Spark Streaming DStream的操作
一、DStream的定义
DStream是离散流,Spark Streaming提供的一种高级抽象,代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume,也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。
DStream的内部,其实是一系列持续不断产生的RDD,RDD是Spark Core的核心抽象,即不可变的,分布式的数据集。
对DStream应用的算子,其实在底层会被翻译为对DStream中每个RDD的操作,比如对一个DStream执行一个map操作,会产生一个新的DStream,其底层原理为,对输入DStream中的每个时间段的RDD,都应用一遍map操作,然后生成的RDD,即作为新的DStream中的那个时间段的一个RDD。
二、DStream的操作
1,普通的转换操作
| 转换 | 描述 |
|---|---|
| map(func) | 源 DStream的每个元素通过函数func返回一个新的DStream。 |
| flatMap(func) | 类似与map操作,不同的是每个输入元素可以被映射出0或者更多的输出元素。 |
| filter(func) | 在源DSTREAM上选择Func函数返回仅为true的元素,最终返回一个新的DSTREAM 。 |
| repartition(numPartitions) | 通过输入的参数numPartitions的值来改变DStream的分区大小。 |
| union(otherStream) | 返回一个包含源DStream与其他 DStream的元素合并后的新DSTREAM。 |
| count() | 对源DStream内部的所含有的RDD的元素数量进行计数,返回一个内部的RDD只包含一个元素的DStreaam。 |
| reduce(func) | 使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚 合操作,返回一个内部所包含的RDD只有一个元素的新DStream。 |
| countByValue() | 计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次。 |
| reduceByKey(func, [numTasks]) | 当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下位8),可以通过配置numTasks设置不同的并行任务数。 |
| join(otherStream, [numTasks]) | 当被调用类型分别为(K,V)和(K,W)键值对的2个DStream 时,返回类型为(K,(V,W))键值对的一个新 DSTREAM。 |
| cogroup(otherStream, [numTasks]) | 当被调用的两个DStream分别含有(K, V) 和(K, W)键值对时,返回一个(K, Seq[V], Seq[W])类型的新的DStream。 |
| transform(func) | 通过对源DStream的每RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |
| updateStateByKey(func) | 返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。 |
2,窗口转换函数
| 转换 | 描述 |
|---|---|
| window(windowLength, slideInterval) | 返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
| countByWindow(windowLength,slideInterval) | 返回基于滑动窗口的DStream中的元素的数量。 |
| reduceByWindow(func, windowLength,slideInterval) | 基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream。 |
| reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) | 基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。 |
| reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks]) | 一个更高效的reduceByKkeyAndWindow()的实现版本,先对滑动窗口中新的时间间隔内数据增量聚合并移去最早的与新增数据量的时间间隔内的数据统计量。例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么我们可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,在减去[t-2,t-1]的统计量,这种方法可以复用中间三秒的统计量,提高统计的效率。 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
在Spark Streaming中,数据处理是按批进行的,而数据采集是逐条进行的。因此在Spark Streaming中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔(window duration)决定,而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。除了窗口的长度,窗口操作还有另一个重要的参数就是滑动间隔(slide duration),它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。
3,输出操作
| 转换 | 描述 |
|---|---|
| print() | 在Driver中打印出DStream中数据的前10个元素。 |
| saveAsTextFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsObjectFiles(prefix, [suffix]) | 将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| foreachRDD(func) | 最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。 |
三、常用操作详解
1,transform(func)
该transform操作(转换操作)及其类似的transformWith操作,允许在DStream上应用任意的RDD-to-RDD函数。它可以实现DStream API中未提供的操作,比如两个数据流的连接操作。
示例代码:
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam informationval cleanedDStream = wordCounts.transform { rdd =>rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning...
}
2,updateStateByKey操作
使用的一般操作都是不记录历史数据的,也就说只记录当前定义时间段内的数据,跟前后时间段无关。如果要统计历史时间内的总共数据并且实时更新,如何解决呢?该updateStateByKey操作可以让你保持任意状态,同时不断有新的信息进行更新。
要使用updateStateByKey操作,必须进行下面两个步骤 :
(1)定义状态: 状态可以是任意的数据类型。
(2)定义状态更新函数:用一个函数指定如何使用先前的状态和从输入流中获取的新值更新状态。
对DStream通过updateStateByKey(updateFunction)来实现实时更新。
更新函数有两个参数 :
(1)newValues是当前新进入的数据。
(2)runningCount 是历史数据,被封装到了Option中。
示例:
首先我们需要了解数据的类型
编写处理方法
封装结果
代码:
//定义更新函数
//我们这里使用的Int类型的数据,因为要做统计个数
def updateFunc(newValues : Seq[Int],state :Option[Int]) :Some[Int] = {//传入的newVaules将当前的时间段的数据全部保存到Seq中//调用foldLeft(0)(_+_) 从0位置开始累加到结束 val currentCount = newValues.foldLeft(0)(_+_) //获取历史值,没有历史数据时为None,有数据的时候为Some//getOrElse(x)方法,如果获取值为None则用x代替val previousCount = state.getOrElse(0)//计算结果,封装成Some返回Some(currentCount+previousCount)
}
//使用
val stateDStream = DStream.updateStateByKey[Int](updateFunc)
相关文章:

Spark Streaming DStream的操作
一、DStream的定义 DStream是离散流,Spark Streaming提供的一种高级抽象,代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume,也可以通过对其他DStream应用高阶函数来创建,比如map、redu…...

蓝桥杯冲刺 - week1
文章目录💬前言🌲day192. 递归实现指数型枚举843. n-皇后问题🌲day2日志统计1209. 带分数🌲day3844. 走迷宫1101. 献给阿尔吉侬的花束🌲day41113. 红与黑🌲day51236. 递增三元组🌲day63491. 完全…...

Leetcode27. 移除元素
目录一、题目描述:二、解决思路和代码1. 解决思路2. 代码一、题目描述: 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用…...
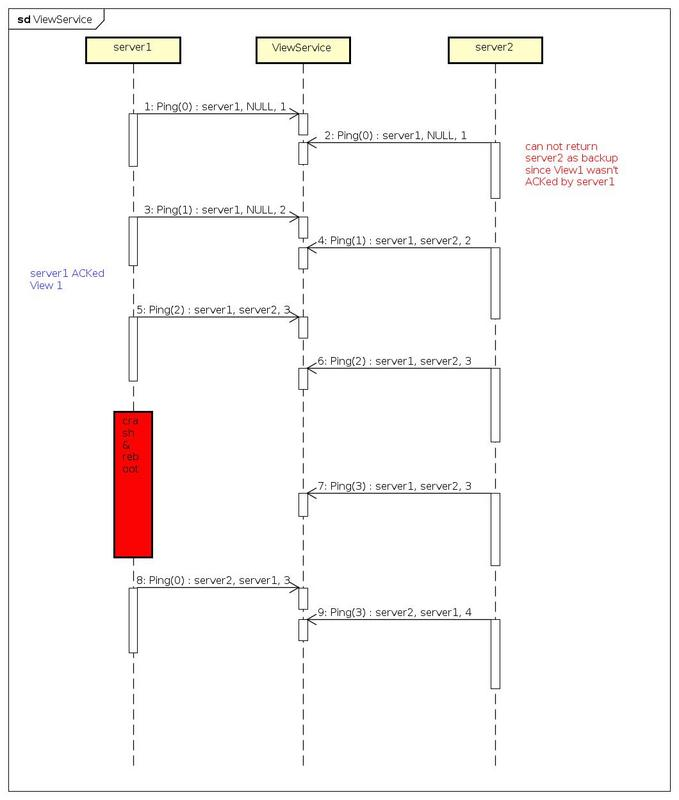
ViewService——一种保证客户端与服务端同步的方法
简介在分布式系统中,最常见的场景就是主备架构。但是如果主机不幸宕机,如何正确的通知客户端当前后端服务器的状况成为一个值得研究的问题。本文描述了一种简单的模型用于解决此问题。背景以一个分布式的Key-Value数据库为背景。数据库对外提供3个接口Ge…...

