机器学习:学习k-近邻(KNN)模型建立、使用和评价
机器学习:学习k-近邻(KNN)模型建立、使用和评价
文章目录
- 机器学习:学习k-近邻(KNN)模型建立、使用和评价
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 1.数据读取
- 2.数据理解
- 3.数据准备
- 4.算法选择及其超级参数的设置
- 5.具体模型的训练
- 6.用模型进行预测
- 7.模型评价
- 总结
一、实验目的
学习kNN(k-Nearest Neighbors)算法
二、实验原理
k-近邻(kNN,k-Nearest Neighbors)算法是一种基于实例的分类方法。该方法就是找出与未知样本x距离最近的k个训练样本,看这k个样本中多数属于哪一类,就把x归为那一类。k-近邻方法是一种懒惰学习方法,它存放样本,直到需要分类时才进行分类,如果样本集比较复杂,可能会导致很大的计算开销,因此无法应用到实时性很强的场合。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比
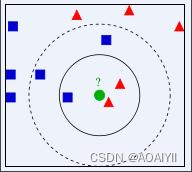
例如,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排列;
3.选取与当前点距离最小的 K 个点;
4.确定前 K 个点所在类别的出现频率;
5.返回前 K 个点出现频率最高的类别作为当前点的预测分类
三、实验环境
Python 3.9
Anaconda
IPython Notebook
四、实验内容
学习KNN算法,了解模型创建、使用模型及模型评价等操作
五、实验步骤
1.数据读取
1.导入os模块,返回当前工作路径
import os
os.getcwd()
2.导入pandas和numpy包,并改变工作目录
import pandas as pd
import numpy as np
import os
os.chdir(r'D:\CSDN\数据分析\KNN')
print(os.getcwd())

3.读取该目录下的bc_data.csv文件,并返回文件内容
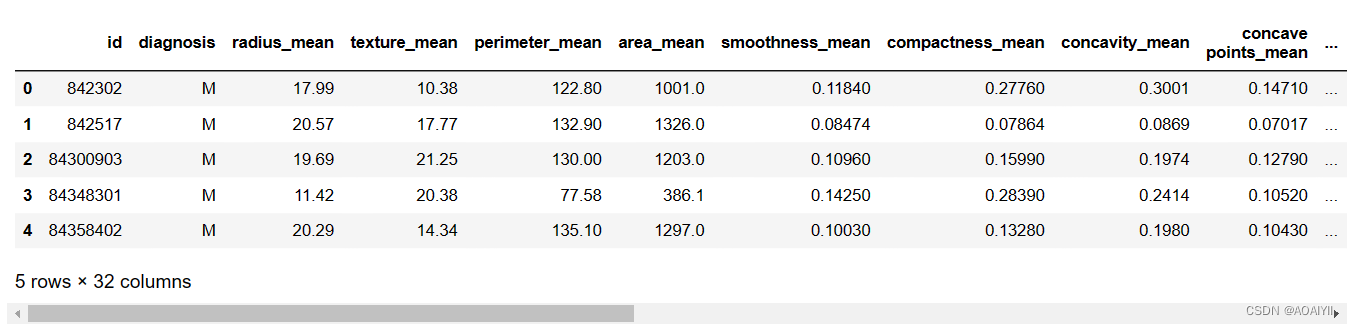
bc_data = pd.read_csv(r'D:\CSDN\数据分析\KNN\bc_data.csv', header=0)
bc_data.head()
其中header参数用来指定数据开始读取行数。设置为0表示从第一行开始读取,设置为1,表示从第二行开始读取
2.数据理解
1.shape函数是numpy.core.fromnumeric中的函数,直接用.shape可以快速读取矩阵的形状,使用shape[0]读取矩阵第一维度的长度
bc_data.shape

2.查看bc_data的列名
print(bc_data.columns)

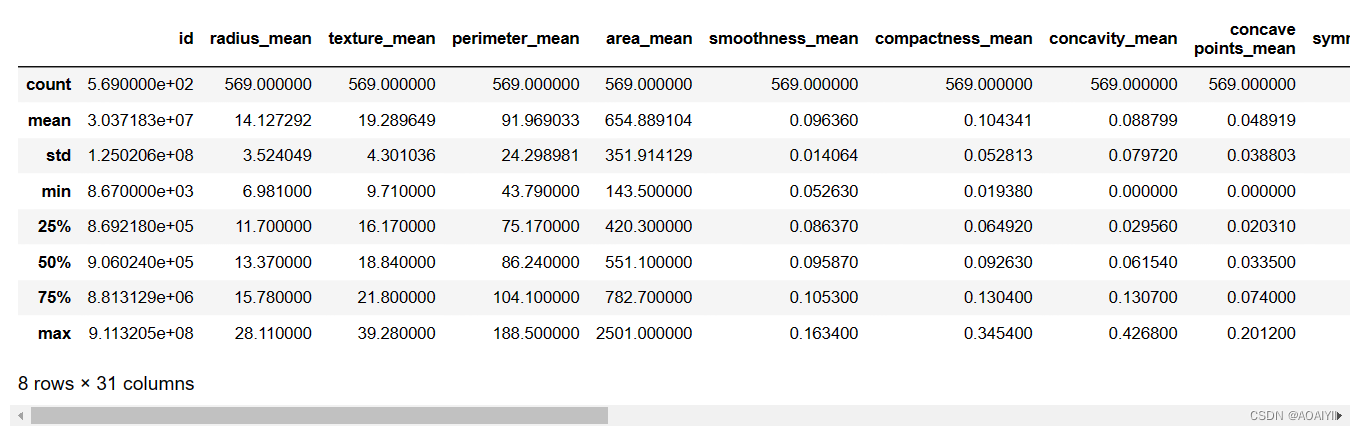
3.查看bc_data的描述性统计
bc_data.describe()
3.数据准备
