自动化面试常见算法题!
 1、实现一个数字的反转,比如输入12345,输出54321
1、实现一个数字的反转,比如输入12345,输出54321
num = 12345
num_str = str(num)
reversed_num_str = num_str[::-1]
reversed_num = int(reversed_num_str)
print(reversed_num) # 输出 54321
- 代码解析:首先将输入的数字转换为字符串,然后使用切片操作将字符串反转,最后再将反转后的字符串转换回数字类型。
2、统计在一个队列中的数字,有多少个正数,多少个负数,如[1,3,5,7,0,-1,-9,-4,-5,8]
nums = [1, 3, 5, 7, 0, -1, -9, -4, -5, 8]
positive_count = 0
negative_count = 0for num in nums:if num > 0:positive_count += 1elif num < 0:negative_count += 1print(f"正数数量:{positive_count},负数数量:{negative_count}")
- 代码解析:首先定义了一个数字列表 nums,然后用变量 positive_count和negative_count 分别记录其中的正数和负数数量。循环遍历这个列表,对于每个数字,如果它是正数则正数数量加一,否则如果是负数则负数数量加一。最后输出正数和负数数量的统计结果。
3、一个数的阶乘运算,求结果,如求5的阶乘结果。
n = 5 # 求 5 的阶乘
factorial = 1 # 阶乘的初始值为 1for i in range(1, n+1):factorial *= i # 依次乘以 1, 2, 3, ..., nprint(factorial) # 输出 120
- 代码解析:首先定义了待求阶乘的数 n,然后将阶乘的初始值设为 1。在循环中,使用 range(1, n+1) 来遍历 1 到 n 这n个数的值。对于每个数,用 factorial 依次乘以它,最终得到的结果即为阶乘。最后输出结果
4、1加到N的阶层之和,比如N=4, result = (1! + 2! + 3! + 4!)
n = 4
factorial_sum = 0 # 1到N的阶层之和
result = 0 # 最终的结果# 循环计算1到N的阶层之和
for i in range(1, n+1):factorial = 1 # 用来记录i的阶层for j in range(1, i+1):factorial *= jfactorial_sum += factorial# 累加到结果中
result += factorial_sumprint(result) # 输出 33
- 代码解析:首先定义了待求解的数 n 和计算 1 到 N 的阶层之和的变量 factorial_sum。在循环中,使用两层嵌套循环来计算 i 的阶层,然后把所有阶层求和得到 factorial_sum。最后将 factorial_sum 加入到最终结果 result 中。最后输出结果。
5、求出1000以内的完全数
for n in range(2, 1001):factors = [] # 用来存储n的因子for i in range(1, n):if n % i == 0:factors.append(i) # 将i加入到n的因子列表中if sum(factors) == n:print(n)
- 代码解析:外层循环 for n in range(2, 1001) 遍历所有可能的完全数,即从2到1000。在内层循环 for i in range(1, n) 中,使用 n % i == 0 来判断i是否是n的因子,如果是则将它加入到因子列表 factors 中。在循环结束后,使用 sum(factors) == n 来判断所有因子的和是否等于n,如果是则说明n是完全数,输出它的值即可。
- 完全数是指除自身外所有因子之和等于自身的数。其中最经典的两个完全数是6和28,它们的因子分别是1, 2, 3和1, 2, 4, 7, 14。
6、求出1000以内的水仙花数
