人工智能笔记分享
文章目录
- 人工智能
- 图灵测试
- 分类
- 分类与聚类的区别(重点)
- 分类 (Classification)
- 聚类 (Clustering)
- 特征提取 + 分类器(重点)
- 特征提取
- 为什么要进行特征提取?(重点)
- 分类器
- 训练集、测试集大小(重点)
- K则交叉验证(重点)
- 过拟合、欠拟合
- 分类准确率
- softmax
- 卷积神经网络
- 向量卷积计算
- 矩阵、张量卷积计算
- 池化层
- 循环神经网络
- RNN
- GRU
- LSTM
- 光流骨架
- 光流(重点)
- 骨架
- 光流骨架区别
- 关联规则挖掘
- 两个兴趣度度量
- 衍生概念
- AP算法
- 聚类算法
- k-means聚类(重点)
- 层次聚类(重点)
- 密度聚类-DBSCAN(重点)
- 层次聚类和密度聚类区别(重点)
介绍
我整理了一些比较关键的、考试可能会考的点,只是为了应付考试,都是些概念,不涉及具体算法实现。希望对大家有所帮助!
人工智能
图灵测试
什么是图灵测试?
人和机器人对话, 且人不知道对方为计算机
三个老爷爷
阿兰·图灵、维纳、约翰·麦卡锡
分类
判断一个实物的类型,这样的过程在人工智能 领域里被成为分类
分类:根据所给数据的不同特点, 判断它属于哪个类别
分类与聚类的区别(重点)
- 省流:分类有监督,要预定义数据,分训练集测试集 聚类则不用,丢个数据让机器自己训练
- 应用场景:分类需提前指明分哪几类?否则只说分类特征的话,只能是聚类咯~
分类 (Classification)
- 定义: 分类是一种监督学习方法,它将输入数据分配到预定义的类别中。
- 目标: 通过学习一个模型来预测新数据点所属的类别。
- 数据类型: 需要带有标签的数据集,即每个输入数据都有一个已知的输出类别。
- 算法: 常见的分类算法包括决策树、随机森林、支持向量机(SVM)、k近邻算法(k-NN)、朴素贝叶斯和神经网络。
- 应用: 分类问题的典型应用包括垃圾邮件检测(邮件是垃圾邮件或正常邮件)、图像识别(图像中是猫还是狗)、疾病诊断(病人是否患有某种疾病)等。
聚类 (Clustering)
- 定义: 聚类是一种无监督学习方法,它将数据点分组为多个簇,使得同一个簇中的数据点彼此之间的相似度最大,不同簇的数据点之间的相似度最小。
- 目标: 发现数据中的自然分组或结构,而不是预测新数据点所属的类别。
- 数据类型: 不需要带有标签的数据集,即数据点没有预定义的输出类别。
- 算法: 常见的聚类算法包括k均值(k-means)、层次聚类(hierarchical clustering)、DBSCAN(基于密度的聚类方法)和均值漂移(mean-shift)。
- 应用: 聚类问题的典型应用包括客户细分(根据购买行为将客户分组)、图像分割(将图像像素分为不同区域)、文档分类(根据内容将文档分组)等。
特征提取 + 分类器(重点)
特征提取
如:花瓣长度 花瓣宽度 花瓣颜色 植株高度 花瓣面积 …
1、对同样的事物,我们可以提取出各种各样的特征
2、不同的特征对于分类器的准确分类会有很大的影响
表示方式:向量 (x1,x2,x3…)(长度,宽度,面积…)
- 提取特征是关键!
为什么要进行特征提取?(重点)
简化数据:原始数据往往包含大量的冗余信息和噪音。通过特征提取,可以简化数据,只保留对模型有用的信息,提高计算效率。
提高模型性能:提取出具有代表性的特征,可以帮助模型更准确地识别数据中的模式,从而提高模型的预测性能。
降维:对于高维数据,特征提取可以减少维度,降低计算复杂度,并减轻“维度灾难”问题。
增强解释性:提取出具有物理意义或业务意义的特征,有助于理解模型的决策过程,增强结果的可解释性。
减少过拟合:通过提取关键特征并去除噪音数据,可以减少模型的复杂度,降低过拟合的风险。
提高训练效率:更小且更有代表性的特征集可以显著减少模型训练时间和资源消耗。
分类器
可线性,也可非线性,线性划分平面,也可以是超平面
可以用大量数据来训练分类器
训练集、测试集大小(重点)
数据充足可 1:1
数据不充足可 6:4, 7:3
K则交叉验证(重点)
K最小值为2,最大值为样本总数
K 小了:计算成本低,性能不稳定,影响模型的泛化能力
