FlinkCDC 数据同步优化及常见问题排查
【面试系列】Swift 高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏:
欢迎关注微信公众号:野老杂谈
⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题.
⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、应用领域等内容。
⭐️ 全流程数据技术实战指南:全面讲解从数据采集到数据可视化的整个过程,掌握构建现代化数据平台和数据仓库的核心技术和方法。
文章目录
- Flink 作业优化参数
- Debezium 连接器优化参数
- Kafka Sink 优化参数
- 资源分配
- 监控和调试
- 示例配置
- 常见问题及解决方法
- 总结
Flink CDC 性能优化主要涉及到 Flink 作业的配置、Debezium 连接器的参数调整以及资源的合理分配。以下是一些常用的性能优化参数及其解释:
Flink 作业优化参数
-
并行度(Parallelism):
- 增加作业的并行度可以提高数据处理能力。通过
env.setParallelism(int parallelism)设置 Flink 作业的并行度。
- 增加作业的并行度可以提高数据处理能力。通过
-
Checkpoint 机制:
- 启用并优化 checkpoint 机制,确保数据的准确性和一致性。设置 checkpoint 的间隔和超时,如
env.enableCheckpointing(10000)(10秒)。
- 启用并优化 checkpoint 机制,确保数据的准确性和一致性。设置 checkpoint 的间隔和超时,如
-
内存管理:
- 配置 TaskManager 的内存参数,确保作业有足够的内存资源。
- 调整
taskmanager.memory.task.heap.size和taskmanager.memory.task.off-heap.size。
-
状态后端(State Backend):
- 使用高性能的状态后端,如 RocksDB 状态后端,并配置合适的参数。
- 设置状态后端如:
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints"))。
Debezium 连接器优化参数
-
批量大小(Batch Size):
- 调整批量抓取的大小,可以通过
snapshot.fetch.size参数配置。 - 示例:
snapshot.fetch.size = 1024。
- 调整批量抓取的大小,可以通过
-
最大缓存行数(Max Queue Size):
- 调整缓存行数,平衡内存使用和吞吐量。配置
max.queue.size参数。 - 示例:
max.queue.size = 8192。
- 调整缓存行数,平衡内存使用和吞吐量。配置
-
轮询间隔(Polling Interval):
- 调整轮询数据库变更日志的间隔,减少延迟。配置
poll.interval.ms参数。 - 示例:
poll.interval.ms = 500。
- 调整轮询数据库变更日志的间隔,减少延迟。配置
-
数据库连接池大小(Database Connection Pool Size):
- 增加数据库连接池的大小,提高并发查询能力。配置
connection.pool.size参数。 - 示例:
connection.pool.size = 20。
- 增加数据库连接池的大小,提高并发查询能力。配置
-
线程池大小(Thread Pool Size):
- 配置处理线程池的大小,增强数据处理能力。配置
max.batch.size和max.queue.size。 - 示例:
max.batch.size = 2048。
- 配置处理线程池的大小,增强数据处理能力。配置
Kafka Sink 优化参数
-
生产者并发度(Producer Parallelism):
- 增加 Kafka 生产者的并发度,提高数据写入性能。
- 示例:
properties.put("num.producers", "3")。
-
批量大小(Batch Size):
- 调整生产者批量发送的大小,减少网络开销。配置
batch.size参数。 - 示例:
batch.size = 16384。
- 调整生产者批量发送的大小,减少网络开销。配置
-
缓冲区内存(Buffer Memory):
- 增加 Kafka 生产者的缓冲区内存,处理高并发的写入请求。配置
buffer.memory参数。 - 示例:
buffer.memory = 33554432。
- 增加 Kafka 生产者的缓冲区内存,处理高并发的写入请求。配置
资源分配
-
TaskManager 资源:
- 分配足够的 CPU 和内存资源给 TaskManager,确保 Flink 作业的稳定运行。
- 示例:
taskmanager.numberOfTaskSlots: 4,taskmanager.memory.process.size: 4096m。
-
JobManager 资源:
- 确保 JobManager 有足够的资源来管理作业。
- 示例:
jobmanager.memory.process.size: 2048m。
监控和调试
-
Metrics 监控:
- 启用 Flink 的监控功能,实时监控作业的性能和资源使用情况。
- 配置
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter。
-
日志级别:
- 调整日志级别,捕捉和分析性能瓶颈。
- 配置
log4j.logger.org.apache.flink=INFO,必要时调整为DEBUG级别。
示例配置
# Flink 配置
taskmanager.numberOfTaskSlots: 4
taskmanager.memory.process.size: 4096m
jobmanager.memory.process.size: 2048m
env.parallelism: 4
env.checkpoint.interval: 10000
state.backend: rocksdb# Debezium 配置
snapshot.fetch.size: 1024
max.queue.size: 8192
poll.interval.ms: 500
connection.pool.size: 20
max.batch.size: 2048# Kafka 配置
properties:bootstrap.servers: "localhost:9092"num.producers: 3batch.size: 16384buffer.memory: 33554432
使用 Flink CDC 进行数据同步时,可能会遇到一些常见问题。以下列出了一些常见问题及其解决方法:
常见问题及解决方法
-
高延迟问题
问题描述:数据变更不能及时同步,延迟较高。
解决方法:
- 增加并行度:提高 Flink 作业的并行度,使数据处理速度更快。
- 优化批量大小:调整 Debezium 连接器的
snapshot.fetch.size和max.batch.size,确保批处理高效。 - 调整轮询间隔:减少 Debezium 连接器的
poll.interval.ms,加快数据捕获频率。 - 资源配置:确保 Flink 集群和数据库有足够的资源,防止资源瓶颈。
-
任务重启或失败
问题描述:Flink CDC 作业频繁重启或失败,影响数据同步的稳定性。
解决方法:
- Checkpoint 配置:启用和优化 checkpoint,确保数据的一致性和恢复能力。设置合理的 checkpoint 间隔和超时。
- 错误处理策略:设置适当的错误处理策略,例如重试次数和重启策略。
- 监控和日志:通过 Flink 的监控和日志分析,找出任务失败的原因,针对性地解决问题。
-
数据丢失
问题描述:部分数据未能成功同步到目标系统,导致数据丢失。
解决方法:
- Checkpoint 和保存点:启用 checkpoint 和保存点,确保在任务失败时能够恢复数据。
- 数据源配置:确保 Debezium 连接器正确配置,能够捕获所有的变更日志。
- 消息队列配置:如果使用 Kafka 作为中间层,确保 Kafka 的可靠性配置,如
acks=all,min.insync.replicas等。
-
数据不一致
问题描述:源数据库和目标系统的数据不一致。
解决方法:
- 事务支持:确保源数据库的事务支持,Debezium 连接器能够正确处理事务。
- 数据验证:定期进行数据验证,确保源数据和目标数据的一致性。
- 故障恢复:在发生故障时,通过 checkpoint 恢复,确保数据不丢失。
-
性能瓶颈
问题描述:数据量较大时,Flink 作业或数据库出现性能瓶颈。
解决方法:
- 水平扩展:增加 Flink 集群的节点数和并行度,提升整体处理能力。
- 索引优化:优化数据库表的索引,提高查询和数据捕获的性能。
- 批处理优化:调整批处理大小和平衡,确保数据处理的高效。
-
网络问题
问题描述:网络延迟或不稳定导致数据同步中断或延迟。
解决方法:
- 网络监控:监控网络状况,及时发现并解决网络问题。
- 重试机制:设置合理的重试机制,确保在网络中断时能够恢复数据传输。
- 网络优化:优化网络配置,确保网络带宽和延迟在可控范围内。
-
版本兼容性
问题描述:Flink CDC 组件与 Flink、Debezium、数据库或目标系统的版本不兼容,导致功能异常或错误。
解决方法:
- 版本检查:在部署前,检查 Flink、Debezium、数据库和目标系统的版本兼容性。
- 升级策略:制定合理的升级策略,确保版本更新时各组件的兼容性。
- 社区支持:关注 Flink CDC 和 Debezium 社区,获取最新的版本信息和支持。
总结
使用 Flink CDC 进行数据同步时,常见问题包括高延迟、任务重启或失败、数据丢失、数据不一致、性能瓶颈、网络问题和版本兼容性问题。通过增加并行度、优化批量大小和轮询间隔、启用 checkpoint 和保存点、优化索引、监控网络、检查版本兼容性等方法,可以有效解决这些问题,确保数据同步的高效性和稳定性。定期进行数据验证和监控,及时发现和解决问题,是保证数据同步系统稳定运行的关键。
优化 Flink CDC 的性能需要从 Flink 作业配置、Debezium 连接器参数、Kafka Sink 参数以及资源分配等多方面进行综合考虑和调整。合理配置这些参数,可以显著提升数据处理的吞吐量和降低延迟,确保数据同步的高效性和稳定性。通过监控和调试,可以持续发现并解决性能瓶颈,保证系统的高效运行。
💗💗💗 如果觉得这篇文对您有帮助,请给个点赞、关注、收藏吧,谢谢!💗💗💗
相关文章:

FlinkCDC 数据同步优化及常见问题排查
【面试系列】Swift 高频面试题及详细解答 欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: 欢迎关注微信公众号:野老杂谈 ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、…...

手把手edusrc漏洞挖掘和github信息收集
0x1 前言 这里主要还是介绍下新手入门edusrc漏洞挖掘以及在漏洞挖掘的过程中信息收集的部分哈!(主要给小白看的,大佬就当看个热闹了)下面的话我将以好几个不同的方式来给大家介绍下edusrc入门的漏洞挖掘手法以及利用github信息收…...
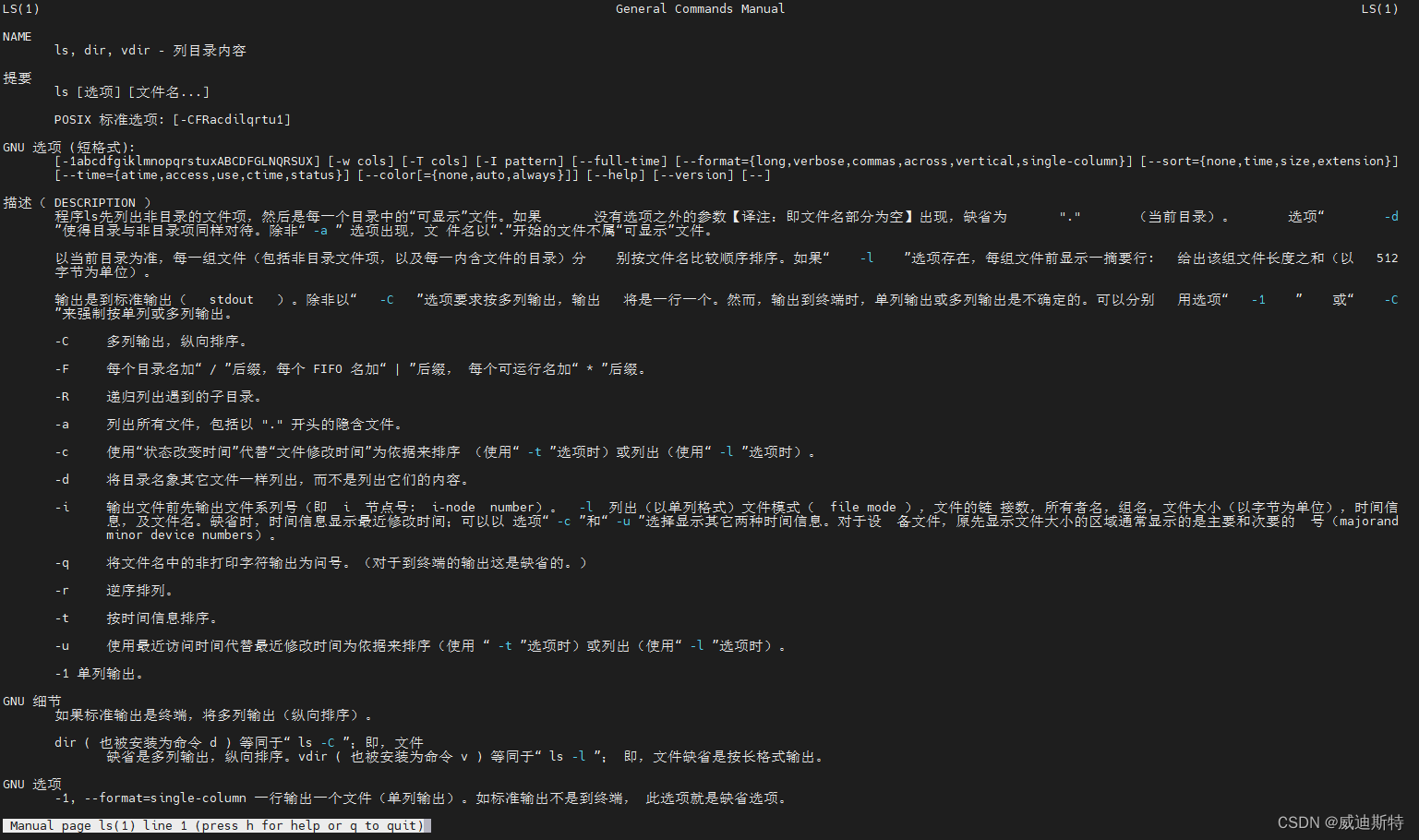
linux系统中的各种命令的解释和帮助(含内部命令、外部命令)
目录 一、说明 二、命令详解 1、帮助命令的种类 (1)help用法 (2)--help用法 2、如何区别linux内部命令和外部命令 三、help和—help 四、man 命令 1、概述 2、语法和命令格式 (1)man命令的格式&…...

