Java 并发集合:CopyOnWrite 写时复制集合介绍
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 016 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自己的技术栈的同学。与此同时,本专栏的所有文章,也都会准备充足的代码示例和完善的知识点梳理,因此也十分适合零基础的小白和要准备工作面试的同学学习。当然,我也会在必要的时候进行相关技术深度的技术解读,相信即使是拥有多年 Java 开发经验的从业者和大佬们也会有所收获并找到乐趣。
–
Java 集合框架(Java Collections Framework)为开发者提供了一套强大且灵活的数据结构和算法工具,使得数据管理和操作变得更加高效和简洁。在多线程环境中,如何在保证线程安全的同时,保持集合操作的高效性,成为了一个至关重要的课题。为此,Java 提供了一系列并发集合类,其中
CopyOnWrite系列集合因其独特的“写时复制”机制,成为了解决并发读写问题的一种有效方案。
CopyOnWrite集合类主要包括CopyOnWriteArrayList和CopyOnWriteArraySet。它们通过在每次修改集合时创建一个新副本,从而保证了读操作的无锁化,这种设计极大地提高了读操作的性能,同时也简化了开发者的使用难度。然而,写时复制的特性也带来了一定的内存开销和写操作的性能代价。因此,了解其工作原理和适用场景,对于我们在实际开发中选择合适的集合类至关重要。在本文中,我们将深入探讨
CopyOnWrite集合的实现原理、优缺点以及适用场景,帮助读者全面理解和正确使用这些集合类。无论是编写高性能的多线程应用程序,还是解决复杂的并发数据访问问题,掌握CopyOnWrite集合的使用技巧,都将为您的开发工作带来极大的助益。
文章目录
- 1、写时复制的介绍
- 2、写时复制的实现
- 2.1、CopyOnWriteArrayList 数据结构
- 2.2、CopyOnWriteArrayList 读操作
- 2.2、CopyOnWriteArrayList 写时复制
- 2.2.1、add() 函数
- 2.2.2、remove() 函数
- 2.2.3、set() 函数
- 2.3、CopyOnWriteArraySet 的实现
- 3、写实复制的特性
- 3.1、读多写少
- 3.2、弱一致性
- 3.3、连续存储
- 3.3.1、数组容器
- 3.3.3、非数组容器
1、写时复制的介绍
写时复制(Copy-on-Write,简称COW)是一种计算机程序设计领域的优化策略。
其核心思想是:如果有多个调用者同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这一过程对其他的调用者都是透明的。
- 当对容器进行写操作(这里的写可以理解为 “增、删、改”)时,为了避免读写操作同时进行而导致的线程安全问题
我们将原始容器中的数据复制一份放入新创建的容器,然后对新创建的容器进行写操作; - 而读操作继续在原始容器上进行,这样读写操作之间便不会存在数据访问冲突,也就不存在线程安全问题
当写操作执行完成之后,新创建的容器替代原始容器,原始容器便废弃。
写时复制的主要优点是,如果调用者没有修改该资源,就不会有副本被创建,因此多个调用者只是进行读取操作时可以共享同一份资源。这种策略不仅优化了内存使用,还保护了数据,因为在写操作之前,原始数据不会被覆盖或修改,从而避免了数据丢失的风险。
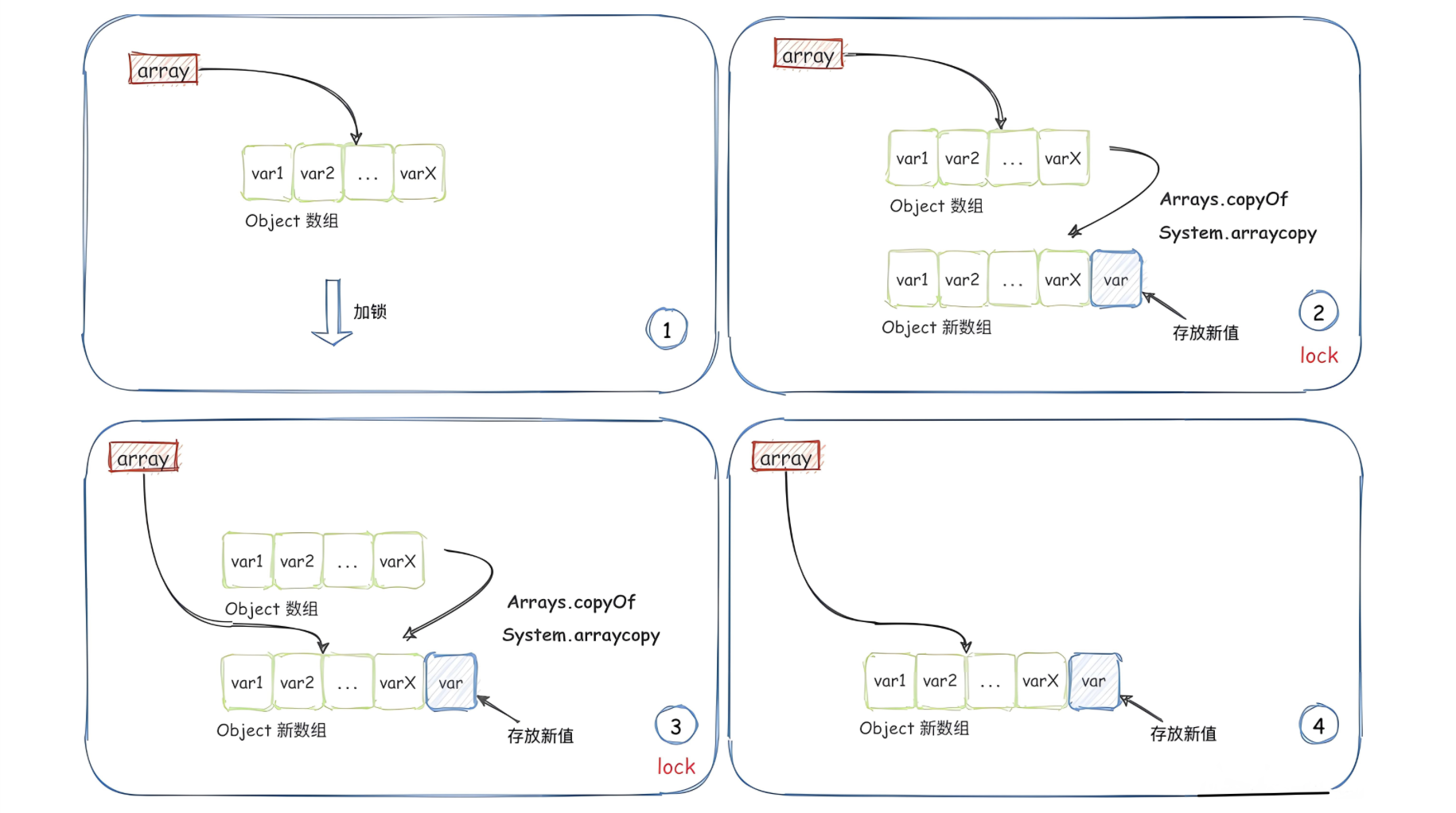
在 Java 中,CopyOnWriteArrayList 和 CopyOnWriteArraySet 就是使用了这种策略的两个类。这两个类都位于java.util.concurrent 包下,是线程安全的集合类。当需要修改集合中的元素时,它们不会直接在原集合上进行修改,而是复制一份新的集合,然后在新的集合上进行修改。修改完成后,再将指向原集合的引用指向新的集合。这种设计使得读操作可以在不加锁的情况下进行,从而提高了并发性能。
总的来说,写时复制是一种适用于读多写少场景的优化策略,它通过复制数据的方式实现了读写分离,提高了并发性能。但是,它也存在一些潜在的性能问题,如内存占用增加、写操作性能下降以及频繁的垃圾回收。因此,在使用时需要根据具体场景进行权衡和选择。
2、写时复制的实现
2.1、CopyOnWriteArrayList 数据结构
CopyOnWriteArrayList 是 Java 中的一种线程安全的 List 实现,它通过每次写操作时复制底层数组来保证线程安全。CopyOnWriteArrayList 跟 ArrayList 一样,也实现了 List 接口:
public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable {// ReentrantLock用于保证在多线程环境下的线程安全final transient ReentrantLock lock = new ReentrantLock();// 持有实际元素的数组,通过volatile修饰保证在多线程环境下的可见性private transient volatile Object[] array;// 默认构造函数,初始化一个空数组public CopyOnWriteArrayList() {this.array = new Object[0];}// 省略其他方法和实现细节...
}可以看到,CopyOnWriteArrayList 底层的数据结构是一个数组(Object[] array)。这个数组通过 volatile 修饰,保证在多线程环境下的可见性。当数组内容发生变化时,其他线程能够立即看到最新的数组内容。
2.2、CopyOnWriteArrayList 读操作
读操作不需要加锁,因为写操作总是会生成新的数组副本,并且数组引用是 volatile 的,所以读操作总能读取到最新的数组内容。这使得读操作非常高效,适用于读多写少的场景。
