中文命名实体识别
本文通过people_daily_ner数据集,介绍两段式训练过程,第一阶段是训练下游任务模型,第二阶段是联合训练下游任务模型和预训练模型,来实现中文命名实体识别任务。
一.任务和数据集介绍
1.命名实体识别任务
NER(Named Entity Recognition)和Pos(Part-of-Speech)是2类典型的标记分类问题。NER是信息抽取基础,识别文本中的实体(比如人名、地点、组织结构名等),本质就是预测每个字对应的标记。DL兴起前,主要是HMM和CRF等模型,现在基本是DL模型。可根据需要设置标注方式,常见方式有BIO、BIESO等。NER数据样例如下所示:

2.数据集介绍
本文使用中文命名实体识别数据集people_daily_ner,样例数据如下所示:
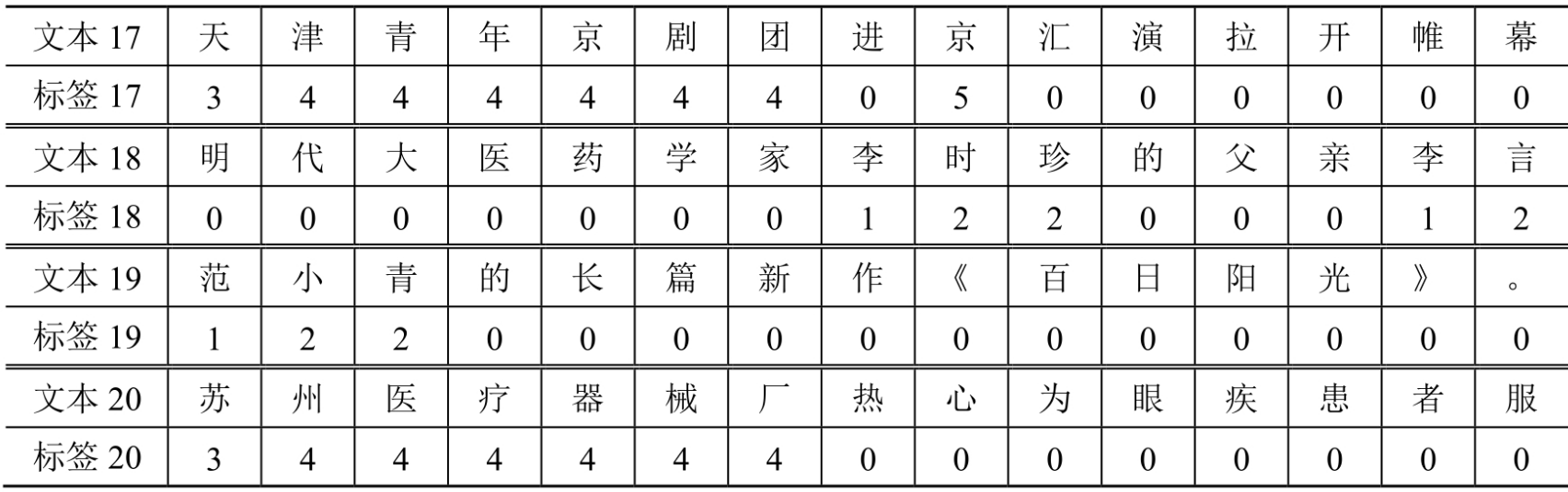
people_daily_ner数据集标签对照表如下所示:

- O:表示不属于一个命名实体。
- B-PER:表示人名的开始。
- I-PER:表示人名的中间和结尾部分。
- B-ORG:表示组织机构名的开始。
- I-ORG:表示组织机构名的中间和结尾部分。
- B-LOC:表示地名的开始。
- I-LOC:表示地名的中间和结尾部分。
3.模型架构
本文使用hfl/rbt3模型[2],参数量约3800万。基本思路为使用一个预训练模型从文本中抽取数据特征,再对每个字的数据特征做分类任务,最终得到和原文一一对应的标签序列(BIO)。
二.准备数据集
1.使用编码工具
使用hfl/rbt3编码器编码工具如下所示:
def load_encode_tool(pretrained_model_name_or_path):"""加载编码工具"""tokenizer = AutoTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'))return tokenizer
if __name__ == '__main__':# 测试编码工具pretrained_model_name_or_path = r'L:/20230713_HuggingFaceModel/rbt3'tokenizer = load_encode_tool(pretrained_model_name_or_path)print(tokenizer)# 测试编码句子out = tokenizer.batch_encode_plus(batch_text_or_text_pairs=[[ '海', '钓', '比', '赛', '地', '点', '在', '厦', '门', '与', '金', '门', '之', '间', '的', '海', '域', '。'],[ '这', '座', '依', '山', '傍', '水', '的', '博', '物', '馆', '由', '国', '内', '′', '一', '流', '的', '设', '计', '师', '主', '持', '设', '计', '。']],truncation=True, # 截断padding='max_length', # [PAD]max_length=20, # 最大长度return_tensors='pt', # 返回pytorch张量is_split_into_words=True # 按词切分)# 查看编码输出for k, v in out.items():print(k, v.shape)# 将编码还原为句子print(tokenizer.decode(out['input_ids'][0]))print(tokenizer.decode(out['input_ids'][1]))
输出结果如下所示:
BertTokenizerFast(name_or_path='L:\20230713_HuggingFaceModel\rbt3', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
input_ids torch.Size([2, 20])
token_type_ids torch.Size([2, 20])
attention_mask torch.Size([2, 20])
[CLS] 海 钓 比 赛 地 点 在 厦 门 与 金 门 之 间 的 海 域 。 [SEP]
[CLS] 这 座 依 山 傍 水 的 博 物 馆 由 国 内 一 流 的 设 计 [SEP]
需要说明参数is_split_into_words=True让编码器跳过分词步骤,即告诉编码器输入句子是分好词的,不用再进行分词。
2.定义数据集
定义数据集代码如下所示:
class Dataset(torch.utils.data.Dataset):def __init__(self, split):# 在线加载数据集# dataset = load_dataset(path='people_daily_ner', split=split)# dataset.save_to_disk(dataset_dict_path='L:/20230713_HuggingFaceModel/peoples_daily_ner')# 离线加载数据集dataset = load_from_disk(dataset_path='L:/20230713_HuggingFaceModel/peoples_daily_ner')[split]# print(dataset.features['ner_tags'].feature.num_classes) #7# print(dataset.features['ner_tags'].feature.names) # ['O','B-PER','I-PER','B-ORG','I-ORG','B-LOC','I-LOC']self.dataset = datasetdef __len__(self):return len(self.dataset)def __getitem__(self, i):tokens = self.dataset[i]['tokens']labels = self.dataset[i]['ner_tags']return tokens, labels
if __name__ == '__main__':# 测试编码工具pretrained_model_name_or_path = r'L:/20230713_HuggingFaceModel/rbt3'tokenizer = load_encode_tool(pretrained_model_name_or_path)# 加载数据集dataset = Dataset('train')tokens, labels = dataset[0]print(tokens, labels, dataset)print(len(dataset))
输出结果如下所示:
['海', '钓', '比', '赛', '地', '点', '在', '厦', '门', '与', '金', '门', '之', '间', '的', '海', '域', '。'] [0, 0, 0, 0, 0, 0, 0, 5, 6, 0, 5, 6, 0, 0, 0, 0, 0, 0] <__main__.Dataset object at 0x0000027B01DC3940>
20865
其中,20865表示训练数据集的大小。在people_daily_ner数据集中,每条数据包括两个字段,即tokens和ner_tags,分别代表句子和标签,在__getitem__()函数中把这两个字段取出并返回即可。
3.定义计算设备
device = 'cpu'
if torch.cuda.is_available():device = 'cuda'
print(device)
4.定义数据整理函数
def collate_fn(data):tokens = [i[0] for i in data]labels = [i[1] for i in data]inputs = tokenizer.batch_encode_plus(tokens, # 文本列表truncation=True, # 截断padding=True, # [PAD]max_length=512, # 最大长度return_tensors='pt', # 返回pytorch张量is_split_into_words=True) # 分词完成,无需再次分词# 求一批数据中最长的句子长度lens = inputs['input_ids'].shape[1]# 在labels的头尾补充7,把所有的labels补充成统一的长度for i in range(len(labels)):labels[i] = [7] + labels[i]labels[i] += [7] * lenslabels[i] = labels[i][:lens]# 把编码结果移动到计算设备上for k, v in inputs.items():inputs[k] = v.to(device)# 把统一长度的labels组装成矩阵,移动到计算设备上labels = torch.tensor(labels).to(device)return inputs, labels
