ElasticSearch的DSL查询⑤(ES数据聚合、DSL语法数据聚合、RestClient数据聚合)
目录
一、数据聚合
1.1 DSL实现聚合
1.1.1 Bucket聚合
1.1.2 带条件聚合
1.1.3 Metric聚合
1.1.4 总结
2.1 RestClient实现聚合
2.1.1 Bucket聚合
2.1.2 带条件聚合
2.2.3 Metric聚合
一、数据聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
-
什么品牌的手机最受欢迎?
-
这些手机的平均价格、最高价格、最低价格?
-
这些手机每月的销售情况如何?
ES实现这些统计功能比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合常见的有三类:
-
桶(
Bucket)聚合:用来对文档做分组-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组 -
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(
Metric)聚合:用来计算一些值,比如:最大值、最小值、平均值等-
Avg:求平均值 -
Max:求最大值 -
Min:求最小值 -
Stats:同时求max、min、avg、sum等
-
-
管道(
pipeline)聚合:将其它聚合的结果为基础做进一步做深层次的运算(聚合)
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
1.1 DSL实现聚合
与之前的搜索功能类似,我们依然先学习DSL的语法,再学习JavaAPI.
1.1.1 Bucket聚合
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
基本语法如下:
# 聚合
GET /goods/_search
{"query": {"match_all": {}}, // 当没有条件(查询所有)的时候可以省略"aggs": { // 定义聚合"cate_agg": { // 给聚合起个名字,随意"terms": { // 聚合类型,terms:词条类型的"field": "category", // 参与聚合的字段"size": 20 // 希望获取聚合结果的数量,默认20}}},"size":0 //在查询过程中不仅仅会把聚合结果返回给我们,同时还会把搜索结果的数据返回给我们,设置size为0,就是不需要返回文档信息。如果不设置size默认为10
}语法说明:
-
size:在查询过程中不仅仅会把聚合结果返回给我们,同时还会把搜索结果的数据返回给我们,设置size为0,就是不需要返回文档信息。如果不设置size默认为10 -
aggs:定义聚合-
cate_agg:聚合名称,自定义,但不能重复-
terms:聚合的类型,按分类聚合,所以用term-
field:参与聚合的字段名称 -
size:希望返回的聚合结果的最大数量
-
-
-
查询的结果:

这个就有点类始于Sql语句:select category,count(*) from goods group by category
一次可以获取多个聚合:

1.1.2 带条件聚合
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可。
例如,查询价格高于1000元的手机品牌有哪些
我们需要从需求中分析出搜索查询的条件和聚合的目标:
-
搜索查询条件:
-
价格高于1000
-
必须是手机
-
-
聚合目标:统计的是品牌,肯定是对brand字段做term聚合
语法如下:
# 聚合
GET /goods/_search
{"query": {"bool": {"filter": [{"term": {"category": "手机"}},{"range": {"price": {"gt": 1000}}}]}},"aggs": {"brand_agg":{"terms": {"field": "brand","size": 20}}},"size":0
}聚合结果如下:

可以看到,结果中只剩下1个品牌了。。。
1.1.3 Metric聚合
除了对数据分组(Bucket)以外,我们还可以对每个Bucket内的数据进一步做数据计算和统计。
例如:想知道手机有哪些品牌,每个品牌的价格最小值、最大值、平均值。
语法如下:
# 聚合
GET /goods/_search
{"query": {"bool": {"filter": [{"term": {"category": "手机"}}]}},"aggs": {"brand_agg":{"terms": {"field": "brand","size": 20},"aggs": { // 对品牌分组的结果再进行聚合"price_stats": { // 聚合名称随意"stats": { // 聚合类型:Avg:求平均值,Max:求最大值,Min:求最小值,Stats:同时求max、min、avg、sum。"field": "price" // 要聚合字段}}}}},"size":0
}可以看到我们在brand_agg聚合的内部,我们新加了一个aggs参数。这个聚合就是brand_agg的子聚合,会对brand_agg形成的每个桶中的文档分别统计。
-
price_stats:聚合名称-
stats:聚合类型,stats是metric聚合的一种-
field:聚合字段,这里选择price,统计价格
-
-
由于stats是对brand_agg形成的每个品牌桶内文档分别做统计,因此每个品牌都会统计出自己的价格最小、最大、平均值。
结果如下:

另外,我们还可以让聚合按照每个品牌的价格平均值排序:

1.1.4 总结
aggs代表聚合,与query同级,此时query的作用是?
-
限定聚合的的文档范围
聚合必须的三要素:
-
聚合名称
-
聚合类型
-
聚合字段
聚合可配置属性有:
-
size:指定聚合结果数量
-
order:指定聚合结果排序方式
-
field:指定聚合字段
2.1 RestClient实现聚合
可以看到在DSL中,aggs聚合条件与query条件是同一级别,都属于查询JSON参数。因此依然是利用request.source()方法来设置。不过聚合条件的要利用AggregationBuilders这个工具类来构造。
2.1.1 Bucket聚合
DSL与JavaAPI的语法对比如下:

聚合结果解析对比:

完整代码:
@Testpublic void testAgg() throws IOException {// 1.创建Request对象SearchRequest request = new SearchRequest("goods");// 2.准备请求参数request.source().size(0);// 2.1 聚合参数request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(5));// 3.发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 4.解析聚合结果Aggregations aggregations = response.getAggregations();// 4.1 获取品牌聚合Terms brandAgg = aggregations.get("brandAgg");// 4.2 获取聚合中的桶List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();// 4.3 遍历桶内数据for (Terms.Bucket bucket : buckets) {// 4.4 获取桶内keySystem.out.println("key = " + bucket.getKeyAsString());System.out.println("count = " + bucket.getDocCount());}}执行结果:

2.1.2 带条件聚合
例如,查询价格高于1000元的手机品牌有哪些
DSL与JavaAPI的语法对比如下:

Java代码如下:
@Testpublic void testConditionAgg() throws IOException {// 1.创建Request对象SearchRequest request = new SearchRequest("goods");// 2.准备请求参数BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("category", "手机")).filter(QueryBuilders.rangeQuery("price").gt(1000));request.source().query(boolQueryBuilder);request.source().size(0);// 2.1 聚合参数request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(5));// 3.发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 4.解析聚合结果Aggregations aggregations = response.getAggregations();// 4.1 获取品牌聚合Terms brandAgg = aggregations.get("brandAgg");// 4.2 获取聚合中的桶List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();// 4.3 遍历桶内数据for (Terms.Bucket bucket : buckets) {// 4.4 获取桶内keySystem.out.println("key = " + bucket.getKeyAsString());System.out.println("count = " + bucket.getDocCount());}}执行结果:
 可以看到,结果中只剩下1个品牌了。。。
可以看到,结果中只剩下1个品牌了。。。
2.2.3 Metric聚合
例如:想知道手机有哪些品牌,每个品牌的价格最小值、最大值、平均值。
DSL与JavaAPI的语法对比如下:

结果解析对比:

完整代码如下:
@Testpublic void testAgg() throws IOException {// 1.创建Request对象SearchRequest request = new SearchRequest("goods");// 2.准备请求参数BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("category", "手机"));request.source().query(boolQueryBuilder);request.source().size(0);// 2.1 聚合参数request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(5).order(// 排序,true:升序(asc),false:降序(desc)BucketOrder.aggregation("priceStats.avg", false) ).subAggregation(AggregationBuilders.stats("priceStats").field("price")));// 3.发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 4.解析聚合结果Aggregations aggregations = response.getAggregations();// 4.1 获取品牌聚合Terms brandAgg = aggregations.get("brandAgg");// 4.2 获取聚合中的桶List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();// 4.3 遍历桶内数据for (Terms.Bucket bucket : buckets) {// 4.4 获取桶内keySystem.out.println("key = " + bucket.getKeyAsString());System.out.println("count = " + bucket.getDocCount());Aggregations subAgg = bucket.getAggregations();Stats priceStats = subAgg.get("priceStats");System.out.println("min = " + priceStats.getMin());System.out.println("max = " + priceStats.getMax());System.out.println("avg = " + priceStats.getAvg());System.out.println("sum = " + priceStats.getSum());}}执行结果:

感谢大家的阅读
相关文章:
ElasticSearch的DSL查询⑤(ES数据聚合、DSL语法数据聚合、RestClient数据聚合)
目录 一、数据聚合 1.1 DSL实现聚合 1.1.1 Bucket聚合 1.1.2 带条件聚合 1.1.3 Metric聚合 1.1.4 总结 2.1 RestClient实现聚合 2.1.1 Bucket聚合 2.1.2 带条件聚合 2.2.3 Metric聚合 一、数据聚合 聚合(aggregations)可以让我们极其方便的实…...

DBeaver 24.0 高阶用法
DBeaver 24.0 高阶用法 文章目录 DBeaver 24.0 高阶用法DBeaver 介绍功能一、元数据搜索功能二、仪表盘显示功能三、ER图功能四、导出数据最后 DBeaver 介绍 DBeaver 确实是一款功能强大的通用数据库管理工具,适合所有需要以专业方式处理数据的用户。它不仅提供了直…...

外卖会员卡项目骗局揭秘,你还在做梦吗?改醒醒了
大家好,我是鲸天科技千千,大家都知道我是做开发的,做互联网行业很多年了,平时会在这里给大家分享一些互联网相关的小技巧和小项目,感兴趣的给我点个关注。 关于外卖会员卡这个项目的一些骗局和套路,我真的…...

比较顺序3s1,3s2,4s1之间的关系
(A,B)---6*30*2---(0,1)(1,0) 分类A和B,让B全是0。当收敛误差为7e-4,收敛199次取迭代次数平均值,3s1为 3s2为 4s1为 3s1,3s2,4s1这3个顺序之间是否有什么联系 , 因为4s1可以按照结构加法 变换成与4s1内在…...

BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin
目录 [web][极客大挑战 2019]Http 考点:Referer协议、UA协议、X-Forwarded-For协议 [web][HCTF 2018]admin 考点:弱密码字典爆破 四种方法: [web][极客大挑战 2019]Http 考点:Referer协议、UA协议、X-Forwarded-For协议 访问…...
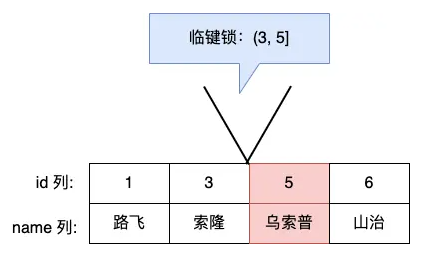
数据库锁之行级锁、记录锁、间隙锁和临键锁
1. 行级锁 InnoDB 引擎支持行级锁,而MyISAM 引擎不支持行级锁,只支持表级锁。行级锁是基于索引实现的。 对于普通的select语句,是不会加记录锁的,因为它属于快照读,通过在MVCC中的undo log版本链实现。如果要在查询时对…...

基于yolov8的血细胞检测计数系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的血细胞检测与计数系统是一种利用深度学习技术,特别是YOLOv8目标检测算法,实现高效、准确血细胞识别的系统。该系统能够自动识别并计数图像或视频中的血细胞,包括红细胞、白细胞和血小板等,为医疗诊断提…...

【深度学习详解】Task3 实践方法论-分类任务实践 Datawhale X 李宏毅苹果书 AI夏令营
前言 综合之前的学习内容, 本篇将探究机器学习实践方法论 出现的问题及其原因 🍎 🍎 🍎 系列文章导航 【深度学习详解】Task1 机器学习基础-线性模型 Datawhale X 李宏毅苹果书 AI夏令营 【深度学习详解】Task2 分段线性模型-引入…...

乐凡北斗 | 手持北斗智能终端的作用与应用场景
在科技日新月异的今天,北斗智能终端作为一项融合了北斗导航系统与现代智能技术的创新成果,正悄然改变着我们的生活方式和工作模式。 北斗智能终端,是以北斗卫星导航系统为核心,集成了高精度定位、导航、授时等功能的智能设备。它…...