public E get(int index) {return (E) this.array[index];
}
get() 函数实现了 CopyOnWriteArrayList 的读操作,代码逻辑非常简单,直接按照下标访问 array 数组从代码中我们可以发现,读操作没有加锁,因此即便在多线程环境下,效率也非常高
2.2、CopyOnWriteArrayList 写时复制
当对 CopyOnWriteArrayList 进行写操作(如 add, set, remove)时,都会创建底层数组的新副本。在新的副本上进行修改操作,修改完成后再将引用指向新的数组。这种写时复制的机制保证了在进行写操作时不会影响到正在进行读操作的线程。
2.2.1、add() 函数
add() 函数的代码实现如下所示,add() 函数包含写时复制逻辑,因此相对于 get() 函数,要复杂一些
public boolean add(E e) {// 获取锁,确保在多线程环境下只有一个线程能进行写操作lock.lock();try {// 获取当前数组的长度int len = array.length;// 使用 Arrays.copyOf() 方法创建一个新数组,并将现有数组的元素复制到新数组中// Arrays.copyOf() 方法底层依赖 native 方法 System.arraycopy() 来实现复制操作,速度较快Object[] newElements = Arrays.copyOf(array, len + 1);// 将新元素添加到新数组的最后一个位置newElements[len] = e;// 将底层数组引用指向新数组array = newElements;// 返回 true 表示添加成功return true;} finally {// 释放锁lock.unlock();}
}
当往容器中添加数据时,并非直接将数据添加到原始数组中,而是创建一个长度比原始数组大一的数组 newElements,将原始数组中的数据拷贝到 newElements。然后将数据添加到 newElements 的末尾,最后修改 array 引用指向 newElements。
除此之外,我们可以看到,为了保证写操作的线程安全性,避免两个线程同时执行写时复制,写操作通过加锁(lock.lock();)来串行执行也就是说:读读、读写都可以并行执行,唯独写写不可以并行执行.
2.2.2、remove() 函数
remove() 函数的代码实现如下所示:
public E remove(int index) {// 获取锁,确保在多线程环境下只有一个线程能进行写操作lock.lock();try {// 获取当前数组的长度int len = array.length;// 获取指定索引处的元素,该元素将在稍后被移除E oldValue = get(array, index);// 计算从指定索引到数组末尾之间的元素个数int numMoved = len - index - 1;if (numMoved == 0) {// 如果要移除的元素是数组的最后一个元素,直接创建一个长度为 len - 1 的新数组array = Arrays.copyOf(array, len - 1);} else {// 如果要移除的元素在数组的中间位置Object[] newElements = new Object[len - 1];// 将原数组中从索引 0 到 index-1 的元素复制到新数组中System.arraycopy(array, 0, newElements, 0, index); // array[0, index - 1]// 将原数组中从索引 index+1 到末尾的元素复制到新数组中,从 index 位置开始System.arraycopy(array, index + 1, newElements, index, numMoved); // 更新底层数组引用为新数组array = newElements;}// 返回被移除的元素return oldValue;} finally {// 释放锁lock.unlock();}
}
remove() 函数的处理逻辑跟 add() 函数类似:先通过加锁保证写时复制操作的线程安全性,然后申请一个大小比原始数组大小小一的新数组 newElements。除了待删除数据之外,我们将原始数组中的其他数据统统拷贝到 newElements,拷贝完成之后,我们将 array 引用指向 newElements。
2.2.3、set() 函数
set() 函数的代码实现如下所示
public E set(int index, E element) {// 获取锁,确保在多线程环境下只有一个线程能进行写操作lock.lock();try {// 获取指定索引处的旧值E oldValue = get(array, index);// 如果旧值与新值不同,才进行更新操作if (oldValue != element) {// 获取当前数组的长度int len = array.length;// 使用 Arrays.copyOf() 方法创建一个新数组,并将现有数组的元素复制到新数组中// Arrays.copyOf() 方法底层依赖 native 方法 System.arraycopy() 来实现复制操作,速度较快Object[] newElements = Arrays.copyOf(array, len);// 将新元素放置到指定索引处newElements[index] = element;// 更新底层数组引用为新数组array = newElements;}// 返回旧值return oldValue;} finally {// 释放锁lock.unlock();}
}
在 set() 函数中,跟 add() 函数、remove() 函数的类似,通过加锁确保线程安全,在旧值与新值不同时复制底层数组并替换指定索引处的元素,最后更新数组引用并释放锁。
2.3、CopyOnWriteArraySet 的实现