for n in range(100, 1000):# 将 n 的每一位取出来,计算它们的立方和digits = [int(d) for d in str(n)]digit_cubes_sum = sum(d ** 3 for d in digits)# 如果立方和等于 n,则说明这是一个水仙花数if digit_cubes_sum == n:print(n)
- 代码解析:外层循环 for n in range(100, 1000) 遍历所有三位数,内层使用了列表推导式和 sum() 函数来计算 n 的每个数字的立方和。在判断时,如果立方和等于 n,说明 n 是一个水仙花数,将它输出即可。
- 水仙花数是指一个 n 位数(n≥3)它的每个位上的数字的 n 次幂之和等于它本身。比如 153 就是一个水仙花数,因为 1^3 + 5^3+ 3^3 = 153.
7、求出1000以内的回文数
for n in range(100, 1000):# 将 n 转换为字符串,并将字符串反转后再转成数字reversed_n = int(str(n)[::-1])# 如果翻转后的数等于 n,则说明 n 是一个回文数if reversed_n == n:print(n)
- 代码解析:外层循环 for n in range(100, 1000) 遍历所有三位数,将每个数字转换成字符串,然后使用字符串切片 [::-1] 反转它,并将反转后的字符串转回数字。在判断时,如果反转后的数等于 n,则说明 n 是一个回文数,将它输出即可。
- 回文数是指一个数字从左往右和从右往左读都是一样的,比如 121、1221。
8、实现一个数字的斐波那契数列
# 方式一:循环实现
def fib(n):a, b = 0, 1for i in range(n):a, b = b, a + breturn a
# 测试代码
n = 10
print([fib(i) for i in range(n)]) # 输出结果为 [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]# 方式二:递归实现
def fib(n):if n <= 1:return nelse:return fib(n-1) + fib(n-2)
# 测试代码
n = 10
print([fib(i) for i in range(n)]) # 输出结果为 [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
- 代码解析:
- **方式一(循环实现):初始化 a 和 b 为 0 和 1,然后使用 **for 循环遍历 0 到 n-1,每次将 a 和 b 的值更新为 b 和 a+b,最后返回 a。
- **方式二(递归实现):首先判断 n 的值是否小于等于 1,如果是,则直接返回 n。否则,递归调用 **fib(n-1) 和 fib(n-2) 并返回它们的和。
- 斐波那契数列是指从 0 和 1 开始,后续每个数都等于前两个数之和的数列。其数值为:1、1、2、3、5、8、13、21、34……在数学上,这一数列以如下递推的方法定义:F(0)=1,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n ≥ 2,n ∈ N*)
9、统计列表1~9999中包含3的元素的总个数
import re# 方式一:循环实现
count = 0# 遍历 1~9999 中的每个数字,将数字转换成字符串并查找其中是否包含字符 3
for i in range(1, 10000):if '3' in str(i):count += 1print(count) # 输出结果为 3439# 方式二:循环+正则匹配实现
theList = list(filter(lambda x: re.match('(.*?)3(.*?)',str(x)) ,a))
print(f"列表[1~9999]中包含3的元素总个数为:{len(theList)}") # 输出结果为 3439
代码解析:
- 方式一(循环):使用 for 循环遍历 1~9999 中的每个数字,并将每个数字转换成字符串,然后查找其中是否包含字符 3。如果包含,则将计数器加 1。最后,计数器的值就是包含数字 3 的元素的个数
