用开源模型MusicGen制作六一儿童节专属音乐
使用的是开源模型MusicGen,它可以根据文字描述或者已有旋律生成高质量的音乐(32kHz),其原理是通过生成Encodec token然后再解码为音频,模型利用EnCodec神经音频编解码器来从原始波形中学习离散音频token。EnCodec将音频信号映射到一个或多个并行的离散token流。然后使用一个自回归语言模型来递归地对EnCodec中的音频token进行建模。生成的token然后被馈送到EnCodec解码器,将它们映射回音频空间并获取输出波形。最后,可以使用不同类型的条件模型来控制生成

准备运行环境
拷贝模型文件
import moxing as mox
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/MusicGen/model/', 'model')
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/course/ModelBox/opus-mt-zh-en', 'opus-mt-zh-en')
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/course/ModelBox/frpc_linux_amd64', 'frpc_linux_amd64')
基于Python3.9.15 创建虚拟运行环境
!/home/ma-user/anaconda3/bin/conda create -n python-3.9.15 python=3.9.15 -y --override-channels --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
!/home/ma-user/anaconda3/envs/python-3.9.15/bin/pip install ipykernel
修改Kernel文件
import json
import osdata = {"display_name": "python-3.9.15","env": {"PATH": "/home/ma-user/anaconda3/envs/python-3.9.15/bin:/home/ma-user/anaconda3/envs/python-3.7.10/bin:/modelarts/authoring/notebook-conda/bin:/opt/conda/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/home/ma-user/modelarts/ma-cli/bin:/home/ma-user/modelarts/ma-cli/bin:/home/ma-user/anaconda3/envs/PyTorch-1.8/bin"},"language": "python","argv": ["/home/ma-user/anaconda3/envs/python-3.9.15/bin/python","-m","ipykernel","-f","{connection_file}"]
}if not os.path.exists("/home/ma-user/anaconda3/share/jupyter/kernels/python-3.9.15/"):os.mkdir("/home/ma-user/anaconda3/share/jupyter/kernels/python-3.9.15/")with open('/home/ma-user/anaconda3/share/jupyter/kernels/python-3.9.15/kernel.json', 'w') as f:json.dump(data, f, indent=4)print('kernel.json文件修改完毕')
安装依赖
!pip install --upgrade pip
!pip install torch==2.0.1 torchvision==0.15.2
!pip install sentencepiece
!pip install librosa
!pip install --upgrade transformers scipy
!pip install gradio==4.16.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
!cp frpc_linux_amd64 /home/ma-user/anaconda3/envs/python-3.9.15/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2
!chmod +x /home/ma-user/anaconda3/envs/python-3.9.15/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2
模型测试
模型推理
#@title Default title text
import torch
from transformers import AutoProcessor, MusicgenForConditionalGeneration, pipelinezh2en = pipeline("translation", model="./opus-mt-zh-en")
prompt = "六一儿童节 男孩专属节奏感强的音乐"
prompt = zh2en(prompt)[0].get("translation_text")
print(prompt)device = 'cuda' if torch.cuda.is_available() else 'cpu'
processor = AutoProcessor.from_pretrained("./model/")
model = MusicgenForConditionalGeneration.from_pretrained("./model/")
model.to(device)inputs = processor(text=[prompt],padding=True,return_tensors="pt",
).to(device)# max_new_tokens对应生成音乐的长度,1024表示生成20s长的音乐;
