【办公类-21-11】 20240327三级育婴师 多个二级文件夹的docx合并成docx有页码,转PDF
背景展示:有页码的操作题

背景需求:
实操课终于全部结束了,把考试内容(docx)都写好了
【办公类-21-10】三级育婴师 视频转文字docx(等线小五单倍行距),批量改成“宋体小四、1.5倍行距、蓝色字体、去掉五分钟”-CSDN博客文章浏览阅读787次,点赞9次,收藏7次。【办公类-21-10】三级育婴师 视频转文字docx(等线小五单倍行距),批量改成“宋体小四、1.5倍行距、蓝色字体、去掉五分钟”https://blog.csdn.net/reasonsummer/article/details/137055848

最后所有docx需要合并在一起,便于打印,但是前期发现合并的PDF内没有页码,双面打印后没有页码不知道到底是第几题。
【办公类-21-08】三级育婴师 多个二级文件夹的docx合并成PDF-CSDN博客文章浏览阅读510次,点赞7次,收藏6次。【办公类-21-08】三级育婴师 多个二级文件夹的docx合并成PDFhttps://blog.csdn.net/reasonsummer/article/details/136460044?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136460044%22%2C%22source%22%3A%22reasonsummer%22%7D

需求:
1、将所有docx文件合并一个docx,
2、插入页码,并确保一个题目一页,
3、保存docx,转成PDF。
通过三天的AI问询,终于将这个需求实现了。
第1步:从二级文件里提取所有的蓝色字体docx,放到整理

代码
import os,time
import shutilprint('-----1、复制每个文件夹下的(没有5分钟字样的docx文件到二级文件夹“整理”里-------')# 一级文件夹路径
folder_path = r'D:\04三级操作题'
# 目标文件夹路径
new_path = folder_path+r'\整理'
os.makedirs(new_path, exist_ok=True)# 获取一级文件夹中的所有二级文件夹(包括整理文件夹)
subfolders = [f.path for f in os.scandir(folder_path) if f.is_dir()]# 遍历二级文件夹并复制docx文件到目标文件夹复制到整理里面
for subfolder in subfolders:if subfolders=='整理': # 排除“整理”文件夹passelse:docx_files = [f for f in os.listdir(subfolder) if f.endswith('.docx')]for file in docx_files:source_file = os.path.join(subfolder, file)destination_file = os.path.join(new_path, file)if source_file == destination_file:# 如果复制文件相同,就跳过 continueif '5分钟' in file:# # 不要有5分钟文件名的docxpasselse:shutil.copy2(source_file, destination_file)