1.删除bc_data中的id列,其中axis使用0值表示沿着每一列或行标签\索引值向下执行方法,使用1值表示沿着每一行或者列标签模向执行对应的方法
data = bc_data.drop(['id'],axis = 1)
print(data.head())
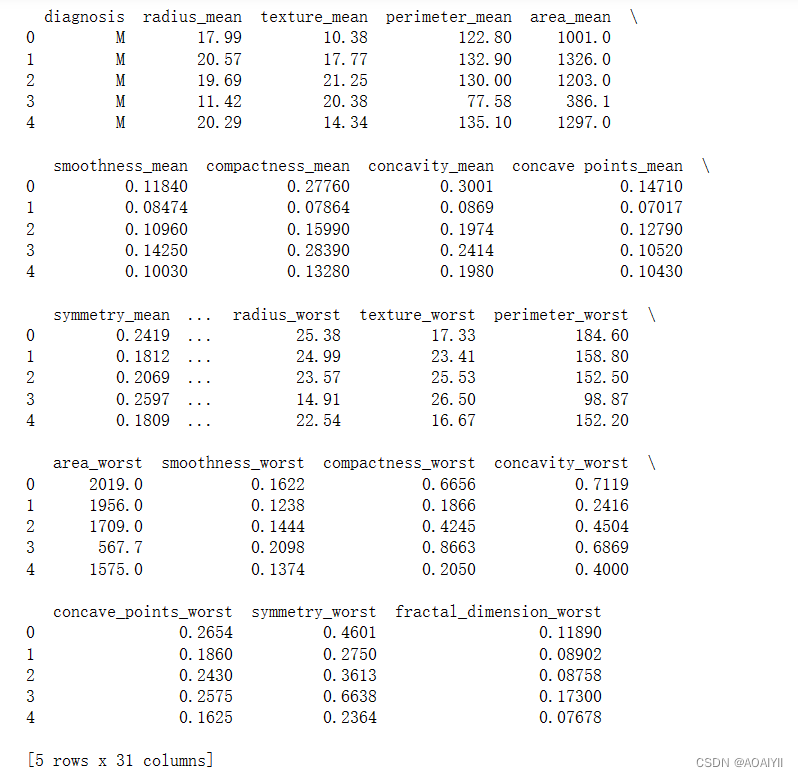
2.删除data文件中的diagnosis列并查看X_data内容
X_data = data.drop(['diagnosis'], axis=1)
X_data.head()
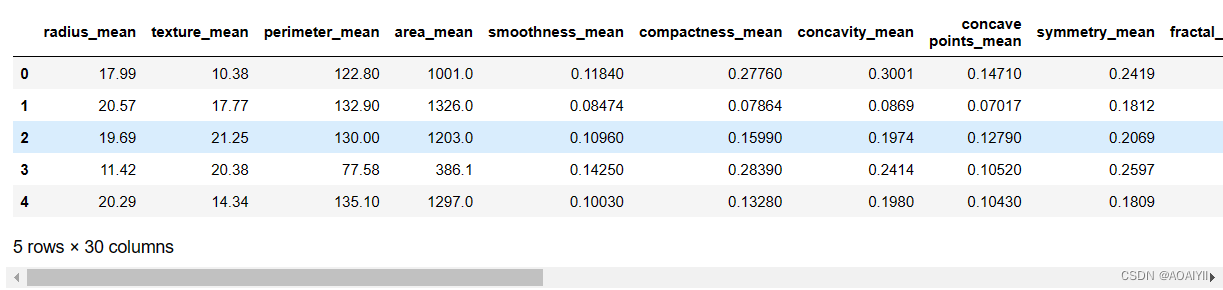
3.使用numpy中的ravel()方法将data中的多维数据降为一维,并使用切片查询y_data
这里需要注意的是np.ravel()返回的是视图,修改时会影响原始矩阵
y_data = np.ravel(data[['diagnosis']])
y_data[0:6]
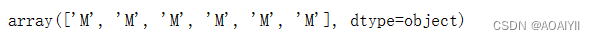
4.导入sklearn库中的train_test_split函数,划分训练集和测试集
from sklearn.model_selection import train_test_split
X_trainingSet, X_testSet, y_trainingSet, y_testSet = train_test_split(X_data, y_data, random_state=1)

参数解释如下:

5.使用shape函数查看训练集矩阵形状
print(X_trainingSet.shape)

6.使用shape函数查看测试集矩阵形状
print(X_testSet.shape)

4.算法选择及其超级参数的设置
1.导入sklearn模块中的KNeighborsClassifier函数,并使用kd_tree算法
from sklearn.neighbors import KNeighborsClassifier
myModel = KNeighborsClassifier(algorithm='kd_tree')
5.具体模型的训练
1.使用.fit方法对训练数据进行模型拟合
myModel.fit(X_trainingSet,y_trainingSet)
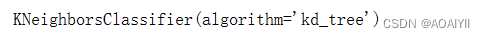
6.用模型进行预测
1.使用.predict方法,用训练好的模型进行预测
y_predictSet = myModel.predict(X_testSet)
2.打印输出y_predictSet预测结果
print(y_predictSet)
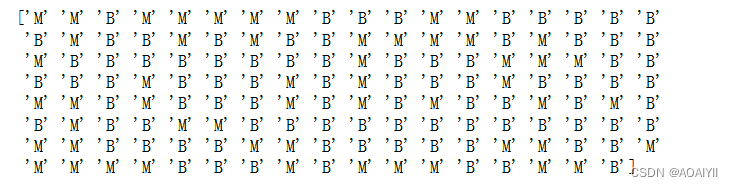
3.打印输出y_testSet
print(y_testSet)
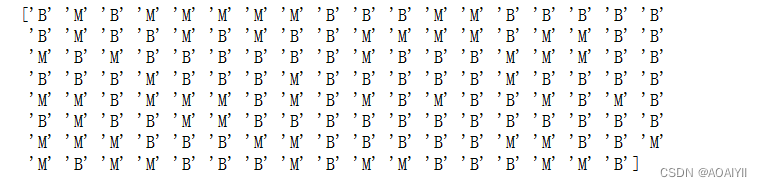
7.模型评价
1.导入sklearn模块中的accuracy_score,对模型进行评价
from sklearn.metrics import accuracy_score
