超详细——集成学习——Adaboost实现多分类——附代码
资料参考
1.【集成学习】boosting与bagging_哔哩哔哩_bilibili
集成学习——boosting与bagging
强学习器:效果好,模型复杂
弱学习器:效果不是很好,模型简单
优点
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。
集成学习算法需要关注的问题
1、个体学习器如何训练得到?改变训练数据或概率分布如何改变?
2、如何将个体学习器组合?
分类
boosting
个体学习器存在强依赖关系、必须串行生成序列化方法。
工作机制:
一、提高那些在前一轮被弱分类器分错的样本权值,减小那些在前一轮被弱分类器分对的样本的权值,使误分的样本在后续受到更多的关注。体现了串行。
二、加法模型将弱分类器进行线性组合。
举例:
比如我们现在要去参加期末考,有三个科目。假设你有三个分身,分身A学习语文的成绩比较好,但是数学跟英语的学习比较差。这个时候我们就派分身B上场,我们可以减少他学习语文的时间,增加他学习英语数学的时间,但是我们又发现他数学学的不错,但是语文跟英语学的不好。所以这时候我们就用分身C,同样,我们加大其对英语的学习力度,减少其对语文数学的学习比重,所以学习出来就是英语学的比较好,等到我们期末考的时候我们再将其收回来也就是说组合起来再去参加期末考,这样一来语文数学英语都能得到比较高的分数。

所谓的加法模型其实就是给这些学习器附上一个相应的权重,通过相加让他们组合起来。
代表算法:
Adaboost
GBDT
XGBoost
LightGBM
bagging
个体学习器间不存在强依赖关系、可同时生成并行化方法。
工作机制:
一、从原始样本集中抽出k个训练集。
回答了我们上面所提到问题:改变训练数据或概率分布如何改变?
意思就是假如我们这里有k个弱学习器,那我们就会抽取k个训练集
分配给这k个学习器去进行学习,他抽样过程中所采取的抽样方式是有放回抽样。
1、有放回抽样:每轮从原始样本集中使用Bootstraping法(即自助法,是一种有放回的抽样方法,可能抽到重复的样本)抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中.共进行k轮抽取,得到k个训练集.(k个训练集相互独立)
2、随机森林中,还会随即抽取一定数量的特征
二、k个训练集分别训练,得到共k个模型体现了并行。
三、将上步得到的k个模型,通过一定方式组合起来。
1、分类问题:将上步得到的k个模型采用投票的方式得到分类结果,因为我们每个人学到的东西都不一样,面对一个问题的时候,大家就需要通过投票去进行表决,有的人票权比较大 ,有的人票权就比较小,也是一种线性加权的方式组合起来。
2、回归问题:
计算上述模型的均值作为最后的结果。
举例:

我们上面提到我们需要给这个数据集有放回的进行采样,比如我们第一个数据集采的是第一个跟第三个样本,构建了我第一个数据集。
采样的时候他除了随机采样之外,他还会对特征进行采样,比如他随机采样了这两个特征。

最后我们的数据集拿到的是这四个格子组成的数据,也就是说他加上了对特征的随机采样。那这就是第一步,采集数据。

将我们这k个训练集分别训练,得到共k个模型,体现了并行,这几个学习器之间是互不影响的,我们可以去同时执行。这就解决了我们上面提到的第一个问题
代表:
随机森林
Adaboost
解决的是二分类问题
数学表达:

首先其整体的模型采用的是加法模型
这里的到
都是弱分类器,也叫做基分类器 。
1、在每一轮中,分别记录好那些被当前弱分类器,正确分类与错误分类的样本在下一轮训练时,提高错误分类样本的权值,同时降低正确分类样本的权值,用以训练新的弱分类器
这样一来,那些没有得到正确分类的数据,由于其权值加大,会受到后一轮的弱分类器的更大关注。
2、加权多数表决:加大分类误差率小的弱分类器的权值,使其在表决中起较大作用。减小分类误差率大的弱分类器的权值,在其表决中起较小的作用。
如何理解权值?

比如在这里我们这一开始三个样本的权值所占的比例都是一样的,都是1/3,假设经过第一轮的学习之后,其成功的将后面的,
这两个样本进行了正确的分类,所以第二轮的时候我们就将第二轮的比例调为了1/6.学习错误的样本 ,我们就将其调整到2/3。也就调到了下面这样的样本。也就是说相当于我们改变了样本的数量,也就是我们将没有正确训练的样本的数量将其增多了。然后这两个正确分类的数量,占比就变少了。在学习的过程中,我们就会更关注被分类错误的样本。

再回到这里,我们的权值也会受到我们的分类误差率的影响,当我们的分类误差率小的的时候就会给一个较大的权重
,这样做就会在最后做表决的时候起到的作用更大。
算法流程:
二分类训练数据集:

这个数据集就是。这里面有
个训练样本。
就是我们的实例,也相当于我们的特征值。
指的是我们的标签值,因为我们这里做的是二分类,所以这里就只有两类,这里就分别为
这两类。
定义基分类器(弱分类器) :
:
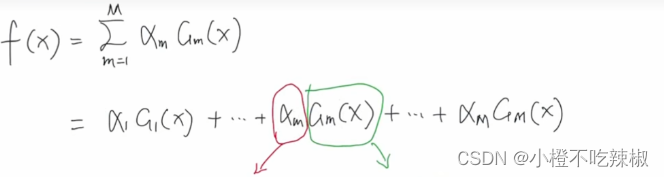
一般来讲我们这里的到
他们一般都属于同一种类型,我可以是逻辑回归,也可以是决策树。通常来讲,在你指定了基分类器具体是哪一个之后,
到
用的就都是同一种。比如你这里
是逻辑回归了,那这里就都是逻辑回归了。
在我们的基分类器定下来之后,他的之后的随之的方法也就确定下来了,比如当我们的是逻辑回归的时候,我们就可以用交叉熵损失和梯度下降来进行训练,
 ,我们的书上也有这样一个最简单的二分类取值器,也就是说它只需要去给定一个阈值,当我们的X大于这个阈值的时候他就为1,小于这个值的时候就为-1.通过这个阈值来进行划分。这也是我们最简单的一种分类器了。
,我们的书上也有这样一个最简单的二分类取值器,也就是说它只需要去给定一个阈值,当我们的X大于这个阈值的时候他就为1,小于这个值的时候就为-1.通过这个阈值来进行划分。这也是我们最简单的一种分类器了。
循环M次:
在上面两个都准备好了之后,我们就可以去训练我们的模型。
循环m次就是说,我们每一次去训练一个基分类器以及他的权重,然后我们有m个所以这里我们就循环m次。
1、初始化/更新当前训练数据的权值分布:
初始化,初始化的时候我们就用D1这个权值来表示,

每一个样本我们都给其赋了权值,我们认为其是均匀的,1/N,
更新数据的权值分布:
之前我们是计算了,之前的数据是进行了一个权值的初始化,之后我们的
需要用到的数据就不一样,我那么知道我们要提高前一轮“错误分类"的样本的权值,降低前一轮"正确分类"的样本的权值以此来构建我们的训练样本去训练我们
,如果我们不是第一次了我们就是执行我们样本更新。

这里我们的这个m下标表示的就是第几个弱分类器训练样本的权值,然后我们这里有N个样本,每个样本都会有它的权值,这里的重点就是我们
这个权值的更新的这个公式,我们也可以清楚的看到这是一个递推公式,它的更新跟前一轮的权值是有关系的,看着比较复杂,但是目的就是为了满足我们下面绿色的那些字。
解释:
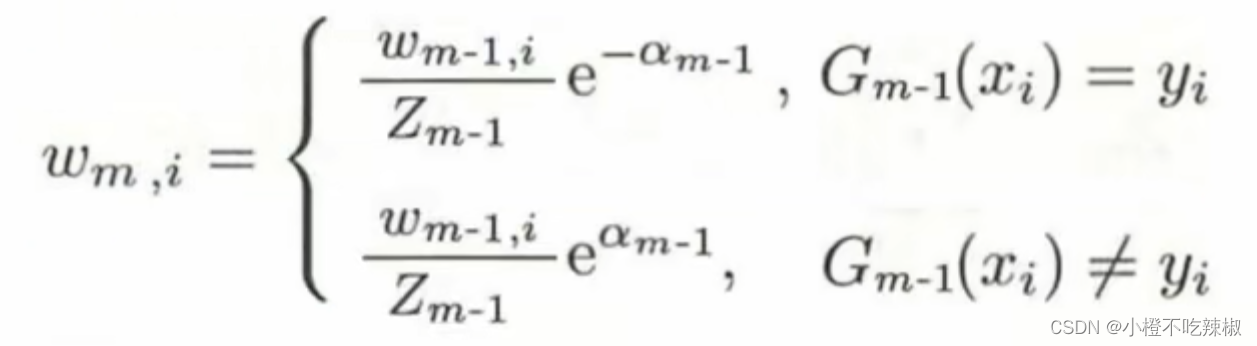
也就是说,当我们是正确分类的时候(假设为二分类问题,正确分类的标签值为1),我们的弱分类器得出来的结果跟我们的标签值
是同号的,所以
,如果是异号的那就是上图下面的结果。
我们也提到了我们的肯定也是大于0小于等于1/2的,
当我们分类正确时, 当前面加了符号之后呢这个整体就是一个小于1大于0的数。
当前面加了符号之后呢这个整体就是一个小于1大于0的数。
当我们分类错误时, 这个整体就是大于1的
这个整体就是大于1的
我们再来看我们的规范化因子
规范化因子

