保姆级使用PyTorch训练与评估自己的MobileViT网络教程

文章目录
- 前言
- 0. 环境搭建&快速开始
- 1. 数据集制作
- 1.1 标签文件制作
- 1.2 数据集划分
- 1.3 数据集信息文件制作
- 2. 修改参数文件
- 3. 训练
- 4. 评估
- 5. 其他教程
前言
项目地址:https://github.com/Fafa-DL/Awesome-Backbones
操作教程:https://www.bilibili.com/video/BV1SY411P7Nd
MobileViT原论文:点我跳转
如果你以为该仓库仅支持训练一个模型那就大错特错了,我在项目地址放了目前支持的42种模型(LeNet5、AlexNet、VGG、DenseNet、ResNet、Wide-ResNet、ResNeXt、SEResNet、SEResNeXt、RegNet、MobileNetV2、MobileNetV3、ShuffleNetV1、ShuffleNetV2、EfficientNet、RepVGG、Res2Net、ConvNeXt、HRNet、ConvMixer、CSPNet、Swin-Transformer、Vision-Transformer、Transformer-in-Transformer、MLP-Mixer、DeiT、Conformer、T2T-ViT、Twins、PoolFormer、VAN、HorNet、EfficientFormer、Swin Transformer V2、MViT V2、MobileViT、DaViT、RepLKNet、BEiT、EVA、MixMIM、EfficientNetV2),使用方式一模一样。且目前满足了大部分图像分类需求,进度快的同学甚至论文已经在审了
0. 环境搭建&快速开始
- 这一步我也在最近录制了视频
最新Windows配置VSCode与Anaconda环境
『图像分类』从零环境搭建&快速开始
- 不想看视频也将文字版放在此处。建议使用Anaconda进行环境管理,创建环境命令如下
conda create -n [name] python=3.6 其中[name]改成自己的环境名,如[name]->torch,conda create -n torch python=3.6
- 我的测试环境如下
torch==1.7.1
torchvision==0.8.2
scipy==1.4.1
numpy==1.19.2
matplotlib==3.2.1
opencv_python==3.4.1.15
tqdm==4.62.3
Pillow==8.4.0
h5py==3.1.0
terminaltables==3.1.0
packaging==21.3
- 首先安装Pytorch。建议版本和我一致,进入Pytorch官网,点击
install previous versions of PyTorch,以1.7.1为例,官网给出的安装如下,选择合适的cuda版本
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 10.2
pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2# CUDA 10.1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 9.2
pip install torch==1.7.1+cu92 torchvision==0.8.2+cu92 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CPU only
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
- 安装完Pytorch后,再运行
pip install -r requirements.txt
- 下载MobileNetV3-Small权重至datas下
- Awesome-Backbones文件夹下终端输入
python tools/single_test.py datas/cat-dog.png models/mobilenet/mobilenet_v3_small.py --classes-map datas/imageNet1kAnnotation.txt
1. 数据集制作
1.1 标签文件制作
-
将项目代码下载到本地
-
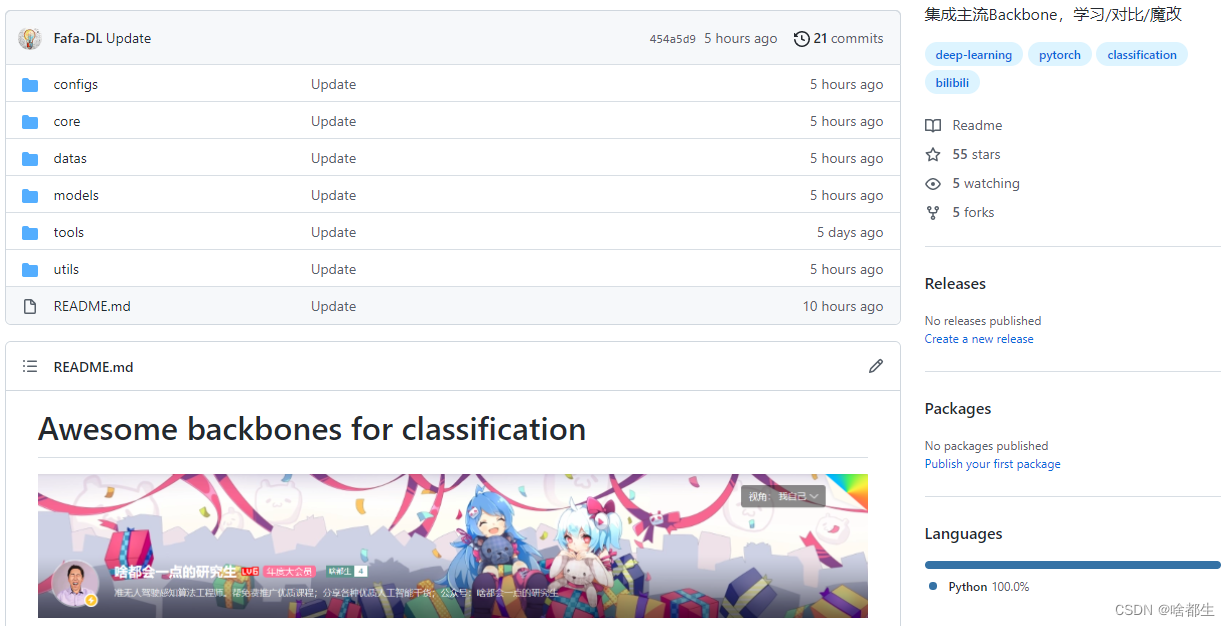
本次演示以花卉数据集为例,目录结构如下:
├─flower_photos
│ ├─daisy
│ │ 100080576_f52e8ee070_n.jpg
│ │ 10140303196_b88d3d6cec.jpg
│ │ ...
│ ├─dandelion
│ │ 10043234166_e6dd915111_n.jpg
│ │ 10200780773_c6051a7d71_n.jpg
│ │ ...
│ ├─roses
│ │ 10090824183_d02c613f10_m.jpg
│ │ 102501987_3cdb8e5394_n.jpg
│ │ ...
│ ├─sunflowers
│ │ 1008566138_6927679c8a.jpg
│ │ 1022552002_2b93faf9e7_n.jpg
│ │ ...
│ └─tulips
│ │ 100930342_92e8746431_n.jpg
│ │ 10094729603_eeca3f2cb6.jpg
│ │ ...
- 在
Awesome-Backbones/datas/中创建标签文件annotations.txt,按行将类别名 索引写入文件;
daisy 0
dandelion 1
roses 2
sunflowers 3
tulips 4