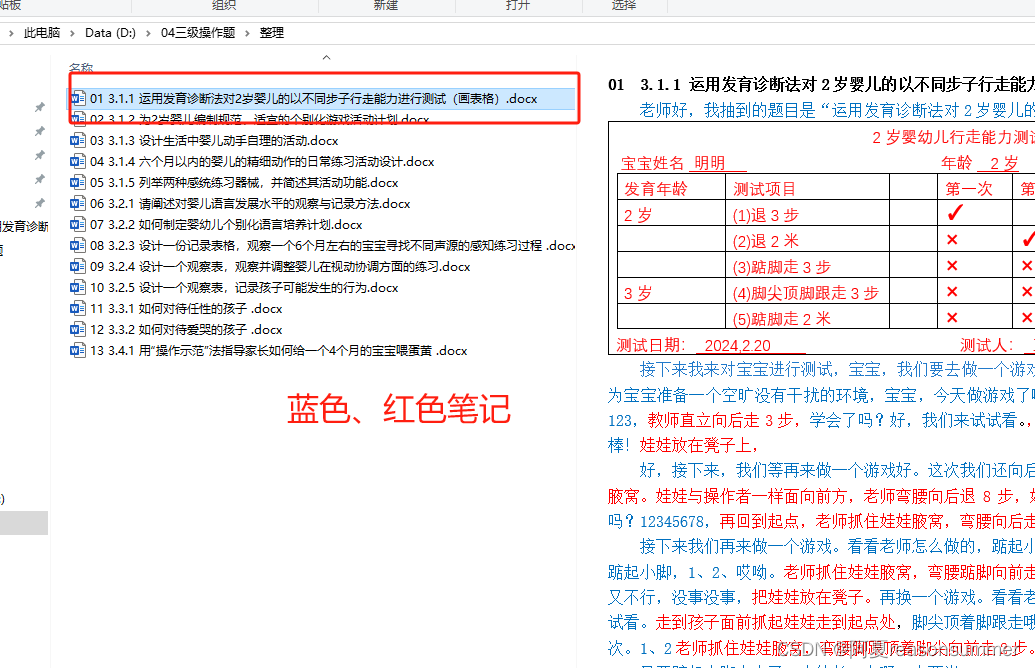
第2步:修改整理内docx的上下左右边距,页脚的边距



并且每段最后加一个下一页换页符(确保每个题目占满一面)

代码
print('-----2、把“整理”里面的所有docx打开,最后添加分节符、设置页眉页脚距离边距的大小(把页面撑到最大)------')
# 打开每个文件,添加一个分节符
from docx import Document
from docx.enum.section import WD_SECTION_START
from docx.shared import Cm# 遍历整理文件夹内的所有docx文件
for filename in os.listdir(new_path):if filename.endswith(".docx"):file_path = os.path.join(new_path, filename)# 打开docx文件doc = Document(file_path)# 设置页脚距离页面边界1厘米section = doc.sections[0]section.left_margin = Cm(1)section.right_margin = Cm(1)section.top_margin = Cm(1)section.bottom_margin = Cm(1)# 将页脚距离页面边界从1.75厘米改为1厘米section.footer_distance = Cm(1)# 添加一个新分节符doc.add_section(WD_SECTION_START.NEW_PAGE) # 保存文档(覆盖原文件)doc.save(file_path)边距修改后,可以写文字的部分变大了


第3步:读取一个有页码的模板,把“整理”内所有的docx文字复制到模板,并另存


print('-----3、读取一个带页码的模板,把整理里面的docx合并到这个模板里------')from docx import Document
from docx.enum.section import WD_SECTION_START
import os
from docx.shared import Cm# # 创建一个带页码的空Document对象,并把页眉页脚边距改小combined_doc = Document(folder_path+r'\页码.docx')# 读取“整理”里面的docx的内容
docx_files = []for file_name in os.listdir(new_path):if file_name.endswith(".docx"):docx_files.append(os.path.join(new_path, file_name))for file in docx_files:doc = Document(file)for element in doc.element.body:combined_doc.element.body.append(element) out_file=folder_path+r'\教育参考题1-13.docx'
combined_doc.save(out_file)
已经实现了每题1-2面(分页符)

但是还有第1行和最后1行(模板自带的,这些空行回车需要删除)

第4步,删除docx的第一个和最后一个回车
print('-----4、把“合并docx"的第一段回车和最后一个回车删除。(页码模板自带)---')
doc = Document(out_file)
# 删除第1个和最后一个段落(都只有一个回车)
for i in [0,-1]:dell_paragraph = doc.paragraphs[i]doc._element.body.remove(dell_paragraph._element)
doc.save(out_file)

第5步,docx转PDF
print('-----5、把“合并docx"转为”合并PDF“---')
# from docx2pdf import convert
# # 转换123.docx为123.pdf
# convert(out_file, out_file[:4]+'.pdf')
# 用这个导致有些内容到下一页了。import comtypes.client,time# 启动Word应用程序
word = comtypes.client.CreateObject('Word.Application')
doc = word.Documents.Open(out_file)# pdf_file=out_file[:-4]+'pdf'# 将文档保存为PDF文件
doc.SaveAs(out_file[:-4]+'pdf', FileFormat=17) # 17表示PDF格式
# r'D:\04三级操作题\教育参考题1-13.pdf'
time.sleep(2)
# 关闭Word应用程序
doc.Close()
word.Quit()print("转换完成!")



