B树、B+树详解
B树
前言
首先,为什么要总结B树、B+树的知识呢?最近在学习数据库索引调优相关知识,数据库系统普遍采用B-/+Tree作为索引结构(例如mysql的InnoDB引擎使用的B+树),理解不透彻B树,则无法理解数据库的索引机制;接下来将用最简洁直白的内容来了解B树、B+树的数据结构
另外,B-树,即为B树。因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解。如人们可能会以为B-树是一种树,而B树又是一种树。而事实上是,B-tree就是指的B树,目前理解B的意思为平衡
B树的出现是为了弥合不同的存储级别之间的访问速度上的巨大差异,实现高效的 I/O。平衡二叉树的查找效率是非常高的,并可以通过降低树的深度来提高查找的效率。但是当数据量非常大,树的存储的元素数量是有限的,这样会导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。另外数据量过大会导致内存空间不够容纳平衡二叉树所有结点的情况。B树是解决这个问题的很好的结构
概念
首先,B树不要和二叉树混淆,在计算机科学中,B树是一种自平衡树数据结构,它维护有序数据并允许以对数时间进行搜索,顺序访问,插入和删除。B树是二叉搜索树的一般化,因为节点可以有两个以上的子节点。[1]与其他自平衡二进制搜索树不同,B树非常适合读取和写入相对较大的数据块(如光盘)的存储系统。它通常用于数据库和文件系统。
定义
B树是一种平衡的多分树,通常我们说m阶的B树,它必须满足如下条件:
- 每个节点最多只有m个子节点。
- 每个非叶子节点(除了根)具有至少⌈ m/2⌉子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有k个子节点的非叶节点包含k -1个键。
- 所有叶子都出现在同一水平,没有任何信息(高度一致)。
第一次看到这个定义的时候,在想什么鬼?。。。。什么是阶?子节点、飞叶子点、根???啥意思!少年别慌。。。
什么是B树的阶 ?
B树中一个节点的子节点数目的最大值,用m表示,假如最大值为10,则为10阶,如图

所有节点中,节点【13,16,19】拥有的子节点数目最多,四个子节点(灰色节点),所以可以定义上面的图片为4阶B树,现在懂什么是阶了吧
什么是根节点 ?
节点【10】即为根节点,特征:根节点拥有的子节点数量的上限和内部节点相同,如果根节点不是树中唯一节点的话,至少有俩个子节点(不然就变成单支了)。在m阶B树中(根节点非树中唯一节点),那么有关系式2<= M <=m,M为子节点数量;包含的元素数量 1<= K <=m-1,K为元素数量。
什么是内部节点 ?
节点【13,16,19】、节点【3,6】都为内部节点,特征:内部节点是除叶子节点和根节点之外的所有节点,拥有父节点和子节点。假定m阶B树的内部节点的子节点数量为M,则一定要符合(m/2)<= M <=m关系式,包含元素数量M-1;包含的元素数量 (m/2)-1<= K <=m-1,K为元素数量。m/2向上取整。
什么是叶子节点?
节点【1,2】、节点【11,12】等最后一层都为叶子节点,叶子节点对元素的数量有相同的限制,但是没有子节点,也没有指向子节点的指针。特征:在m阶B树中叶子节点的元素符合(m/2)-1<= K <=m-1。
好了,概念已经清楚,不用着急背公式, 接着往下看
插入
针对m阶高度h的B树,插入一个元素时,首先在B树中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素。
- 若该节点元素个数小于m-1,直接插入;
- 若该节点元素个数等于m-1,引起节点分裂;以该节点中间元素为分界,取中间元素(偶数个数,中间两个随机选取)插入到父节点中;
- 重复上面动作,直到所有节点符合B树的规则;最坏的情况一直分裂到根节点,生成新的根节点,高度增加1;
上面三段话为插入动作的核心,接下来以5阶B树为例,详细讲解插入的动作;
5阶B树关键点:
- 2<=根节点子节点个数<=5
- 3<=内节点子节点个数<=5
- 1<=根节点元素个数<=4
- 2<=非根节点元素个数<=4
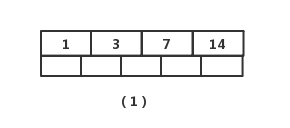
插入8

图(1)插入元素【8】后变为图(2),此时根节点元素个数为5,不符合 1<=根节点元素个数<=4,进行分裂(真实情况是先分裂,然后插入元素,这里是为了直观而先插入元素,下面的操作都一样,不再赘述),取节点中间元素【7】,加入到父节点,左右分裂为2个节点,如图(3)