上图我们针对的是某一个样本,在下图我们针对的是所有的样本
在下图中我们将所有样本的分子部分加起来,本质上相当于是一个归一化的操作
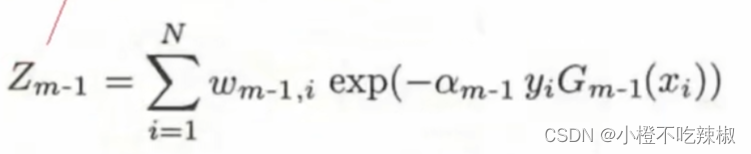
其实 就是将我们下面红色部分映射到0到1之间的范围,也就相当于一个归一化的操作

2、训练当前基础分类器:
紧接着我们就要拿训练的样本去训练,使用具有权值分布的训练数据集学习,得到基分类器
,那么我们应该如何训练呢,具体怎么训练就应该看我们当初选择的基分类器的类型是什么样的,如果我们用的是逻辑回归,那么我们用的就是交叉熵损失作为我们的损失函数,训练好了之后我们就要去计算我们的权值
。
3、计算当前基分类器的权值:
我们知道我们的由我们的分类误差率所决定,比如我我们的分类误差率比较大的话就得让我们的
比较小,如果分类误差率比较小的话就说明比较准。
第一步:
所以我们先计算当前在训练数据集上的分类误差率
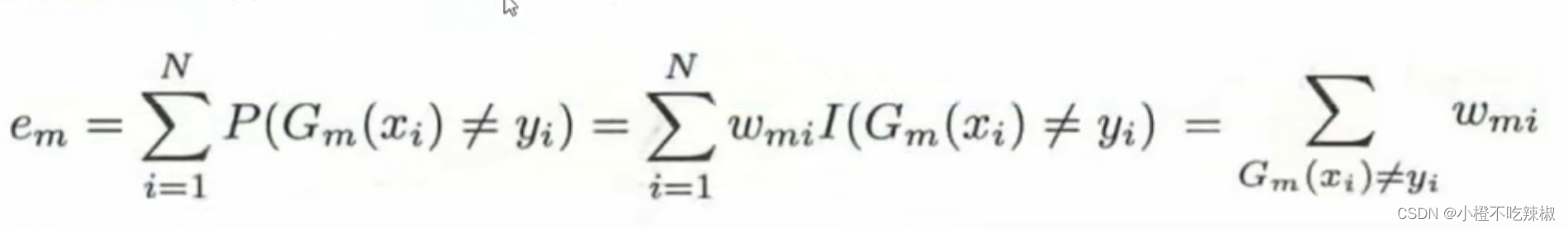
这个就是我们的公式,当我们的的结果不等于我们真实值标签
的时候就说明我们分类错误了。这里面
的含义就是当括号里的条件满足的时候,这个
的值就是1,表达的意思就是在我们1到N那么多个样本里面,我们要找到他分类错误的这些点,然后让他们这些样本点的这些权值让他们加起来,这里的
指的就是我们的权值,即样本数据的权值部分,如下图所示。所以进一步的可以写成我们最右边的那个式子。
 代表的就是分类错误的那些点的权值给他进行一个相加求和。
代表的就是分类错误的那些点的权值给他进行一个相加求和。
但这里我们值得一提的是我们这里分类误差的范围,其范围也是确定的。
![]()

这里我们的>0我们不再解释,这里的≤0.5是如何来的呢,比如说当我们的
训练出来的一个模型去做预测的时候,跟我们的的
呈现的是上图这样的关系,比如他预测的时候错了三个,只有一个是预测对了,又因为我们这里是二分类的问题,所以我们的
不是-1就是1,所以我们只需要在
前面加一个负号就会从上面变换到下面的1,1,1。也就是说我们将从三个错误的结果当中变成了三个正确的一个错误的,也就是说我们 分类误差率从原本的3/4变到了1/4。也就是当我们的分类误差率大于0.5的时候就可以得到一个小于等于0.5的一个数,所以这个范围就是小于等于0.5。
将我们的分率误差率计算出来就可以计算我们的
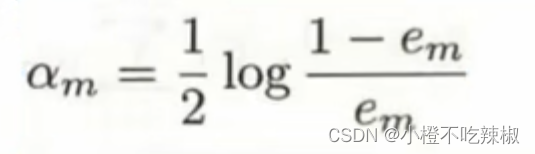
![]()
在这里我们对这个公式进行分析
 我们画一下这个的函数图像,这里的
我们画一下这个的函数图像,这里的是未知数
然后我们又知道是满足
![]()
故函数图像为,带入我们的=1/2。得到他的值为1
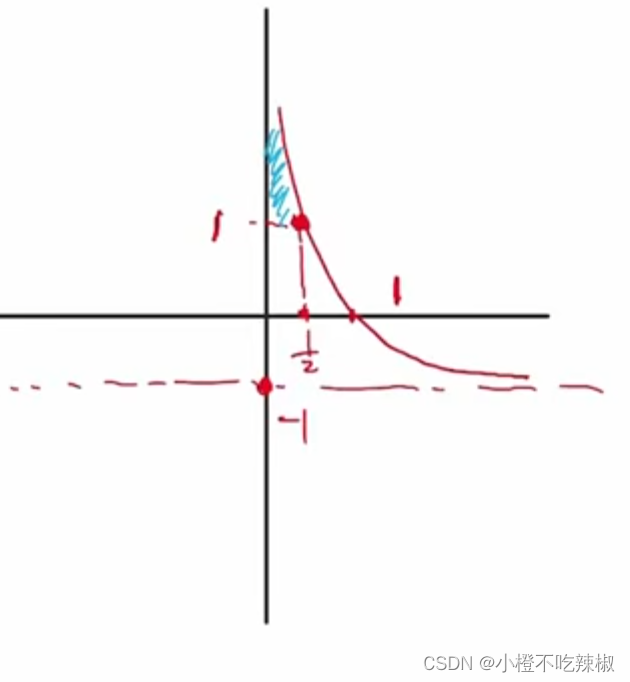
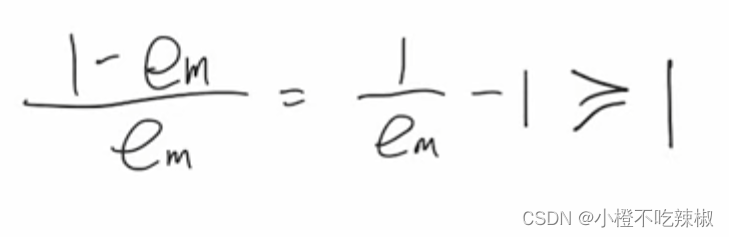 ,由上面
,由上面的定义域可以知道我们蓝色部分就是当前讨论函数的取值范围,然后我们继续探讨log的部分。


这个就是我们log的图像,然后我们的为大于等于1,所以我们的
log的部分就可以这样画。

所以他的值域就在上面的部分我们也知道就是大于等于0的。

故我们的图像也会往右边移动,所以我们的就会跟着变大
4、将更新到加法模型
中
![]()
5、判断是否满足循环退出条件:
分类器个数是否达到M:比如可以设置我们M的值,到达了循环三次,M为3,我们就退出。或者给定一个精度,当我们的准确率到达了多少的时候我们就去退出。
总分类器误差率是否低于设定的精度:因为我们这里的他最终算出来的其实是一个数,他不是某一个类别,所以我们需要通过一个函数
去转换到我们所需要的一个类别,比如说我们在这里
,它的
≥0的时候,那我们最终的结果就是1,当
<0的时候分配出来的结果就是-1。
假设我们这里循环退出的条件并没有达到,也就是说m=1的时候,那我们就接着进行第二次循环去计算,我们回到上面的更新。
例题:
二分类训练数据集:

首先我们有一个二分类的训练数据集,我们需要去运用adaboost去训练出一个二分类的学习器,能够根据他给出的x能够去判断出他给出的y值是属于1还是-1

定义基分类器(弱分类器):
,
 ,我们就采用这种最简单的二分类学习器,也就是给定义一个阈值,通过这个阈值去判断。
,我们就采用这种最简单的二分类学习器,也就是给定义一个阈值,通过这个阈值去判断。
训练方法:
在x中划分出候选阈值,从中选出使得误差率最小的,作为我们的最终阈值构建好
循环M次:
m=1时:
1、初始化/更新当前[训练数据的权值分布]
if初始化:
看到我们的训练数据,可以肯定的是一个均值分布,所以是就是1/10
,
if更新:
2、训练当前基分类器
使用具有权值分布的训练数据集学习,得到基分类器
。
训练方法:在x中划分出各候选阈值,构建好各候选。找到使误差率
最小的
,作为本轮的基分类器