现在docx合并和PDF合并都有页码了
1、docx:便于日后的修改(内容补充)
2、PDF:便于双面打印(内容板式不变化)
全部代码展示:
'''
合并word,带页码(读取一个带页码的空模板),转出PDF
作者:阿夏(AI对话大师)
时间:2024年3月27日
'''import os,time
import shutilprint('-----1、复制每个文件夹下的(没有5分钟字样的docx文件到二级文件夹“整理”里-------')# 一级文件夹路径
folder_path = r'D:\04三级操作题'
# 目标文件夹路径
new_path = folder_path+r'\整理'
os.makedirs(new_path, exist_ok=True)# 获取一级文件夹中的所有二级文件夹(包括整理文件夹)
subfolders = [f.path for f in os.scandir(folder_path) if f.is_dir()]# 遍历二级文件夹并复制docx文件到目标文件夹复制到整理里面
for subfolder in subfolders:if subfolders=='整理': # 排除“整理”文件夹passelse:docx_files = [f for f in os.listdir(subfolder) if f.endswith('.docx')]for file in docx_files:source_file = os.path.join(subfolder, file)destination_file = os.path.join(new_path, file)if source_file == destination_file:# 如果复制文件相同,就跳过 continueif '5分钟' in file:# # 不要有5分钟文件名的docxpasselse:shutil.copy2(source_file, destination_file)print('-----2、把“整理”里面的所有docx打开,最后添加分节符、设置页眉页脚距离边距的大小(把页面撑到最大)------')
# 打开每个文件,添加一个分节符
from docx import Document
from docx.enum.section import WD_SECTION_START
from docx.shared import Cm# 遍历整理文件夹内的所有docx文件
for filename in os.listdir(new_path):if filename.endswith(".docx"):file_path = os.path.join(new_path, filename)# 打开docx文件doc = Document(file_path)# 设置页脚距离页面边界1厘米section = doc.sections[0]section.left_margin = Cm(1)section.right_margin = Cm(1)section.top_margin = Cm(1)section.bottom_margin = Cm(1)# 将页脚距离页面边界从1.75厘米改为1厘米section.footer_distance = Cm(1)# 添加一个新分节符doc.add_section(WD_SECTION_START.NEW_PAGE) # 保存文档(覆盖原文件)doc.save(file_path)print('-----3、读取一个带页码的模板,把整理里面的docx合并到这个模板里------')from docx import Document
from docx.enum.section import WD_SECTION_START
import os
from docx.shared import Cm# # 创建一个带页码的空Document对象,并把页眉页脚边距改小combined_doc = Document(folder_path+r'\页码.docx')# 读取“整理”里面的docx的内容
docx_files = []for file_name in os.listdir(new_path):if file_name.endswith(".docx"):docx_files.append(os.path.join(new_path, file_name))for file in docx_files:doc = Document(file)for element in doc.element.body:combined_doc.element.body.append(element) out_file=folder_path+r'\教育参考题1-13.docx'
combined_doc.save(out_file)print('-----4、把“合并docx"的第一段回车和最后一个回车删除。(页码模板自带)---')
doc = Document(out_file)
# 删除第1个和最后一个段落(都只有一个回车)
for i in [0,-1]:dell_paragraph = doc.paragraphs[i]doc._element.body.remove(dell_paragraph._element)
doc.save(out_file)print('-----5、把“合并docx"转为”合并PDF“---')
# from docx2pdf import convert
# # 转换123.docx为123.pdf
# convert(out_file, out_file[:4]+'.pdf')
# 用这个导致有些内容到下一页了。import comtypes.client,time# 启动Word应用程序
word = comtypes.client.CreateObject('Word.Application')
doc = word.Documents.Open(out_file)# pdf_file=out_file[:-4]+'pdf'# 将文档保存为PDF文件
doc.SaveAs(out_file[:-4]+'pdf', FileFormat=17) # 17表示PDF格式
# r'D:\04三级操作题\教育参考题1-13.pdf'
time.sleep(2)
# 关闭Word应用程序
doc.Close()
word.Quit()print("转换完成!")相关文章:
【办公类-21-11】 20240327三级育婴师 多个二级文件夹的docx合并成docx有页码,转PDF
背景展示:有页码的操作题 背景需求: 实操课终于全部结束了,把考试内容(docx)都写好了 【办公类-21-10】三级育婴师 视频转文字docx(等线小五单倍行距),批量改成“宋体小四、1.5倍行…...
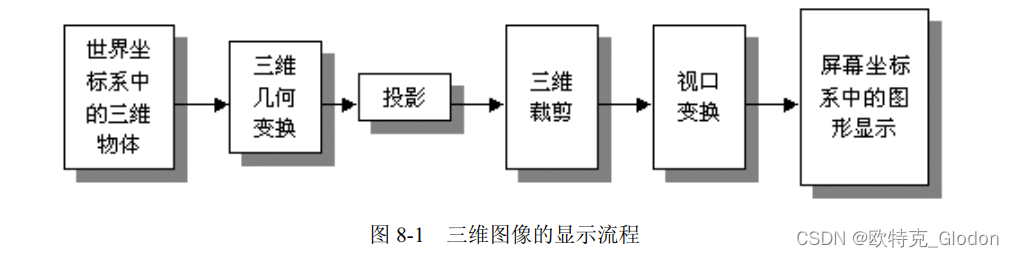
OSG编程指南<二十一>:OSG视图与相机视点更新设置及OSG宽屏变形
1、概述 什么是视图?在《OpenGL 编程指南》中有下面的比喻,从笔者开始学习图形学就影响深刻,相信对读者学习场景管理也会非常有帮助。 产生目标场景视图的变换过程类似于用相机进行拍照,主要有如下的步骤: (1)把照相机固定在三脚架上,让它对准场景(视图变换)。 (2)…...