接着插入元素【5】,【11】,【17】时,不需要任何分裂操作,如图(4)
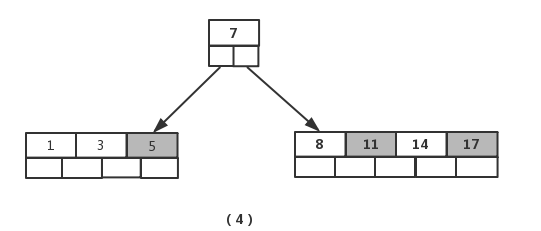
插入元素【13】
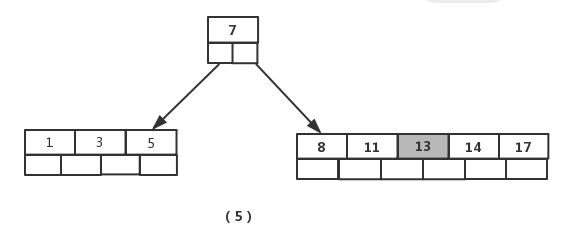
节点元素超出最大数量,进行分裂,提取中间元素【13】,插入到父节点当中,如图(6)
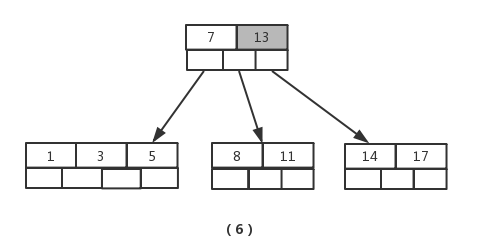
接着插入元素【6】,【12】,【20】,【23】时,不需要任何分裂操作,如图(7)
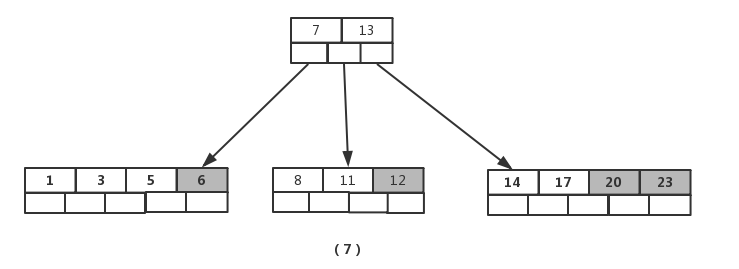
插入【26】时,最右的叶子结点空间满了,需要进行分裂操作,中间元素【20】上移到父节点中,注意通过上移中间元素,树最终还是保持平衡,分裂结果的结点存在2个关键字元素。
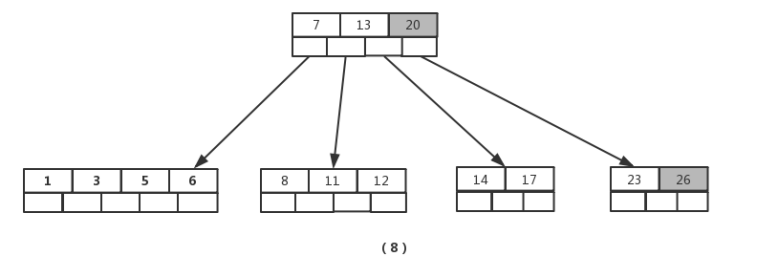
插入【4】时,导致最左边的叶子结点被分裂,【4】恰好也是中间元素,上移到父节点中,然后元素【16】,【18】,【24】,【25】陆续插入不需要任何分裂操作
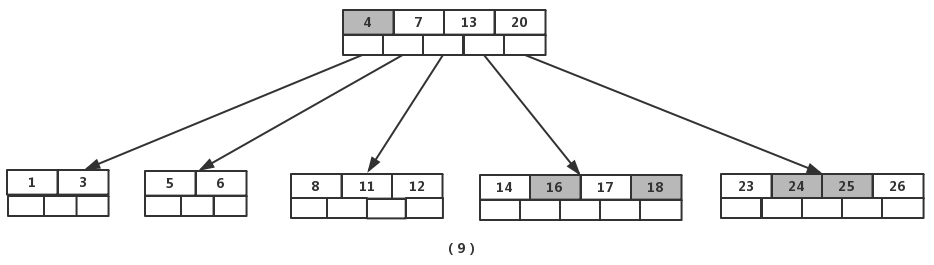
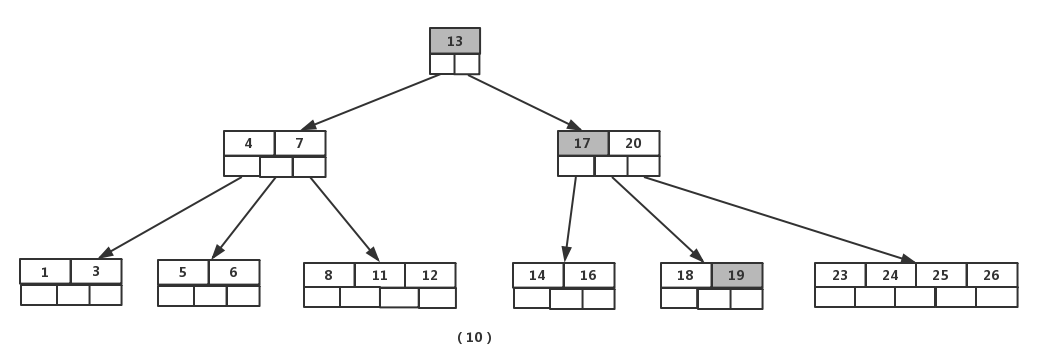