1.2 数据集划分
- 打开
Awesome-Backbones/tools/split_data.py - 修改
原始数据集路径以及划分后的保存路径,强烈建议划分后的保存路径datasets不要改动,在下一步都是默认基于文件夹进行操作
init_dataset = 'A:/flower_photos' # 改为你自己的数据路径
new_dataset = 'A:/Awesome-Backbones/datasets'
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/split_data.py
- 得到划分后的数据集格式如下:
├─...
├─datasets
│ ├─test
│ │ ├─daisy
│ │ ├─dandelion
│ │ ├─roses
│ │ ├─sunflowers
│ │ └─tulips
│ └─train
│ ├─daisy
│ ├─dandelion
│ ├─roses
│ ├─sunflowers
│ └─tulips
├─...
1.3 数据集信息文件制作
- 确保划分后的数据集是在
Awesome-Backbones/datasets下,若不在则在get_annotation.py下修改数据集路径;
datasets_path = '你的数据集路径'
- 在
Awesome-Backbones/下打开终端输入命令:
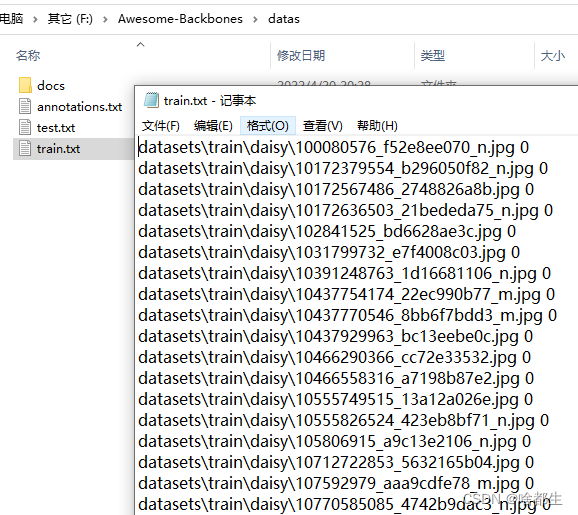
python tools/get_annotation.py
- 在
Awesome-Backbones/datas下得到生成的数据集信息文件train.txt与test.txt
2. 修改参数文件
-
每个模型均对应有各自的配置文件,保存在
Awesome-Backbones/models下 -
由
backbone、neck、head、head.loss构成一个完整模型 -
找到MobileViT参数配置文件,可以看到
所有支持的类型都在这,且每个模型均提供预训练权重
-
在
model_cfg中修改num_classes为自己数据集类别大小 -
按照自己电脑性能在
data_cfg中修改batch_size与num_workers -
若有预训练权重则可以将
pretrained_weights设置为True并将预训练权重的路径赋值给pretrained_weights -
若需要冻结训练则
freeze_flag设置为True,可选冻结的有backbone, neck, head -
在
optimizer_cfg中修改初始学习率,根据自己batch size调试,若使用了预训练权重,建议学习率调小 -
学习率更新详见
core/optimizers/lr_update.py,同样准备了视频『图像分类』学习率更新策略|优化器 -
更具体配置文件修改可参考配置文件解释,同样准备了视频『图像分类』配置文件补充说明
3. 训练
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下train.txt与test.txt与annotations.txt对应 - 选择想要训练的模型,在
Awesome-Backbones/models/下找到对应配置文件,以mobilevit_s为例 - 按照
配置文件解释修改参数 - 在
Awesome-Backbones路径下打开终端运行
python tools/train.py models/mobilevit/mobilevit_s.py

