215.Mit6.S081-实验三-page tables
在本实验室中,您将探索页表并对其进行修改,以简化将数据从用户空间复制到内核空间的函数。
一、实验准备
开始编码之前,请阅读xv6手册的第3章和相关文件:
- kernel/memlayout.h,它捕获了内存的布局。
- kernel/vm.c,其中包含大多数虚拟内存(VM)代码。
- kernel/kalloc.c,它包含分配和释放物理内存的代码。
可看这一篇博客来增加理解。
211.xv6——3(page tables)-CSDN博客
要启动实验,请切换到pgtbl分支:
$ git fetch
$ git checkout pgtbl
$ make clean
二、Print a page table (easy)
1.实验要求
为了帮助您了解RISC-V页表,也许为了帮助将来的调试,您的第一个任务是编写一个打印页表内容的函数。
- 定义一个名为
vmprint()的函数。- 它应当接收一个
pagetable_t作为参数,并以下面描述的格式打印该页表。- 在
exec.c中的return argc之前插入if(p->pid==1) vmprint(p->pagetable),以打印第一个进程的页表。- 如果你通过了
pte printout测试的make grade,你将获得此作业的满分。现在,当您启动xv6时,它应该像这样打印输出来描述第一个进程刚刚完成
exec()inginit时的页表:page table 0x0000000087f6e000 ..0: pte 0x0000000021fda801 pa 0x0000000087f6a000 .. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000 .. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000 .. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000 .. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000 ..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000 .. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000 .. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000 .. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000
- 第一行显示
vmprint的参数。之后的每行对应一个PTE,包含树中指向页表页的PTE。- 每个PTE行都有一些“
..”的缩进表明它在树中的深度。- 每个PTE行显示其在页表页中的PTE索引、PTE比特位以及从PTE提取的物理地址。
- 不要打印无效的PTE。在上面的示例中,顶级页表页具有条目0和255的映射。
- 条目0的下一级只映射了索引0,该索引0的下一级映射了条目0、1和2。
您的代码可能会发出与上面显示的不同的物理地址。条目数和虚拟地址应相同。
2.提示
- 你可以将
vmprint()放在kernel/vm.c中- 使用定义在kernel/riscv.h末尾处的宏
- 函数
freewalk可能会对你有所启发- 将
vmprint的原型定义在kernel/defs.h中,这样你就可以在exec.c中调用它了- 在你的
printf调用中使用%p来打印像上面示例中的完成的64比特的十六进制PTE和地址3.实现
(1)首先在kernel/vm.c中添加vmprint()函数
// 递归打印页表的函数。 // pagetable是页表,level表示当前递归的深度。 void _vmprint(pagetable_t pagetable, int level) {// 遍历页表中的每一个PTE(页表项)。for (int i = 0; i < 512; i++){pte_t pte = pagetable[i]; // 获取当前的页表项。if(pte & PTE_V) // 如果页表项有效(存在)。{// 打印缩进,根据当前递归的深度level来决定。for (int j = 0; j < level; j++){if(j)printf(" ");printf("..");}uint64 child = PTE2PA(pte); // 获取页表项指向的物理地址。printf("%d: pte %p pa %p\n", i, pte, child); // 打印页表项信息。// 如果不是叶子节点(没有R/W/X权限),继续递归打印下一级页表。if((pte & (PTE_W | PTE_R | PTE_X)) == 0){_vmprint((pagetable_t)child, level + 1);}}} }// 打印页表的入口函数。 // pagetable是页表的根。 void vmprint(pagetable_t pagetable) {printf("page table %p\n", pagetable); // 打印页表的根地址。_vmprint(pagetable, 1); // 从根页表开始递归打印,初始深度为1。 }(2)在kernel/defs.h中添加定义
(3)在kernel/exec.c中添加
4.测试结果