最后,当插入【19】时,含有【14】,【16】,【17】,【18】的结点需要分裂,把中间元素【17】上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间元素【13】上移到新形成的根结点中,这样具体插入操作的完成。
删除
首先查找B树中需删除的元素,如果该元素在B树中存在,则将该元素在其结点中进行删除;删除该元素后,首先判断该元素是否有左右孩子结点,如果有,则上移孩子结点中的某相近元素(“左孩子最右边的节点”或“右孩子最左边的节点”)到父节点中,然后是移动之后的情况;如果没有,直接删除。
- 某结点中元素数目小于(m/2)-1,(m/2)向上取整,则需要看其某相邻兄弟结点是否丰满;
- 如果丰满(结点中元素个数大于(m/2)-1),则向父节点借一个元素来满足条件;
- 如果其相邻兄弟都不丰满,即其结点数目等于(m/2)-1,则该结点与其相邻的某一兄弟结点进行“合并”成一个结点;
接下来还以5阶B树为例,详细讲解删除的动作;
- 关键要领,元素个数小于 2(m/2 -1)就合并,大于4(m-1)就分裂
如图依次删除依次删除【8】,【20】,【18】,【5】
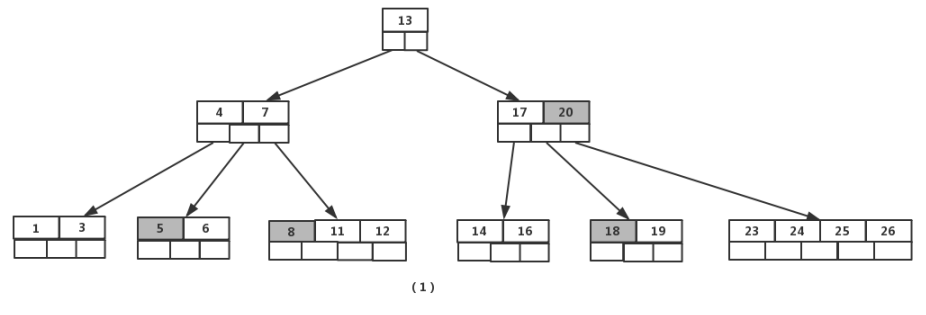
首先删除元素【8】,当然首先查找【8】,【8】在一个叶子结点中,删除后该叶子结点元素个数为2,符合B树规则,操作很简单,咱们只需要移动【11】至原来【8】的位置,移动【12】至【11】的位置(也就是结点中删除元素后面的元素向前移动)

