MySQL之基本查询(二)(update || delete || 聚合函数 || group by)
目录
一、表的更新update
二、表的删除delete
三、聚合函数
四、group by 分组查询
一、表的更新update
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]使用实列:
~ 将孙悟空同学的数学成绩变更为 80 分
update exam_result set math=80 where name='孙悟空';原先分数:

更改后分数:

~ 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
mysql> update exam_result set math=60, chinese=70 where name='曹孟德';原先分数:

更改后分数:

~ 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
对于这个问题,我们可以先拿到总成绩倒数前三的3位同学的总成绩和数学成绩:
select name,math,chinese+math+english total from exam_result order by total limit 3;
上图显示出来的数据其实也是一张表,我们可以对该表进行数据修改:
update exam_result set math=math+30 order by chinese + math + english limit 3; 
注:如果没有筛选条件,update将进行整表更新。
二、表的删除delete
删除数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]使用实例:
~ 删除孙悟空同学的考试成绩
mysql> delete from exam_result where name='孙悟空';删除前的数据:

删除后数据:

~ 删除总分第一名的同学的考试成绩
mysql> delete from exam_result order by chinese+math+english desc limit 1;原先数据:总分第一名是猪悟能,所以我们需要删除他的成绩。


删除后的数据:

删除表的所有数据
我们先创建一张用于测试的表:
mysql> CREATE TABLE for_delete (-> id INT PRIMARY KEY AUTO_INCREMENT,-> name VARCHAR(20)-> );
然后插入测试数据:
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C'); 
然后删除表的所有数据,并查看:
mysql> delete from for_delete;
我们查看一下创建语句:
mysql> show create table for_delete\G; 
我们发现,auto_increment是4,那么如果我们再插入一条新的数据:自增 id 在原值上增长
INSERT INTO for_delete (name) VALUES ('D'); 
查看表结构,会有 AUTO_INCREMENT项:

所以,对于delete清空表数据的方式,其不会清空AUTO_INCREMENT的值。
截断表
语法:
TRUNCATE [TABLE] table_name;注:这个操作慎用,其特点如下,
1、只能对整表操作,不能像 DELETE 一样可以针对部分数据操作,即只能用于清空表的所有的数据。
2、实际上 TRUNCATE 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事务,所以无法回滚。
3、会重置 AUTO_INCREMENT 项。
我们先创建一个测试表:
CREATE TABLE for_truncate (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
插入一些测试数据:

然后,查看一下该表的创建语句:auto_increment是4。

接着,我们截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作:

然后,查看一下该表截断后的创建语句:auto_increment已经被清空了。

然后,向表中插入一条新的数据:

再查看一下该表的创建语句:auto_increment是2。

注:delete和truncate都是对表中的数据进行操作。所以数据没了,但是表任然存在。

三、聚合函数
聚合函数可以对一组值执行计算并返回单一的值。
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
使用实例:
下面的所有操作和结果均来源下表:

~ 统计班级共有多少同学
mysql> select count(*) from exam_result;
~ 统计数学成绩总分
mysql> select sum(math) from exam_result;
~ 统计数学成绩平均分
mysql> select avg(math) from exam_result;
~ 返回英语成绩的最高分
mysql> select max(english) from exam_result;
~ 返回 < 70 分以下的数学成绩的最低分
mysql> select min(math) from exam_result where math<70;
四、group by 分组查询
在select中使用group by 子句可以对指定列进行分组查询。分组的目的是为了进行分组之后,方便进行聚合统计。
语法:
select column1, column2, .. from table group by column;使用实例
首先,创建一个雇员信息表(来自Oracle 9i的经典测试表):EMP员工表,DEPT部门表,SALGRADE工资等级表。
~ 显示每个部门的平均工资和最高工资
select deptno,avg(sal) 平均工资,max(sal) 最高工资 from emp group by deptno;

