clickhouse数据库简介,列式存储
clickhouse数据库简介
1、关于列存储
所说的行式存储和列式存储,指的是底层的存储形式,数据在磁盘上的真实存储,至于暴漏在上层的用户的使用是没有区别的,看到的都是一行一行的表格。
| id | name | user_id |
|---|---|---|
| 1 | 闪光 | 1026603 |
| 2 | 轨道物流 | 1026556 |
行式存储

列式存储

存储方式的不同就决定了读取和存储数据的逻辑不同,比如,要查询id这一列的全部数据,如果是行存储的话,就需要加载整张表,然后遍历取出id这一个字段;如果是列存储的话,只需要加载第一段的数据即可。相反的,如果你需要查询第一条记录,如果是行存储的话,只需要读取第一段数据,如果是列存储的话,需要全部读取出来遍历后拼凑出第一条记录。
同样的,在写入数据的时候,显然列存储要更费劲一些。
列存储模式下,同一类数据存放在一起,这在一定程度上有利于数据压缩,比如user_id字段,可以抽出基数部分(1026556)和偏移量(47,0),数据量大的话压缩效果就出来了。而对于字符串字段,同样可以采取很好的压缩算法。官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
行式更适合OLTP(OnLineTransaction ),比如传统的基于增删改查操作的应用。列式更适合OLAP(OnLineAnalyticalProcessing),非常适合于在数据仓库领域发挥作用,比如数据分析、海量存储和商业智能;涉及不经常更新的数据。
2、OLAP场景的特点
读多于写
不同于**事务处理(OLTP)**的场景,比如电商场景中加购物车、下单、支付等需要在原地进行大量insert、update、delete操作;**数据分析(OLAP)**场景通常是将数据批量导入后,进行任意维度的灵活探索、BI工具洞察、报表制作等。数据一次性写入后,分析师需要尝试从各个角度对数据做挖掘、分析,直到发现其中的商业价值、业务变化趋势等信息。这是一个需要反复试错、不断调整、持续优化的过程,其中数据的读取次数远多于写入次数。这就要求底层数据库为这个特点做专门设计,而不是盲目采用传统数据库的技术架构。
大宽表,读大量行但是少量列,结果集较小
在OLAP场景中,通常存在一张或是几张多列的大宽表,列数高达数百甚至数千列。对数据分析处理时,选择其中的少数几列作为维度列、其他少数几列作为指标列,然后对全表或某一个较大范围内的数据做聚合计算。这个过程会扫描大量的行数据,但是只用到了其中的少数列。而聚合计算的结果集相比于动辄数十亿的原始数据,也明显小得多。
数据批量写入,且数据不更新或少更新
OLTP类业务对于延时(Latency)要求更高,要避免让客户等待造成业务损失;而OLAP类业务,由于数据量非常大,通常更加关注写入吞吐(Throughput),要求海量数据能够尽快导入完成。一旦导入完成,历史数据往往作为存档,不会再做更新和删除操作。
无需事务,数据一致性要求低
OLAP类业务对于事务需求较少,通常是导入历史日志数据,或搭配一款事务型数据库并实时从事务型数据库中进行数据同步。多数OLAP系统都支持最终一致性。
灵活多变,不适合预先建模
分析场景下,随着业务变化要及时调整分析维度、挖掘方法,以尽快发现数据价值、更新业务指标。而数据仓库中通常存储着海量的历史数据,调整代价十分高昂。预先建模技术虽然可以在特定场景中加速计算,但是无法满足业务灵活多变的发展需求,维护成本过高。
3、关于clickHouse
clickHouse是一个开源的列式数据库(DBMS),于2016年,由俄罗斯最大的搜索公司Yandex开源,采用C++开发。凭借优秀的性能,市场反应非常热烈。阿里,腾讯,头条都在大量使用clickhouse来做数据分析智能推荐。
在OLAP场景中侧重于对数据的分析,因此读数据操作是多于写数据的。在数据一次性写入后,数据工程师需要从各个角度对数据进行挖掘、分析,直到发现其中的业务变化趋势,对于数据的读取是非常频繁,而且不需要数据的更新,也不需要事务来强调一致性,只要获取到数据就好啦,ClickHouse非常适合作为底层数据库提供支持。
