计算机毕设 基于大数据的社交平台数据爬虫舆情分析可视化系统
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- **实现功能**
- **可视化统计**
- **web模块界面展示**
- 3 LDA模型
- 4 情感分析方法
- **预处理**
- 特征提取
- 特征选择
- 分类器选择
- 实验
- 5 部分核心代码
- 6 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据的社交平台数据爬虫舆情分析可视化系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
1 课题背景
基于Python的社交平台大数据挖掘及其可视化。
2 实现效果
实现功能
- 实时热点话题检测
- 情感分析
- 结果可视化
- Twitter数据挖掘平台的设计与实现
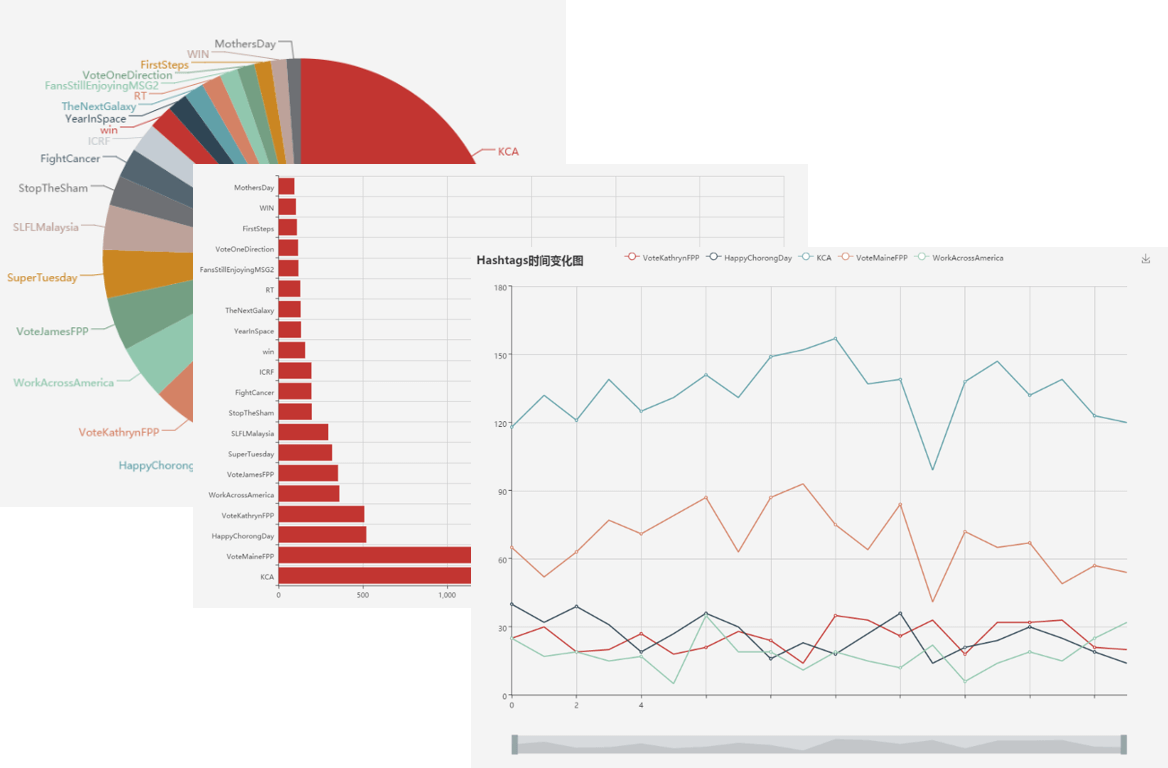
可视化统计
Hashtag统计
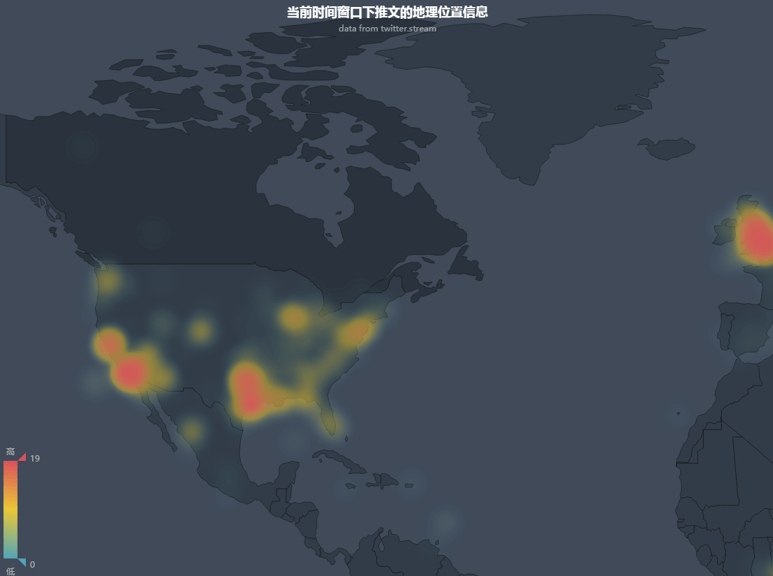
地理位置信息的可视化
话题结果可视化
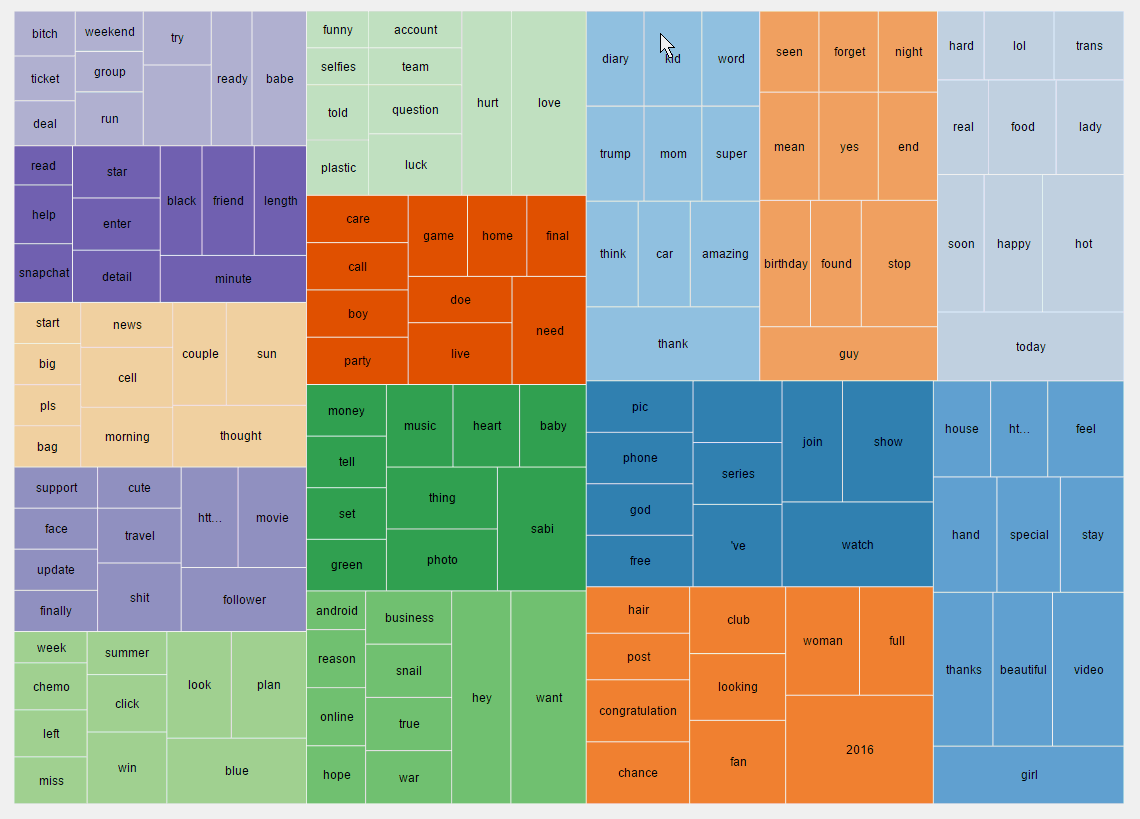
矩阵图
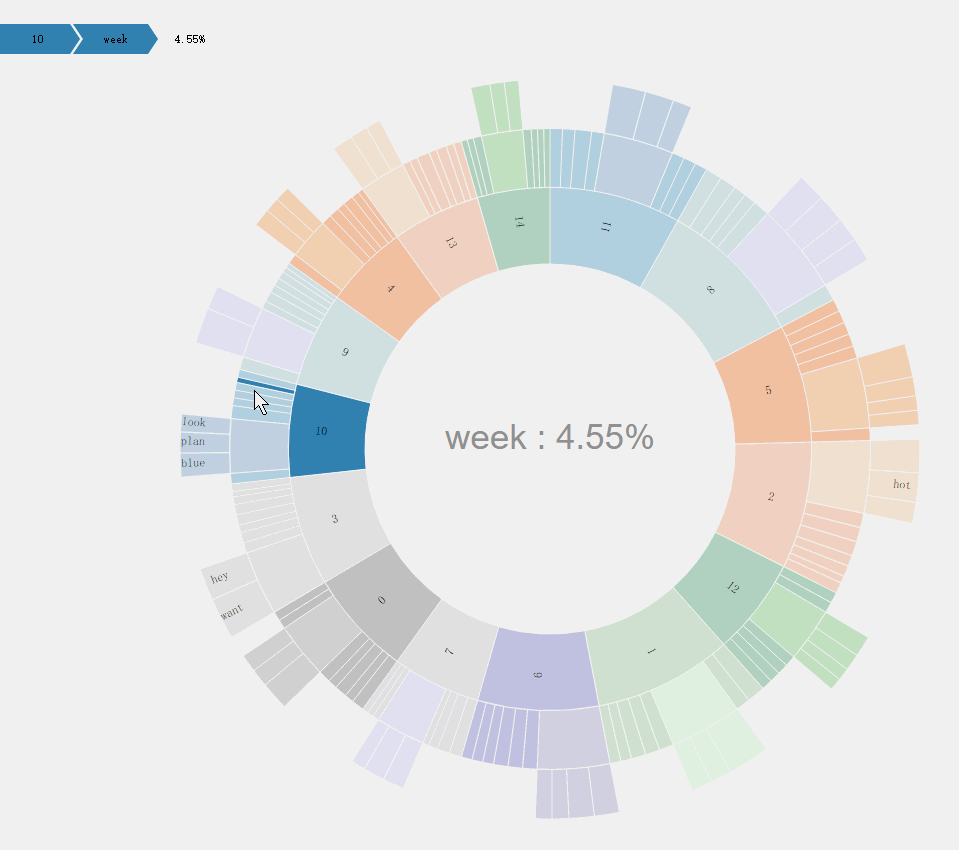
旭日图
情感分析的可视化
web模块界面展示
3 LDA模型
2003年,D.Blei等人提出了广受欢迎的LDA(Latentdirichlet allocation)主题模型[8]。LDA除了进行主题的分析外,还可以运用于文本分类、推荐系统等方面。
LDA模型可以描述为一个“上帝掷骰子”的过程,首先,从主题库中随机抽取一个主题,该主题编号为K,接着从骰子库中拿出编号为K的骰子X,进行投掷,每投掷一次,就得到了一个词。不断的投掷它,直到到达预计的文本长度为止。简单的说,这一过程就是“随机的选择某个主题,然后从该主题中随机的选择词语”。按照之前的描述,一篇文档中词语生成的概率为:

可以用矩阵的乘法来表示上述的过程:
回到LDA模型来说,LDA模型的输入是一篇一篇用BOW(bag of words)表示的文档,即用该文档中无序的单词序列来表示该文档(忽略文档中的语法和词语的先后关系)。LDA的输出是每篇文档的主题分布矩阵和每个主题下的单词分布矩阵。简而言之,LDA主题模型的任务就是已知左边的矩阵,通过一些方法,得到右边两个小矩阵。这里的“一些方法”即为LDA采样的方法,目前最主要的有两种,一种是变分贝叶斯推断(variationalBayes, VB),另一种叫做吉布斯采样(Gibbs Sampling),其中吉布斯采样也被称为蒙特卡洛马尔可夫 (Markov Chain Monte Carlo,MCMC)采样方法。