CopyOnWriteArraySet 使用 CopyOnWriteArrayList 作为底层数据结构,通过写时复制的方式保证线程安全。
public class CopyOnWriteArraySet<E> extends AbstractSet<E> {// 底层数据结构使用 CopyOnWriteArrayList 来存储元素private final CopyOnWriteArrayList<E> al;// 默认构造函数,初始化底层的 CopyOnWriteArrayListpublic CopyOnWriteArraySet() {al = new CopyOnWriteArrayList<E>();}// 添加元素到集合中,如果元素不存在则添加并返回 true,否则返回 falsepublic boolean add(E e) {return al.addIfAbsent(e);}// 从集合中移除指定元素,如果移除成功则返回 true,否则返回 falsepublic boolean remove(Object o) {return al.remove(o);}// 判断集合中是否包含指定元素,如果包含则返回 true,否则返回 falsepublic boolean contains(Object o) {return al.contains(o);}// 省略其他方法和实现细节...
}
添加元素时,只有在元素不存在时才会添加;移除和检查元素的方法直接委托给底层的 CopyOnWriteArrayList 实现。整个实现确保了高并发环境下的安全性和一致性。
3、写实复制的特性
3.1、读多写少
从上述 CopyOnWriteArrayList 的源码和性能测试结果可以得出以下结论:
-
写操作需要加锁:所有的写操作(如
add、set、remove等)都需要获取锁,确保线程安全性,因此这些操作只能串行执行; -
写时复制:每次写操作都需要创建数组副本并进行数据拷贝,这涉及大量的数据搬移,导致写操作的执行效率非常低;
-
读多写少的场景:由于写操作的高开销,
CopyOnWriteArrayList适用于读多写少的应用场景。在这种场景下,读操作可以并发执行,且无需加锁。
以下是一个性能测试的示例代码,用于比较 CopyOnWriteArrayList 和 ArrayList 在执行大量写操作时的耗时:
public class Demo {public static void main(String[] args) {List<Integer> cowList = new CopyOnWriteArrayList<>();long startTime = System.currentTimeMillis();for (int i = 0; i < 100000; i++) {cowList.add(i);}System.out.println("CopyOnWriteArrayList耗时: " + (System.currentTimeMillis() - startTime) + " 毫秒");List<Integer> list = new ArrayList<>();startTime = System.currentTimeMillis();for (int i = 0; i < 100000; i++) {list.add(i);}System.out.println("ArrayList耗时: " + (System.currentTimeMillis() - startTime) + " 毫秒");}
}
这里我执行的结果是:CopyOnWriteArrayList 执行 100000 次写操作耗时约 2098 毫秒。ArrayList 执行同样数量的写操作仅耗时约 2 毫秒。CopyOnWriteArrayList 的耗时是 ArrayList 的 1000 多倍,说明在写操作频繁的场景下,CopyOnWriteArrayList 的性能表现非常差。
3.2、弱一致性
CopyOnWriteArrayList 由于写时复制的特性,写操作的结果并不会立即对读操作可见。写操作在新数组上执行,而读操作在原始数组上执行,这就导致在 array 引用指向新数组之前,读操作只能读取到旧的数据。这种现象被称为弱一致性。
在示例代码中,存在两个线程:一个线程调用 add() 函数添加数据,另一个线程调用 sum() 函数遍历容器求和。
public class Demo {private List<Integer> scores = new CopyOnWriteArrayList<>();public void add(int idx, int score) {scores.add(idx, score); // 将数据插入到 idx 下标位置}public int sum() {int ret = 0;for (int i = 0; i < scores.size(); i++) {ret += scores.get(i);}return ret;}
}
重复统计问题的产生:假设一个线程在执行 add(int idx, int score) 方法向 scores 列表中添加数据的同时,另一个线程在执行 sum() 方法遍历 scores 列表求和。这种情况下,可能会发生以下情况:
-
线程 A 执行
add()方法:线程 A 调用scores.add(idx, score)方法,底层会创建一个新的数组并将原数组的内容复制到新数组,然后将新元素添加到新数组中; -
线程 B 执行
sum()方法:在scores列表的array引用更新之前,线程 B 开始遍历原数组;
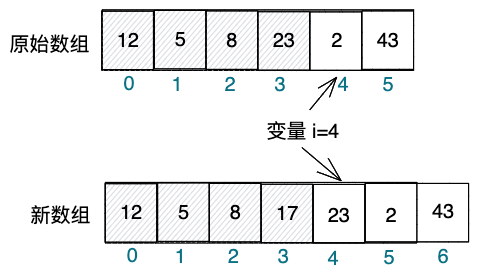
- 写时复制导致的数据不一致:由于写时复制的特性,线程 A 操作的是新数组,而线程 B 读取的是旧数组。此时,如果线程 A 更新了
array引用,指向了新数组,而线程 B 仍然在遍历旧数组,可能会产生数据不一致的问题。