Laplace变换-3
回忆#常见函数的Laplace变换: t z − 1 ↦ Γ ( z ) s z t^{z-1} \mapsto \frac{\Gamma(z)}{s^{z}} tz−1↦szΓ(z) (要求 R e ( z ) > 0 \mathrm{Re}(z)>0 Re(z)>0) e a t ↦ 1 s − a e^{at} \mapsto \frac{1}{s-a} eat↦s−a1…...
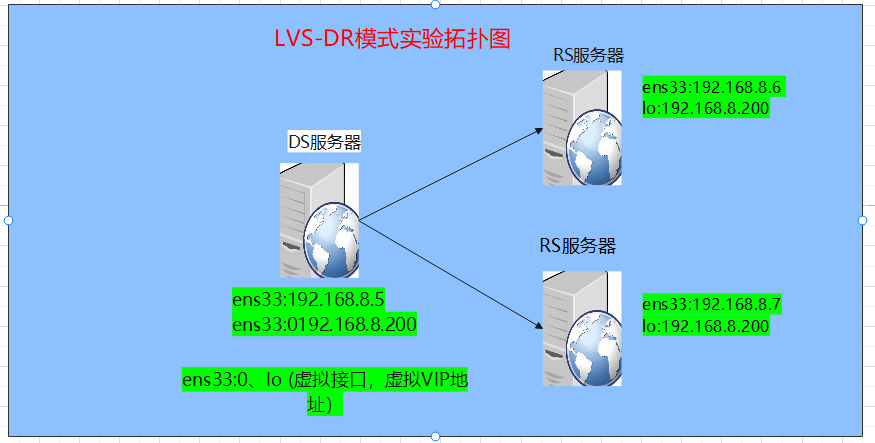
LVS负载均衡-DR模式配置
LVS:Linux virtual server ,即Linux虚拟服务器 LVS自身是一个负载均衡器(Director),不直接处理请求,而是将请求转发至位于它后端的真实服务器real server上。 LVS是四层(传输层 tcp/udp)负载均衡…...
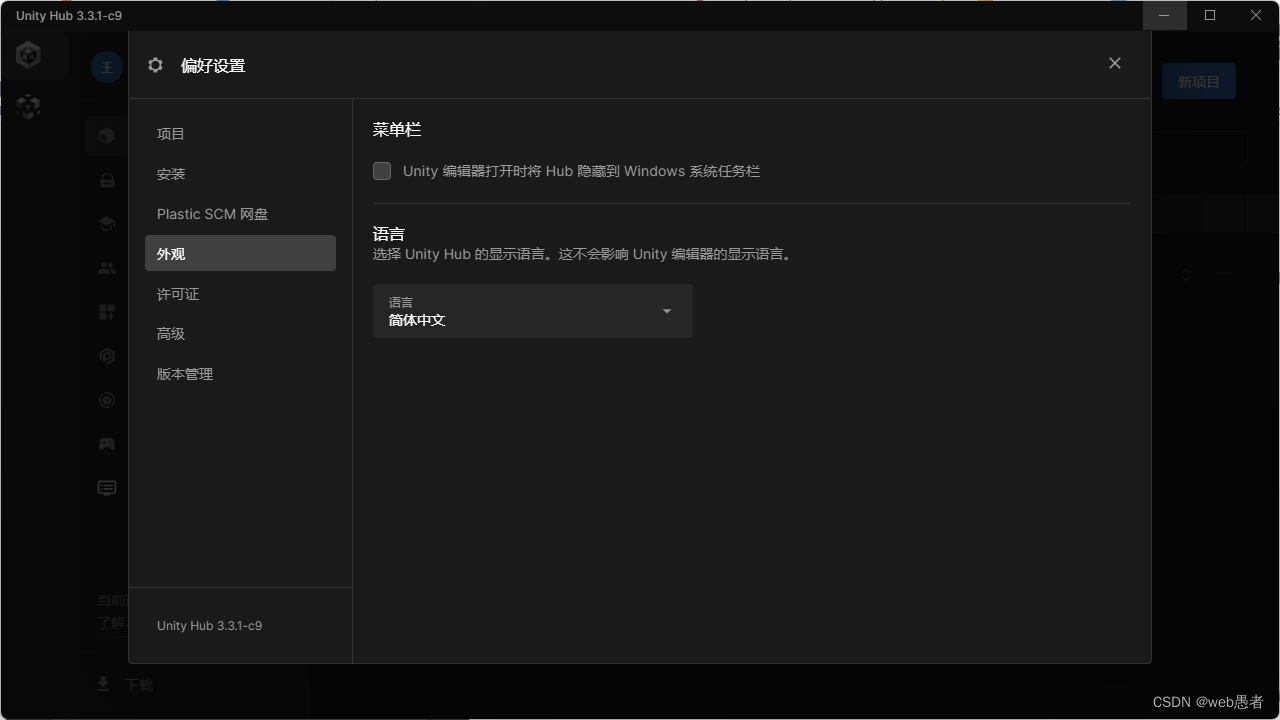
【unity】如何汉化unity Hub
相信大家下载安装unity后看着满操作栏的英文,英文不好的小伙伴们会一头雾水。但是没关系你要记住你要怎么高速运转的机器进入中国,请记住我给出的原理,不懂不代表不会用啊。现在我们就来把编译器给进行汉化。 第一步:我们打开Uni…...