下一步,删除【20】,因为【20】没有在叶子结点中,而是在中间结点中找到,咱们发现他的继承者【23】(字母升序的下个元素),将【23】上移到【20】的位置,然后将孩子结点中的【23】进行删除,这里恰好删除后,该孩子结点中元素个数大于2,无需进行合并操作。

下一步删除【18】,【18】在叶子结点中,但是该结点中元素数目为2,删除导致只有1个元素,已经小于最小元素数目2,而由前面我们已经知道:如果其某个相邻兄弟结点中比较丰满(元素个数大于ceil(5/2)-1=2),则可以向父结点借一个元素,然后将最丰满的相邻兄弟结点中上移最后或最前一个元素到父节点中,在这个实例中,右相邻兄弟结点中比较丰满(3个元素大于2),所以先向父节点借一个元素【23】下移到该叶子结点中,代替原来【19】的位置,【19】前移;然【24】在相邻右兄弟结点中上移到父结点中,最后在相邻右兄弟结点中删除【24】,后面元素前移。

最后一步删除【5】, 删除后会导致很多问题,因为【5】所在的结点数目刚好达标,刚好满足最小元素个数(ceil(5/2)-1=2),而相邻的兄弟结点也是同样的情况,删除一个元素都不能满足条件,所以需要该节点与某相邻兄弟结点进行合并操作;首先移动父结点中的元素(该元素在两个需要合并的两个结点元素之间)下移到其子结点中,然后将这两个结点进行合并成一个结点。所以在该实例中,咱们首先将父节点中的元素【4】下移到已经删除【5】而只有【6】的结点中,然后将含有【4】和【6】的结点和含有【1】,【3】的相邻兄弟结点进行合并成一个结点。

也许你认为这样删除操作已经结束了,其实不然,在看看上图,对于这种特殊情况,你立即会发现父节点只包含一个元素【7】,没达标(因为非根节点包括叶子结点的元素K必须满足于2=<K<=4,而此处的K=1),这是不能够接受的。如果这个问题结点的相邻兄弟比较丰满,则可以向父结点借一个元素。而此时兄弟节点元素刚好为2,刚刚满足,只能进行合并,而根结点中的唯一元素【13】下移到子结点,这样,树的高度减少一层。