使用STM32F103ZE开发贪吃蛇游戏
目录 前言 一、设置FreeROTS用户任务 (1)事件event任务 (2)按键输入方向控制任务 (3)果实食物任务 (4)显示任务函数 (3)开始任务 二、主函数 三、ADC采样…...

如何利用Web3D技术打造在线虚拟展览馆
随着Web3D技术的不断发展,越来越多的企业和组织开始将其应用于虚拟展览馆的建设中。虚拟展览馆可以为观众提供高度沉浸式的展览体验,让观众可以随时随地参观各种展览,同时也为展览组织者提供了更多的展示方式和机会。下面将介绍如何利用Web3D…...

第二十三章 opengl之高级OpenGL(实例化)
OpenGL实例化实例化数组绘制小行星带实例化 综合应用。 如果绘制了很多的模型,但是大部分的模型包含同一组顶点数据,只是不同的世界空间变换。 举例:一个全是草的场景,每根草都是一个包含了几个小三角形的模型。需要绘制很多根草…...

C++ String类总结
头文件 #include <string>构造函数 default (1) basic_string();explicit basic_string (const allocator_type& alloc); copy (2) basic_string (const basic_string& str);basic_string (const basic_string& str, const allocator_type& alloc); su…...

内网升级“高效安全”利器!统信软件发布私有化更新管理平台
随着数字化的深度推进,信息安全重要性进一步凸显。建设自主可控的国产操作系统,提升信息安全自主能力,已成为国家重要战略之一。 操作系统安全对计算机系统的整体安全发挥着关键作用,各类客户往往需要在第一时间获取更新与安全补…...
JAVA开发(自研项目的开发与推广)
https://live.csdn.net/v/284629 案例背景: 作为JAVA开发人员,我们可以开发无数多的web项目,电商系统,小程序,H5商城。有时候作为技术研发负责人,项目做成了有时候也需要对内进行内测,对外进行…...
Mysql用户权限分配详解
文章目录MySQL 权限介绍一、Mysql权限级别分析(1)全局级别(1.1) USER表的组成结构(1.1.1) 用户列(1.1.2) 权限列(1.1.3) 安全列(1.1.4)…...