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
所谓数据的有序存储指的是数据在建表时可以将数据按照某些列进行排序,排序之后,相同类型的数据在磁盘上有序的存储,在进行范围查询时所获取的数据都存储在一个或若干个连续的空间内,极大的减少了磁盘IO时间;所谓数据分区分片,指的是在ClickHouse的部署模式上支持单机模式和分布式集群模式,在分布式中会把数据分为多个分片,并且分布到不同的节点上,它提供了丰富的分片策略,包含random随机分片(将写入数据随机分发到集群中的某个节点)、constant固定分片(将写入数据分发到某个固定节点)、columnvalue分片(将写入数据按某一列的值进行hash分片)、自定义表达式分片(将写入数据按照自定义的规则进行hash分片)。
在计算层ClickHouse提供了多核并行、分布式计算、近似计算、复杂数据类型支持等技术能力,最大化程度利用CPU资源,提升系统查询速度。所谓多核并行指的是在ClickHouse中数据是被分成了多个分区,查询某条数据时通过多分区的数据利用CPU的多核同时并行处理获取数据,降低了查询时长;所谓分布式计算指的是ClickHouse将查询任务拆分成多个子任务下发到多个集群中进行多机并行处理,最后汇聚结果给到用户,提供最近hostname规则(即将任务下发到机器最近的hostname节点)、inorder(即按顺序进行分发,当某个分片不可用时,下发到下一个分片);所谓近似计算指的是牺牲一定的精确度获取数据,在海量数据的分析中,其实并不需要非常精准的数据,近似数据足以分析决策,ClickHouse提供了中位数、分位数等多种聚合函数,极大的提高了查询性能,减轻了计算压力。
ClickHouse的发展可谓是非常快速,除了各个大厂都在使用之外,在社区方面,github标记为星级项目的人超过9000,成为最受开源的项目之一。它是一套完整的解决方案,自带存储能力、计算能力,自己实现了分布式计算、分布式集群部署,完全高可用,真可谓是简单灵活又不失强大!
4、结语
近年来ClickHouse发展趋势迅猛,社区和大厂都纷纷跟进使用。本文尝试从OLAP场景的需求出发,介绍了ClickHouse存储层、计算层的主要设计。ClickHouse实现了大多数当前主流的数据分析技术,具有明显的技术优势:
- 提供了极致的查询性能:开源公开benchmark显示比传统方法快1001000倍,提供50MB200MB/s的高吞吐实时导入能力)
- 以极低的成本存储海量数据: 借助于精心设计的列存、高效的数据压缩算法,提供高达10倍的压缩比,大幅提升单机数据存储和计算能力,大幅降低使用成本,是构建海量数据仓库的绝佳方案。
- 简单灵活又不失强大:提供完善SQL支持,上手十分简单;提供json、map、array等灵活数据类型适配业务快速变化;同时支持近似计算、概率数据结构等应对海量数据处理。
相比于开源社区的其他几项分析型技术,如Druid、Presto、Impala、Kylin、ElasticSearch等,ClickHouse更是一整套完善的解决方案,它自包含了存储和计算能力(无需额外依赖其他存储组件),完全自主实现了高可用,而且支持完整的SQL语法包括JOIN等,技术上有着明显优势。相比于hadoop体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。当前社区仍旧在迅猛发展中,相信后续会有越来越多好用的功能出现。
参考阅读
https://zhuanlan.zhihu.com/p/98135840
https://developer.aliyun.com/live/43846
相关文章:
clickhouse数据库简介,列式存储
clickhouse数据库简介 1、关于列存储 所说的行式存储和列式存储,指的是底层的存储形式,数据在磁盘上的真实存储,至于暴漏在上层的用户的使用是没有区别的,看到的都是一行一行的表格。 idnameuser_id1闪光10266032轨道物流10265…...