三、A kernel page table per process (hard)
Xv6有一个单独的用于在内核中执行程序时的内核页表。内核页表直接映射(恒等映射)到物理地址,也就是说内核虚拟地址
x映射到物理地址仍然是x。Xv6还为每个进程的用户地址空间提供了一个单独的页表,只包含该进程用户内存的映射,从虚拟地址0开始。因为内核页表不包含这些映射,所以用户地址在内核中无效。因此,当内核需要使用在系统调用中传递的用户指针(例如,传递给write()的缓冲区指针)时,内核必须首先将指针转换为物理地址。本节和下一节的目标是允许内核直接解引用用户指针。1.实验要求
你的第一项工作是修改内核来让每一个进程在内核中执行时使用它自己的内核页表的副本。修改
struct proc来为每一个进程维护一个内核页表,修改调度程序使得切换进程时也切换内核页表。对于这个步骤,每个进程的内核页表都应当与现有的的全局内核页表完全一致。如果你的usertests程序正确运行了,那么你就通过了这个实验。阅读本作业开头提到的章节和代码;了解虚拟内存代码的工作原理后,正确修改虚拟内存代码将更容易。页表设置中的错误可能会由于缺少映射而导致陷阱,可能会导致加载和存储影响到意料之外的物理页存页面,并且可能会导致执行来自错误内存页的指令。
2.提示
- 在
struct proc中为进程的内核页表增加一个字段- 为一个新进程生成一个内核页表的合理方案是实现一个修改版的
kvminit,这个版本中应当创造一个新的页表而不是修改kernel_pagetable。你将会考虑在allocproc中调用这个函数。- 确保每一个进程的内核页表都关于该进程的内核栈有一个映射。在未修改的XV6中,所有的内核栈都在
procinit中设置。你将要把这个功能部分或全部的迁移到allocproc中- 修改
scheduler()来加载进程的内核页表到核心的satp寄存器(参阅kvminithart来获取启发)。不要忘记在调用完w_satp()后调用sfence_vma()- 没有进程运行时
scheduler()应当使用kernel_pagetable- 在
freeproc中释放一个进程的内核页表- 你需要一种方法来释放页表,而不必释放叶子物理内存页面。
- 调式页表时,也许
vmprint能派上用场- 修改XV6本来的函数或新增函数都是允许的;你或许至少需要在kernel/vm.c和kernel/proc.c中这样做(但不要修改kernel/vmcopyin.c, kernel/stats.c, user/usertests.c, 和user/stats.c)
- 页表映射丢失很可能导致内核遭遇页面错误。这将导致打印一段包含
sepc=0x00000000XXXXXXXX的错误提示。你可以在kernel/kernel.asm通过查询XXXXXXXX来定位错误。3.具体实现
本实验主要是让每个进程都有自己的内核页表,这样在内核中执行时使用它自己的内核页表的副本。
(1)首先在kernel/proc.h里面的struct proc增加内核页表的字段,表示内核态页表。
(2)在
vm.c中添加新的方法proc_kpt_init,该方法用于在allocproc中初始化进程的内核页表。这个函数还需要一个辅助函数uvmmap,该函数和kvmmap方法几乎一致,不同的是kvmmap是对Xv6的内核页表进行映射,而uvmmap将用于进程的内核页表进行映射。//用于映射虚拟地址到物理地址 void uvmmap(pagetable_t pagetable,uint64 va,uint64 pa,uint64 sz,int perm) {if(mappages(pagetable,va,sz,pa,perm)!=0){panic("uvmmap");} }//用于初始化内核页表 pagetable_t ukvminit() {pagetable_t kernelpt = uvmcreate();if(kernelpt==0)return 0;uvmmap(kernelpt, UART0, UART0, PGSIZE, PTE_R | PTE_W);uvmmap(kernelpt, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);uvmmap(kernelpt, CLINT, CLINT, 0x10000, PTE_R | PTE_W);uvmmap(kernelpt, PLIC, PLIC, 0x400000, PTE_R | PTE_W);uvmmap(kernelpt, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);uvmmap(kernelpt, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);uvmmap(kernelpt, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);return kernelpt; }(3)在
kernel/proc.c中的allocproc函数里添加调用函数的代码:
记得在
kernel/defs.h添加函数声明:pagetable_t ukvminit(void);(4)在内核栈的初始化原来是在
kernel/proc.c中的procinit函数内,这部分要求将函数内的代码转移到allocproc函数内,因此在上一步初始化内核态页表的代码下面接着添加初始化内核栈的代码:
kvminithart是用于原先的内核页表,我们将进程的内核页表传进去就可以。在vm.c里面添加一个新方法proc_inithart。
然后在
scheduler()内调用即可,但在结束的时候,需要切换回原先的kernel_pagetable。直接调用调用上面的kvminithart()就能把Xv6的内核页表加载回去。
(6) 在
freeproc中释放一个进程的内核页表。首先释放页表内的内核栈,调用uvmunmap可以解除映射,最后的一个参数(do_free)为一的时候,会释放实际内存。// free the kernel stack in the RAM uvmunmap(p->kernelpt, p->kstack, 1, 1); p->kstack = 0;然后释放进程的内核页表,先在kernel/proc.c里面添加一个方法
proc_freekernelpt。如下,历遍整个内核页表,然后将所有有效的页表项清空为零。如果这个页表项不在最后一层的页表上,需要继续进行递归。void proc_freekernelpt(pagetable_t kernelpt) {// similar to the freewalk method// there are 2^9 = 512 PTEs in a page table.for (int i = 0; i < 512;i++){pte_t pte = kernelpt[i];if(pte&PTE_V){kernelpt[i] = 0;if((pte&(PTE_R|PTE_W|PTE_X))==0){uint64 child = PTE2PA(pte);proc_freekernelpt((pagetable_t)child);}}}kfree((void *)kernelpt); }(6). 将需要的函数定义添加到
kernel/defs.h中
(7). 修改
vm.c中的kvmpa,将原先的kernel_pagetable改成myproc()->kernelpt,使用进程的内核页表。最后,在 vm.c 中添加头文件:
#include "spinlock.h" #include "proc.h"最后修改kvmpa函数
uint64 kvmpa(uint64 va) {uint64 off = va % PGSIZE;pte_t *pte;uint64 pa;pte = walk(myproc()->kernelpt, va, 0); // 修改这里if(pte == 0)panic("kvmpa");if((*pte & PTE_V) == 0)panic("kvmpa");pa = PTE2PA(*pte);return pa+off; }4.测试结果