【TypeScript 入门】13.枚举类型
枚举类型 枚举类型:定义包含被命名的常量的集合。比如 TypeScript 支持枚举数字、字符两种常量值类型。 使用方式: enum + 枚举名字 + 花括弧包裹被命名了的常量成员: enum Size {S,M,L } const a = Size.M console.log(Size, Size)...
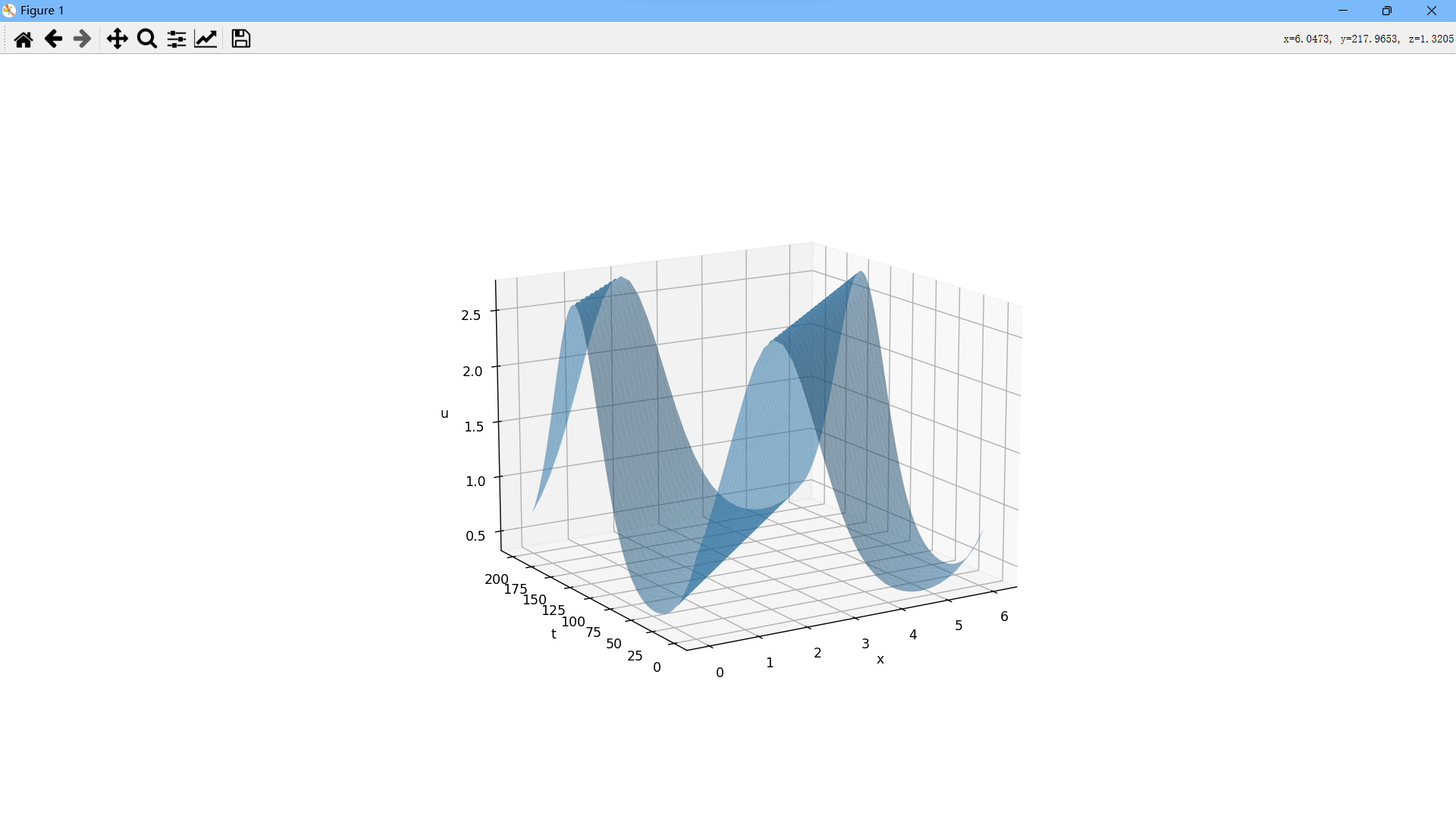
Python科学计算:偏微分方程1
首先,我们来看初边值问题:伯格斯方程:假设函数是定义在上的函数,且满足:右侧第一项表示自对流,第二项则表示扩散,在许多物理过程中,这两种效应占据着主导地位,为了固定一…...
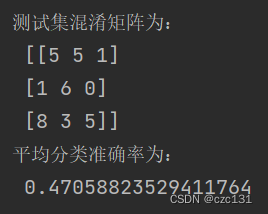
PLS-DA分类的实现(基于sklearn)
目录 简单介绍 代码实现 数据集划分 选择因子个数 模型训练并分类 调用函数 简单介绍 (此处取自各处资料) PLS-DA既可以用来分类,也可以用来降维,与PCA不同的是,PCA是无监督的,PLS-DA是有监督的…...