flask 发送ajax
前端 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body> <script src"https://cdn.lyshark.com/javascript/jquery/3.5.1/jquery.min.js"…...

Android Gradle 命令打包AAR
平台 Android Archive (AAR) 文件是一种特定于Android的存档文件格式,用于将Android库和资源打包成单个可重用的单元。AAR文件通常用于共享和分发Android库,以便其他Android应用项目可以轻松引用和使用这些库。 AAR文件是一种便捷的方式,用于…...
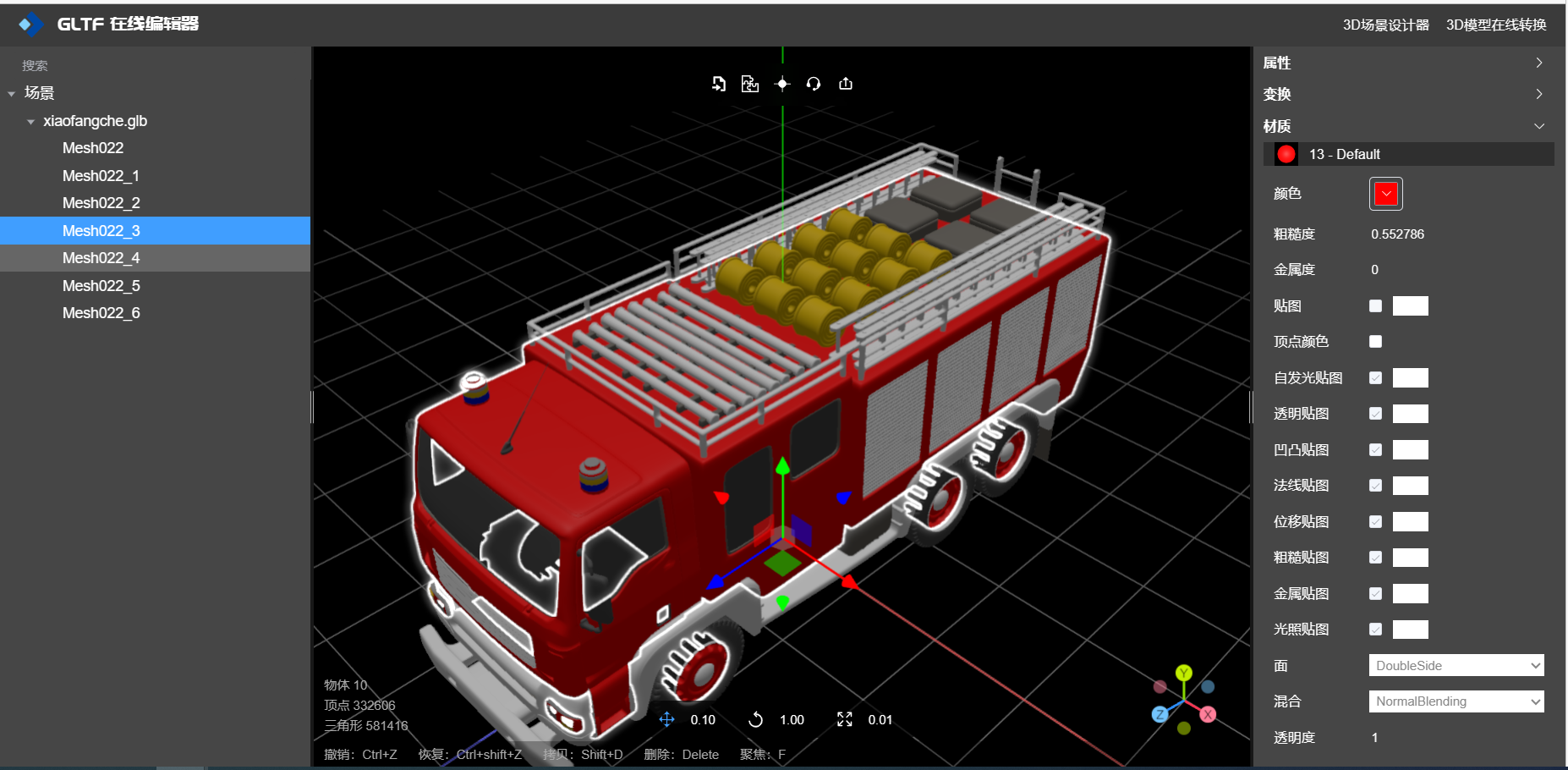
如何导出带有材质的GLB模型?
1、为什么要使用 GLB 模型? GLB格式(GLTF Binary)是一种用于存储和传输3D模型及相关数据的文件格式,具有以下优点和作用: 统一性:GLB是一种开放标准的3D文件格式,由Khronos Group制定和维护。它融合了GL…...