print(accuracy_score(y_testSet,y_predictSet))

说明:模型的正确率为0.937062937063
总结
k-近邻(kNN,k-Nearest Neighbors)算法是一种基于实例的分类方法。该方法就是找出与未知样本x距离最近的k个训练样本,看这k个样本中多数属于哪一类,就把x归为那一类。k-近邻方法是一种懒惰学习方法,它存放样本,直到需要分类时才进行分类,如果样本集比较复杂,可能会导致很大的计算开销,因此无法应用到实时性很强的场合。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
相关文章:
机器学习:学习k-近邻(KNN)模型建立、使用和评价
机器学习:学习k-近邻(KNN)模型建立、使用和评价 文章目录机器学习:学习k-近邻(KNN)模型建立、使用和评价一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.数据读取2.数据理解3.数据准备4.算…...

Hive Sampling 抽样函数:Random随机抽样、Block 基于数据块抽样、Bucket table 基于分桶表抽样
Hive Sampling 抽样函数 文章目录Hive Sampling 抽样函数Random随机抽样Block 基于数据块抽样Bucket table 基于分桶表抽样语法在HQL中,可以通过三种方式采样数据:随机采样,存储桶表采样和块采样。Random随机抽样 随机抽样使用rand()函数确保…...
)
2023年中职网络安全竞赛跨站脚本渗透解析-1(超详细)
跨站脚本渗透 任务环境说明:需求环境可私信博主! 服务器场景:Server2125(关闭链接)服务器场景操作系统:未知访问服务器网站目录1,根据页面信息完成条件,将获取到弹框信息作为flag提交;访问服务器网站目录2,根据页面信息完成条件,将获取到弹框信息作为flag提交;访问服…...
虚拟 DOM 详解
什么是虚拟 dom? 虚拟 dom 本质上就是一个普通的 JS 对象,用于描述视图的界面结构 在vue中,每个组件都有一个render函数,每个render函数都会返回一个虚拟 dom 树,这也就意味着每个组件都对应一棵虚拟 DOM 树 查看虚拟…...
)
Delphi Http Https 最好的解决方法(一)
当前文章主要解决Delphi调用http、https的常见报错。 开发工具: Delphi XE 10.1 Berlin版本 可能所需的控件包: QDAC 请自行下载。 1. 接口描述 dll_init 接口初始化,程序启动时调用,主要是对工具类实例的创建 dll_post 发送post请求&am…...
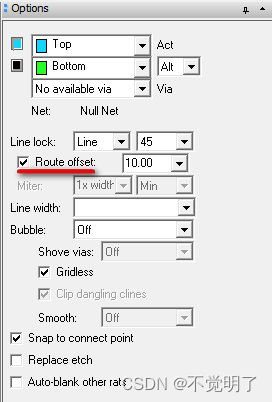
Allegro无法打开10度走线命令的原因和解决办法
Allegro无法打开10度走线命令的原因和解决办法 做PCB设计的时候,10度走线也是较为常见的设计方式,Allegro支持10度走线,如下图 需要10度走线的时候,Options只需要勾选Route offset命令即可 但有时options处会看不到10度走线的命令,如下图...