Linux:线程互斥
线程互斥 先看到一个抢票案例: class customer { public:int _ticket_num 0;pthread_t _tid;string _name; };int g_ticket 10000;void* buyTicket(void* args) {customer* cust (customer*)args;while(true){if(g_ticket > 0){usleep(1000);cout << …...
misc流量分析
一、wireshark语法 1、wireshark过滤语法 (1)过滤IP地址 ip.srcx.x..x.x 过滤源IP地址 ip.dstx.x.x.x 过滤目的IP ip.addrx.x.x.x 过滤某个IP (2)过滤端口号 tcp.port80tcp.srcport80 显示TCP的源端口80tcp.dstport80 显示…...

Linux驱动(五):Linux2.6驱动编写之设备树
目录 前言一、设备树是个啥?二、设备树编写语法规则1.文件类型2.设备树源文件(DTS)结构3.设备树源文件(DTS)解析 三、设备树API函数1.在内核中获取设备树节点(三种)2.获取设备树节点的属性 四、…...

算法【Java】 —— 前缀和
模板引入 一维前缀和 https://www.nowcoder.com/share/jump/9257752291725692504394 解法一:暴力枚举 在每次提供 l 与 r 的时候,都从 l 开始遍历数组,直到遇到 r 停止,这个方法的时间复杂度为 O(N * q) 解法二:前…...

python网络爬虫(四)——实战练习
0.为什么要学习网络爬虫 深度学习一般过程: 收集数据,尤其是有标签、高质量的数据是一件昂贵的工作。 爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,…...

tio websocket 客户端 java 代码 工具类
为了更好地组织代码并提高可复用性,我们可以将WebSocket客户端封装成一个工具类。这样可以在多个地方方便地使用WebSocket客户端功能。以下是使用tio库实现的一个WebSocket客户端工具类。 1. 添加依赖 确保项目中添加了tio的依赖。如果使用的是Maven,可以…...

通过卷积神经网络(CNN)识别和预测手写数字
一:卷积神经网络(CNN)和手写数字识别MNIST数据集的介绍 卷积神经网络(Convolutional Neural Networks,简称CNN)是一种深度学习模型,它在图像和视频识别、分类和分割任务中表现出色。CNN通过模仿…...

【A题第二套完整论文已出】2024数模国赛A题第二套完整论文+可运行代码参考(无偿分享)
“板凳龙” 闹元宵路径速度问题 摘要 本文针对传统舞龙进行了轨迹分析,并针对一系列问题提出了解决方案,将这一运动进行了模型可视化。 针对问题一,我们首先对舞龙的螺线轨迹进行了建模,将直角坐标系转换为极坐标系࿰…...

一份热乎的数据分析(数仓)面试题 | 每天一点点,收获不止一点
目录 1. 已有ods层⽤⼾表为ods_online.user_info,有两个字段userid和age,现设计数仓⽤⼾表结构如 下: 2. 设计数据仓库的保单表(⾃⾏命名) 3. 根据上述两表,查询2024年8⽉份,每⽇,…...

3 html5之css新选择器和属性
要说css的变化那是发展比较快的,新增的选择器也很多,而且还有很多都是比较实用的。这里举出一些案例,看看你平时都是否用过。 1 新增的一些写法: 1.1 导入css 这个是非常好的一个变化。这样可以让我们将css拆分成公共部分或者多…...

【Kubernetes】K8s 的鉴权管理(一):基于角色的访问控制(RBAC 鉴权)
K8s 的鉴权管理(一):基于角色的访问控制(RBAC 鉴权) 1.Kubernetes 的鉴权管理1.1 审查客户端请求的属性1.2 确定请求的操作 2.基于角色的访问控制(RBAC 鉴权)2.1 基于角色的访问控制中的概念2.1…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

03 - 变量与数据类型
03 - 变量与数据类型 变量是编程里最基础的概念,相当于你往电脑里存东西的"容器"。这章我们把变量的命名规则、Python 的几种基本数据类型都过一遍。 变量是什么 说白了,变量就是一个有名字的盒子。你往里面放个东西,以后想用这个…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...