P1-P5_动手学深度学习-pytorch(李沐版,粗浅的笔记)
目录
- 预告
- 1.学习深度学习的关键是动手
- 2.什么是《动手学深度学习》
- 3.曾经推出的版本(含github链接)
- 一、课程安排
- 1.目标
- 2.内容
- 3.上课形式
- 4.你将学到什么
- 5.资源
- 二、深度学习的介绍
- 1.AI地图
- 2.深度学习在一些应用上的突破
- 3.案例研究一广告点击
- 三、安装
- 1.Windows下的安装CUDA
- 2.验证CUDA是否安装成功
- 3.下载并安装一个Python环境(安装Miniconda)
- 4.到Pytorch官网下载对应的GPU版本
- 5.运行一个深度学习的应用(安装jupyter和d2l;下载d2I记事本,运行测试)
- 6.本次总结
- 四、数据操作+数据预处理
- 1.数据操作
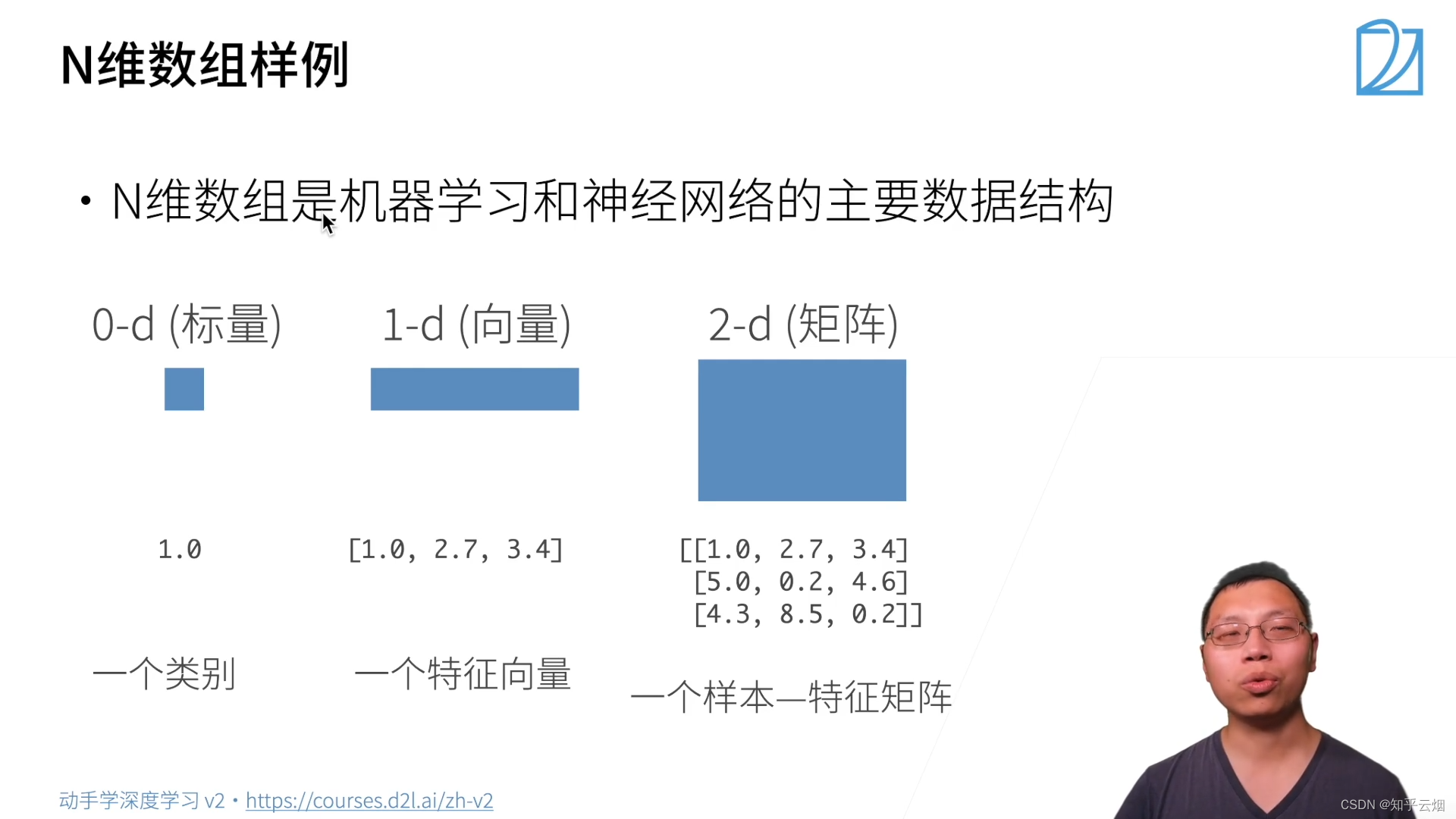
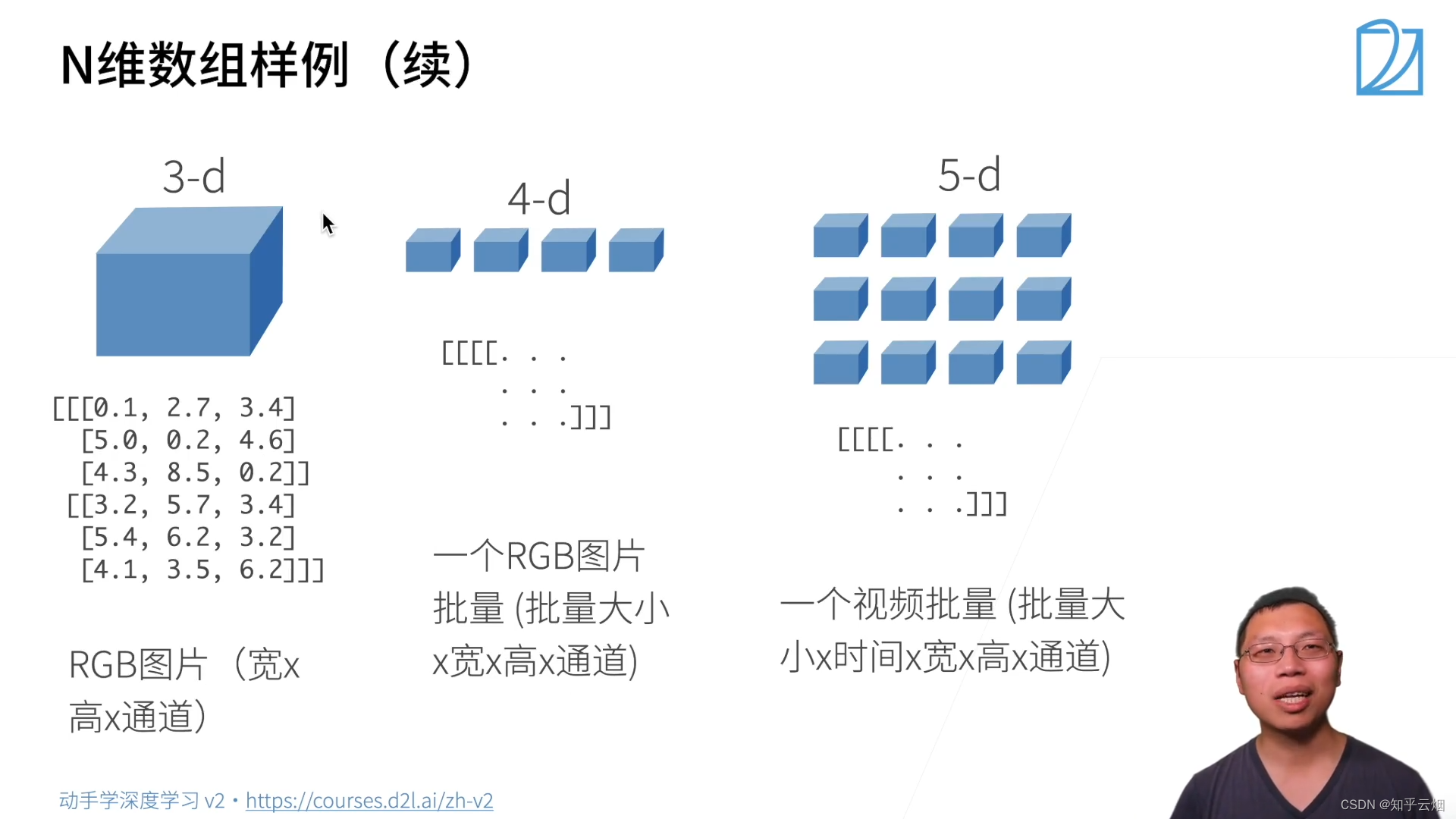
- (1)N维数组样例
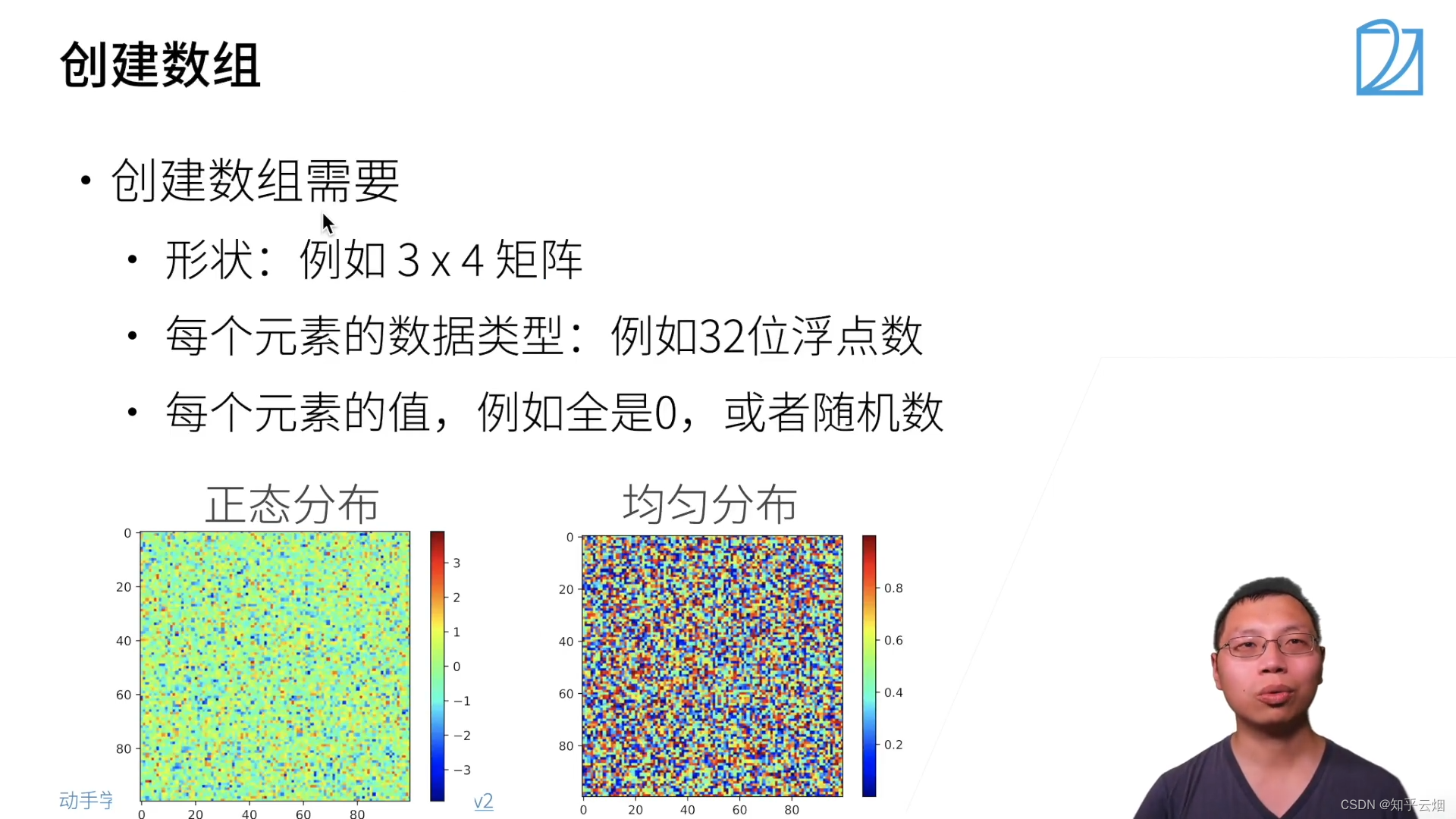
- (2)创建数组
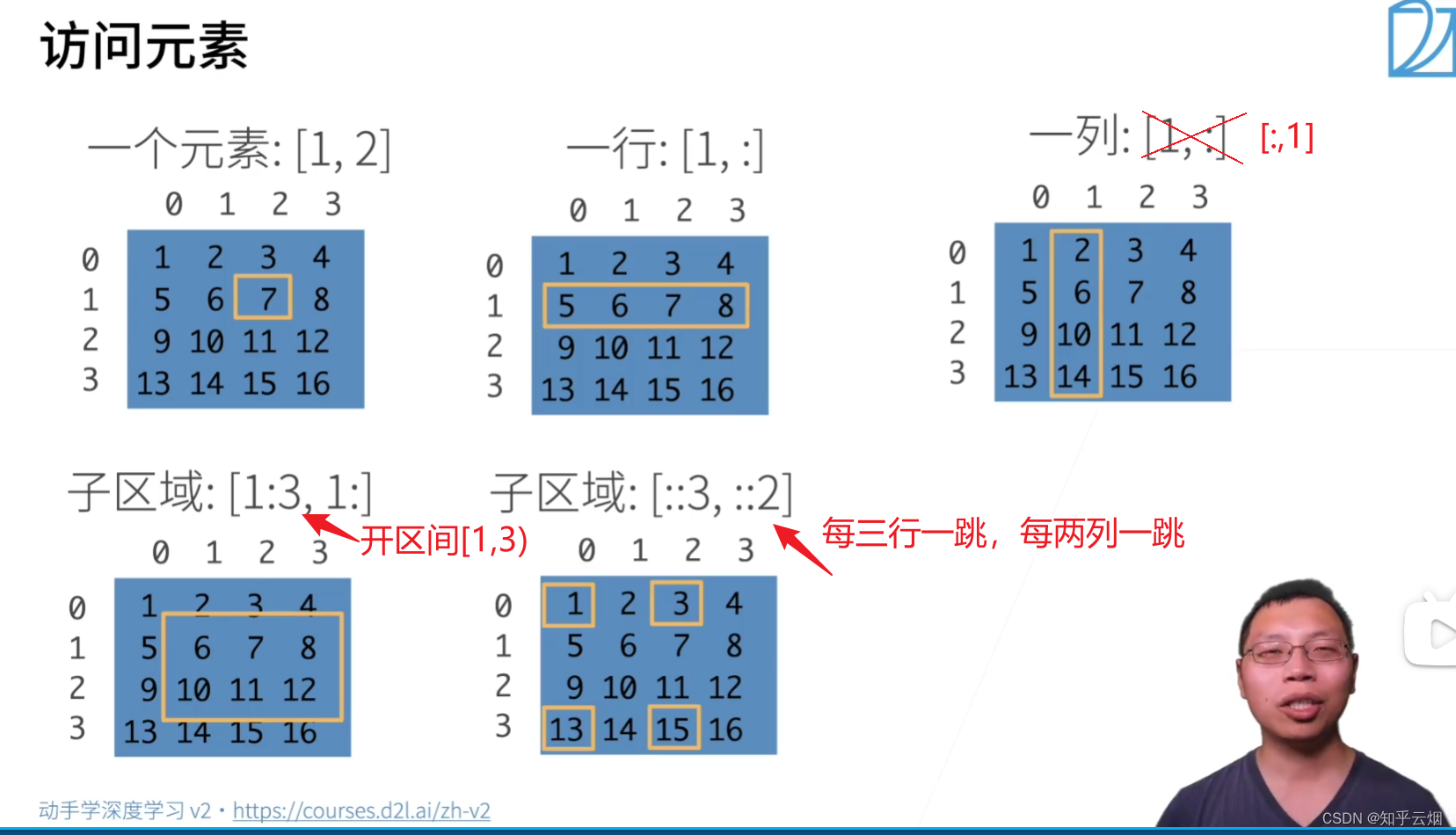
- (3)访问元素
- 2.数据操作实现
- (1)补充:Jupyter的入门
- (2)补充:Markdown的入门
- (3)数据操作
- 3.数据预处理
- 4.数据操作QA
- 五、线性代数
- 1.线性代数
- (1)标量
- (2)向量
- (3)矩阵
- (4)特殊矩阵
- 2.线性代数的实现
- 3.按特定轴求和
- 4.线性代数QA
说明:该文章是学习 李沐老师在B站上分享的视频 动手学深度学习 PyTorch版而记录的笔记, 版权归李沐老师以及老师背后的团队所有,为了节省时间,笔记仅仅是粗浅的截图以及贴上代码,作用仅仅是复习以及忘了方便到b站上进行回看,以及方便更多的人学习。 若有侵权,请联系本人删除。笔记难免可能出现错误或笔误,若读者发现笔记有错误,欢迎在评论里批评指正。另外 部分内容直接由镜像GPT生成,请自行注意甄别。
笔记可能更新缓慢,建议去b站观看完整视频。
其他参考链接: Windows 下安装 CUDA 和 Pytorch 跑深度学习 - 动手学深度学习v2、 python数据分析神器Jupyter notebook快速入门、 也许是B站最好的 Markdown 科普教程、 Markdown的官方文档
课程主页:https://courses.d2l.ai/zh-v2
教材:https://zh-v2.d2l.ai
课程论坛讨论:https://discuss.d2l.ai/c/16
Pytorch论坛:https://discuss.pytorch.org/
预告

1.学习深度学习的关键是动手

2.什么是《动手学深度学习》

3.曾经推出的版本(含github链接)

含github链接:https://github.com/d2l-ai/d2l-zh


一、课程安排
1.目标

2.内容

3.上课形式

4.你将学到什么

5.资源

课程主页:https://courses.d2l.ai/zh-v2
教材:https://zh-v2.d2l.ai
课程论坛讨论:https://discuss.d2l.ai/c/16
Pytorch论坛:https://discuss.pytorch.org/
二、深度学习的介绍

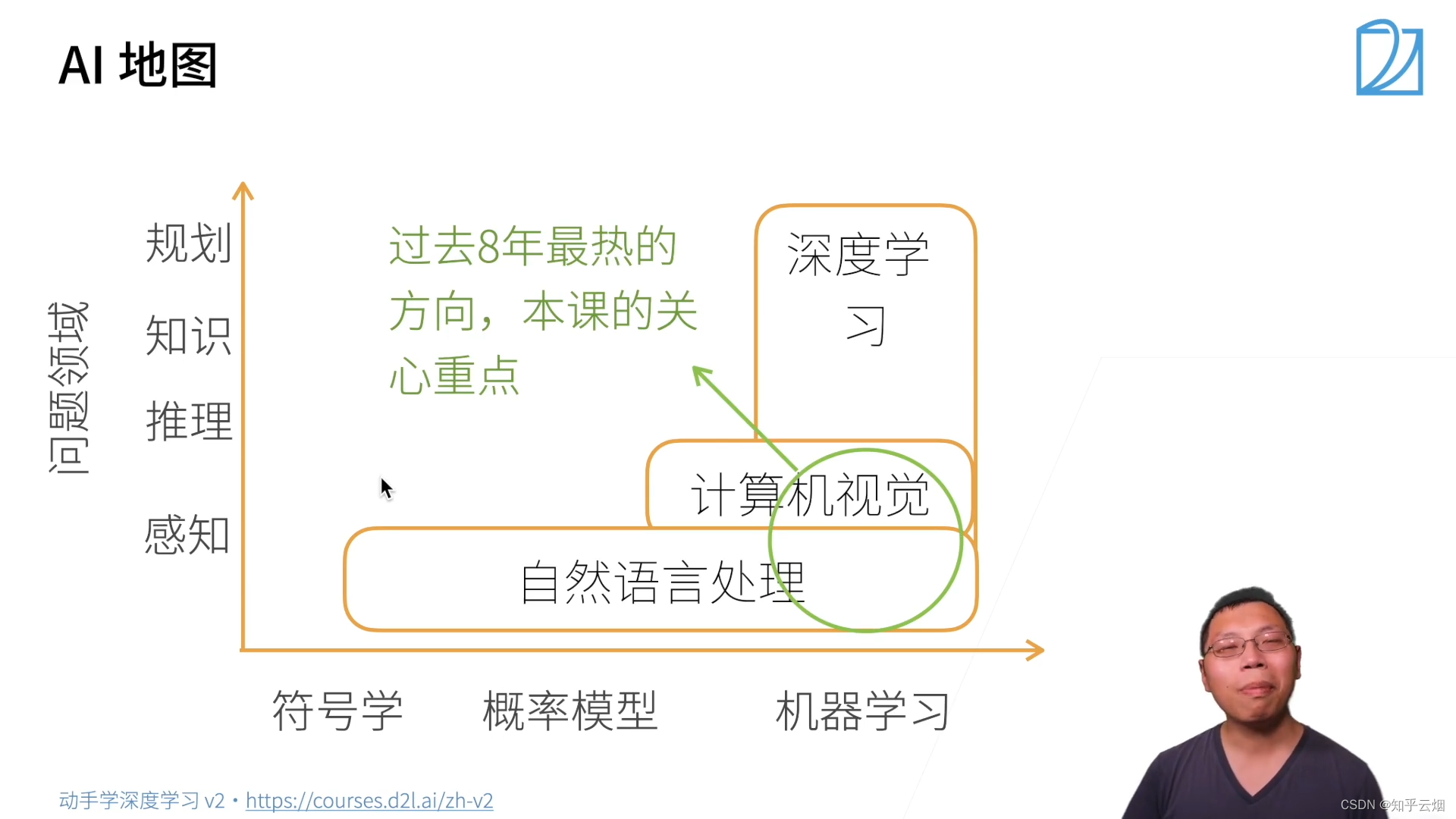
1.AI地图
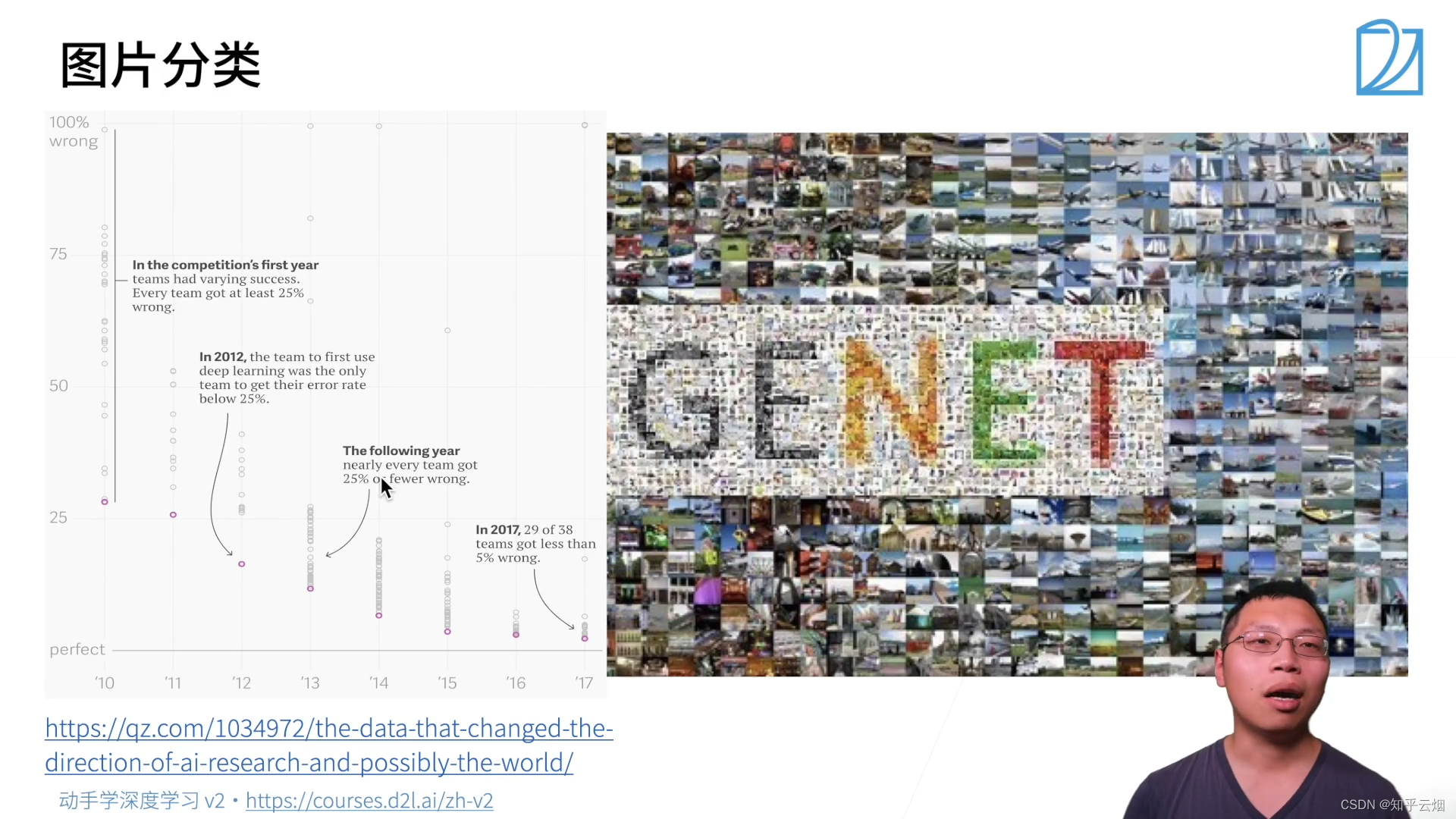
2.深度学习在一些应用上的突破
图片分类、物体检测和分割、样式迁移、人脸合成、文字生成图片、文字生成、无人驾驶、广告点击等。