Frequency Domain Model Augmentation for Adversarial Attack
原文:[2207.05382] Frequency Domain Model Augmentation for Adversarial Attack (arxiv.org)代码:https://github.com/yuyang-long/SSA.黑盒攻击替代模型与受攻击模型之间的差距通常较大,表现为攻击性能脆弱。基于同时攻击不同模型可以提高…...
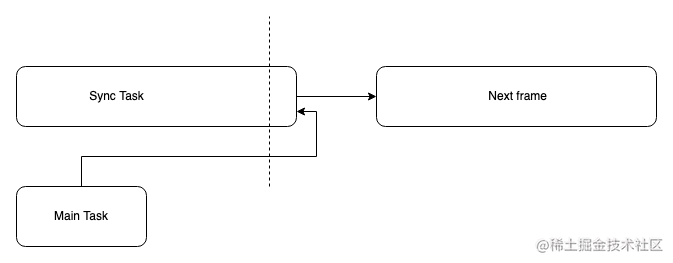
react源码中的协调与调度
requestEventTime 其实在React执行过程中,会有数不清的任务要去执行,但是他们会有一个优先级的判定,假如两个事件的优先级一样,那么React是怎么去判定他们两谁先执行呢? // packages/react-reconciler/src/ReactFibe…...
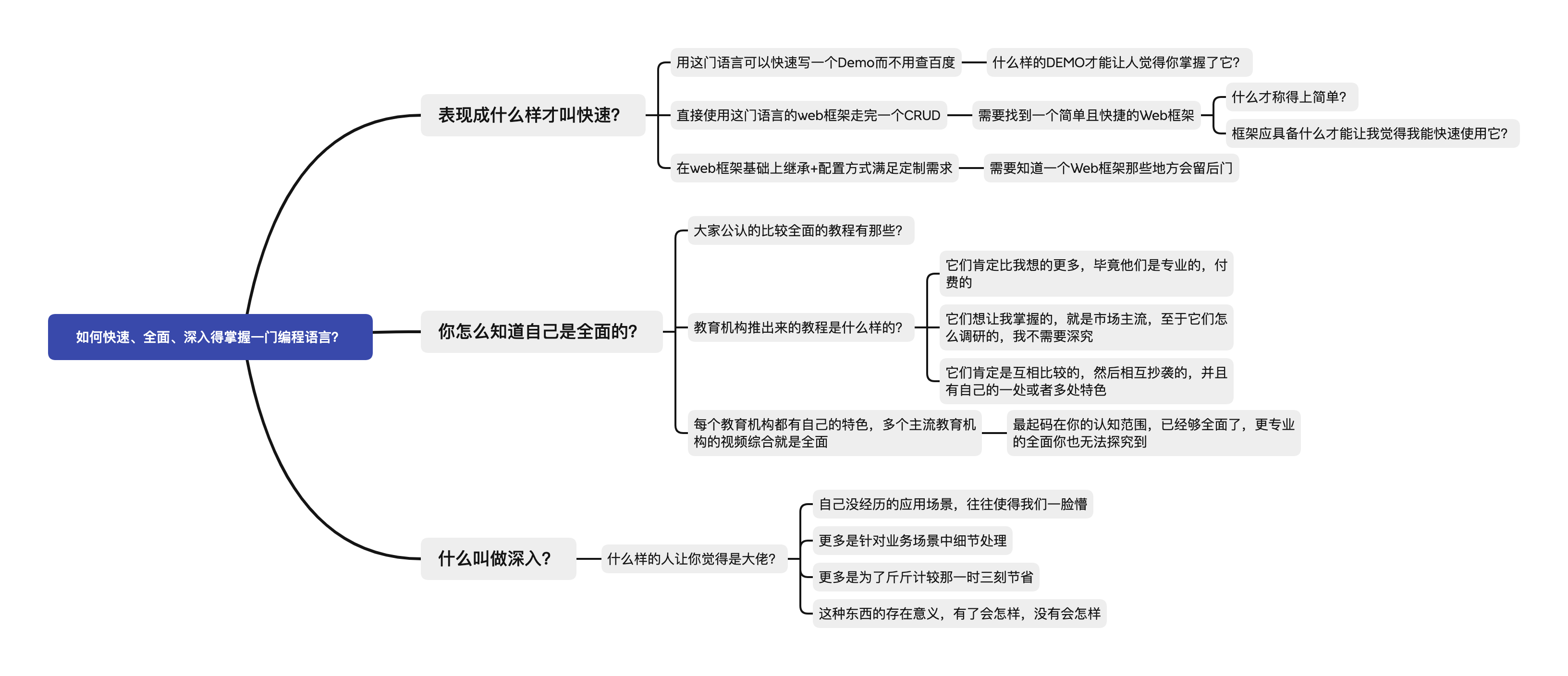
如何快速、全面、深入地掌握一门编程语言
思考路线 如何快速? 什么样的Demo才能让人觉得你掌握了它? 空 判断:构造一个可以判断所有空的 is_empty 函数 for 循环:i 和 集合迭代两种 时间获取:年/月/日 时分秒 时间戳与时间格式互转 休眠时间函数 字符串处理…...