- 方式二(循环+正则匹配): re.match() 函数用于检查列表 a 中的每个元素是否包含数字3。正则表达式 (.*?)3(.*?) 匹配任何包含数字3的字符串,无论它在字符串中的位置如何。 filter() 函数用于创建一个新列表,其中仅包含与正则表达式匹配的 a 中的元素。 lambda 函数用于定义一个简单的函数,它接受一个参数 x ,并且如果 re.match('(.*?)3(.*?)',str(x)) 返回一个匹配对象(即如果 x 包含数字3),则返回 True ,否则返回 False 。 结果列表被赋值给变量 theList 。 - len() 函数用于计算 theList 的长度,这给出了在范围[1, 9999]中包含数字3的元素的总数。
10、写一个冒泡排序的算法程序
def bubble_sort(arr):n = len(arr)# 遍历 n 次for i in range(n):# 第 i 次遍历,找出未排序部分的最大元素并将其放到末尾for j in range(n - i - 1):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]# 测试代码
arr = [5, 2, 8, 4, 1]
bubble_sort(arr)
print(arr) # 输出结果为 [1, 2, 4, 5, 8]
- 代码解析: bubble_sort() 函数接收一个列表 arr,并将其进行冒泡排序。具体实现时,使用两个嵌套的循环对列表中的所有元素进行比较,如果相邻两个元素的顺序相反,则交换它们的顺序,直到整个列表都排好序。 **先定义了一个列表 **arr,然后调用 bubble_sort(arr) 对其进行冒泡排序,并输出排序后的结果。
- 冒泡排序是一种基本的排序算法,也是最简单的一种排序算法之一。它的基本思想是:通过重复交换相邻的两个元素来实现排序。具体来说,冒泡排序的过程如下: 从列表的第一个元素开始,依次比较相邻的两个元素,如果第一个元素大于第二个元素,则交换它们的位置; 继续比较第二个元素和第三个元素,如果第二个元素大于第三个元素,则交换它们的位置; 重复上述步骤,直到比较到列表的最后一个元素; 重复上述步骤,直到列表中的所有元素都按照从小到大的顺序排列为止。
11、用python实现二分法排序
def binary_search(arr, target):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1# 测试代码
arr = [1, 3, 4, 6, 8, 9, 11, 12, 13, 16]
target = 9
pos = binary_search(arr, target)
if pos == -1:print("元素不在列表中")
else:print("元素在列表中的下标为:", pos)
- 代码解析: binary_search() 函数接收一个有序列表 arr 和一个待查找的元素 target,并返回该元素在列表中的下标(从 0 开始计数);如果该元素不在列表中,则返回 -1。二分查找算法通过不断地将待查找部分缩小一半来实现查找 **有序列表 **arr 和一个待查找的元素 target,然后调用 binary_search(arr, target) 函数查找该元素在列表中的下标,并输出结果。
- 二分查找,也叫二分查找、折半查找,是一种在有序数组中查找某一特定元素的搜索算法。二分查找每次将查找区间减半,直到找到目标元素,或者确定目标元素不存在于数组中。具体来说,二分查找的基本步骤如下: 首先,令左侧下标 low 等于数组的第一个元素下标,右侧下标 high 等于数组的最后一个元素下标,计算中间下标 mid; 比较中间下标的值与目标值的大小关系。若相等,则返回中间下标;若小于目标值,则目标值在中间下标的右侧,将 low 置为 mid + 1;否则目标值在中间下标的左侧,将 high 置为 mid - 1; 重复上述步骤,直到 low 大于 high,表示查找区间为空,返回 -1。