总的来说,MCMC实现起来更加简单方便,而VB的速度比MCMC来得快,研究表明他们具有差不多相同的效果。所以,对于大量的数据,采用VB是更为明智的选择。
4 情感分析方法
本文采用的情感分析可以说是一个标准的机器学习的分类问题。目标是给定一条推文,将其分为正向情感、负向情感、中性情感。
预处理
- POS标注:CMU ArkTweetNLP
- 字母连续三个相同:替换 “coooooooool”=>“coool”
- 删除非英文单词
- 删除URL
- 删除@:删除用户的提及@username
- 删除介词、停止词
- 否定展开:将以"n’t"结尾的单词进行拆分,如"don’t" 拆分为"do not",这里需要注意对一些词进行特殊处理,如"can’t"拆分完之后的结果为"can not",而不是"ca not"。
- 否定处理:从否定词(如shouldn’t)开始到这个否定词后的第一个标点(.,?!)之间的单词,均加入_NEG后缀。如perfect_NEG。 “NEG”后缀
特征提取
文本特征
-
N-grams
- 1~3元模型
- 使用出现的次数而非频率来表示。不仅是因为使用是否出现来表示特征有更好的效果[16],还因为Twitter的文本本身较短,一个短语不太可能在一条推文中重复出现。
-
感叹号问号个数
- 在句子中的感叹号和问号,往往含有一定的情感。为此,将它作为特征。
-
字母重复的单词个数
- 这是在预处理中对字母重复三次以上单词进行的计数。字母重复往往表达了一定的情感。
-
否定的个数
- 否定词出现后,句子的极性可能会发生翻转。为此,把整个句子否定的个数作为一个特征
-
缩写词个数等
-
POS 标注为[‘N’, ‘V’, ‘R’, ‘O’, ‘A’] 个数(名词、动词、副词、代词、形容词)
-
词典特征(本文使用的情感词典有:Bing Lius词库[39]、MPQA词库[40]、NRC Hashtag词库和Sentiment140词库[42]、以及相应的经过否定处理的词库[45])
- 推文中的单词在情感字典个数 (即有极性的单词个数)
- 推文的 总情感得分:把每个存在于当前字典单词数相加,到推文的 总情感得分:把每个存在于当前 - 字典单词数相加,到推文的 总情感得分:把每个存在于当前字典单词数相加,到推文总分,这个数作为一特征。
- 推文中单词最大的正向情感得分和负。
- 推文中所有正向情感的单词分数 和以及 所有负向情感单词的分数和。
- 最后一个词的分数
-
表情特征
- 推文中正向 情感 和负向的表情个数
- 最后一个表情的极性是 否为正向
特征选择
本文 特征选择主要是针对于 N-grams 特征 的,采用方法如下:
设定min_df(min_df>=0)以及threshold(0 <= threshold <= 1)
对于每个在N-grams的词:
统计其出现于正向、负向、中性的次数,得到pos_cnt, neg_cnt, neu_cnt,以及出现总数N,然后分别计算
pos = pos_cnt / N
neg = neg_cnt / N
neu = neu_cnt / N
对于 pos,neg,neu中任一一个大于阈值threshold 并且N > min_df的,保留该词,否则进行删除。
上述算法中滤除了低频的词,因为这可能是一些拼写错误的词语;并且,删除了一些极性不那么明显的词,有效的降低了维度。
分类器选择
在本文中,使用两个分类器进行对比,他们均使用sklearn提供的接口 。第一个分类器选用SVM线性核分类器,参数设置方面,C = 0.0021,其余均为默认值。第二个分类器是Logistic Regression分类器,其中,设置参数C=0.01105。
在特征选择上,min_df=5, threshold=0.6。
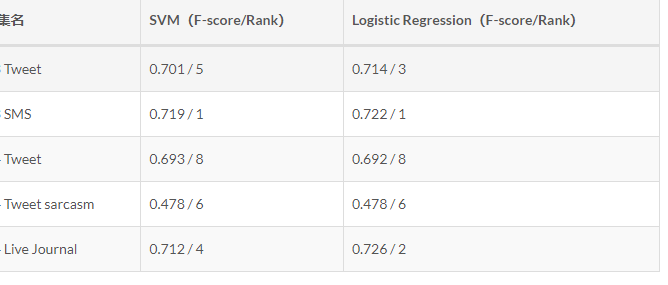
实验
- SemEval(国际上的一个情感分析比赛)训练数据和测试数据
- 评价方法采用F-score
- 对比SemEval2016结果如下
测试集名
5 部分核心代码
import json
from django.http import HttpResponse
from django.shortcuts import render
from topic.models.TopicTrendsManager import TopicTrendsManager
from topic.models.TopicParameterManager import TopicParameterManagerdef index(request):return render(request, 'topic/index.html')# TODO 检查参数的合法性, and change to post method
def stream_trends(request):param_manager = TopicParameterManager(request.GET.items())topic_trends = TopicTrendsManager(param_manager)res = topic_trends.get_result(param_manager)return HttpResponse(json.dumps(res), content_type="application/json")def stop_trends(request):topic_trends = TopicTrendsManager(None)topic_trends.stop()res = {"stop": "stop success"}return HttpResponse(json.dumps(res), content_type="application/json")def text(request):return render(request, 'topic/visualization/result_text.html')def bubble(request):return render(request, 'topic/visualization/result_bubble.html')def treemap(request):return render(request, 'topic/visualization/result_treemap.html')def sunburst(request):return render(request, 'topic/visualization/result_sunburst.html')def funnel(request):return render(request, 'topic/visualization/result_funnel.html')def heatmap(request):return render(request, 'topic/visualization/result_heatmap.html')def hashtags_pie(request):return render(request, 'topic/visualization/result_hashtags_pie.html')def hashtags_histogram(request):return render(request, 'topic/visualization/result_hashtags_histogram.html')def hashtags_timeline(request):return render(request, 'topic/visualization/result_hashtags_timeline.html')
6 最后
相关文章:
计算机毕设 基于大数据的社交平台数据爬虫舆情分析可视化系统
文章目录 0 前言1 课题背景2 实现效果**实现功能****可视化统计****web模块界面展示**3 LDA模型 4 情感分析方法**预处理**特征提取特征选择分类器选择实验 5 部分核心代码6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕…...