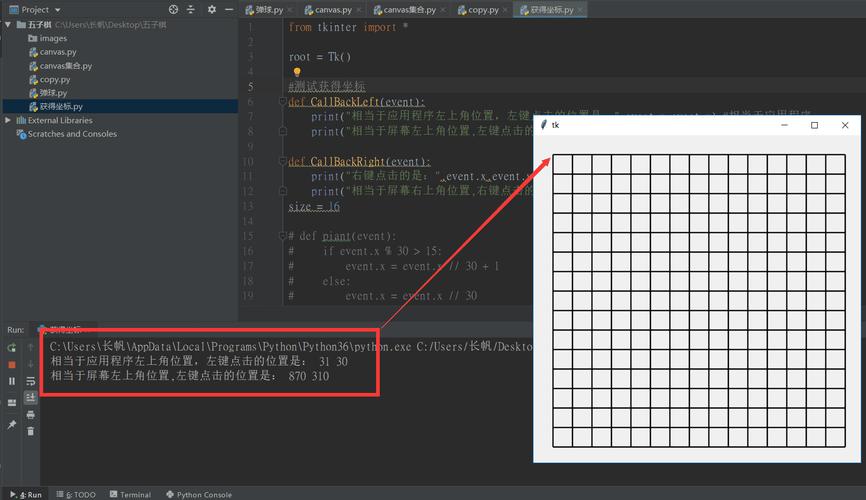
python五子棋代码最简单的,python五子棋代码画棋盘
大家好,本文将围绕python五子棋代码输赢逻辑判断展开说明,如何用python制作五子棋游戏是一个很多人都想弄明白的事情,想搞清楚python五子棋代码最简单的需要先了解以下几个事情。 1、求解用python 编写五子棋怎样编写判断输赢的函数ÿ…...
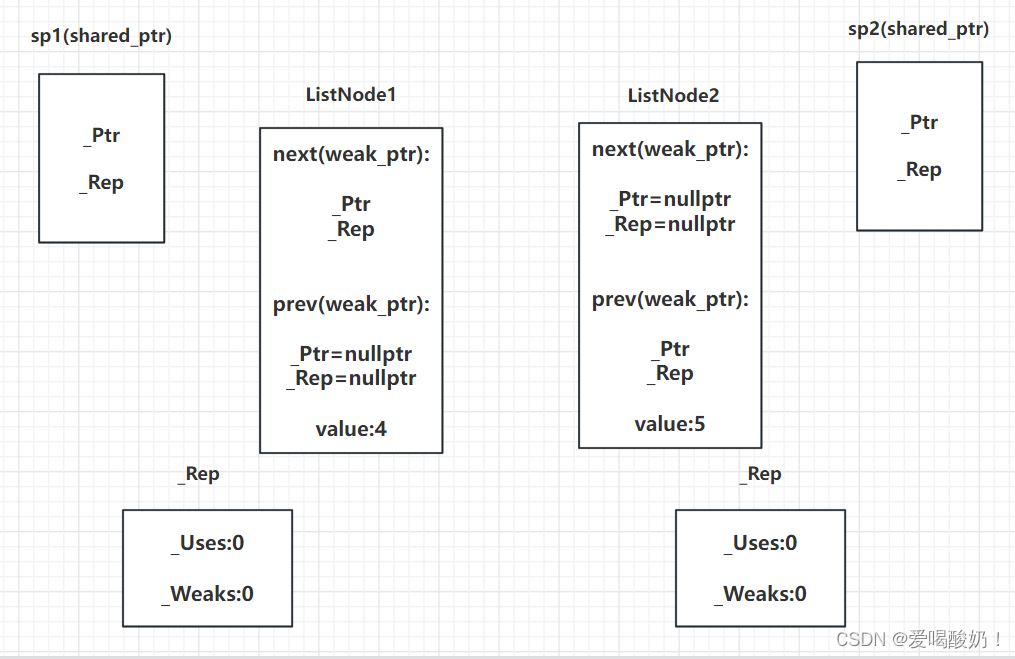
C++ 智能指针的原理:auto_ptr、unique_ptr、shared_ptr、weak_ptr
目录一、理解智能指针1.普通指针的使用二、智能指针1.auto_ptr2.unique_ptr3.shared_ptr(1)了解shared_ptr(2)shared_ptr的缺陷4.weak_ptr本文代码在win10的vs2019中通过编译。 一、理解智能指针 1.普通指针的使用 如果程序需要…...

二叉树前中后层次遍历,递归实现
文章目录前序遍历代码\Python代码\C中序遍历代码\Python代码\C后序遍历代码\Python代码\C层序遍历代码\Python代码\C反向层序遍历代码\Python代码\C总结前序遍历 题目链接 前序遍历意思就是按照“根节点-左子树-右子树”的顺序来遍历二叉树,通过递归方法来实现…...