形参data表示一批数据,主要是对句子和标签进行编码,这里会涉及到一个填充的问题。标签的开头和尾部填充7,因为0-6都有物理意义),而句子开头会被插入[CLS]标签。无论是句子还是标签,最终都被转换为矩阵。测试数据整理函数如下所示:
data = [(['海', '钓', '比', '赛', '地', '点', '在', '厦', '门', '与', '金', '门', '之', '间', '的', '海', '域', '。'], [0, 0, 0, 0, 0, 0, 0, 5, 6, 0, 5, 6, 0, 0, 0, 0, 0, 0]),(['这', '座', '依', '山', '傍', '水', '的', '博', '物', '馆', '由', '国', '内', '一', '流', '的', '设', '计', '师', '主', '持', '设', '计', ',', '整', '个', '建', '筑', '群', '精', '美', '而', '恢', '宏', '。'],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])]
inputs, labels = collate_fn(data)
for k, v in inputs.items():print(k, v.shape)
print('labels', labels.shape)
输出结果如下所示:
input_ids torch.Size([2, 37])
token_type_ids torch.Size([2, 37])
attention_mask torch.Size([2, 37])
labels torch.Size([2, 37])
5.定义数据集加载器
loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=16, collate_fn=collate_fn, shuffle=True, drop_last=True)
通过数据集加载器查看一批样例数据,如下所示:
for i, (inputs, labels) in enumerate(loader):break
print(tokenizer.decode(inputs['input_ids'][0]))
print(labels[0])
for k, v in inputs.items():print(k, v.shape)
输出结果如下所示:
[CLS] 这 种 输 液 器 不 必 再 悬 吊 药 瓶 , 改 用 气 压 推 动 液 体 流 动 , 自 闭 防 回 流 , 安 全 、 简 便 、 抗 污 染 , 堪 称 输 液 器 历 史 上 的 一 次 革 命 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
tensor([7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7], device='cuda:0')
input_ids torch.Size([16, 87])
token_type_ids torch.Size([16, 87])
attention_mask torch.Size([16, 87])
三.定义模型
1.加载预训练模型
# 加载预训练模型
pretrained = AutoModel.from_pretrained(Path(f'{pretrained_model_name_or_path}'))
# 统计参数量
# print(sum(i.numel() for i in pretrained.parameters()) / 10000)
# 测试预训练模型
pretrained.to(device)
2.定义下游任务模型
先介绍一个两段式训练的概念,通常是先单独对下游任务模型进行训练,然后再连同预训练模型和下游任务模型一起进行训练的模式。
class Model(torch.nn.Module):def __init__(self):super().__init__()# 标识当前模型是否处于tuning模式self.tuning = False# 当处于tuning模式时backbone应该属于当前模型的一部分,否则该变量为空self.pretrained = None# 当前模型的神经网络层self.rnn = torch.nn.GRU(input_size=768, hidden_size=768, batch_first=True)self.fc = torch.nn.Linear(in_features=768, out_features=8)def forward(self, inputs):# 根据当前模型是否处于tuning模式而使用外部backbone或内部backbone计算if self.tuning:out = self.pretrained(**inputs).last_hidden_stateelse:with torch.no_grad():out = pretrained(**inputs).last_hidden_state# backbone抽取的特征输入RNN网络进一步抽取特征out, _ = self.rnn(out)# RNN网络抽取的特征最后输入FC神经网络分类out = self.fc(out).softmax(dim=2)return out# 切换下游任务模型的tuning模式def fine_tuning(self, tuning):self.tuning = tuning# tuning模式时,训练backbone的参数if tuning:for i in pretrained.parameters():i.requires_grad = Truepretrained.train()self.pretrained = pretrained# 非tuning模式时,不训练backbone的参数else:for i in pretrained.parameters():i.requires_grad_(False)pretrained.eval()self.pretrained = None
(1)tuning表示当前模型是否处于微调模型,pretrained表示微调模式时预训练模型属于当前模型。
(2)在__init__()中定义了下游任务模型的2个层,分别为GRU网络和全连接神经网络层,GRU作用是进一步抽取特征,提高模型预测正确率。
(3)fine_tuning()用来切换训练模式pretrained.train()和评估模式pretrained.eval()。
四.训练和测试
1.模型训练