12、写一个快排的算法程序
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2] # 选择中间的元素作为基准值left = [x for x in arr if x < pivot] # 小于基准值的放在左边mid = [x for x in arr if x == pivot] # 等于基准值的放在中间right = [x for x in arr if x > pivot] # 大于基准值的放在右边return quick_sort(left) + mid + quick_sort(right)# 测试代码
arr = [5, 2, 8, 4, 1]
arr_sorted = quick_sort(arr)
print(arr_sorted) # 输出结果为 [1, 2, 4, 5, 8]
- 代码解析: quick_sort() 函数接收一个列表 arr,并返回排序后的新列表。具体实现时,先选择列表中间的元素作为基准值 pivot,然后将列表分成三部分:小于基准值的放在左边,等于基准值的放在中间,大于基准值的放在右边。然后递归地对左、右两个子列表进行排序。 **先定义了一个列表 **arr,然后调用 quick_sort(arr) 将其进行快速排序,并输出排序后的结果。
- 快速排序(Quick Sort)是一种常用的排序算法,属于交换排序的一种。其基本思想是:选定一个基准值,将列表分成两个子列表,小于基准值的放在左边,大于或等于基准值的放在右边,然后递归地对左、右两个子列表进行排序,最终将整个列表排序。具体来说,快速排序算法的基本步骤如下: 确定基准值:选取一个基准值,在列表中选择一个元素作为基准值。 分割:将列表按照基准值进行分割,小于基准值的放在左边,大于或等于基准值的放在右边。分割后,将列表分成了两个部分,左边部分的所有元素都小于基准值,右边部分的所有元素都大于或等于基准值。 递归:对左、右两个子列表分别进行快速排序的递归操作,直到排序完成。
相关文章:
自动化面试常见算法题!
1、实现一个数字的反转,比如输入12345,输出54321 num 12345 num_str str(num) reversed_num_str num_str[::-1] reversed_num int(reversed_num_str) print(reversed_num) # 输出 54321代码解析:首先将输入的数字转换为字符串ÿ…...
CCF-CSP真题202206-2《寻宝!大冒险!》
题目背景 暑假要到了。可惜由于种种原因,小 P 原本的出游计划取消。失望的小 P 只能留在西西艾弗岛上度过一个略显单调的假期……直到…… 某天,小 P 获得了一张神秘的藏宝图。 问题描述 西西艾弗岛上种有 n 棵树,这些树的具体位置记录在…...
Rust编程(三)生命周期与异常处理
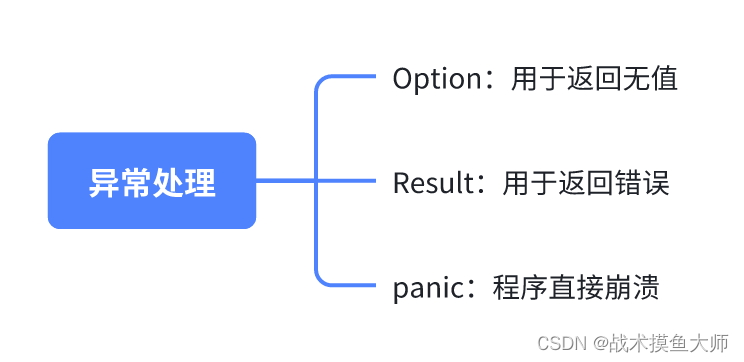
生命周期 生命周期,简而言之就是引用的有效作用域。在大多数时候,我们无需手动的声明生命周期,因为编译器可以自动进行推导。生命周期的主要作用是避免悬垂引用,它会导致程序引用了本不该引用的数据: {let r;{let x …...
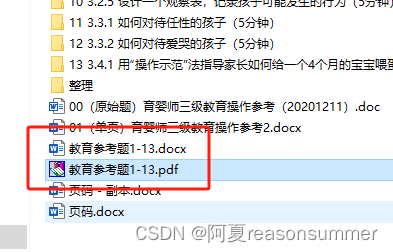
【办公类-21-11】 20240327三级育婴师 多个二级文件夹的docx合并成docx有页码,转PDF
背景展示:有页码的操作题 背景需求: 实操课终于全部结束了,把考试内容(docx)都写好了 【办公类-21-10】三级育婴师 视频转文字docx(等线小五单倍行距),批量改成“宋体小四、1.5倍行…...
OSG编程指南<二十一>:OSG视图与相机视点更新设置及OSG宽屏变形
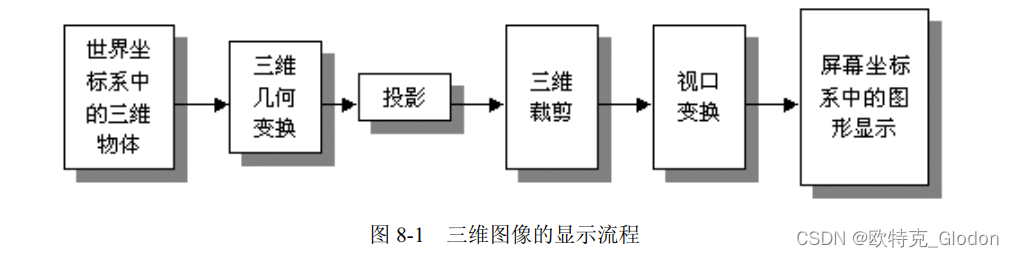
1、概述 什么是视图?在《OpenGL 编程指南》中有下面的比喻,从笔者开始学习图形学就影响深刻,相信对读者学习场景管理也会非常有帮助。 产生目标场景视图的变换过程类似于用相机进行拍照,主要有如下的步骤: (1)把照相机固定在三脚架上,让它对准场景(视图变换)。 (2)…...