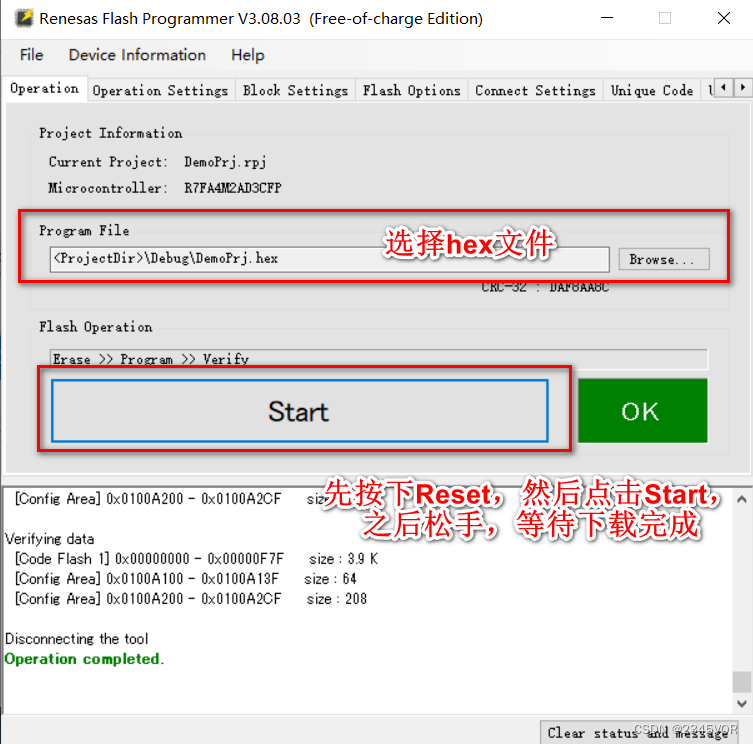
【RA4M2系列开发板GPIO体验2按键控制LED】
【RA4M2系列开发板GPIO体验2按键控制LED】1. 前言2. 配置工程2.1 新建FSP项目2.2 硬件连接以及FSP配置2.2.1 硬件连接2.2.2 FSP配置3. 软件实现3.1 实现的功能3.2 FreeRTOS使用3.2.1 Stack分配函数3.2.2 LED任务3.2.3 Key任务3.3 程序设计3.3.1 设置输出hex文件3.3.2 编译3.3.3…...
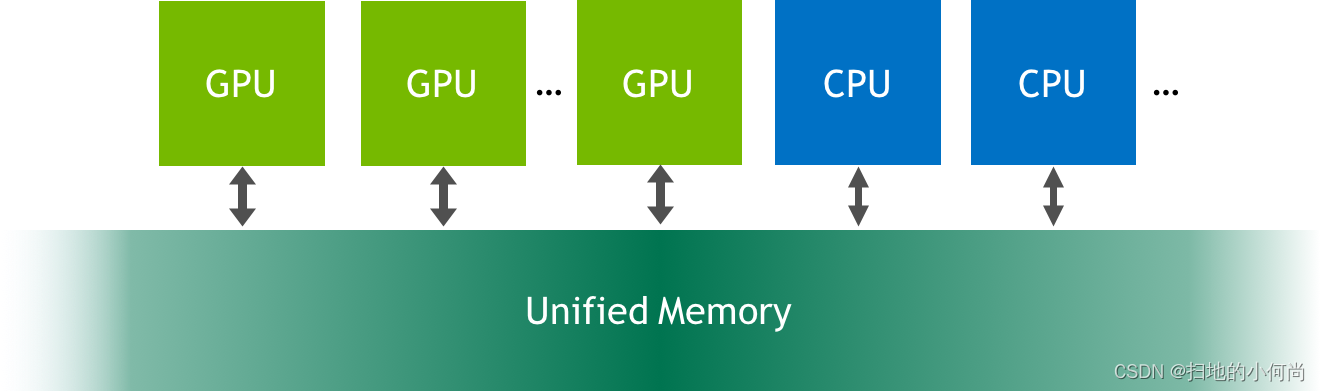
初步介绍CUDA中的统一内存
初步介绍CUDA中的统一内存 更多精彩内容: https://www.nvidia.cn/gtc-global/?ncidref-dev-876561 文章目录初步介绍CUDA中的统一内存为此,我向您介绍了统一内存,它可以非常轻松地分配和访问可由系统中任何处理器、CPU 或 GPU 上运行的代码使用的数据。…...