K 大了:计算成本高,性能稳定,但可能带来过于乐观的估计,每次验证集的大小较小,模型可能无法充分地从验证集中学习到数据的特性,导致评估的偏差较大
k 个 accuracy 如何处理?
- 通常通过计算 平均准确率 和 标准差 来评估模型的 总体表现 和 稳定性
过拟合、欠拟合
过拟合:训练集过好,而测试集糟糕
欠拟合:训练集就不行了,根本没好好训练!
how(了解就行):增加样本量、k则交叉验证、数据预处理、正则化、特征选择 …
分类准确率
分类准确率= 分类正确的样本数 / 测试样本的总数
softmax
softmax 是 归一化指数函数
用于多分类,可以归一化,将输出值转为概率
卷积神经网络
向量卷积计算
每次滑一步,分别进行向量点乘,最终结果还是一个向量
矩阵、张量卷积计算
和向量同理,反正我会算!
池化层
池化层通过减少特征图的空间维度,减少了后续卷积层的计算量和参数量,从而提高了网络的计算效率和训练速度,可防止过拟合
循环神经网络
RNN
时间序列,不适合处理长序列(会遗忘)
GRU
两个门,更新门和重置门,设定上一个时刻和当前时刻的权重比
LSTM
三个门,比GRU复杂,分量之前每关系,相对独立,可自由设置
遗忘门能决定需要保留先前步长中哪些相关信息
输入门决定在当前输入中哪些重要信息需要被添加
输出门决定了下一个隐藏状态。
光流骨架
光流(重点)
光流是指在一系列连续的图像帧之间,物体像素位置的运动变化
基于光流的方法主要关注的是像素级别的运动信息,通常用于计算图像中的运动矢量场
骨架
基于骨架的方法主要关注的是对象(通常是人类)的关节和身体部分的位置信息
通过检测和追踪人体的关键点(如头、肩、肘、膝等),可以重建出人体的骨架结构
- 目标检测 先检测到人
- 骨架提取 拿到这个人的骨架
- 特征提取 对骨架进行特征提取并分析
- 动作识别 根据特征来识别判断出是什么动作
光流骨架区别
- 运动信息的表示方式:
- 光流方法基于像素级别的运动矢量,表示的是连续帧之间的运动变化。
- 骨架方法基于关键点和关节位置,表示的是人体的姿态和骨架结构。
- 应用场景:
- 光流方法适用于需要细粒度运动分析的场景,如目标跟踪、视频稳定等。
- 骨架方法适用于人体动作识别、姿态估计和运动分析等。
- 计算复杂度和鲁棒性:
- 光流方法计算复杂度较高,容易受到光照变化和噪声的影响。
- 骨架方法计算相对简单,更鲁棒于光照和背景变化。
关联规则挖掘
两个兴趣度度量
支持度 整体概率,比如某个项集在事务集中出现的概率
置信度 条件概率,比如含A的事务集中,出现AC的概率
- 提升度 在B单独发生中,是 A 引起的,即 A → \rightarrow → B 的概率
衍生概念
频繁k项集 大于人为设定的最小支持度
候选k项集 用于生成频繁k项集的项集
AP算法
不断往上推,然后看置信度和提升度满不满足要求
聚类算法
k-means聚类(重点)
分成k个簇,先选取k个样本点,每加入一个点时先分类,再重新计算簇中心点,循环直到所有点分完为止
k近邻(KNN)是选周围k个样本点,然后来进行归类,是监督算法,要进行区分!
层次聚类(重点)
根据距离最小的两个点来聚类,不断往上叠层,每次都使样本簇数-1,最终像一个树结构,有层次感
优点:
1、得到层次化表达,信息丰富
2、有利于把数据集的聚类结构视觉化
缺点:
1、对噪声和离群点很敏感,需要有力的预处理过程
2、计算量很大
密度聚类-DBSCAN(重点)
- 具有噪声的基于密度的空间聚类
- 把分布相对密集、距离较近的点聚到一起
- 不是所有的点都是类的一部分
- DBSCAN定义了噪声点,在具有噪声的情况下具有较大的作用
优点:
1、不需要指明类的数量
2、能灵活地找到并分离各种形状和大小的类
3、能有效处理数据集中的噪声和离群点
缺点:
1、从两类可达的边界点,被分配给了另一个类(因为这个类先发现这个点),不能保证回传正确的分类情况
2、较难找到不同密度的类
层次聚类和密度聚类区别(重点)
| 层次聚类 | 密度聚类 |
|---|---|
| 数据完整 | 数据不完整 |
| 更有层次化,利于可视化 | 更有集中性,适用于有噪声情况 |
| 对噪声和离群点很敏感,受极端情况影响大 | 可舍弃极端情况,只集中对密度大的部分进行聚类 |
相关文章:

人工智能笔记分享
文章目录 人工智能图灵测试分类分类与聚类的区别(重点)分类 (Classification)聚类 (Clustering) 特征提取 分类器(重点)特征提取为什么要进行特征提取?(重点)分类器 训练集、测试集大小&#x…...

秋招提前批面试经验分享(上)
⭐️感谢点开文章👋,欢迎来到我的微信公众号!我是恒心😊 一位热爱技术分享的博主。如果觉得本文能帮到您,劳烦点个赞、在看支持一下哈👍! ⭐️我叫恒心,一名喜欢书写博客的研究生在读…...

[AIGC] ClickHouse的表引擎介绍
ClickHouse是一种高性能的列式数据库管理系统,支持各种不同的表引擎。表引擎是数据库系统中的核心组件,它定义了数据的存储方式和访问方式。本文将介绍ClickHouse中常见的表引擎及其特点。 文章目录 一、MergeTree引擎二、ReplacingMergeTree引擎三、Sum…...

关于新装Centos7无法使用yum下载的解决办法
起因 之前也写了一篇类似的文章,但感觉有漏洞,这次想直接把漏洞补齐。 问题描述 在我们新装的Centos7中,如果想要用C编程,那就必须要用到yum下载,但是,很多新手,包括我使用yum下载就会遇到一…...

OpenEarthMap:全球高分辨率土地覆盖制图的基准数据集(开源来下载!!!)
OpenEarthMap由220万段5000张航拍和卫星图像组成,覆盖6大洲44个国家97个地区,在0.25-0.5m的地面采样距离上人工标注8类土地覆盖标签。我们提供8类标注:裸地、牧场、已开发空间、道路、树木、水、农业用地和建筑。类选择与现有的具有亚米GSD的产品和基准数…...

工作助手VB开发笔记(1)
1.思路 1.1 样式 样式为常驻前台的一个小窗口,小窗口上有三到四个按钮,为一级功能,是当前工作内容的常用功能窗口,有十个二级窗口,为选中窗口时的扩展选项,有若干后台功能,可选中至前台 可最…...

WAWA鱼曲折的大学四年回忆录
声明:本文内容纯属个人主观臆断,如与事实不符,请参考事实 前言: 早想写一下大学四年的总结了,但总是感觉无从下手,不知道从哪里开始写,通过这篇文章主要想做一个记录,并从现在的认…...