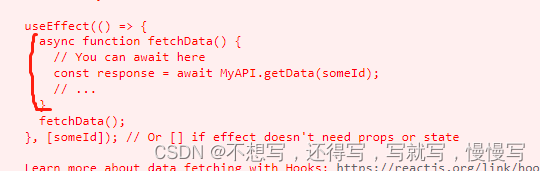
常用hook
Hook 是 React 16.8 的新增特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。理解:hook是react提供的函数API官方提供的hook基础hookuseState APIconst [state, setState] useState(initialState); //返回state值 以及更新state的方法 …...
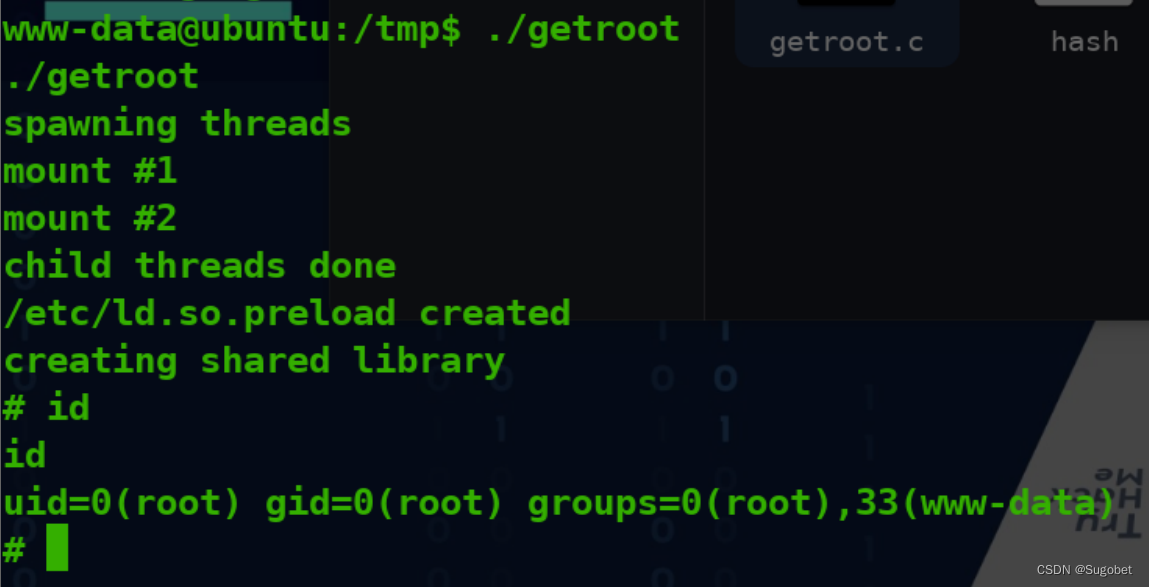
TryHackMe-GoldenEye(boot2root)
GoldenEye 这个房间将是一个有指导的挑战,以破解詹姆斯邦德风格的盒子并获得根。 