Elaticsearch学习
Elaticsearch
索引
1、索引创建
PUT /index_v1
{"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"aaa": {"type": "keyword","store": true}, "hhh": {"type": "keyword","store": true}}}
}
2、索引别名
person_info_v1为索引名称,person_info为索引要创建的别名
put /person_info_v1/_alias/person_info
查询语法
1、minimum_should_match
bool查询也可以用 minimum_should_match, 如果配置成数字 3, 则表示 查询关键词被分词器分成 3 个及其以下的term 时, they are all required(条件都需要满足才能符合查询要求)
对于被analyzer分解出来的每一个term都会构造成一个should的bool query的查询,每个term变成一个term query子句。 例如"query": “how not to be”,被解析成: { “bool”: { “should”: [ { “term”: { “body”: “how”}}, { “term”: { “body”: “not”}}, { “term”: { “body”: “to”}}, { “term”: { “body”: “be”}} ],
2、查询分词效果
anlyzer后面是分词器,有ik_smart,ik_max_word等,text后面是想要查看分词效果的词
POST _analyze
{"analyzer":"ik_max_word","text":"李四"}
3、must和should混合使用
must是数据库中AND的意思,should是数据库中OR的意思,使用的时候不能简单的QueryBuilders.boolQuery.must().should(),要向下面这样使用
QueryBuilders.boolQuery().must(QueryBuilders.termQuery("is_deleted", DELETE_FLAG)).must(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("person_name", keywordVal).operator(Operator.AND).analyzer("ik_max_word") ));
Operato.AND表示查询分词要和es中的索引都匹配上才行,比如索引中内容是
张三三,分词效果是张和三三,查询内容是张三,分词是张和三,那这个时候就查询不到结果,查询内容改成张三三,分词效果是张和三三,就和索引中的分词都匹配上了,可以查询出内容。这样做的原因是防止你输入张三的时候把李三也查出来。如果不显示的声明Operator.AND,那会默认使用Operator.OR,这样的话输入张三,就会把李三也查出来,因为张三分词是张和三,只要三匹配了,就会查出来
4、查询索引中数据大小
GET /my-index-000001/_stats
5、字段匹配度排序
比如有个person_name字段,正常查询的时候按照_score排序,查询张建的时候,张建建的分值比张建的分值大,导致排序的时候张建建排在张建之前,但是按照常理来说,张建应该排在张建建之前,这就涉及到es的分词器以及分值计算问题了
解决方法是在person_name字段中设置一个子字段,不分词
"person_name": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart","store": true,"index_options": "docs","fields": {"raw": { "type": "keyword", "store": true }}}
查询的时候,使用match_parse精确查询子字段并用boost设置较大的权重,使用match模糊查询person_name字段
查询语句
1、短语匹配
{"query": {"bool": {"should": [{"match_phrase": {"person_name.raw": {"query": "张建建","boost": 10}}},{"match": {"person_name": {"query": "张建建"}}}]}}
}
java代码
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.should(QueryBuilders.matchPhraseQuery("person_name.raw",keywordVal).boost(4));
queryBuilder.should(QueryBuilders.matchQuery("person_name", keywordVal).operator(Operator.AND).analyzer("ik_max_word"));
2、查询所有
/_search
{"query": {"match_all": {}}
}
3、查询数量
/_count
{"query": {"match_all": {}}
}
4、排序
{"query": {"match": {"ent_name": "杭州乾元"}},"sort": [{"est_date": {"order": "asc"}}]
}
5、nested查询
{"query": {"bool": {"filter": [{"nested": {"query": {"bool": {"filter": [{"term": {"clues.clue_id": {"value": "xxx","boost": 1}}}],"boost": 1}},"path": "clues","score_mode": "none","boost": 1}}],"boost": 1}}
}
6、字段+nested
{"query": {"bool": {"filter": [{"terms": {"_id": ["xxx"],"boost": 1}},{"nested": {"query": {"bool": {"filter": [{"terms": {"clues.clue_code": ["xxx"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "clues","ignore_unmapped": false,"score_mode": "none","boost": 1}}],"adjust_pure_negative": true,"boost": 1}}
}
7、nested字段为空条件查询
{"query": {"bool": {"must_not": [{"nested": {"path": "tags","query": {"exists": {"field": "tags"}}}}]}}
}
8、案件数据为空,但是线索不为空的数据