C/C++面试常见知识点
目录 C/C语言C内存分区malloc/free与new/delete的区别联合体联合体大小的计算 结构体对齐为什么需要结构体内存对齐 结构体与联合体的区别左值引用与右值引用指针和引用的区别迭代器失效static关键字在C语言的作用进程地址空间的分布内联函数 三大特性构造函数不能是虚函数析构…...

详细介绍数据结构-堆
计算机中的堆数据结构 什么是堆 在计算机科学中,堆(Heap)是一种重要的数据结构,它用于在动态分配时存储和组织数据。堆是一块连续的内存区域,其中每个存储单元(通常是字节)都与另一个存储单元…...
001flutter基础学习
flutter基础学习 参考:https://book.flutterchina.club/chapter1/flutter_intro.html Flutter是谷歌的移动UI框架跨平台: Linux,Android, IOS,Fuchsia原生用户界面:它是原生的,让我们体验更好,性能更好开源免费:完全开源,可以进行商用Flutter与主流框架的对比 Cor…...

leetCode 1143.最长公共子序列 动态规划 + 图解
此题我的往期文章推荐: leetCode 1143.最长公共子序列 动态规划 滚动数组-CSDN博客https://blog.csdn.net/weixin_41987016/article/details/133689692?spm1001.2014.3001.5501leetCode 1143.最长公共子序列 一步步思考动态规划 优化空间复杂度_呵呵哒(…...