Go 依赖注入设计模式
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

使用React复刻ThreeJS官网示例——keyframes动画
最近在看three.js相关的东西,想着学习一下threejs给的examples。源码是用html结合js写的,恰好最近也在学习react,就用react框架学习一下。 本文参考的是threeJs给的第一个示例 three.js examples (threejs.org) 一、下载threeJS源码 通常我们…...
嵌入式linux面试1
1. linux 1.1. Window系统和Linux系统的区别 linux区分大小写windows在dos(磁盘操作系统)界面命令下不区分大小写; 1.2. 文件格式区分 windows用扩展名区分文件;如.exe代表执行文件,.txt代表文本文件,.…...

智能交通(3)——Learning Phase Competition for Traffic Signal Control
论文分享 https://dl.acm.org/doi/pdf/10.1145/3357384.3357900https://dl.acm.org/doi/pdf/10.1145/3357384.3357900 论文代码 https://github.com/gjzheng93/frap-pubhttps://github.com/gjzheng93/frap-pub 摘要 越来越多可用的城市数据和先进的学习技术使人们能够提…...

【扩散模型】LCM LoRA:一个通用的Stable Diffusion加速模块
潜在一致性模型:[2310.04378] Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (arxiv.org) 原文:Paper page - Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (…...

【PYG】pytorch中size和shape有什么不同
一般使用tensor.shape打印维度信息,因为简单直接 在 PyTorch 中,size 和 shape 都用于获取张量的维度信息,但它们之间有细微的区别。下面是它们的定义和用法: size: size 是一个方法(size())和…...

备份服务器出错怎么办?
在企业的日常运营中,备份服务器扮演着至关重要的角色,它确保了数据的安全和业务的连续性。然而,备份服务器也可能遇到各种问题,如备份失败、数据损坏或备份系统故障等。这些问题可能导致数据丢失或业务中断,给企业带来…...

数据库(表)
要求如下: 一:数据库 1,登录数据库 mysql -uroot -p123123 2,创建数据库zoo create database zoo; Query OK, 1 row affected (0.01 sec) 3,修改字符集 mysql> use zoo;---先进入数据库zoo Database changed …...

Feign-未完成
Feign Java中如何实现接口调用?即如何发起http请求 前三种方式比较麻烦,在发起请求前,需要将Java对象进行序列化转为json格式的数据,才能发送,然后进行响应时,还需要把json数据进行反序列化成java对象。 …...

# [0705] Task06 DDPG 算法、PPO 算法、SAC 算法【理论 only】
easy-rl PDF版本 笔记整理 P5、P10 - P12 joyrl 比对 补充 P11 - P13 OpenAI 文档整理 ⭐ https://spinningup.openai.com/en/latest/index.html 最新版PDF下载 地址:https://github.com/datawhalechina/easy-rl/releases 国内地址(推荐国内读者使用): 链…...