http://www.image-net.org/

https://github.com/matterport/Mask_RCNN

https://github.com/StacyYang/MXNet-Gluon-Style-Transfer




https://openai.com/blog/dall-e/


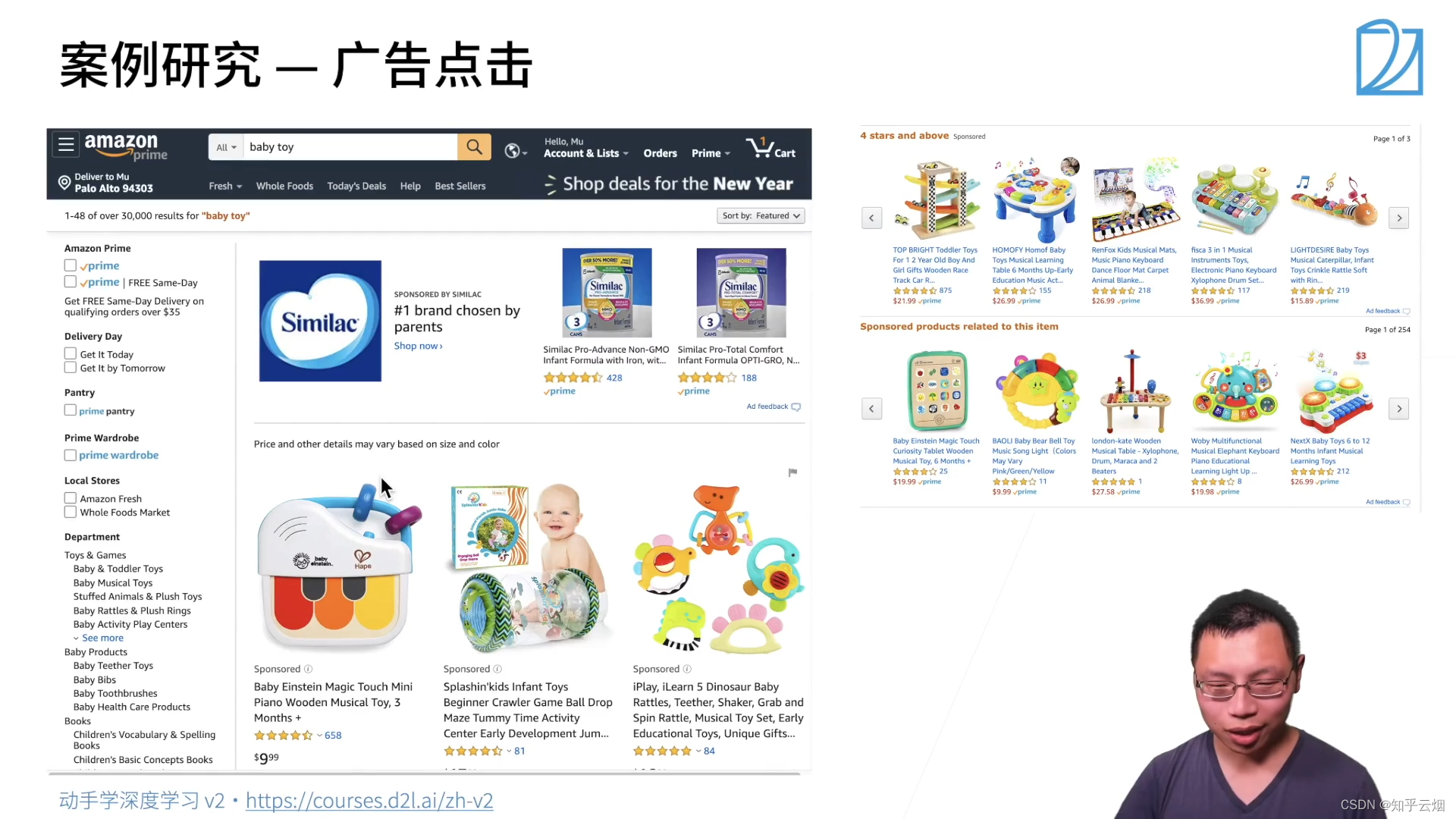
3.案例研究一广告点击
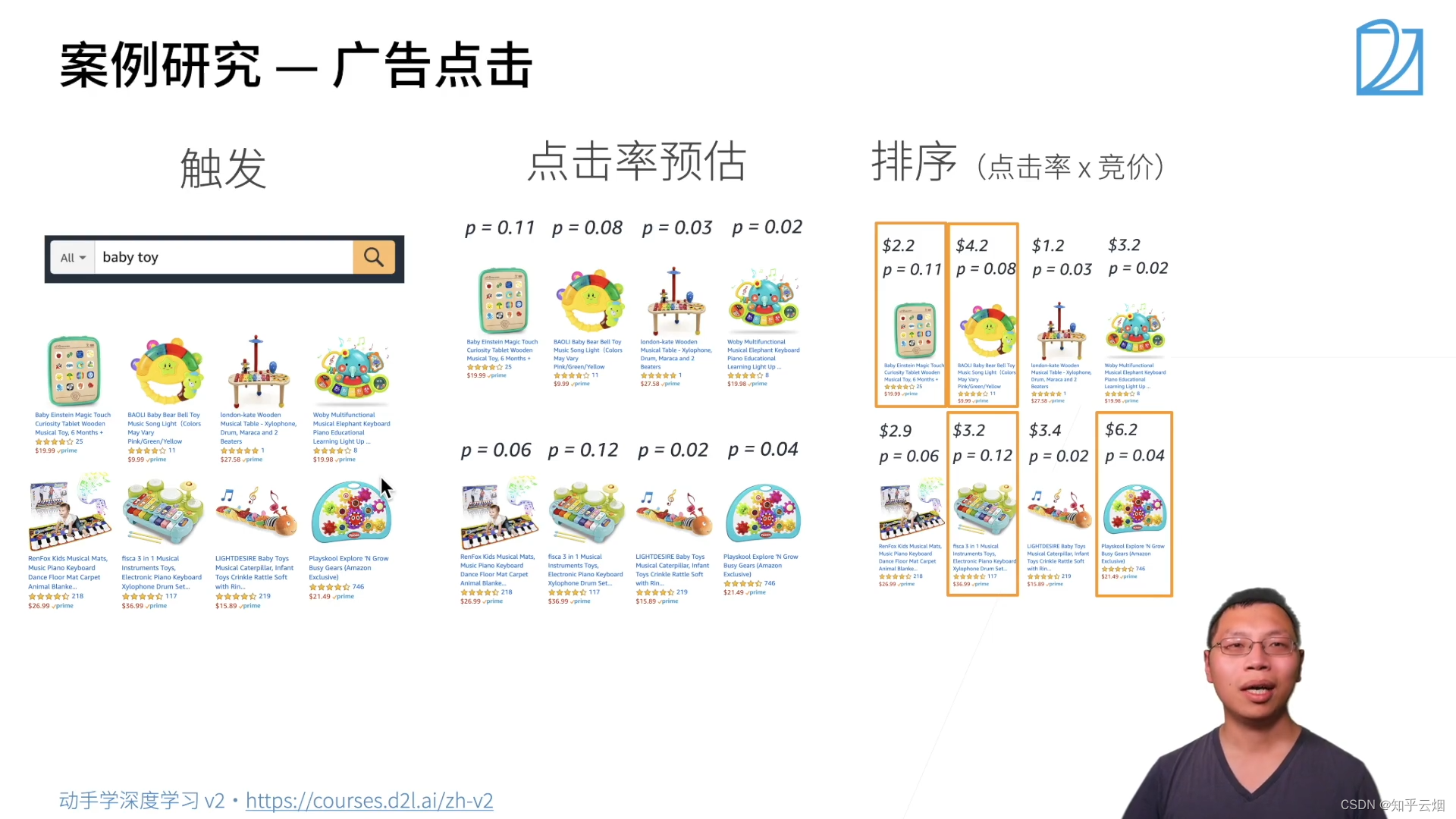

简单的机器学习包括特征提取、模型的预测。
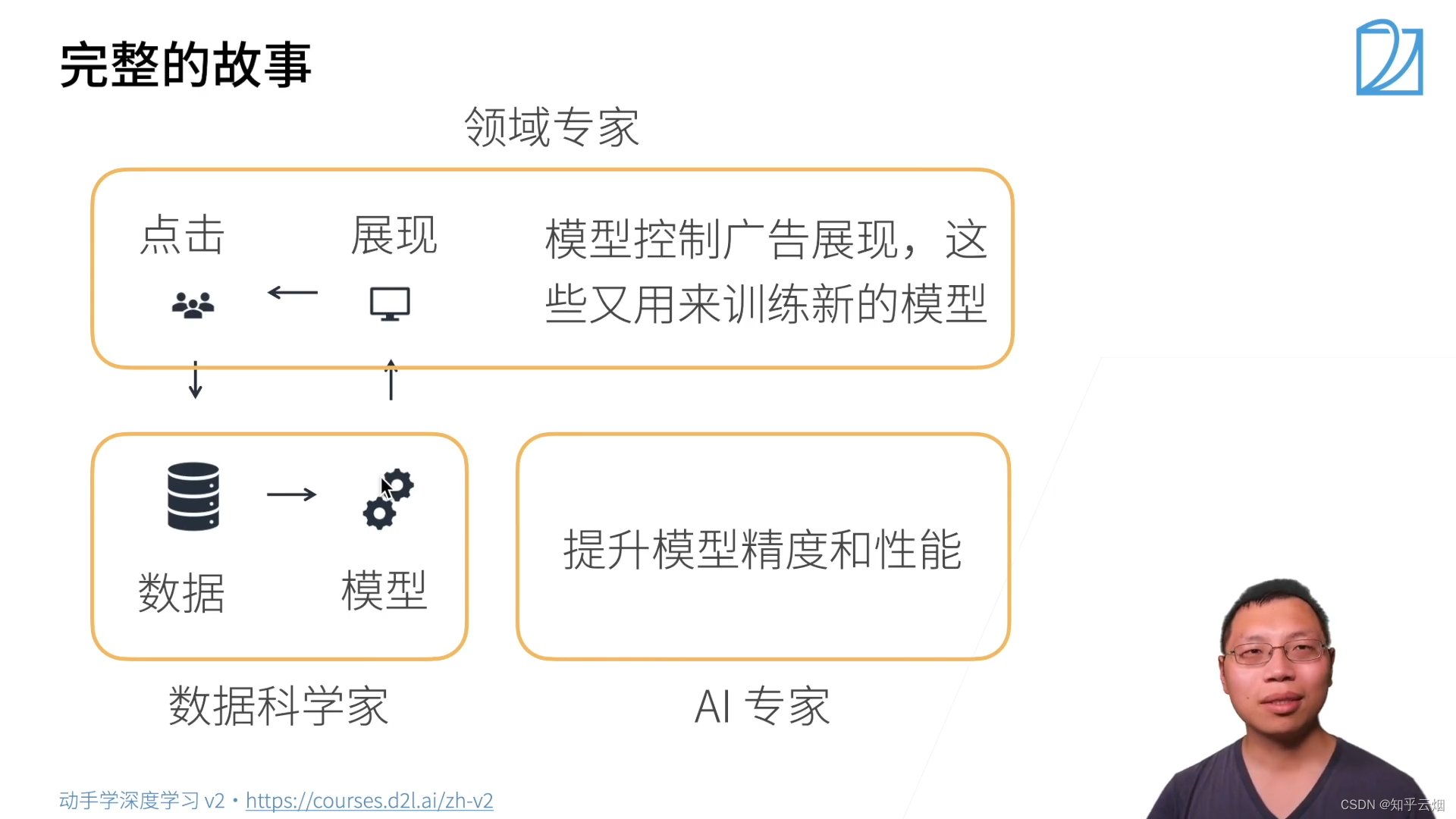
三、安装


# 1.[可选]使用conda/miniconda环境
conda env remove d2l-zh
conda create -n -y d2l-zh python=3.8 pip
conda activate d2l-zh
# 2.安装需要的包
pip install -y jupyter d2l torch torchvision
# 3.下载代码并执行
wget https://zh-v2.d2l.ai/d2l-zh.zip
unzip d2l-zh.zip
jupyter notebook
关于安装这块,初学者可能大家跟我一样看不懂云端的配置方法,故请切换到李沐老师的非云端的环境配置方法的视频:Windows 下安装 CUDA 和 Pytorch 跑深度学习 - 动手学深度学习v2
1.Windows下的安装CUDA
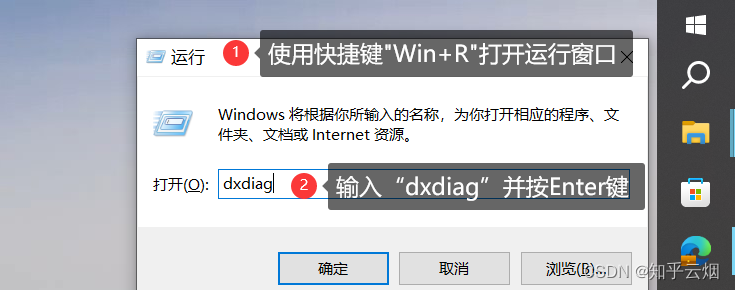
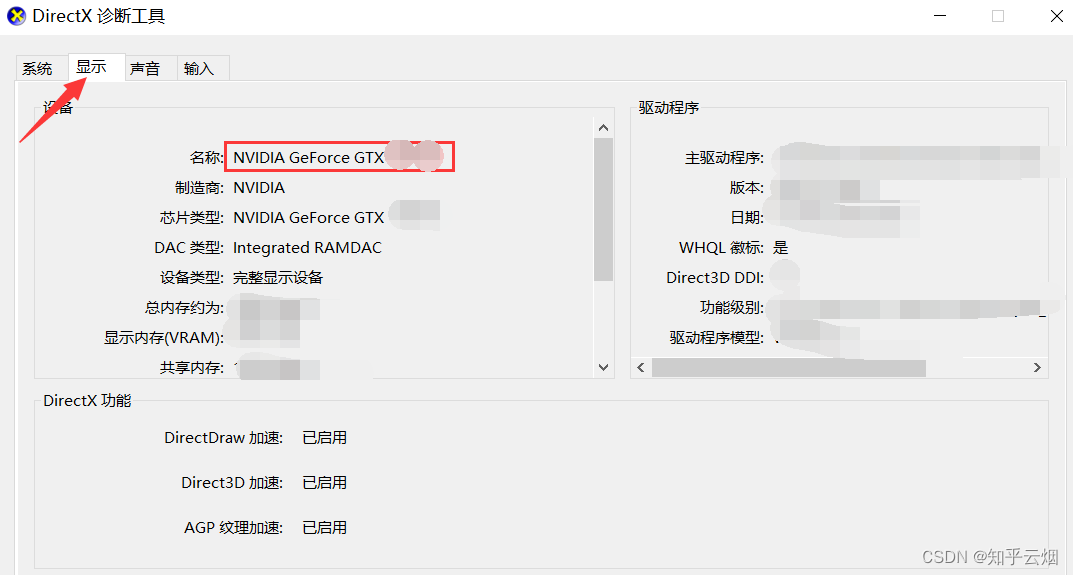
首先,如下图所示,使用快捷键"Win+R"打开运行窗口,然后输入“dxdiag”并回车。然后点击“显示”,查看电脑是否有NVIDIA的GPU,如果没有,本安装方法不适用。
dxdiag
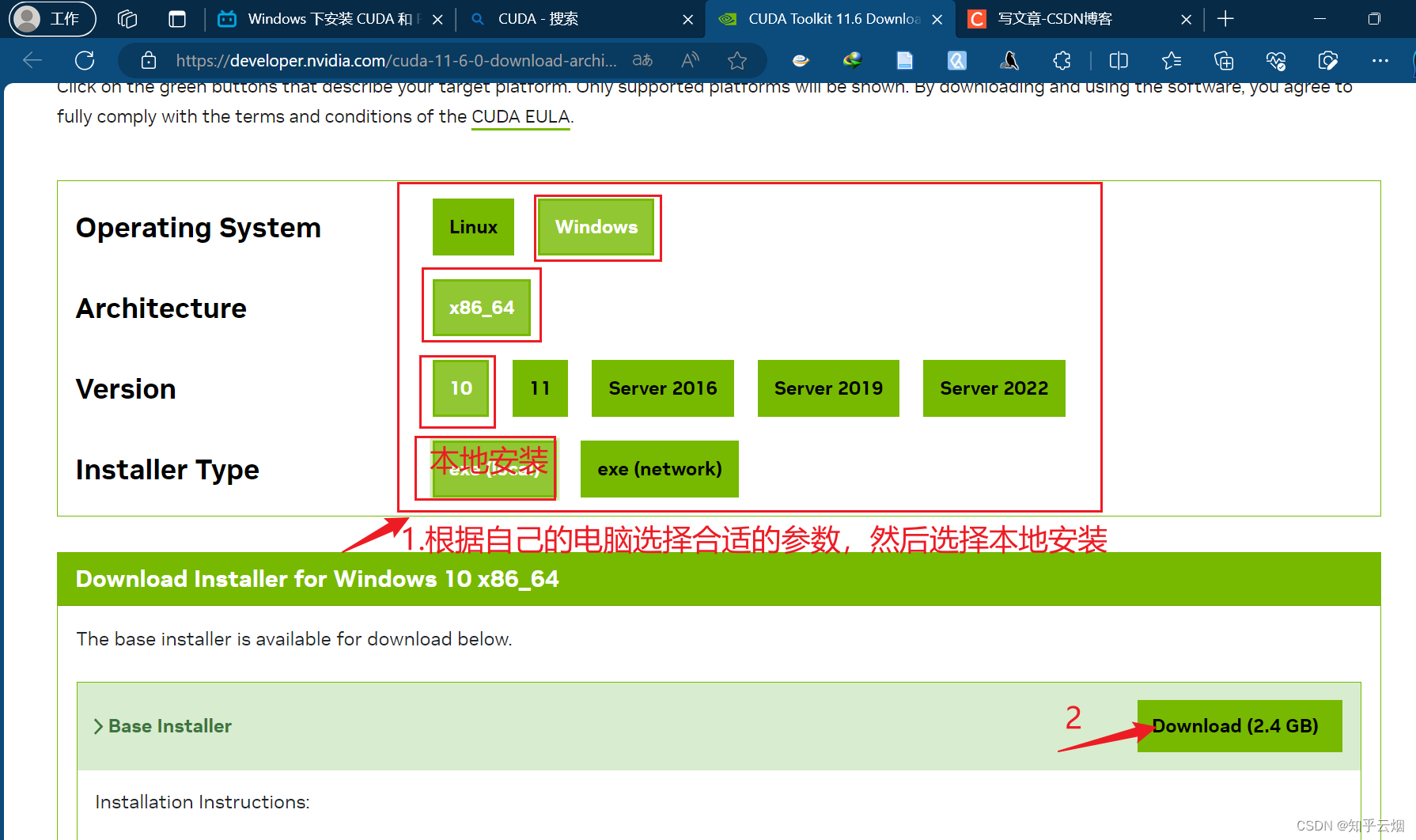
接下来我们去Nvidial的官网下载CUDA。可直接搜素“CUDA”,点击“CUDA Toolkit 11.6 Downlo…”。然后根据自己的电脑选择合适的参数,选择本地安装,点击“Download”即可进行下载。(注意:此处版本最好安装11.8或12.1的,2023.10.5注明,此时PyTorch最新支持这两个版本。建议大家在选择版本前,先到Pytorch官网(“https://pytorch.org/”)看看。)

双击安装。
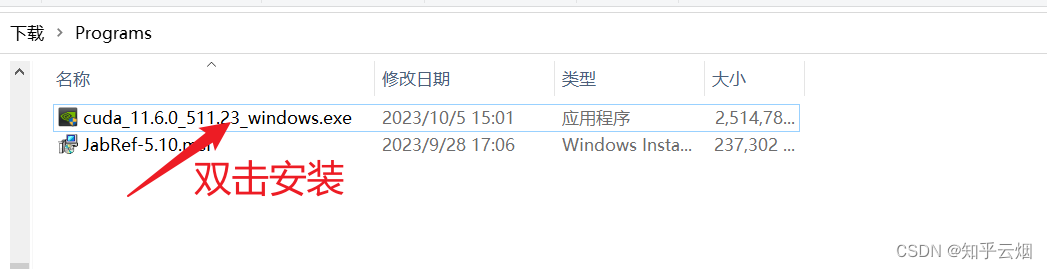
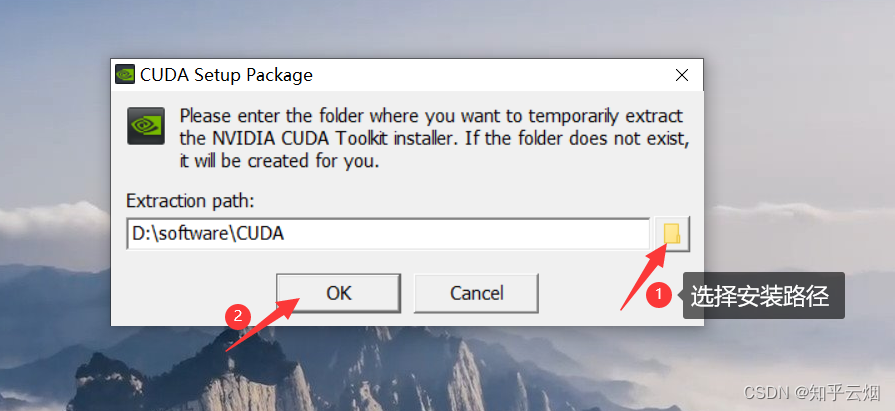
选择安装目录,点击“OK”。
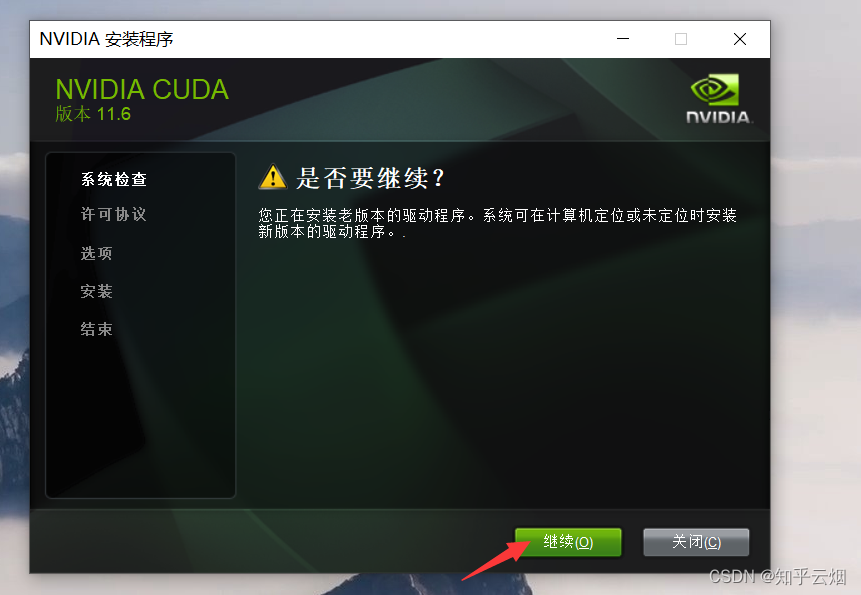
点击“继续”。(未安装过CUDA的可能不会出现这个页面。)
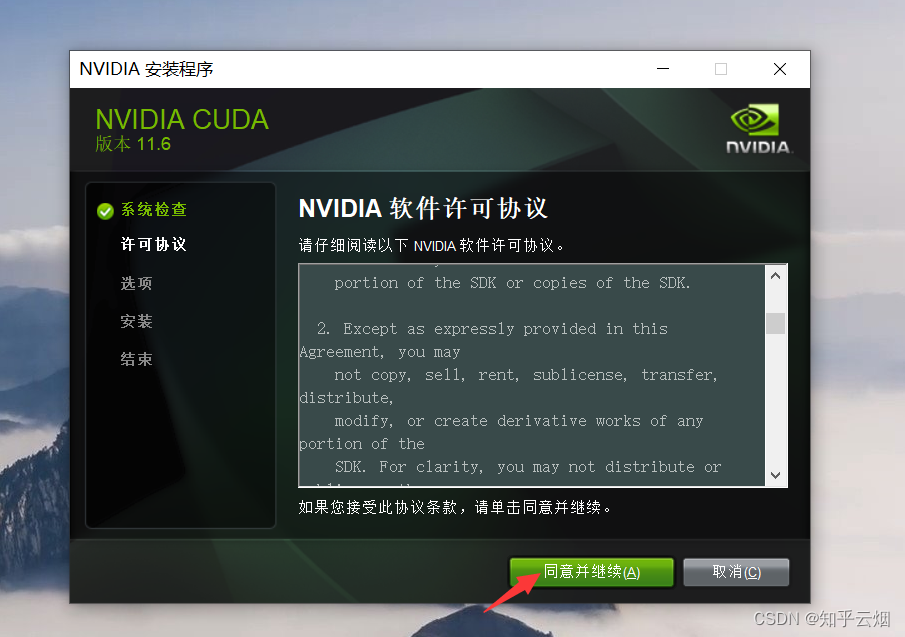
接着按下面一堆图所示操作。
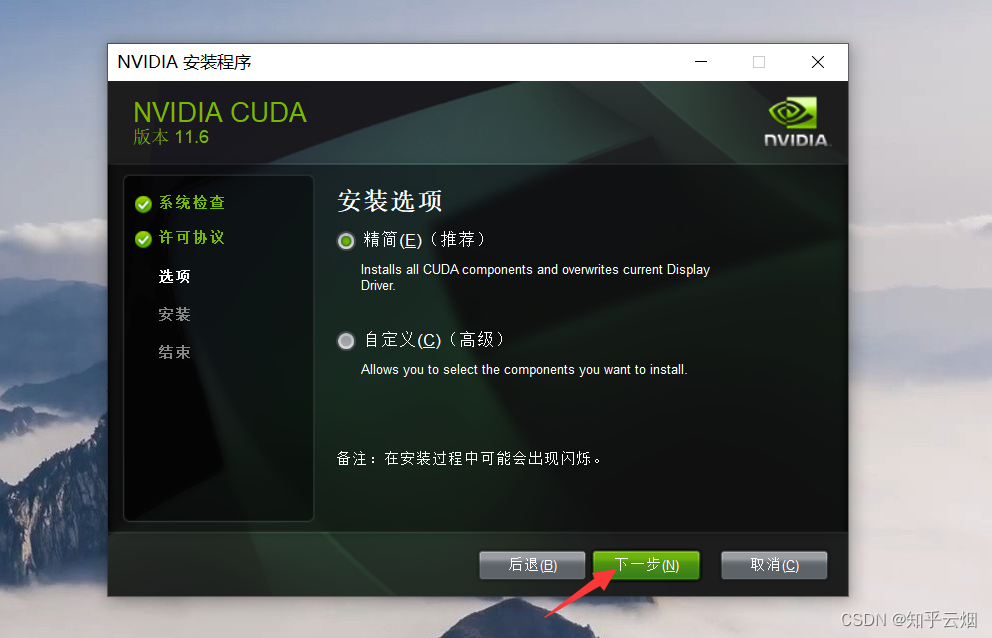
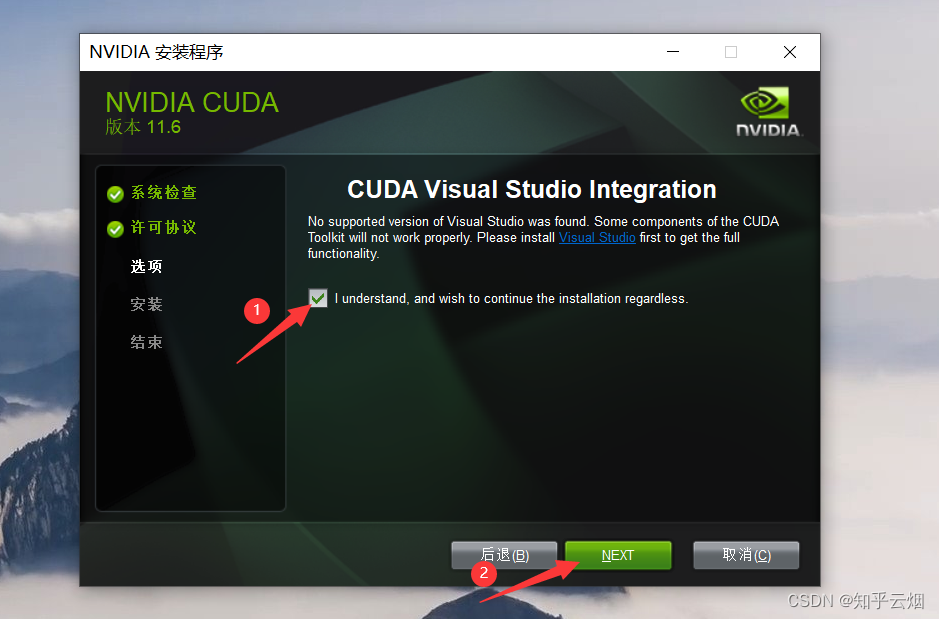
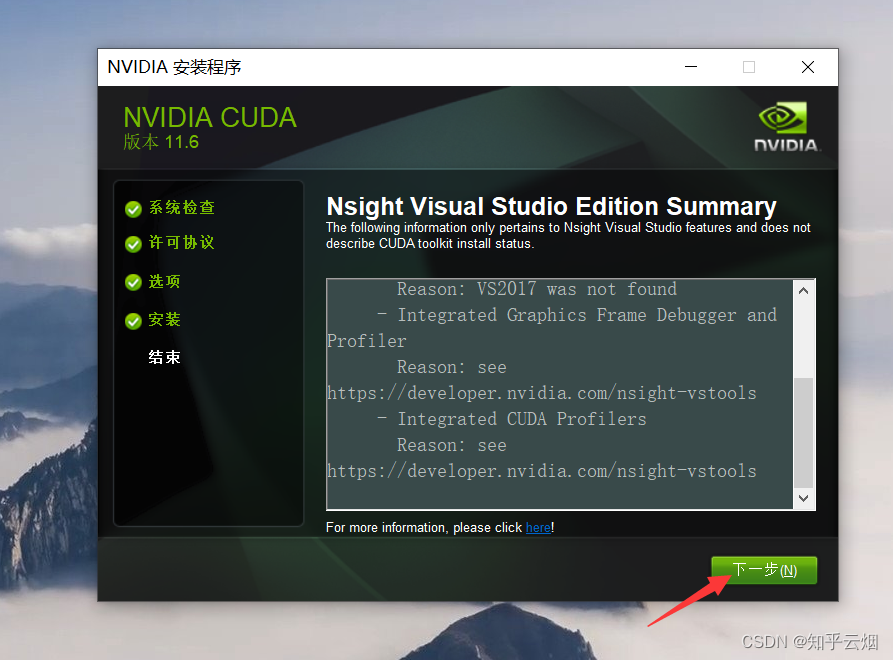
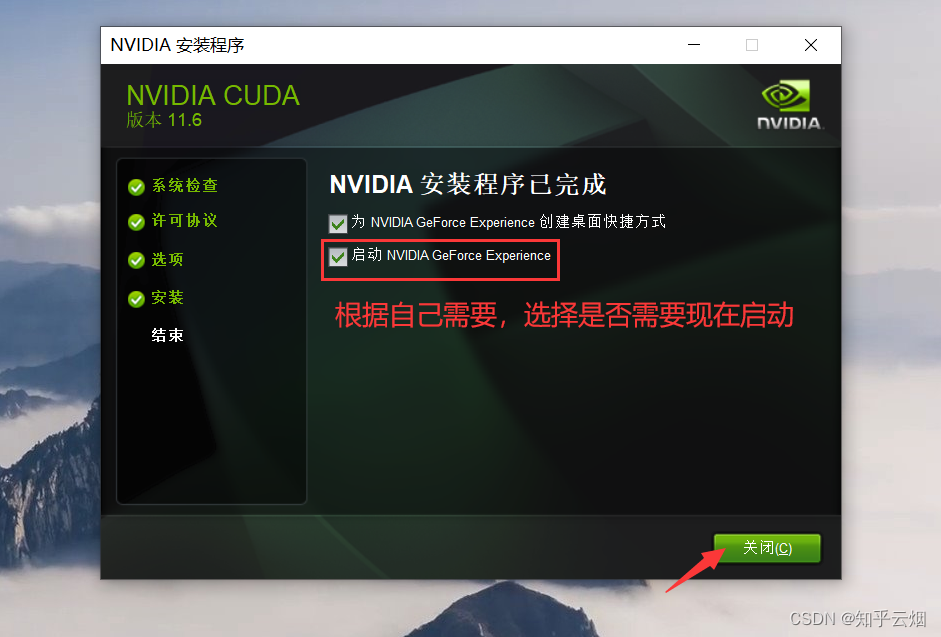
2.验证CUDA是否安装成功
如下图,打开命令行窗口。
然后输入命令“nvidia-smi”,能查到CUDA的版本号,说明CUDA安装成功。
nvidia-smi