解密人工智能:KNN | K-均值 | 降维算法 | 梯度Boosting算法 | AdaBoosting算法
文章目录 一、机器学习算法简介1.1 机器学习算法包含的两个步骤1.2 机器学习算法的分类 二、KNN三、K-均值四、降维算法五、梯度Boosting算法和AdaBoosting算法六、结语 一、机器学习算法简介 机器学习算法是一种基于数据和经验的算法,通过对大量数据的学习和分析&…...
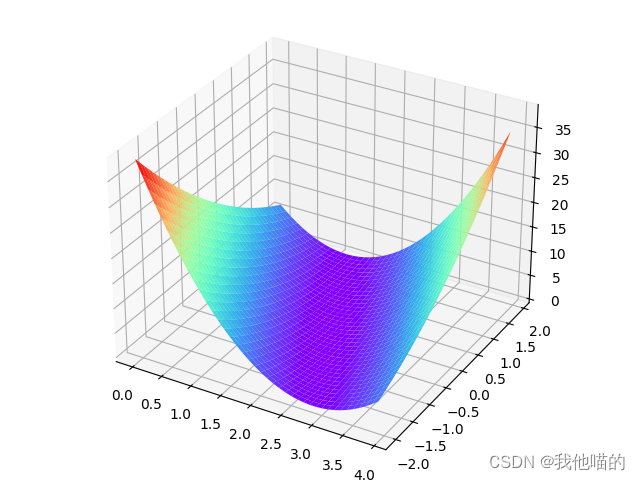
Python深度学习实践
线性模型 课程 import numpy as np import matplotlib.pyplot as plt x_data[1.0,2.0,3.0] y_data[2.0,4.0,6.0] #前馈函数 def forward(x):return x*w #损失函数 def loss(x,y):y_predforward(x)return (y_pred-y)*(y_pred-y) w_list[] mse_list[] for w in np.arange(0.0,4…...
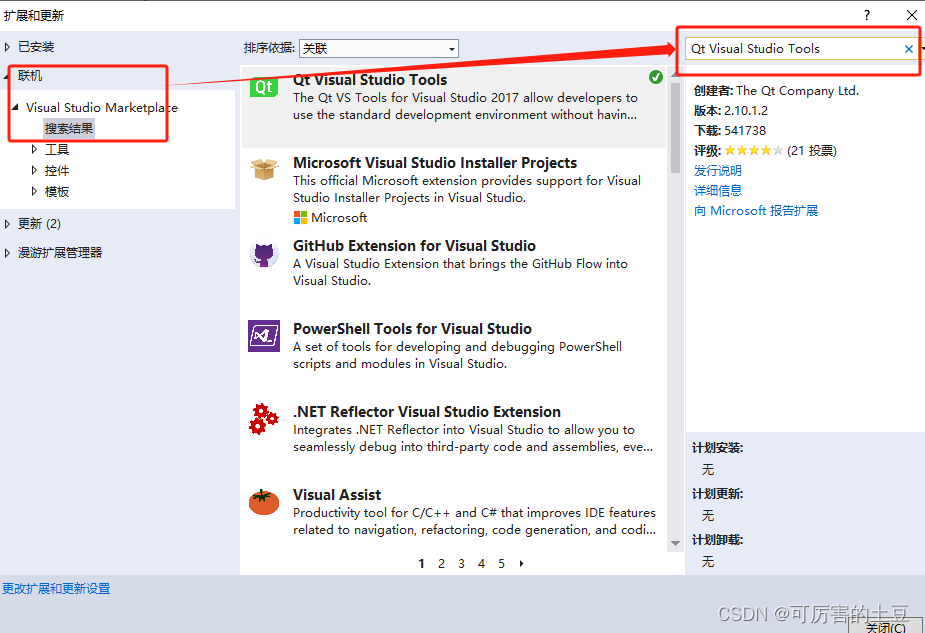
VS2017+QT+PCL环境配置
前言: 最近自己再弄一下小项目中需要用到pcl来开发点云的显示,但是却遇到很多坑,所以记录下来分析给知音人。 避雷:由于vtk和pcl之间有版本以来关系,但是安装过程是不变的。 选择对应的版本参考如下安装: pcl1.8.1依赖vtk版本7.1.1;pcl1.9.1至pcl1.12.0依赖vtk最低版本为…...