Laplace变换-3
回忆#常见函数的Laplace变换: t z − 1 ↦ Γ ( z ) s z t^{z-1} \mapsto \frac{\Gamma(z)}{s^{z}} tz−1↦szΓ(z) (要求 R e ( z ) > 0 \mathrm{Re}(z)>0 Re(z)>0) e a t ↦ 1 s − a e^{at} \mapsto \frac{1}{s-a} eat↦s−a1…...
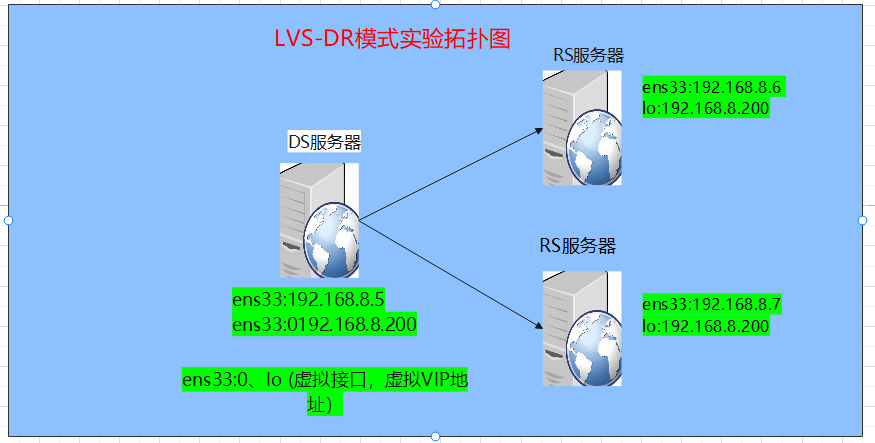
LVS负载均衡-DR模式配置
LVS:Linux virtual server ,即Linux虚拟服务器 LVS自身是一个负载均衡器(Director),不直接处理请求,而是将请求转发至位于它后端的真实服务器real server上。 LVS是四层(传输层 tcp/udp)负载均衡…...
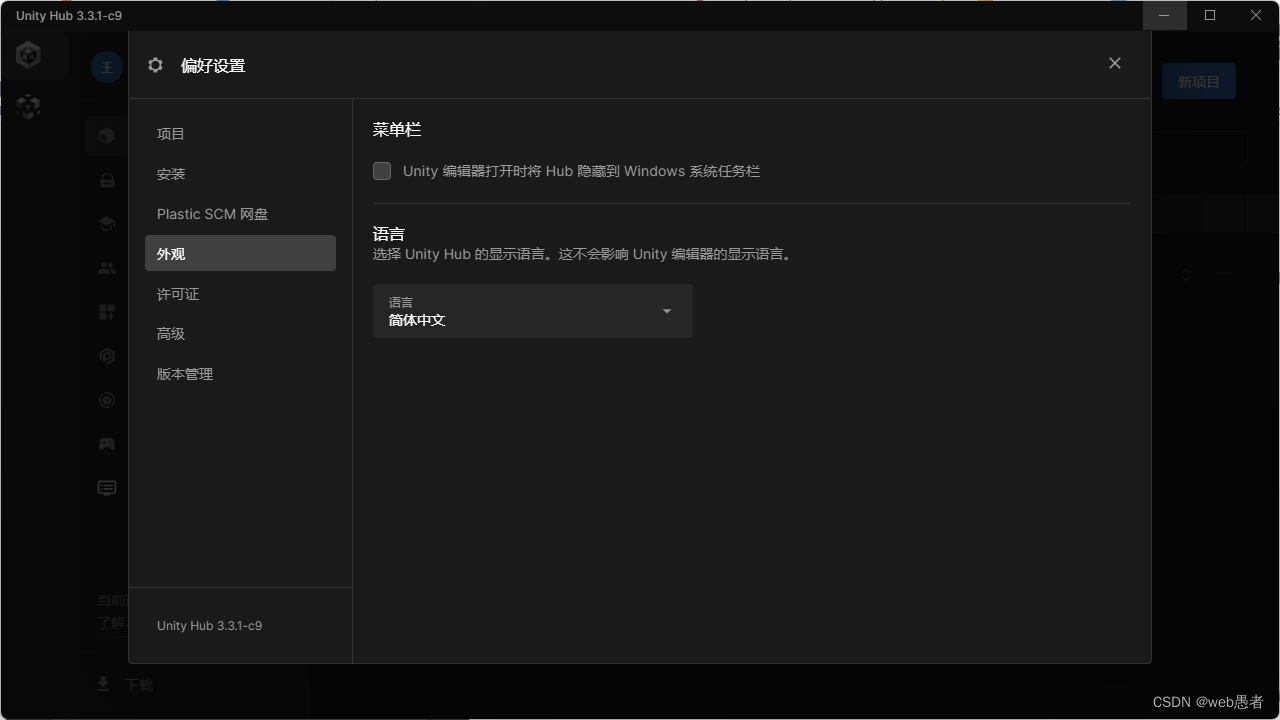
【unity】如何汉化unity Hub
相信大家下载安装unity后看着满操作栏的英文,英文不好的小伙伴们会一头雾水。但是没关系你要记住你要怎么高速运转的机器进入中国,请记住我给出的原理,不懂不代表不会用啊。现在我们就来把编译器给进行汉化。 第一步:我们打开Uni…...