【算法】KMP-快速文本匹配
文章目录 一、KMP算法说明二、详细实现1. next数组定义2. 使用next加速匹配3. next数组如何快速生成4. 时间复杂度O(mn)的证明a) next生成的时间复杂度b) 匹配过程时间复杂度 三、例题1. [leetcode#572](https://leetcode.cn/problems/subtree-of-another-tree/description/)2.…...

多维数组和交错数组笔记
1.) 关于数据的几个概念: Rank,即数组的维数,其值是数组类型的方括号之间逗号个数加上1。 Demo:利用一维数组显示斐波那契数列F(n) F(n-1) F(n-2) (n >2 ),每行显示5项,20项. static void Main(string[] args){int[] F n…...

Python(django)之单一接口展示功能前端开发
1、代码 建立apis_manage.html 代码如下: <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><title>测试平台</title> </head> <body role"document"> <nav c…...

【大模型】非常好用的大语言模型推理框架 bigdl-llm,现改名为 ipex-llm
非常好用的大语言模型推理框架 bigdl-llm,现改名为 ipex-llm bigdl-llmgithub地址环境安装依赖下载测试模型加载和优化预训练模型使用优化后的模型构建一个聊天应用 bigdl-llm IPEX-LLM is a PyTorch library for running LLM on Intel CPU and GPU (e.g., local P…...