3、计算当前基分类器的权值
计算当前在训练数据集上的[分类误差率]


根据这个表可以看出来,绿色部分就是我们分类错误的部分
根据分类误差率,计算基分类器
的权重系数


4、将更新到加法模型
中

5、判断是否满足循环退出条件
①分类器个数是否达到M
②总分类器误差率是否低于设定的精度
在这里我们使用第二个


因为这一题的最终答案是可以做到最终完全是零错误的,所以就还没有达到我们的精度要求,所以我们就继续进行下一个循环
m=2时:
1、初始化/更新当前[训练数据的权值分布]
if初始化:

将我们上一轮得到的还有
还有
,还有上一轮样本数据的权值带入就可以的出来就可以得到
if更新:

上图就是我们算出来的一个结果,就是这些
2、训练当前基分类器
使用具有权值分布的训练数据集学习,得到基分类器
。
训练方法:在x中划分出各候选阈值,构建好各候选。找到使误差率
最小的
,作为本轮的基分类器

3、计算当前基分类器的权值
计算当前在训练数据集上的[分类误差率]
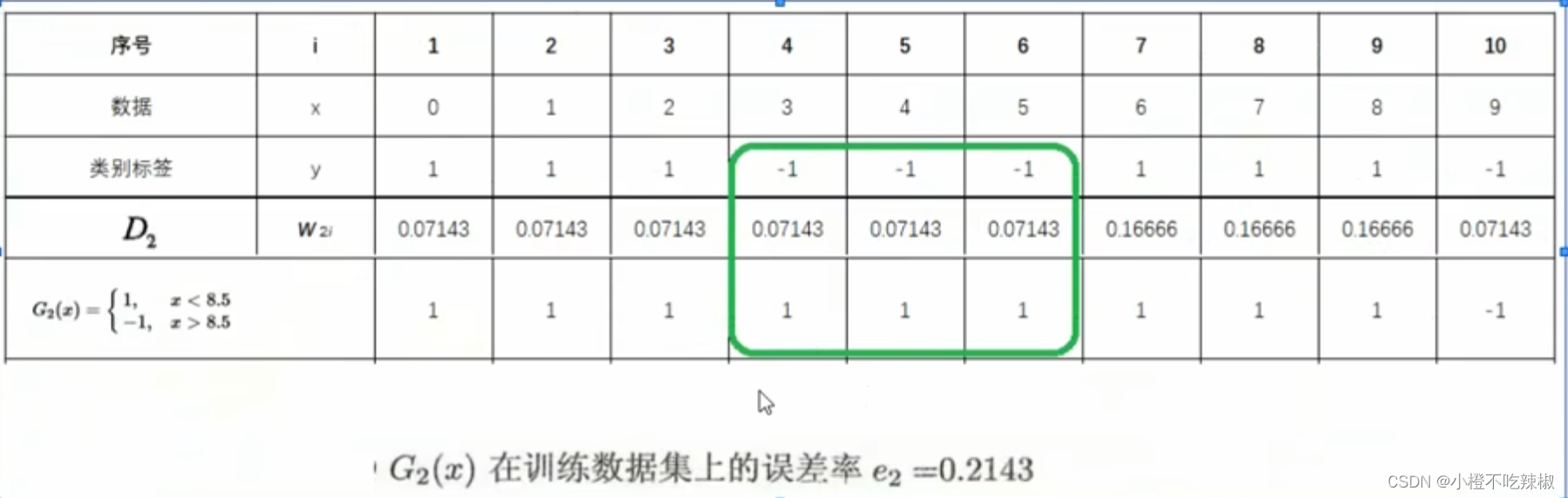
我们这个分类器还是存在着三个错误分类的点,然后我们将三个错误分类的点 三个权值给他加起来得到了
根据分类误差率,计算基分类器
的权重系数
![]()
4、将更新到加法模型
中

5、判断是否满足循环退出条件
①分类器个数是否达到M
②总分类器误差率是否低于设定的精度

在这里我们还是有三个错误分类的点,所以还是没有达到我们的要求,之前我们也说过这是可以达到我们的百分百分类的,所以我们继续进行循环。
m=3时:
跟上面的一样
1、初始化/更新当前[训练数据的权值分布]
2、训练当前基分类器
3、计算当前基分类器的权值
4、将更新到加法模型
中

5、判断是否满足循环退出条件
①分类器个数是否达到M
②总分类器误差率是否低于设定的精度
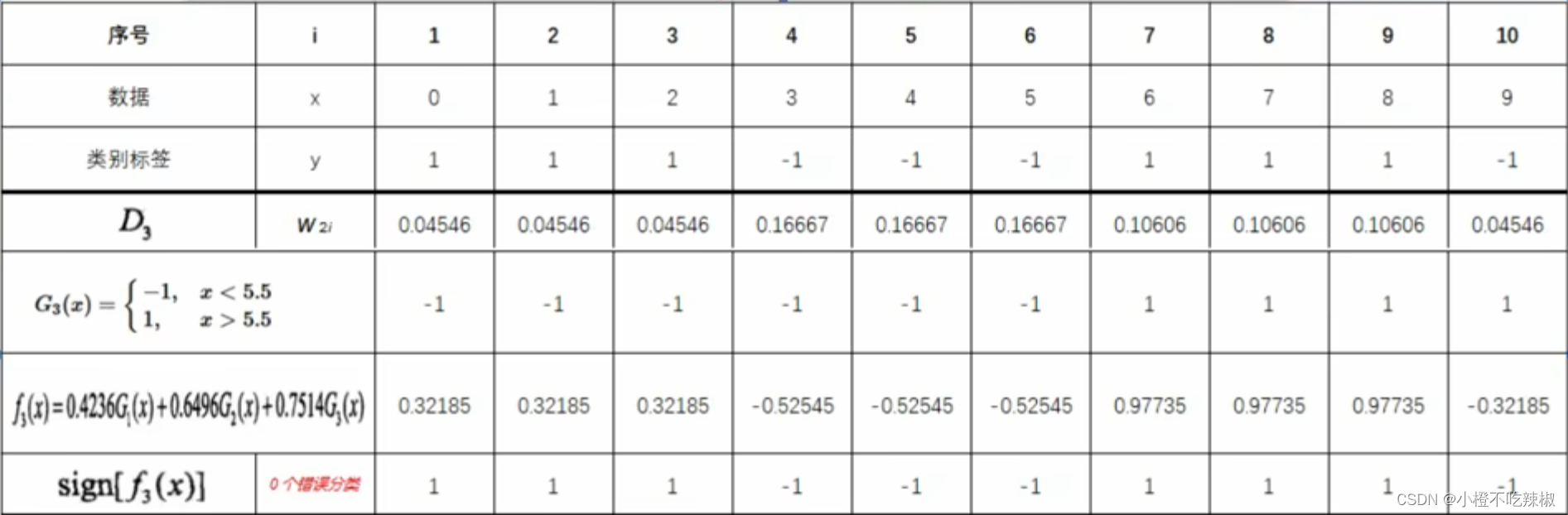
在这里我们还是有三个错误分类的点,所以还是没有达到我们的要求,之前我们也说过这是可以达到我们的百分百分类的,所以我们继续进行循环。
这个时候我们就发现完完全全都对的上了,就是没有错误分类的那些点了。
最终分类器

加法模型
预测函数

首先加法模型就是将很多学习器进行一个线性加权的组合,所以是一个累加的符号。
这里的指的就是我们Adaboost里的弱分类器,
指的就是我们弱分类器里面的训练参数
类比一下我们Adaboost的预测函数:可知道Adaboost就是一个加法模型
 当然他只包含线性的部分,不包含做决策的部分,因为我们最后还要通过
当然他只包含线性的部分,不包含做决策的部分,因为我们最后还要通过函数,唯一长得不太一样的地方就是其中的参数部分,只是我们省略没有写而已。
损失函数
自定义![]() ,y就是我们的label值(标签值),f(x)就是我们这里的加法模型
,y就是我们的label值(标签值),f(x)就是我们这里的加法模型
当我们面临
回归问题:我们可以使用MSE均方误差
分类问题:指数函数,交叉熵损失
损失函数我们需要看具体的情况来定,也可以定义属于自己的损失函数。
优化方法
像逻辑回归,FM,FFM等等用的就是梯度下降来优化损失函数来找到参数。
在这里我们的加法模型不太适合用梯度下降,而是适合用前向分布算法的方式。
梯度下降的缺点:整体损失极小化:
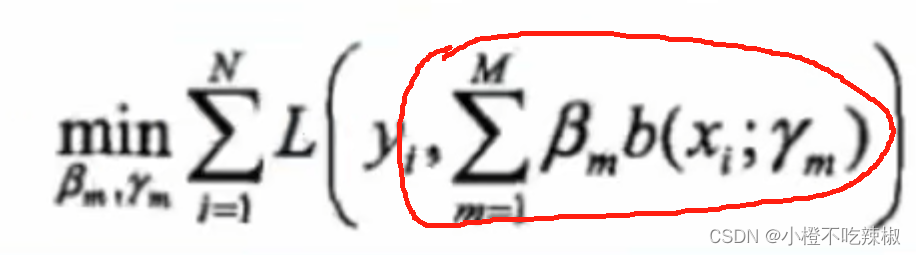 首先要把我们的目标函数写出来,所以我们需要我们的整体损失极小化,因此我们的损失函数指的是我们总体的一个损失,也就是从我们的1到M都加起来去求损失,这样一来我们的复杂度就高。
首先要把我们的目标函数写出来,所以我们需要我们的整体损失极小化,因此我们的损失函数指的是我们总体的一个损失,也就是从我们的1到M都加起来去求损失,这样一来我们的复杂度就高。
举例

