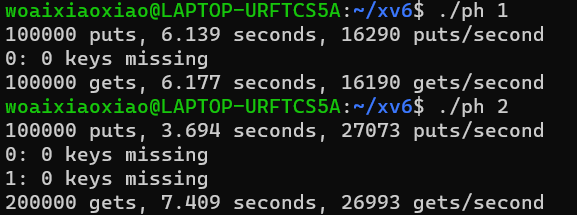
lab7 thread
文章目录 Uthread: switching between threadstaskhints思路上下文的恢复和保存thread_createthread_schedule Using threads思路 Barrier Uthread: switching between threads 在这个练习中,你将为一个用户级别线程系统设计上下文切换机制,并实现它。 …...

接口自动化测试:mock server之Moco工具
什么是mock server mock:英文可以翻译为模仿的,mock server是我们用来解除依赖(耦合),假装实现的技术,比如说,前端需要使用某些api进行调试,但是服务端并没有开发完成这些api&#…...
用python从零开始做一个最简单的小说爬虫带GUI界面(2/3)
目录 前一章博客 前言 主函数的代码实现 逐行代码解析 获取链接 获取标题 获取网页源代码 获取各个文章的链接 函数的代码 导入库文件 获取文章的标题 获取文章的源代码 提取文章目录的各个文章的链接 总代码 下一章内容 前一章博客 用python从零开始做一个最简单…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...