conda取消自动进入base环境
安装conda后取消命令行前出现的base,则默认进入了conda环境,如果想取消每次启动自动激活conda的基础环境。 方法一 每次在命令行通过conda deactivate退出base环境回到系统自带的环境 如果再进入的话: conda deactivate 方法二 1&#…...

【文生图】Stable Diffusion XL 1.0模型Full Fine-tuning指南(U-Net全参微调)
文章目录 前言重要教程链接以海报生成微调为例总体流程数据获取POSTER-TEXTAutoPosterCGL-DatasetPKU PosterLayoutPosterT80KMovie & TV Series & Anime Posters 数据清洗与标注模型训练模型评估生成图片样例宠物包商品海报护肤精华商品海报 一些TipsMata:…...

STM32笔记—DMA
目录 一、DMA简介 二、DMA主要特性 三、DMA框图 3.1 DMA处理 3.2 仲裁器 3.3 DMA通道 扩展: 断言: 枚举: 3.4 可编程的数据传输宽度、对齐方式和数据大小端 3.5 DMA请求映像 四、DMA基本结构 4.1 DMA_Init配置 4.2 实现DMAADC扫描模式 实现要求…...
机器学习概论
一、机器学习概述 1、机器学习与人工智能、深度学习的关系 人工智能:机器展现的人类智能机器学习:计算机利用已有的数据(经验),得出了某种模型,并利用此模型预测未来的一种方法。深度学习:实现机器学习的一种技术 2…...
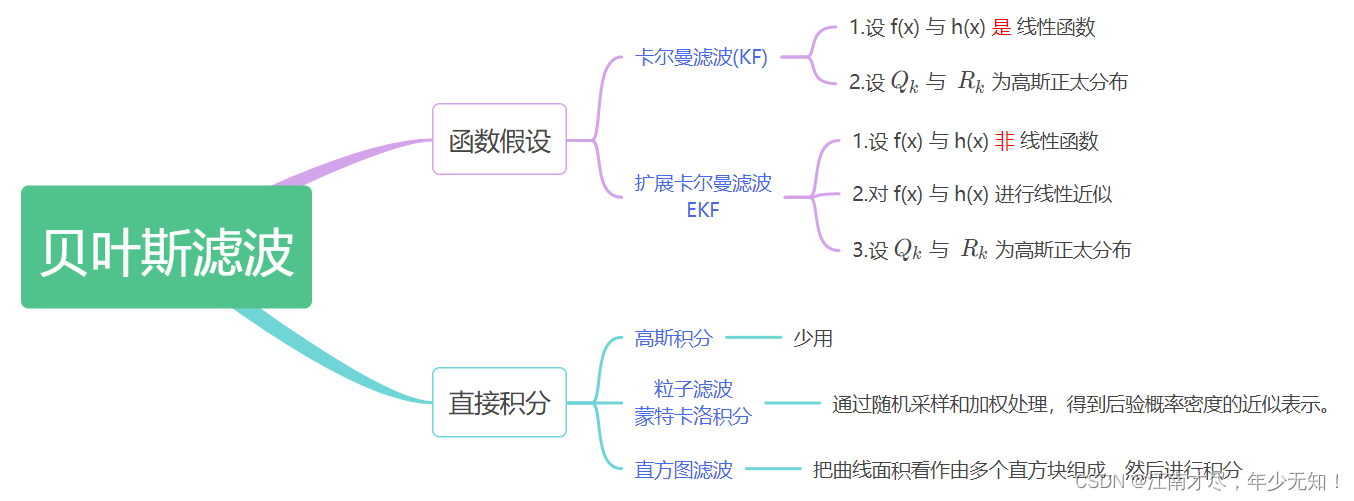
卡尔曼家族从零解剖-(04)贝叶斯滤波→细节讨论,逻辑梳理,批量优化
讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解的 卡尔曼家族从零解剖 链接 :卡尔曼家族从零解剖-(00)目录最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/133846882 文末正下方中心提供了本人 联系…...