Open3D 点云CPD算法配准(粗配准)
目录 一、概述 二、代码实现 2.1关键函数 2.2完整代码 三、实现效果 3.1原始点云 3.2配准后点云 一、概述 在Open3D中,CPD(Coherent Point Drift,一致性点漂移)算法是一种经典的点云配准方法,适用于无序点云的非…...
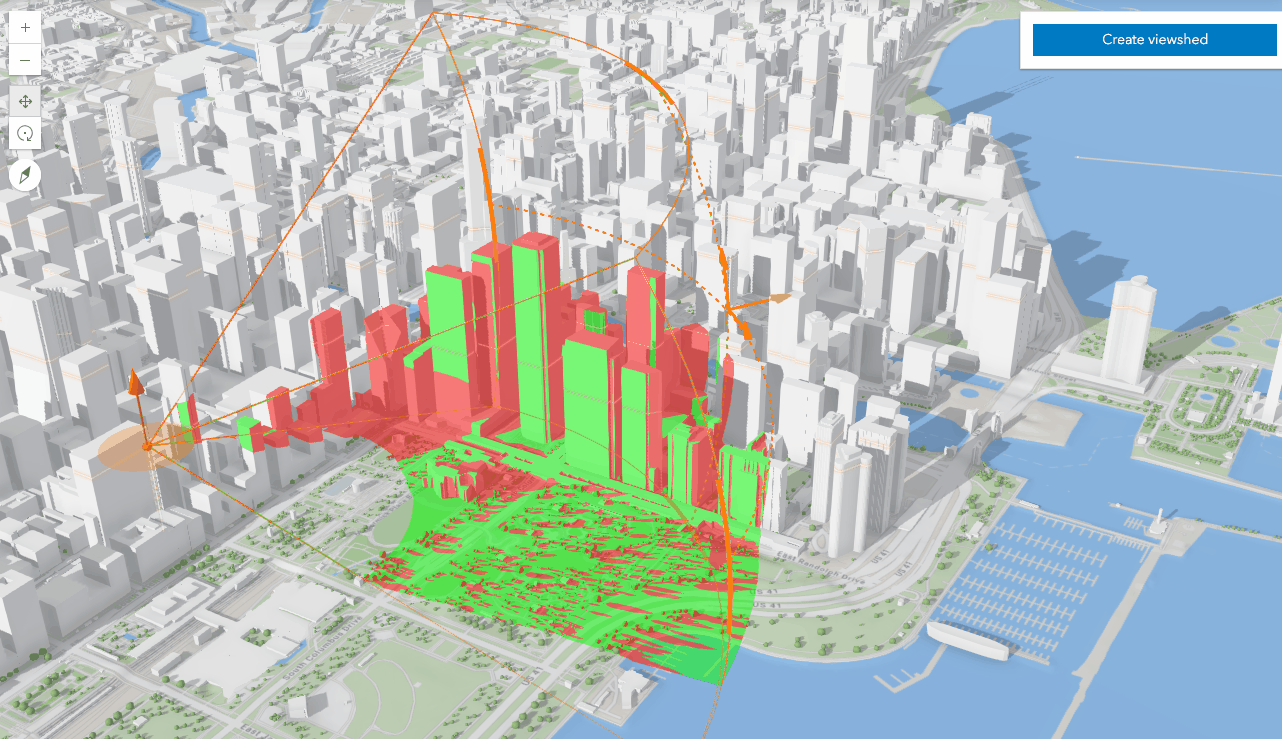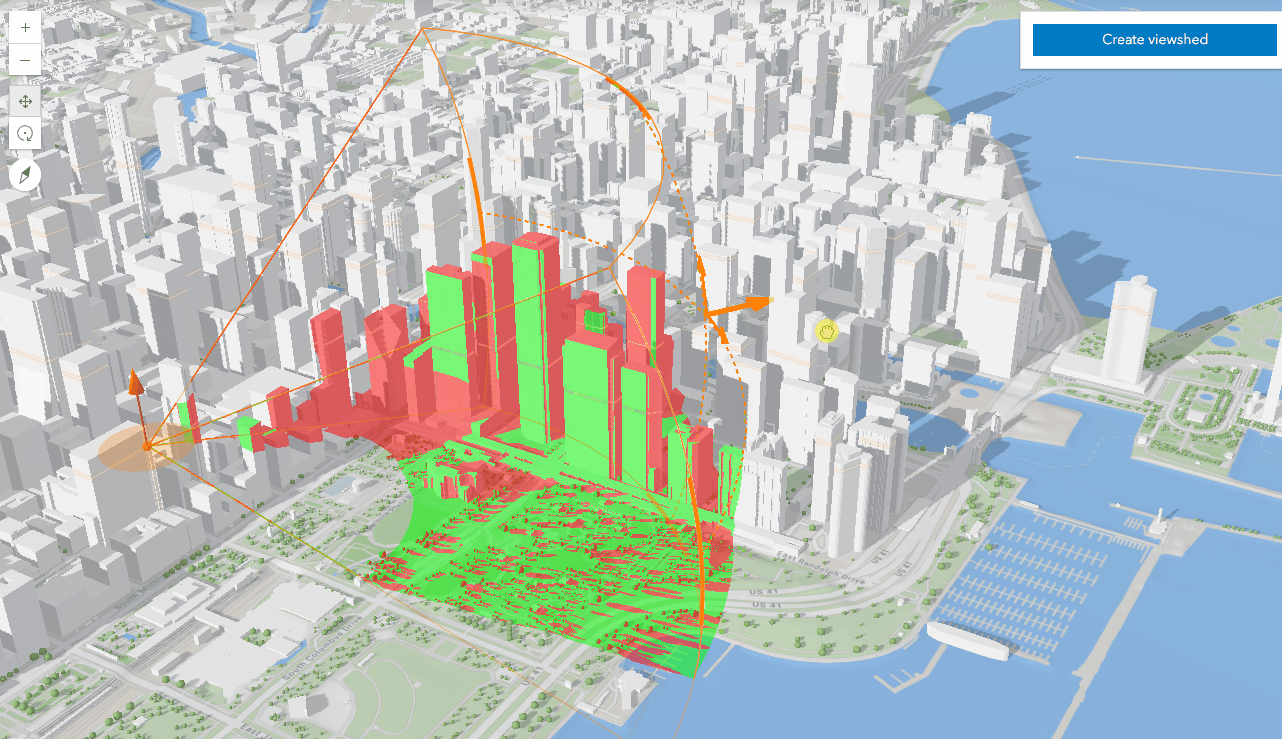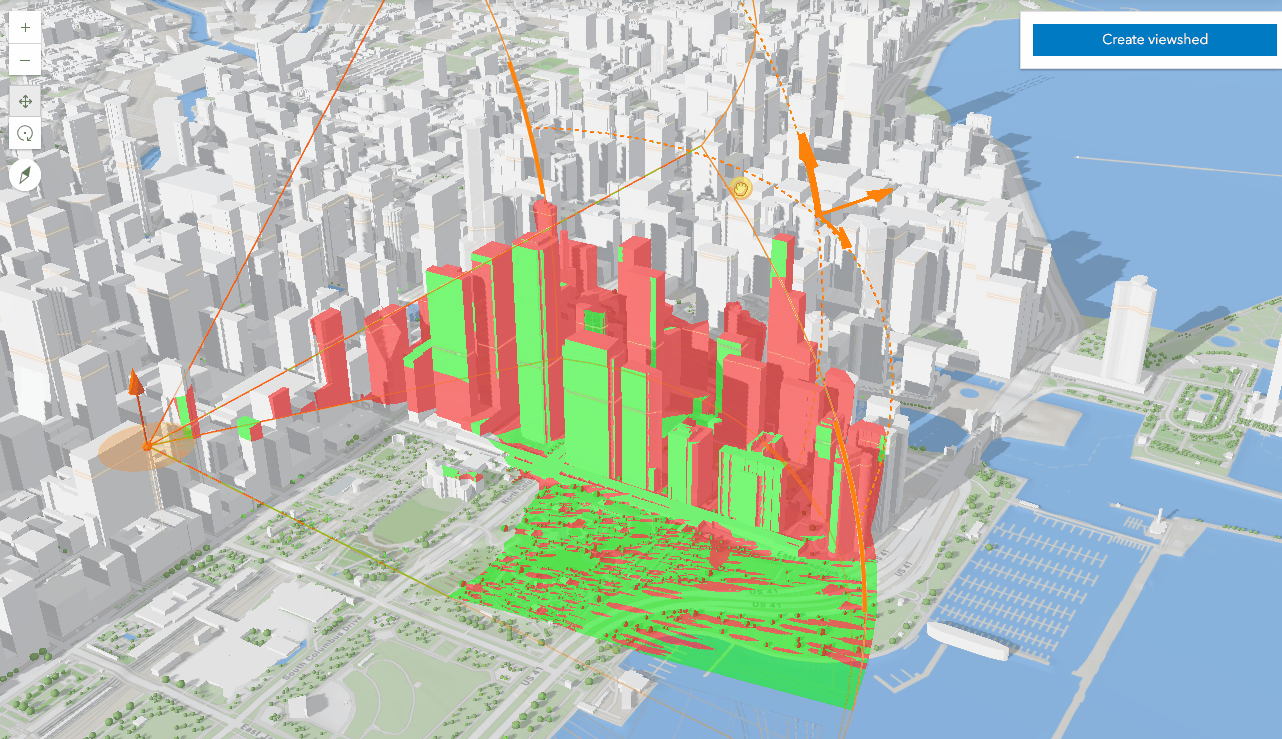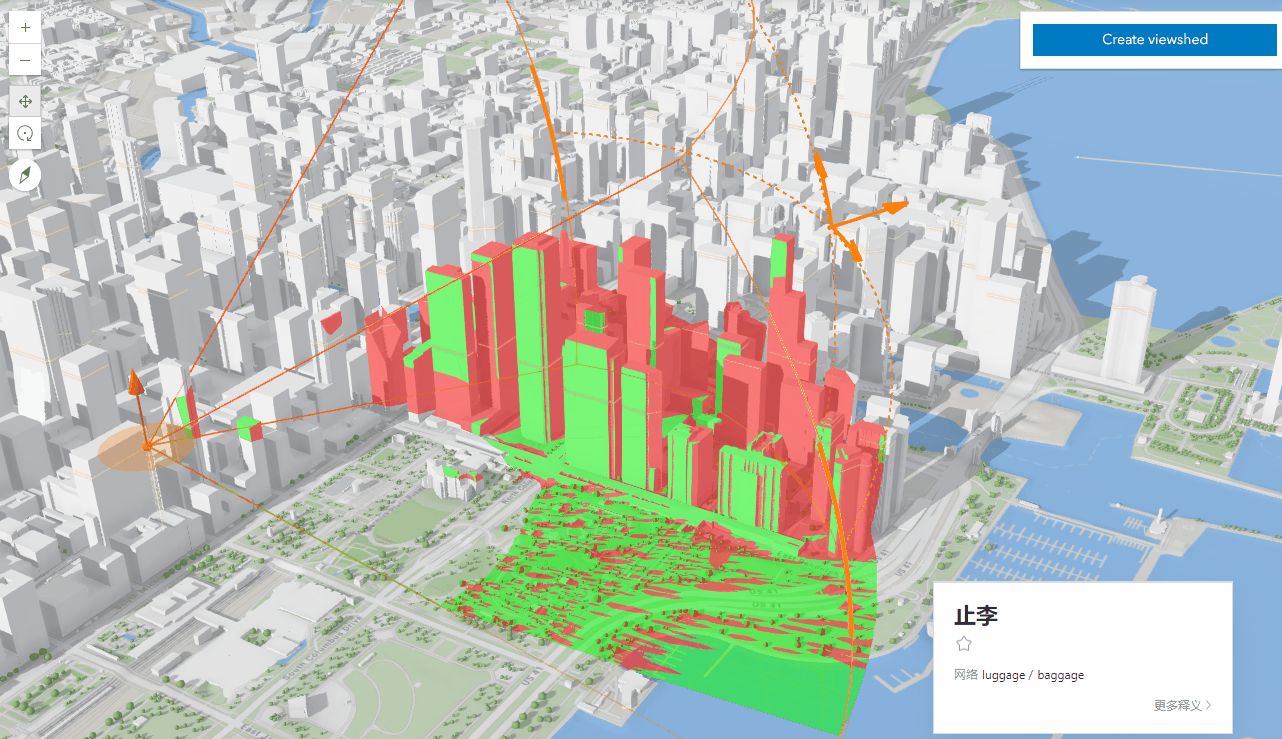
04-ArcGIS For JavaScript的可视域分析功能
文章目录 综述代码实现代码解析结果 综述 在数字孪生或者实景三维的项目中,视频融合和可视域分析,一直都是热点问题。Cesium中,支持对阴影的后处理操作,通过重新编写GLSL代码就能实现视域和视频融合的功能。ArcGIS之前支持的可视…...