Gemma轻量级开放模型在个人PC上释放强大性能,让每个桌面秒变AI工作站
Google DeepMind团队最近推出了Gemma,这是一个基于其先前Gemini模型研究和技术的开放模型家族。这些模型专为语言理解、推理和安全性而设计,具有轻量级和高性能的特点。 Gemma 7B模型在不同能力领域的语言理解和生成性能,与同样规模的开放模型…...
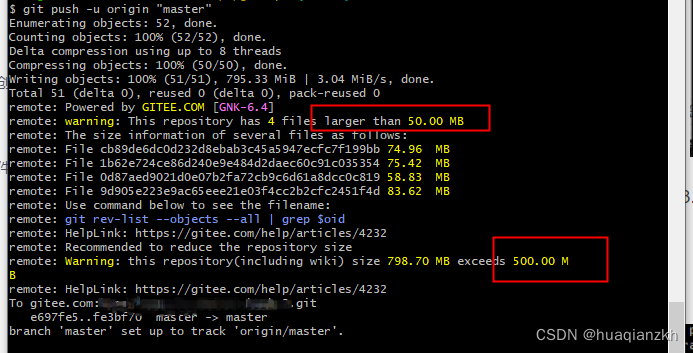
Git使用中遇到的问题(随时更新)
问题1.先创建本地库,后拉取远程仓库时上传失败的问题怎么解决? 操作主要步骤: step1 设置远程仓库地址: $ git remote add origin gitgitee.com:yourAccount/reponamexxx.git step2 推送到远程仓库: $ git push -u origin "master&qu…...

php 跨域问题
设置header <?php $origin isset($_SERVER[HTTP_ORIGIN])? $_SERVER[HTTP_ORIGIN]:;$allow_originarray(http://www.aaa.com,http://www.bbb.com, ); if( $origin in $allow_origin ){header("Access-Control-Allow-Origin:".$origin);header("Access-Co…...