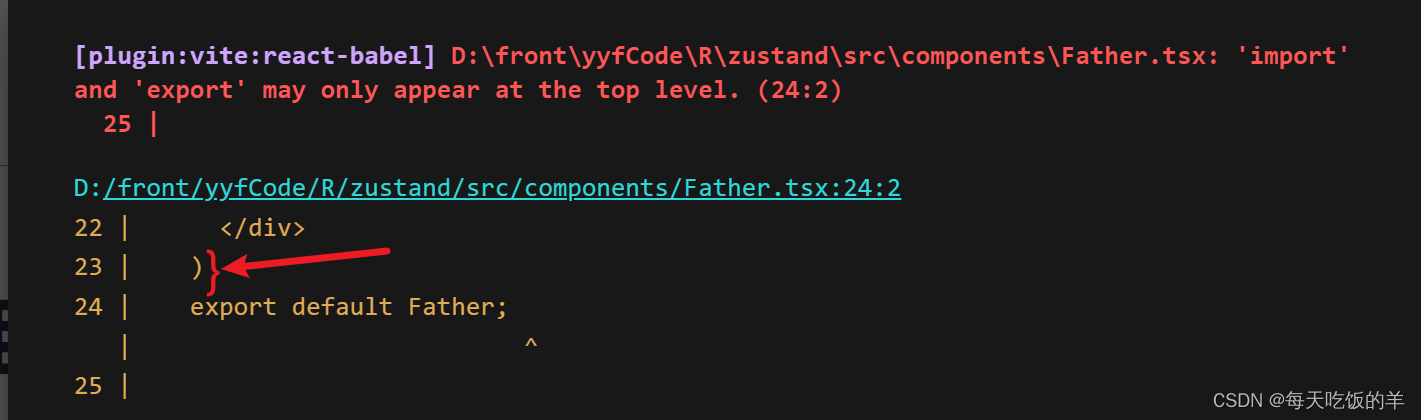
小菜React
1、Unterminated regular expression literal, 对于函数就写.ts,有dom元素就写.tsx 2、 The requested module /src/components/setup.tsx?t1699255799463 does not provide an export named Father export default useStore默认导出的钩子,组件引入的…...

新手用mac电脑,对文件的疑问和gpt回应
macOs系统安装软件的疑问 所有问题mac系统文件结构我用mac安装软件,不用像windows一样创建文件夹吗只能安装到Applications文件夹吗安装程序的指南和提供的安装选项是什么软件安装在Applications下的/appName文件夹,它的所有数据都会在该文件夹吗如果卸载…...

LeetCode|动态规划|392. 判断子序列、115. 不同的子序列、 583. 两个字符串的删除操作
目录 一、392. 判断子序列 1.题目描述 2.解题思路 3.代码实现(双指针解法) 4.代码实现(动态规划解法) 二、115. 不同的子序列 1.题目描述 2.解题思路 3.代码实现(C语言版本) 4.代码实现(C版本) …...

vscode 阅读 android以及kernel 源码
在Ubuntu系统中安装vscode 参考文档: https://blog.csdn.net/m0_57368670/article/details/127184424 1, 下载vscode https://code.visualstudio.com 2, 安装vscode $ sudo dpkg -i code_1.78.1-1683194560_amd64.deb 3, 打开vscode $ code vscode 阅读 android…...

Intel oneAPI笔记(3)--jupyter官方文档(SYCL Program Structure)学习笔记
前言 本文是对jupyterlab中oneAPI_Essentials/02_SYCL_Program_Structure文档的学习记录,包含对Device Selector、Data Parallel Kernel、Host Accessor、Buffer Destruction、的介绍,最后还有一个小关于向量(Vector)加法的实例 …...

verilog——移位寄存器
在Verilog中,你可以使用移位寄存器来实现数据的移位操作。移位寄存器是一种常用的数字电路,用于将数据向左或向右移动一个或多个位置。这在数字信号处理、通信系统和其他应用中非常有用。以下是一个使用Verilog实现的简单移位寄存器的示例: m…...

C++11 多线程学习笔记
1. thread — 线程篇 所需头文件:<thread> 1.1 构造函数 // 1 默认构造函数 thread() noexcept; // 2 移动构造函数,把other的所有权转移给新的thread对象,之后 other 不再表示执行线程。 thread( thread&& other ) noex…...