4. 评估
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下test.txt与annotations.txt对应 - 在
Awesome-Backbones/models/下找到对应配置文件 - 在参数配置文件中
修改权重路径,其余不变
ckpt = '你的训练权重路径'
- 在
Awesome-Backbones路径下打开终端运行
python tools/evaluation.py models/mobilevit/mobilevit_s.py

- 单张图像测试,在
Awesome-Backbones打开终端运行
python tools/single_test.py datasets/test/dandelion/14283011_3e7452c5b2_n.jpg models/mobilevit/mobilevit_s.py

至此完毕,实在没运行起来就去B站看我手把手带大家运行的视频教学吧~
5. 其他教程
除开上述,我还为大家准备了其他一定用到的操作教程,均放在了GitHub项目首页,为了你们方便为也粘贴过来
- 环境搭建
- 数据集准备
- 配置文件解释
- 训练
- 模型评估&批量检测/视频检测
- 计算Flops&Params
- 添加新的模型组件
- 类别激活图可视化
- 学习率策略可视化
有任何更新均会在Github与B站进行通知,记得Star与三连关注噢~
相关文章:
保姆级使用PyTorch训练与评估自己的MobileViT网络教程
文章目录前言0. 环境搭建&快速开始1. 数据集制作1.1 标签文件制作1.2 数据集划分1.3 数据集信息文件制作2. 修改参数文件3. 训练4. 评估5. 其他教程前言 项目地址:https://github.com/Fafa-DL/Awesome-Backbones 操作教程:https://www.bilibili.co…...

Giscus,由 GitHub Discussions驱动的评论系统
在创建网站或博客时,许多人都希望能够为其内容提供评论功能,以与用户进行交流和互动。然而,实现这一点可能会非常复杂,需要处理许多不同的问题,如身份验证、反垃圾邮件、跨站脚本攻击等。为了帮助解决这些问题…...

