Token 和 N-Gram、Bag-of-Words 模型释义
ChatGPT(GPT-3.5)和其他大型语言模型(Pi、Claude、Bard 等)凭何火爆全球?这些语言模型的运作原理是什么?为什么它们在所训练的任务上表现如此出色?
虽然没有人可以给出完整的答案,但了解自然语言处理的一些基本概念有助于我们了解 LLM 内在工作原理。尤其是了解 Token 和 N-gram 对于理解几乎所有当前自回归和自编码模型都十分重要。本文为“「X」Embedding in NLP”的进阶版,将带大家详解 NLP 的核心基础!
01.Token 和 N-gram
在 C/C++ 的入门计算机科学课程中,通常很早就会教授字符串的概念。例如,C 语言中的字符串可以表示为以空字符终止的字符数组:
char my_str[128] = "Milvus";
在这个例子中,每个字符都可以被视为一个离散单位,将它们组合在一起就形成了有意义的文本——在这种情况下,my_str表示了世界上最广泛采用的向量数据库。
简单来说,这就是 N-gram 的定义:一系列字符(或下一段讨论的其他离散单位),当它们连在一起时,具有连贯的意义。在这个实例中,N 对应于字符串中的字符总数(在这个例子是 7)。
N-gram 的概念不必局限于单个字符——它们也可以扩展到单词。例如,下面的字符串是一个三元组(3-gram)的单词:
char my_str[128] = "Milvus vector database"
在上面的例子中,很明显my_str是由三个单词组成的,但一旦考虑到标点符号,情况就变得有些复杂:
char my_str[128] = "Milvus's architecture is unparalleled"
上面的字符串,严格来说,是四个单词,但第一个单词Milvus's是使用另一个单词Milvus作为基础的所有格名词。对于语言模型来说,将类似单词分割成离散的单位是有意义的,这样就可以保留额外的上下文:Milvus和's。这些被称为 Token,将句子分割成单词的基本方法称为标记化(Tokenization)。采用这种策略,上述字符串现在是一个由 5 个 Token 组成的 5-gram。
所有现代语言模型在数据转换之前都会进行某种形式的输入标记化。市面上有许多不同的标记器——例如,WordPiece 是一个流行的标记器,它被用在大多数 BERT 的变体中。在这个系列中我们没有过多深入标记器的细节——对于想要了解更多的人来说,可以查看 Huggingface的标记器总结
02.N-gram 模型
接下来,我们可以将注意力转向 N-gram 模型。简单来说,n-gram 模型是一种简单的概率语言模型,它输出一个特定 Token 在现有 Token 串之后出现的概率。例如,我们可以建模一个特定 Token 在句子或短语中跟随另一个Token(∣)的概率(p):
p(database∣vector)=0.1
上述声明表明,在这个特定的语言模型中,“vector”这个词跟在“database”这个词后面的概率为 10%。对于 N-gram 模型,这些模型总是通过查看输入文档语料库中的双词组的数量来计算,但在其他语言模型中,它们可以手动设置或从机器学习模型的输出中获取。
上面的例子是一个双词模型,但我们可以将其扩展到任意长度的序列。以下是一个三元组的例子:
p(database∣Milvus,vector)=0.9
这表明“database”这个词将以 90% 的概率跟在“Milvus vector”这两个 Token 之后。同样,我们可以写成:
p(chocolate∣Milvus,vector)=0.001
这表明在“Milvus vector”之后出现的词不太可能是“chocolate”(确切地说,概率为0.1%)。将这个应用到更长的序列上:
p(Milvus∣the,most,widely,adopted,vector,database,is)=0.999
接下来讨论一个可能更重要的问题:我们如何计算这些概率?简单而直接的答案是:我们计算文档或文档语料库中出现的次数。我将通过以下 3 个短语的例子来逐步解释(每个句子开头的代表特殊的句子开始标记)。为了清晰起见,我还在每个句子的结尾句号和前一个词之间增加了额外的空格:
-
<S>Milvus是最广泛采用的向量数据库。 -
<S>使用Milvus进行向量搜索。 -
<S>Milvus很棒。
列出以<S>、Milvus或vector开头的双词组:
some_bigrams = {these bigrams begin with <S>
("<S>", "Milvus"): 2,
("<S>", "vector"): 1,these bigrams begin with Milvus
("Milvus", "is"): 1,
("Milvus", "."): 1,
("Milvus", "rocks"): 1,these bigrams begin with vector
("vector", "database"): 1,
("vector", "search"): 1
}
根据这些出现的情况,可以通过对每个 Token 出现的总次数进行规范化来计算概率。例如:

类似:
有了这些知识,我们就可以编写一些代码来构建一个双词模型。为了简单起见,我们假设所有输入文档中的每个 Token 都由一些空白字符分隔(回想一下前面的部分,现代标记器通常有更复杂的规则)。让我们从定义模型本身开始,即双词计数和 Token 计数:
from typing import Dict, Tuple
from collections import defaultdict
#keys correspond to tokensvalues are the number of occurences
token_counts = defaultdict(int)
#keys correspond to 2-tuples bigram pairsvalues are the number of occurences
bigram_counts = defaultdict(int)
def build_bigram_model(corpus):
"""Bigram model. """
#loop through all documents in the corpus
for doc in corpus:
prev = "<S>"
for word in doc.split():
#update token counts
token_counts[word] += 1
#update bigram counts
bigram = (prev, word)
bigram_counts[bigram] += 1
prev = word
#add a dummy end-of-sequence token so probabilities add to one
bigram_counts[(word, "</S>")] += 1
return (token_counts, bigram_counts)
def bigram_probability(bigram: Tuple[str]):
"""Computes the likelihood of the bigram from the corpus. """
return bigram_counts[bigram] / token_counts[bigram[0]]
然后,build_bigram_model会遍历整个文档语料库,先按空白字符分割每个文档,再存储双词组和 Token 计数。然后,我们可以调用bigram_probability函数,该函数查找相应的双词组计数和 Token 计数,并返回比率。
我们在 Milvus 的文档上测试这个模型,大家可以在此下载文档,并尝试上面的代码。
with open("README.md", "r") as f:
build_bigram_model([f.read()])
print(bigram_probability(("vector", "database")))
0.3333333333333333
03.词袋模型
除了 N-gram,另一个值得讨论的是词袋模型(BoW)。词袋模型将文档或文档语料库表示为一个无序的 Token 集合——从这个意义上说,它保持了每个 Token 出现的频率,但忽略了它们在每个文档中出现的顺序。因此,BoW 模型中的整个文档可以转换为稀疏向量,其中向量的每个条目对应于文档中特定单词出现的频率。在这里,我们将文档“Milvus 是最广泛采用的向量数据库。使用Milvus进行向量搜索很容易。”表示为一个 BoW稀疏向量:
limited vocabularybow_vector = [
0, # a
1, # adopted
0, # bag
0, # book
0, # coordinate
1, # database
1, # easy
0, # fantastic
0, # good
0, # great
2, # is
0, # juggle
2, # Milvus
1, # most
0, # never
0, # proof
0, # quotient
0, # ratio
0, # rectify
1, # search
1, # the
0, # undulate
2, # vector
1, # widely
1, # with
0, # yes
0, # zebra
]
这些稀疏向量随后可以用于各种 NLP 任务,如文本和情感分类。关于词袋模型的训练和推理学习可参考 Jason Brownlee的博客。
虽然词袋模型易于理解和使用,但它们有明显的局限性,即无法捕捉上下文或单个 Token 的语义含义,这意味着它们不适合用于最简单的任务之外的任何事情。
04.总结
在这篇文章中,我们讨论了自然语言处理的三个核心基础:标记化(Tokenization)、N-gram 和词袋模型。围绕 N-gram 的概念有助于后续了解关于自回归和自编码模型的训练方式。在下一个教程中,我们将分析“现代”NLP,即循环网络和文本 embedding。敬请期待!
本文由 mdnice 多平台发布
相关文章:
Token 和 N-Gram、Bag-of-Words 模型释义
ChatGPT(GPT-3.5)和其他大型语言模型(Pi、Claude、Bard 等)凭何火爆全球?这些语言模型的运作原理是什么?为什么它们在所训练的任务上表现如此出色? 虽然没有人可以给出完整的答案,但…...