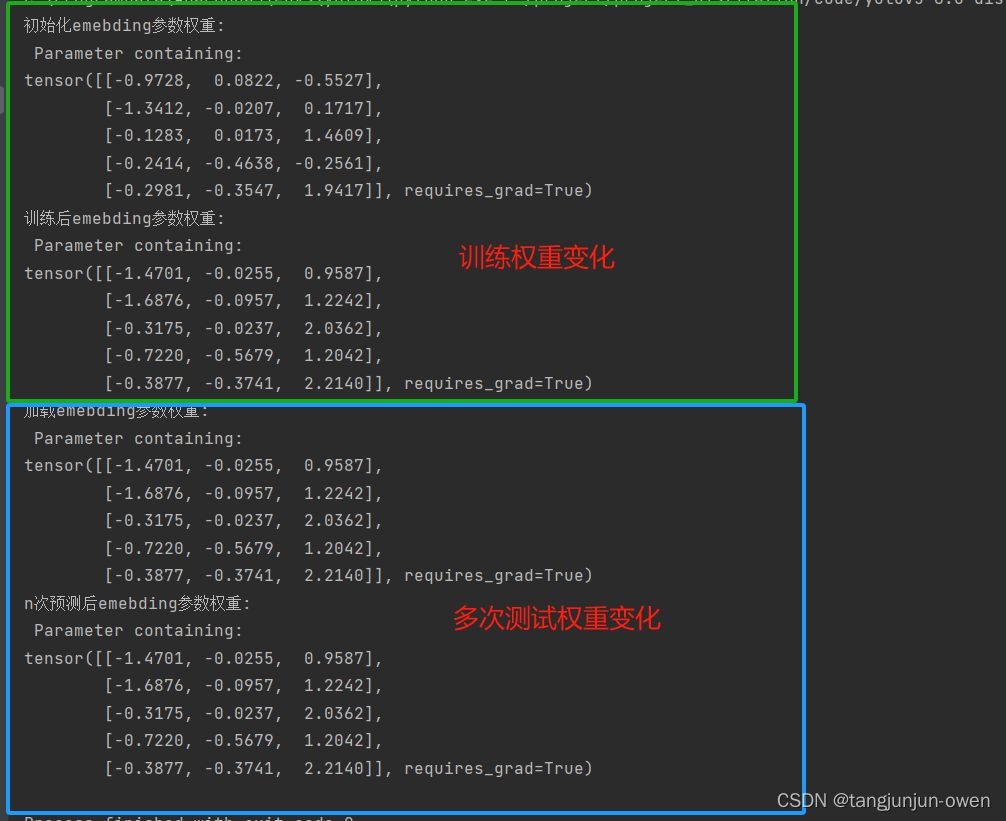
nn.embedding函数详解(pytorch)
提示:文章附有源码!!! 文章目录 前言一、nn.embedding函数解释二、nn.embedding函数使用方法四、模型训练与预测的权重变化探讨 前言 最近发现prompt工程(如sam模型),也有transform的detr模型等都使用了nn.Embedding函…...

gitee.com[0: xxx.xx.xxx.xx]: errno=Unknown error
git在提交或拉取代码的时候,遇到以下报错信息: Unable to connect to gitee.com[0: xxx.xx.xxx.xx]: errnoUnknown error 解决问题步骤: 1、找到自己的电脑上的git用户配置文件 文件位置位于:C:\Users\用户名\.gitconfig 比如我…...

bug: https://aip.baidubce.com/oauth/2.0/token报错blocked by CORS policy
还是跟以前一样,我们先看报错点:(注意小编这里是H5解决跨域的,不过解决跨域的原理都差不多) Access to XMLHttpRequest at https://aip.baidubce.com/oauth/2.0/token from origin http://localhost:8000 has been blo…...
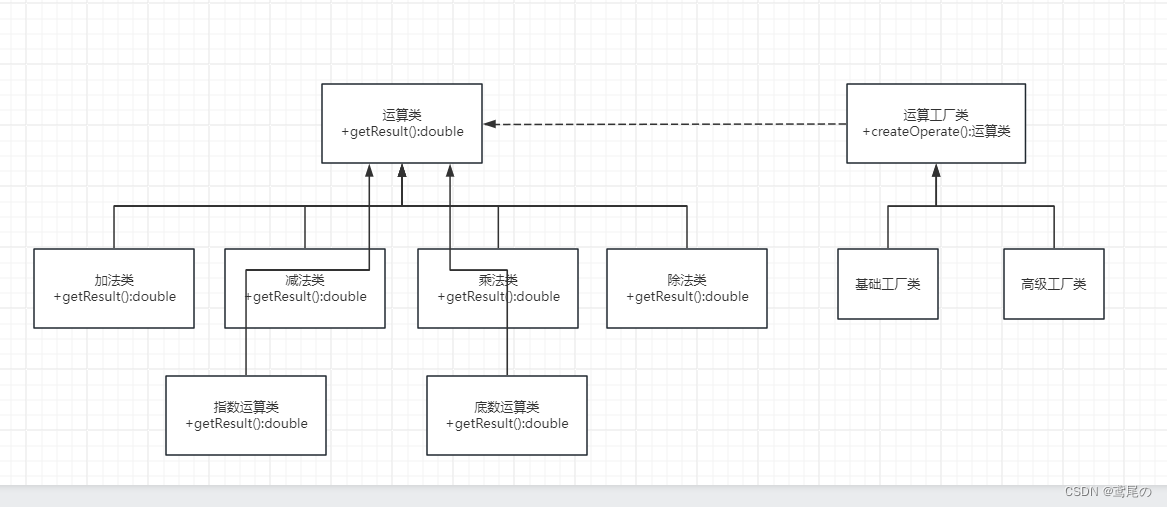
简单工厂VS工厂方法
工厂方法模式–制造细节无需知 前面介绍过简单工厂模式,简单工厂模式只是最基本的创建实例相关的设计模式。在真实情况下,有更多复杂的情况需要处理。简单工厂生成实例的类,知道了太多的细节,这就导致这个类很容易出现难维护、灵…...