假设 scores 列表中有 n 个元素,线程 A 在第 i 个位置添加新元素,而线程 B 正在遍历第 i 个元素。如果 array 引用在此时更新,指向了新数组,线程 B 会继续遍历旧数组并重复统计第 i 个元素。这就导致了 sum() 方法可能会多统计一次该元素的值,产生错误的求和结果。
迭代器实现与弱一致性问题的解决:CopyOnWriteArrayList 提供了一个专门的迭代器,用于遍历容器。这个迭代器在创建时,将原始数组赋值给 snapshot 引用,之后的遍历操作都是在 snapshot 上进行的。这样,即使 array 引用指向新的数组,也不会影响到 snapshot 引用继续指向原始数组,从而解决了弱一致性带来的问题。
以下是 CopyOnWriteArrayList 中迭代器的实现代码:
// 位于 CopyOnWriteArrayList.java 中
public Iterator<E> iterator() {return new COWIterator<E>(getArray(), 0);
}static final class COWIterator<E> implements ListIterator<E> {private final Object[] snapshot; // 指向原始数组private int cursor;private COWIterator(Object[] elements, int initialCursor) {cursor = initialCursor;snapshot = elements;}public boolean hasNext() {return cursor < snapshot.length;}@SuppressWarnings("unchecked")public E next() {if (!hasNext()) throw new NoSuchElementException();return (E) snapshot[cursor++];}// ... 省略其他方法 ...
}
使用迭代器来重构 sum() 方法,使其在遍历过程中避免重复统计的问题。重构后的代码如下:
public int sum() {int ret = 0;Iterator<Integer> itr = scores.iterator();while (itr.hasNext()) {ret += itr.next();}return ret;
}
重构后的优点:
-
避免数据不一致:由于迭代器在创建时将原始数组赋值给
snapshot,遍历操作都是在snapshot上进行,即使array引用指向新的数组,遍历过程中的数据也不会改变,从而避免了重复统计的问题; -
线程安全:迭代器提供了一种线程安全的遍历方式,确保在高并发环境下能够正确读取数据;
-
简洁代码:使用迭代器使得遍历代码更加简洁和易读,同时保证了代码的正确性和性能。
3.3、连续存储
在本篇开头,我们提到了 JUC 提供了 CopyOnWriteArrayList、CopyOnWriteArraySet 却没有提供 CopyOnWriteLinkedList、CopyOnWriteHashMap 等其他类型的写时复制容器,这是出于什么样的考虑呢?
3.3.1、数组容器
在写时复制的处理逻辑中,每次执行写操作时,哪怕只添加、修改、删除一个数据,都需要大动干戈,把原始数据重新拷贝一份。如果原始数据比较大,那么对于链表、哈希表来说,因为数据在内存中不是连续存储的,因此拷贝的耗时将非常大,写操作的性能将无法满足一个工业级通用类对性能的要求。
而 CopyOnWriteArrayList 和 CopyOnWriteArraySet 底层都是基于数组来实现的,数组在内存中是连续存储的
JUC 使用 JVM 提供的 native 方法,如下所示,通过 C++ 代码中的指针实现了内存块的快速拷贝,因此写操作的性能在可接受范围之内。
而在平时的业务开发中,对于一些读多写少的业务场景,在确保性能满足业务要求的前提下,我们仍然可以使用写时复制技术来提高读操作性能。
// 位于 System.java 中
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
3.3.3、非数组容器
JUC 没有提供非数组类型的写时复制容器,是出于对于一个工业级通用类的性能的考量对于非数组类型的容器,我们需要自己去开发相应的写时复制逻辑,
假设系统配置存储在文件中,在系统启动时,配置文件被解析加载到内存中的 HashMap 容器中,之后 HashMap 容器中的配置会频繁地被用到系统支持配置热更新,在不重启系统的情况下,我们希望能较实时地更新内存中的配置,让其跟文件中的配置保持一致
为了实现热更新这个功能,我们在系统中创建一个单独的线程,定时从配置文件中加载解析配置,更新到内存中的 HashMap 容器中
对于这样一个读多写少的应用场景,我们就可以使用写时复制技术,如下代码所示在更新内存中的配置时,使用写时复制技术,避免写操作和读操作互相影响。相对于 ConcurrentHashMap 来说,读操作完全不需要加锁,甚至连 CAS 操作都不需要,因此读操作的性能更高。
public class Configuration {private static final Map<String, String> map = new HashMap<>();// 热更新, 这里不需要加锁(只有一个线程调用此函数), 也不需要拷贝(全量更新配置)public void reload() {Map<String, String> newMap = new HashMap<>();// ... 从配置文件加载配置, 并解析放入 newMapmap = newMap;}
}
相关文章:
Java 并发集合:CopyOnWrite 写时复制集合介绍
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 016 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