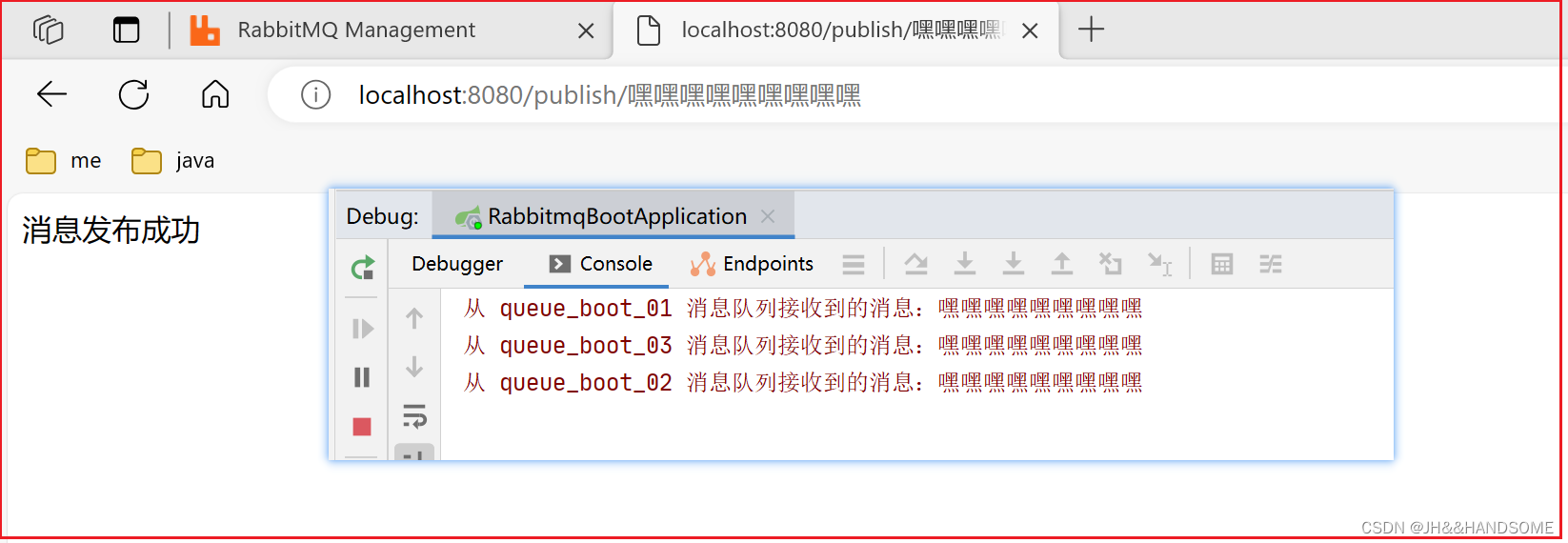
207、SpringBoot 整合 RabbitMQ 实现消息的发送 与 接收(监听器)
目录 ★ 发送消息★ 创建队列的两种方式代码演示需求1:发送消息1、ContentUtil 先定义常量2、RabbitMQConfig 创建队列的两种方式之一:配置式:问题: 3、MessageService 编写逻辑PublishController 控制器application.properties 配…...
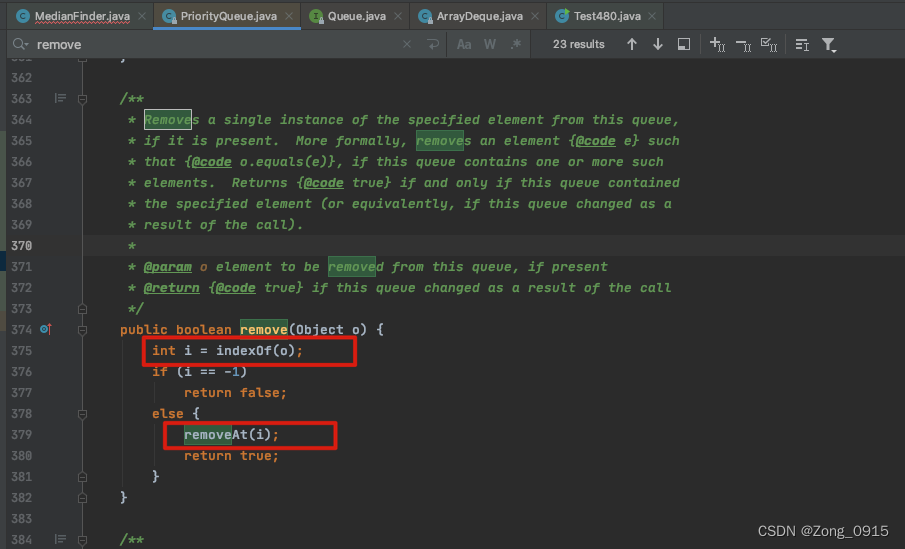
想要精通算法和SQL的成长之路 - 滑动窗口和大小根堆
想要精通算法和SQL的成长之路 - 滑动窗口和大小根堆 前言一. 大小根堆二. 数据流的中位数1.1 初始化1.2 插入操作1.3 完整代码 三. 滑动窗口中位数3.1 在第一题的基础上改造3.2 栈的remove操作 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 大小根堆 先来说下大小根堆是什…...
Python算法练习 10.15
leetcode 2130 链表的最大孪生和 在一个大小为 n 且 n 为 偶数 的链表中,对于 0 < i < (n / 2) - 1 的 i ,第 i 个节点(下标从 0 开始)的孪生节点为第 (n-1-i) 个节点 。 比方说,n 4 那么节点 0 是节点 3 的孪…...