假设我们的M再大一点比如说3,那我们就还要优化,就要同时优化3*M个参数,这也只是一个理想情况,
这里只代表了一个参数,很多情况下
代表的不只是一个参数,也很有可能表示的是一个向量,比如在逻辑回归里,这里代表的是很多个w,很多个特征权重值,需要同时优化的参数就非常多。
前向分布算法:

对比梯度下降(蓝色方框部分) ,我们就没有了累加的符号。
这样做会有什么效果呢?
我们刚刚说了,在我们的传统梯度下降当中,我们需要同时对β还有γ同时进行优化跟迭代。但是在我们的前向分布算法当中,我们会将这些参数进行分布的计算。比如我们会先计算,然后再计算
,然后再计算
,也就是对应了这里的循环m。也就是我们计算的时候只会拿到一个
一个
。
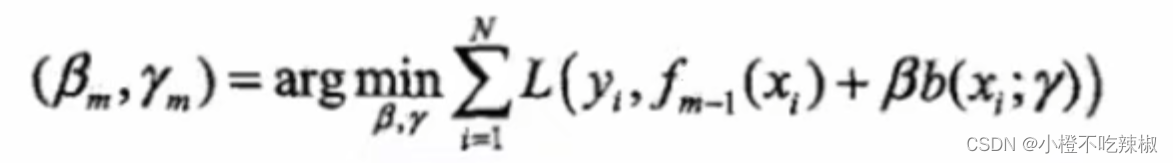
并且我们观察到,在这个式子里面, 这个部分属于上一步得到的加法模型,上一步计算出来的东西在这一步已经是一个定值了,也就是说里面以及没有所谓的参数了,所以我们只需把精力集中在当前需要去优化的基分类器还有它的权重参数就可以了,这样也体现了一个串行的思想。
这个部分属于上一步得到的加法模型,上一步计算出来的东西在这一步已经是一个定值了,也就是说里面以及没有所谓的参数了,所以我们只需把精力集中在当前需要去优化的基分类器还有它的权重参数就可以了,这样也体现了一个串行的思想。
比如这个部分我们就代表了语文,我们语文已经学习的很好了,那我们下一步就是重点去学习我们其他的科目,是标签值。
然后学完了之后我们就去更新,然后一步一步的去循环整个过程,直到把这M个给学到最后就可以得到我们总体的一个加法模型。
Adaboost算法原理解析
在讲完我们的加法模型之后,我们再来讲讲adaboost是如何利用加法模型还有前向分布算法来结合巧妙的构思从而去实现我们这两个要求的。

优化问题:二分类
二分类训练数据集,下图是其定义

在这里我们的类别标签分别用-1跟+1表示。在逻辑回归的时候,我们习惯性的用0跟1表示类别,但在Adaboost里面我们习惯性用-1跟+1表示类别。
模型:加法模型

最终分类器:
 、
、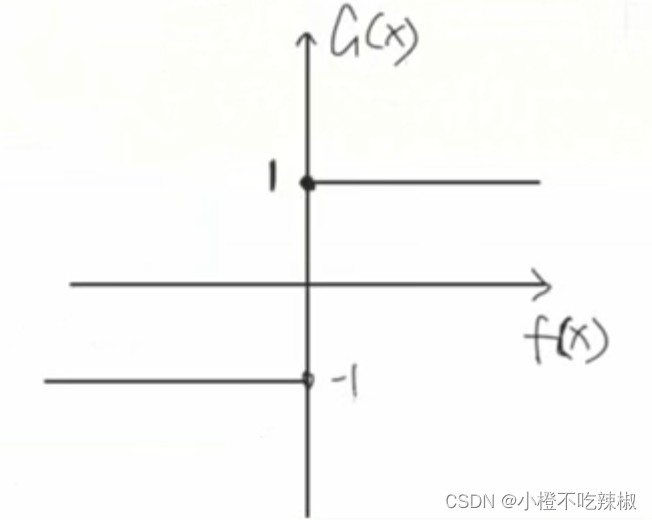
这里Sign函数的意思就是当我们上面的加法模型得到的,当它的值是大于等于0的时候,
就属于1;当他小于0的时候,
就为-1,从而去把两个类给分开,所以我们这里的0来作为他分割类别的阈值。
损失函数:指数损失函数
二分类问题,使用指数损失函数:
![]() ,exp是以e的底的指数函数
,exp是以e的底的指数函数
y是标签值
当G(x)分类正确时,与y同号,L(y,f(x))≤1.
当G(x)分类错误时,与y异号,L(y,f(x))>1.
为什么不用交叉熵损失?
交叉熵损失是用极大似然估计去计算出来的一个表达式,它的分类是0跟1,不是我们的-1跟1
所以当我们标签值y为1的时候,当我们G(x)分类正确的时候,那我们对应的f(x)肯定也是一个大于等于0的一个数,故L(y,f(x))≤1,并且我们这个f(x)越大的话我们L的这个损失就会越小,反之亦然。
将损失函数视为训练数据的权值:

这样的一个损失函数就非常适合在作为我们训练数据的权值
![]()
这个公式的意义就是我们第m轮训练数据的里面每一个训练数据的样本的权值就可以通过这个公式来进行计算。就是前一轮的。由这个公式就去更新我们训练数据的权重。
单个样本损失函数
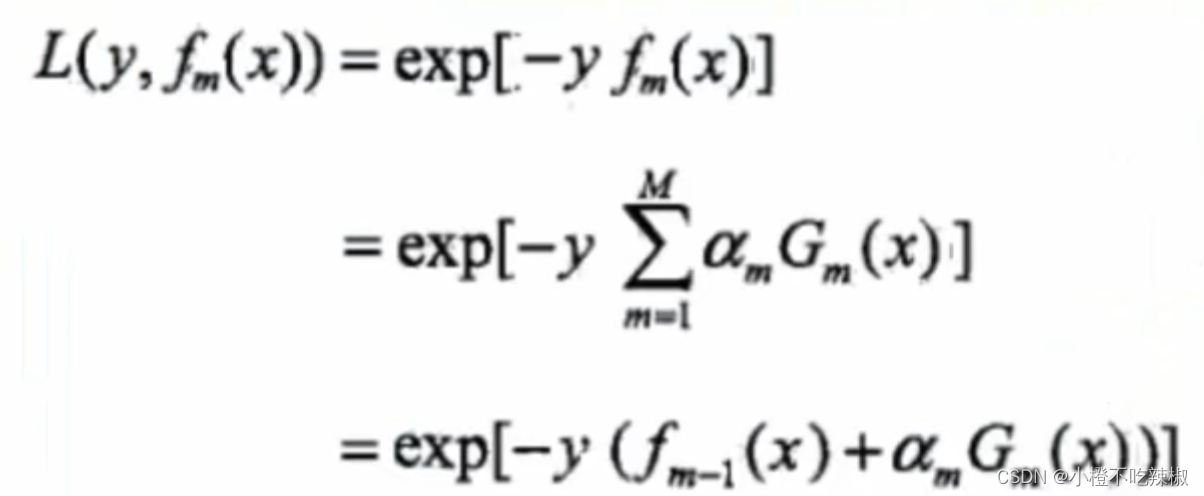
总体损失函数(把所有样本放进去)