看完插入,删除,想必也把B树的特征掌握了,下面普及下其他知识,换个脑子
磁盘IO与预读
计算机存储设备一般分为两种:内存储器(main memory)和外存储器(external memory)。
内存储器为内存,内存存取速度快,但容量小,价格昂贵,而且不能长期保存数据(在不通电情况下数据会消失)。
外存储器即为磁盘读取,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。下图是计算机硬件延迟的对比图,供大家参考:

考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
事实1 : 不同容量的存储器,访问速度差异悬殊。
- 磁盘(ms级别) << 内存(ns级别), 100000倍
- 若内存访问需要1s,则一次外存访问需要一天
- 为了避免1次外存访问,宁愿访问内存100次...所以将
最常用的数据存储在最快的存储器中
事实2 : 从磁盘中读 1 B,与读写 1KB 的时间成本几乎一样
从以上数据中可以总结出一个道理,索引查询的数据主要受限于硬盘的I/O速度,查询I/O次数越少,速度越快,所以B树的结构才应需求而生;B树的每个节点的元素可以视为一次I/O读取,树的高度表示最多的I/O次数,在相同数量的总元素个数下,每个节点的元素个数越多,高度越低,查询所需的I/O次数越少;假设,一次硬盘一次I/O数据为8K,索引用int(4字节)类型数据建立,理论上一个节点最多可以为2000个元素,2000*2000*2000=8000000000,80亿条的数据只需3次I/O(理论值),可想而知,B树做为索引的查询效率有多高;
另外也可以看出同样的总元素个数,查询效率和树的高度密切相关
B树的高度
一棵含有N个总关键字数的m阶的B树的最大高度是多少?
log(m/2)(N+1)/2 + 1 ,log以(m/2)为低,(N+1)/2的对数再加1
算法如下

B+树
B+树是应文件系统所需而产生的B树的变形树,那么可能一定会想到,既然有了B树,又出一个B+树,那B+树必然是有很多优点的
B+树的特征:
- 有m个子树的中间节点包含有m个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引;
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息);
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息);
查找算法
查找以典型的方式进行,类似于二叉查找树。起始于根节点,自顶向下遍历树,选择其分离值在要查找值的任意一边的子指针。在节点内部典型的使用是二分查找来确定这个位置。
对B+树可以进行两种查找运算:
1、从最小关键字起顺序查找;
2、从根结点开始,进行随机查找。
在查找时,若非终端结点上的关键值等于给定值,并不终止,而是继续向下直到叶子结点。因此,在B+树中,不管查找成功与否,每次查找都是走了一条从根到叶子结点的路径。其余同B-树的查找类似。
插入算法
m阶B树的插入操作在叶子结点上进行,假设要插入关键值a,找到叶子结点后插入a,做如下算法判别:
①如果当前结点是根结点并且插入后结点关键字数目小于等于m,则算法结束;
②如果当前结点是非根结点并且插入后结点关键字数目小于等于m,则判断若a是新索引值时转步骤④后结束,若a不是新索引值则直接结束;
③如果插入后关键字数目大于m(阶数),则结点先分裂成两个结点X和Y,并且他们各自所含的关键字个数分别为:u=大于(m+1)/2的最小整数,v=小于(m+1)/2的最大整数;
由于索引值位于结点的最左端或者最右端,不妨假设索引值位于结点最右端,有如下操作:
如果当前分裂成的X和Y结点原来所属的结点是根结点,则从X和Y中取出索引的关键字,将这两个关键字组成新的根结点,并且这个根结点指向X和Y,算法结束;
如果当前分裂成的X和Y结点原来所属的结点是非根结点,依据假设条件判断,如果a成为Y的新索引值,则转步骤④得到Y的双亲结点P,如果a不是Y结点的新索引值,则求出X和Y结点的双亲结点P;然后提取X结点中的新索引值a’,在P中插入关键字a’,从P开始,继续进行插入算法;
④提取结点原来的索引值b,自顶向下,先判断根是否含有b,是则需要先将b替换为a,然后从根结点开始,记录结点地址P,判断P的孩子是否含有索引值b而不含有索引值a,是则先将孩子结点中的b替换为a,然后将P的孩子的地址赋值给P,继续搜索,直到发现P的孩子中已经含有a值时,停止搜索,返回地址P。
删除算法
B+树的删除也仅在叶子结点进行,当叶子结点中的最大关键字被删除时,其在非终端结点中的值可以作为一个“分界关键字”存在。若因删除而使结点中关键字的个数少于m/2(m/2结果取上界,如5/2结果为3)时,其和兄弟结点的合并过程亦和B-树类似。
1、首先,查找要删除的值。接着从包含它的节点中删除这个值。
2、如果没有节点处于违规状态则处理结束。
3、如果节点处于违规状态则有两种可能情况:
(1)它的兄弟节点,就是同一个父节点的子节点,可以把一个或多个它的子节点转移到当前节点,而把它返回为合法状态。如果是这样,在更改父节点和两个兄弟节点的分离值之后处理结束。
(2)它的兄弟节点由于处在低边界上而没有额外的子节点。在这种情况下把两个兄弟节点合并到一个单一的节点中,而且我们递归到父节点上,因为它被删除了一个子节点。持续这个处理直到当前节点是合法状态或者到达根节点,在其上根节点的子节点被合并而且合并后的节点成为新的根节点。
算法区分
B+树与B-树
B+树是应文件系统所需而产生的一种B-树的变形树。一棵m阶的B+树和m阶的B树的差异在于:
(1)有n棵子树的结点中含有n个关键码;
(2)所有的叶子结点中包含了全部关键码的信息,及指向含有这些关键码记录的指针,且叶子结点本身依关键码的大小自小而大的顺序链接;
(3)所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键码。
为什么说B+树比B树更适合数据库索引?
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
3)B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低;不懂可以看看这篇解读-》范围查找
补充:B树的范围查找用的是中序遍历,而B+树用的是在链表上遍历;
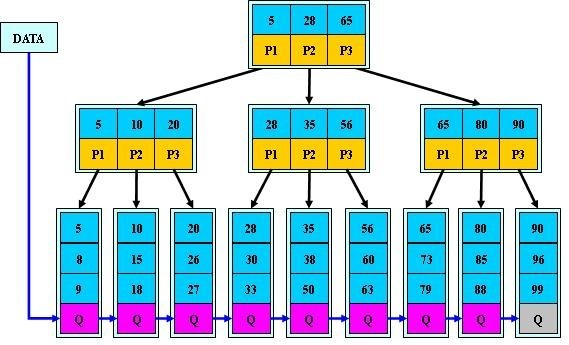
B+树如下:
相关文章:
B树、B+树详解
B树 前言 首先,为什么要总结B树、B树的知识呢?最近在学习数据库索引调优相关知识,数据库系统普遍采用B-/Tree作为索引结构(例如mysql的InnoDB引擎使用的B树),理解不透彻B树,则无法理解数据…...
使用hugging face开源库accelerate进行多GPU(单机多卡)训练卡死问题
目录 问题描述及配置网上资料查找1.tqdm问题2.dataloader问题3.model(input)写法问题4.环境变量问题 我的卡死问题解决方法 问题描述及配置 在使用hugging face开源库accelerate进行多GPU训练(单机多卡)的时候,经常出现如下报错 [E Process…...
IDEA 修改插件安装位置
不说假话,一定要看到最后,不然你以为我为什么要自己总结!!! IDEA 修改插件安装位置 前言步骤 前言 IDEA 默认的配置文件均安装在C盘,使用时间长会生成很多文件,这些文件会占用挤兑C盘空间&…...