3.下载并安装一个Python环境(安装Miniconda)
首先进入“Conda”(链接“https://docs.conda.io/en/latest/”),然后点击“Miniconda”,点击“Miniconda3 Windows 64-bit”。

如下一堆图所示进行安装。

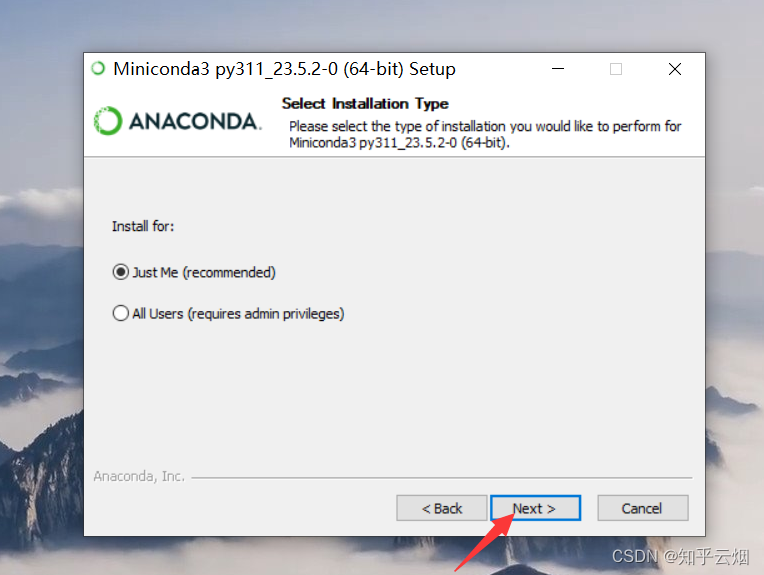
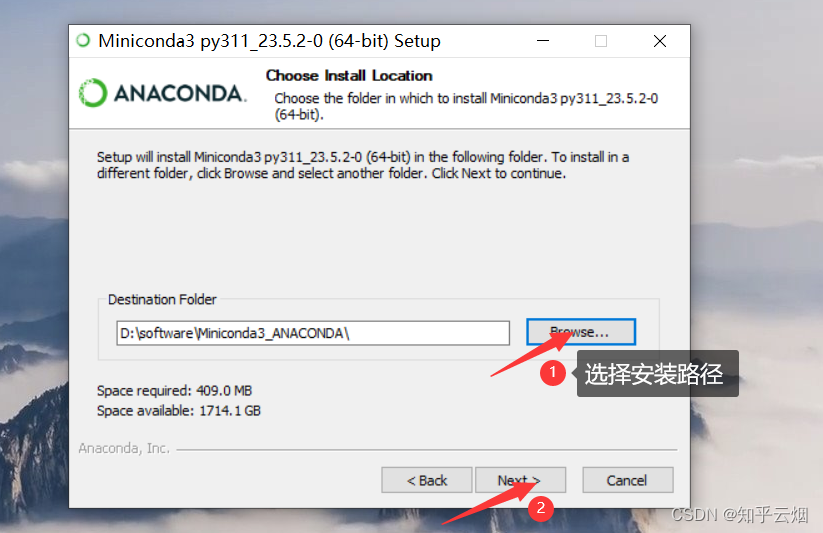
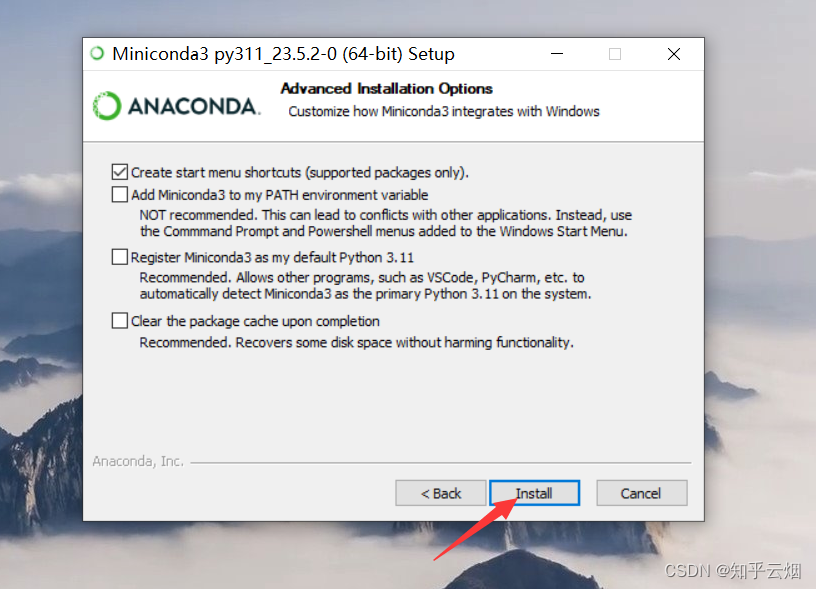
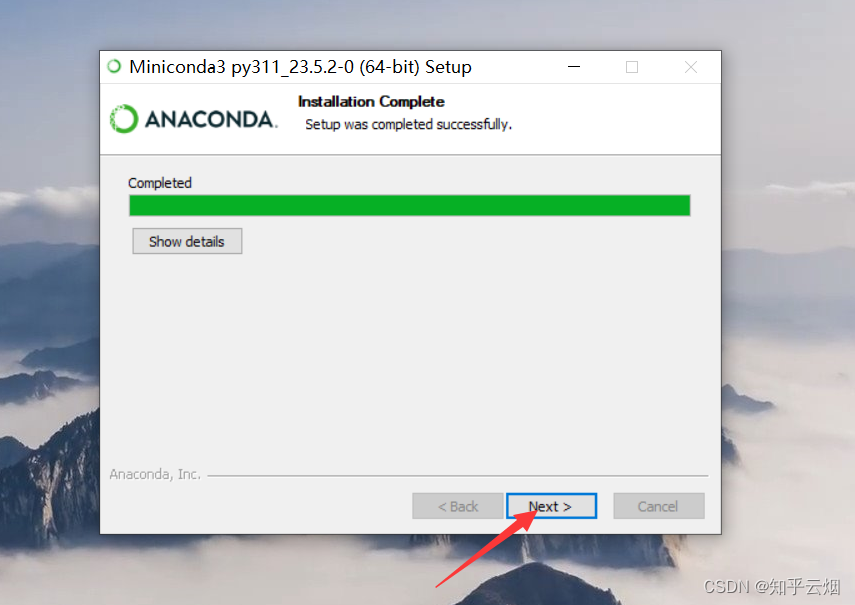
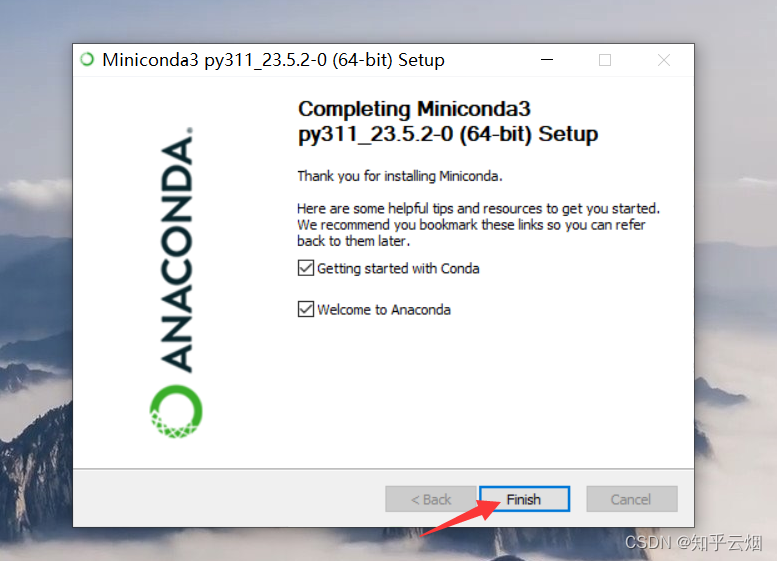
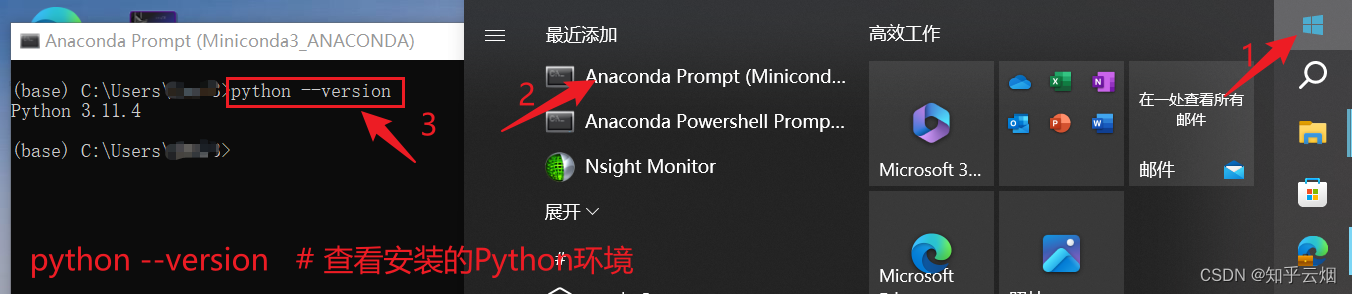
然后如下图所示查看安装的Python环境。
python --version # 查看安装的Python环境
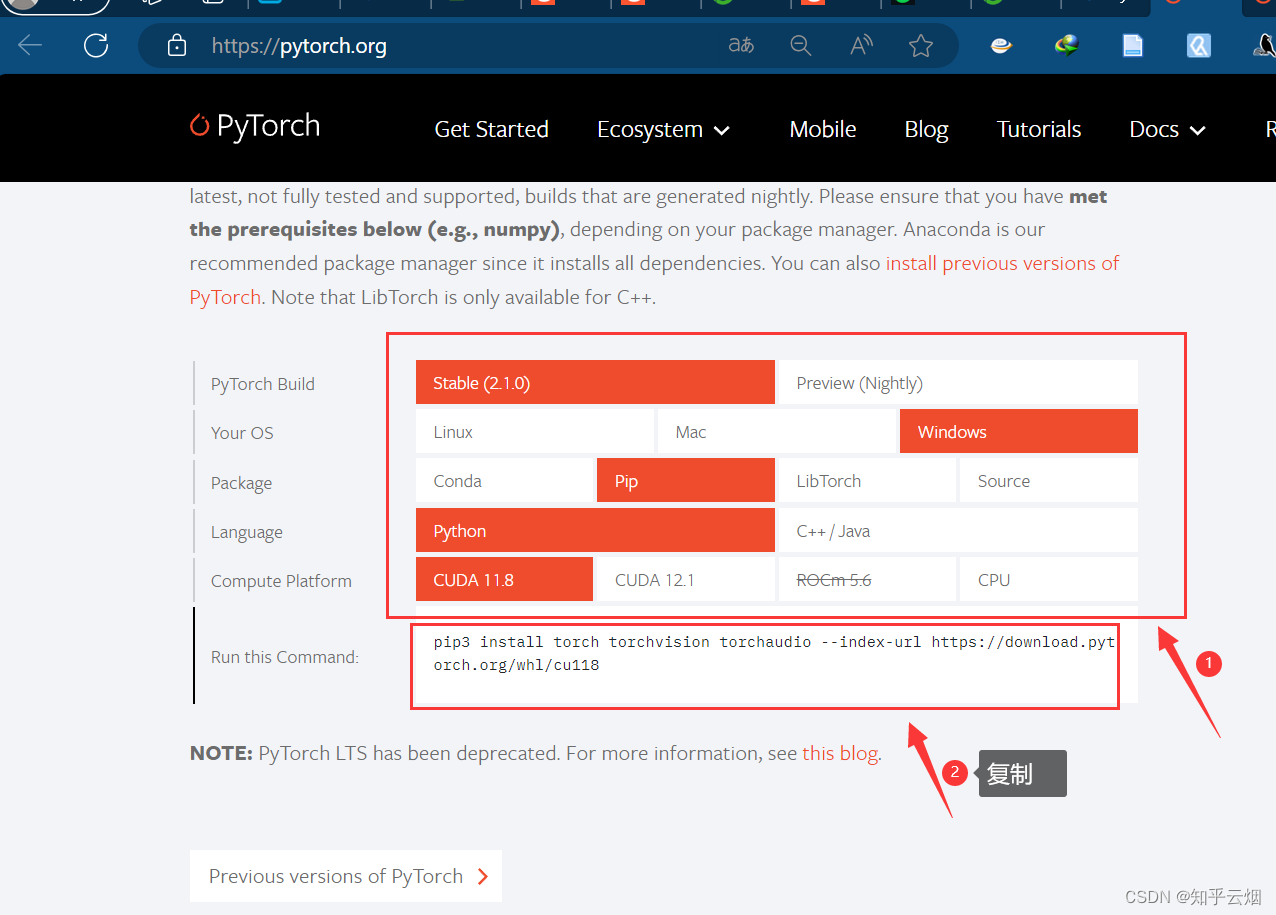
4.到Pytorch官网下载对应的GPU版本
接着到到Pytorch官网(“https://pytorch.org/”)下载对应的GPU版本。发现刚刚装的CUDA(版本11.6)不是最新的,于是选择版本11.8的,版本差异最小,有点小问题。
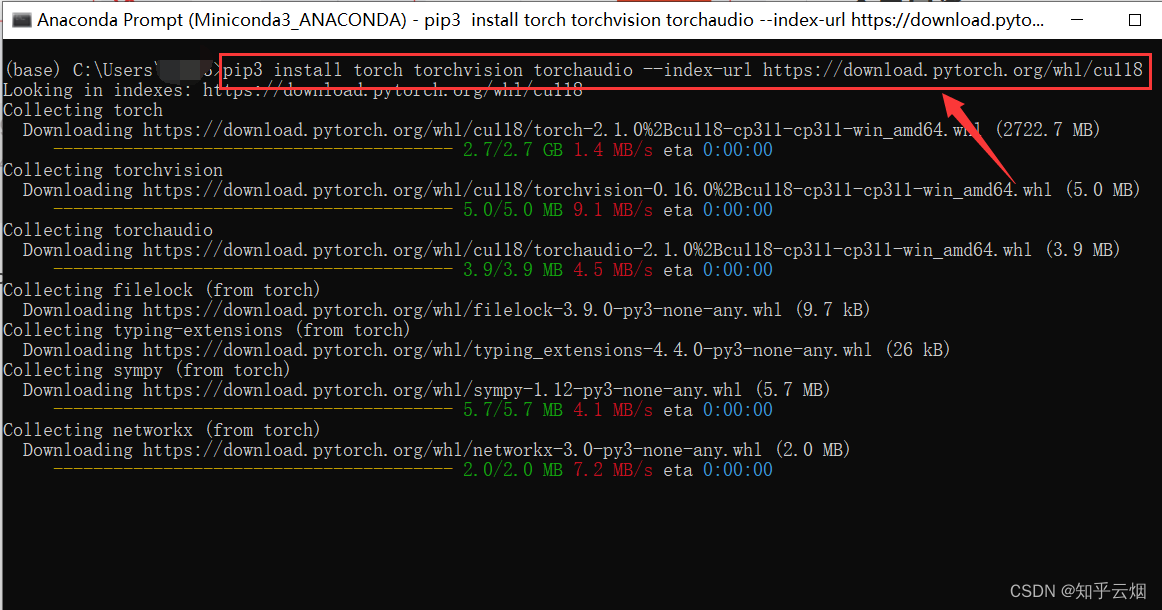
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
然后到”Anaconda Prompt“去执行刚刚复制的pip命令。
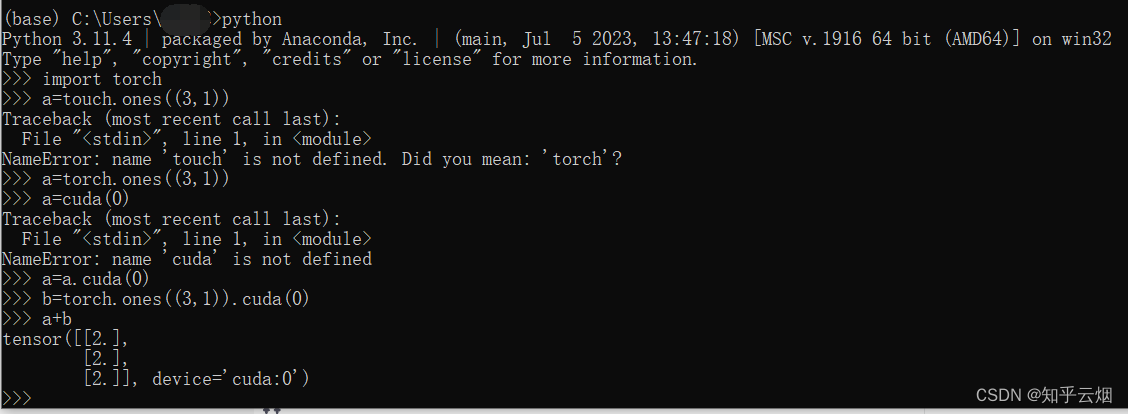
安装完后,我们尝试在GPU上运行一个简单的Python程序,验证是否有问题。结果发现程序能够正常运行,说明没有问题。(本人代码输错了好几次,请忽略)
python # 进入python
import torch
a=torch.ones((3,1))
a=a.cuda(0)
b=torch.ones((3,1)).cuda(0)
a+b
5.运行一个深度学习的应用(安装jupyter和d2l;下载d2I记事本,运行测试)
打开教材官网:https://zh-v2.d2l.ai。然后下载记事本并解压。
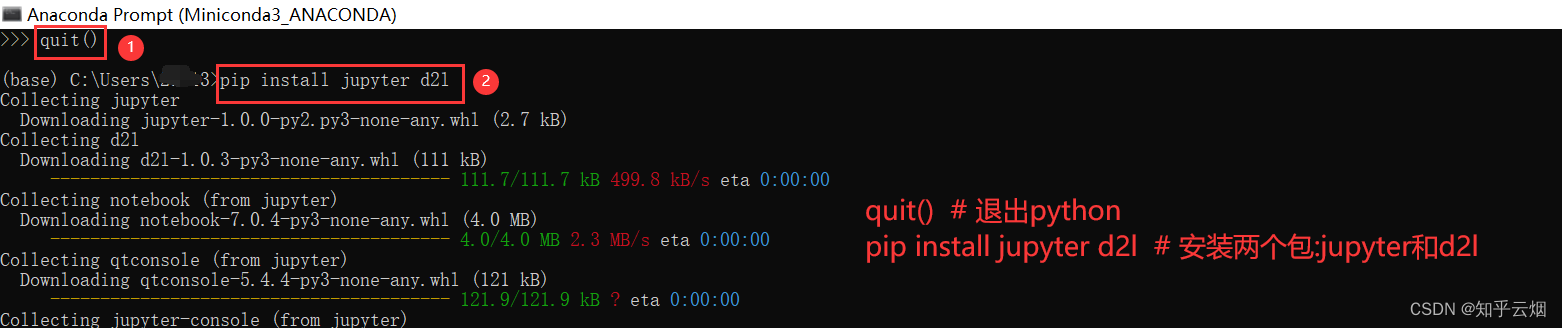
接着退出python,再安装两个包:jupyter和d2l。
quit() # 退出python
pip install jupyter d2l # 安装两个包:jupyter和d2l
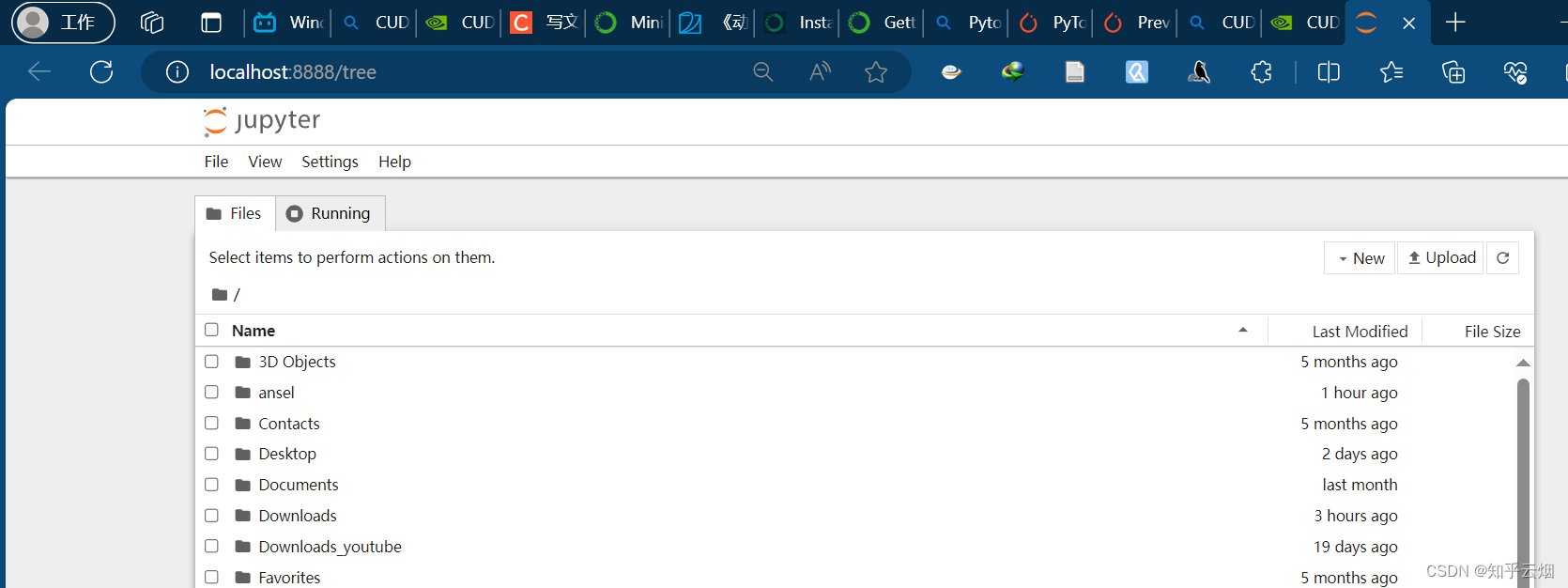
如下图所示启动”jupyter notebook“,会自动打开一个浏览器窗口。
jupyter notebook # 启动”jupyter notebook“