{"query": {"bool": {"filter": [{"bool": {"should": [{"bool": {"must_not": [{"exists": {"field": "case_type"}}],"adjust_pure_negative": true,"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},{"range": {"clue_num": {"from": "0","to": null,"include_lower": false,"include_upper": true,"boost": 1}}}]}}
}
删除
删除索引中的全部数据
POST /my_index/_delete_by_query
{"query": {"match_all": {}}
}
命令行删除:
curl -u elastic:'xxxx' -XPOST 'ip:port/medical_institution/_delete_by_query?refresh&slices=5&pretty' -H 'Content-Type: application/json' -d'{ "query": { "match_all": {} }}'
插入
POST /person_info_test_v1/_doc/
{"person_name": "张建芬"
}
更新
1、数据更新
(1)nested更新
POST http://ip:port/case_info/_update_by_query
{"script": {"source": "ctx._source.clues[0].clue_state = 2","lang": "painless"},"query": {"bool": {"filter": [{"nested": {"query": {"bool": {"filter": [{"term": {"clues.clue_id": {"value": "xxx","boost": 1}}}],"boost": 1}},"path": "clues","score_mode": "none","boost": 1}}],"boost": 1}}
}
(2)nested字段置空
{"script": {"source": "ctx._source.clues = []","lang": "painless"},"query": {"term": {"_id": "xxx"}}
}
(3)多条件更新
POST http://ip:port/case_info/_update_by_query
{"script": {"source": "ctx._source.obj_code = 'xxx'","lang": "painless"},"query": {"bool": {"filter": [{"term": {"case_type": "check_action"}},{"term": {"obj_code": "xxx"}}]}}
}
(4)数组(nested)字段更新
#更新为空的字段
{"script": {"source": "def tags= ctx._source.tags;def newTag=params.tagInfo; if (tags == null) { ctx._source.tags = params.tagInfo;}","lang": "painless","params": {"tagInfo": [{"tag_code": "case_xzcf_basic_0001","tag_value": "简易程序"},{"tag_code": "case_xzcf_basic_0002","tag_value": "立案阶段"},{"tag_code": "case_xzcf_basic_0003","tag_value": "无文书"}]}},"query": {"term": {"_id": "0e978d6afb74b52a322d7aa8fbfbddf8"}}
}
#将不为空的字段置为空
{"script": {"source": "def tags= ctx._source.tags;def newTag=params.tagInfo; ctx._source.tags = params.tagInfo;","lang": "painless","params": {"tagInfo": []}},"query": {"bool": {"must": [{"nested": {"path": "tags","query": {"exists": {"field": "tags"}}}}]}}
}
2、更新配置参数
PUT http://ip:port/case_info/_settings
{"refresh_interval": "1s"
}
访问
1、在linux中加密访问
#elastic是用户名,xxx是密码
curl ip:port -u elastic:'xxx'
2、ES健康状态查看
curl http://localhost:9200/_cat/health?v -u elastic:'xxx'
ES问题处理
一、数据插入失败
1、提示只读
] retrying failed action with response code: 403 ({"type"=>"cluster_block_exception", "reason"=>"index [person_info_v1] blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"})
解决方法:首先查看磁盘空间是否被占满了,如果磁盘空间够用,则执行以下语句,将索引只读状态置为false
/indexname/_settings PUT
{"index": {"blocks": {"read_only_allow_delete": "false"}}
}{"index": {"refresh_interval": "1s"}
}
2、cpu占用过高
在网页上输入以下地址
http://ip:port/_nodes/hotthreads
问题处理
一、数据插入失败
1、提示只读
] retrying failed action with response code: 403 ({"type"=>"cluster_block_exception", "reason"=>"index [person_info_v1] blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"})
解决方法:首先查看磁盘空间是否被占满了,如果磁盘空间够用,则执行以下语句,将索引只读状态置为false
/indexname/_settings PUT
{"index": {"blocks": {"read_only_allow_delete": "false"}}
}{"index": {"refresh_interval": "1s"}
}
2、cpu占用过高
在网页上输入以下地址
http://ip:port/_nodes/hotthreads
查询出的内容搜索cpu usage by thread即可
相关文章:

Elaticsearch学习
Elaticsearch 索引 1、索引创建 PUT /index_v1 {"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"aaa": {"type": "keyword","store&qu…...

【腾讯云云上实验室】向量数据库+LangChain+LLM搭建智慧辅导系统实践
目录 一、搭建智慧辅导系统——向量数据库实践指南1.1、创建向量数据库并新建集合1.2、使用 TKE 快速部署 ChatGLM1.3、部署 LangChain PyPDFVectorDB等组件1.4、配置知识库语料1.5、基于 VectorDB LLM 的智能辅导助手 二、LLM时代的次世代引擎——向量数据库2.1、向量数据库L…...

从0开始学习JavaScript--深入了解JavaScript框架
JavaScript框架在现代Web开发中扮演着关键角色,为开发者提供了丰富的工具和抽象层,使得构建复杂的、高性能的Web应用变得更加容易。本文将深入探讨JavaScript框架的核心概念、常见框架的特点以及它们在实际应用中的使用。 JavaScript框架的作用 JavaSc…...

【教3妹学编程-算法题】二叉树中的伪回文路径
3妹:好冷啊, 冻得瑟瑟发抖啦 2哥 : 又一波寒潮来袭, 外面风吹的呼呼的。 3妹:今天还有雨,2哥上班记得带伞。 2哥 : 好的 3妹:哼,不喜欢冬天,也不喜欢下雨天,要是我会咒语…...
快速上手Banana Pi BPI-M4 Zero 全志科技H618开源硬件开发开发板
Linux[编辑] 准备[编辑] 1. Linux镜像支持SD卡或EMMC启动,并且会优先从SD卡启动。 2. 建议使用A1级卡,至少8GB。 3. 如果您想从 SD 卡启动,请确保可启动 EMMC 已格式化。 4. 如果您想从 EMMC 启动并使用 Sdcard 作为存储,请确…...
Node.js入门指南(三)
目录 Node.js 模块化 介绍 模块暴露数据 导入模块 导入模块的基本流程 CommonJS 规范 包管理工具 介绍 npm cnpm yarn nvm的使用 我们上一篇文章介绍了Node.js中的http模块,这篇文章主要介绍Node.js的模块化,包管理工具以及nvm的使用。 Node…...

Leetcode—2824.统计和小于目标的下标对数目【简单】
2023每日刷题(三十九) Leetcode—2824.统计和小于目标的下标对数目 实现代码 class Solution { public:int countPairs(vector<int>& nums, int target) {int n nums.size();sort(nums.begin(), nums.end());int left 0, right left 1;i…...

【基础架构】part-2 可扩展性
文章目录 可扩展性(Scalability)2.1 水平扩展2.2 垂直扩展2.3 弹性扩展 三、可靠性(Reliability)3.1 容错机制3.2 错误处理和恢复策略3.3 监控和自动化运维 四、 安全性(Security)4.1 身份验证和授权4.2 加…...