# 目前最大支持生成30s长的音乐,对应max_new_tokens值为1536
audio_values = model.generate(**inputs, max_new_tokens=1024)
生成音频文件
from IPython.display import Audiosampling_rate = model.config.audio_encoder.sampling_rate
if torch.cuda.is_available():audio_data = audio_values[0].cpu().numpy()
else:audio_data = audio_values[0].numpy()Audio(audio_data, rate=sampling_rate)
保存文件
import scipysampling_rate = model.config.audio_encoder.sampling_rate
if torch.cuda.is_available():audio_data = audio_values[0, 0].cpu().numpy()
else:audio_data = audio_values[0, 0].numpy()
scipy.io.wavfile.write("music_out.wav", rate=sampling_rate, data=audio_data)
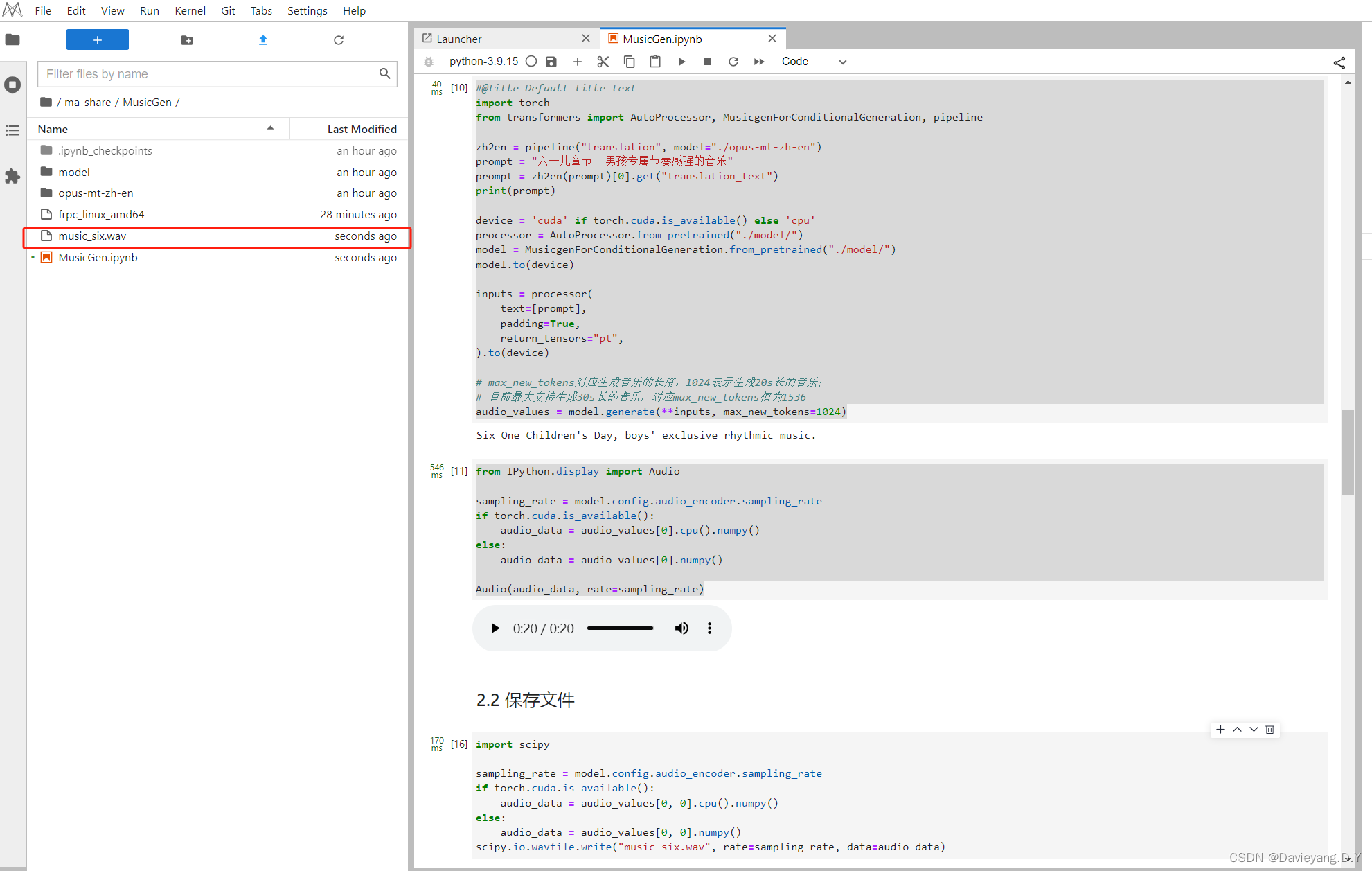
图形化生成界面应用
import torch
import scipy
import librosa
from transformers import AutoProcessor, MusicgenForConditionalGeneration, pipelinedef music_generate(prompt: str, duration: int):zh2en = pipeline("translation", model="./opus-mt-zh-en")token = int(duration / 5 * 256)print('token:',token)prompt = zh2en(prompt)[0].get("translation_text")print('prompt:',prompt)device = 'cuda' if torch.cuda.is_available() else 'cpu'processor = AutoProcessor.from_pretrained("./model/")model = MusicgenForConditionalGeneration.from_pretrained("./model/")model.to(device)inputs = processor(text=[prompt],padding=True,return_tensors="pt",).to(device)audio_values = model.generate(**inputs, max_new_tokens=token)sampling_rate = model.config.audio_encoder.sampling_rateif torch.cuda.is_available():audio_data = audio_values[0, 0].cpu().numpy()else:audio_data = audio_values[0, 0].numpy()scipy.io.wavfile.write("music_out.wav", rate=sampling_rate, data=audio_data)audio,sr = librosa.load(path="music_out.wav")return sr, audioimport gradio as grwith gr.Blocks() as demo:gr.HTML("""<h1 align="center">文本生成音乐</h1>""")with gr.Row():with gr.Column(scale=1):prompt = gr.Textbox(lines=1, label="提示语")duration = gr.Slider(5, 30, value=15, step=5, label="歌曲时长(单位:s)", interactive=True)runBtn = gr.Button(value="生成", variant="primary")with gr.Column(scale=1):music = gr.Audio(label="输出")runBtn.click(music_generate, inputs=[prompt, duration], outputs=[music], show_progress=True)demo.queue().launch(share=True)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Running on local URL: http://127.0.0.1:7860
IMPORTANT: You are using gradio version 4.16.0, however version 4.29.0 is available, please upgrade.
--------
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Running on public URL: https://cd3ee3f9072d7e8f5d.gradio.liveThis share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
点击链接打开图形界面,如图所示
相关文章:
用开源模型MusicGen制作六一儿童节专属音乐
使用的是开源模型MusicGen,它可以根据文字描述或者已有旋律生成高质量的音乐(32kHz),其原理是通过生成Encodec token然后再解码为音频,模型利用EnCodec神经音频编解码器来从原始波形中学习离散音频token。EnCodec将音频信号映射到一个或多个并…...