然后类似下面的路径,找到”resnet.ipynb“并点击。
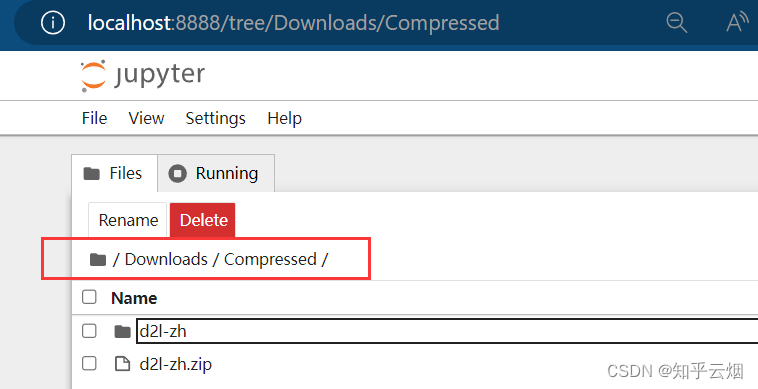
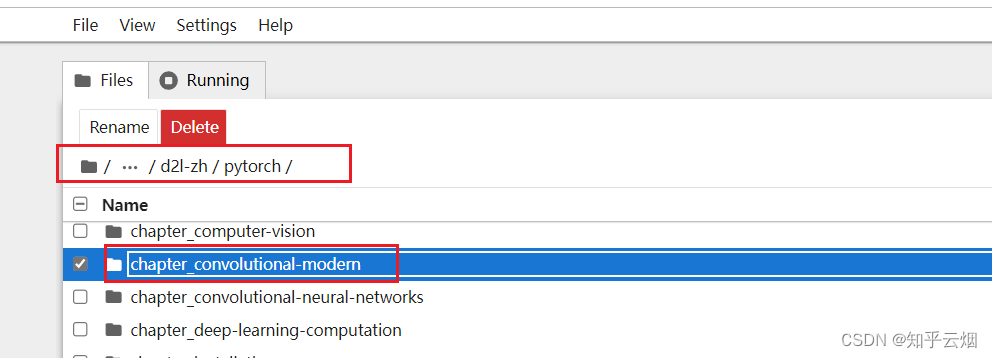
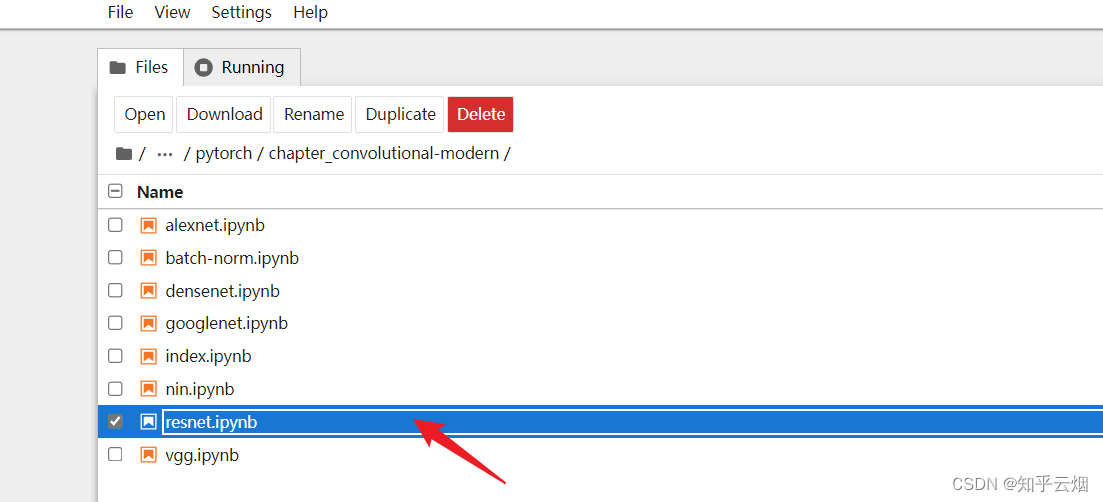
接着,选择”Kernel“,点击运行所有的选项”Restart Kernel and Run All Cells…“。点击”Restart“。
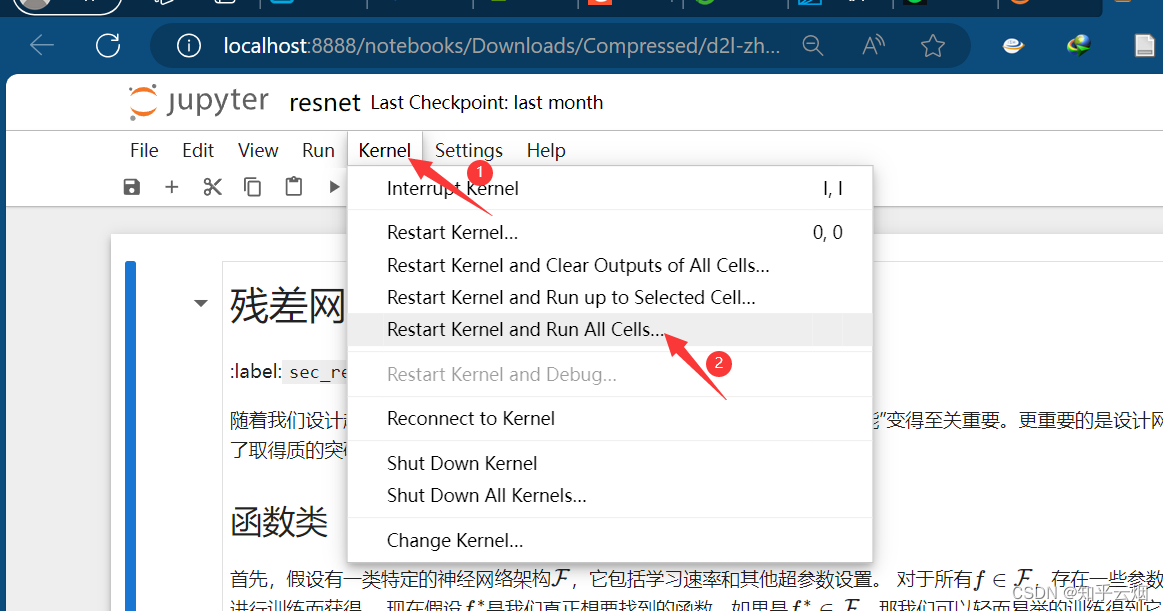
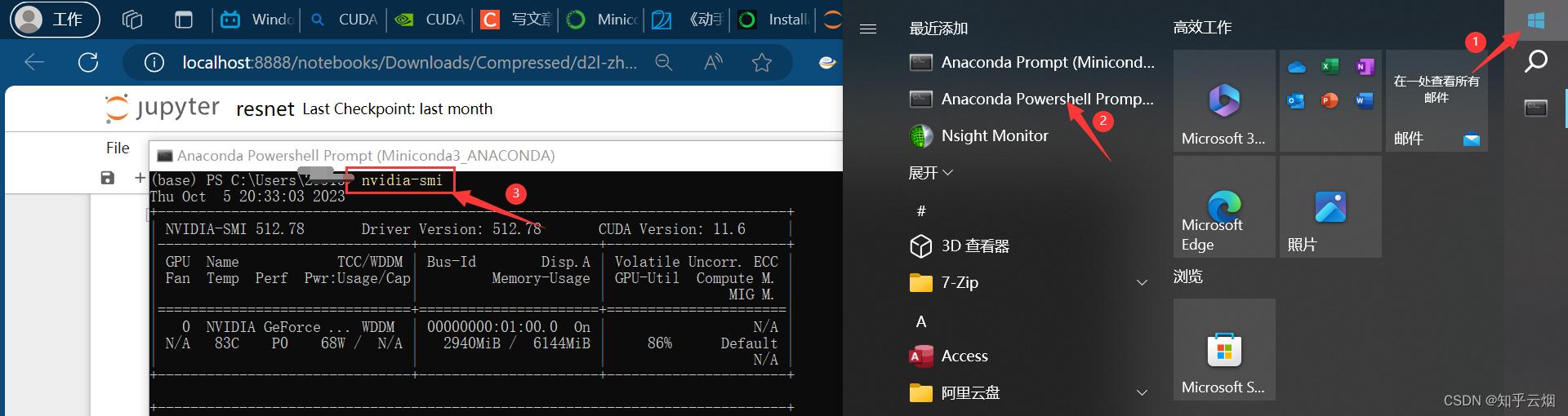
然后将页面拖到最后,发现模型已经跑了起来。打开”Anaconda Powershell Promp…“,输入”nvidia-smi“查看GPU的使用率。
nvidia-smi # 查看GPU的使用率
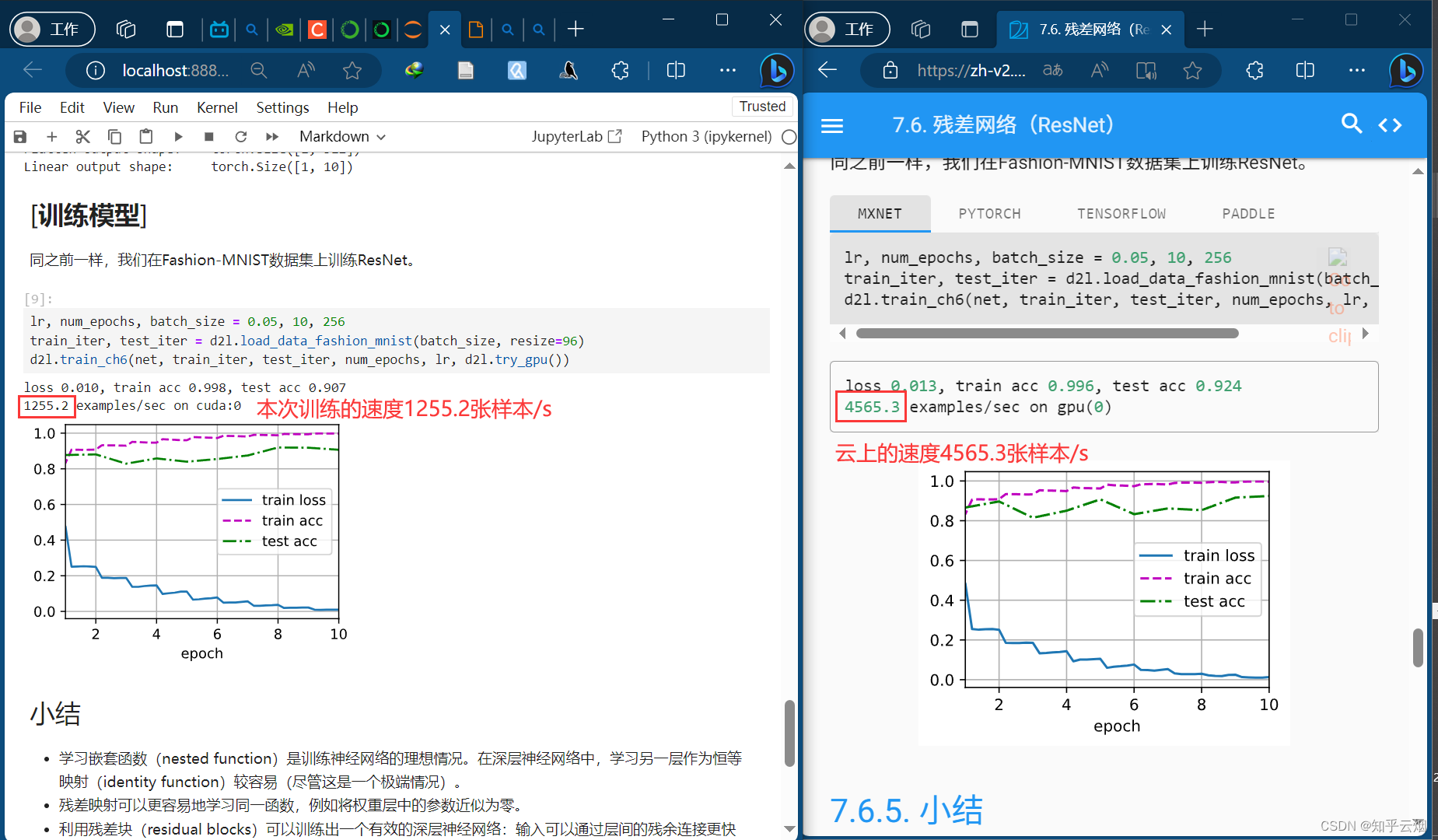
等模型跑完后,打开教材对应的地方,对比两次的结果。
6.本次总结

四、数据操作+数据预处理
1.数据操作

(1)N维数组样例
(2)创建数组
(3)访问元素
2.数据操作实现
(1)补充:Jupyter的入门
关于Jupyter notebook的使用,大家可以随便找个视频学习一下,比如本人观看了下面的视频:python数据分析神器Jupyter notebook快速入门。
需要知道(由于Jupyter的改版,部分操作有所变化):
注:这些内容均来源于刚刚的链接,只是少部分由于Jupyter的改版,操作有所变化
1.特点:把代码和文本变成单元格,可逐步运行单元格或运行部分单元格。
2.优点:
-(1).学习简单,掌握十几个快捷键即可飞速入门。
-(2).Jupyter是以代码块和单元格为单位进行运行的。优点:容易查看中间变量,易调试,方便找出bug。
-(3).可插入markdown的说明性文字。
3.安装
pip install jupyter # 安装jupyter包
4.新建文件
- New-选择需要创建的文件类型或者文件夹等
5.打开方式以及创建“jupyter”文件
- 打开命令行窗口,输入命令”jupyter notebook“即可打开。(注意:如果是跟着本笔记走的,得去“Anaconda Prompt”中打开,因为是在那里面安装的jupyter包,否则不能启动jupyter)
jupyter notebook # 启动”jupyter notebook“,让浏览器使用jupyter打开当前目录
- 浏览器使用jupyter打开当前目录后,然后寻找jupyter文件。第一次使用可能没有jupyter文件,此时选择一个合适的目录,然后右击“New Notebook”创建“.ipynb”的jupyter notebook文件
- 选择语言类型,点击“Select”,即可成功创建文件。
6.文档编辑
- 自行学习markdown的编写方式以及听刚刚给出的链接的视频
- 分为命令模式和编辑模式
- 公式可使用LaTeX代码
7.快捷键
- 查看快捷键:Help-Show Keyboard Shortcuts。下面是将快捷键复制出来经翻译后的结果,个别是补充的:
** 命令模式 ESC
** 重新做 Ctrl + Shift + Z
** 撤销 Ctrl + Z
中断内核 I + I
重新启动内核… 0 + 0
** 切换到代码单元格类型 Y
切换到标题1 1
切换到标题2 2
切换到标题3 3
切换到标题4 4
切换到标题5 5
切换到标题6 6
** 切换到Markdown单元格类型 M
切换到原始单元格类型 R
折叠所有标题 Ctrl + Shift + ArrowLeft
** 复制单元格 C
** 剪切单元格 X
** 删除单元格 D + D
** 进入编辑模式 Enter
展开所有标题 Ctrl + Shift + ArrowRight
向上扩展选择 Shift + ArrowUp
向上扩展选择 Shift + K
向下扩展选择 Shift + ArrowDown
向下扩展选择 Shift + J
扩展选择至底部 Shift + End
扩展选择至顶部 Shift + Home
** 在上方插入单元格 A
** 在下方插入单元格 B
在当前标题上方插入标题 Shift + A
在当前标题下方插入标题 Shift + B
合并上方单元格 Ctrl + Backspace
合并下方单元格 Ctrl + Shift + M
合并选定单元格 Shift + M
下移单元格 Ctrl + Shift + ArrowDown
上移单元格 Ctrl + Shift + ArrowUp
选择下方单元格 ArrowDown
选择下方单元格 J
选择上方标题或折叠标题 ArrowLeft
选择下方标题或展开标题 ArrowRight
选择上方单元格 ArrowUp
选择上方单元格 K
粘贴至下方单元格 V
重做单元格操作 Shift + Z
** 运行选定单元格并不前进 Ctrl + Enter
运行选定单元格并在下方插入 Alt + Enter
选择所有单元格 Ctrl + A
** 显示行号 Shift + L
并排渲染 Shift + R
撤销单元格操作 Z
** 运行选定单元格并跳到下一单元格 Shift + Enter
结束搜索 Escape
查找下一个 Ctrl + G
查找上一个 Ctrl + Shift + G
查找… Ctrl + F
激活下一个标签 Ctrl + Shift + ]
激活下一个标签栏 Ctrl + Shift + .
激活上一个标签 Ctrl + Shift + [
激活上一个标签栏 Ctrl + Shift + ,
切换左侧区域 Ctrl + B
切换模式 Ctrl + Shift + D
激活命令面板 Ctrl + Shift + C
显示键盘快捷键 Ctrl + Shift + H
** 暂停 F9
** 下一步 F10
调试器面板 Ctrl + Shift + E
步入 F11
步出 Shift + F11
** 终止 Shift + F9
** 保存笔记本 Ctrl + S
另存为笔记本… Ctrl + Shift + S
激活以前使用的标签 Ctrl + Shift + '
目录 Ctrl + Shift + K
8.文件重命名
- 听刚刚给出的链接的视频或者自己摸索或者上网查
9.运行
- (1)全部运行:Run-Run All Cells。代码块前显示数字,表示未执行;显示“[*]”,表示已执行。
- (2)运行代码块:快捷键Shift+Enter其他操作请自己摸索,慢慢就熟悉了
(2)补充:Markdown的入门
参考的视频链接:也许是B站最好的 Markdown 科普教程。
1.定义:一种轻量级的标记语言。
2.Markdown编辑器:将Markdown文档渲染为HTML的格式,以供在Web浏览器中浏览阅读。
3.优点:沉浸、统一、可迁移
4.语法:
- (1)标题
- 一级标题:“# 一、**”
- 二级标题:“## 1.1**”
- 依次类推,一般支持6级标题
- (2)无序列表
- 格式:“- 无序列表”。效果:“▪ 无序列表”
- (3)有序列表
- 格式:“1. 有序列表”,回车可以让数字有序增加,Tab键可以可以缩进列表,Shitf+Tab键取消列表缩进。
- (4)斜体
- 格式:“*斜体*”
- (5)加粗
- 格式:“**加粗**”
- (6)删除
- 格式:“~~删除~~”
- (7)高亮
- 格式:“==高亮==”
- 部分不支持的地方可使用html格式:“<mark>torch</mark>”
- (8)分割线
- 用法:“---”,再回车
- (9)超链接
- 格式:“[百度](https://www.baidu.com/)”,方框内是标题,括号内是链接。其他语法请参考Markdown的官方文档,链接:https://markdown.com.cn/
Markdown的官方文档的超链接:Markdown的官方文档
(3)数据操作
请观看b站视频的同时,直接阅读教材的对应章节,链接:2.1. 数据操作
对应的jupyter文件的相对路径:“\d2l-zh\pytorch\chapter_preliminaries\index.ipynb”。
# 注:为了理解其中的代码,加了点注释
import torch # 导入torch包
# 这行代码导入了PyTorch库,它是一个用于深度学习和机器学习的开源深度学习库。
# PyTorch提供了各种工具和功能,使得构建、训练和部署神经网络变得更加容易。
# 通过导入torch,你可以在Python代码中使用PyTorch的各种模块和函数,包括张量操作、神经网络层、优化器、损失函数等。
# 这使得你能够进行深度学习任务,如图像分类、自然语言处理、回归分析等。x=torch.arange(12) # torch.arange()是PyTorch中用于创建一个等差数列的函数,默认步长为1。
xx.shape # 通过张量的shape属性来访问张量的形状和张量中元素的总数
x.numel() # 用于获取张量中元素的总数X=x.reshape(3,4) # 要求12=3*4,三行四列
Xtorch.zeros((2,3,4)) # 全0张量
torch.ones((2,3,4)) # 全1张量
torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]]) # tensor:张量x=torch.tensor([1.0,2,4,8])
y=torch.tensor([2,2,2,2])
x+y,x-y,x*y,x/y,x**y # **运算符是求幂运算torch.exp(x)# 多个张量连结
# -创建了两个张量 X 和 Y,然后使用 torch.cat() 函数进行了张量的拼接操作
# -dim=0:行 dim=1:列
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)X == Y # 通过逻辑运算符构建二元张量X.sum() # 元素求和# 广播机制:形状不一样时,按行复制或按列复制整个向量,使两个形状一样,再求和
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
a + b# 元素的访问
# [-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素
X[-1], X[1:3] # 此处结合语境为:[-1]选择最后一行元素,可以用[1:3]选择第二行和第三行元素# 通过索引改变矩阵的元素
X[1, 2] = 9
X# 为多个元素赋值
X[0:2, :] = 12
X# 为新结果分配内存,注意与C语言区别
before = id(Y) # id:标识号
Y = Y + X
id(Y) == before# 执行原地操作 Z的id不变
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y # Z[:] 表示将 Z 的所有元素替换为运算结果
print('id(Z):', id(Z))# 如果在后续计算中没有重复使用X, 我们也可以使用X[:] = X + Y或X += Y来减少操作的内存开销。
before = id(X)
X += Y
id(X) == before# 转换为NumPy张量
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)# 将大小为1的张量转换为Python标量
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)
3.数据预处理
请观看b站视频的同时,直接阅读教材的对应章节,链接:2.2. 数据操作