[SWPUCTF 2021 新生赛]no_wakeup
直接赋值即可 $a ->admin admin; $a ->passwd wllm; 发现没有绕过,改成大于2的绕过__wakeup 这是因为PHP在反序列化时会检查序列化字符串的长度,如果长度小于等于2,则不会调用__wakeup()方法。...
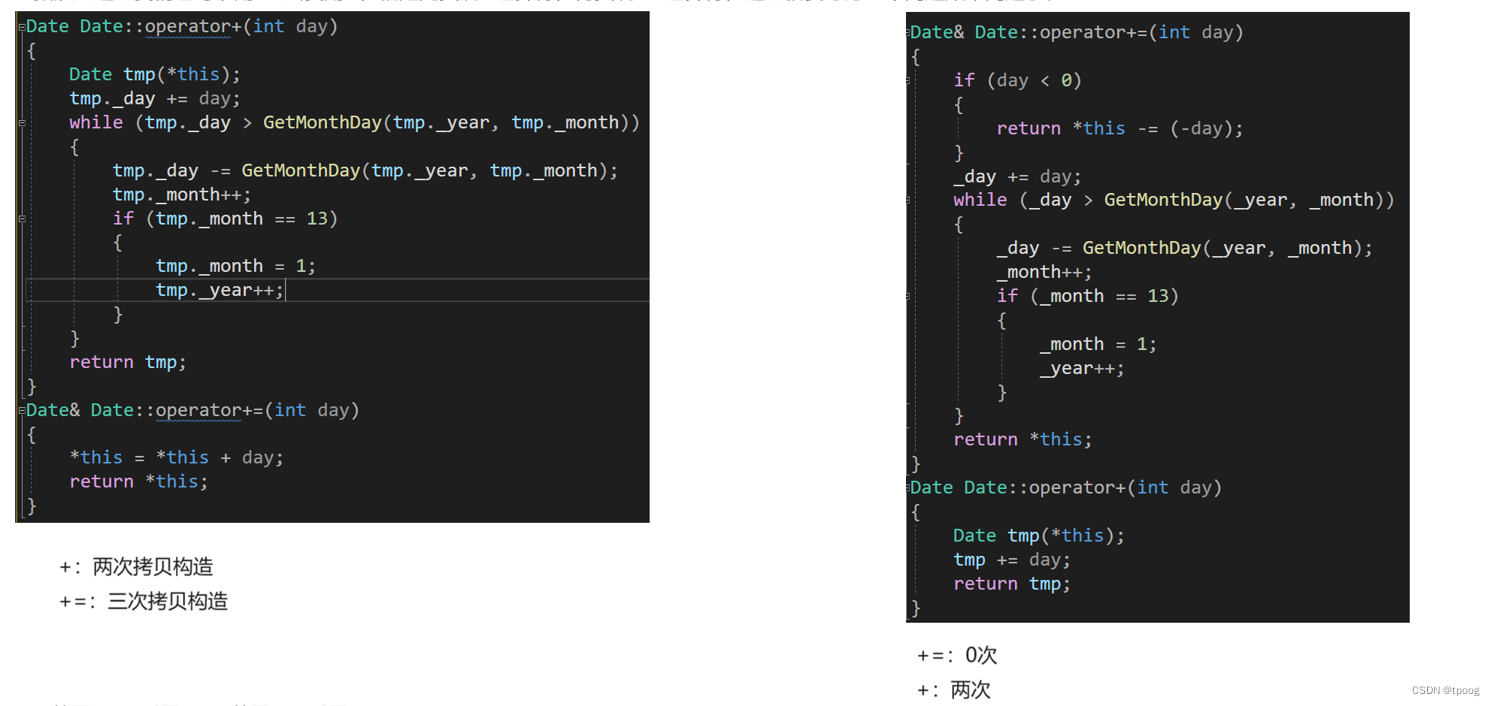
类和对象(3)日期类的实现
日期类的实现 一,声明二,函数成员定义2.1构造函数2.2获取月份天数2.3比较运算符2.3.1等于和大于2.3.2其他 2.4计算运算符2.4.1 &&2.4.2-&&- 2.5日期-日期 一,声明 class Date { public:Date(int year 1, int month 1, int…...