【JSON文件解析】JSON文件
文章目录概要:本期主要介绍Qt解析JSON数据格式文件的方式。一、JSON数据格式1.JSON类似于XML,在JSON文件中,有且只有一个根节点2.JSON有两种主流包含型构造字符:{对象}、[数组]3.JSON的值主要包括:对象、数组、数字、字…...

OpenGL超级宝典学习笔记:纹理
前言 本篇在讲什么 本篇章记录对OpenGL中纹理使用的学习 本篇适合什么 适合初学OpenGL的小白 本篇需要什么 对C语法有简单认知 对OpenGL有简单认知 最好是有OpenGL超级宝典蓝宝书 依赖Visual Studio编辑器 本篇的特色 具有全流程的图文教学 重实践,轻理…...

主辅助服务市场出清模型研究【旋转备用】(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...

不用费劲,这5款效率工具为你解决学习工作烦恼
今天我要向大家推荐5款超级好用的效率软件,无论是在学习还是办公中都能够极大地提高效率。这些软件可以帮助你解决许多问题,而且每个都是真正的神器。 1.键盘仿真鼠标——NeatMouse NeatMouse 是一个小型的工具能够使用鼠标光标控制指针。当你的鼠标不…...
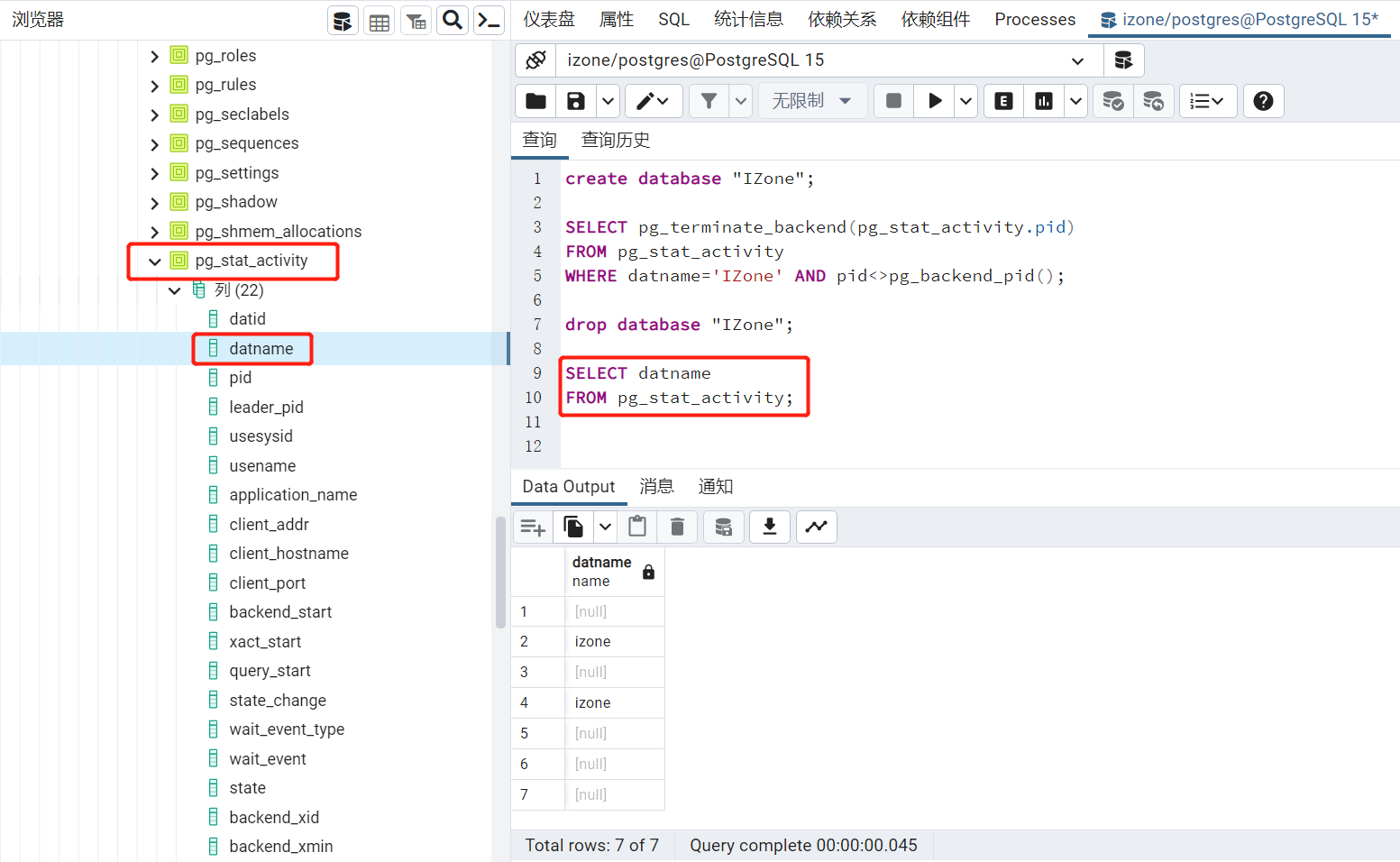
PostgreSQL 数据库大小写规则
PostgreSQL 数据库对大小写的处理规则如下: 严格区分大小写默认把所有 SQL 语句都转换成小写再执行加双引号的 SQL 语句除外 如果想要成功执行名称中带有大写字母的对象,则需要把对象名称加上双引号。 验证如下: 想要创建数据库 IZone&…...
【springmvc】执行流程
SpringMVC执行流程 原理图 1、SpringMVC常用组件 DispatcherServlet:前端控制器,不需要工程师开发,由框架提供 作用:统一处理请求和响应,整个流程控制的中心,由它调用其它组件处理用户的请求 HandlerMa…...