使用VSCODE链接Anaconda
打代码还是在VSCODE里得劲 所以得想个办法在VSCODE里运行py文件 一开始在插件商店寻找插件 但是没有发现什么有效果的 幸运的是VSCODE支持自己选择Python的编译器 打开VSCODE 按住CtrlShiftP 输入Select Interpreter 如果电脑已经安装上了Python的环境 VSCODE会默认选择普通…...
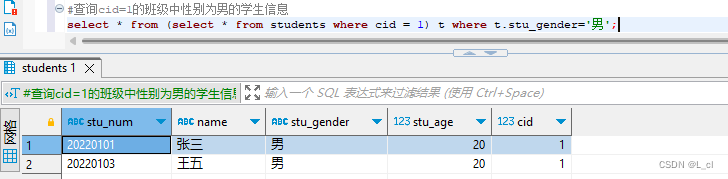
Mysql数据库 9.SQL语言 查询语句 连接查询、子查询
连接查询 通过查询多张表,用连接查询进行多表联合查询 关键字:inner join 内连接 left join 左连接 right join 右连接 数据准备 创建新的数据库:create database 数据库名; create database db_test2; 使用数据库:use 数据…...
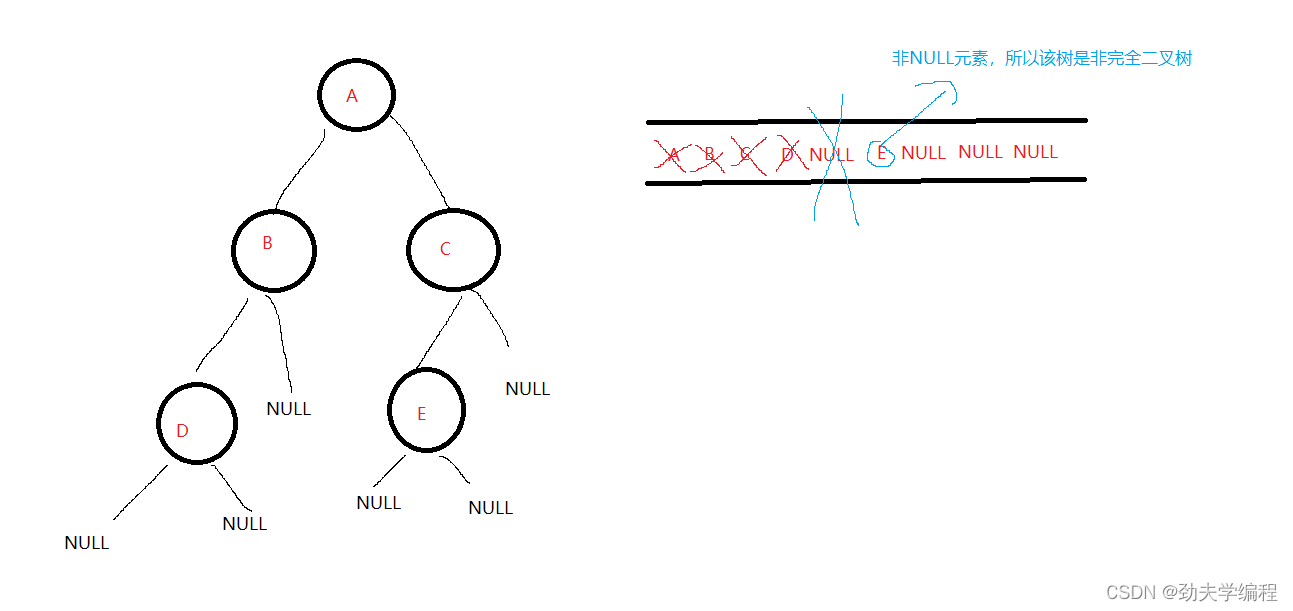
二叉树按二叉链表形式存储,试编写一个判别给定二叉树是否是完全二叉树的算法
完全二叉树:就是每层横着划过去是连起来的,中间不会断开 比如下面的左图就是完全二叉树 再比如下面的右图就是非完全二叉树 那我们可以采用层序遍历的方法,借助一个辅助队列 当辅助队列不空的时候,出队头元素,入队头…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

潮州东方轻奢风全屋高定找哪家
开篇引言根据《2026年中国全屋定制行业发展报告》,潮州市全屋定制市场规模同比增长38%,其中全屋高端定制细分市场同比增长52%。目前,潮州市家庭全屋定制需求占比72%,高端定制需求占比45%。为了帮助潮州市消费者选择合规、靠谱、差…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...