Nestjs基础
一、创建项目 1、创建 安装 Nest CLI(只需要安装一次) npm i -g nestjs/cli 进入要创建项目的目录,使用 Nest CLI 创建项目 nest new 项目名 运行项目 npm run start 开发环境下运行,自动刷新服务 npm run start:dev 2、…...

7大实战技巧精通DLT Viewer:汽车电子日志分析权威指南
7大实战技巧精通DLT Viewer:汽车电子日志分析权威指南 【免费下载链接】dlt-viewer Diagnostic Log and Trace viewing program 项目地址: https://gitcode.com/gh_mirrors/dl/dlt-viewer 一、认知:揭开DLT Viewer的神秘面纱 在现代汽车电子系统…...

3个实用方案解决百度网盘限速问题:高效下载工具使用指南
3个实用方案解决百度网盘限速问题:高效下载工具使用指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 百度网盘作为国内主流云存储服务,其资源分享功…...

Krita AI Diffusion终极指南:从零开始掌握AI绘画插件
Krita AI Diffusion终极指南:从零开始掌握AI绘画插件 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitcode.…...

Kook Zimage真实幻想Turbo参数详解:Steps和CFG Scale怎么设效果最好?
Kook Zimage真实幻想Turbo参数详解:Steps和CFG Scale怎么设效果最好? 1. 理解核心参数的意义 在AI绘画中,Steps(步数)和CFG Scale(提示词引导系数)是影响生成效果最直接的两个参数。它们就像烹…...

突破网盘下载限制:八大平台直链获取的高效方案
突破网盘下载限制:八大平台直链获取的高效方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...

从零到一:在阿里云上快速搭建高性能我的世界服务器
1. 阿里云服务器选购与配置 第一次在云服务上搭建游戏服务器可能会觉得复杂,但其实只要跟着步骤走,30分钟就能搞定。我去年帮朋友的游戏社群搭建过5个不同版本的MC服务器,踩过不少坑,也总结出一套最高效的方案。阿里云对新用户特别…...

Helm与Vault整合的实践之旅
在容器化和微服务架构的今天,管理配置文件和敏感信息变得愈发重要。使用Helm进行应用部署时,结合Vault来管理和注入机密信息是一个很好的实践。本文将通过一个实际的例子,详细说明如何在Helm Chart中使用Vault来配置和注入机密信息。 背景 Helm是一个包管理工具,可以帮助…...

OpenClaw+SecGPT-14B:构建无需编程的内网资产管理系统
OpenClawSecGPT-14B:构建无需编程的内网资产管理系统 1. 为什么需要无代码内网资产管理 去年接手公司IT运维时,我发现内网设备清单还是三年前的Excel表格。每当新设备接入或旧设备淘汰,手动更新文档总会被遗忘。更麻烦的是,不同…...
)
手把手教你用HFP协议开发智能手表通话功能(附AT指令集)
智能手表通话功能开发实战:HFP协议深度解析与AT指令应用 清晨六点,你的智能手表在手腕上微微震动——不是闹钟,而是一通来自海外客户的紧急电话。你轻触屏幕接听,通过手表内置麦克风清晰沟通,全程无需寻找手机。这种无…...

Qwen3.5-9B-AWQ-4bit部署教程:双卡RTX 4090 D显存优化与AWQ量化优势解析
Qwen3.5-9B-AWQ-4bit部署教程:双卡RTX 4090 D显存优化与AWQ量化优势解析 1. 模型概述 Qwen3.5-9B-AWQ-4bit是一个支持图像理解的多模态模型,能够结合上传图片与文字提示词,输出中文分析结果。这个模型特别适合处理以下任务: 图…...