def train(epochs):lr = 2e-5 if model.tuning else 5e-4 # 根据模型的tuning模式设置学习率optimizer = AdamW(model.parameters(), lr=lr) # 优化器criterion = torch.nn.CrossEntropyLoss() # 损失函数scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader) * epochs, optimizer=optimizer) # 学习率衰减策略model.train()for epoch in range(epochs):for step, (inputs, labels) in enumerate(loader):# 模型计算# [b,lens] -> [b,lens,8]outs = model(inputs)# 对outs和labels变形,并且移除PAD# outs -> [b, lens, 8] -> [c, 8]# labels -> [b, lens] -> [c]outs, labels = reshape_and_remove_pad(outs, labels, inputs['attention_mask'])# 梯度下降loss = criterion(outs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数scheduler.step() # 更新学习率optimizer.zero_grad() # 清空梯度if step % (len(loader) * epochs // 30) == 0:counts = get_correct_and_total_count(labels, outs)accuracy = counts[0] / counts[1]accuracy_content = counts[2] / counts[3]lr = optimizer.state_dict()['param_groups'][0]['lr']print(epoch, step, loss.item(), lr, accuracy, accuracy_content)torch.save(model, 'model/中文命名实体识别.model')
训练过程基本步骤如下所示:
(1)从数据集加载器中获取一个批次的数据。
(2)让模型计算预测结果。
(2)使用工具函数对预测结果和labels进行变形,移除预测结果和labels中的PAD。
(4)计算loss并执行梯度下降优化模型参数。
(5)每隔一定的steps,输出一次模型当前的各项数据,便于观察。
(6)每训练完一个epoch,将模型的参数保存到磁盘。
接下来介绍两段式训练过程,第一阶段是训练下游任务模型,第二阶段是联合训练下游任务模型和预训练模型如下所示:
# 两段式训练第一阶段,训练下游任务模型
model.fine_tuning(False)
# print(sum(p.numel() for p in model.parameters() / 10000))
train(1)# 两段式训练第二阶段,联合训练下游任务模型和预训练模型
model.fine_tuning(True)
# print(sum(p.numel() for p in model.parameters() / 10000))
train(5)
2.模型测试
模型测试基本思路:从磁盘加载模型,然后切换到评估模式,将模型移动到计算设备,从测试集中取批次数据,输入模型中,统计正确率。
def test():# 加载训练完的模型model_load = torch.load('model/中文命名实体识别.model')model_load.eval() # 切换到评估模式model_load.to(device)# 测试数据集加载器loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'), batch_size=128, collate_fn=collate_fn, shuffle=True, drop_last=True)correct = 0total = 0correct_content = 0total_content = 0# 遍历测试数据集for step, (inputs, labels) in enumerate(loader_test):# 测试5个批次即可,不用全部遍历if step == 5:breakprint(step)# 计算with torch.no_grad():# [b, lens] -> [b, lens, 8] -> [b, lens]outs = model_load(inputs)# 对outs和labels变形,并且移除PAD# fouts -> [b, lens, 8] -> [c, 8]# labels -> [b, lens] -> [c]outs, labels = reshape_and_remove_pad(outs, labels, inputs['attention_mask'])# 统计正确数量counts = get_correct_and_total_count(labels, outs)correct += counts[0]total += counts[1]correct_content += counts[2]total_content += counts[3]print(correct / total, correct_content / total_content)
3.预测任务
def predict():# 加载模型model_load = torch.load('model/中文命名实体识别.model')model_load.eval()model_load.to(device)# 测试数据集加载器loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'), batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True)# 取一个批次的数据for i, (inputs, labels) in enumerate(loader_test):break# 计算with torch.no_grad():# [b, lens] -> [b, lens, 8] -> [b, lens]outs = model_load(inputs).argmax(dim=2)for i in range(32):# 移除PADselect = inputs['attention_mask'][i] == 1input_id = inputs['input_ids'][i, select]out = outs[i, select]label = labels[i, select]# 输出原句子print(tokenizer.decode(input_id).replace(' ', ''))# 输出tagfor tag in [label, out]:s = ''for j in range(len(tag)):if tag[j] == 0:s += '.'continues += tokenizer.decode(input_id[j])s += str(tag[j].item())print(s)print('=====================')
参考文献:
[1]HuggingFace自然语言处理详解:基于BERT中文模型的任务实战
[2]https://huggingface.co/hfl/rbt3
[3]https://huggingface.co/datasets/peoples_daily_ner/tree/main
[4]https://github.com/OYE93/Chinese-NLP-Corpus/
[5]https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然语言处理详解/第10章:中文命名实体识别.py
相关文章:
中文命名实体识别
本文通过people_daily_ner数据集,介绍两段式训练过程,第一阶段是训练下游任务模型,第二阶段是联合训练下游任务模型和预训练模型,来实现中文命名实体识别任务。 一.任务和数据集介绍 1.命名实体识别任务 NER(Named En…...