【go语言实践】基础篇 - 流程控制
if语句 go里面if不需要括号将条件表达式包含起来,这与python也有点类似 if 条件表达式 { } if num > 18 {// ... } else if num > 20 {// ... } else {// ... }需要注意的是go支持在if的条件表达式中直接定义一个变量,变量的作用域只在if范围内…...

Linux:gdb的简单使用
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》《Linux》 文章目录 前言一、前置理解二、使用总结 前言 gdb是Linux中的调试代码的工具 一、前置理解 我们都知道要调试一份代码,这份代码的发布模式必须是debug。那你知道在li…...

NestJS的微服务实现
1.1 基本概念 微服务基本概念:微服务就是将一个项目拆分成多个服务。举个简单的例子:将网站的登录功能可以拆分出来做成一个服务。 微服务分为提供者和消费者,如上“登录服务”就是一个服务提供者,“网站服务器”就是一个服务消…...

Debian 终端Shell命令行长路径改为短路径
需要修改bashrc ~/.bashrc先备份一份 cp .bashrc bashrc.backup编辑bashrc vim ~/.bashrc可以看到bashrc内容为 # ~/.bashrc: executed by bash(1) for non-login shells. # see /usr/share/doc/bash/examples/startup-files (in the package bash-doc) # for examples# If…...

Ansible变量是什么?如何实现任务的循环?
Ansible 利用变量存储整个 Ansible 项目文件中可重复使用的值,从而可以简化项目的创建和维护,并减少错误的发生率。在定义Ansible变量时,通常有如下三种范围的变量: global范围:从命令行或Ansible配置中设置的变量&am…...

随机梯度下降的代码实现
在单变量线性回归的机器学习代码中,我们讨论了批量梯度下降代码的实现,本篇将进行随机梯度下降的代码实现,整体和批量梯度下降代码类似,仅梯度下降部分不同: import numpy as np import pandas as pd import matplotl…...

渐进推导中常用的一些结论
标题很帅 STAR-RIS Enhanced Joint Physical Layer Security and Covert Communications for Multi-antenna mmWave Systems文章末尾的一个推导。 lim M → ∞ ∥ Φ ( w k ⊗ Θ r ) Ω r w H g ∗ ∥ 2 2 M lim M → ∞ Tr ( g T Ω r w ( w k ⊗ Θ r ) H Φ H Φ…...

网络安全等级保护V2.0测评指标
网络安全等级保护(等保V2.0)测评指标: 1、物理和环境安全 2、网络和通信安全 3、设备和计算安全 4、应用和数据安全 5、安全策略和管理制度 6、安全管理机构和人员 7、安全建设管理 8、安全运维管理 软件全文档获取:点我获取 1、物…...