我们有N个样本
优化方法:前向分布算法
算法流程我们之前讲加法模型的时候就讲过了
第m轮
我们将我们要极小化的损失函数放下来

L换成了exp指数函数。
式子变换:
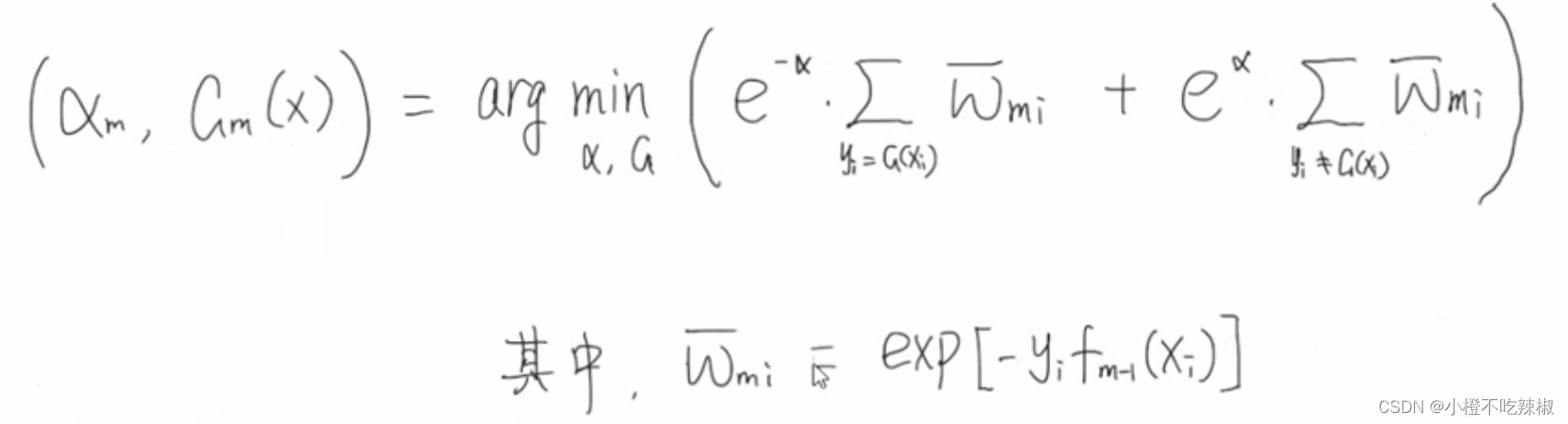
推导过程:

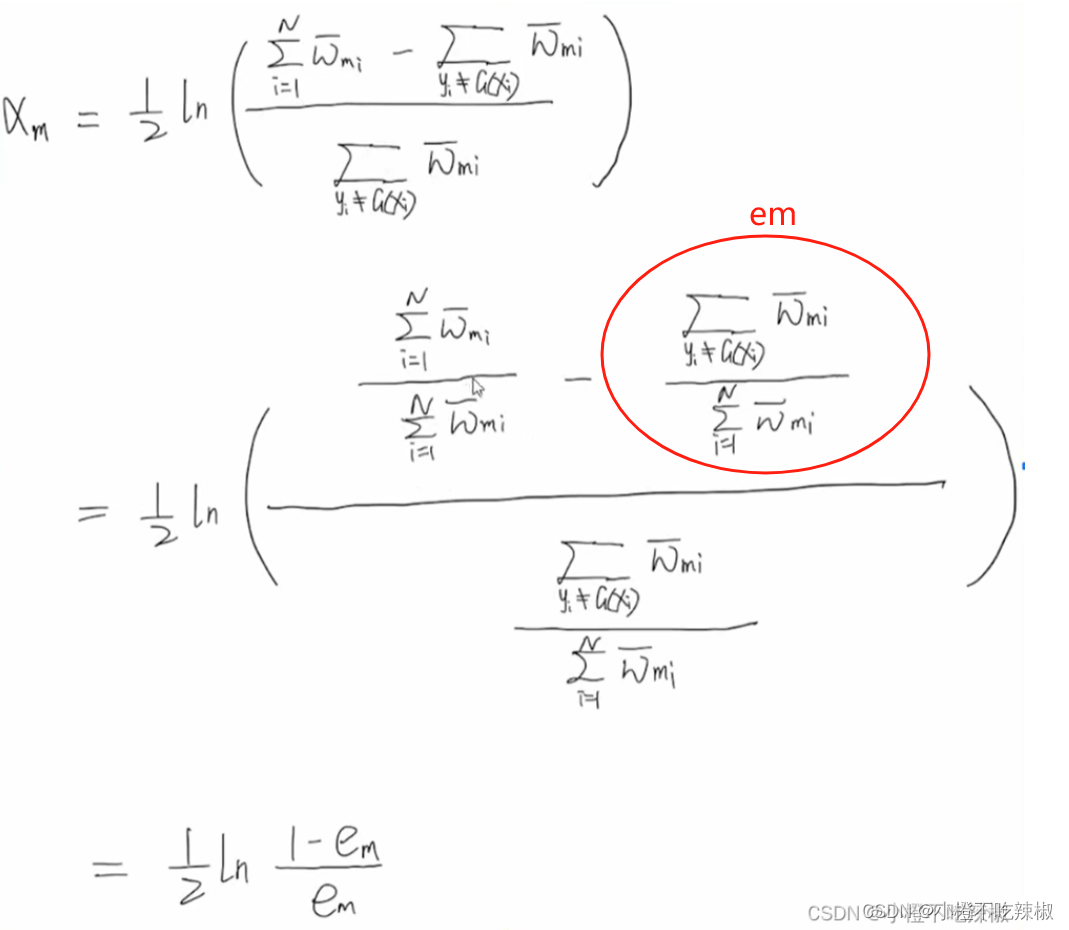
求解
1、优化

用构建好的训练样本去训练的时侯,会得出分类误差率最小的一个效果,那就是最优的。
从本身的意义上来讲,最优的
当然要使得误差最小

当括号里面条件成立的时候就是1,
指的就是样本的权重
2、优化

推导过程:
式子变换:

凸优化:

红色的部分就是我们的定值了,只有蓝色箭头的是一个变量,我们只需对这个函数的
求导,让其导数等于0,就可以知道其最小值了。

导数为0


公式转换

这里我们分类误差率就是所有分类错误的点除以样本点
3、前向更新
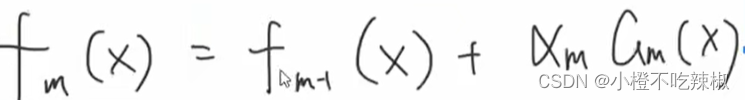
4、更新训练数据权值
如果我们这里是第m轮的话,这里就是m+1轮