WPF CommunityToolkit.Mvvm Messenger通讯
文章目录 环境WeakReferenceMessenger方法介绍无回调订阅发送Token区分有回调订阅发送 环境 CommunityToolkit.Mvvm Messenger 十月的寒流: 如何使用 CommunityToolkit.Mvvm 中的 Messenger 来进行 ViewModel 之间的通信 WeakReferenceMessenger 我这里只讲简单的弱Messenger…...

【杂言】写在研究生开学季
这两天搬进了深研院的宿舍,比中南的本科宿舍好很多,所以个人还算满意。受台风 “苏拉” 的影响,原本的迎新计划全部打乱,导致我现在都还没报道。刚开学的半个月将被各类讲座、体检以及入学教育等活动占满,之后又是比较…...

渗透测试漏洞原理之---【任意文件读取漏洞】
文章目录 1、概述1.1、漏洞成因1.2、漏洞危害1.3、漏洞分类1.4、任意文件读取1.4.1、文件读取函数1.4.2、任意文件读取 1.5、任意文件下载1.5.1、一般情况1.5.2、PHP实现1.5.3、任意文件下载 2、任意文件读取攻防2.1、路径过滤2.1.1、过滤../ 2.2、简单绕过2.2.1、双写绕过2.2.…...

合宙Air724UG LuatOS-Air LVGL API控件-图片 (Image)
图片 (Image) 图片IMG是用于显示图像的基本对象类型,图像来源可以是文件,或者定义的符号。 示例代码 -- 创建图片控件 img lvgl.img_create(lvgl.scr_act(), nil) -- 设置图片显示的图像 lvgl.img_set_src(img, "/lua/luatos.png") -- 图片…...
仿京东 项目笔记2(注册登录)
这里写目录标题 1. 注册页面1.1 注册/登录页面——接口请求1.2 Vue开发中Element UI的样式穿透1.2.1 ::v-deep的使用1.2.2 elementUI Dialog内容区域显示滚动条 1.3 注册页面——步骤条和表单联动 stepsform1.4 注册页面——滑动拼图验证1.5 注册页面——element-ui组件Popover…...

Spark与Flink的区别
分析&回答 (1)设计理念 1、Spark的技术理念是使用微批来模拟流的计算,基于Micro-batch,数据流以时间为单位被切分为一个个批次,通过分布式数据集RDD进行批量处理,是一种伪实时。 2、Flink是基于事件驱动的,是面向流的处理框架, Flink基于…...
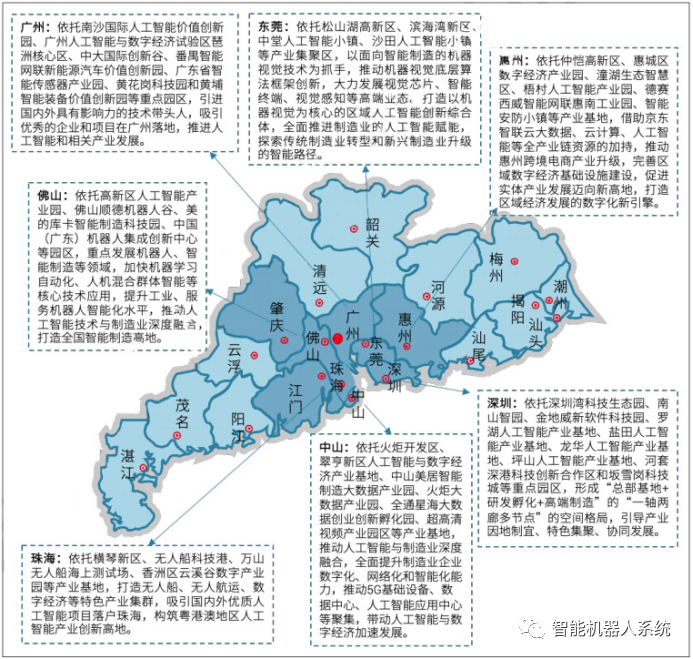
未来智造:珠三角引领人工智能产业集群
原创 | 文 BFT机器人 产业集群是指产业或产业群体在地理位置上集聚的现象,产业集群的研究对拉动区域经济发展,提高区域产业竞争力具有重要意义。 从我国人工智能产业集群形成及区域布局来看,我国人工智能产业发展主要集聚在京津冀、长三角、…...