Ps:批处理
Ps菜单:文件/自动/批处理 Automate/Batch 批处理 Batch命令可以对一个文件夹中的文件执行事先创建的动作 Actions,从而快速地完成大量的重复性操作,提升工作效率。 提示 1: 可以从 Adobe Bridge 中调用 Photoshop 的批处理命令。 …...

前端框架中的虚拟DOM和实际DOM之间的关系
聚沙成塔每天进步一点点 本文回顾 ⭐ 专栏简介前端框架中的虚拟DOM和实际DOM之间的关系1. 实际DOM(Real DOM)1.1 定义1.2 特点 2. 虚拟DOM(Virtual DOM)2.1 定义2.2 特点 3. 虚拟DOM的工作流程3.1 创建虚拟DOM3.2 比较虚拟DOM&…...
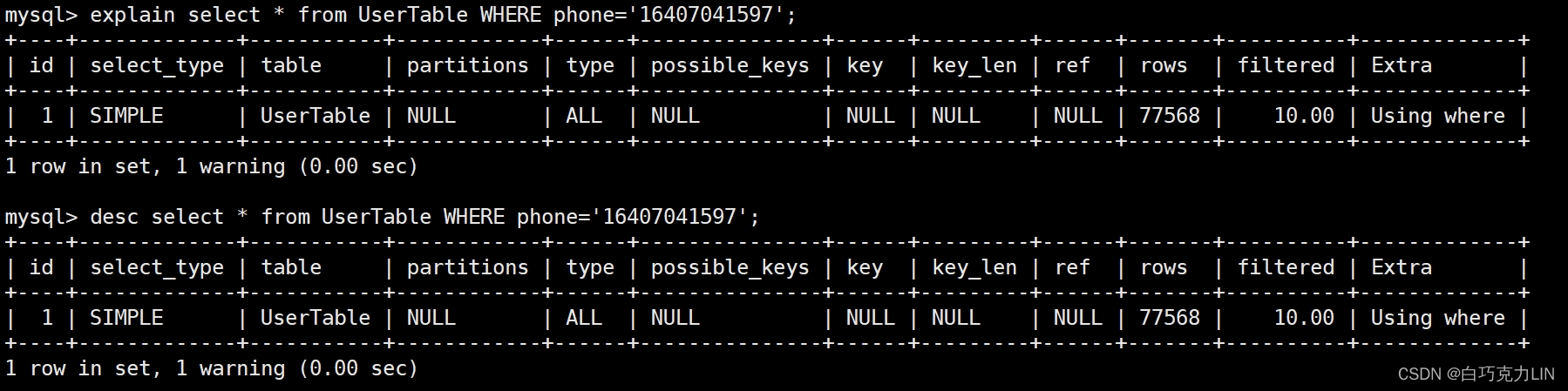
MySQL进阶——SQL性能分析
在上篇文章我们学习了MySQL进阶——存储引擎,这篇文章学习MySQL进阶——SQL性能分析。 SQL性能分析主要是从SQL语句执行频率、耗时时间、CPU使用情况和执行时表连接情况进行分析,常用的方法工具有:SQL执行频率、慢查询日志、profile详情和ex…...