四、Simplify copyin/copyinstr
内核的
copyin函数读取用户指针指向的内存。它通过将用户指针转换为内核可以直接解引用的物理地址来实现这一点。这个转换是通过在软件中遍历进程页表来执行的。在本部分的实验中,您的工作是将用户空间的映射添加到每个进程的内核页表(上一节中创建),以允许copyin(和相关的字符串函数copyinstr)直接解引用用户指针。1.实验要求
- 将定义在kernel/vm.c中的
copyin的主题内容替换为对copyin_new的调用(在kernel/vmcopyin.c中定义);- 对
copyinstr和copyinstr_new执行相同的操作。- 为每个进程的内核页表添加用户地址映射,以便
copyin_new和copyinstr_new工作。- 如果
usertests正确运行并且所有make grade测试都通过,那么你就完成了此项作业。此方案依赖于用户的虚拟地址范围不与内核用于自身指令和数据的虚拟地址范围重叠。Xv6使用从零开始的虚拟地址作为用户地址空间,幸运的是内核的内存从更高的地址开始。然而,这个方案将用户进程的最大大小限制为小于内核的最低虚拟地址。内核启动后,在XV6中该地址是
0xC000000,即PLIC寄存器的地址;请参见kernel/vm.c中的kvminit()、kernel/memlayout.h和文中的图3-4。您需要修改xv6,以防止用户进程增长到超过PLIC的地址。2.提示
- 先用对
copyin_new的调用替换copyin(),确保正常工作后再去修改copyinstr- 在内核更改进程的用户映射的每一处,都以相同的方式更改进程的内核页表。包括
fork(),exec(), 和sbrk().- 不要忘记在
userinit的内核页表中包含第一个进程的用户页表- 用户地址的PTE在进程的内核页表中需要什么权限?(在内核模式下,无法访问设置了
PTE_U的页面)- 别忘了上面提到的PLIC限制
Linux使用的技术与您已经实现的技术类似。直到几年前,许多内核在用户和内核空间中都为当前进程使用相同的自身进程页表,并为用户和内核地址进行映射以避免在用户和内核空间之间切换时必须切换页表。然而,这种设置允许边信道攻击,如Meltdown和Spectre。
3.实现
本实验是实现将用户空间的映射添加到每个进程的内核页表,将进程的页表复制一份到进程的内核页表就好。
首先添加复制函数。需要注意的是,在内核模式下,无法访问设置了
PTE_U的页面,所以我们要将其移除。(1)复制页表内容
void u2kvmcopy(pagetable_t pagetable, pagetable_t kernelpt, uint64 oldsz, uint64 newsz) {pte_t *pte_from, *pte_to;// 将 oldsz 向上取整到最近的页边界oldsz = PGROUNDUP(oldsz);// 遍历 [oldsz, newsz) 范围内的每一页for (uint64 i = oldsz; i < newsz; i += PGSIZE) {// 从用户页表中获取地址 i 对应的 PTEif ((pte_from = walk(pagetable, i, 0)) == 0)panic("u2kvmcopy: src pte does not exist");// 确保用户页表中的页表项是有效的(即包含 PTE_V 标志)if (!(*pte_from & PTE_V))panic("u2kvmcopy: src pte not valid");// 获取或创建内核页表中地址 i 对应的 PTEif ((pte_to = walk(kernelpt, i, 1)) == 0)panic("u2kvmcopy: pte walk failed");// 从用户页表项中获取物理地址uint64 pa = PTE2PA(*pte_from);// 从用户页表项中获取标志,并移除用户权限标志 PTE_Uuint flags = (PTE_FLAGS(*pte_from)) & (~PTE_U);// 设置内核页表项*pte_to = PA2PTE(pa) | flags;} }第二步,fork(),sbrk(),exec()
然后在内核更改进程的用户映射的每一处 (
fork(),exec(), 和sbrk()),都复制一份到进程的内核页表。fork()
exec()
sbrk(), 在kernel/sysproc.c里面找到
sys_sbrk(void),可以知道只有growproc是负责将用户内存增加或缩小 n 个字节。以防止用户进程增长到超过PLIC的地址,我们需要给它加个限制。
然后替换掉原有的
copyin()和copyinstr()// Copy from user to kernel. // Copy len bytes to dst from virtual address srcva in a given page table. // Return 0 on success, -1 on error. int copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) {return copyin_new(pagetable, dst, srcva, len); }// Copy a null-terminated string from user to kernel. // Copy bytes to dst from virtual address srcva in a given page table, // until a '\0', or max. // Return 0 on success, -1 on error. int copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max) {return copyinstr_new(pagetable, dst, srcva, max); }并且添加到
kernel/defs.h中// vmcopyin.c int copyin_new(pagetable_t, char *, uint64, uint64); int copyinstr_new(pagetable_t, char *, uint64, uint64);