【leetcode52-55图论、56-63回溯】
图论 回溯...
2024 年江西省研究生数学建模竞赛题目 A题交通信号灯管理---完整文章分享(仅供学习)
问题: 交通信号灯是指挥车辆通行的重要标志,由红灯、绿灯、黄灯组成。红灯停、绿灯行,而黄灯则起到警示作用。交通信号灯分为机动车信号灯、非机动车信号灯、人行横道信号 灯、方向指示灯等。一般情况下,十字路口有东西向和南北向…...
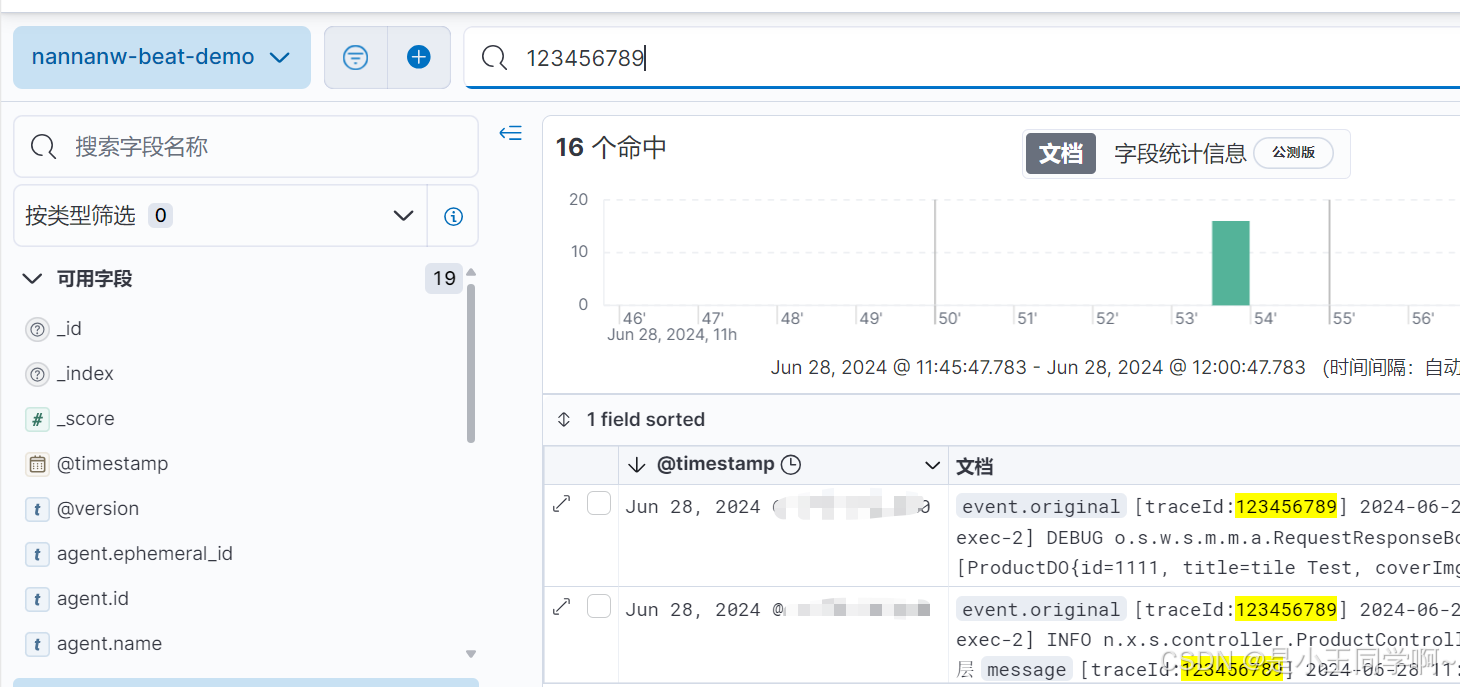
日志可视化监控体系ElasticStack 8.X版本全链路实战
目录 一、SpringBoot3.X整合logback配置1.1 log4j、logback、self4j 之间关系 1.2 SpringBoot3.X整合logback配置 二、日志可视化分析ElasticStack 2.1为什么要有Elastic Stack 2.2 什么是Elastic Stack 三、ElasticSearch8.X源码部署 四、Kibana源码部署 五、LogSta…...

【LinuxC语言】定义线程池结果
文章目录 前言任务结构体线程池定义总结前言 在并发编程中,线程池是一种非常重要的设计模式。线程池可以有效地管理和控制线程的数量,避免线程频繁创建和销毁带来的性能开销,提高系统的响应速度。在Linux环境下,我们可以使用C语言来实现一个简单的线程池。 线程池的主要组…...