Linux 查看修改系统时间| date -s
Linux 查看修改系统时间 date 命令的介绍date基本语法date命令使用示例显示指定条件的时间设置指定条件的时间时间加减操作显示文件最后修改时间显示 UTC 时间 备注 date 命令的介绍 date 命令在 Linux/Unix 系统上的使用。 date 命令可以用于查看和设置系统时间。 date基本语…...

数据库MySQL学习笔记
数据库MySQL学习笔记 主要记录常见的MySQL语句学习过程,增删改查。 -- 显示所有数据库 SHOW DATABASES;-- 创建新数据库 CREATE DATABASE mydatabase;-- 使用数据库 USE mydatabase;-- 显示当前数据库中的所有表 SHOW TABLES;-- 创建新表 CREATE TABLE users (id …...

四端口千兆以太网交换机与 SFP 扩展功能
在数字化时代,网络基础设施的重要性日益凸显,它是企业和个人取得成功的关键支撑。配备 SFP 插槽的 4 端口千兆以太网交换机提供了一种灵活且可扩展的网络解决方案,能够应对快速的数据传输、低延迟以及不断增长的带宽需求。本篇文章深入探讨了…...

Renderless 思想正在影响前端开发
本文由前端小伙伴方长_beezen 原创。欢迎大家踊跃投稿。 原文链接:https://juejin.cn/post/7385752495535472655 前言 截止到 2024 年,跨端应用开发所需要考虑的兼容性,已经涵盖了框架、平台和设备类型等多个方面,例如࿱…...
maven 打包执行配置(对maven引用的包或者丢进去的包都包含在里面)打成jar包
一 、springboot jar包 maven的pom文件 1 在resources下放了一些文件想打进去jar包 2 在lib下放了其他稀奇古怪jar包文件想打进去jar包 编写如下引入jar <build><!-- 打包名称 --><finalName>${project.artifactId}</finalName><resources><…...