相关文章:

215.Mit6.S081-实验三-page tables
在本实验室中,您将探索页表并对其进行修改,以简化将数据从用户空间复制到内核空间的函数。 一、实验准备 开始编码之前,请阅读xv6手册的第3章和相关文件: kernel/memlayout.h,它捕获了内存的布局。kernel/vm.c&…...

flask使用定时任务flask_apscheduler(APScheduler)
Flask-APScheduler描述: Flask-APScheduler 是一个 Flask 扩展,增加了对 APScheduler 的支持。 APScheduler 有三个内置的调度系统可供您使用: Cron 式调度(可选开始/结束时间) 基于间隔的执行(以偶数间隔运行作业…...

ApiFox或postman怎么用params类型传输json或集合+json的String类型
你是否碰见过这样的接口? post请求然后传输的参数都要和查询时一样以param形式传参数,那String什么的都好说,传就直接进后台了,那json呢,集合呢,是不是直接给你返400呢. 1.传json如何处理 那我们看看怎么实现,如果你要传json数据,那需要将特殊字符转义,也叫url转码,否则传不…...

数据结构第16节 最大堆
最大堆是一种特殊的完全二叉树数据结构,其中每个父节点的键值都大于或等于其子节点的键值。在Java中,最大堆通常用于实现优先队列,堆排序算法,或者在需要快速访问最大元素的应用场景中。 让我们通过一个具体的案例来说明最大堆的…...