在RT-Thread下为MPU手搓以太网MAC驱动-4
文章目录 MAC驱动里面对MDIO的支持MAC驱动与MDIO总线 这是个人驱动开发过程中做的一些记录,仅代表个人意见和理解,不喜勿喷 MAC驱动需要支持不同的PHY芯片 MAC驱动里面对MDIO的支持 在第一篇文章中提到对MAC设备做出了抽象,其中MAC抽象里面有…...

可的哥(Codigger)推出Monaco编辑器插件,提升编程体验
Monaco编辑器,作为业界领先的代码编辑器,在编程体验中发挥着不可或缺的重要作用,能够在多种编程语言和开发环境中表现出色,为开发者提供高效、便捷的编程环境。可的哥(Codigger)在应用商店上线Monaco编辑器…...

为什么选择mobx
对于React而言,大家熟能而详的是redux,但我们的项目用的是mobx,接下来就让我给你详细说下它的优势和不足,可以参考。 MobX是什么? MobX 是一种简单易用的状态管理库,它采用基于观察者的模式,可…...

如何解决段转储问题
非常恶心 ,这个问题困了我一个月,怀疑过代码有问题 ,怀疑过数据集没处理好,怀疑过环境没有配置好,尝试改动,跑过很多次,还是段转储报错卡住。。。 然后一个月荒废,打算放弃这个模型…...

【杂谈】AIGC之ChatGPT-与智能对话机器人的奇妙对话之旅
与智能对话机器人的奇妙对话之旅 引言 在数字时代的浪潮中,ChatGPT如同一位智慧的旅伴,它不仅能够与我们畅谈古今,还能解答我们的疑惑,成为我们探索知识海洋的得力助手。今天,就让我们走进ChatGPT的世界,…...

CentOS7配置国内清华源并安装docker-ce以及配置docker加速
说明 由于国内访问国外的网站包括docker网站,由于种种的原因经常打不开,或无法访问,所以替换成国内的软件源和国内镜像就是非常必要的了,这里整理了我安装配置的基本的步骤。 国内的软件源有很多,这里选择清华源作为…...