【算法】KMP-快速文本匹配
文章目录 一、KMP算法说明二、详细实现1. next数组定义2. 使用next加速匹配3. next数组如何快速生成4. 时间复杂度O(mn)的证明a) next生成的时间复杂度b) 匹配过程时间复杂度 三、例题1. [leetcode#572](https://leetcode.cn/problems/subtree-of-another-tree/description/)2.…...

多维数组和交错数组笔记
1.) 关于数据的几个概念: Rank,即数组的维数,其值是数组类型的方括号之间逗号个数加上1。 Demo:利用一维数组显示斐波那契数列F(n) F(n-1) F(n-2) (n >2 ),每行显示5项,20项. static void Main(string[] args){int[] F n…...

Python(django)之单一接口展示功能前端开发
1、代码 建立apis_manage.html 代码如下: <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><title>测试平台</title> </head> <body role"document"> <nav c…...

【大模型】非常好用的大语言模型推理框架 bigdl-llm,现改名为 ipex-llm
非常好用的大语言模型推理框架 bigdl-llm,现改名为 ipex-llm bigdl-llmgithub地址环境安装依赖下载测试模型加载和优化预训练模型使用优化后的模型构建一个聊天应用 bigdl-llm IPEX-LLM is a PyTorch library for running LLM on Intel CPU and GPU (e.g., local P…...

Kubernetes示例yaml:3. service-statefulset.yaml
service-statefulset.yaml 示例 apiVersion: apps/v1 kind: statefulset metadata:...... spec:......volumeMounts:- name: pvcmountPath: /var/lib/arangodb3VolumeClaimTemplates:- metadata:name: pvcspec:accessModes: [ "ReadWriteOnce" ]storangeClassName: …...

Windows平台cmake编译QT源码库,使用VScode开发QT
不愿意安装庞大的QT开发IDE,可以编译QT源码库。 下载源码可以用国内镜像,如清华大学的:Index of /qt/archive/qt/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 我用的是 6.5.3,进去之后,不要下载整个源…...