将第二个式子与我们之前的式子做对比 ,这个式子相比于上面的显然没有递推的关系,我们可以看一下其是如何推导出来的
,这个式子相比于上面的显然没有递推的关系,我们可以看一下其是如何推导出来的
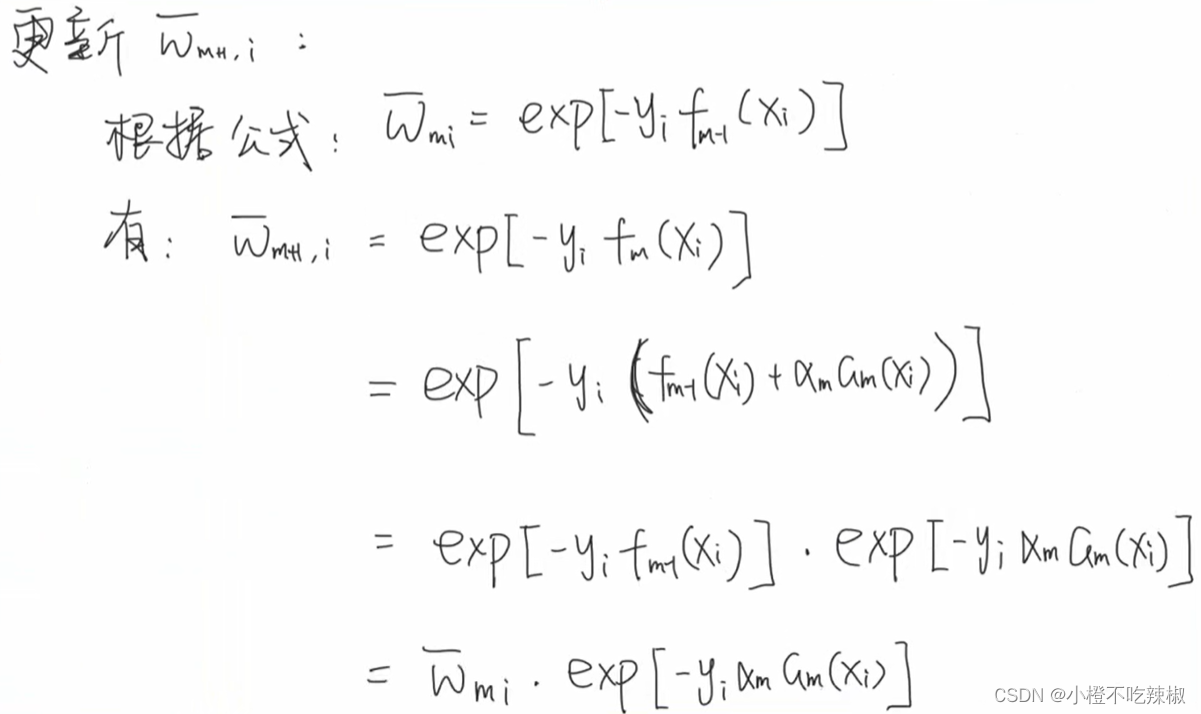
注意事项
在我们的例题这里的分类误差率跟我们算法原理解析不一样的原因是上图的
其实是已经规范过了的,也就是说他已经将他已经映射到我们0到1之间的概率空间了,已经是一个概率了。而我们下图的
不是概率,而是损失。
如果要讨论这两个不同的地方,我们需要去看训练数据更新的他们的区别在哪里。分别对应的如下。
上图是例题的,下图是算法原理里面的
我们可以看到他们之间的区别只是在于第一个他除了,他的作用也只是说把其概率限制在了0到1之间,区别就是一个做了归一化一个没有做归一化,其凸优化求解过程都是一样的。
代码
资料参考:
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, recall_score, f1_score, precision_score
import seaborn as sns
import matplotlib.pyplot as plt# 创建一些模拟的多类别数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=0,random_state=42, n_classes=3, n_clusters_per_class=1)# 将数据集分割成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建AdaBoost模型实例
# 使用决策树桩作为基本分类器
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1), n_estimators=10,algorithm="SAMME", learning_rate=0.5, random_state=42)# 训练AdaBoost模型
ada_clf.fit(X_train, y_train)print("建立的弱分类器:", ada_clf.estimators_)
print("分类误差:", ada_clf.estimator_errors_)
print("分类器权重:", ada_clf.estimator_weights_)
print("迭代速率:", ada_clf.learning_rate)# 进行预测
y_pred = ada_clf.predict(X_test)print("\n---------- 模型评价 ----------")
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
df_cm = pd.DataFrame(cm) # 构建DataFrame
print("ConfusionMatrix", df_cm)
print('Accuracy score:', accuracy_score(y_test, y_pred)) # 准确率
print('Recall:', recall_score(y_test, y_pred, average='weighted')) # 召回率
print('F1-score:', f1_score(y_test, y_pred, average='weighted')) # F1分数
print('Precision score:', precision_score(y_test, y_pred, average='weighted')) # 精确度# 绘制混淆矩阵的热图
plt.figure(figsize=(8, 6))
sns.heatmap(df_cm, annot=True, fmt="d", cmap="Blues")
plt.title("Confusion Matrix")
plt.xlabel("Predicted label")
plt.ylabel("True label")
plt.show()# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Model accuracy: {accuracy:.2f}")
参考资料
【集成学习系列教程1】AdaBoost分类算法原理及sklearn应用_adaboost sklearn-CSDN博客
Adaboost分类算法原理及代码实例 python_adaboost python-CSDN博客
集成学习算法:AdaBoost详解以及代码实现-CSDN博客
相关文章:
超详细——集成学习——Adaboost实现多分类——附代码
资料参考 1.【集成学习】boosting与bagging_哔哩哔哩_bilibili 集成学习——boosting与bagging 强学习器:效果好,模型复杂 弱学习器:效果不是很好,模型简单 优点 集成学习通过将多个学习器进行结合,常可获得比单一…...
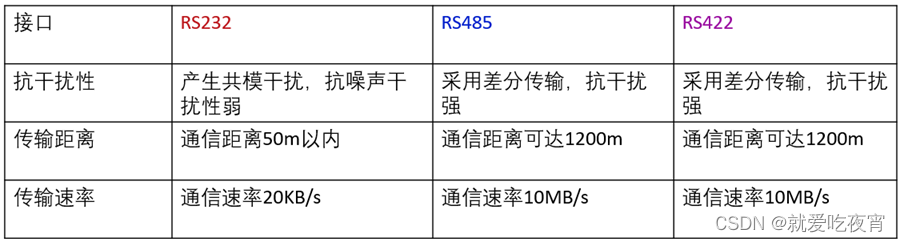
串口通信标准RS232 RS485 RS422的区别
很多工程师经常把RS-232、RS-422、RS-485称为通讯协议,其实这是不对的,它们仅仅是关于串口通讯的一个机械和电气接口标准(顶多是网络协议中的物理层),不是通讯协议,那它们又有哪些区别呢: 第一…...

jdk环境安装
jdk安装 创建软件安装的目录 mkdir -p /bigdata/{soft,server} /bigdata/soft 安装文件的存放目录 /bigdata/server 软件安装的目录 把安装的软件上传到/bigdata/soft 目录 解压到指定目录 -C :指定解压到指定目录 tar -zxvf /bigdata/soft/jdk-8u241-linux-x64.tar.gz -C /b…...
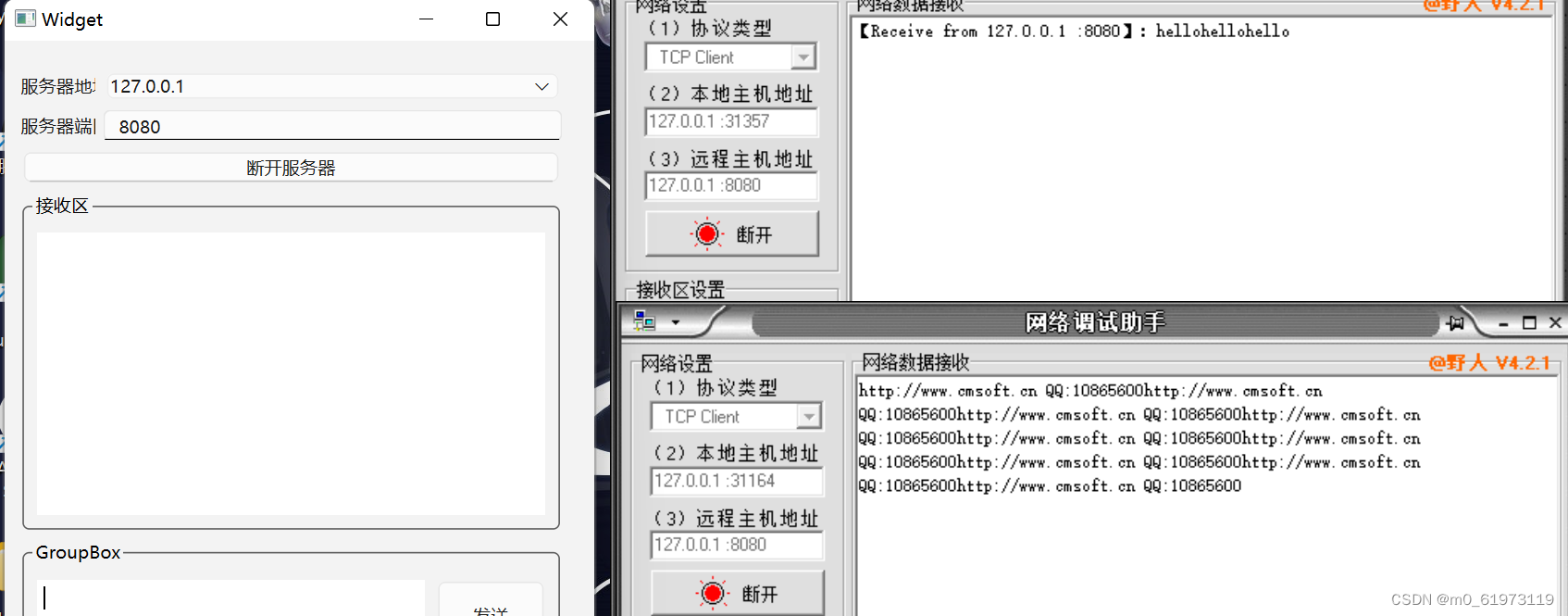
QT+网络调试助手+TCP服务器
一、UI界面设计 二、单线程 代码设计 1、 查找合法的本地地址,用于当作服务器的IP地址 #include <QThread> #include <QTcpSocket> #include <QNetworkInterface> #include <QMessageBox>QList<QHostAddress> ipAddressesList QNe…...
场景)
【unity】(1)场景
Unity的场景(Scene)是构建游戏中各种环境和级别的基础。一个场景可以包含游戏中的所有对象,如角色、道具、地形等。 创建和管理场景 创建新场景: 在Unity编辑器中,选择File > New Scene,或者使用快捷键…...