端口扫描 循例nmap Web枚举 进入80 查看terminal.js 拿去cyberchef解码 拿着这组凭据到/sev-home登录 高清星际大战 POP3枚举 使用刚刚的凭据尝试登录pop3 使用hydra尝试爆破 这…...
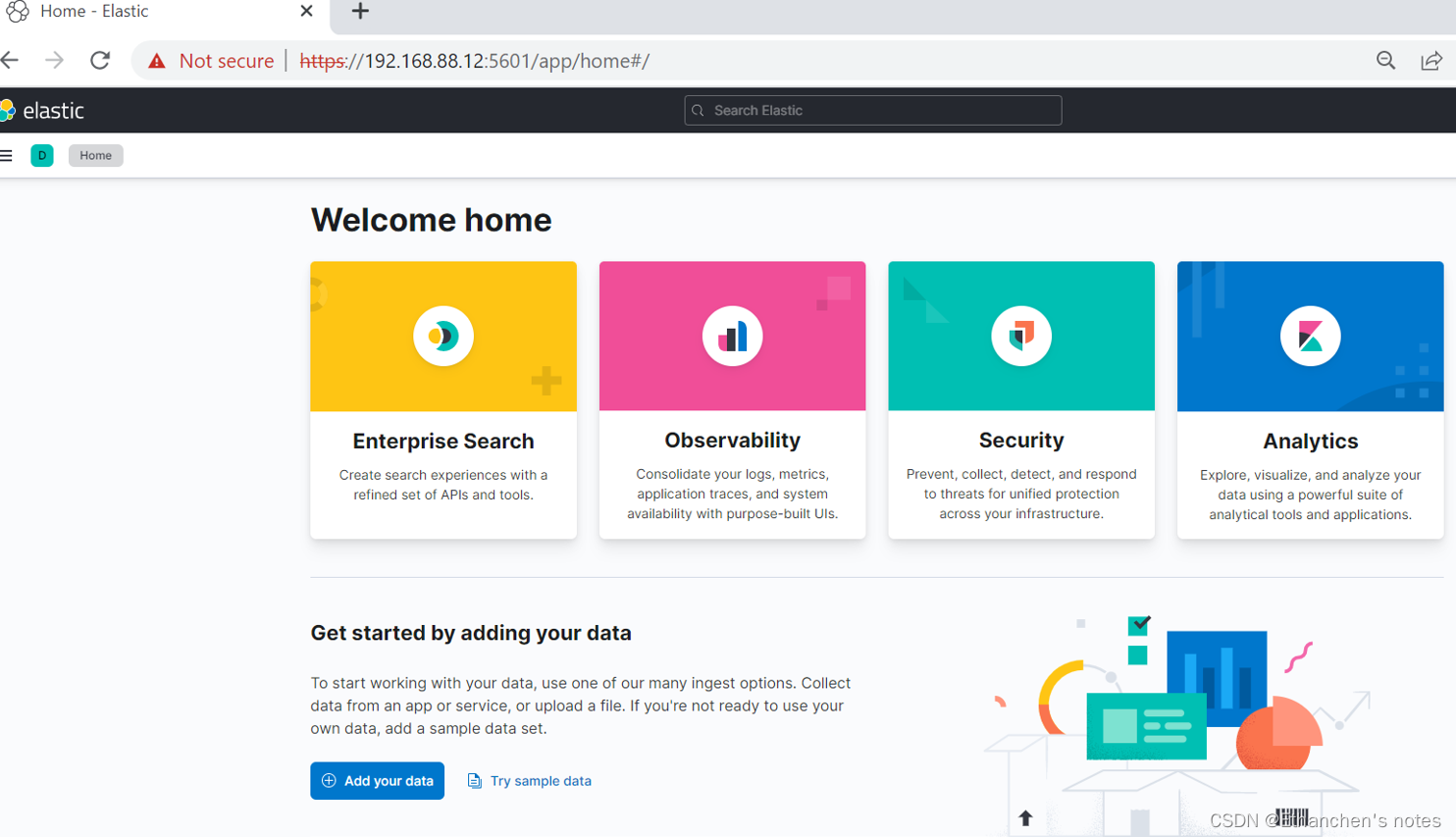
Elasticsearch基本安全加上安全的 HTTPS 流量
基本安全加上安全的 HTTPS 流量 在生产环境中,除非您在 HTTP 层启用 TLS,否则某些 Elasticsearch 功能(例如令牌和 API 密钥)将被禁用。这个额外的安全层确保进出集群的所有通信都是安全的。 当您在模式下运行该elasticsearch-ce…...
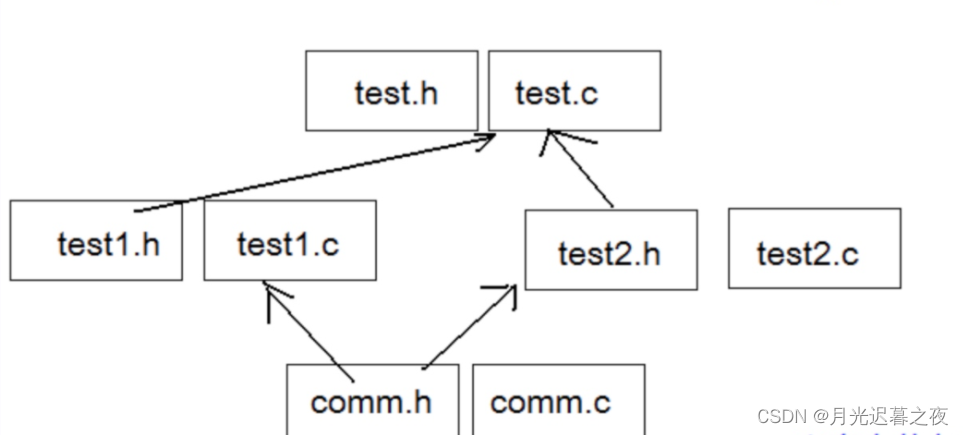
C语言-程序环境和预处理(2)
文章目录预处理详解1.预定义符号2.#define2.1#define定义的标识符2.2#define定义宏2.3#define替换规则注意事项:2.4#和###的作用##的作用2.5带副作用的宏参数2.6宏和函数的对比宏的优势:宏的劣势:宏和函数的一个对比命名约定3.undef4.条件编译…...