腾讯云轻量8核16G18M服务器多少钱一年?
腾讯云轻量8核16G18M服务器多少钱一年?优惠价格4224元15个月,买一年送3个月。配置为轻量应用服务器、16核32G28M、28M带宽、6000GB月流量、上海/广州/北京、380GB SSD云硬盘。 腾讯云服务器有两个活动,一个是官方的主会场入口,还…...
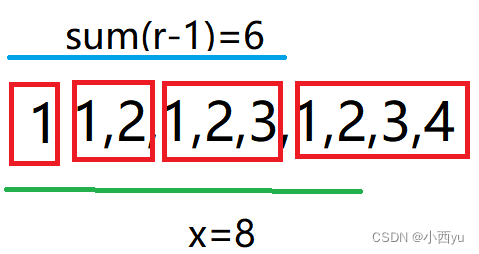
二分练习题——123
123 二分等差数列求和前缀和数组 题目分析 连续一段的和我们想到了前缀和,但是这里的l和r的范围为1e12,明显不能用O(n)的时间复杂度去求前缀和。那么我们开始观察序列的特点,可以按照等差数列对序列进行分块。如上图,在求前10个…...
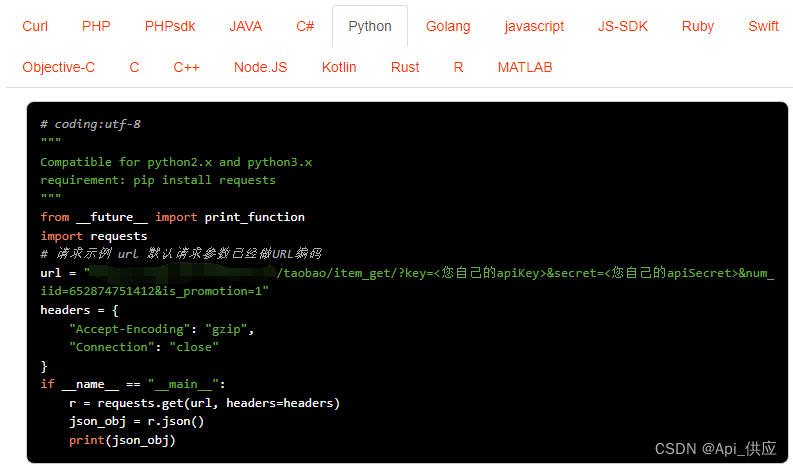
淘宝详情数据采集(商品上货,数据分析,属性详情,价格监控),海量数据值得get
淘宝详情数据采集涉及多个环节,包括商品上货、数据分析、属性详情以及价格监控等。在采集这些数据时,尤其是面对海量数据时,需要采取有效的方法和技术来确保数据的准确性和完整性。以下是一些关于淘宝详情数据采集的建议: 请求示…...
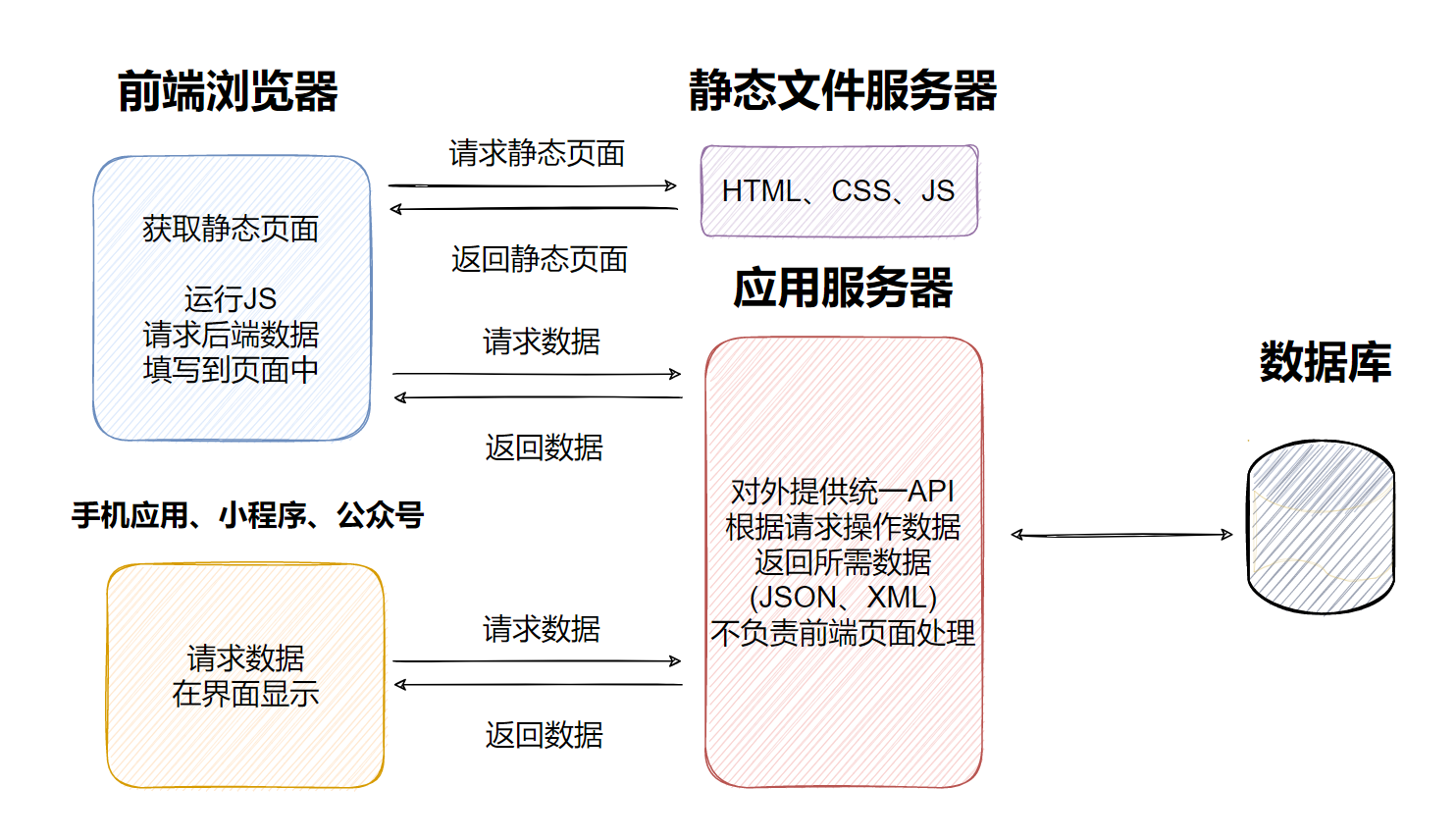
Django之Web应用架构模式
一、Web应用架构模式 在开发Web应用中,有两种模式 1.1、前后端不分离 在前后端不分离的应用模式中,前端页面看到的效果都是由后端控制,由后端渲染页面或重定向,也就是后端需要控制前端的展示。前端与后端的耦合度很高 1.2、前后端分离 在前后端分离的应用模式中,后端仅返…...