智能防眩目前照灯系统控制器ADB
经纬恒润的自适应远光系统—— ADB(Adaptive Driving Beam) 是一种能够根据路况自适应变换远光光型的智能远光控制系统。根据本车行驶状态、环境状态以及道路车辆状态,ADB 系统自动为驾驶员开启或退出远光。同时,根据车辆前方视野…...
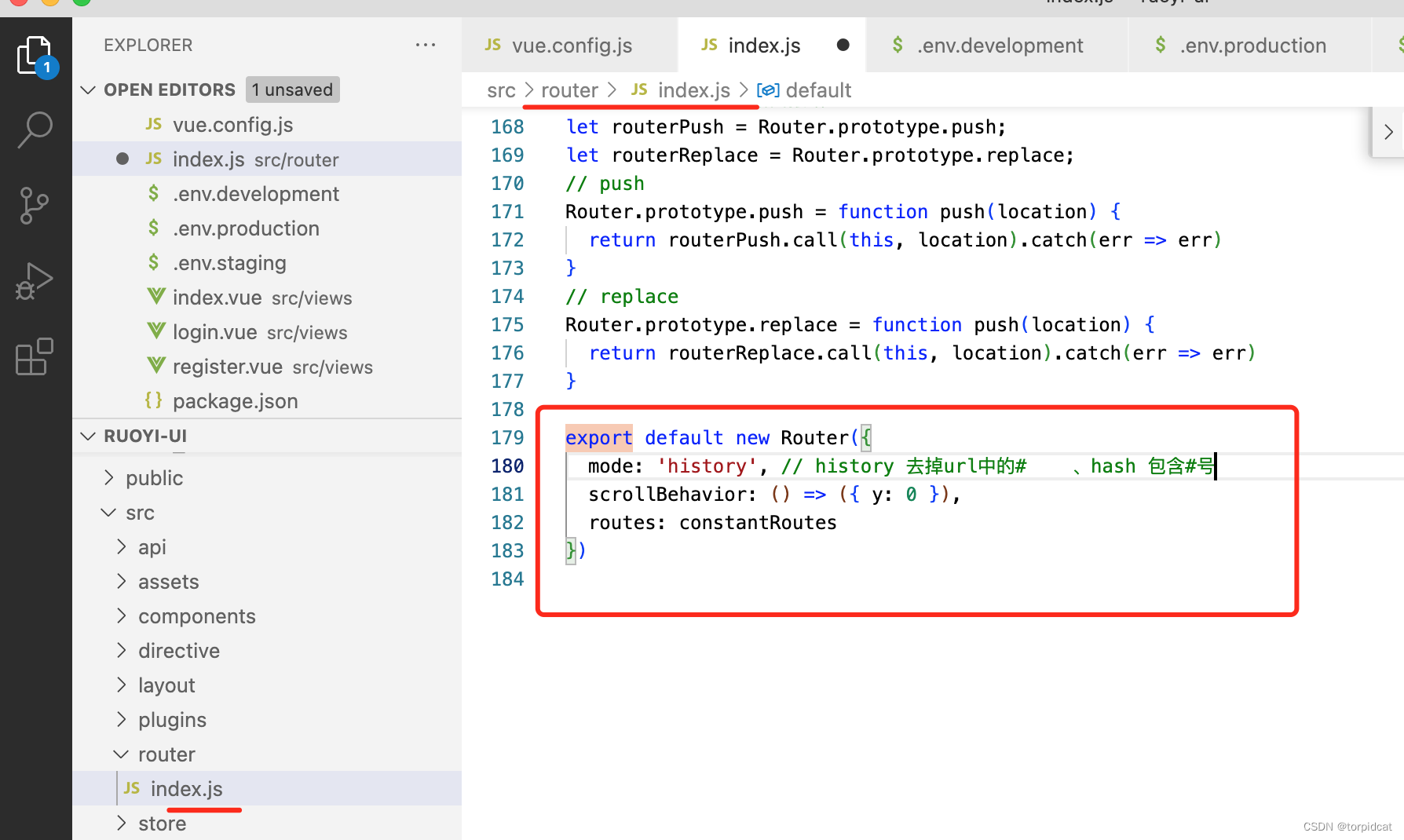
若依 ruoyi 路径 地址 # 井号去除
export default new Router({mode: history, // history 去掉url中的# 、hash 包含#号scrollBehavior: () > ({ y: 0 }),routes: constantRoutes })...
Elasticsearch 和 Arduino:一起变得更好!
作者:Enrico Zimuel 使用 Arduino IoT 设备与 Elasticsearch 和 Elastic Cloud 进行通信的简单方法 在 Elastic,我们不断寻找简化搜索体验的新方法,并开始关注物联网世界。 来自物联网的数据收集可能非常具有挑战性,尤其是当我们…...