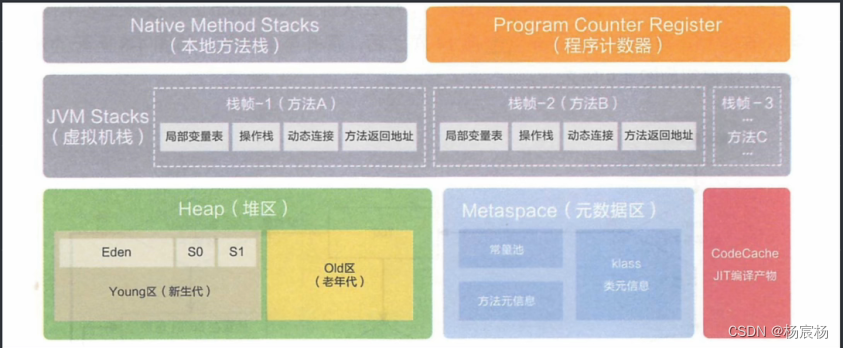
JVM 收集算法 垃圾收集器 元空间 引用
文章目录JVM 收集算法标记-清除算法标记-复制算法标记-整理算法JVM垃圾收集器Serial收集器ParNew收集器Parallel Scavenge /Parallel Old收集器CMS收集器Garbage First(G1)收集器元空间引用强引用软引用弱引用虚引用JVM 收集算法 前面我们了解了整个堆内存实际是以分代收集机制…...
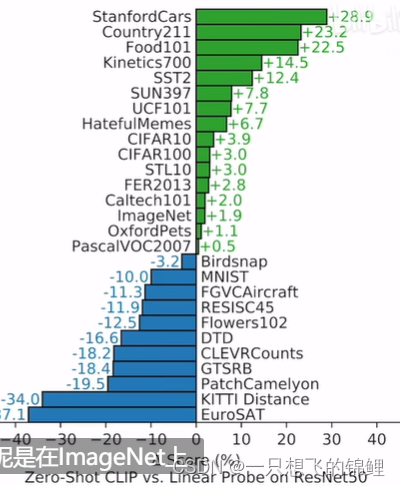
clip精读
开头部分 1. 要点一 从文章题目来看-目的是:使用文本监督得到一个可以迁移的 视觉系统 2.要点二 之前是 fix-ed 的class 有诸多局限性,所以现在用大量不是精细标注的数据来学将更好,利用的语言多样性。——这个方法在 nlp其实广泛的存在&…...