注:CSV是"Comma-Separated Values"(逗号分隔值)的缩写,是一种常见的文本文件格式,用于存储和交换表格数据。CSV文件由纯文本组成,数据以行为单位,每行中的数据字段之间用逗号(,)或其他分隔符(如分号、制表符等)进行分隔。
# os模块提供了一种与操作系统功能进行交互的方式,包括与文件系统的交互、管理目录和运行系统命令等。
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
# os.makedirs: 这是os模块中的一个函数,用于递归地创建目录。如果目录已经存在,它不会引发错误。
# os.path.join('..', 'data'): 这一部分使用os.path.join函数来创建一个路径字符串。在这里,它将两个字符串连接起来,形成一个相对路径,其中'..'表示上一级目录,'data'表示一个名为"data"的子目录
# exist_ok=True: 这是一个参数,如果设置为True,则表示如果目录已经存在,不会引发错误。如果目录不存在,它将创建目录。
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本# NA:表示未知数f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')
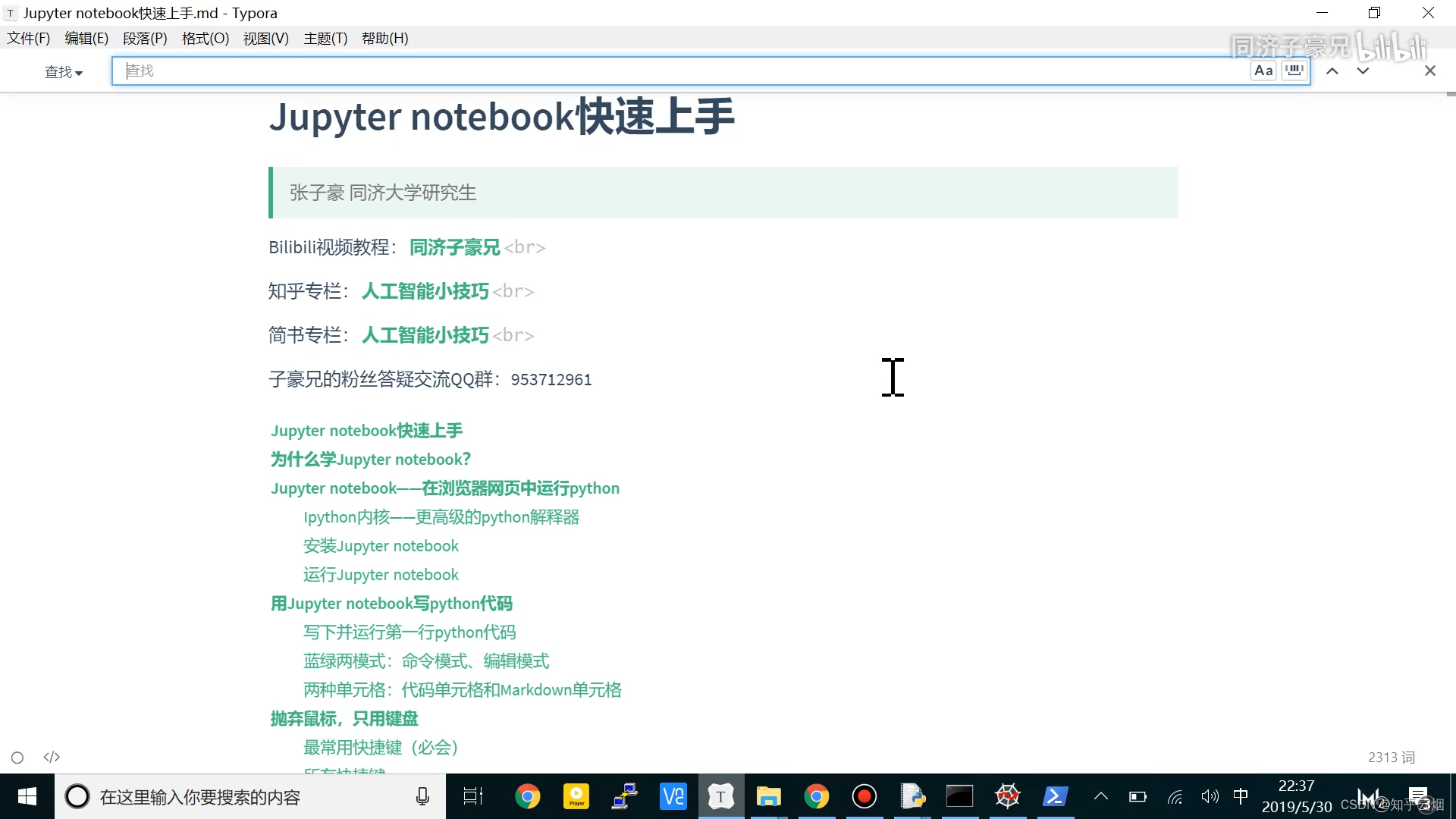
# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
import pandas as pd
# pandas是一个强大的数据处理和分析库,特别适用于处理结构化数据,如表格数据。它提供了各种数据结构和函数,使数据的读取、转换、筛选、统计分析等操作变得非常简便。
# 常见的pandas数据结构包括DataFrame和Series,它们允许你以表格形式组织和操作数据。data = pd.read_csv(data_file)
# 使用pd.read_csv(data_file)读取了一个CSV文件的内容,并将其存储在一个pandas的数据结构中,通常是一个DataFrame。这里的data_file是CSV文件的文件路径,你需要将其替换为实际的文件路径。
print(data)
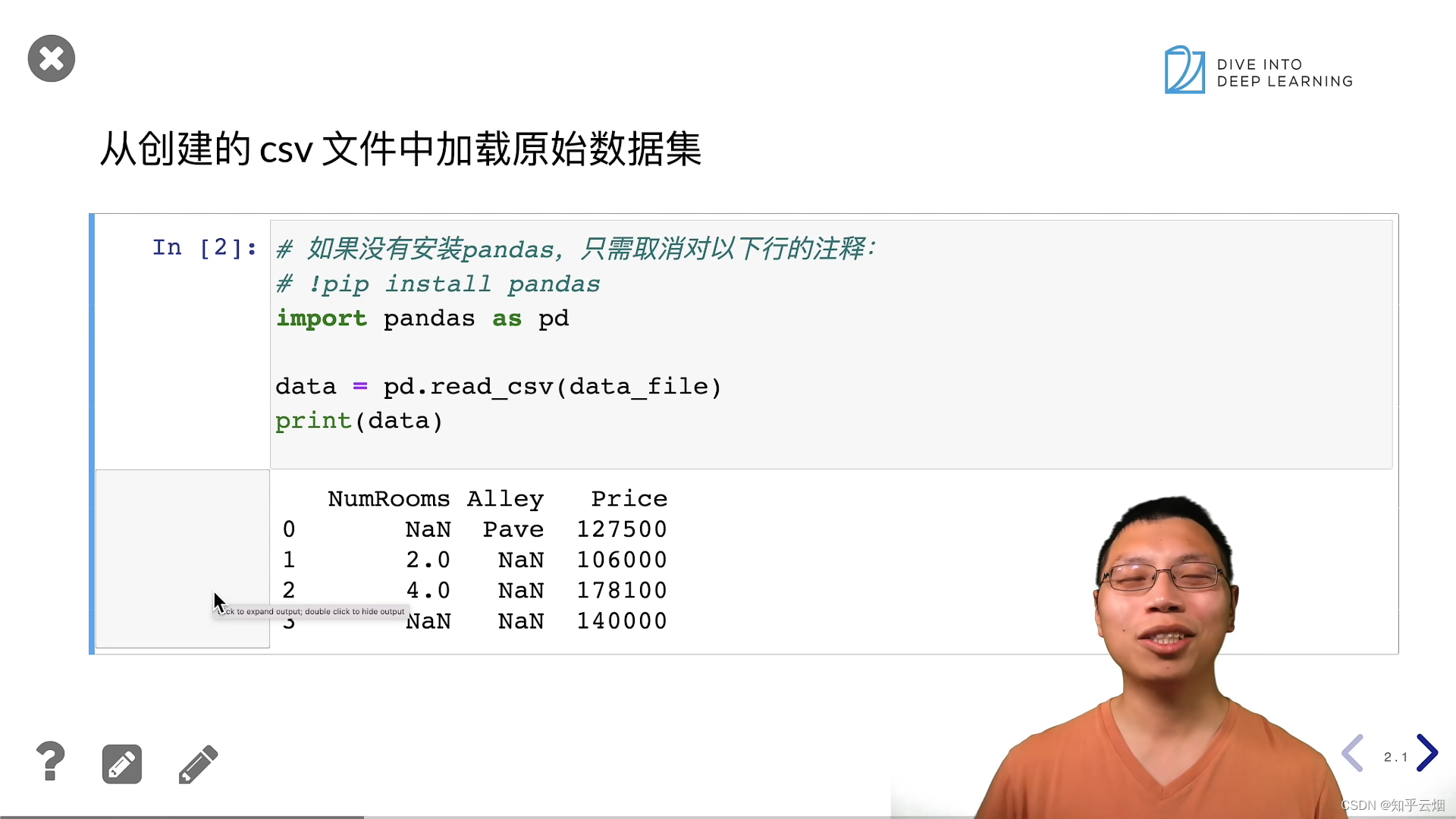
# 通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
# mean()函数计算了该列中非空数值的平均值
# inputs.fillna(inputs.mean()): 这部分使用fillna()方法,将inputs中的缺失值(NaN,Not-a-Number)用对应列的平均值填充
print(inputs)

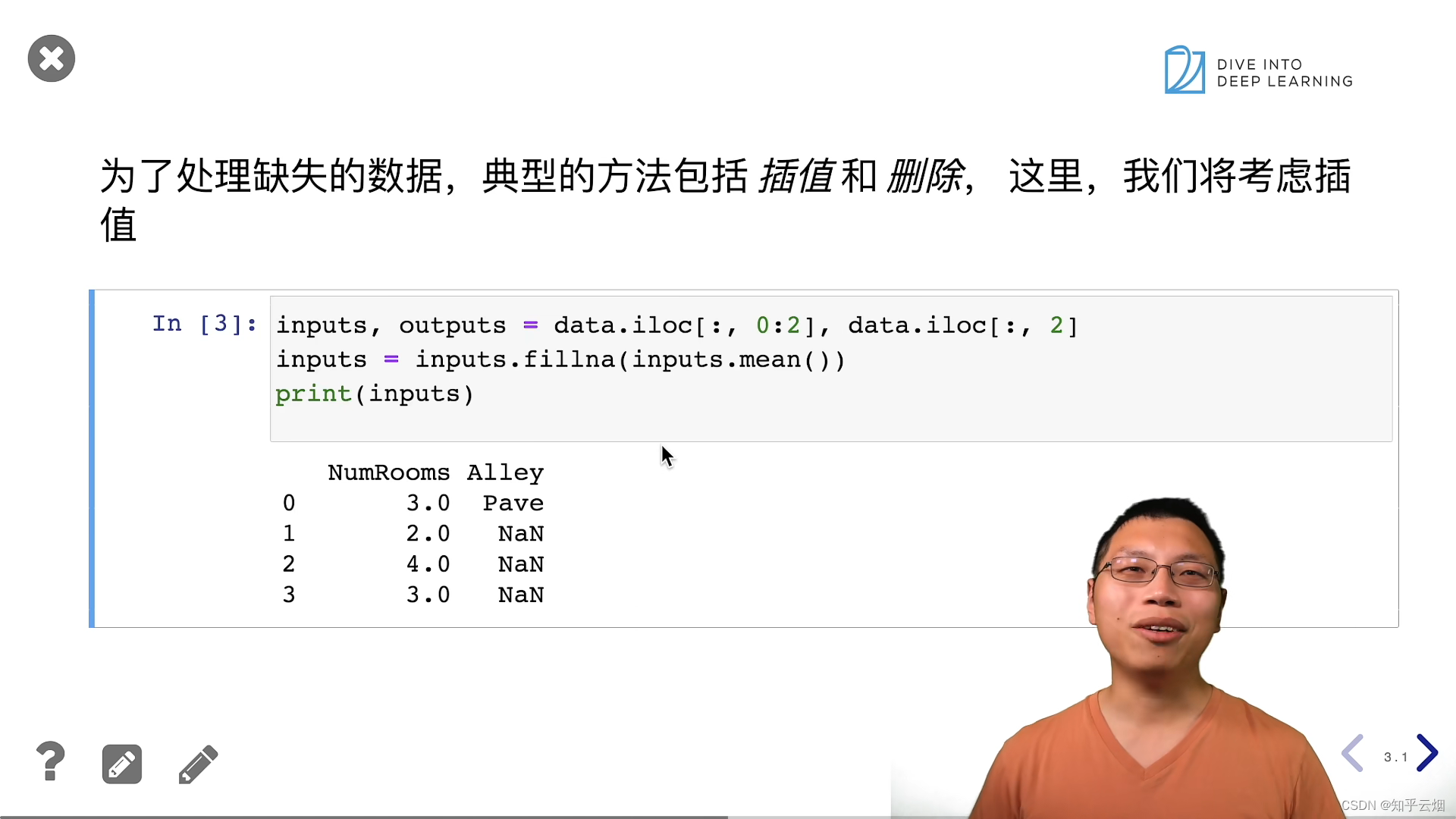
inputs = pd.get_dummies(inputs, dummy_na=True)
"""
这行代码使用了pandas库中的get_dummies()函数来进行独热编码(One-Hot Encoding)处理。让我解释一下这段代码的作用:
- pd.get_dummies(inputs, dummy_na=True): 这部分代码对inputs进行了独热编码的处理。独热编码是一种用于处理分类变量的方法,它将原始的分类变量转换为二进制的形式,以便在机器学习模型中使用。
- inputs: 这是要进行独热编码的数据,通常是一个pandas的数据框(DataFrame)。
- dummy_na=True: 这个参数是可选的,如果设置为True,则会为原始数据中的缺失值(NaN)创建一个额外的列进行编码。
- 独热编码将原始的分类变量拆分成多个二进制变量,每个变量代表一个可能的分类值。这有助于避免模型将分类变量解释为连续变量,并确保模型能够正确理解和使用这些分类信息。
- 举例来说,如果原始数据包含一个"颜色"列,其中包括"红色"、"绿色"和"蓝色"这三个分类值,独热编码后会创建三个新的列,分别代表这三种颜色,每列的取值只有0和1,1表示对应的颜色。同时,如果设置了dummy_na=True,还会创建一个额外的列表示缺失值。
"""
print(inputs)
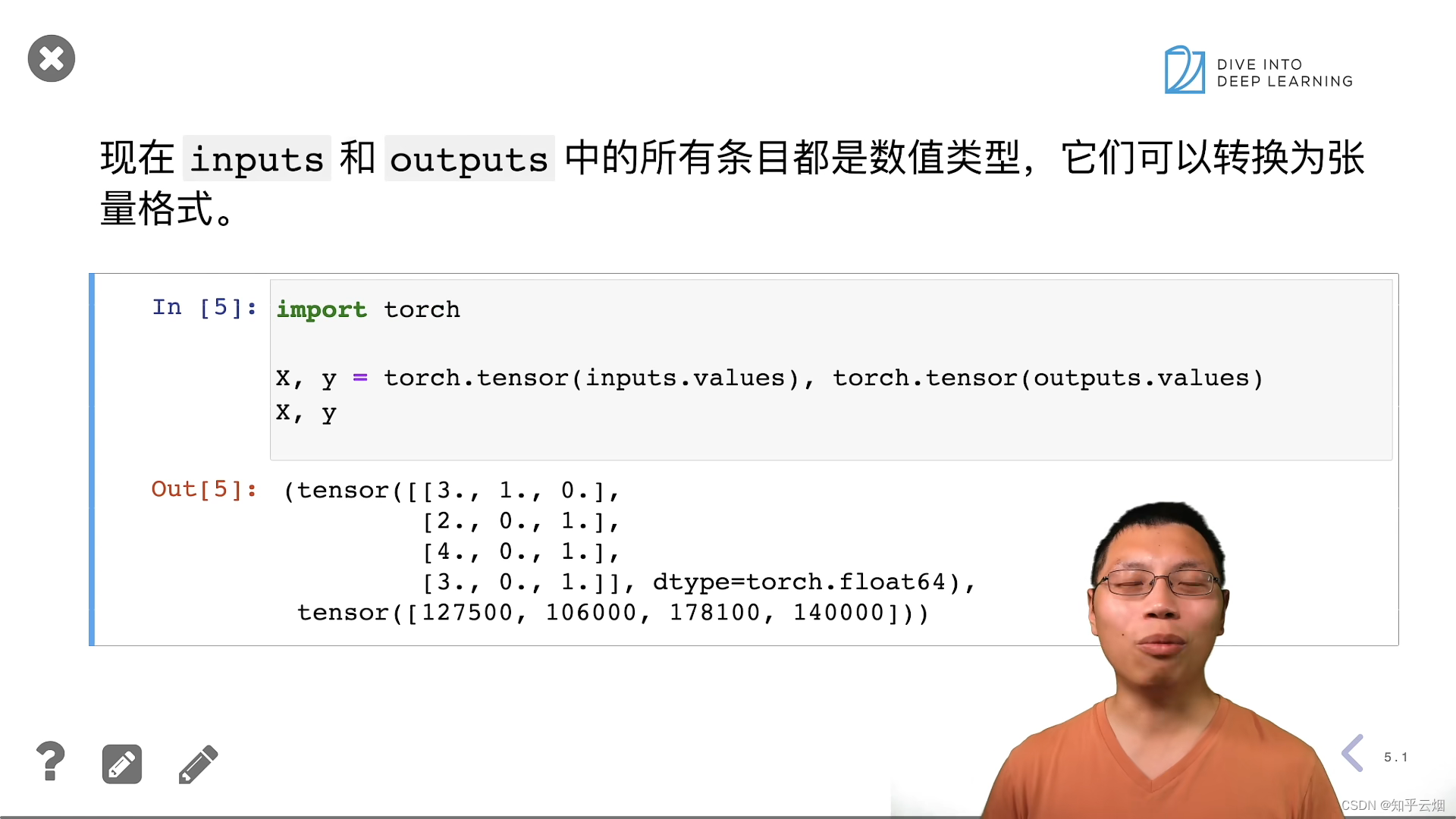
# 转换为张量格式
import torchX = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y
4.数据操作QA

五、线性代数
1.线性代数
请观看b站视频的同时,直接阅读教材的对应章节,链接:2.3.线性代数
(1)标量
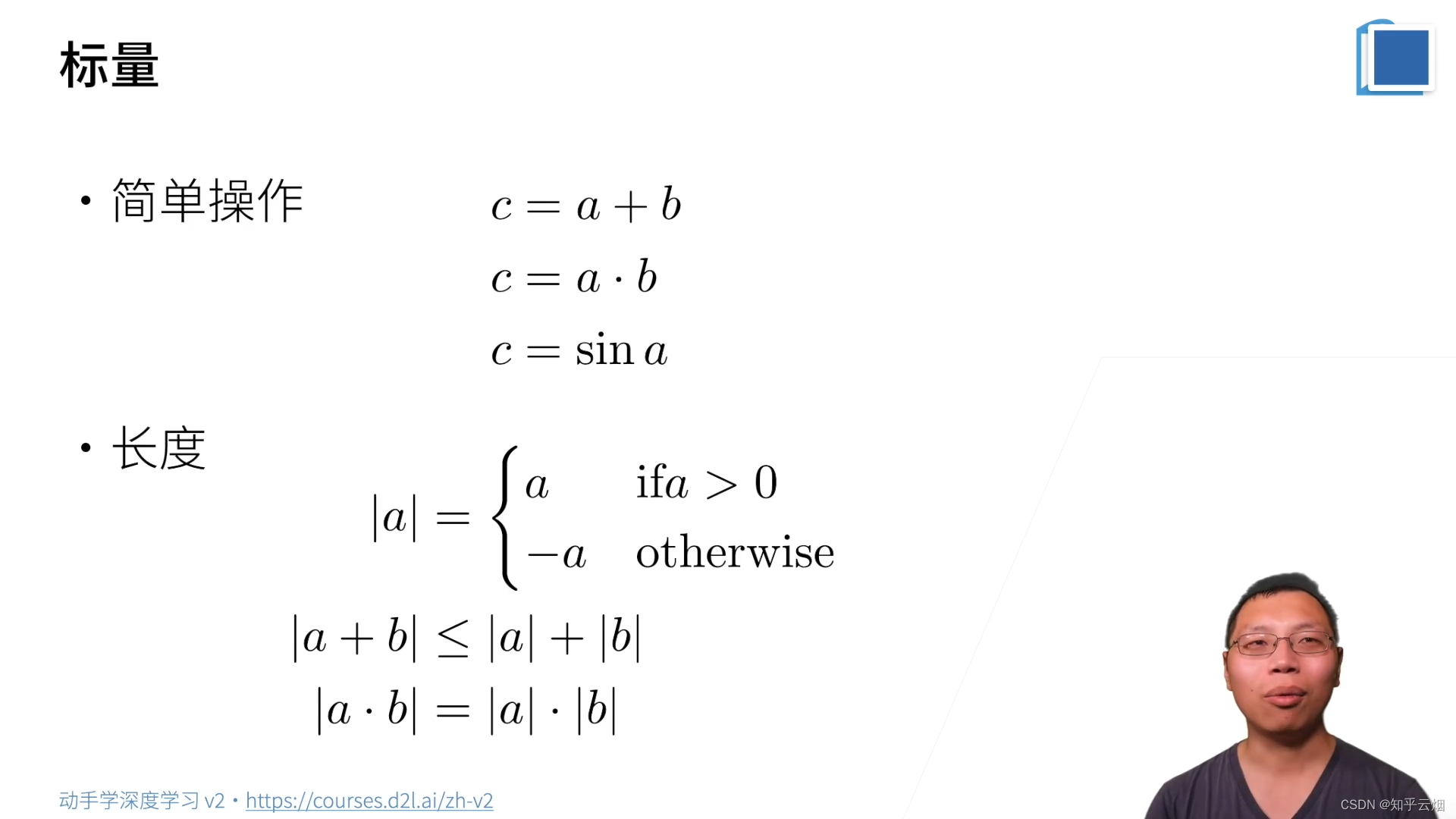
(2)向量

其中 α \alpha α为标量。上面的公式中 ∣ ∣ a ⋅ b ∣ ∣ = ∣ a ∣ ⋅ ∣ ∣ b ∣ ∣ ||a \cdot b||=|a| \cdot ||b|| ∣∣a⋅b∣∣=∣a∣⋅∣∣b∣∣的 a a a为标量,其他地方的 a a a为向量。
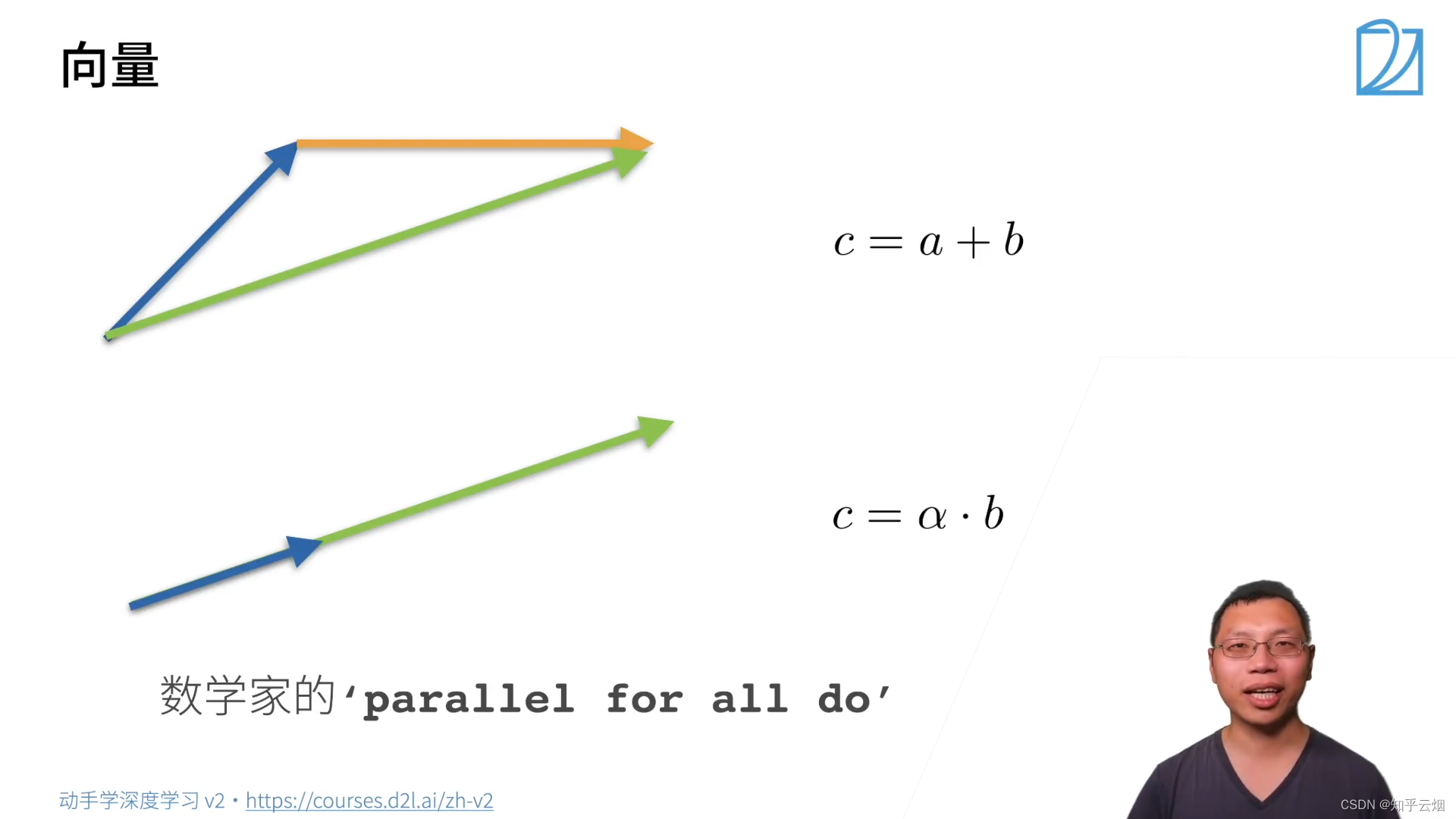

