数据库面经---10则
数据库范式有哪些:
- 第一范式(1NF):
- 数据表中的每一列都是不可分割的原子值。
- 每一行数据在关系表中都有唯一标识,通常是通过主键来实现。
- 第二范式(2NF):
- 满足第一范式。
- 非主键列完全依赖于全部主键而不是部分主键。也就是说,非主键列不能依赖于主键中的一部分属性。
- 第三范式(3NF):
- 满足第二范式。
- 非主键列之间没有传递依赖关系。换句话说,如果 A→B 且 B→C,则不能有 A→C。
group by和order by
前者分组,后者排序
where和having的区别
- WHERE:WHERE子句通常用于SELECT、UPDATE和DELETE语句中。
- WHERE用于在查询之前对行进行过滤,根据指定的条件选择满足条件的行。
- WHERE可以使用比较运算符(如等于、大于、小于等)和逻辑运算符(如AND、OR、NOT)来构建条件。
- HAVING:HAVING子句通常用于SELECT语句中结合GROUP BY子句使用,用于对分组后的结果进行筛选。
- HAVING用于在分组聚合查询之后对结果进行过滤,根据指定的条件筛选满足条件的分组。
- HAVING一般用于统计函数(如SUM、COUNT、AVG)的结果上进行筛选。
存储器、视图、游标
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合。想要实现相应的功能时,只需要调用这个存储过程就行了(类似于函数,输入具有输出参数)。
优点:
- 预先编译,而不需要每次运行时编译,提高了数据库执行效率。
- 封装了一系列操作,对于一些数据交互比较多的操作,相比于单独执行SQL语句,可以减少网络通信量。
- 具有可复用性,减少了数据库开发的工作量。
- 安全性高,可以让没有权限的用户通过存储过程间接操作数据库。
- 更易于维护。
缺点:
- 可移植性差,存储过程将应用程序绑定到了数据库上。
- 开发调试复杂。
- 修改复杂,需要重新编译,有时还需要更新程序中的代码以更新调用。
触发器:
触发器(TRIGGER)是由事件(比如INSERT/UPDATE/DELETE)来触发运行的操作(不能被直接调用,不能接收参数)。在数据库里以独立的对象存储,用于保证数据完整性(比如可以检验或转换数据)。
视图:
从数据库的基本表中通过查询选取出来的数据组成的虚拟表(数据库中只存放视图的定义,而不存放视图的数据)。可以对其进行增/删/改/查等操作。视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,不存储具体的数据(基本表数据发生了改变,视图也会跟着改变)。
可以跟基本表一样,进行增删改查操作(增删改操作有条件限制,一般视图只允许查询操作),对视图的增删改也会影响原表的数据。它就像一个窗口,透过它可以看到数据库中自己感兴趣的数据并且操作它们。
优点:
简单化,数据所见即所得
安全性,用户只能查询或修改他们所能见到得到的数据
逻辑独立性,可以屏蔽真实表结构变化带来的影响
缺点:
性能相对较差,简单的查询也会变得稍显复杂
修改不方便,特变是复杂的聚合视图基本无法修改
游标:
用于定位在查询返回的结果集的特定行,以对特定行进行操作。使用游标可以方便地对结果集进行移动遍历,根据需要滚动或对浏览/修改任意行中的数据。主要用于交互式应用。它是一段私有的SQL工作区,也就是一段内存区域,用于暂时存放受SQL语句影响的数据,简单来说,就是将受影响的数据暂时放到了一个内存区域的虚表当中,这个虚表就是游标。
游标是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。即游标用来逐行读取结果集。游标充当指针的作用。尽管游标能遍历结果中的所有行,但他一次只指向一行。
游标的一个常见用途就是保存查询结果,以便以后使用。游标的结果集是由SELECT语句产生,如果处理过程需要重复使用一个记录集,那么创建一次游标而重复使用若干次,比重复查询数据库要快的多。通俗来说,游标就是能在sql的查询结果中,显示某一行(或某多行)数据,其查询的结果不是数据表,而是已经查询出来的结果集。
内连接、外连接、左连接、右连接
内连接:
包括相等联接和自然联接。 内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。
外连接:
外联接可以是左向外联接、右向外联接或完整外部联接。
左连接:
左边所有数据行
右连接:
右边所有数据行
索引的数据结构
- B+树索引(B+ Tree Index):B+树是一种平衡多路查找树,它具有以下特点:
- 所有叶子节点都位于同一层,且通过指针连接。
- 非叶子节点不存储具体的数据,只存储索引键和指向子节点的指针。
- 叶子节点按照索引键的顺序存储了所有数据,并且相邻叶子节点之间有一个双向链表连接。
B+树索引适合范围查询和排序操作,可以快速定位到指定的索引键或者一个范围内的索引键。
- 哈希索引(Hash Index):
哈希索引是使用哈希表作为底层实现的索引结构。它通过将索引键映射为哈希桶的位置来加快查询速度。每个哈希桶中存储了符合哈希值的索引键所关联的数据位置。
哈希索引适合等值查询,可以在常数时间内精确定位到指定的索引键。然而,哈希索引不支持范围查询和排序操作,并且对于哈希冲突需要进行额外的处理。
B树和B+树是什么意思,区别在哪?
B 树的每个节点都包含数据(索引+记录),而用户的记录数据的大小很有可能远远超过了索引数据,这就需要花费更多的磁盘 I/O 操作次数来读到「有用的索引数据」。
而且,在我们查询位于底层的某个节点(比如 A 记录)过程中,「非 A 记录节点」里的记录数据会从磁盘加载到内存,但是这些记录数据是没用的,我们只是想读取这些节点的索引数据来做比较查询,而「非 A 记录节点」里的记录数据对我们是没用的,这样不仅增多磁盘 I/O 操作次数,也占用内存资源。
B+树:
B+树是在B树的基础上进行改进和优化的一种变体,它具有以下特点:
- 所有叶子节点通过指针连接形成一个有序链表,方便范围查询。
- 只有叶子节点存储索引键和对应的数据,非叶子节点只存储索引键,不存储数据。
- 非叶子节点的索引键用于搜索和定位到正确的子节点。
B+ 树与 B 树差异的点,主要是以下这几点:
- 叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;
- 所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
- 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
- 非叶子节点中有多少个子节点,就有多少个索引;
聚簇索引和非聚簇索引
聚簇索引:找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。聚簇索引按照索引键的顺序对表中的数据行进行物理排序,并将数据行直接存储在叶子节点上。每张表只能有一个聚簇索引,
非聚簇索引:索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。非聚簇索引不改变表中数据行的物理存储顺序,而是在索引中存储索引键和指向对应数据行的指针。一个表可以有多个非聚簇索引。
适合/不适合创建索引的情况
- 频繁更新的字段不适合创建索引,因为每次更新不单单是更新记录,还会更新索引,保存索引文件
- where条件里用不到的字段,不创建索引;
- 表记录太少,不需要创建索引;
- 数据重复且分布平均的字段,因此为经常查询的和经常排序的字段建立索引。注意某些数据包含大量重复数据,因此他建立索引就没有太大的效果,例如性别字段,只有男女,不适。立索引。
什么时候适用索引?
- 字段有唯一性限制的,比如商品编码;
- 经常用于 WHERE 查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。
- 经常用于 GROUP BY 和 ORDER BY 的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
什么时候不需要创建索引?
- WHERE 条件,GROUP BY,ORDER BY 里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。
- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女,
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
事物的概念
事务就是用户定义的一系列执行SQL语句的操作, 这些操作要么完全地执行,要么完全地都不执行, 它是一个不可分割的工作执行单元。
相关文章:

数据库面经---10则
数据库范式有哪些: 第一范式(1NF): 数据表中的每一列都是不可分割的原子值。每一行数据在关系表中都有唯一标识,通常是通过主键来实现。第二范式(2NF): 满足第一范式。…...

深度学习基本介绍-李沐
目录 AI分类:模型分类:广告案例: bilibili视频链接:https://www.bilibili.com/video/BV1J54y187f9/?p2&spm_id_frompageDriver&vd_sourcee6a6e7fec41c59c846c142eb5ef1da0b AI分类: 模型分类: 图…...
【上分日记】第369场周赛(分类讨论 + 数学 + 前缀和)
文章目录 前言正文1.3000. 对角线最长的矩形的面积2.3001. 捕获黑皇后需要的最少移动次数3.3002. 移除后集合的最多元素数3.3003. 执行操作后的最大分割数量 总结尾序 前言 终于考完试了,考了四天,也耽搁了四天,这就赶紧来补这场周赛的题了&a…...
: The CMAKE_CXX_COMPILER:)
CMake Error at CMakeLists.txt:14 (project): The CMAKE_CXX_COMPILER:
报错 CMake Error at CMakeLists.txt:14 (project):The CMAKE_CXX_COMPILER:arm-none-eabi-g 解决办法1 Arm GNU Toolchain Downloads – Arm Developer x86_64 linux上: x86_64 Linux hosted cross toolchains AArch32 bare-metal target (arm-none-eabi)arm-g…...