Python酷库之旅-第三方库Pandas(004)
目录 一、用法精讲 5、pandas.DataFrame.to_csv函数 5-1、语法 5-2、参数 5-3、功能 5-4、返回值 5-5、说明 5-6、用法 5-6-1、代码示例 5-6-2、结果输出 6、pandas.read_fwf函数 6-1、语法 6-2、参数 6-3、功能 6-4、返回值 6-5、说明 6-6、用法 6-6-1、代码…...

天猫超市卡怎么用
猫超卡是在天猫超市里面消费用的卡 但是我们现在买东西都喜欢货比三家,肯定是哪家划算在哪买,要是淘宝其他店铺或京东卖的更便宜,猫超卡自然就用不上了 这种情况的话,还不如直接把猫超卡的余额提出来,买东西也不受限…...

ai智能语音机器人电销系统:让销售更快速高效
智能机器人电销系统是指采用人工智能和机器人技术来实现的自动电销工具。随着企业竞争加剧,销售团队面临的挑战也越来越大。在人力资源和成本控制方面有很大的限制,而传统的电销方式也已经无法满足市场需求,因此需要一种新的解决方案来提高营…...

Redis 中的通用命令(命令的返回值、复杂度、注意事项及操作演示)
Redis 中的通用命令(高频率操作) 文章目录 Redis 中的通用命令(高频率操作)Redis 的数据类型redis-cli 命令Keys 命令Exists 命令Expire 命令Ttl 命令Type命令 Redis 的数据类型 Redis 支持多种数据类型,整体来说,Redis 是一个键值对结构的,…...