什么是AIGC?
目录前言一、什么是AIGC?1、什么是PGC?2、什么是UGC?3、什么是PUCG?4、什么是AIGC?二、总结前言 很明显,ChatGPT的爆火,带动了AIGC(AI-Generated Content)概念的火热。 …...

【深度强化学习】(2) Double DQN 模型解析,附Pytorch完整代码
大家好,今天和大家分享一个深度强化学习算法 DQN 的改进版 Double DQN,并基于 OpenAI 的 gym 环境库完成一个小游戏,完整代码可以从我的 GitHub 中获得: https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model 1…...

【正则表达式】正则表达式语法规则
正则表达式语法规则1.普通字符 字符描述[ABC]匹配 […] 中的所有字符[^ABC]匹配除了 […] 中字符的所有字符[A-Z][A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母.匹配除换行符以外的任意字符[\s\S]匹配所有。\s 是匹配所有空白符…...
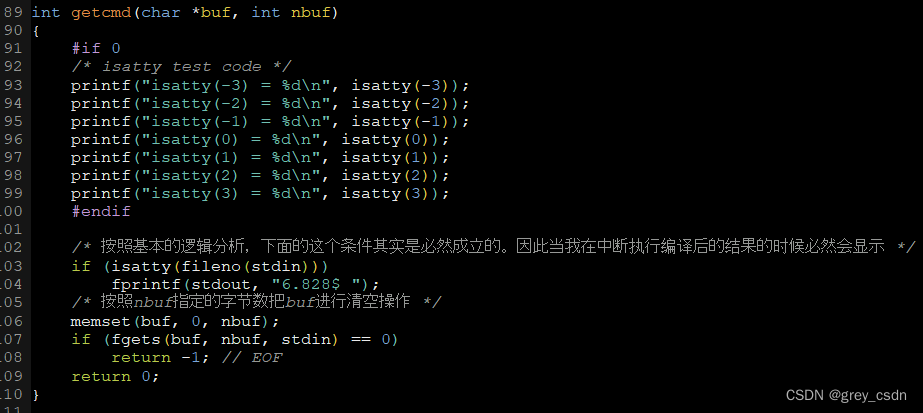
1636_isatty函数的功能
全部学习汇总: GreyZhang/g_unix: some basic learning about unix operating system. (github.com) 前面刚刚看完了一个函数和三个文件指针,一行代码懂了半行。但是继续分析我之前看到的代码还是遇到了困难,因为之前自己对于UNIX的一些基础知…...
基于Stackelberg博弈的光伏用户群优化定价模型(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

EXCEL职业版本(3)
Excel职业版本(3) 公式与函数 运算符 算数运算符 关系运算符 地址的引用 相对引用:你变它就变,如影随形 A2:A5 绝对引用:以不变应万变 $A$2 混合引用:识时务者为俊杰,根据时…...