牛客网SQL160
国庆期间每类视频点赞量和转发量_牛客题霸_牛客网 select * from ( select tag,dt, sum(单日点赞量)over(partition by tag order by dt rows between 6 preceding and 0 following), max(单日转发量)over(partition by tag order by dt rows between 6 preceding and 0 follo…...
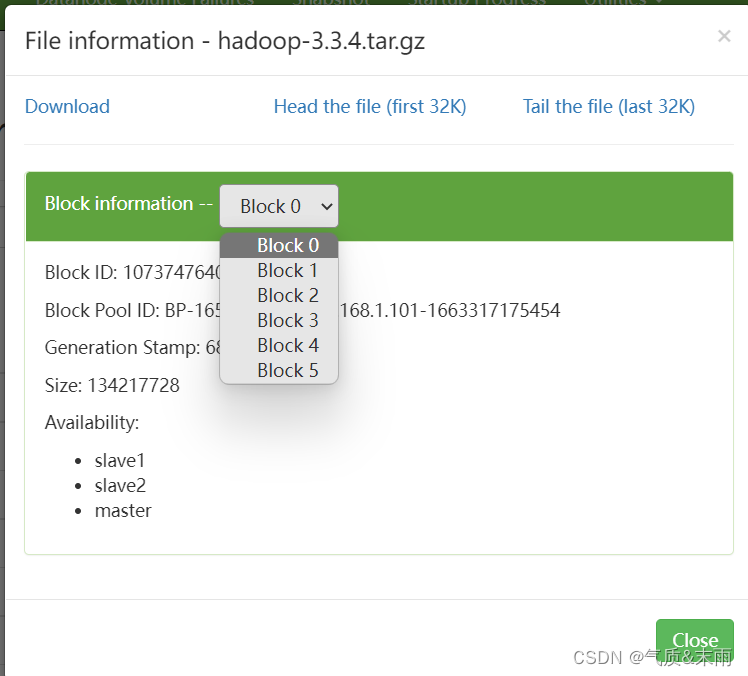
HDFS Java API 操作
文章目录 HDFS Java API操作零、启动hadoop一、HDFS常见类接口与方法1、hdfs 常见类与接口2、FileSystem 的常用方法 二、Java 创建Hadoop项目1、创建文件夹2、打开Java IDEA1) 新建项目2) 选择Maven 三、配置环境1、添加相关依赖2、创建日志属性文件 四、Java API操作1、在HDF…...
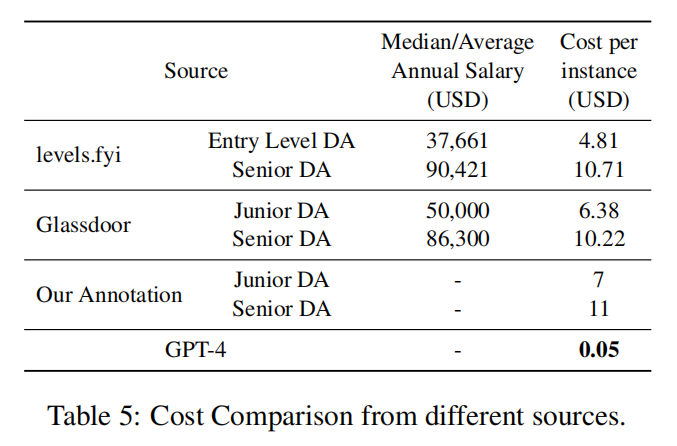
论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】
文章目录 论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】背景:数据分析师工作范围基于GPT-4的端到端数据分析框架将GPT-4作为数据分析师的框架的流程图 实验分析评估指标表1:GPT-4性能表现表2&…...
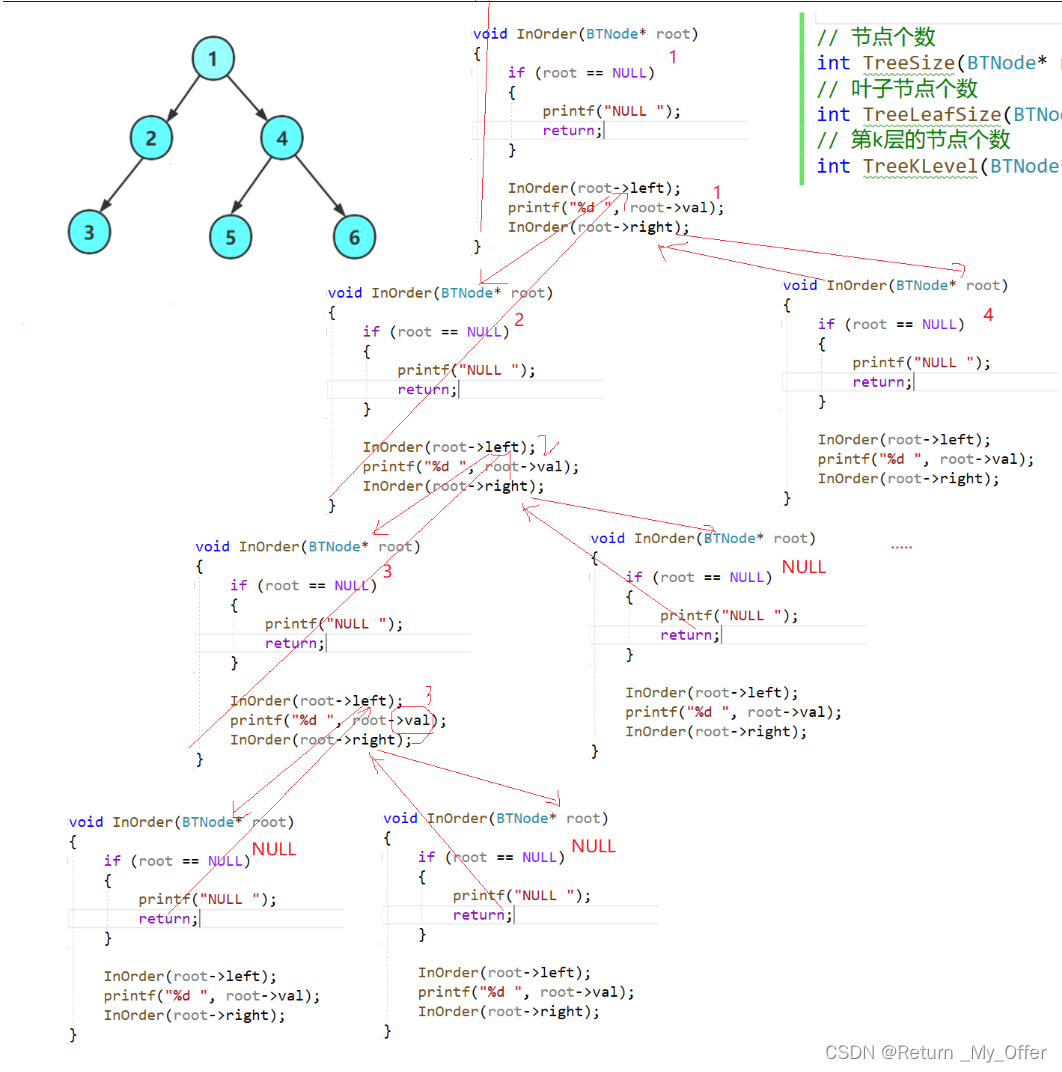
【数据结构】:二叉树与堆排序的实现
1.树概念及结构(了解) 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的有一个特殊的结点&#…...