【Unity db】sqlite
背景 最近使用unity,需要用到sqlite,记录下使用过程 需要的动态库 Mono.Data.Sqlite.dll,这个文件下载参考下面链接 SqliteConnection的Close和Open 连接的概念: 在数据库编程中,连接是一个重要的概念,…...
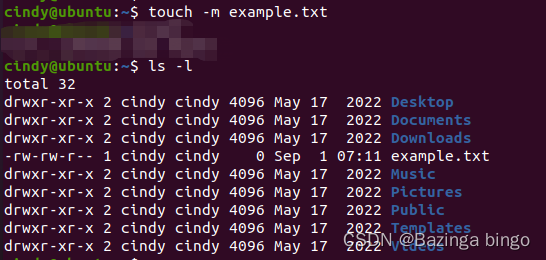
Linux 指令心法(四)`touch` 创建一个新的空文件
文章目录 命令的概述和用途命令的用法命令行选项和参数的详细说明命令的示例命令的注意事项或提示 命令的概述和用途 touch 是一个用于在 Linux 和 Unix 系统中创建空文件或更改现有文件的访问和修改时间的命令。如果指定的文件不存在,touch会创建一个新的空文件&a…...
分类算法系列②:KNN算法
目录 KNN算法 1、简介 2、原理分析 数学原理 相关公式及其过程分析 距离度量 k值选择 分类决策规则 3、API 4、⭐案例实践 4.1、分析 4.2、代码 5、K-近邻算法总结 🍃作者介绍:准大三网络工程专业在读,努力学习Java,涉…...

12. 微积分 - 梯度积分
Hi,大家好。我是茶桁。 上一节课,我们讲了方向导数,并且在最后留了个小尾巴,是什么呢?就是梯度。 我们再来回看一下但是的这个式子: [ f x f y...

Large Language Models and Knowledge Graphs: Opportunities and Challenges
本文是LLM系列的文章,针对《Large Language Models and Knowledge Graphs: Opportunities and Challenges》的翻译。 大语言模型和知识图谱:机会与挑战 摘要1 引言2 社区内的共同辩论点3 机会和愿景4 关键研究主题和相关挑战5 前景 摘要 大型语言模型&…...

Python操作Excel教程(图文教程,超详细)Python xlwings模块详解,
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:小白零基础《Python入门到精通》 xlwings模块详解 1、快速入门1、打开Excel2、创建工作簿2.1、使用工作簿2.2、操作…...

Java入门
Java导入包 import 主要用于导入在使用类前准备好了Import 关键字可以多次使用,导入多个包Import 关键字可以多次使用,导入多个类如果同一个包中需要大量的类,那么可以使用通配符进行导入如果Import了不同包,相同名称的类&#x…...
深度解析BERT:从理论到Pytorch实战
本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。 关注TechLead&#x…...
小程序数据导出文件
小程序josn数据生成excel文件 先从下载传送门将xlsx.mini.min.js拷贝下来,新建xlsx.js文件放入小程序项目文件夹下。 const XLSX require(./xlsx)//在需要用的页面中引入// 定义导出 Excel 报表的方法exportData() {const that thislet newData [{time:2021,val…...

hadoop1.2.1伪分布式搭建
0.使用host-only方式 将Windows上的虚拟网卡改成跟Linux上的网卡在同一网段 注意:一定要将widonws上的WMnet1的IP设置和你的虚拟机在同一网段,但是IP不能相同 1.Linux环境配置(windows下面的防火墙也要关闭) 1.1修改主…...