Kubernetes示例yaml:3. service-statefulset.yaml
service-statefulset.yaml 示例 apiVersion: apps/v1 kind: statefulset metadata:...... spec:......volumeMounts:- name: pvcmountPath: /var/lib/arangodb3VolumeClaimTemplates:- metadata:name: pvcspec:accessModes: [ "ReadWriteOnce" ]storangeClassName: …...

Windows平台cmake编译QT源码库,使用VScode开发QT
不愿意安装庞大的QT开发IDE,可以编译QT源码库。 下载源码可以用国内镜像,如清华大学的:Index of /qt/archive/qt/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 我用的是 6.5.3,进去之后,不要下载整个源…...

腾讯云轻量8核16G18M服务器多少钱一年?
腾讯云轻量8核16G18M服务器多少钱一年?优惠价格4224元15个月,买一年送3个月。配置为轻量应用服务器、16核32G28M、28M带宽、6000GB月流量、上海/广州/北京、380GB SSD云硬盘。 腾讯云服务器有两个活动,一个是官方的主会场入口,还…...
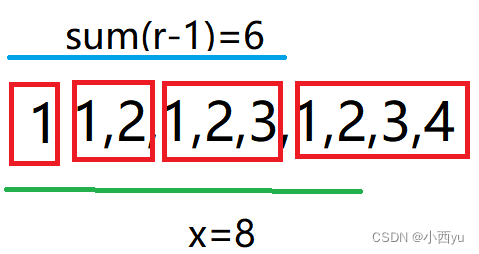
二分练习题——123
123 二分等差数列求和前缀和数组 题目分析 连续一段的和我们想到了前缀和,但是这里的l和r的范围为1e12,明显不能用O(n)的时间复杂度去求前缀和。那么我们开始观察序列的特点,可以按照等差数列对序列进行分块。如上图,在求前10个…...
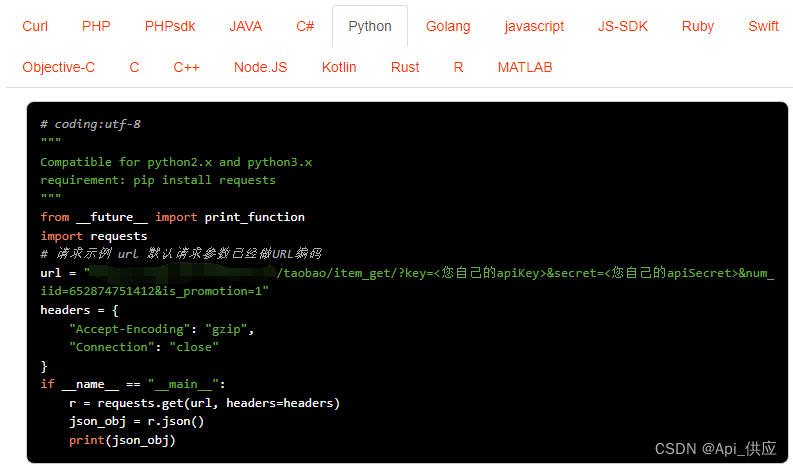
淘宝详情数据采集(商品上货,数据分析,属性详情,价格监控),海量数据值得get
淘宝详情数据采集涉及多个环节,包括商品上货、数据分析、属性详情以及价格监控等。在采集这些数据时,尤其是面对海量数据时,需要采取有效的方法和技术来确保数据的准确性和完整性。以下是一些关于淘宝详情数据采集的建议: 请求示…...
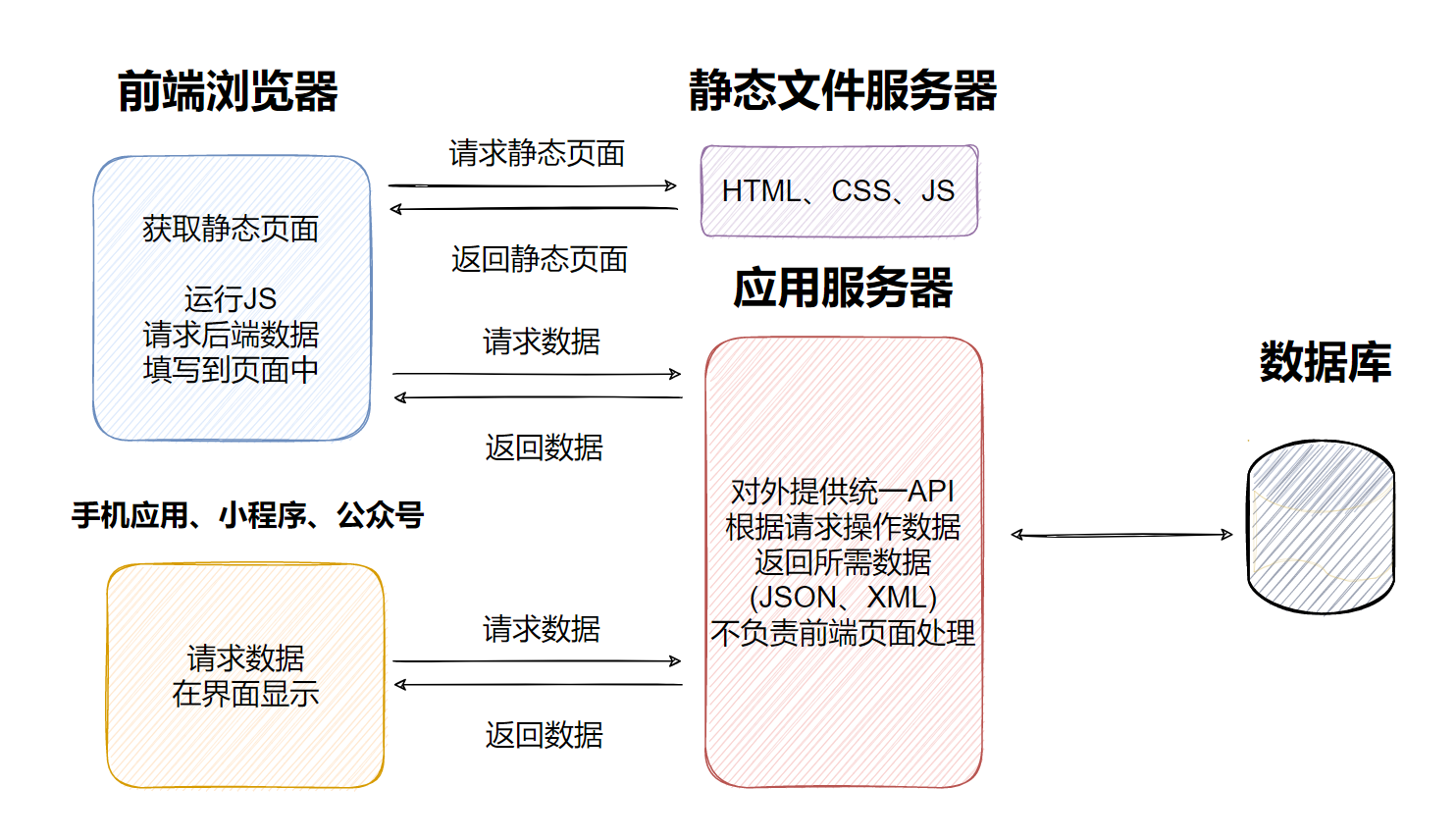
Django之Web应用架构模式
一、Web应用架构模式 在开发Web应用中,有两种模式 1.1、前后端不分离 在前后端不分离的应用模式中,前端页面看到的效果都是由后端控制,由后端渲染页面或重定向,也就是后端需要控制前端的展示。前端与后端的耦合度很高 1.2、前后端分离 在前后端分离的应用模式中,后端仅返…...