uniapp分包
分包是为了优化小程序的下载和启动速度 小程序启动默认下载主包并启动页面,当用户进入分包时,才会下载对应的分包,下载完进行展示。 /* 在manifest.json配置下添加optimization,开启分包优化 */ "mp-weixin" : {/**分包…...
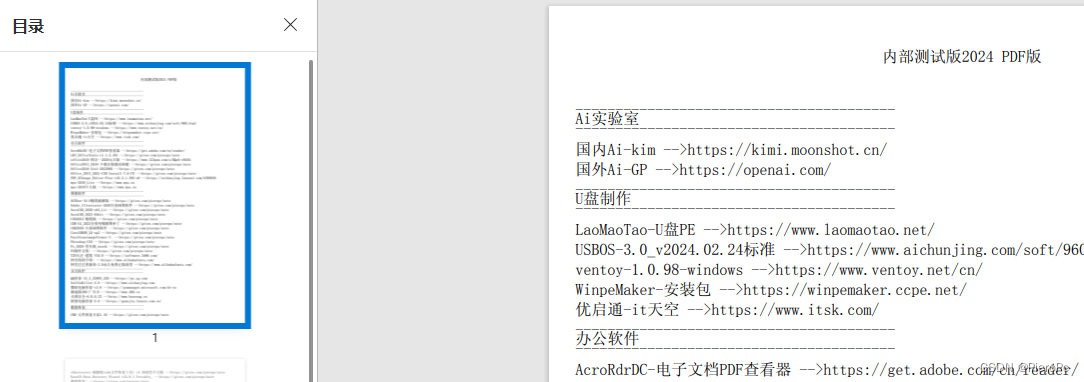
Python 生成Md文件带超链 和 PDF文件 带分页显示内容
software.md # -*- coding: utf-8 -*- import os f open("software.md", "w", encoding"utf-8") f.write(内部测试版2024 MD版\n) for root, dirs, files in os.walk(path): dax os.path.basename(root)if dax "":print("空白…...

行业模板|DataEase旅游行业大屏模板推荐
DataEase开源数据可视化分析工具于2022年6月发布模板市场(https://templates-de.fit2cloud.com),并于2024年1月新增适用于DataEase v2版本的模板分类。模板市场旨在为DataEase用户提供专业、美观、拿来即用的大屏模板,方便用户根据…...

this.$refs[tab.$attrs.id].scrollIntoView is not a function
打印this.$refs[tab.$attrs.id].scrollIntoView 在控制台看到的是一个undefined 是因为this.$refs[tab.$attrs.id] 不是一个dom 是一个vuecomponent 如图所示: 所以我用的这个document.querySelector(.${tab.$attrs.id})获取dom document.querySelector(.${tab.$attrs.id})…...

【AI是在帮助开发者还是取代他们?】AI与开发者:合作与创新的未来
目录 前言一、AI工具现状(一)GitHub Copilot(二)TabNine 二、AI对开发者的影响(一)影响和优势(二)新技能和适应策略(三)保持竞争力的策略 三、AI开发的未来&a…...
【SpringBoot Web框架实战教程(开源)】01 使用 pom 方式创建 SpringBoot 第一个项目
导读 这是一系列关于 SpringBoot Web框架实战 的教程,从项目的创建,到一个完整的 web 框架(包括异常处理、拦截器、context 上下文等);从0开始,到一个可以直接运用在生产环境中的web框架。而且所有源码均开…...

Boosting【文献精读、翻译】
Boosting Bhlmann, P., & Yu, B. (2009). Boosting. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1), 69–74. doi:10.1002/wics.55 摘要 在本文中,我们回顾了Boost方法,这是分类和回归中最有效的机器学习方法之一。虽然我们也讨…...

保姆级教程|如何配置ROS1主从机
在机器人开发经常遇到使用两个板子通信问题,比如一个板子跑底层的运动控制,一个板子跑定位导航。为了确保两个板子之间的ROS通信流畅,我们需要在两个板子的.bashrc文件中添加必要的环境变量配置。首先,确保你的 /etc/hosts 文件中…...
及其Python 和 MATLAB 实现)
贝叶斯优化算法(Bayesian Optimization)及其Python 和 MATLAB 实现
贝叶斯优化算法(Bayesian Optimization)是一种基于贝叶斯统计理论的优化方法,通常用于在复杂搜索空间中寻找最优解。该算法能够有效地在未知黑盒函数上进行优化,并在相对较少的迭代次数内找到较优解,因此在许多领域如超…...

NLP - 基于bert预训练模型的文本多分类示例
项目说明 项目名称 基于DistilBERT的标题多分类任务 项目概述 本项目旨在使用DistilBERT模型对给定的标题文本进行多分类任务。项目包括从数据处理、模型训练、模型评估到最终的API部署。该项目采用模块化设计,以便于理解和维护。 项目结构 . ├── bert_dat…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...