Sqoop与其他数据采集工具的比较分析
比较Sqoop与其他数据采集工具是一个重要的话题,因为不同的工具在不同的情况下可能更适合。在本博客文章中,将深入比较Sqoop与其他数据采集工具,提供详细的示例代码和全面的内容,以帮助大家更好地了解它们之间的差异和优劣势。 Sq…...

Pandas实战100例 | 案例 31: 转换为分类数据
案例 31: 转换为分类数据 知识点讲解 在处理包含文本数据的 DataFrame 时,将文本列转换为分类数据类型通常是一个好主意。这可以提高性能并节省内存。Pandas 允许将列转换为 category 类型。 分类数据类型: category 类型适用于那些只包含有限数量不同值的列&…...

椋鸟C语言笔记#33:文件的顺序读写
萌新的学习笔记,写错了恳请斧正。 目录 光标(文件位置指示器) 文件的顺序读写 fgetc 使用实例 fputc 使用实例 fgets fputs 使用实例 fscanf fprintf fread fwrite 使用实例 光标(文件位置指示器) 我们…...

Transformer - Attention is all you need 论文阅读
虽然是跑路来NLP,但是还是立flag说要做个project,结果kaggle上的入门project给的例子用的是BERT,还提到这一方法属于transformer,所以大概率读完这一篇之后,会再看BERT的论文这个样子。 在李宏毅的NLP课程中多次提到了…...

安装配置Flink
安装配置Flink 1.上传安装包到Linux 2.解压到指定路径 tar -zxf ./flink-1.14.0-bin-scala_2.12.tgz /usr/local/src/3.修改环境变量 vi ~/.bashrc#往最后加入 export FLINK_HOME /usr/local/src/flink-1.14.0/ export PATH$PATH:$FLINK_HOME/bin#激活环境变量 source ~/.…...
解决Spss没有创建虚拟变量的选项的问题
这个是今天用spss想创建虚拟变量然后发现我的spss没有。 然后能怎么办我就百度呗, 说是在扩展里连接扩展中心 天哪,谁能连上,我连不上 于是就找到了从github上下载到本地,然后安装到spss中 目录 解决方法 点击code 再点击D…...

wxWidgets实战:使用mpWindow绘制阻抗曲线
选择模型时,需要查看model的谐振频率,因此需要根据s2p文件绘制一张阻抗曲线。 如下图所示: mpWindow 左侧使用mpWindow,右侧使用什么? wxFreeChart https://forums.wxwidgets.org/viewtopic.php?t44928 https://…...
冻结和解冻神经网络模型的参数)
深度学习15—(迁移学习)冻结和解冻神经网络模型的参数
冻结与解冻代码: def freeze_net(net):if not net:returnfor p in net.parameters():p.requires_grad Falsedef unfreeze_net(net):if not net:returnfor p in net.parameters():p.requires_grad True 这段代码定义了两个函数:freeze_net 和 unfree…...

强化学习应用(八):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介 Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。 Q-learning算法的核心思想是通过不断更新一个称为Q值的…...

常见面试题之HTML
行内元素有哪些?块级元素有哪些? 空(void)元素有那些? HTML 中的行内元素(inline elements)通常用于在一行内显示,不会独占一行的空间。常见的行内元素有: <span>:用于对文本…...

数据结构与算法教程,数据结构C语言版教程!(第三部分、栈(Stack)和队列(Queue)详解)六
第三部分、栈(Stack)和队列(Queue)详解 栈和队列,严格意义上来说,也属于线性表,因为它们也都用于存储逻辑关系为 "一对一" 的数据,但由于它们比较特殊,因此将其单独作为一章,做重点讲解。 使用栈…...