显卡、显卡驱动、cuda、cuDNN之间关系
显卡、显卡驱动、CUDA 和 cuDNN 是构成高性能计算和深度学习环境的关键组件,它们之间有着紧密的联系。下面是对这些组件及其关系的详细介绍: 显卡(GPU) 显卡,全称为图形处理器(Graphics Processing Unit&…...

Rewrk一个更现代的http框架基准测试实用程序
Rewrk一个更现代的http框架基准测试实用程序。HTTP基准测试(HTTP benchmarking)是一种测量和评估HTTP服务器或应用程序性能指标的活动。其目的是在特定条件下模拟大量用户请求,以测量服务器或应用程序的响应能力、吞吐量、延迟等指标…...

【算法】排序算法介绍 附带C#和Python实现代码
1. 冒泡排序(Bubble Sort) 2. 选择排序(Selection Sort) 3. 插入排序(Insertion Sort) 4. 归并排序(Merge Sort) 5. 快速排序(Quick Sort) 排序算法是计算机科学中的一个基础而重要的部分,用于将一组数据按照一定的顺序排列。下面介绍几种常见的排序算法,…...

360安全浏览器就是不行-python秒破解
下面画框都很容易破解,大家试试...

Python实现傅里叶级数可视化工具
Python实现傅里叶级数可视化工具 flyfish 有matlab实现,我没matlab,我有Python,所以我用Python实现。 整个工具的实现代码放在最后,界面使用PyQt5开发 起源 傅里叶级数(Fourier Series)由法国数学家和物理学家让-巴…...

PDF 分割拆分 API 数据接口
PDF 分割拆分 API 数据接口 文件处理,PDF 高效的 PDF 分割工具,高效处理,可永久存储。 1. 产品功能 高效处理大文件;支持多语言字符识别;支持 formdata 格式 PDF 文件流传参;支持设置每个 PDF 文件的页数…...

【python】随机森林预测汽车销售
目录 引言 1. 数据收集与预处理 2. 划分数据集 3. 构建随机森林模型 4. 模型训练 5. 模型评估 6. 模型调优 数据集 代码及结果 独热编码 随机森林模型训练 特征重要性图 混淆矩阵 ROC曲线 引言 随机森林(Random Forest)是一种集成学习方法…...

Stable Diffusion教程|练丹师是如何炼丹的Lora模型训练
前言 还记得我们之前就讲过学习SD成为炼丹师不?那么今天就来手把手教大家炼丹,看看同一个角色或某种风格的小模型是如何制作出来的。 目录 1 炼丹介绍 2 环境准备 3 Lora模型训练 **一、**炼丹介绍 什么是炼丹? 早在学习SD地第一篇就…...

QT--SQLite
配置类相关的表,所以我使用sqlite,且QT自带该组件; 1.安装 sqlite-tools-win-x64-3460000、SQLiteExpert5.4.31.575 使用SQLiteExpert建好数据库.db文件,和对应的表后把db文件放在指定目录 ./db/program.db; 2.选择sql组件 3.新…...

【深度学习入门篇 ②】Pytorch完成线性回归!
🍊嗨,大家好,我是小森( ﹡ˆoˆ﹡ )! 易编橙终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官、CSDN人工智能领域优质创作者 。 易编橙:一个帮助编程小…...

Syslog 管理工具
Syslog常被称为系统日志或系统记录,是一种用来在互联网协议(TCP/IP)的网上中传递记录档消息的标准,常用来指涉实际的Syslog 协议,或者那些提交syslog消息的应用程序或数据库。 系统日志协议(Syslog&#x…...

硅纪元AI应用推荐 | 百度橙篇成新宠,能写万字长文
“硅纪元AI应用推荐”栏目,为您精选最新、最实用的人工智能应用,无论您是AI发烧友还是新手,都能在这里找到提升生活和工作的利器。与我们一起探索AI的无限可能,开启智慧新时代! 百度橙篇,作为百度公司在202…...