JL-03-Y1 清易易站
产品概述 清易易站是清易电子新研发的一体式气象站,坚持科学化和人文化相结合的设计理念,应用新检测原理研发的传感器观测各类气象参数,采用社会上时尚的工艺理念设计气象站的整体结构,实现了快速观测、无线传输、数据准确、精度较…...
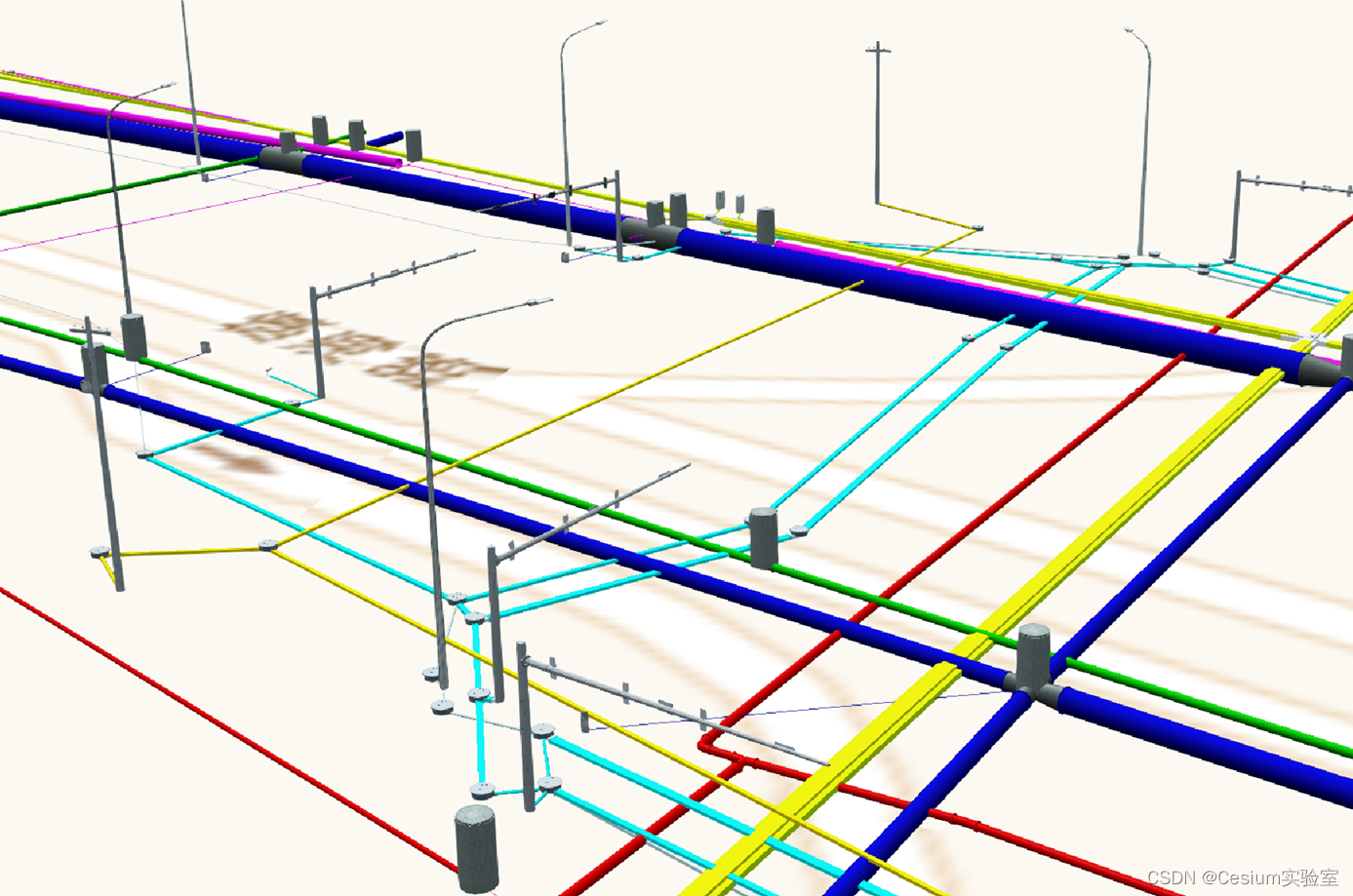
PipeSer管线管网云服务
行业需求 地下管网,作为现代城市不可或缺的基础设施,堪称城市的“地下生命线”。它承载着城市的供水、排水、燃气、电力、通信等重要功能,是确保城市正常运转和居民生活便利的关键所在。将地下管网的复杂布局和运行状态以三维形式直观展现出来…...

kubesphere报错
1.安装过程报错unable to sign certificate: must specify a CommonName [rootnode1 ~]# ./kk init registry -f config-sample.yaml -a kubesphere.tar.gz _ __ _ _ __ | | / / | | | | / / | |/ / _ _| |__ ___| |/…...
【QT5】<总览二> QT信号槽、对象树及样式表
文章目录 前言 一、QT信号与槽 1. 信号槽连接模型 2. 信号槽介绍 3. 自定义信号槽 二、不使用UI文件编程 三、QT的对象树 四、添加资源文件 五、样式表的使用 六、QSS文件的使用 前言 承接【QT5】<总览一> QT环境搭建、快捷键及编程规范。若存…...

2024.05.24 校招 实习 内推 面经
绿*泡*泡VX: neituijunsir 交流*裙 ,内推/实习/校招汇总表格 1、实习丨蔚来2025届实习生招募计划开启(内推) 实习丨蔚来2025届实习生招募计划开启(内推) 2、校招&实习丨联芯集成电路2025届暑期实习…...