使用Docker部署PDF多功能工具Stirling-PDF
1.服务器上安装docker 安装比较简单,这种安装的Docker不是最新版本,不过对于学习够用了,依次执行下面命令进行安装。 sudo apt install docker.io sudo systemctl start docker sudo systemctl enable docker 查看是否安装成功 $ docker …...

linux安装系统遇到的问题
这两天打算攻克下来网络编程,发现这也确实是很重要的一个东西,但我就奇了怪了,老师就压根没提,反正留在我印象的就一个tcp/ip七层网络。也说正好,把linux命令也熟悉熟悉,拿着我大一课本快速过过 连接cento…...

groovy XmlParser 递归遍历 xml 文件,修改并保存
使用 groovy.util.XmlParser 解析 xml 文件,对文件进行修改(新增标签),然后保存。 是不是 XmlParser 没有提供方法遍历每个节点,难道要自己写? 什么是递归? 不用说,想必都懂得~ …...
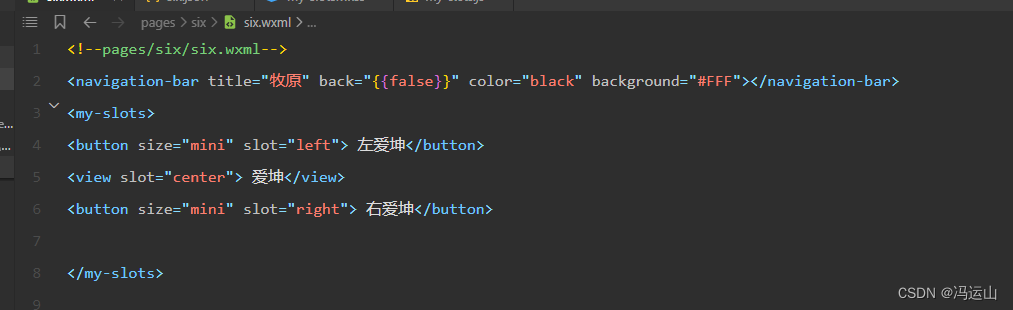
小程序基础学习(多插槽)
先创建插槽 定义多插槽的每一个插槽的属性 在js文件中启用多插槽 在页面使用多插槽 组件代码 <!--components/my-slots/my-slots.wxml--><view class"container"><view class"left"> <slot name"left" ></slot>&…...
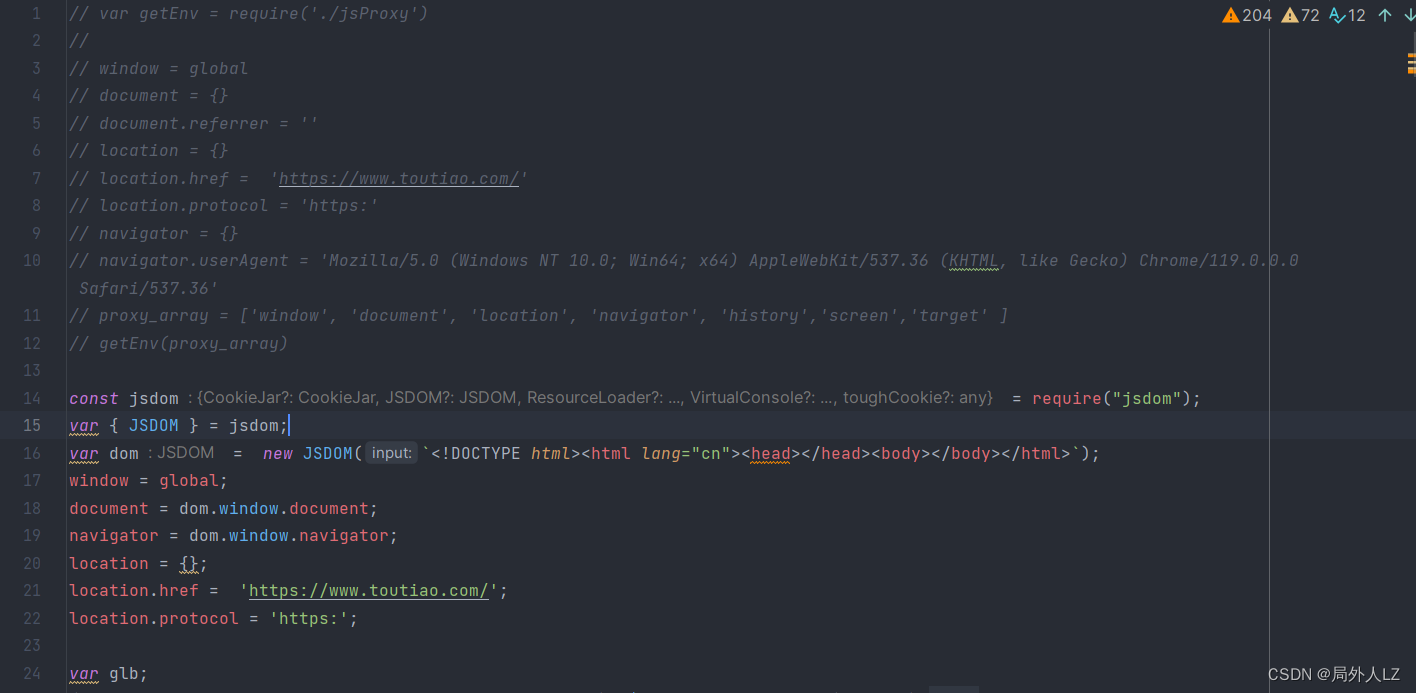
爬虫补环境jsdom、proxy、Selenium案例:某条
声明: 该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关 一、简介 爬虫逆向补环境的目的是为了模拟正常用户的行为,使爬虫看起来更像是一个真实的用户在浏览网站。这样可以…...