java中list的addAll用法详细实例?
List 的 addAll() 方法用于将一个集合中的所有元素添加到另一个 List 中。下面是一个详细的实例,展示了 addAll() 方法的使用: java Copy code import java.util.ArrayList; import java.util.List; public class AddAllExample { public static v…...
关于学习计算机的心得与体会
也是隔了一周没有发文了,最近一直在准备期末考试,后来想了很久,学了这么久的计算机,这当中有些收获和失去想和各位正在和我一样在学习计算机的路上的老铁分享一下,希望可以作为你们碰到困难时的良药。先叠个甲…...
LLM之RAG理论(一)| CoN:腾讯提出笔记链(CHAIN-OF-NOTE)来提高检索增强模型(RAG)的透明度
论文地址:https://arxiv.org/pdf/2311.09210.pdf 检索增强语言模型(RALM)已成为自然语言处理中一种强大的新范式。通过将大型预训练语言模型与外部知识检索相结合,RALM可以减少事实错误和幻觉,同时注入最新知识。然而&…...
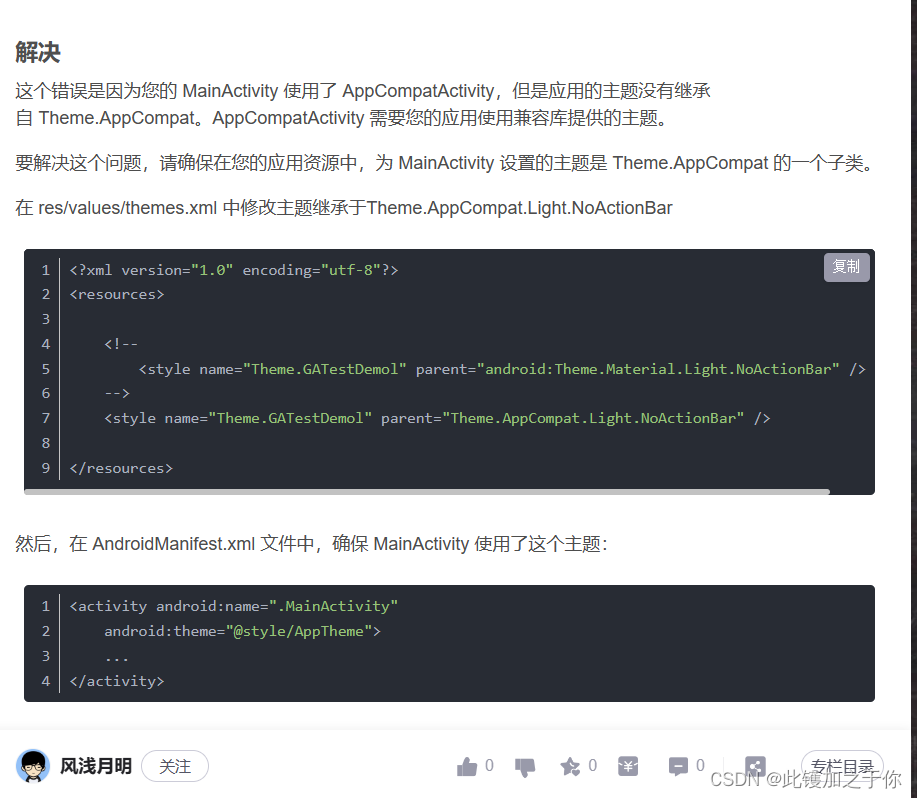
Android studio:打开应用程序闪退的问题2.0
目录 找到问题分析问题解决办法 找到问题 老生常谈,可能这东西真的很常见吧,在之前那篇文章中 linkhttp://t.csdnimg.cn/UJQNb 已经谈到了关于打开Androidstuidio开发的软件后明明没有报错却无法运行(具体表现为应用程序闪退的问题ÿ…...

Spring IoC如何存取Bean对象
小王学习录 IoC(Inversion of Control)1. 什么是IoC2. 什么是Spring IoC3. 什么是DI4. Spring IoC的作用 存储Bean对象1. 创建Bean2. 将Bean注册到Spring中. 取Bean对象.1. 获取Spring上下文信息使用ApplicationContext和BeanFactory的区别 2. 获取指定Bean对象 IoC(Inversion …...

【开源】基于Vue.js的实验室耗材管理系统
文末获取源码,项目编号: S 081 。 \color{red}{文末获取源码,项目编号:S081。} 文末获取源码,项目编号:S081。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 耗材档案模块2.2 耗材入库模块2.3 耗…...
Datawhale聪明办法学Python(task2Getting Started)
一、课程基本结构 课程开源地址:课程简介 - 聪明办法学 Python 第二版 章节结构: Chapter 0 安装 InstallationChapter 1 启航 Getting StartedChapter 2 数据类型和操作 Data Types and OperatorsChapter 3 变量与函数 Variables and FunctionsChapte…...
量化交易怎么操作?量化软件怎么选择比较好?(散户福利,建议收藏)
一:量化的具体操作步骤是什么呢?1. 数据获取:索取和收集金融市场数据。 2. 策略制定:制定数量交易策略,这包括制定投资目标、建立交易规则和风险控制机制等,这个过程需要不断优化和更新。 3. 编写算法&am…...
什么是 AWS IAM?如何使用 IAM 数据库身份验证连接到 Amazon RDS(上)
驾驭云服务的安全环境可能很复杂,但 AWS IAM 为安全访问管理提供了强大的框架。在本文中,我们将探讨什么是 AWS Identity and Access Management (IAM) 以及它如何增强安全性。我们还将提供有关使用 IAM 连接到 Amazon Relational Database Service (RDS…...
Python从入门到精通七:Python函数进阶
函数多返回值 学习目标: 知道函数如何返回多个返回值 问: 如果一个函数如些两个return (如下所示),程序如何执行? 答:只执行了第一个return,原因是因为return可以退出当前函数,导致return下方的代码不执…...
uniapp踩坑之项目:使用过滤器将时间格式化为特定格式
利用filters过滤器对数据直接进行格式化,注意:与method、onLoad、data同层级 <template><div><!-- orderInfo.time的数据为:2023-12-12 12:10:23 --><p>{{ orderInfo.time | formatDate }}</p> <!-- 2023-1…...