【Hive实战】 HiveMetaStore的指标分析
HiveMetaStore的指标分析(一) 文章目录 HiveMetaStore的指标分析(一)背景目标部署架构 hive-site.xml相关配置元数据服务的指标相关配置 源码部分(hive2.3系)JvmPauseMonitor.javaHiveMetaStore的内部类HMS…...

【Linux系统】CUDA的安装与graspnet环境配置遇到的问题
今天在安装环境时遇到报错: The detected CUDA version (10.1) mismatches the version that was used to compile PyTorch (11.8). Please make sure to use the same CUDA versions. 报错原因:安装的cuda版本不对应,我需要安装cuda的版本…...
滤波算法学习笔记
目录 引言 一、定义 二、分类 三、常见滤波算法 四、应用与优势 五、发展趋势 例程 1. 均值滤波(Moving Average Filter) 2. 中值滤波(Median Filter) 3. 高斯滤波(Gaussian Filter) 4.指数移动…...
【机器学习】机器学习的重要方法——线性回归算法深度探索与未来展望
欢迎来到 破晓的历程博客 引言 在数据科学日益重要的今天,线性回归算法以其简单、直观和强大的预测能力,成为了众多领域中的基础工具。本文将详细介绍线性回归的基本概念、核心算法,并通过五个具体的使用示例来展示其应用,同时探…...

百度云智能媒体内容分析一体机(MCA)建设
导读 :本文主要介绍了百度智能云MCA产品的概念和应用。 媒体信息海量且复杂,采用人工的方式对视频进行分析处理,面临着效率低、成本高的困难。于是,MCA应运而生。它基于百度自研的视觉AI、ASR、NLP技术,为用户提供音视…...

笔记本电脑部署VMware ESXi 6.0系统
正文共:888 字 18 图,预估阅读时间:1 分钟 前面我们介绍了在笔记本上安装Windows 11操作系统(Windows 11升级不了?但Win10就要停服了啊!来,我教你!),也介绍了…...
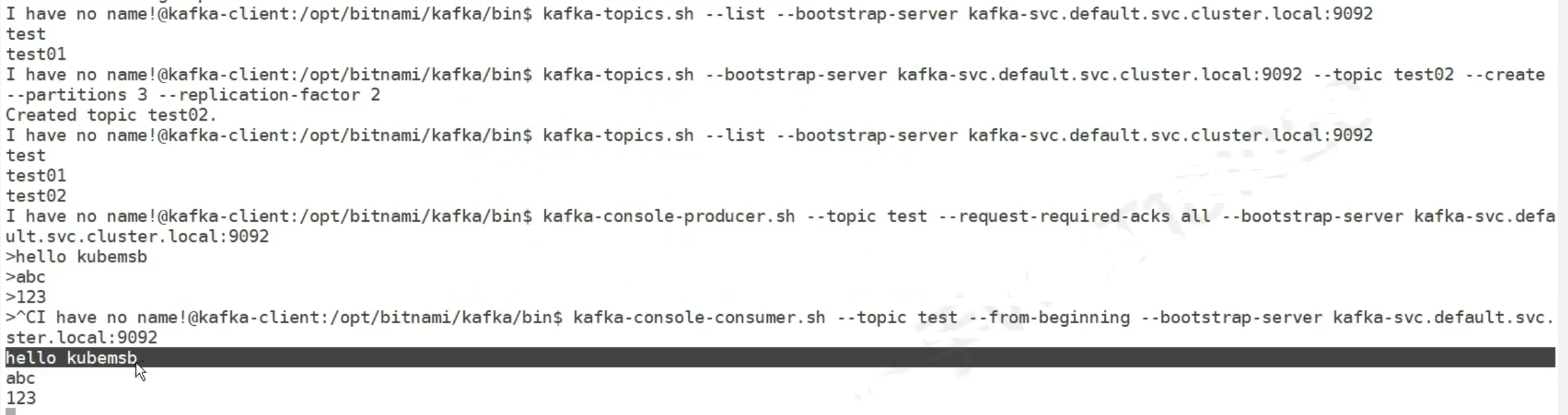
k8s 中间件
1. zookeeper 是的,Zookeeper 和 Kafka 经常一起使用,Zookeeper 在 Kafka 中扮演了关键角色。以下是 Zookeeper 和 Kafka 在实际项目中的结合使用及其作用的详细说明。 项目背景 假设我们有一个分布式数据处理系统,该系统需要高吞吐量的实…...