查找Pycharm跑代码下载模型存放位置以及有关模型下载小技巧(model_name_or_path参数)
目录一、前言二、发现问题三、删除这些模型方法一:直接删除注意方法二:代码删除一、前言 当服务器连不上,只能在本地跑代码时需要使用***预训练语言模型进行处理 免不了需要把模型下载到本地 时间一长就会发现C盘容量不够 二、发现问题 正…...

JS学习笔记day04
今日内容 零、 复习昨日 一、事件 二、DOM操作 三、案例 零、 复习昨日 js 脚本语言,弱类型 引入方案: 3种 js的内容: 语法dombom 语法 变量 var 数据类型 引用类型 - 对象,JSON {key:value,key:value} 数组 var arr new Array();var arr [1,2];下标取值赋值pop() s…...

异步控制流程 遍历篇
文章目录基础方法onlyOnce 只执行一次,第二次报错once 只执行一次,第二次无效iteratorSymbol 判断是否具有迭代器并返回迭代器arrayEach 普通数组遍历baseEach 对象类型遍历symbolEach 具有迭代器类型遍历异步遍历each异步控制流程的目的: 对…...
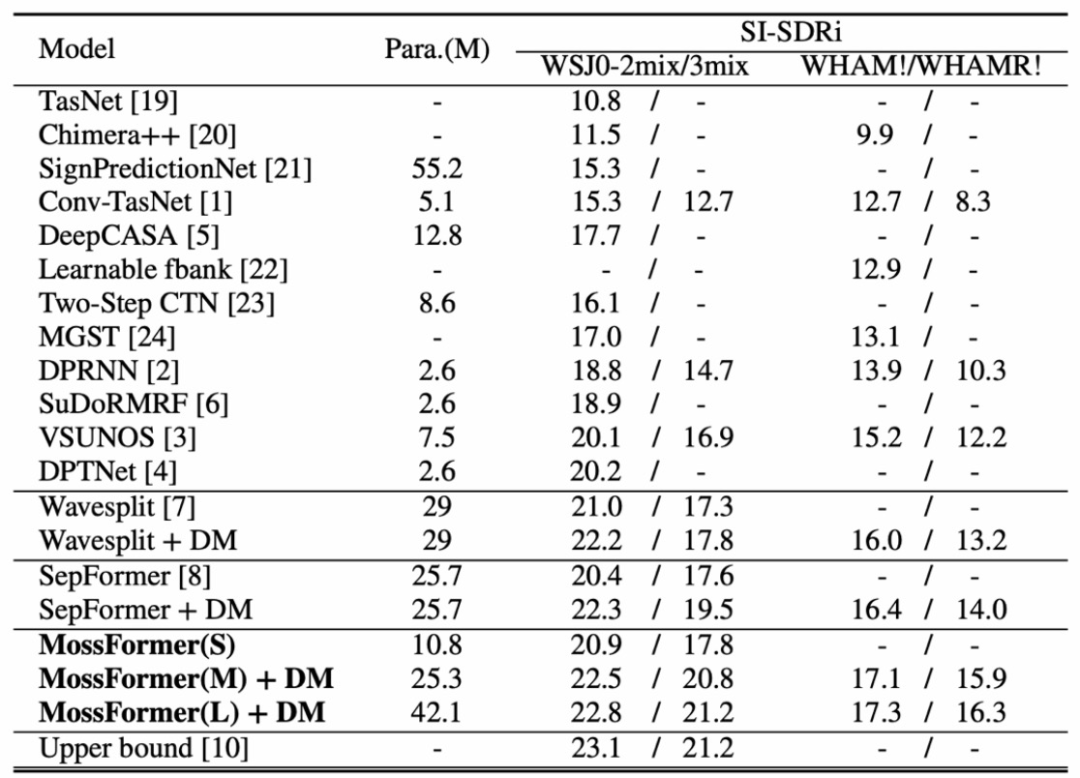
ICASSP 2023论文模型开源|语音分离Mossformer
人类能在复杂的多人说话环境中轻易地分离干扰声音,选择性聆听感兴趣的主讲人说话。但这对机器却不容易,如何构建一个能够媲美人类听觉系统的自动化系统颇具挑战性。 本文将详细解读ICASSP2023本届会议收录的单通道语音分离模型Mossformer论文࿰…...