如何理解 Java 8 引入的 Lambda 表达式及其使用场景
Lambda表达式是Java 8引入的一项重要特性,它使得编写简洁、可读和高效的代码成为可能。Lambda表达式本质上是一种匿名函数,能够更简洁地表示可传递的代码块,用于简化函数式编程的实现。 一、Lambda表达式概述 1. 什么是Lambda表达式 Lambd…...

GPT-4与GPT-4O的区别详解:面向小白用户
1. 模型介绍 在人工智能的语言模型领域,OpenAI的GPT-4和GPT-4O是最新的成员。这两个模型虽然来源于相同的基础技术,但在功能和应用上有着明显的区别。 GPT-4:这是一个通用型语言模型,可以理解和生成自然语言。无论是写作、对话还…...
使用throttle防止按钮多次点击
背景:如上图所示,点击按钮,防止按钮点击多次 <div class"footer"><el-button type"primary" click"submitThrottle">发起咨询 </el-button> </div>import { throttle } from loda…...
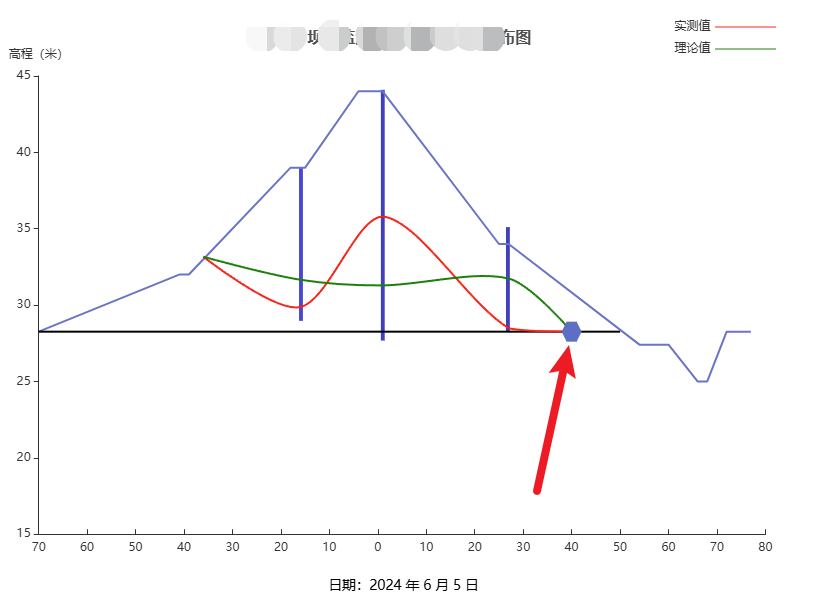
Echarts 在折线图的指定位置绘制一个图标展示
文章目录 需求分析需求 在线段交汇处用一个六边形图标展示 分析 可以使用 markPoint 和 symbol 属性来实现。这是一个更简单和更标准的方法来添加标记点在运行下述代码后,你将在浏览器中看到一个折线图,其中在 [3, 35] (即图表中第四个数据点 Thu 的 y 值为 35 的位置)处…...
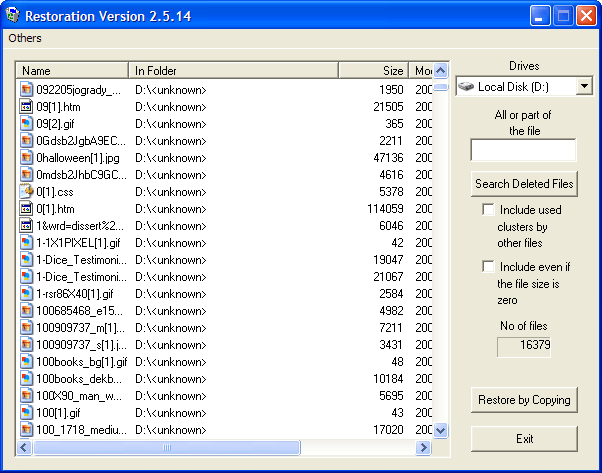
适用于 Windows 的 8 大数据恢复软件
数据恢复软件可帮助您恢复因意外删除或由于某些技术故障(如硬盘损坏等)而丢失的数据。这些工具可帮助您从硬盘驱动器 (HDD) 中高效地恢复丢失的数据,因为这些工具不支持从 SSD 恢复数据。重要的是要了解,您删除的数据不会被系统永…...