GPT提示词分享 —— 口播脚本
可用于撰写视频、直播、播客、分镜头和其他口语内容的脚本。 提示词👇 请以人的口吻,采用缩略语、成语、过渡短语、感叹词、悬垂修饰语和口语化语言,避免重复短语和不自然的句子结构,撰写一篇关于 [主题] 的文章。 GPT3.5&#…...
笔记本作为其他主机显示屏(HDMI采集器)
前言: 我打算打笔记本作为显示屏来用,连上工控机,这不是贼方便吗 操作: 一、必需品 HDMI采集器一个 可以去绿联买一个,便宜的就行,我的大概就长这样 win10下载 PotPlayer 软件 下载链接:h…...
02.percona Toolkit工具pt-archiver命令实践
1.命令作用 Percona Toolkit有的32个命令,可以分为7大类 工具类别 工具命令 工具作用 备注 开发类 pt-duplicate-key-checker 列出并删除重复的索引和外键 pt-online-schema-change 在线修改表结构 pt-query-advisor 分析查询语句,并给出建议&#x…...

【天狼启航者】研究计划
“造车”,预计在4月中旬展开(嵌入式蓝桥杯比赛结束后),这里先计划一下,不断更新。 基本要求: 使用STM32F407系列芯片,使用FreeRTOS系统。 驱动程序必须要有强大的可移植性、模块化、低耦合、简…...
面试题 之 webpack
1.说说你对webpack理解?解决什么问题? Webpack 是实现前端项目的模块化,用于现代 JavaScript 应用程序的静态模块打包工具,被webpack 直接引用的资源打包进 bunde.js的资源,当webpack 处理应用程序时,它会在内部构建一…...

CANN/pypto isfinite函数文档
pypto.isfinite 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品…...

Godot 4.x RTS游戏开发实战:从MVP内核到千单位性能优化
1. 这不是又一个“Godot入门教程”,而是一份专为RTS开发者准备的实战切片你有没有试过在Godot里拖一个Unit节点,加个move_and_slide(),然后兴冲冲地拉出十个单位——结果它们像被磁铁吸住一样挤成一团,路径重叠、碰撞卡死、指令延…...

从拉灯呼叫到闭环处理:安灯管理软件操作流程能解决哪些场景痛点?一套安灯管理软件操作流程实战
在制造工厂的生产现场,异常就像不速之客,总在最忙的时候敲门。设备突然停机、物料没送到位、质量出现批量不良……这些异常发生后,最让人头疼的往往不是问题本身,而是处理问题的过程。工人发现设备停了,扯着嗓子喊班长…...

Linux内核调试利器:/proc/sysrq-trigger原理与实战指南
1. 内核调试的“后门”:/proc/sysrq-trigger 深度解析在Linux内核开发和系统调试的深水区,当系统完全无响应、键盘鼠标失灵,甚至SSH连接都彻底中断时,常规的调试手段往往束手无策。这时,一个隐藏在/proc文件系统中的特…...
)
Midjourney单色调风格失效诊断图谱(含8种典型失败案例+对应--no、--style、--seed三重校准方案)
更多请点击: https://intelliparadigm.com 第一章:Midjourney单色调风格失效诊断图谱(含8种典型失败案例对应--no、--style、--seed三重校准方案) 单色调(Monochrome)图像生成在Midjourney中高度依赖提示词…...

ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署
更多请点击: https://kaifayun.com 第一章:ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署 环境准备与API密钥获取 首先注册ElevenLabs账号并进入 Profile → API Keys页面,生成…...

PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发
PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发 【免费下载链接】vscode-intelephense PHP intellisense for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-intelephense PHP Intelephense是一款为Visual Studio …...

如何免费获取百度文库文档:三步实现纯净打印保存的实用技巧
如何免费获取百度文库文档:三步实现纯净打印保存的实用技巧 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要…...

为什么你的蓝晒图总像“褪色老照片”?3个被忽略的--stylize权重陷阱,今晚失效前速查
更多请点击: https://kaifayun.com 第一章:蓝晒法的光学本质与数字转译悖论 蓝晒法(Cyanotype)作为一种1842年诞生的古典摄影工艺,其核心依赖于铁盐在紫外光照射下发生的光还原反应:柠檬酸铁铵与铁氰化钾…...

独立开发者如何利用Taotoken的透明计费规避项目超支风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的透明计费规避项目超支风险 对于独立开发者而言,项目预算的控制是决定项目能否持续、健康…...