马斯克当庭翻脸:刚说完“比特币好“,转身狂喷“其他加密货币都是骗局“
一句法庭证词,炸翻整个币圈2026年4月29日,美国奥克兰法院。埃隆马斯克坐在证人席上,面对一屋子律师和记者,正在为他起诉OpenAI的案件作证。当被问及OpenAI在2018年是否有计划通过首次代币发行(ICO)筹集资金…...

JDspyder:京东自动化抢购解决方案的技术实现与实战指南
JDspyder:京东自动化抢购解决方案的技术实现与实战指南 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商秒杀和限量商品抢购的激烈竞争中,技术手段…...

Zynq平台实战:为Linux内核打上Preempt-RT实时补丁
1. 为什么Zynq需要实时Linux内核? 在工业控制、机器人、医疗设备等对时序要求严格的领域,毫秒级的延迟都可能导致灾难性后果。Xilinx Zynq-7000这类异构SoC虽然集成了ARM处理器和FPGA,但标准Linux内核的完全公平调度器(CFS&#x…...

智能体驱动的学术论文自动化展示系统:从PDF到交互式网站与视频
1. 项目概述:从静态PDF到动态学术门户的智能跃迁如果你是一名研究者,或者经常需要阅读学术论文,你一定有过这样的体验:面对一篇动辄几十页、充满复杂公式和图表的PDF文档,想要快速抓住其核心创新点、理解方法细节、甚至…...

网盘直链解析工具完整指南:跨平台文件获取解决方案
网盘直链解析工具完整指南:跨平台文件获取解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

AI智能体协同框架agentsync:事件驱动与状态同步实战解析
1. 项目概述与核心价值最近在探索AI智能体(Agent)的协同工作流时,我遇到了一个非常有意思的项目:obielin/agentsync。乍一看这个名字,你可能会联想到“代理同步”,但它的内涵远不止于此。简单来说ÿ…...

告别调试助手:在Linux终端用minicom高效收发AT指令
1. 为什么选择minicom替代图形化串口工具 作为一名在嵌入式领域摸爬滚打多年的开发者,我经历过各种串口调试工具的折磨。从早期的Windows超级终端到现在的各种图形化串口助手,最终发现Linux下的minicom才是真正的高效利器。你可能要问:为什么…...

Applite:用图形化界面轻松管理Mac软件的终极解决方案
Applite:用图形化界面轻松管理Mac软件的终极解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Mac上繁琐的软件管理而烦恼吗?Applite作为一…...

Adobe Illustrator智能填充神器:Fillinger脚本的终极使用指南
Adobe Illustrator智能填充神器:Fillinger脚本的终极使用指南 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否曾经在Adobe Illustrator中面对数百个需要均匀分布的…...

智能体开发中利用OpenClaw与Taotoken构建高效工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 智能体开发中利用OpenClaw与Taotoken构建高效工作流 在开发基于大语言的智能体应用时,一个稳定、灵活且易于管理的模型…...