【校招VIP】前端JavaScript语言之跨域
考点介绍: 什么是跨域?浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域。跨域是前端校招的一个重要考点,在面试过程中经常遇到,需要着重掌握。本期分享的前端算法考点之…...

mysql调优小计
1.选择最合适的字段属性:类型、⻓度、是否允许NULL等;尽量把字段设为not null,⼀⾯查询时对⽐是否为null; 2.要尽量避免全表扫描,⾸先应考虑在 where 及 order by 涉及的列上建⽴索引。 3.应尽量避免在 where ⼦句中对…...

观察使用token plan套餐后月度api成本的可控性变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用token plan套餐后月度api成本的可控性变化 对于个人开发者或小型项目而言,大模型API的调用成本常常是预算中一…...

HC7251晨芯阳科技内置MOS开关降压型LED恒流驱动器
HC7251是一款内置60V功率MOS 高效率、高精度的开关降压型大功率LED 恒流驱动芯片。HC7251采用固定关断时间的峰值电流控制方式,关断时间可通过外部电容进行调节,工作频率可根据用户要求而改变。HC7251通过调节外置的电流采样电阻,能控制高亮度…...

淘金币全自动脚本终极指南:每天节省20分钟,淘宝任务一键完成
淘金币全自动脚本终极指南:每天节省20分钟,淘宝任务一键完成 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/t…...
)
学术论文翻译翻车重灾区!Perplexity翻译查询功能如何通过引用锚点保留+LaTeX公式智能隔离实现零失真输出(仅限Pro+订阅用户可见的隐藏模式)
更多请点击: https://intelliparadigm.com 第一章:学术论文翻译翻车重灾区的底层归因分析 学术论文翻译失准并非偶然现象,其背后存在系统性语言学、认知科学与工程实践三重张力。当非母语研究者依赖通用大模型或词典式工具进行技术文本转译时…...

WSL2下CUDA版本切换实战:从CUDA 12.0降级到11.1,成功安装diff-gaussian-rasterization
WSL2环境下CUDA版本切换与diff-gaussian-rasterization安装全指南 在AI和图形学项目的复现过程中,CUDA版本与依赖库的兼容性问题常常成为开发者的"拦路虎"。最近在复现一篇论文时,我遇到了diff-gaussian-rasterization库因CUDA版本不匹配而无…...

避坑指南:为什么你的mqtt.fx连不上OneNET?Token生成与参数配置的3个关键细节
避坑指南:为什么你的mqtt.fx连不上OneNET?Token生成与参数配置的3个关键细节 当你深夜调试MQTT设备,反复检查代码却依然看到刺眼的"离线"状态时,那种挫败感我深有体会。OneNET作为国内主流物联网平台,其MQTT…...

IC697PWR710H电源模块
IC697PWR710H 是GE Fanuc Series 90-70 PLC系统使用的一款高可靠性电源模块,为机架内所有模块提供稳定的直流供电,属于710系列的改进或衍生版本。中间:15条产品特点IC697PWR710H 输入支持交流120/240V或直流125V,适应不同现场供电…...

CANN/asc-devkit SIMD向量长度获取函数
GetVecLen 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

【热门开源项目下载】yolo-onnx-java
【热门开源项目下载】yolo-onnx-java 1. 项目基础介绍与编程语言 yolo-onnx-java 是一个基于Java语言开发的轻量级AI模型调用框架,专注于为Java开发者提供高效、便捷的深度学习模型推理能力。项目通过ONNX(Open Neural Network Exchange)格式…...
)
告别实车折腾!手把手教你用Vector VT平台搭建OBC/DCDC的HIL测试台架(附避坑清单)
从零搭建OBC/DCDC HIL测试台架:Vector VT平台实战指南与避坑手册 当你第一次面对堆满桌面的Vector VT板卡、缠绕如蛛网的线缆和数十个软件模块时,HIL测试的复杂性可能令人望而生畏。本文将以工程师视角,带你一步步完成从设备上电到首个充电协…...