一键解决Windows运行库问题:Visual C++ AIO完整安装指南
一键解决Windows运行库问题:Visual C AIO完整安装指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的困扰:新下载…...

贝壳季报图解:营收189亿 经调整净利16亿同比增15.7%
雷递网 雷建平 5月19日贝壳(纽交所代码:BEKE;香港联交所代号:2423)今日公布其截至2026年3月31日止第一季度未经审计财务业绩。财报显示,贝壳2026年第一季度贝壳实现净收入189亿元,净利润12.55亿…...

STM32F103C8T6 Bootloader分区与跳转详解:手把手配置64KB Flash的16+48分配方案
STM32F103C8T6 Bootloader分区与跳转实战:64KB Flash的1648分配方案深度解析 在嵌入式开发中,Bootloader的设计往往是项目成败的关键一环。对于资源受限的STM32F103C8T6这类仅有64KB Flash的MCU来说,如何在Bootloader和应用程序之间合理分配这…...

基于XCKU060 FPGA的高速数据采集卡硬件架构与开发实践
1. 项目概述与核心价值最近在做一个高速数据采集与实时处理的项目,对市面上的FPGA加速卡做了一圈调研和测试。其中,青翼这款基于XCKU060 FPGA的4路SFP光纤数据处理板卡(型号PCIE734)给我留下了挺深的印象。它本质上是一张插在服务…...

3步解锁Windows隐藏音质:免费工具让普通音箱变HIFI
3步解锁Windows隐藏音质:免费工具让普通音箱变HIFI 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你是不是总觉得电脑声音"干巴巴"的?看大片缺乏震撼感,听…...

超导量子计算中的三量子比特门技术解析
1. 超导量子计算中的三量子比特门技术概述在量子计算领域,实现高保真度的多量子比特门操作一直是核心挑战。超导量子处理器作为当前最有前景的量子计算平台之一,其性能很大程度上取决于量子门操作的精度和效率。固定频率transmon架构因其出色的相干性和简…...

从理论到实践:用Magma解锁代数计算新维度
1. 为什么你需要Magma这个代数计算神器 第一次接触Magma是在研究生时期,当时我需要计算一个椭圆曲线上的有理点。用Matlab折腾了整整一周毫无进展,导师随手扔给我一个Magma代码示例,三行命令就解决了问题。那一刻我才明白,专业的事…...

【Java杂项】为什么 b += 1 可以,但 b = b + 1 会报错?类型提升与复合赋值详解
【Java杂项】为什么 b 1 可以,但 b b 1 会报错?复合赋值与类型提升讲清楚前言一、先给结论:它不是简单的文本替换二、先看认知冲突2.1 普通赋值为什么报错2.2 复合赋值为什么能通过三、类型提升到底是什么3.1 常见类型提升结果3.2 为什么小…...

不同版本Python安装常见问题与解决方案
1. 如何在特定的版本下安装package (1) 在命令提示符中,打开相应版本python的安装目录; (2) 执行语句python.exe -m pip install XX (3) 更新库 2. 如何在Spyder中设定特定的python解释器 Spyder—Tools—Python Interpreter...

Keil MDK中EVR选项缺失的解决方案与原理
1. 问题现象解析:EVR选项缺失的典型表现 在Keil MDK开发环境中使用Event Recorder(事件记录器)时,开发者常会遇到一个令人困惑的现象:按照官方文档配置printf重定向到EVR时,STDOUT的下拉菜单中本该出现的&q…...