【Linux】进程间通信IPC机制
目录 一、无名管道 二、有名管道 三、共享内存 四、信号量 五、消息队列 六、套接字 一、无名管道 1.只能用于具有亲缘关系的进程之间的通信(也就是父子进程或者兄弟进程)。 2.是一个单工的通信模式,具有固定的读端和写端。 3.管道也可以看成是一种特殊的文件…...
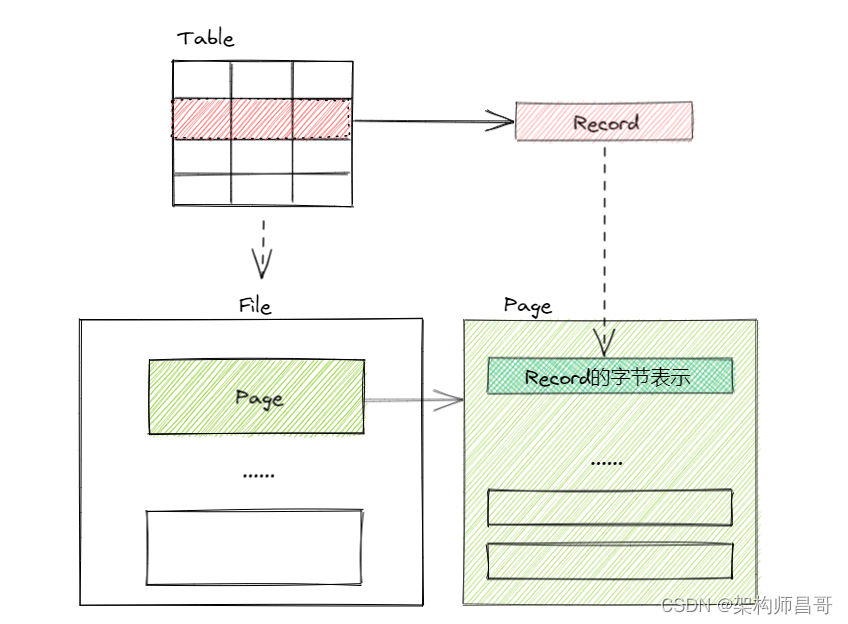
【如此简单!数据库入门系列】之效率基石 -- 磁盘空间管理
文章目录 1 前言2 磁盘空间管理3 磁盘空间管理的实现4 存储对象关系5 总结6 系列文章 1 前言 如何将表中的记录存储在物理磁盘上呢? 概念模式中,记录(Record)表示表中的一行数据,由多个列(字段或者属性&…...
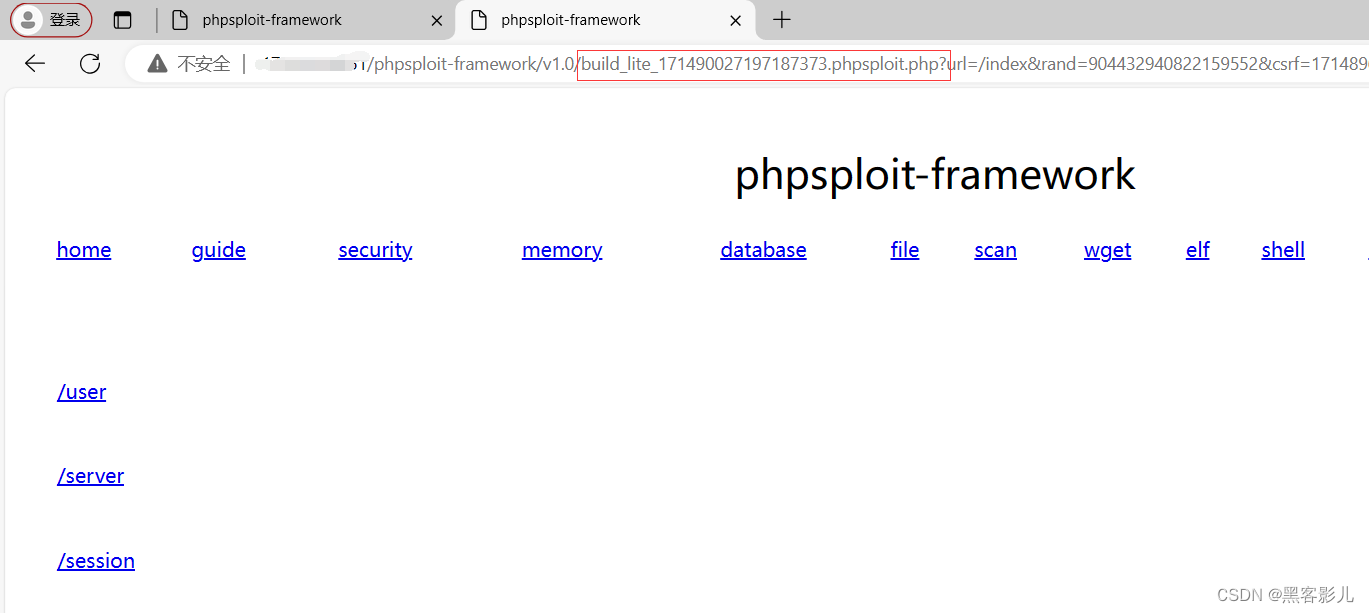
专业渗透测试 Phpsploit-Framework(PSF)框架软件小白入门教程(五)
本系列课程,将重点讲解Phpsploit-Framework框架软件的基础使用! 本文章仅提供学习,切勿将其用于不法手段! 继续接上一篇文章内容,讲述如何进行Phpsploit-Framework软件的基础使用和二次开发。 在下面的图片中&#…...
5月7日监控二叉树+斐波那契数
968.监控二叉树 给定一个二叉树,我们在树的节点上安装摄像头。 节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。 计算监控树的所有节点所需的最小摄像头数量。 示例 1: 输入:[0,0,null,0,0] 输出:1 解释ÿ…...

C++类的设计编程示例
一、银行账户类 【问题描述】 定义银行账户BankAccount类。 私有数据成员:余额balance(整型)。 公有成员方法: 无参构造方法BankAccount():将账户余额初始化为0; 带参构造方法BankAccount(int m)࿱…...
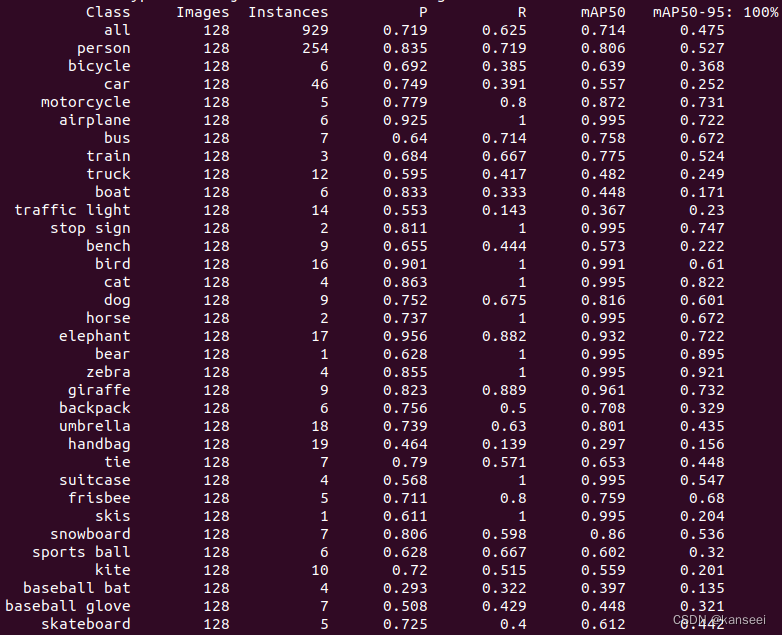
YOLOv5 V7.0 - rknn模型的验证 输出精度(P)、召回率(R)、mAP50、mAP50-95
1.简介 RKNN官方没有提供YOLOv5模型的验证工具,而YOLOv5自带的验证工具只能验证pytorch、ONNX等常见格式的模型性能,无法运行rknn格式。考虑到YOLOv5模型转换为rknn会有一定的精度损失,但是需要具体数值才能进行评估,所以需要一个…...
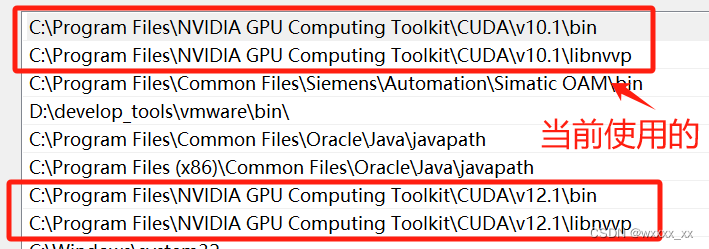
CUDA、CUDNN、Pytorch三者之间的关系
这个东西嘛,我一开始真的是一头雾水,安装起来真是麻烦死了。但是随着要复现的项目越来越多,我也不得不去学会他们是什么,以及他们之间的关系。 首先,一台电脑里面允许有多种版本的cuda存在,然后cuda分为run…...

vue-cli2,vue-cli3,vite 生产环境去掉console.log
console.log一般都是在开发环境下使用的,在生产环境下需要去除 ,如果手动删除未免也太累了,我们可以用插件对于具体环境全局处理。 vue-cli2 项目build 下面webpack.prod.config.js 文件中: plugins: [new webpack.DefinePlugin({process.en…...
Docker-Compose编排LNMP并部署WordPress
前言 随着云计算和容器化技术的快速发展,使用 Docker Compose 编排 LNMP 环境已经成为快速部署 Web 应用程序的一种流行方式。LNMP 环境由 Linux、Nginx、MySQL 和 PHP 组成,为运行 Web 应用提供了稳定的基础。本文将介绍如何通过 Docker Compose 编排 …...