如何 提升需求确定性
提升需求确定性是确保项目成功的关键之一。以下是一些方法和策略可以帮助你提升需求的确定性: 积极的利益相关者参与: 确保所有关键利益相关者(包括最终用户、业务所有者、开发团队等)参与需求收集和确认过程。他们的参与可以提供…...

探索Sui的面向对象模型和Move编程语言
Sui区块链作为一种新兴的一层协议(L1),采用先进技术来解决常见的一层协议权衡问题。Cointelegraph Research详细剖析了这一区块链新秀。 Sui使用Move编程语言,该语言专注于资产表示和访问控制。本文探讨了Sui的对象中心数据存储模…...

【vue动态组件】VUE使用component :is 实现在多个组件间来回切换
VUE使用component :is 实现在多个组件间来回切换 component :is 动态父子组件传值 相关代码实现: <component:is"vuecomponent"></component>import componentA from xxx; import componentB from xxx; import componentC from xxx;switch(…...

从哈密顿量到李代数:对称性识别与结构常数计算实践
1. 从哈密顿量到李代数:物理学家工具箱里的对称性语言在理论物理和数学物理的日常工作中,我们常常面对一个核心问题:如何从一堆看似复杂的运动方程或一个写出来的哈密顿量中,快速识别出系统隐藏的“灵魂”?这个灵魂&am…...

从金融风控到工业质检:MAD离群值检测算法的5个实战应用场景与Python代码
从金融风控到工业质检:MAD离群值检测算法的5个实战应用场景与Python代码在数据驱动的商业决策中,异常值往往蕴含着关键的业务信号——可能是欺诈交易、设备故障,或是市场机会。传统基于标准差的方法容易受极端值影响,而**中位数绝…...
全解析)
C#实现稳定Windows低级鼠标钩子(WH_MOUSE_LL)全解析
1. 为什么“鼠标钩子”不是炫技,而是解决真实问题的底层能力在Windows桌面应用开发中,我见过太多人把“全局鼠标监听”当成一个玄乎其玄的功能——要么觉得它危险、难搞、容易被杀毒软件误报;要么干脆绕开,用轮询GetCursorPos这种…...

【Claude学术写作辅助应用】:教育部新文科AI赋能白皮书唯一推荐工具,附12所双一流高校实证数据
更多请点击: https://intelliparadigm.com 第一章:Claude学术写作辅助应用的政策定位与战略价值 Claude作为新一代大语言模型,在学术写作辅助领域已超越工具属性,成为支撑国家科研诚信建设、高等教育数字化转型与国际学术话语权提…...
)
CentOS 7上解决soffice转换doc到docx报错‘no export filter‘的完整指南(附字体安装)
CentOS 7服务器深度修复:soffice文档转换no export filter全链路解决方案当你在CentOS 7服务器上执行soffice --convert-to docx命令时,终端突然抛出Error: no export filter的红色警告——这不是简单的命令错误,而是典型的环境依赖链断裂。作…...
)
HarmonyOS 鸿蒙PC平台三方库移植:使用 vcpkg 移植 libzen(ZenLib)
网罗开发(小红书、快手、视频号同名)大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等方…...

原来训大模型,就像开一家小餐馆!
你是不是一直觉得,训练大语言模型是 OpenAI、百度这种大厂才能干的事?要几万张显卡,要花几个亿,普通人想都不敢想? 错了!我用自己开发机上的 8 张 H20 显卡,花了点时间,从零开始训了…...

AssetStudio深度解析:Unity序列化协议与产线级资源解包实战
1. 这不是“又一个AssetStudio教程”,而是我用它救回三个项目的真实记录AssetStudio、Unity资源提取、AssetBundle解包——这几个词,对做过Unity客户端开发、逆向分析、MOD制作或老游戏复刻的人来说,不是工具名,是救命稻草。我第一…...

为ClaudeCode配置Taotoken作为备用API解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为ClaudeCode配置Taotoken作为备用API解决访问限制 基础教程类,指导经常遇到ClaudeCode访问限制的开发者,如…...

AI Agent游戏测试革命:自动生成10万+边界用例,覆盖率提升3.2倍——附可运行Python测试Agent源码
更多请点击: https://intelliparadigm.com 第一章:AI Agent游戏行业应用全景图 AI Agent 正在重塑游戏开发、运营与玩家体验的全生命周期。从智能NPC的行为建模,到自动化测试与关卡生成,再到实时个性化内容推荐与反作弊决策&…...