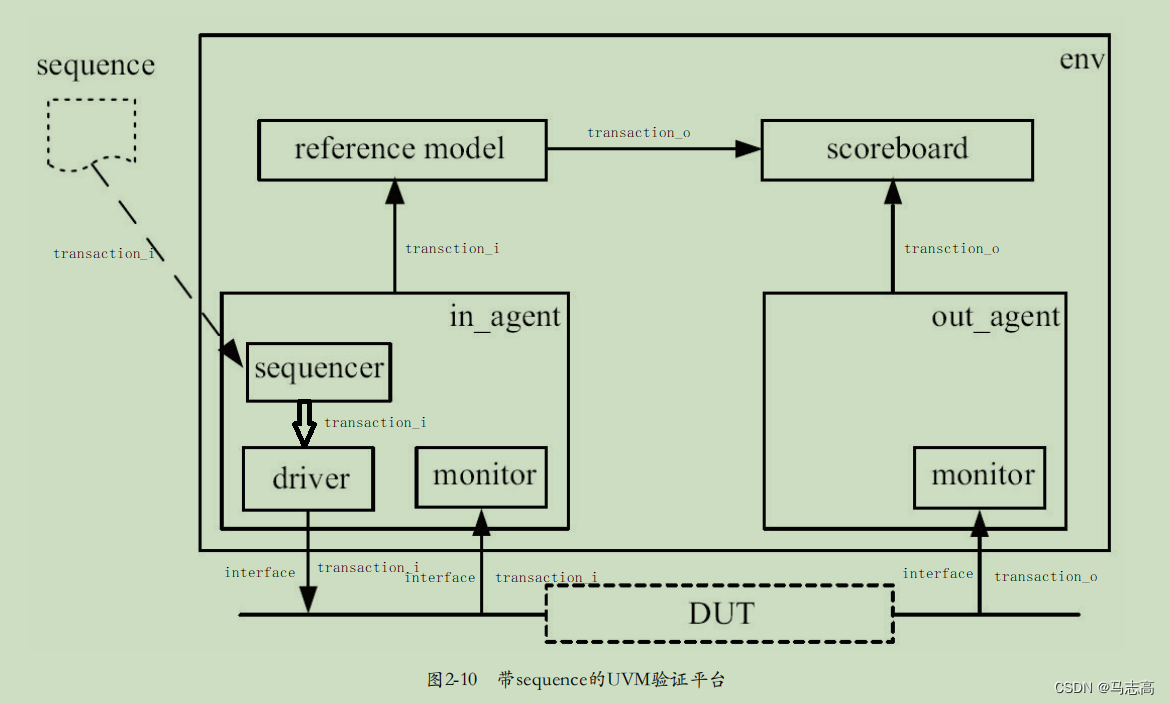
UVM实战--加法器
前言 这里以UVM实战(张强)第二章为基础修改原有的DUT,将DUT修改为加法器,从而修改代码以使得更加深入的了解各个组件的类型和使用。 一. 组件的基本框架 和第二章的平台的主要区别点 (1)有两个transactio…...

Linux系统点亮LED
目录应用层操控硬件的两种方式sysfs 文件系统sysfs 与/sys总结标准接口与非标准接口LED 硬件控制方式编写LED 应用程序在开发板上测试对于一款学习型开发板来说,永远都绕不开LED 这个小小的设备,基本上每块板子都至少会有一颗 LED 小灯,对于我…...
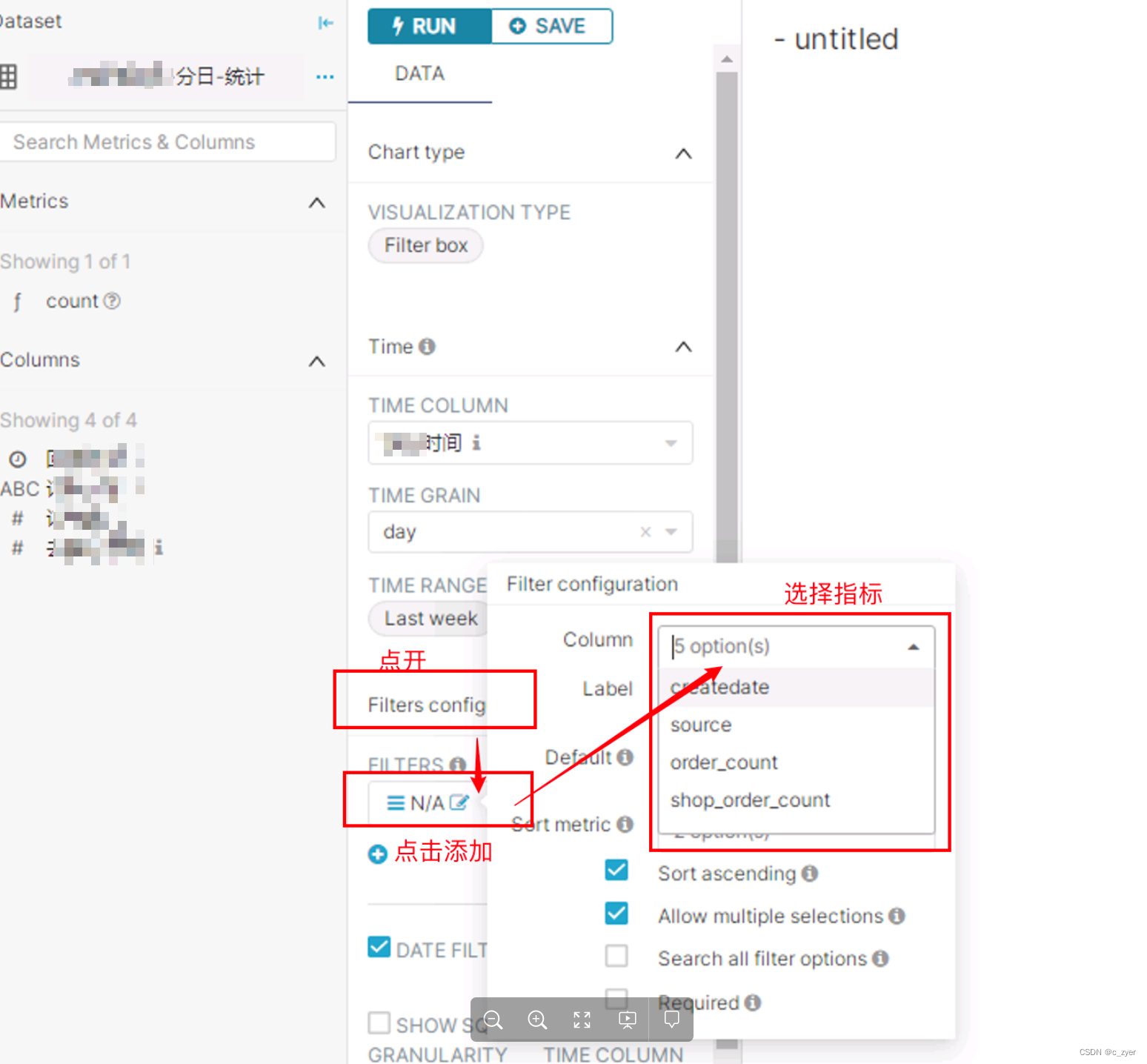
在superset中快速制作报表或仪表盘
在中小型企业,当下需要快速迭代、快速了解运营效果的业务,急需一款开源、好用、能快速迭代生产的报表系统。 老板很关心,BI工程师很关心,同时系统开发人员也同样关心,一个好的技术选型往往能够帮助公司减少很多成本&a…...