附录C:招聘流程
< 回到目录 附录C:招聘流程 _xxx_公司的招聘 使命 只雇佣顶级人才。 他们是能够胜任工作,并与 _(你的公司名称)_ 的企业文化相匹配的超级明星。 方法 记分卡。招聘经理创建一份文件,详细描述此职位的工作内容…...
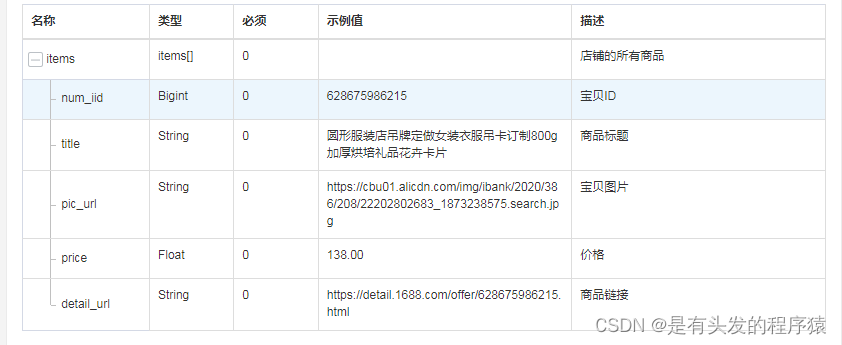
1688快速获取整店铺列表 采集接口php Python
在电子商务的浪潮中,1688平台作为中国领先的批发交易平台,为广大商家提供了一个展示和销售商品的广阔舞台;然而,要在众多店铺中脱颖而出,快速获取商品列表并进行有效营销是关键。 竞争对手分析 价格比较:…...

CTF-WEB(MISC)
安全攻防知识——CTF之MISC - 知乎 CTF之MISC杂项从入门到放弃_ctf杂项 你的名字-CSDN博客 CTF MICS笔记总结_archpr 掩码攻击-CSDN博客 一、图片隐写 CTF杂项---文件类型识别、分离、合并、隐写_ctf图片分离-CSDN博客 EXIF(Exchangeable Image File)是…...

Ubuntu如何更换 PyTorch 版本
环境: Ubuntu22.04 WLS2 问题描述: Ubuntu如何更换 PyTorch 版本考虑安装一个为 CUDA 11.5 编译的 PyTorch 版本。如何安装旧版本 解决方案: 决定不升级CUDA版本,而是使用一个与CUDA 11.5兼容的PyTorch版本,您可…...

python flask css样式无效
解释: Flask是一个Python的轻量级Web框架,它没有为CSS提供任何内置的支持。如果你在Flask项目中引入了CSS文件,但是这个CSS没有生效,可能的原因有: 路径不正确:你的CSS文件没有放在正确的目录下࿰…...
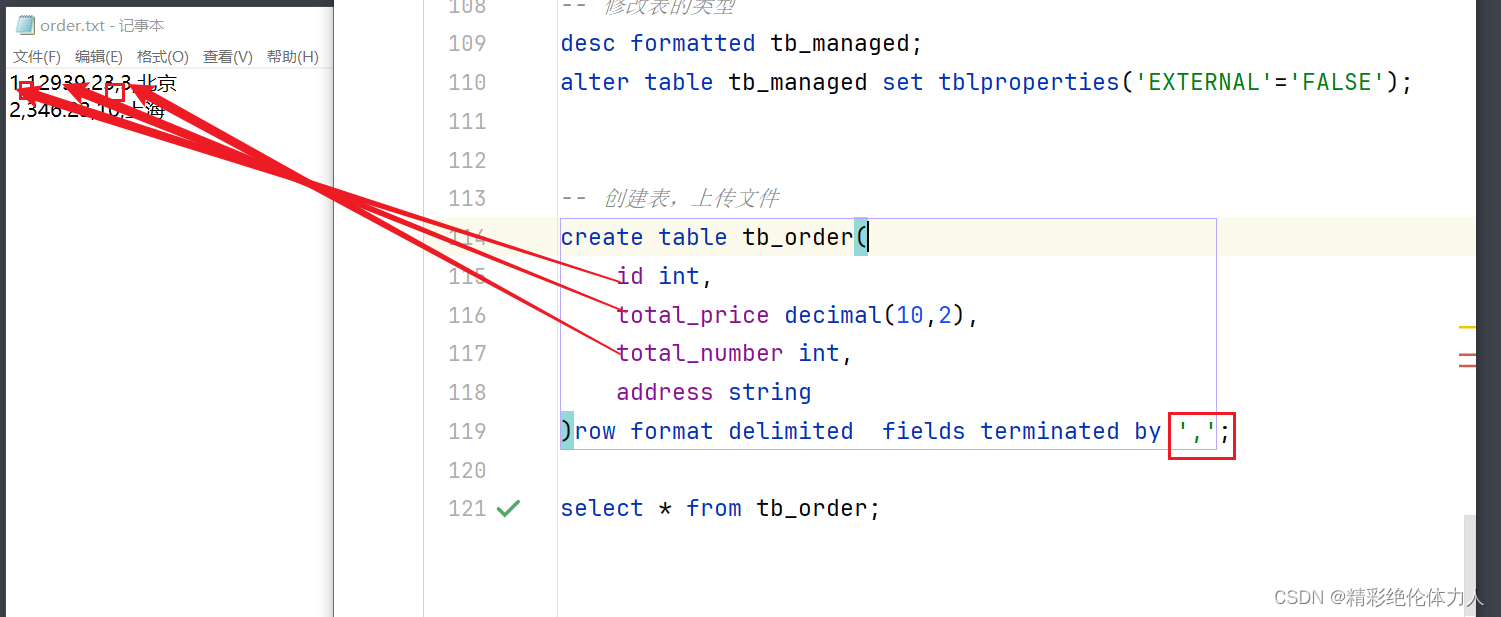
大数据学习笔记14-Hive基础2
一、数据字段类型 数据类型 :LanguageManual Types - Apache Hive - Apache Software Foundation 基本数据类型 数值相关类型 整数 tinyint smallint int bigint 小数 float double decimal 精度最高 日期类型 date 日期 timestamps 日期时间 字符串类型 s…...

别再死记硬背base64了!深入浅出聊聊CTF中那些‘魔改’编码的识别与对抗思路
CTF逆向工程中的编码魔法:从Base64变异到通用对抗策略 在网络安全竞赛的战场上,编码就像是一把双刃剑——它既是保护信息的盾牌,也是隐藏线索的迷雾。对于CTF逆向选手而言,面对各种"魔改"编码就像是在解谜题时突然发现规…...

c++11的初见
列表初始化 c11以后支持{ }的列表初始可以使用{ }括住数据来进行初始化,使用{ }初始化时可以省略号{ }中的数据要匹配构造;使用{ }可以统一初始化方式。#include<iostream> #include<vector> using namespace std; int main(){vector<pai…...

【RuoYi】数据分页功能分析 —— 以登录日志页面为例
本文基于 RuoYi-Vue v3.8.2,以"监控 → 登录日志"页面为例,从前端代码、前端开发者工具、后端代码到后端 Log 输出,完整分析 RuoYi 框架中数据分页的实现原理。一、实例简介本次分析选取的含数据分页功能的页面为:系统管…...

【致91岁的双胞胎】堡垒复习:3步搭建理科“作战地图”,告别零散刷题效率翻倍
很多学生长期陷入理科复习瓶颈:花费大量时间刷题、背书,成绩却始终原地踏步。核心根源只有一个:照搬文科的复习方式学理科。 文科复习侧重知识点记忆、框架梳理、素材积累,通用的A4纸整理法完全适用;但理科的核心是逻辑闭环、体系串联、题型落地、抗遗忘复盘,死记硬背、…...

量子计算如何革新机器翻译:QEDACVC系统解析
1. 量子计算与机器翻译的技术融合量子计算正在为自然语言处理领域带来革命性的变化。传统机器翻译系统依赖于经典计算机架构,如基于Transformer的模型,虽然取得了显著进展,但在处理低资源语言和实时多语言场景时仍面临挑战。量子机器翻译的核…...

免费开源AMD Ryzen调试工具:SMUDebugTool完整使用指南与性能调优实战
免费开源AMD Ryzen调试工具:SMUDebugTool完整使用指南与性能调优实战 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

国自然最后冲刺:如何用ChatGPT把自查做到“零漏项”?
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年是国自然改版元年,模板大变,旧套路失效,新坑又挖了不少。今天七…...
)
告别PCL!用Qt+QGLWidget手把手教你打造自己的3D点云查看器(附完整源码)
轻量级3D点云可视化:基于Qt与OpenGL的高效实现方案 在工业测量、自动驾驶和三维重建等领域,点云数据的可视化一直是开发者面临的挑战。传统方案如PCL虽然功能强大,但其庞大的体积和复杂的依赖链往往让项目变得臃肿。本文将展示如何利用Qt的QG…...

渗透测试中的Windows痕迹清理:从“删库跑路”到“雁过无痕”的反取证艺术
引子:想象一下武侠小说里的场景:绝顶高手在别人家的藏经阁偷学了绝世武功,临走时不但不留下一丝指纹,还顺手把烛台复原、抹平了地上的脚印,甚至故意丢下一枚别的门派的暗器——这,就是网络安全界“痕迹清理…...

如何无限期免费使用IDM:智能试用期重置完整指南
如何无限期免费使用IDM:智能试用期重置完整指南 【免费下载链接】idm-trial-reset Use IDM forever without cracking 项目地址: https://gitcode.com/gh_mirrors/id/idm-trial-reset 你是否为Internet Download Manager(IDM)的30天试…...