(3)矩阵
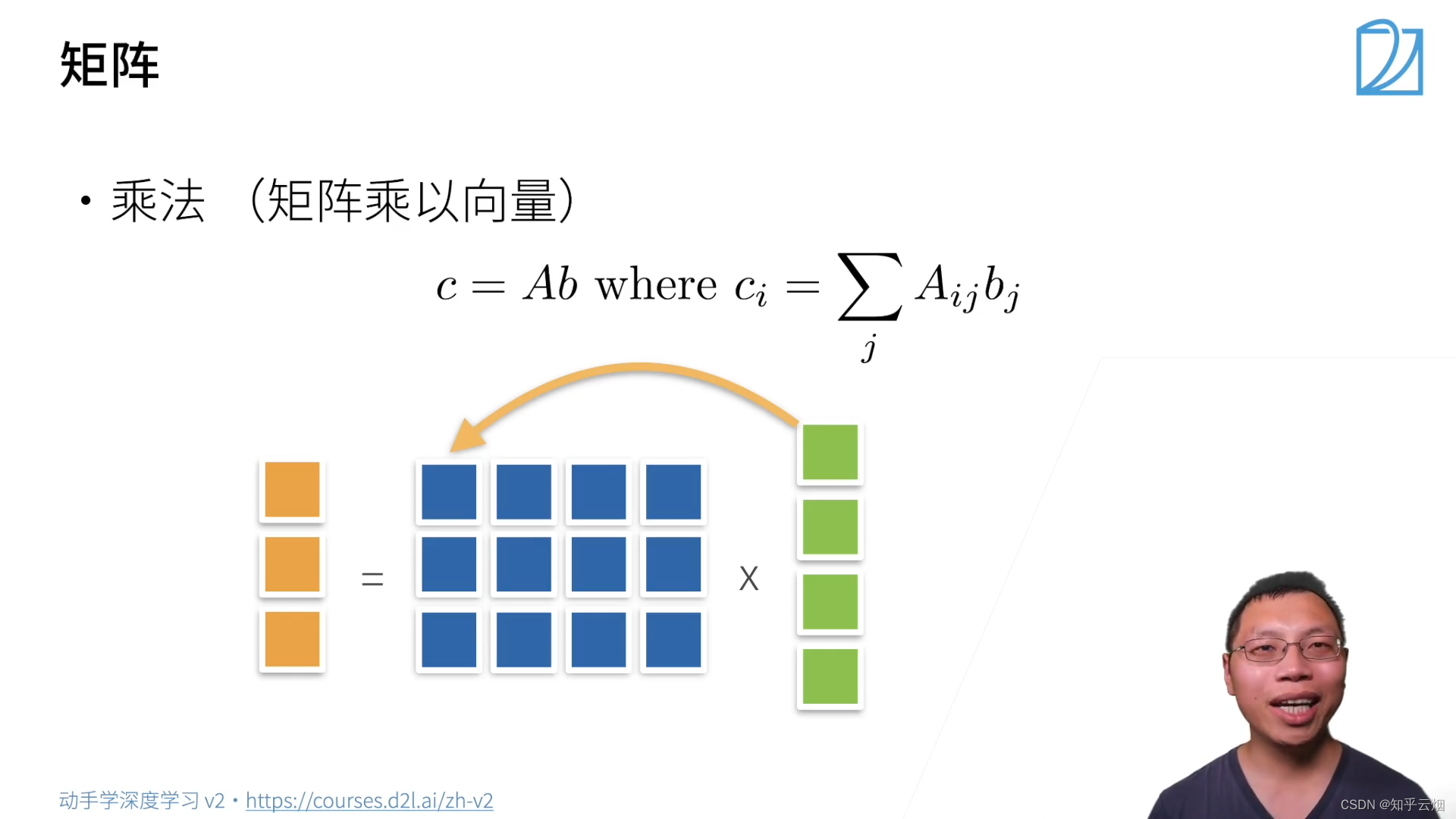
行和列相乘。
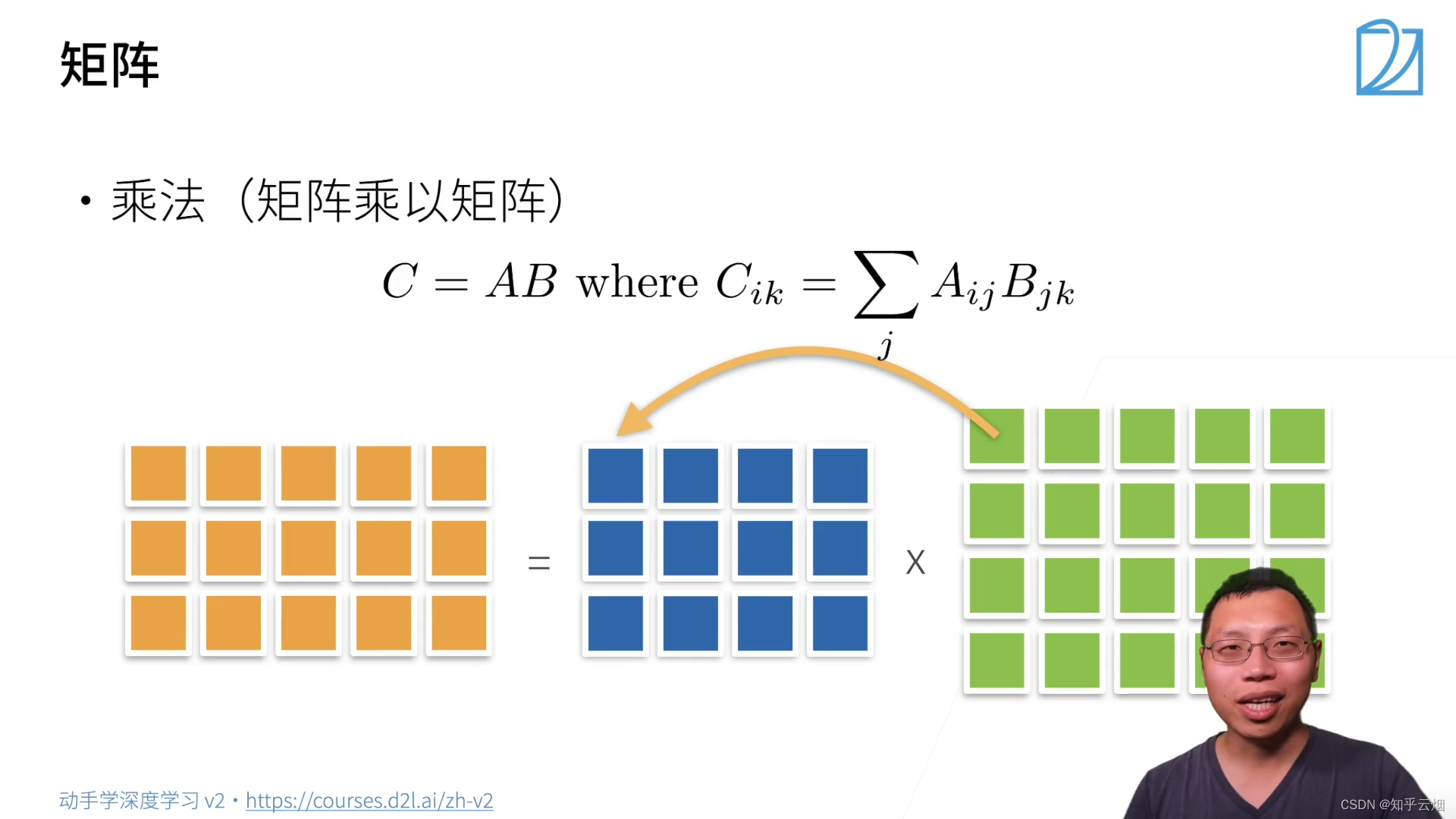
i i i行和 j j j列相乘作为结果矩阵的 i i i行 j j j列的一个元素。

(4)特殊矩阵

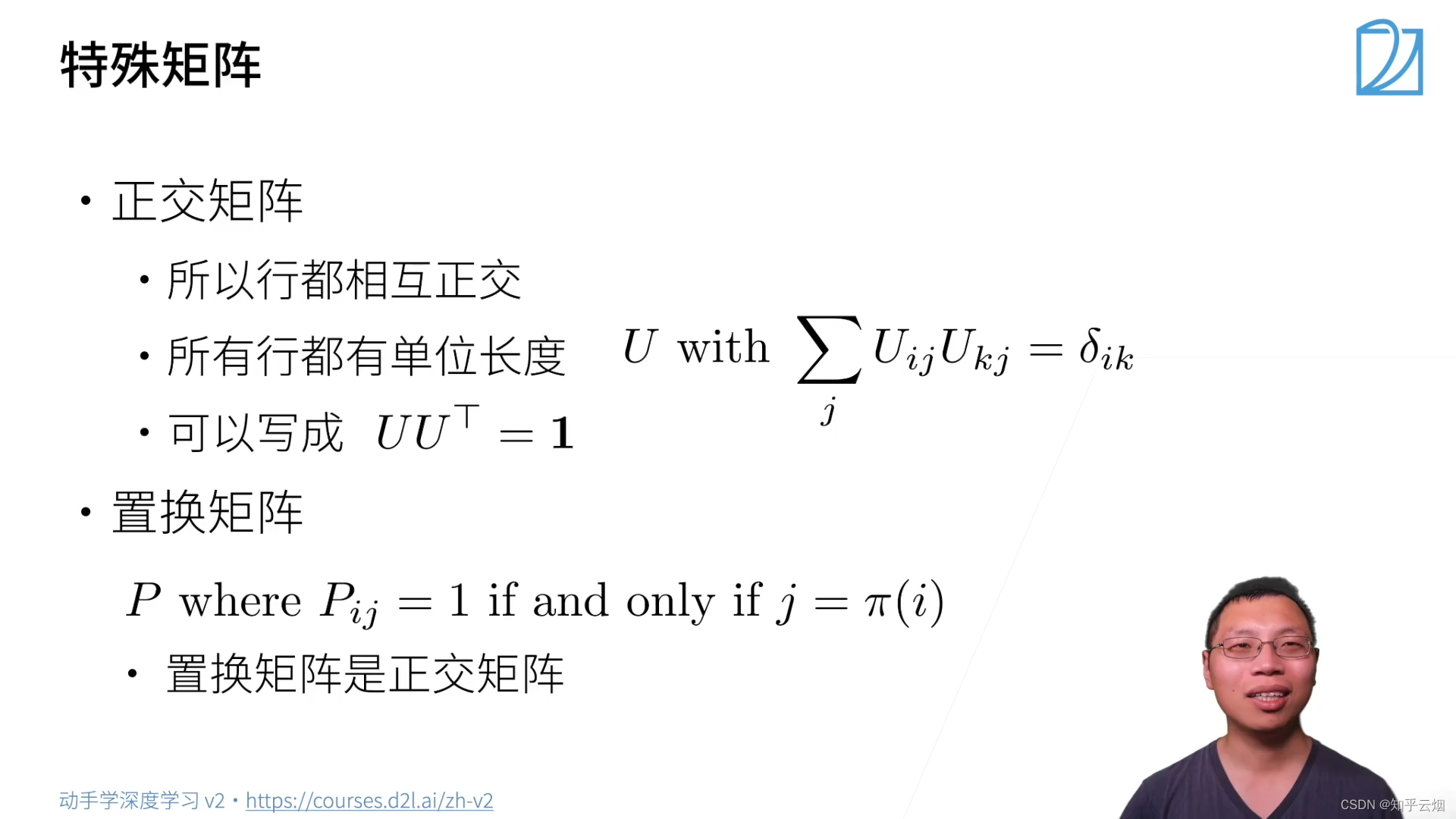
其中“ j = π ( i ) j = \pi ( i ) j=π(i)”表示 j j j是 i i i的置换。

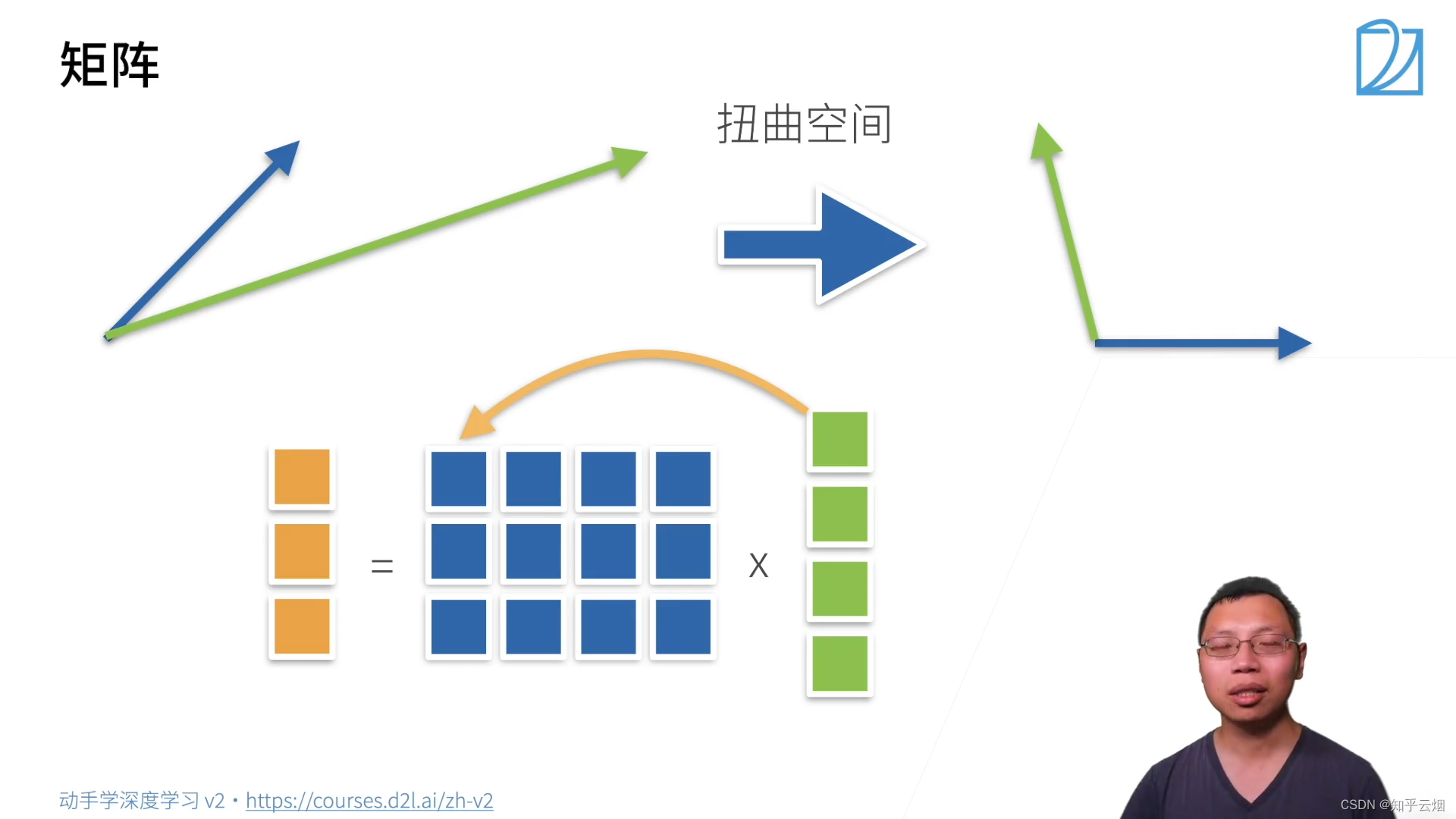
对于特征向量,矩阵并不会改变它的方向,如上图的绿色的向量就是一个特征向量。
2.线性代数的实现

import torchx = torch.tensor(3.0)
y = torch.tensor(2.0)x + y, x * y, x / y, x**y
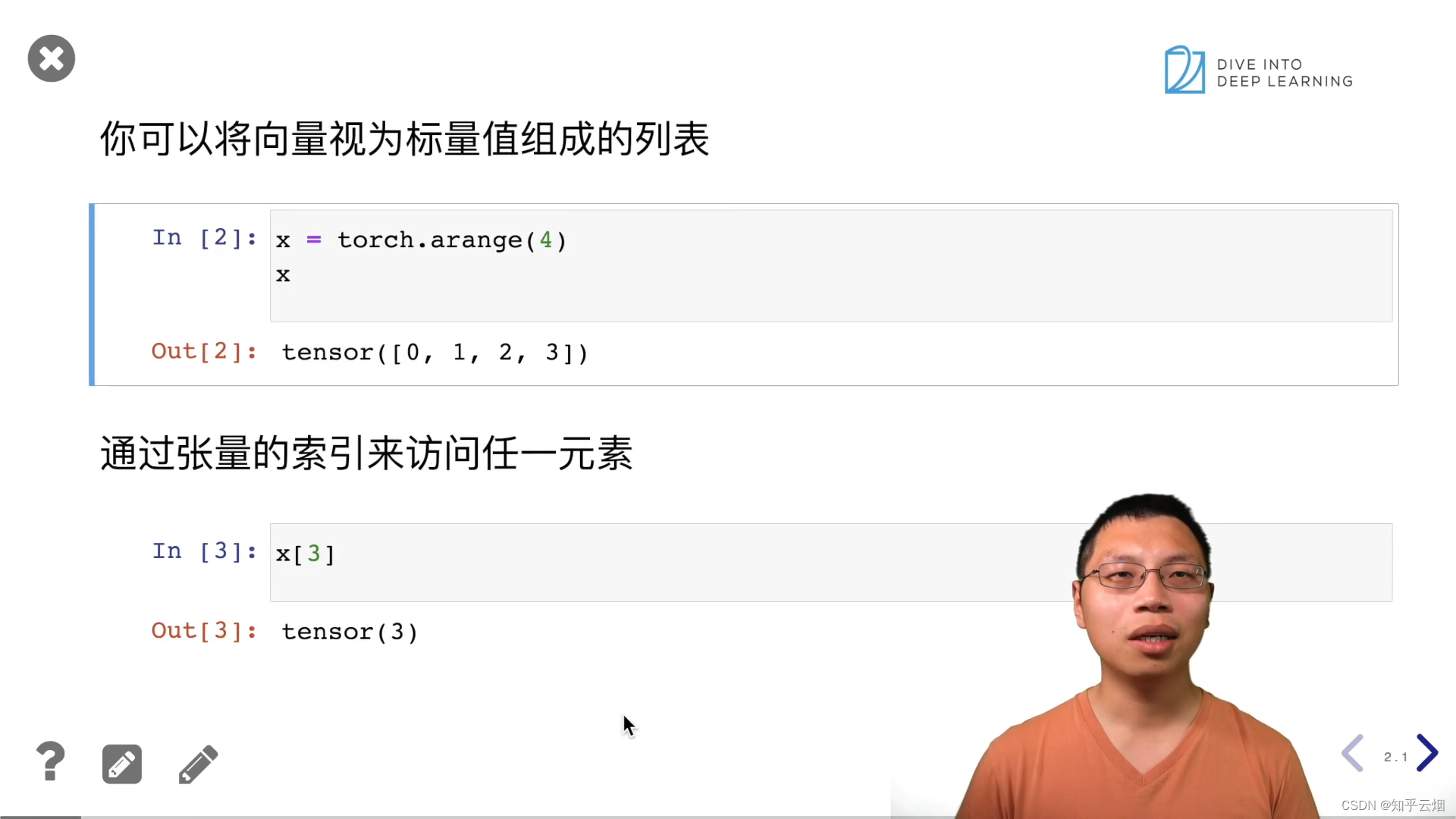
x = torch.arange(4)
x
x[3]

len(x)
x.shape
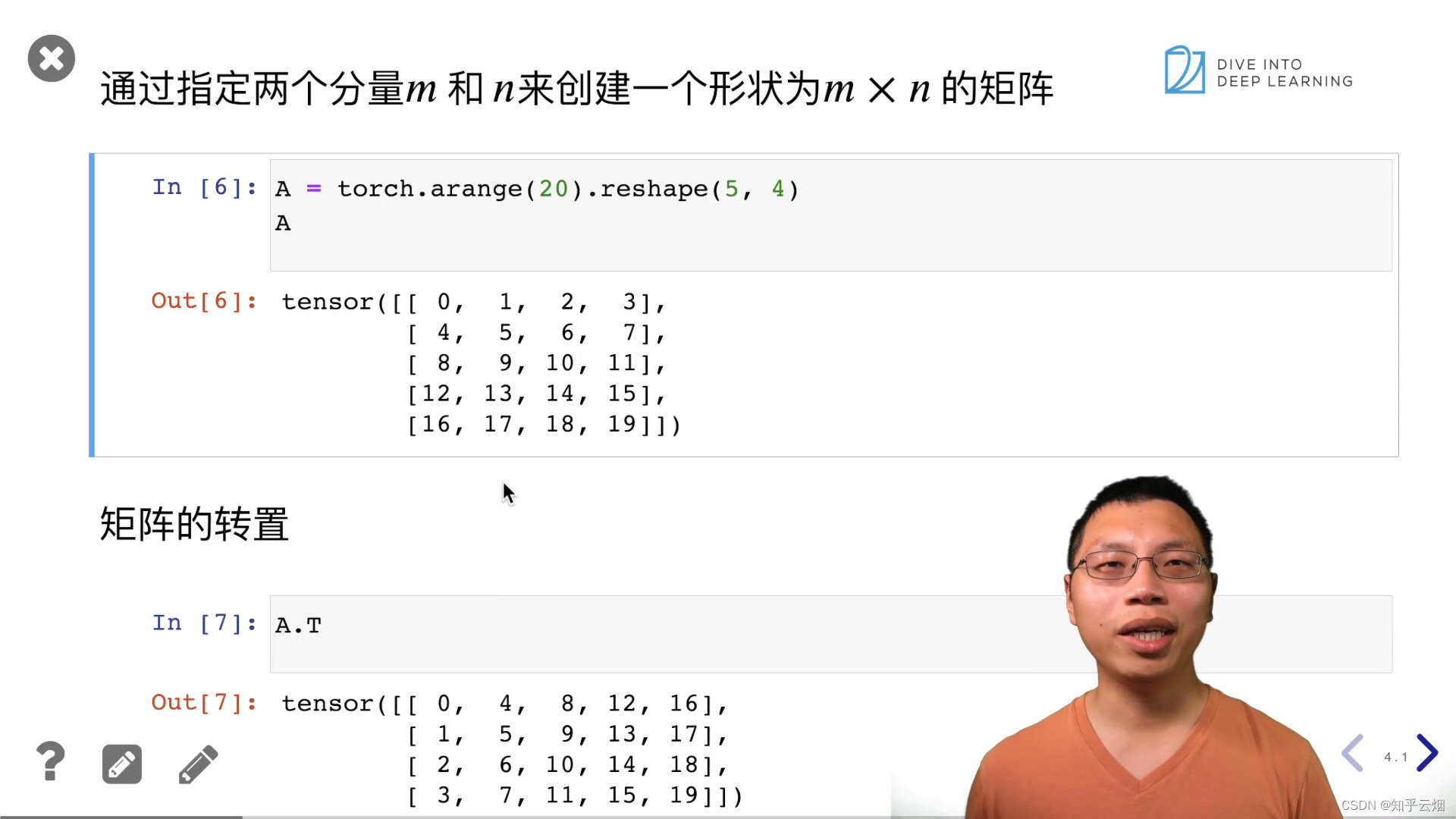
A = torch.arange(20).reshape(5, 4)
A
A.T

B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B
B == B.T
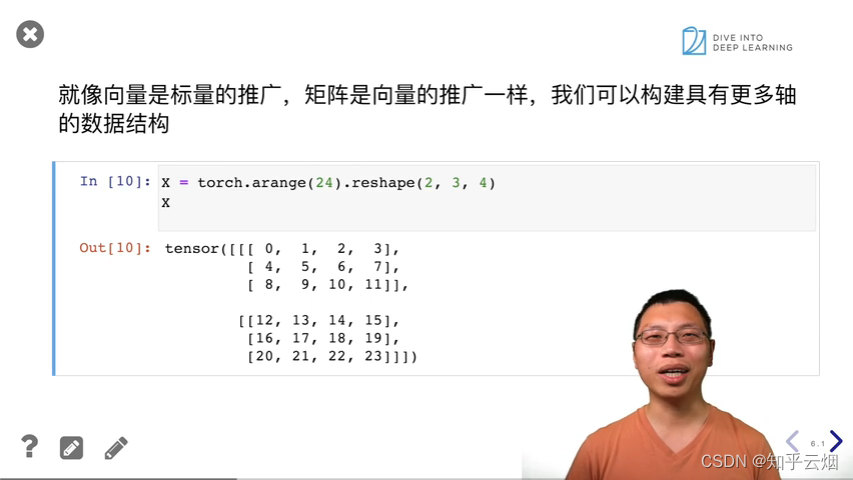
X = torch.arange(24).reshape(2, 3, 4)
X
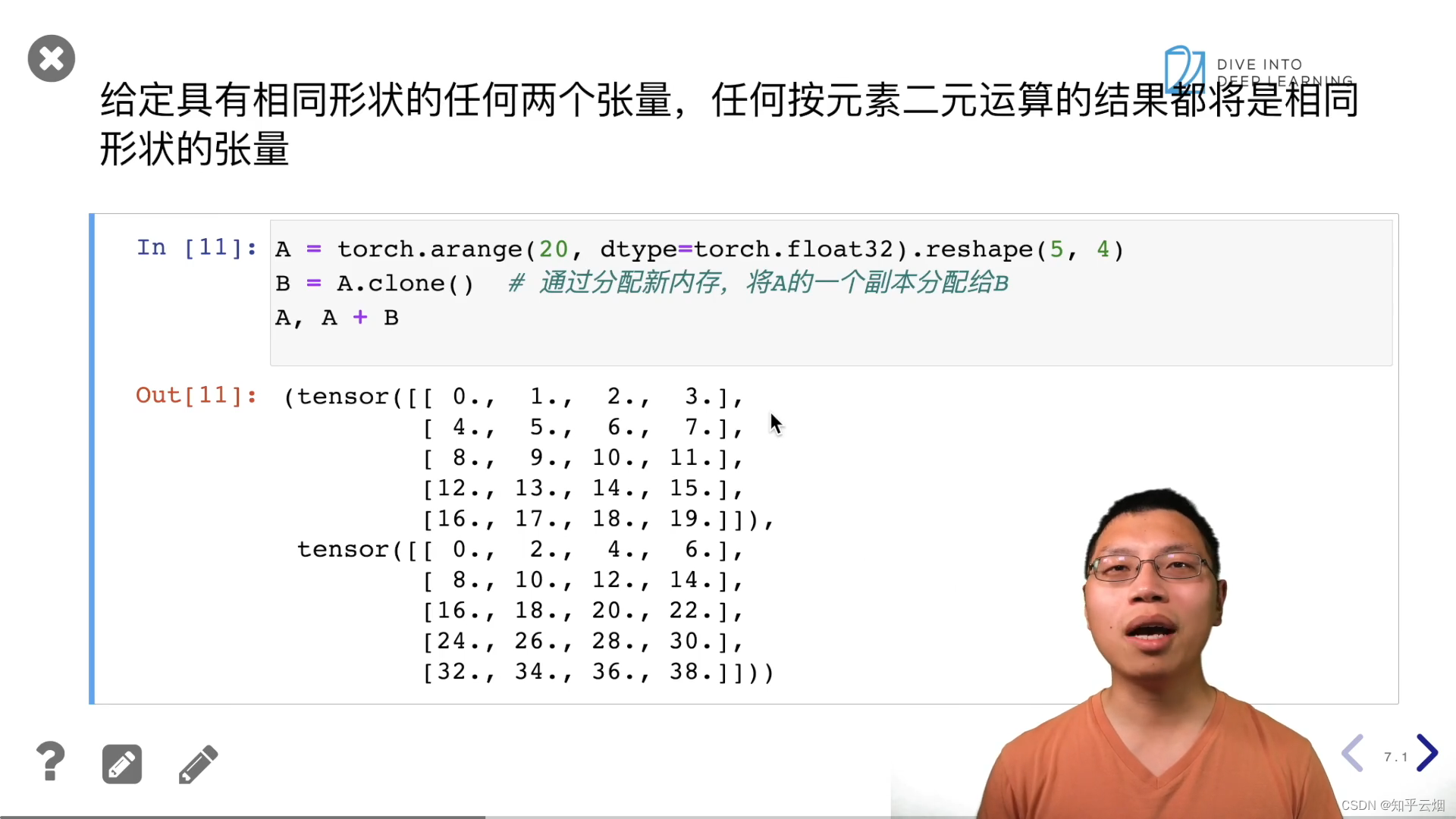
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B
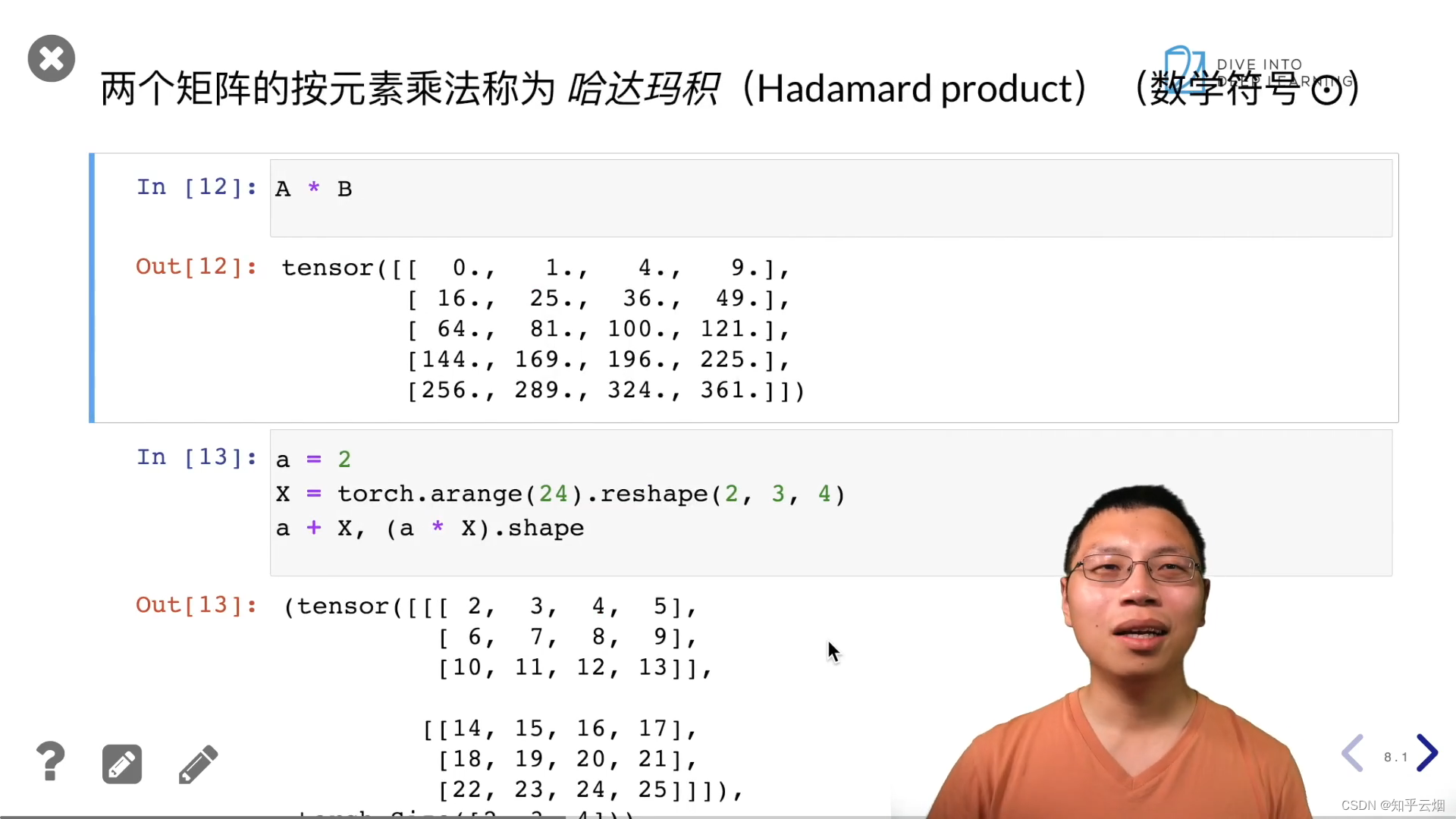
A * B
a = 2
X = torch.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape

x = torch.arange(4, dtype=torch.float32)
x, x.sum()
A.shape, A.sum()
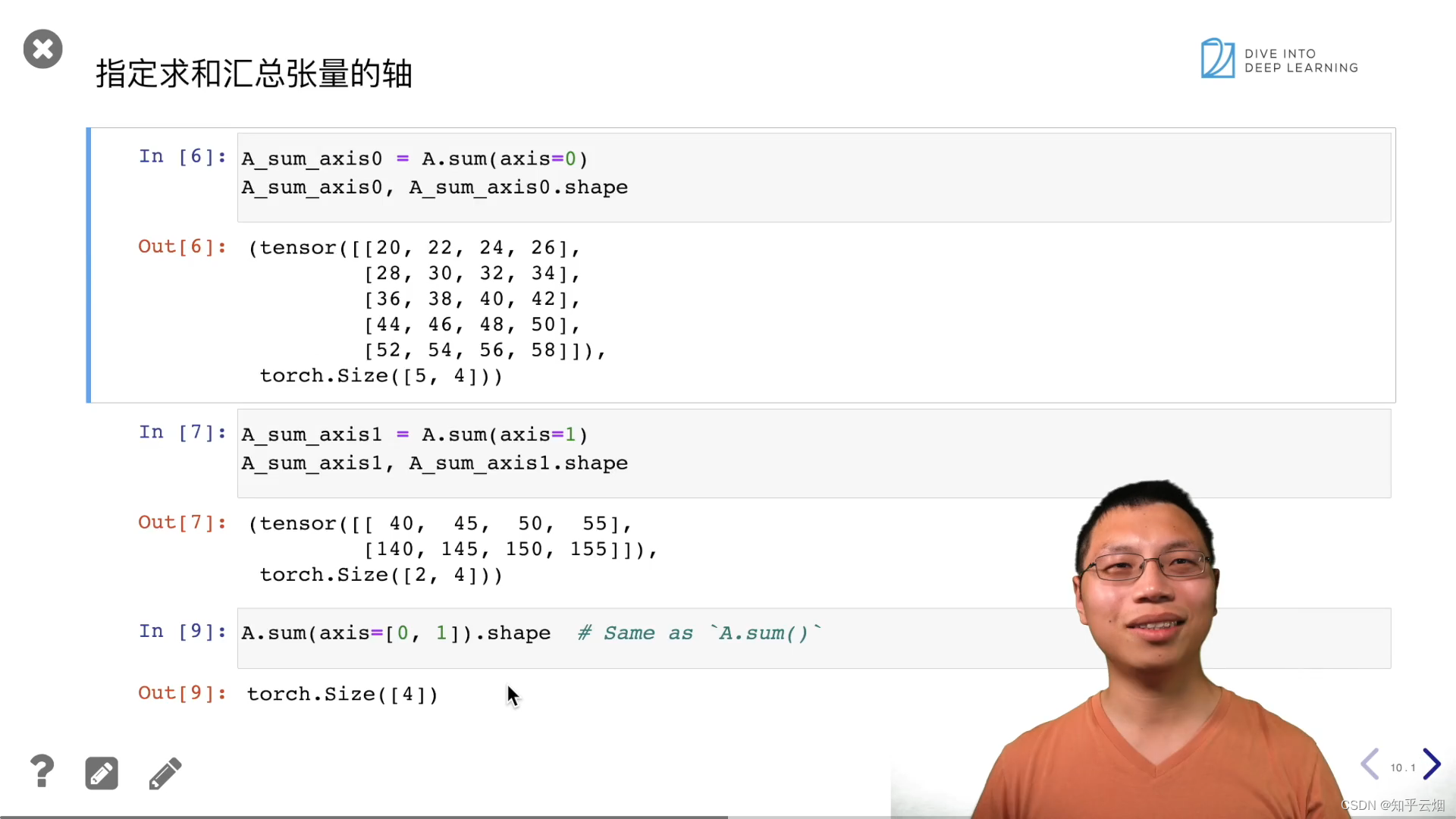
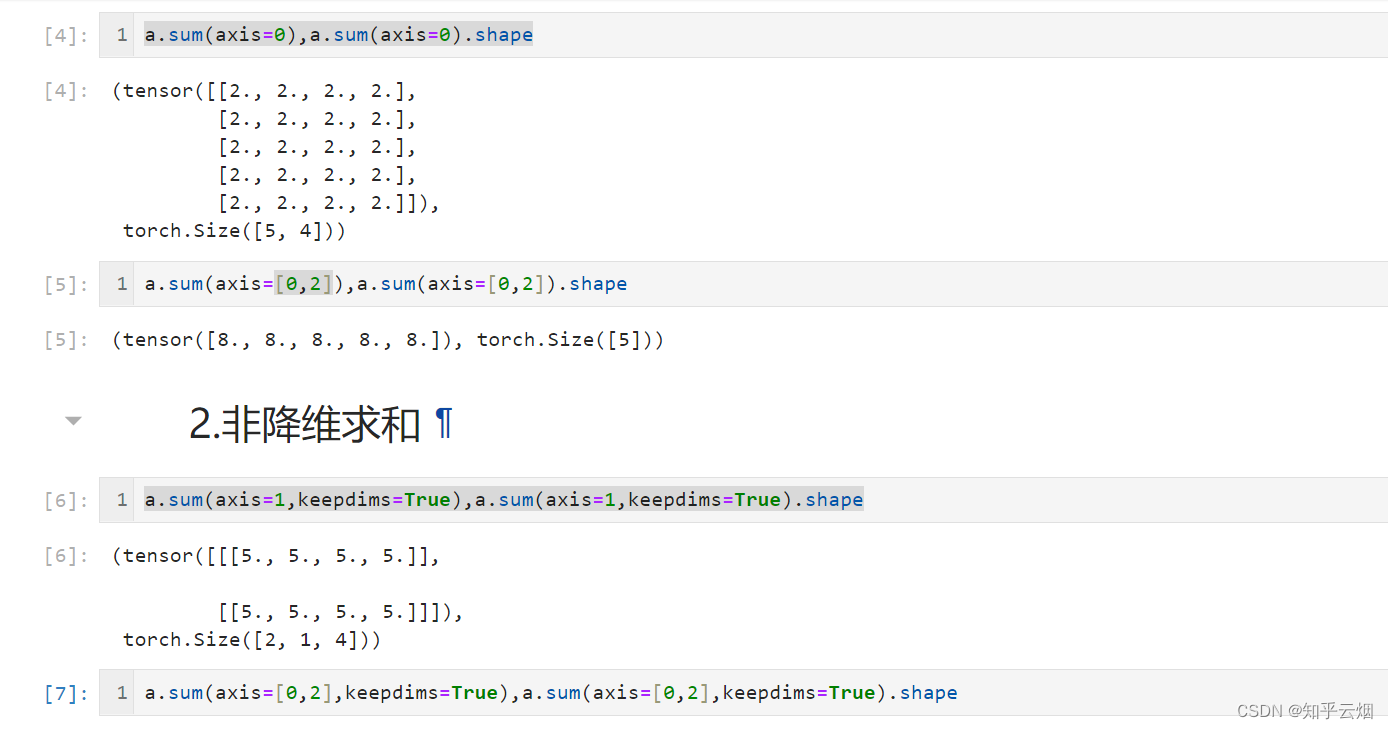
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape
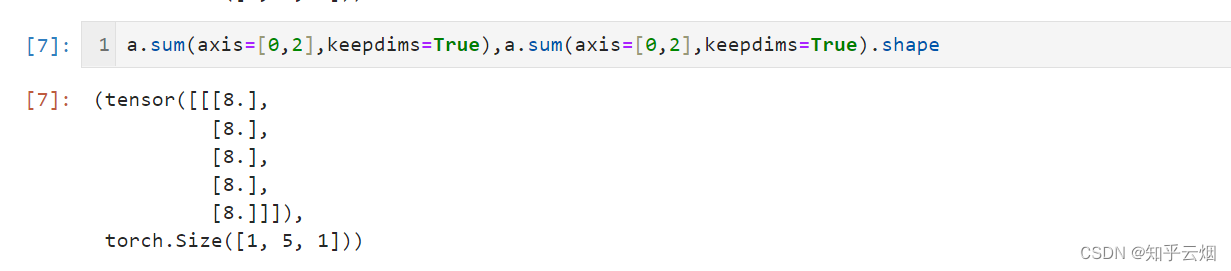
A.sum(axis=[0, 1]) # 结果和A.sum()相同
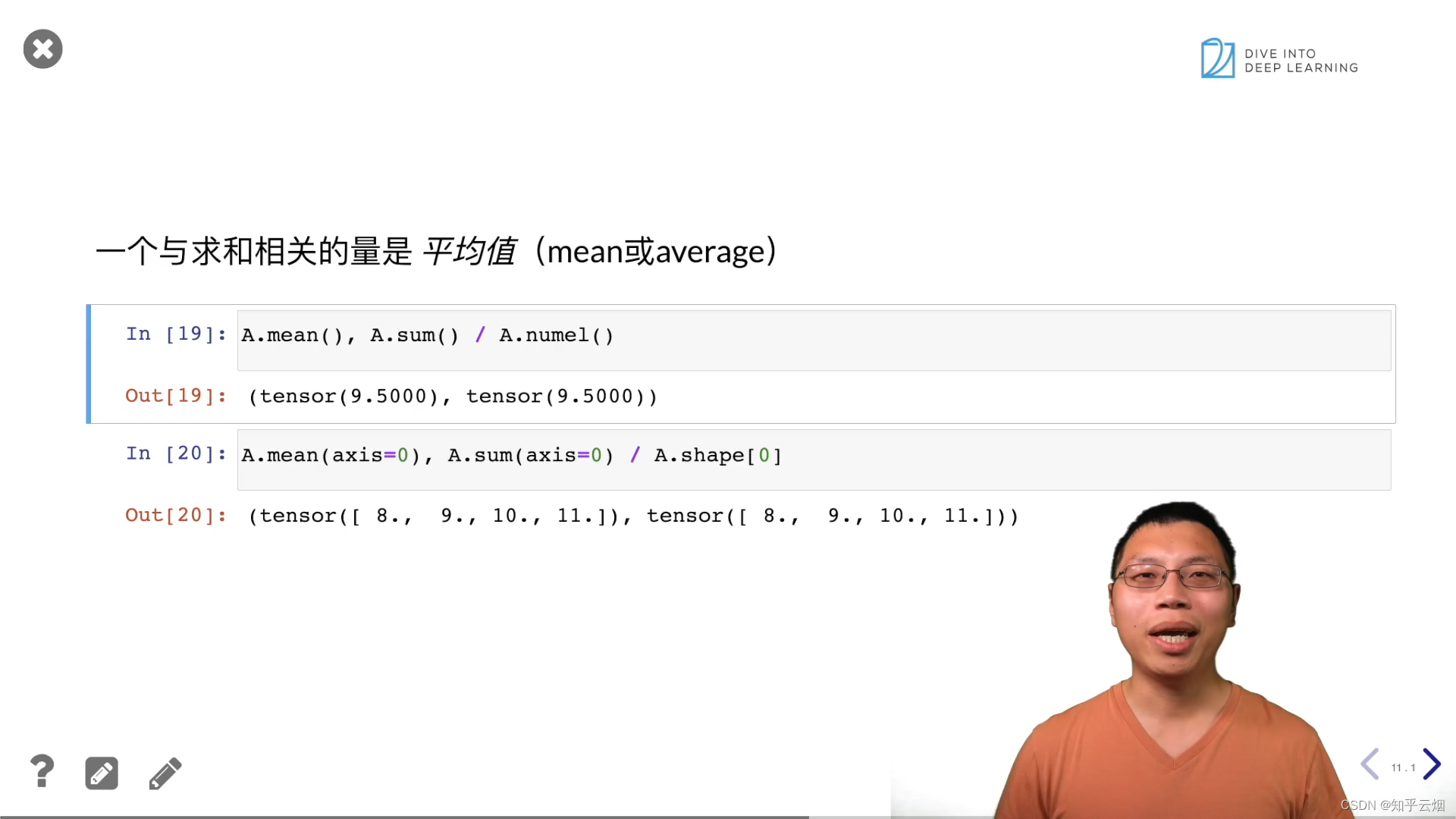
A.mean(), A.sum() / A.numel()
A.mean(axis=0), A.sum(axis=0) / A.shape[0]
注:广播机制要求维度个数一样。
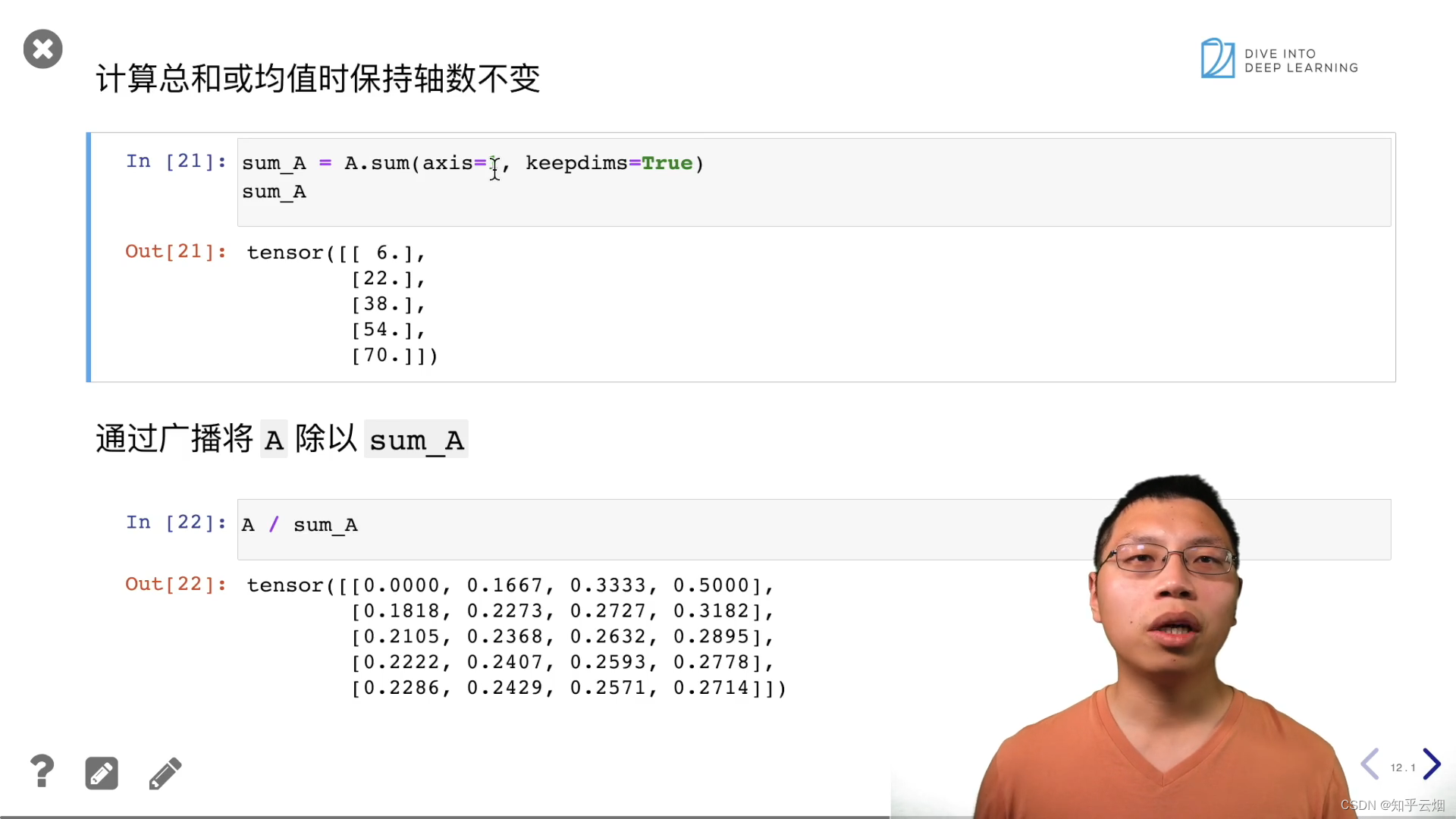
sum_A = A.sum(axis=1, keepdims=True)
sum_A
A / sum_A
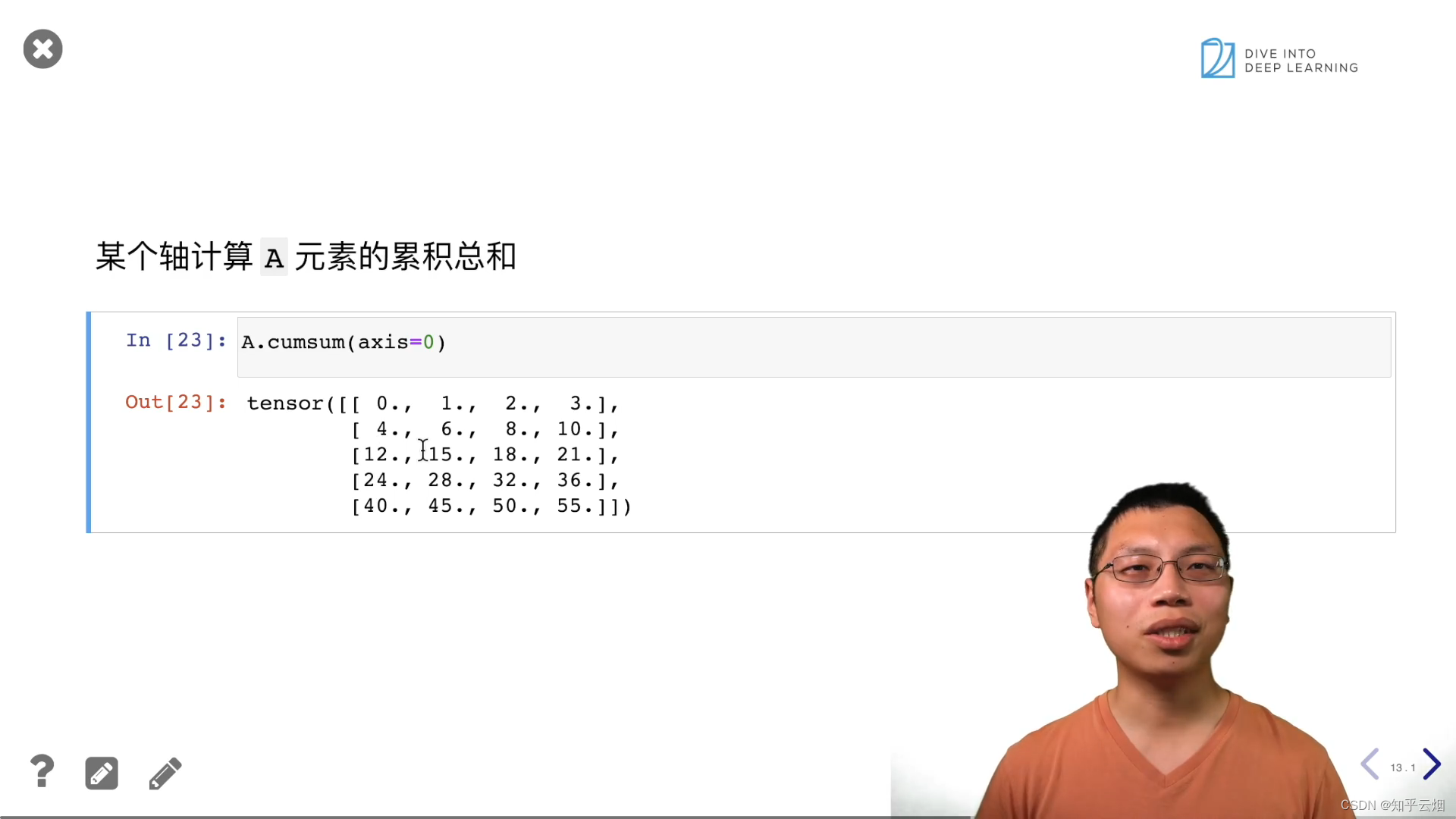
A.cumsum(axis=0)
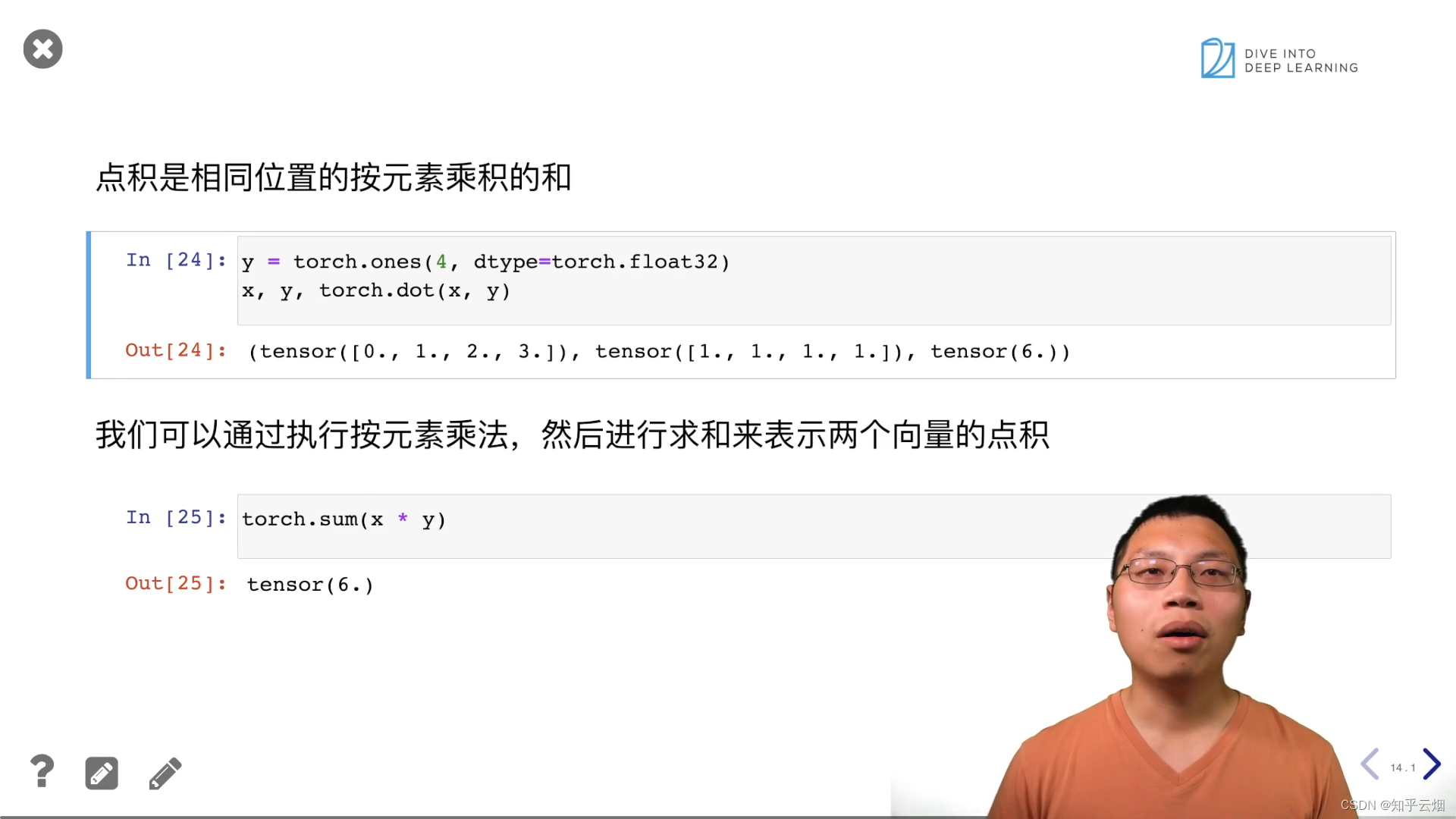
y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y) # torch.dot:点积
torch.sum(x * y)