纯css手写switch
CSS 手写switch 纯css手写switchcss变量 纯css手写switch 思路: switch需要的元素有:开关背景、开关按钮。点击按钮后,背景色变化,按钮颜色变化,呈现开关打开状态。 利用typecheckbox,来实现switch效果(修…...

PyTorch 深度学习之处理多维特征的输入Multiple Dimension Input(六)
1.Multiple Dimension Logistic Regression Model 1.1 Mini-Batch (N samples) 8D->1D 8D->2D 8D->6D 1.2 Neural Network 学习能力太好也不行(学习到的是数据集中的噪声),最好的是要泛化能力,超参数尝试 Example, Arti…...

LeetCode【438】找到字符串中所有字母异位词
题目: 注意:下面代码勉强通过,每次都对窗口内字符排序。然后比较字符串。 代码: public List<Integer> findAnagrams(String s, String p) {int start 0, end p.length() - 1;List<Integer> result new ArrayL…...
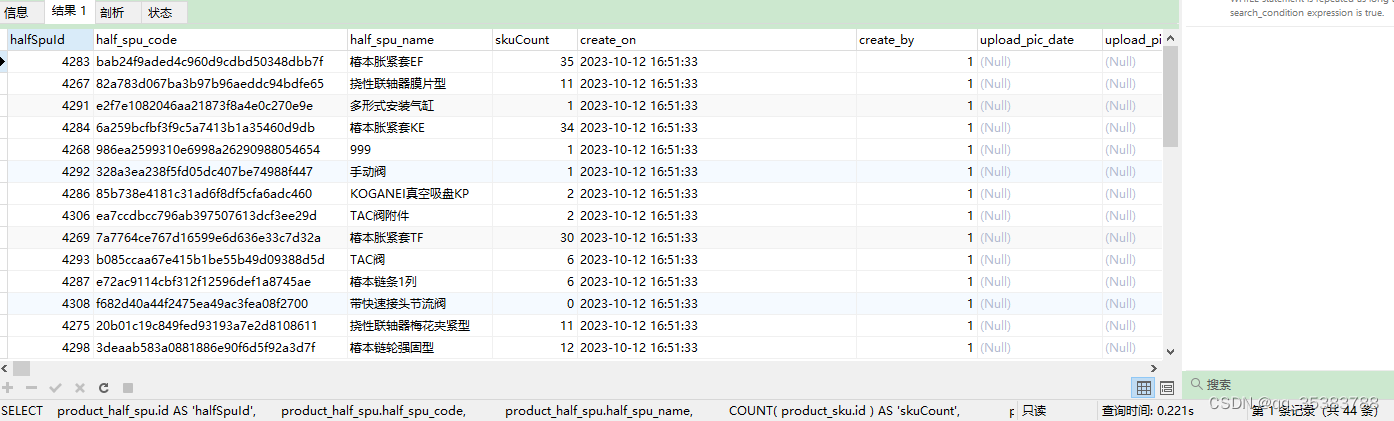
关于LEFT JOIN的一次理解
先看一段例子: SELECTproduct_half_spu.id AS halfSpuId,product_half_spu.half_spu_code,product_half_spu.half_spu_name,COUNT( product_sku.id ) AS skuCount,product_half_spu.create_on,product_half_spu.create_by,product_half_spu.upload_pic_date,produc…...

各报文段格式集合
数据链路层-- MAC帧 前导码8B:数据链路层将封装好的MAC帧交付给物理层进行发送,物理层在发送MAC帧前,还要在前面添加8字节的前导码(分为7字节的前同步码1字节的帧开始定界符)MAC地址长度6B数据长度46~1500B…...

【算法-动态规划】最长公共子序列
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...
区块链游戏的开发流程
链游(Blockchain Games)的开发流程与传统游戏开发有许多相似之处,但它涉及到区块链技术的集成和智能合约的开发。以下是链游的一般开发流程,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司&…...