分布式篇---第五篇
系列文章目录 文章目录 系列文章目录前言一、你知道哪些限流算法?二、说说什么是计数器(固定窗口)算法三、说说什么是滑动窗口算法前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去…...
)
SpringMVC(二)
八、HttpMessageConverter HttpMessageConverter,报文信息转换器,将请求报文转换为Java对象,或将Java对象转换为响应报文 HttpMessageConverter提供了两个注解和两个类型:RequestBody,ResponseBody,Reque…...

kafka操作的一些坑
1.如果Offset Explorer能够检测到kafka中的数据,但是自己的kafka无法读取到 这个问题主要是由于kafka中的信息已经被消费掉了造成的 consumer.commitAsync();这里如果已经消费掉了kafka的信息,那么已经被消费掉的kafka数据就不会被再读取掉,…...

转录组学习第5弹-比对参考基因组
比对参考基因组 在构建文库的过程中需要将DNA片段化,因此测序得到的序列只是基因组的部分序列。为了确定测序reads在基因组上的位置,需要将reads比对回参考基因组上,这个步骤叫做比对,即文献中所提到的alignment或mapping。包括基…...
部署系列六基于nndeploy的深度学习 图像降噪unet部署
文章目录 1.直接在源代码demo中修改2. 如何修改呢?3. 修改 graph4. 总结 https://github.com/DeployAI/nndeploy https://nndeploy-zh.readthedocs.io/zh/latest/introduction/index.html 通过以上2个官方链接对nndeploy基本的使用方法应该有所了解了。 下面就是利用…...

使用 ClickHouse 做日志分析
原作:Monika Singh & Pradeep Chhetri 这是我们在 Monitorama 2022 上发表的演讲的改编稿。您可以在此处找到包含演讲者笔记的幻灯片和此处的视频。 当 Cloudflare 的请求抛出错误时,信息会记录在我们的 requests_error 管道中。错误日志用于帮助解…...
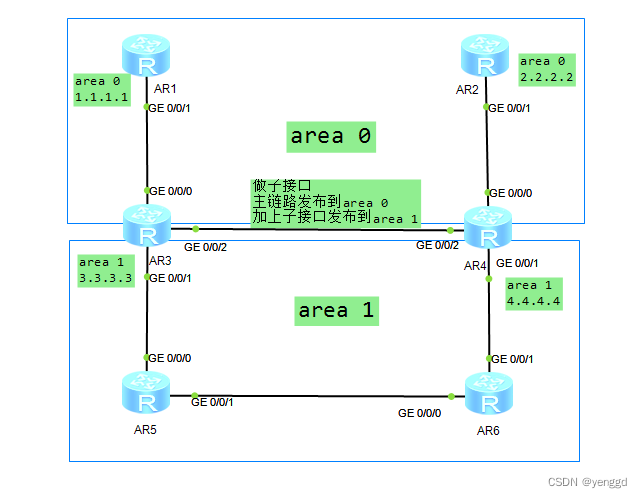
华为ospf路由协议防环和次优路径中一些难点问题分析
第一种情况是ar3的/0/0/2口和ar4的0/0/2口发布在区域1时,当ar1连接ar2的线断了以后,骨干区域就断了,1.1.1.1到2.2.2.2就断了,ping不通了。但ar5和ar6可以ping通2.2.2.2和1.1.1.1,ar3和ar4不可以ping通2.2.2.2和1.1.1.1…...
python-opencv划痕检测-续
python-opencv划痕检测-续 这次划痕检测,是上一次划痕检测的续集。 处理的图像如下: 这次划痕检测,我们经过如下几步: 第一步:读取灰度图像 第二步:进行均值滤波 第三步:进行图像差分 第四步࿱…...

c++[string实现、反思]
我的码云 我的string码云 分析总结 1.项目结构 所有的类和函数需要在namespace中实现,要和string高度对应 private:char* _str;//字符串size_t _size;//有效长度size_t _capacity;//总空间,包括\0const static size_t npos-1;2.定义变量 <1> 所…...

c++版本opencv计算灰度图像的轮廓点
代码 #include<iostream> #include<opencv.hpp>int main() {std::string imgPath("D:\\prostate_run\\result_US_20230804_141531\\mask\\us\\104.bmp");cv::Mat imgGray cv::imread(imgPath, 0);cv::Mat kernel cv::getStructuringElement(cv::MORPH…...