GPT提示词分享 —— 口播脚本
可用于撰写视频、直播、播客、分镜头和其他口语内容的脚本。 提示词👇 请以人的口吻,采用缩略语、成语、过渡短语、感叹词、悬垂修饰语和口语化语言,避免重复短语和不自然的句子结构,撰写一篇关于 [主题] 的文章。 GPT3.5&#…...
笔记本作为其他主机显示屏(HDMI采集器)
前言: 我打算打笔记本作为显示屏来用,连上工控机,这不是贼方便吗 操作: 一、必需品 HDMI采集器一个 可以去绿联买一个,便宜的就行,我的大概就长这样 win10下载 PotPlayer 软件 下载链接:h…...

Android Method Tracing深度解析:Unity性能瓶颈跨层归因实战
1. 为什么Method Tracing不是“点一下就出报告”的银弹,而是Android性能诊断的听诊器在Unity项目上线前的最后两周,我接手了一个卡顿严重的AR应用——启动后3秒内帧率从60掉到22,用户滑动模型时UI直接冻结。团队里有人立刻打开Profiler&#…...

VMware虚拟机安装及配置
密码 # 设置 root 用户密码 sudo passwd root修改国内镜像源 在 Ubuntu 24.04 之前,Ubuntu 的软件源配置文件路径为 /etc/apt/sources.list;从 Ubuntu 24.04 开始,Ubuntu 的软件源配置文件变更为 DEB822 格式,路径为 /etc/apt/so…...

Java基础小知识
一、 计算机基础知识1.计算机硬件的分类:运算器 控制器 存储器 输入设备 输出设备二、cmd命令窗口的基本用法操着: 说明:盘符名称 : 盘符切换。E:回车,表示切换到E盘dir 查看当前路径下的内容cd 目录 进入单级目录。cd…...
)
告别C盘爆满!手把手教你将VS2010旗舰版安装到其他盘(附完整配置流程)
告别C盘爆满!手把手教你将VS2010旗舰版安装到其他盘(附完整配置流程) 对于开发者而言,Visual Studio 2010(VS2010)作为经典的开发环境,至今仍被许多项目所依赖。然而,随着系统盘空间…...

Legacy Update完整指南:让老旧Windows系统重获安全更新的5步教程
Legacy Update完整指南:让老旧Windows系统重获安全更新的5步教程 【免费下载链接】LegacyUpdate Get back online, activate, and install updates on your legacy Windows PC 项目地址: https://gitcode.com/gh_mirrors/le/LegacyUpdate 还在为Windows XP、…...
)
ComfyUI全面掌握-知识点详解——ComfyUI 开发与扩展基础(开发指南+环境搭建)
本文为「ComfyUI 全面掌握」系列第 23 篇,是高阶进阶章节的第一篇知识点详解博客。作为开发系列的起点,本文将带你系统了解 ComfyUI 社区贡献流程,并手把手搭建完整的自定义节点开发环境,为后续的节点开发与发布奠定坚实的技术基础…...

Mythos骨架式推理:企业级AI能力治理与因果建模新范式
1. 项目概述:一次被刻意“锁住”的能力跃迁如果你最近关注大模型前沿动态,大概率已经看到“Anthropic Mythos”这个词在技术圈悄然升温。它不是某个新发布的开源模型,也不是某家创业公司的秘密武器,而是Anthropic内部代号为Mythos…...

2026年想找口碑好的长沙瓷砖美缝?哪家专业这里给你答案!
装修是一件充满期待却又布满挑战的事情,而美缝作为装修收尾的关键一步,其重要性不言而喻。然而,许多业主在美缝过程中遭遇了各种困扰,究竟怎样才能找到一家专业靠谱的美缝团队呢?在长沙,长沙匠心徐师傅美缝…...

kafka安装与可视化工具offset explore连接操作说明
1.1 环境前置要求 本地部署 Kafka 4.0 极简,无复杂依赖,只需满足 1 个核心条件: 本地已安装 JDK 17 及以上版本(推荐 JDK 17),并配置好 Java 环境变量(能在命令行执行 java -version 和 javac -…...

ZYNQ平台开源EtherCAT主站部署与实时运动控制优化实践
1. 项目概述与核心价值最近在做一个基于ZYNQ的工业运动控制项目,客户对多轴同步的实时性和抖动要求非常高,传统的脉冲或总线方案在复杂轨迹规划下显得有些力不从心。经过一番调研和选型,最终决定上马EtherCAT总线。作为工业以太网领域的“性能…...