AI药物研发加速发现:DeepChem深度学习框架实战指南
AI药物研发加速发现:DeepChem深度学习框架实战指南 【免费下载链接】deepchem Democratizing Deep-Learning for Drug Discovery, Quantum Chemistry, Materials Science and Biology 项目地址: https://gitcode.com/GitHub_Trending/de/deepchem 深度学习药…...

FPGA调试避坑指南:Vivado ILA采样深度和探针位宽怎么设?资源占用与调试效果的平衡术
FPGA调试实战:ILA采样深度与探针位宽的黄金平衡法则 当你在Artix-7芯片上调试一个包含32位计数器和多状态机的设计时,突然发现ILA吃掉了一半的Block RAM资源,而采样深度却只够捕获5个时钟周期的数据——这种场景是否似曾相识?本文…...

80+经典游戏的现代救赎:WidescreenFixesPack让老游戏焕发新生
80经典游戏的现代救赎:WidescreenFixesPack让老游戏焕发新生 【免费下载链接】WidescreenFixesPack Plugins to make or improve widescreen resolutions support in games, add more features and fix bugs. 项目地址: https://gitcode.com/gh_mirrors/wi/Widesc…...

Avalonia跨平台开发踩坑记:我的第一个带最小化/关闭按钮的MVVM应用
Avalonia跨平台开发实战:从零构建MVVM窗口控制应用 第一次接触Avalonia时,我被它"一次编写,多平台运行"的承诺所吸引。作为一个长期使用WPF的开发者,跨平台桌面应用开发一直是个痛点。但当我真正开始用Avalonia实现一个…...

时空预测入门:从ConvLSTM的局限到PredRNN的突破,一篇讲清记忆单元演化史
时空预测技术演进:从ConvLSTM到PredRNN的记忆单元革命 时空序列预测一直是计算机视觉和机器学习领域最具挑战性的任务之一。想象一下,当你观看一段足球比赛视频时,大脑不仅能记住球员的位置变化(时间维度),…...
)
避坑指南:Prescan8.5安装常见报错解决方案(含MATLAB集成配置)
Prescan8.5安装避坑指南:7类典型报错与MATLAB集成深度解析 当仿真工程师第一次打开Prescan8.5安装包时,很少有人能预料到接下来可能遭遇的"技术迷宫"。作为自动驾驶仿真领域的重要工具,Prescan的安装过程就像它的功能一样复杂——从…...
)
保姆级教程:用Docker快速搭建一个可复现的Hive测试环境(专治各种启动报错)
从零构建可复现的Hive沙箱:Docker Compose全流程避坑指南 每次调试Hive时遇到FAILED: HiveException或metastore连接问题,是否感觉像在破解一个没有说明书的密码锁?传统环境配置的不可复现性让问题排查变成一场噩梦。本文将带你用Docker技术…...

Miniconda环境迁移实战:如何将CentOS装好的Python环境打包到其他服务器?
Miniconda环境迁移实战:跨服务器Python环境无缝转移指南 当你在CentOS服务器上精心配置了一个完美的Python数据分析环境,却需要在另一台服务器上复现时,难道要重新经历一遍繁琐的安装过程?本文将揭示两种高效可靠的Miniconda环境迁…...
)
SEO_10个提升网站排名的实用SEO技巧分享(220 )
<h1 id"seo10seo">SEO:10个提升网站排名的实用SEO技巧分享</h1> <p>在当今互联网时代,搜索引擎优化(SEO)已经成为提升网站流量和吸引潜在客户的关键手段。百度作为中国最大的搜索引擎,其优化规则对整…...

探索Unity全功能的开源方案:UniHacker跨平台功能扩展工具深度指南
探索Unity全功能的开源方案:UniHacker跨平台功能扩展工具深度指南 【免费下载链接】UniHacker 为Windows、MacOS、Linux和Docker修补所有版本的Unity3D和UnityHub 项目地址: https://gitcode.com/GitHub_Trending/un/UniHacker Unity作为游戏开发领域的行业标…...