SAP ABAP接口开发避坑:JSON数据里的回车换行符怎么处理才不报错?
SAP ABAP接口开发实战:JSON数据中隐形字符的精准处理方案 当ABAP开发者构建与外部系统的数据交互接口时,JSON格式已成为现代系统集成的通用语言。然而,那些隐藏在数据流中的控制字符——比如回车(CR)、换行(LF)、制表符(TAB)——往往成为接口…...

3分钟掌握百度网盘提取码智能获取:baidupankey终极使用指南
3分钟掌握百度网盘提取码智能获取:baidupankey终极使用指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘资源提取码而烦恼吗?每次遇到需要密码的分享链接,你是否都要在多个…...

# ROS机器人系统中基于行为树的智能任务调度实践与优化在**ROS(R
ROS机器人系统中基于行为树的智能任务调度实践与优化 在ROS(Robot Operating System)生态中,任务调度一直是实现复杂机器人行为的核心模块。传统基于状态机或简单顺序执行的方式难以应对动态环境下的多任务并发、优先级冲突和异常恢复等问题。…...

机器学习学习路径:10种类型与资源匹配指南
1. 机器学习入门:如何找到适合自己的学习路径第一次接触机器学习时,我像大多数初学者一样陷入了选择困难。网上充斥着各种教程、书籍和课程推荐,但真正开始学习后才发现,很多资源要么过于理论化,要么与我的实际需求不匹…...

RisohEditor:免费Win32资源编辑器解决exe图标修改与对话框编辑难题
你是否曾经想要替换一个可执行文件(.exe)的图标,却找不到合适的工具?是否想修改某个程序中的对话框文字、菜单选项,或者更新版本信息?这些需求,都需要一款专业的exe资源编辑器。RisohEditor正是…...

飞书表格API避坑指南:从‘sheet=’乱码到批量插入行列,我踩过的坑都在这了
飞书表格API深度排雷手册:那些官方文档没告诉你的细节 第一次调用飞书表格API时,我天真地以为照着官方文档就能轻松搞定。直到在凌晨三点的办公室里,对着满屏的400错误码和乱码sheet名,才意识到自己掉进了多少坑。这份手册记录了…...
)
STM32F4+FreeRTOS以太网实战:DP83848驱动配置避坑指南(附完整代码)
STM32F4FreeRTOS以太网实战:DP83848驱动配置避坑指南(附完整代码) 在工业物联网设备开发中,稳定可靠的以太网通信往往是核心需求之一。STM32F4系列凭借其出色的性能和丰富的外设资源,成为许多开发者的首选平台。而DP8…...

完成Flash到WebGL渲染核心重构,实现技术向新时代的转移。
这是一个从 Flash(ActionScript)迁移到 WebGL 游戏引擎时,开发者必须面对的核心技术重构问题。迁移的本质是从一个高层次的、基于显示列表的 2D 渲染模型,转向一个底层的、基于 GPU 的、可处理 2D/3D 的渲染管线。以下是需要重写的…...

盛合晶微科创板上市,开盘市值近1858亿,无锡国资投资回报率超600%
盛合晶微上市:募资50.28亿,市值飙升至1418亿4月21日,集成电路晶圆级先进封测企业盛合晶微半导体有限公司在上交所科创板挂牌,发行价19.68元,预计募资总额约50.28亿元。上市首日,盛合晶微开盘大涨406.71%报9…...