Go Module 依赖冲突调试方法
Go Module 依赖冲突调试方法 在Go语言开发中,依赖管理是一个关键环节。随着项目规模的扩大,依赖的第三方库越来越多,版本冲突问题也愈发常见。Go Module作为官方推荐的依赖管理工具,虽然简化了依赖管理流程,但在多级依…...
分布图)
LingBot-Depth效果实测:与传感器原生深度对比的绝对误差(mm)分布图
LingBot-Depth效果实测:与传感器原生深度对比的绝对误差(mm)分布图 1. 引言:当深度图遇上“脑补”大师 想象一下,你手里有一张用深度相机拍出来的照片,它告诉你每个像素离相机有多远。但问题是࿰…...
快速上手教程)
Qwen3.5-2B镜像免配置部署:开箱即用WebUI(7860端口)快速上手教程
Qwen3.5-2B镜像免配置部署:开箱即用WebUI(7860端口)快速上手教程 1. 模型简介 Qwen3.5-2B是通义千问系列中的轻量化多模态基础模型,仅有20亿参数规模,专为低功耗、低门槛部署场景设计。这个版本特别适合在端侧设备和…...
)
新手避坑指南:从GEO数据库下载单细胞测序数据的5个关键步骤(附实操截图)
单细胞测序数据下载实战:5个避坑技巧与决策逻辑 第一次打开GEO数据库时,满屏的测序数据就像走进了一个没有地图的迷宫。作为刚接触单细胞转录组分析的研究生,我花了整整两周时间才搞明白哪些数据值得下载——期间踩过的坑包括下载了样本命名混…...
)
保姆级教程:从WOS下载文献到Citespace出图,手把手搞定科研可视化(附避坑指南)
科研可视化实战:从WOS数据采集到Citespace图谱优化的完整指南 第一次打开Citespace时,看着满屏的英文参数和报错提示,我盯着屏幕发了十分钟呆——这大概是每个科研新手都会经历的"震撼教育"。文献计量分析本应是揭示知识脉络的利器…...

眼图分析:高速数字信号完整性的关键工具
1. 眼图基础概念解析 眼图(Eye Diagram)是数字信号完整性分析中最重要的工具之一。作为一名硬件工程师,我每天都会用眼图来评估信号质量。简单来说,眼图就是将数字信号在时间轴上重复叠加后形成的图形,因其形状类似人眼…...

如何免费快速备份你的QQ空间记忆:GetQzonehistory完整指南
如何免费快速备份你的QQ空间记忆:GetQzonehistory完整指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾经担心过QQ空间里的那些珍贵回忆会随着时间流逝而消失&am…...

【实验原理深度解析】弗兰克-赫兹实验:如何用电子“碰撞”揭示原子能级的秘密
1. 电子与原子的"对话":弗兰克-赫兹实验的设计哲学 想象你站在一个漆黑的房间里,向对面墙壁投掷网球。如果墙壁是实心的,球会直接弹回;但如果墙上有一排高度不同的窗口,球只有达到特定速度才能穿过对应高度的…...

Qwen3-VL:30B多模态提示词工程:Clawdbot中优化图文提问格式提升飞书响应质量
Qwen3-VL:30B多模态提示词工程:Clawdbot中优化图文提问格式提升飞书响应质量 1. 引言:从部署到优化的进阶之路 在上一篇文章中,我们已经成功在星图AI云平台部署了Qwen3-VL:30B多模态大模型,并通过Clawdbot搭建了基础框架。现在面…...

基于STM32单片机扫地机器人仿真系统设计 1、使用 STM32 单片机作为核心控制器
基于STM32单片机扫地机器人仿真系统设计 1、使用 STM32 单片机作为核心控制器; 2、选择超声波(1个)、红外线(两个,放在左右)两种传感器进行有效地避障; 3、使用角度传感器 MPU6050 测量角度,检测扫地机器人的运动状态,是否有倾倒; 4、OLED 屏显示超声波距…...