A.shape, x.shape, torch.mv(A, x)
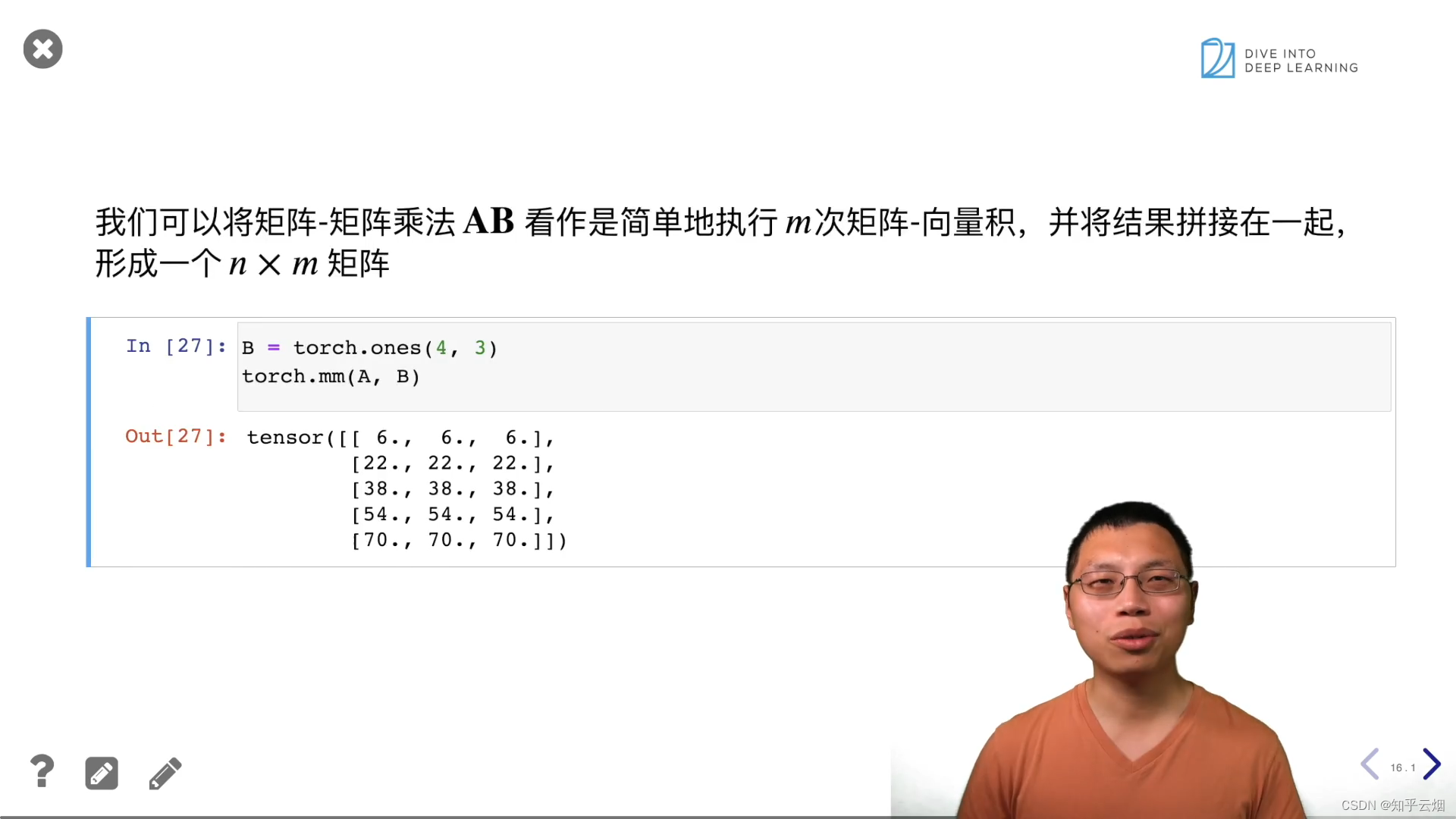
B = torch.ones(4, 3)
torch.mm(A, B)

u = torch.tensor([3.0, -4.0])
torch.norm(u)
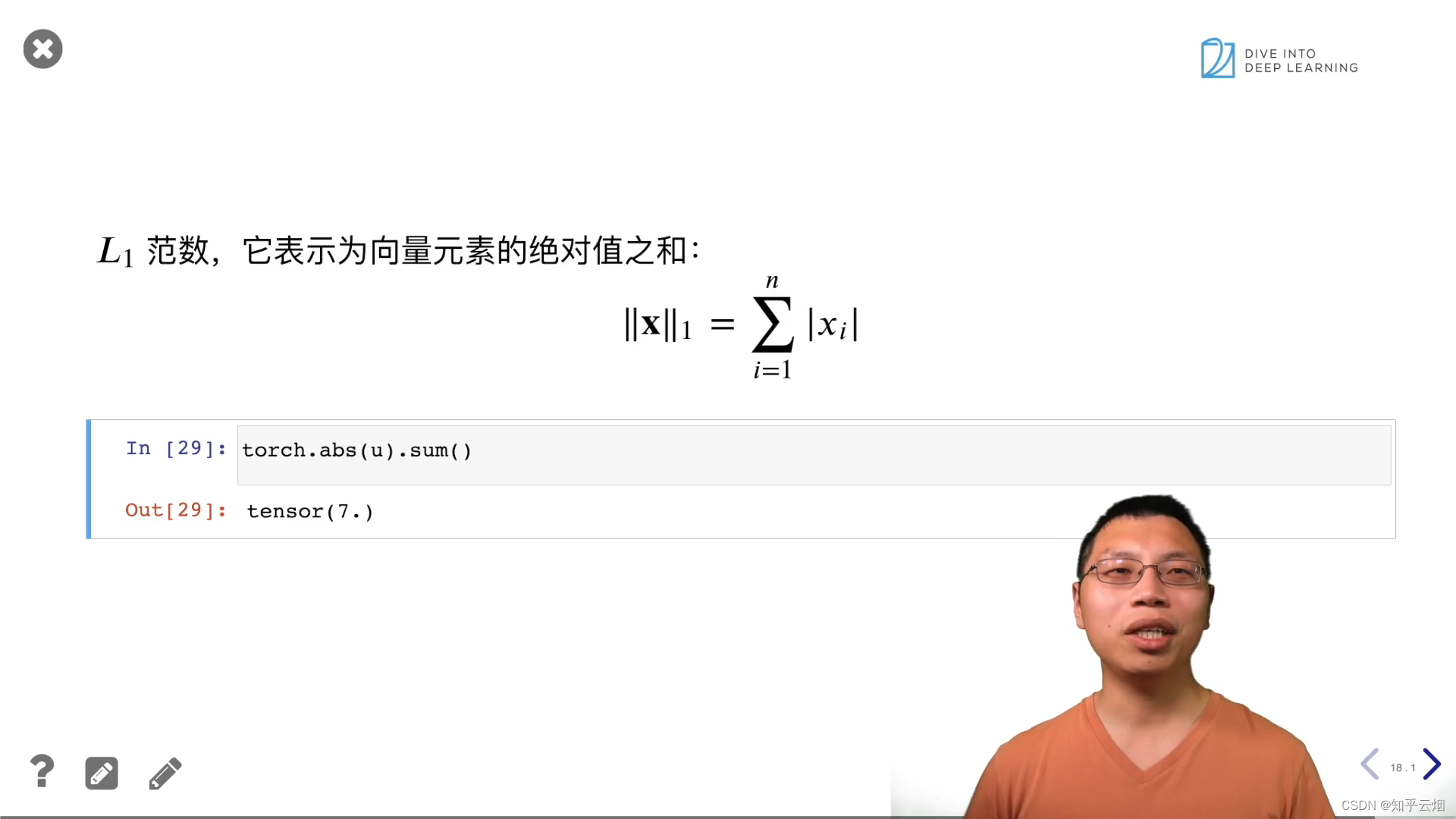
torch.abs(u).sum()
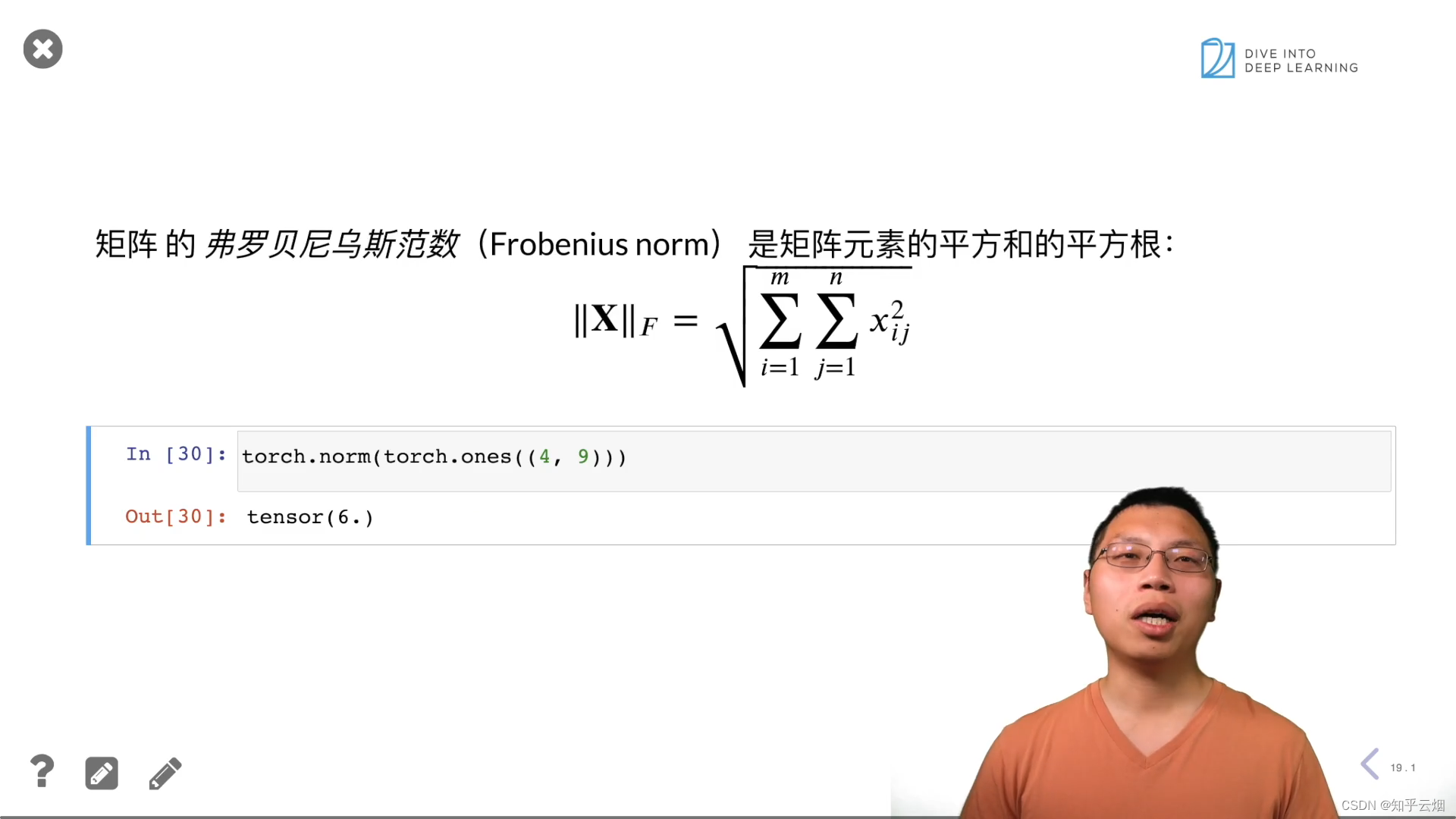
torch.norm(torch.ones((4, 9)))
3.按特定轴求和


4.线性代数QA
详细内容请观看视频:05 线性代数-P4 线性代数QA


相关文章:
P1-P5_动手学深度学习-pytorch(李沐版,粗浅的笔记)
目录 预告 1.学习深度学习的关键是动手 2.什么是《动手学深度学习》 3.曾经推出的版本(含github链接) 一、课程安排 1.目标 2.内容 3.上课形式 4.你将学到什么 5.资源 二、深度学习的介绍 1.AI地图 2.深度学习在一些应用上…...
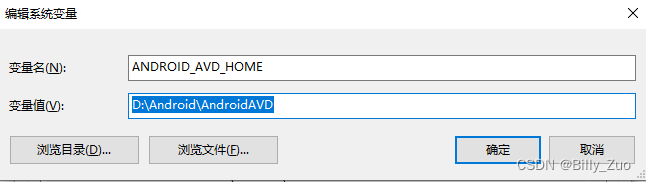
Android Studio修改模拟器AVD Manger目录
Android Studio修改虚拟机AVD Manger目录 1、在AS的设备管理器Device Manager中删除原来创建的所有虚拟机(Android Virtual Device); 2、新建一个自定义的AVD目录,例如:D:\Android\AndroidAVD 3、在高级系统设置中增加…...

STM32--MQ2烟雾传感器
本文主要介绍STM32F103C8T6和烟雾传感器模块的控制算法 简介 烟雾模块选用MQ-2气体传感器,根据传感器的电导率随空气中可燃气体浓度的增加而增大的特性检测空气中可燃气体,然后将电导率的变化转换成对应的电信号 MQ系列烟雾传感分类如下: 该…...
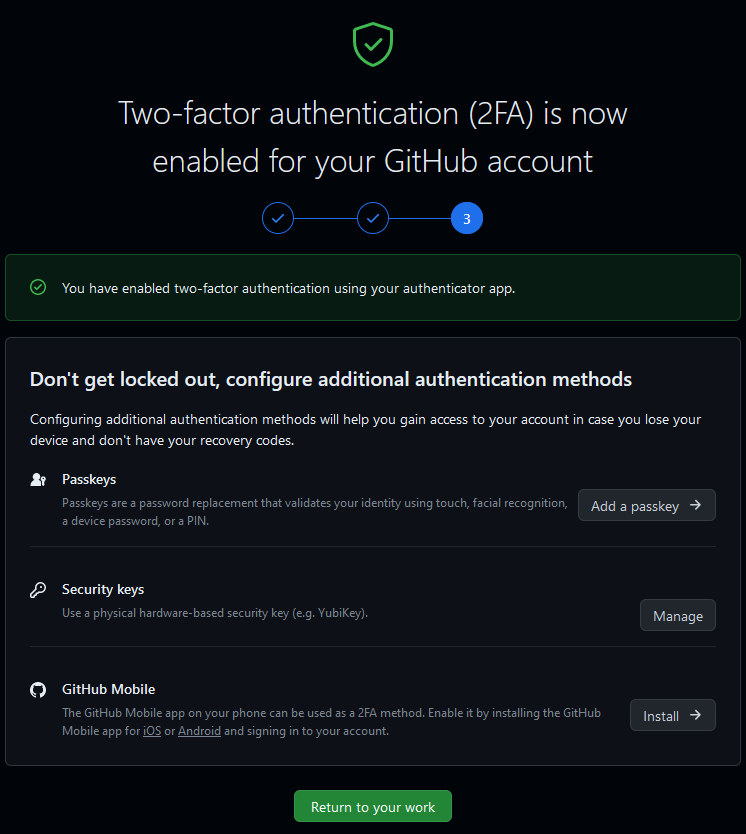
GitHub要求开启2FA,否则不让用了。
背景 其实大概在一个多月前,在 GitHub 网页端以及邮箱里都被提示:要求开启 2FA ,即双因子认证;但是当时由于拖延症和侥幸心理作祟,直接忽略了相关信息,毕竟“又不是不能用”。。 只到今天发现 GitHub 直接…...

Python 编程基础 | 第三章-数据类型 | 3.6、元组
一、元组 Python 的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。 1、创建元组 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可,例如: tup1 (physics, ch…...

2023/10/7 -- ARM
【程序状态寄存器读写指令】 1.指令码以及格式 mrs:读取CPSR寄存器的值 mrs 目标寄存器 CPSR:读取CPSR的数值保存到目标寄存器中msr:修改CPSR寄存器的数值msr CPSR,第一操作数:将第一操作数的数值保存到CPSR寄存器中//修改CPSR寄存器,也就表示程序的状…...

yolov5加关键点回归
文章目录 一、数据1)数据准备2)标注文件说明 二、基于yolov5-face 修改自己的yolov5加关键点回归1、dataloader,py2、augmentations.py3、loss.py4、yolo.py 一、数据 1)数据准备 1、手动创建文件夹: yolov5-face-master/data/widerface/tr…...
untitle
实用的科研图形美化处理教程分享 显微照片排版标记 除了统计图表之外,显微照片也是文章中必不可少的实验结果呈现方式。除了常规实验的各种组织切片照片,在空间转录组文章中显微照片更是常见。显微照片的呈现方式也是有讲究的,比如对照片…...

《论文阅读》监督对抗性对比学习在对话中的情绪识别 ACL2023
《论文阅读》监督对抗性对比学习在对话中的情绪识别 前言摘要相关知识最坏样本干扰监督对比学习生成式对抗网络纳什均衡琴森香农散度范式球模型架构监督对抗性对比学习模型结构图实验结果问题前言 你是否也对于理解论文存在困惑? 你是否也像我之前搜索论文解读,得到只是中文…...

2023-10-07 LeetCode每日一题(股票价格跨度)
2023-10-07每日一题 一、题目编号 901. 股票价格跨度二、题目链接 点击跳转到题目位置 三、题目描述 设计一个算法收集某些股票的每日报价,并返回该股票当日价格的 跨度 。 当日股票价格的 跨度 被定义为股票价格小于或等于今天价格的最大连续日数(…...
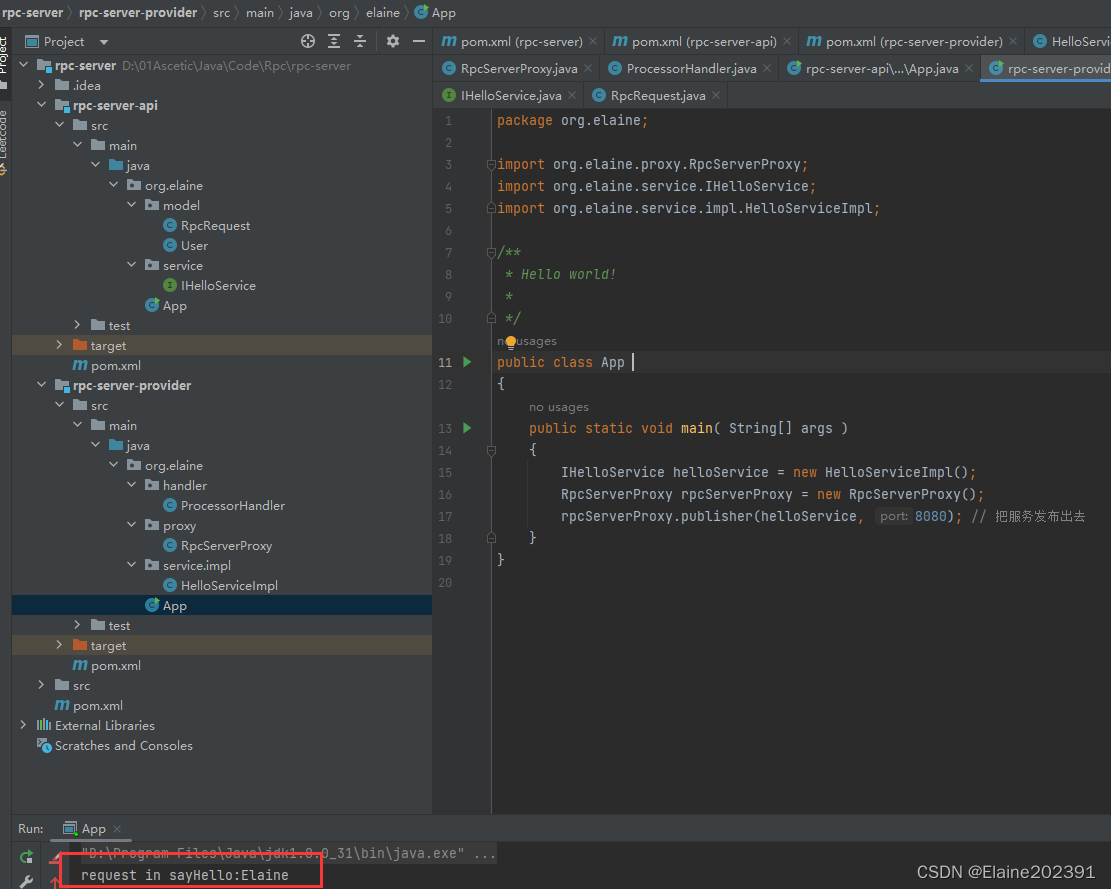
聊聊分布式架构04——RPC通信原理
目录 RPC通信的基本原理 RPC结构 手撸简陋版RPC 知识点梳理 1.Socket套接字通信机制 2.通信过程的序列化与反序列化 3.动态代理 4.反射 思维流程梳理 码起来 服务端时序图 服务端—Api与Provider模块 客户端时序图 RPC通信的基本原理 RPC(Remote Proc…...
维吉尼亚密码
维吉尼亚密码属于多表代换密码 其中A<–>0,B<–>1,…,Z<–>25,则每个密钥K相当于一个长度为m的字母串,称为密钥字。维吉尼亚密码一次加密m个明文字母。 示例:设m6,密钥字为…...

ubuntu20.04挂载拓展盘保姆级流程
背景:跑模型玩时,发现机子硬盘太小了,搞个1t固态作为挂载盘。以下为操作全流程记录 1、开始root权限操作 sudo su若进不去,考虑是否给root设置过密码,新系统第一次进入需要设置密码。 进入成功: rooty:…...
)
顶顶通电话机器人接口对接开源ASR(语音识别)
前景介绍 目前大部分用户使用的都是在线ASR按照分钟或者按次付费,之前开源ASR效果太差不具备商用的条件,随着 阿里达摩院发布了大量开源数据集或者海量工业数据训练的模型,识别效果已经和商用ASR差距非常小,完全具备了很多场景代…...

windows消息机制
windows开发比较简单,首先要理解的就是消息机制。 Windows消息机制是指Windows操作系统中的消息传递机制。在Windows中,应用程序通过消息进行通信和交互。消息是一种轻量级的通信方式,用于在不同的窗口、线程或进程之间传递信息。 在Windows…...

整数划分——DP
用 j j j 个数表示 i i i 的方案数,考虑dp 转移考虑最小值是否为1 无限制 若为1,则转移到 f ( i 1 , j 1 ) f(i1, j1) f(i1,j1)不为1,则全部1,转移到 f ( i j , j ) f(ij, j) f(ij,j) 数之间不能重复 那么相当于每次整…...

Git切换用户常用命令
1、查看 查看用户名 : git config user.name查看密码: git config user.password查看邮箱: git config user.email查看配置信息(包含上面的信息): $ git config --list2、新增、切换 修改用户名 git…...

一般香港服务器带宽选多大够用?(带宽计算方法)
在海外IDC市场份额中,香港服务器依托自身优越的服务器资源条件,在各个行业中发挥的重要作用。但是,不同业务对网络带宽的要求各不相同,弄清楚如何计算带宽需求对于确保业务平稳运行至关重要,最好从一开始就使用正…...

vue中使用ali-oss上传文件到阿里云上
1.使用 npm 安装ali-oss npm install ali-oss --save2.写ali-oss.js // 引入ali-oss let OSS require(ali-oss) let client new OSS({region: oss-cn-xxx, // bucket所在的区域, 默认oss-cn-hangzhousecure: true, // secure: 配合region使用,如果指…...
计算时间的函数及其示例说明)
php实战案例记录(17)计算时间的函数及其示例说明
在PHP中,有许多函数可以用于计算和处理时间。以下是一些常用的计算时间的函数及其示例说明: time():获取当前时间的Unix时间戳。 $currentTimestamp time(); echo $currentTimestamp;date():将Unix时间戳格式化为指定的日期和时…...

对比官方直连体验Taotoken在模型调用稳定性上的差异感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方直连体验Taotoken在模型调用稳定性上的差异感受 作为一名长期与各类大模型API打交道的开发者,我习惯于直接调用…...

基于Adafruit CRICKIT与3D打印的水面机器人DIY全攻略
1. 项目概述:打造你的第一艘智能水面机器人 如果你对机器人、水上航行或者水下摄影感兴趣,但又觉得从零开始设计电路和结构太复杂,那么这个项目就是为你准备的。今天,我想分享一个我最近完成的、非常有趣且实用的创客项目&#x…...

ComfyUI Segment Anything:零门槛实现智能图像分割的完整指南
ComfyUI Segment Anything:零门槛实现智能图像分割的完整指南 【免费下载链接】comfyui_segment_anything Based on GroundingDino and SAM, use semantic strings to segment any element in an image. The comfyui version of sd-webui-segment-anything. 项目地…...

Rime中州韵配置避坑指南:从安装小狼毫到实现Emoji、花字、彩色文本的完整流程
Rime中州韵配置避坑指南:从安装小狼毫到实现Emoji、花字、彩色文本的完整流程 第一次接触Rime输入法的用户,往往会被其高度定制化的特性所吸引——无论是动态状态栏、彩色候选词,还是随心所欲的Emoji混输,都让人眼前一亮。但当真…...
—— 卷积运算的本质(三十八))
深度学习CNN(一)—— 卷积运算的本质(三十八)
1. 定位导航 🎉 第 9 章 CNN 大门正式开启! CNN 是深度学习历史上最具影响力的架构创新之一: 2012 AlexNet:ImageNet 革命,开启深度学习时代 2015 ResNet:突破"深度极限" 2020 Vision Transformer:CNN 的最大竞争对手出现 直到 2024 年:CNN 仍是图像处理、…...

告别复杂设置!Sunshine v0.21.0 + Moonlight安卓版:5分钟搞定家庭局域网游戏串流
5分钟极简指南:用Sunshine和Moonlight打造家庭游戏串流系统 客厅的沙发上,手机屏幕突然变成了你的高性能游戏PC——这不是科幻电影,而是每个家庭都能实现的游戏串流体验。过去需要复杂网络知识才能搭建的串流系统,如今借助Sunshin…...
)
电路分析基础(2)
受控源 基本概念 理想受控源模型...

3分钟完成Honey Select 2中文汉化:免费增强补丁终极使用指南
3分钟完成Honey Select 2中文汉化:免费增强补丁终极使用指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的界面语言障碍而…...

2026 年软硬两用床垫,为何能做到不塌陷?
引言随着科技的不断进步和消费者需求的多样化,床垫市场也在不断创新。特别是软硬两用床垫,因其能够满足不同人群的需求而备受青睐。然而,如何确保床垫在长时间使用后不塌陷,仍然是一个技术难题。本文将探讨2026年软硬两用床垫如何…...

FreeRTOS优先级设置踩坑实录:为什么你的高优先级任务跑不起来?
FreeRTOS优先级设置实战指南:从原理到调试的完整解决方案 当你第一次在FreeRTOS中创建多个任务并设置不同优先级时,可能会遇到一个令人困惑的现象:明明设置了高优先级任务,但系统运行时低优先级任务却先执行。这种情况在从其他RT…...