【可视化实战】Python 绘制出来的数据大屏真的太惊艳了
今天我们在进行一个Python数据可视化的实战练习,用到的模块叫做Panel,我们通过调用此模块来绘制动态可交互的图表以及数据大屏的制作。 而本地需要用到的数据集,可在kaggle上面获取 https://www.kaggle.com/datasets/rtatman/188-million-us…...
Obsidium一键编码作业,Obsidia惊人属性
Obsidium一键编码作业,Obsidia惊人属性 每个区域都包含几个可定制的功能,允许用户确定如何完全执行应用程序的安全性。Obsidia的功能区允许用户存储任何调整或一键编码作业。 Obsidia惊人属性: 代码虚拟化:代码虚拟化允许您转换程序代码的特定…...

约束优化:约束优化的三种序列无约束优化方法
文章目录约束优化:约束优化的三种序列无约束优化方法外点罚函数法L2-罚函数法:非精确算法对于等式约束对于不等式约束L1-罚函数法:精确算法内点罚函数法:障碍函数法等式约束优化问题的拉格朗日函数法:Uzawas Method fo…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...
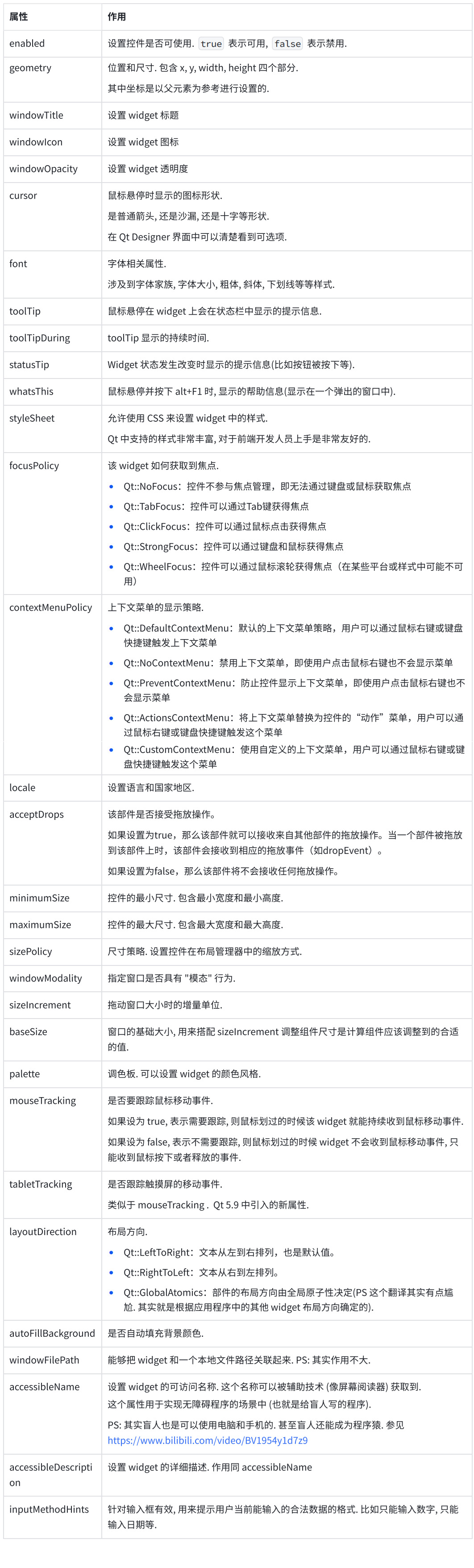
【Qt】控件 QWidget
控件 QWidget 一. 控件概述二. QWidget 的核心属性可用状态:enabled几何:geometrywindows frame 窗口框架的影响 窗口标题:windowTitle窗口图标:windowIconqrc 机制 窗口不透明度:windowOpacity光标:cursor…...