基于Ubuntu环境Git 服务器搭建及使用
多人合作开发的时候 常常会需要使用代码管理平台,保持代码一致和解决冲突。在工作中我使用过SVN和TFS,本文说明另外一种平台,Git,下面是基于Ubuntu环境安装并简单使用Git服务器。 确认安装git apt install git levilevi-ThinkPa…...
【quartus13.1/Verilog】swjtu西南交大:计组课程设计
实验目的: 通过学习简单的指令系统及其各指令的操作流程,用 Verilog HDL 语言实 现简单的处理器模块,并通过调用存储器模块,将处理器模块和存储器模块连接形成简 化的计算机核心部件组成的系统。 二. 实验内容 1. 底层用 Verilog…...

基于springboot的网上点餐系统论文开题报告
一、选题背景 随着互联网和移动互联网技术的快速发展,网上点餐成为了人们越来越喜欢的一种点餐方式。一些具有创新意识的餐厅也开始逐渐尝试利用互联网技术来提升用户的点餐体验。因此,开发一个基于Spring Boot的网上点餐系统就显得非常必要和重要。 二…...

MinerU智能文档理解镜像:财务报表自动识别实战体验
MinerU智能文档理解镜像:财务报表自动识别实战体验 1. 引言:财务文档处理的痛点与机遇 在财务工作中,我们经常需要处理各种格式的财务报表——PDF扫描件、Excel截图、纸质文档照片等。传统的手工录入方式不仅效率低下,还容易出错…...

8-Bit美学不妥协性能|像素剧本圣殿UI渲染与LLM推理资源隔离方案
8-Bit美学不妥协性能|像素剧本圣殿UI渲染与LLM推理资源隔离方案 1. 项目概述 像素剧本圣殿(Pixel Script Temple)是一款专为剧本创作者设计的AI辅助工具,基于Qwen2.5-14B-Instruct大模型深度微调开发。它将高性能AI推理能力与独…...

【数据结构】数组与特殊矩阵
数据结构的学习中,数组与特殊矩阵是基础且核心的内容。它们不仅是程序设计中最常用的线性结构,更是处理复杂矩阵运算的基础。本文将结合解析与真题,带你彻底搞懂数组的存储方式和特殊矩阵的压缩存储技巧。一、一维数组与二维数组:…...

go-zero v1.10.1 更新解析:JSON5 配置正式支持 Redis 通用命令 Do DoCtx 上线 Go 1.24 升级与 core/codec 关键安全修复全梳理
一、版本总览:go-zero v1.10.1,微服务框架的又一次关键迭代 2026年3月28日,国产高性能Go微服务框架go-zero正式发布v1.10.1版本。作为一次补丁式更新,该版本并非简单的问题修复,而是集新功能拓展、核心安全加固、底层依…...

SiameseUIE多任务统一Schema设计:一套定义覆盖NER/关系/事件/情感
SiameseUIE多任务统一Schema设计:一套定义覆盖NER/关系/事件/情感 1. 引言:信息抽取的“瑞士军刀” 想象一下,你手头有一堆杂乱无章的中文文档——可能是新闻稿、用户评论、技术报告或者客服对话。老板让你快速从中找出所有提到的人名、公司…...

抖音批量下载神器:免费一键收藏创作者全部作品
抖音批量下载神器:免费一键收藏创作者全部作品 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音…...
)
RTX3070 + CUDA 11.0 实战:手把手教你从零搭建 PointNet.pytorch 环境(附常见报错解决)
RTX3070 CUDA 11.0 实战:手把手教你从零搭建 PointNet.pytorch 环境(附常见报错解决) 当你手握一块RTX3070显卡,想要复现PointNet这一经典点云处理网络时,是否曾被环境配置的各种坑绊住脚步?本文将带你避开…...

威纶通宏指令实战:从零构建中文输入与智能配方检索系统
1. 威纶通触摸屏的中文输入困境与破解之道 第一次接触威纶通中低端触摸屏时,我就被它缺乏中文输入支持的问题给难住了。当时接了个食品包装机的项目,客户要求操作界面必须支持中文输入,方便工人记录生产批号和产品信息。市面上常见的中高端HM…...

告别计算瓶颈:手把手教你用PyTorch实现ECCV 2024的FFCM图像去雨模块
突破计算效率边界:PyTorch实战ECCV 2024 FFCM图像去雨核心模块 雨滴干扰是计算机视觉领域长期存在的挑战,传统基于空间域的方法往往需要消耗大量计算资源。ECCV 2024提出的FFCM(Fused Fourier Convolution Mixer)模块通过巧妙融合…...

避坑指南:Unreal导航网格NavMesh生成与Agent属性设置的5个常见误区
Unreal引擎导航系统避坑指南:NavMesh生成与Agent配置的5个关键误区 在Unreal引擎中构建可靠的AI寻路系统时,许多开发者常陷入相似的陷阱。当AI角色频繁卡在门槛边缘、拒绝攀爬斜坡或选择匪夷所思的绕路路线时,问题往往不在于代码逻辑…...