目标检测网络系列——YOLO V2
文章目录 YOLO9000better,更准batch Normalization高分辨率的训练使用anchor锚框尺寸的选择——聚类锚框集成改进——直接预测bounding box细粒度的特征图——passthrough layer多尺度训练数据集比对实验VOC 2007VOC 2012COCOFaster,更快网络模型——Darknet19训练方法Strong…...
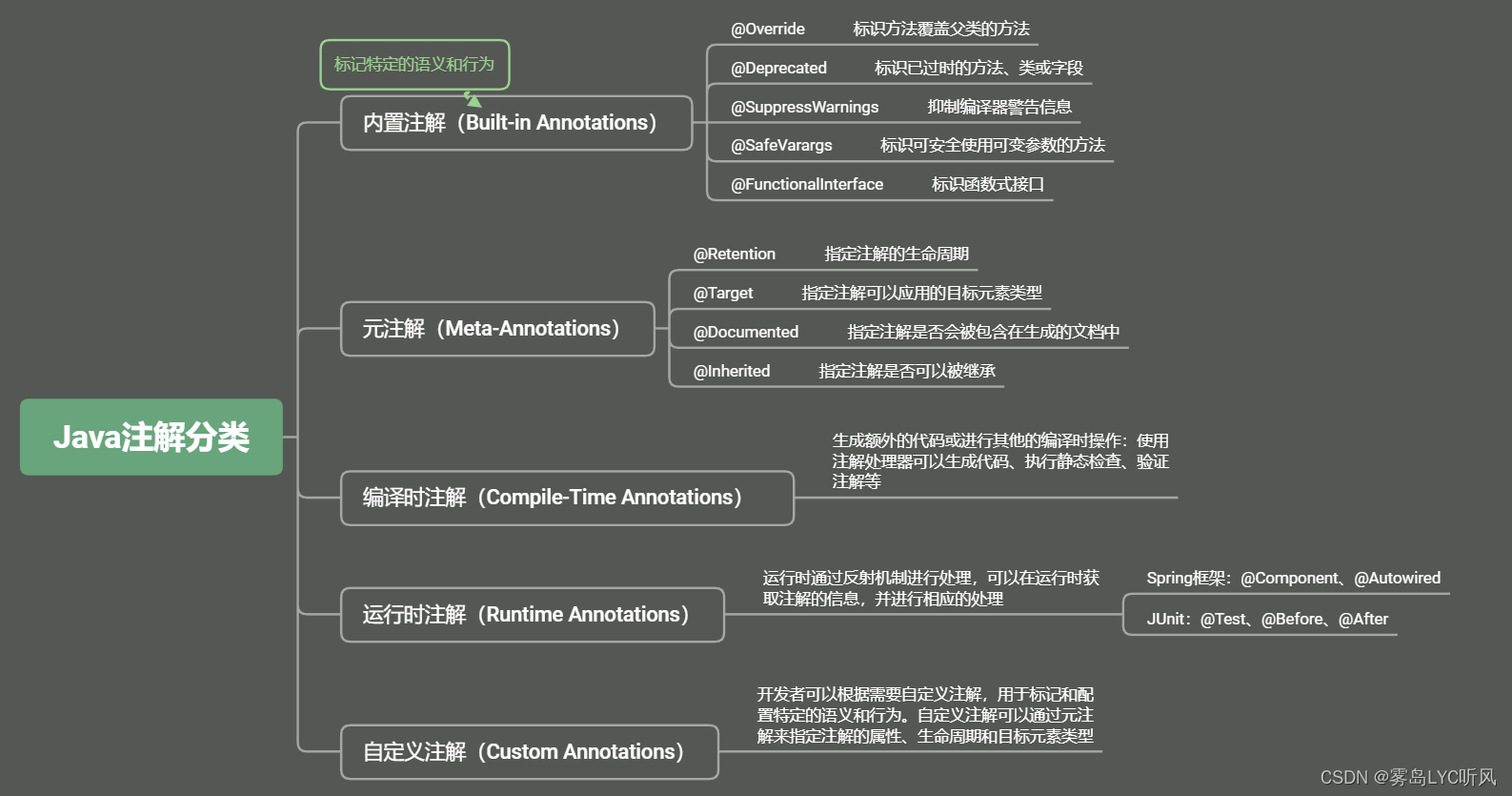
15. Java反射和注解
Java —— 反射和注解 1. 反射2. 注解 1. 反射 动态语言:变量的类型和属性可以在运行时动态确定,而不需要在编译时指定 常见动态语言:Python,JavaScript,Ruby,PHP,Perl;常见静态语言…...
pdf处理工具 Enfocus PitStop Pro 2022 中文 for mac
Enfocus PitStop Pro 2022是一款专业的PDF预检和编辑软件,旨在帮助用户提高生产效率、确保印刷品质量并减少错误。以下是该软件的一些特色功能: PDF预检。PitStop Pro可以自动检测和修复常见的PDF文件问题,如缺失字体、图像分辨率低、颜色空…...
微信小程序入门开发教程
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《微信小程序开发实战》。🎯Ἲ…...

php函数
1. strstr() 返回a在b中的第一个位置 2.substr() 截取字符串 3.PHP字符串函数parse_str(将字符串解析成多个变量)-CSDN博客 4.explode() 字符串分割为数组 5.trim() 1.去除字符串两边的 空白字符 2.去除指定字符 6.extract()函数从数组里…...

3.3 封装性
思维导图: 3.3.1 为什么要封装 ### 3.3.1 为什么要封装 **封装**,在Java的面向对象编程中,是一个核心的思想。它主要是为了保护对象的状态不被外部随意修改,确保数据的完整性和安全性。 #### **核心思想:** - 保护…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

YimMenu:GTA V终极游戏增强工具完整实战手册
YimMenu:GTA V终极游戏增强工具完整实战手册 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间
Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的Windows电脑是否经常提示C盘空间不足ÿ…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

脉冲神经网络与神经形态计算的能效优化实践
1. 脉冲神经网络与神经形态计算基础脉冲神经网络(SNN)作为第三代神经网络模型,其核心在于模拟生物神经系统的信息处理机制。与传统人工神经网络(ANN)相比,SNN具有三个本质区别:首先,…...