vs2019 更改工程项目名称
本地 解决方案所在的位置为:D:\Projcet 解决方案名称:hello.sln 位置:D:\Projcet\hello.sln 工程项目名称:test 位置:D:\Projcet\test (文件夹中包含头文件,源文件) 工程包含的文件: fun.h …...
FusionCompute安装和配置步骤
1. 先去华为官网下载FusionCompute的镜像 下载地址:https://support.huawei.com/enterprise/zh/distributed-storage/fusioncompute-pid-8576912/software/251713663?idAbsPathfixnode01%7C22658044%7C7919788%7C9856606%7C21462752%7C8576912 下载后放在D盘中&am…...

Agnix:为AI智能体打造安全可控的操作系统级执行环境
1. 项目概述:从“智能体”到“操作系统”的范式跃迁最近在开源社区里,一个名为agent-sh/agnix的项目引起了我的注意。乍一看这个名字,agent和agnix的组合,很容易让人联想到这是又一个基于大语言模型的智能体(Agent&…...

200+ 发音人怎么缩小范围:先定风格再试听
🎯 200 发音人怎么缩小范围:先定风格再试听面对顶伯文字转语音工具中超过 200 种发音人,选择困难症难免发作。😵 别急,掌握 「先定风格再试听」 的筛选逻辑,就能快速锁定目标。 本文从风格分类、筛选技巧到…...

抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频
抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and …...
Translumo:Windows游戏实时翻译的终极免费解决方案:如何轻松翻译游戏字幕和视频文本
Translumo:Windows游戏实时翻译的终极免费解决方案:如何轻松翻译游戏字幕和视频文本 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.c…...

公考备考提分真相:从学员视角解析粉笔讲练测评闭环教学体系
引言在公务员考试备考赛道中,无数考生都面临同一个核心困惑:花费时间和金钱报名培训机构,究竟能不能实现有效提分?不少备考者有过备考失利的经历,也踩过传统公考培训的诸多坑。很多传统课程老师讲课条理清晰、内容丰富…...

实验记录-农药种衣剂
1.显色度取决于种子颗粒大小,种子越大,则显色越差;2.需加入增稠剂...

免费LLM API实战指南:从选型到架构的完整解决方案
1. 项目概述:一份免费LLM API的实用指南 如果你正在开发AI应用,或者只是想低成本地体验各种大语言模型,那么“API调用成本”绝对是一个绕不开的痛点。无论是OpenAI还是Anthropic,按Token计费的模式在频繁调用下,账单数…...

为 OpenClaw 配置 Taotoken 以实现自动化工作流中的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 OpenClaw 配置 Taotoken 以实现自动化工作流中的模型调用 OpenClaw 是一款强大的自动化工作流工具,能够通过编排任务…...

基于确定性脚本与LLM决策的AI多智能体自动化监控系统设计与实践
1. 项目概述:一个为AI多智能体协作而生的“自动化监工”如果你正在用OpenClaw这类框架玩多AI智能体协作,大概率会遇到一个头疼的问题:怎么知道这群“数字员工”到底在不在干活?谁在摸鱼?任务到底完成了没有?…...

飞书文档批量导出工具:25分钟搞定700+文档的迁移难题
飞书文档批量导出工具:25分钟搞定700文档的迁移难题 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 当企业需要切换办公平台或进行数据备份时,飞书文档的批量迁移常常成为…...