Codeforces Round 954 (Div. 3)
🚀欢迎来到本文🚀 🍉个人简介:陈童学哦,彩笔ACMer一枚。 🏀所属专栏:Codeforces 本文用于记录回顾本彩笔的解题思路便于加深理解。 📢📢📢传送阵 A. X Axis解…...

【Django】报错‘staticfiles‘ is not a registered tag library
错误截图 错误原因总结 在django3.x版本中staticfiles被static替换了,所以这地方换位static即可完美运行 错误解决...
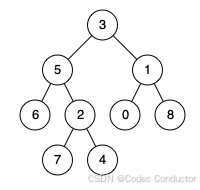
LeetCode 算法:二叉树的最近公共祖先 III c++
原题链接🔗:二叉树的最近公共祖先 难度:中等⭐️⭐️ 题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点…...

Windows CMD 命令汇总表
Windows CMD 命令汇总表 Windows CMD 命令汇总表目录操作磁盘操作文件操作其他命令FTP 命令高级系统命令批处理命令网络命令安全和权限命令 Windows CMD 命令指南目录操作MD - 创建子目录CD - 切换当前目录RD - 删除子目录DIR - 显示目录内容PATH - 设置可执行文件的搜索路径TR…...

探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界
探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界 【免费下载链接】nvme-cli NVMe management command line interface. 项目地址: https://gitcode.com/gh_mirrors/nv/nvme-cli NVMe-CLI作为现代NVMe固态存储设备的核心管理工具,在v2.…...

如何高效构建智能投资助手:韭菜盒子VSCode插件的7大核心功能深度解析
如何高效构建智能投资助手:韭菜盒子VSCode插件的7大核心功能深度解析 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-time stock,…...

MicMute:3秒掌握麦克风静音控制,告别会议尴尬时刻
MicMute:3秒掌握麦克风静音控制,告别会议尴尬时刻 【免费下载链接】MicMute Mute default mic clicking tray icon or shortcut 项目地址: https://gitcode.com/gh_mirrors/mi/MicMute 你是否曾在视频会议中因忘记静音而暴露尴尬的聊天背景声&…...

深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率
深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率 【免费下载链接】sacrebleu Reference BLEU implementation that auto-downloads test sets and reports a version string to facilitate cross-lab comparisons 项目地址: https://gitcode.com/gh_mirrors/s…...

ASML财报解析:EUV光刻机如何驱动半导体产业高增长
1. 财报数据深度拆解:高毛利与利润倍增的背后ASML刚刚发布的第二季度财报,无疑是全球半导体产业的一剂强心针。当看到毛利率稳稳站在50%以上,每股净利润几乎翻倍增长时,我第一反应不是惊讶,而是“果然如此”。这组数据…...

无王无帝定乾坤,来自田间第一人 凰标为律正人心
无王无帝定乾坤,来自田间第一人。 世间最大的乱象,从来不止山河动荡、世道纷争,更是人心失序、良知蒙尘。一、旧世千年:王权为纲,律法为束旧制之弊具体表现规则来源由权贵制定,标准随权势偏移治理逻辑重压制…...

Linux音频驱动开发实战:为TLV320ADC5120编写ALSA Codec驱动
1. 项目概述:从一块“哑巴”音频芯片到Linux系统的“耳朵”最近在折腾一块基于TI TLV320ADC5120的音频采集板,想把它接到我的RK3568开发板上用。芯片手册、硬件原理图都齐了,但一上电,系统里arecord -l根本找不到设备,…...

通达信缠论智能分析插件:5分钟实现专业K线结构可视化
通达信缠论智能分析插件:5分钟实现专业K线结构可视化 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 你是否曾在K线图中迷失方向,看着密密麻麻的蜡烛图却不知如何判断市场趋势&am…...

单片机代码优化实战:从数据类型到算法与数据结构的效率提升
1. 项目概述:为什么单片机代码需要“斤斤计较”?如果你是从PC端或者服务器端开发转过来的朋友,第一次接触单片机编程,可能会觉得处处掣肘。在PC上,我们习惯了动辄几个G的内存,上百G的硬盘,CPU频…...

从平面到立体:用ImageToSTL将照片变为可触摸的3D模型
从平面到立体:用ImageToSTL将照片变为可触摸的3D模型 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side. …...