所以说,分组统计的本质,就是把一组按照条件拆成了多个组,然后进行各自组内的统计。即分组就是,把一张表按照条件在逻辑上拆成了多个子表,然后分别对各自的子表进行聚合统计。
~ 显示每个部门的每种岗位的平均工资和最低工资
首先,我们分析一下需求,我们需要的数据是平均工资和最低工资,这个可以使用函数avg和min,来实现。限制条件就是,我们需要根据部门和岗位进行分组,可以使用group by。
mysql> select deptno,job,avg(sal),min(sal) from emp group by deptno,job;
~ 显示平均工资低于2000的部门和它的平均工资
首先,我们分析一下需求,我们需要根据部门分组后,得到部门的平均工资。
mysql> select deptno,avg(sal) from emp group by deptno;
然后,我们需要根据分组聚合的结果,进行筛选,显示平均工资低于2000的部门和它的平均工资。
select deptno,avg(sal) mysal from emp group by deptno having mysal<2000;
注:其中,having是对聚合统计后的数据,进行条件筛选。
having 和 where
两者区别:条件筛选的阶段是不同的。
where——对具体的任意列进行条件筛选。
having——对分组聚合之后的数据结果进行条件筛选。
注:SQL查询中各个关键字的执行先后顺序,from > on> join > where > group by > with > having > select > distinct > order by > limit
相关文章:
MySQL之基本查询(二)(update || delete || 聚合函数 || group by)
目录 一、表的更新update 二、表的删除delete 三、聚合函数 四、group by 分组查询 一、表的更新update 语法: UPDATE table_name SET column expr [, column expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...] 使用实列: ~ 将孙悟空同学的数学…...

全栈开发(五):初始化前端项目(nuxt3+vue3+element-plus)+前端代理
1.初始化前端项目 Nuxt3:搭建项目_nuxt3 项目搭建-CSDN博客、 2.配置代理 nuxt.config.ts // https://nuxt.com/docs/api/configuration/nuxt-configexport default defineNuxtConfig({devtools: { enabled: true },modules: ["element-plus/nuxt", "pinia/n…...

Linux环境变量进程地址空间
目录 一、初步认识环境变量 1.1常见的环境变量 1.2环境变量的基本概念 二、命令行参数 2.1通过命令行参数获取环境变量 2.2本地变量和内建命令 2.3环境变量的获取 三、进程地址空间 3.1进程(虚拟)地址空间的引入 3.2进程地址空间的布局和理解 …...

C++读取txt文件中的句子在终端显示,同时操控鼠标滚轮(涉及:多线程,产生随机数,文件操作等)
文章目录 运行效果功能描述代码mian.cppincludeMouseKeyControl.hTipsManagement.h srcMouseControl.cppTipsManagement.cpp 运行效果 功能描述 线程一:每隔n随机秒,动一下鼠标滚轮,防止屏幕息屏。 线程二:运行时加载txt文件中的…...

Android 中使用高德地图实现根据经纬度信息画出轨迹、设置缩放倍数并定位到轨迹路线的方法
一、添加依赖和权限 在项目的build.gradle文件中添加高德地图的依赖: implementation com.amap.api:maps:latest_version在AndroidManifest.xml文件中添加必要的权限: <uses-permission android:name"android.permission.ACCESS_FINE_LOCATIO…...

LeetCode从入门到超凡(二)递归与分治算法
引言 大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年9月学习赛的LeetCode学习总结文档;在算法设计中,递归和分治算法是两种非常重要的思想和方法。它们不仅在解决复杂问题时表…...

superset 解决在 mac 电脑上发送 slack 通知的问题
参考文档: https://superset.apache.org/docs/configuration/alerts-reports/ 核心配置: FROM apache/superset:3.1.0USER rootRUN apt-get update && \apt-get install --no-install-recommends -y firefox-esrENV GECKODRIVER_VERSION0.29.0 RUN wget -q https://g…...

SQL_UNION
在 SQL 中使用 UNION 操作符时,被联合的两个或多个 SELECT 语句的列数必须相同,并且相应的列数据类型也需要兼容。这是因为 UNION 操作符会将结果组合成单个结果集,每个 SELECT 语句的结果行将按顺序放置在结果集中。 例如,如果你…...
高等代数笔记(2)————(弱/强)数学归纳法
数学归纳法的引入情景其实很简单,就是多米诺骨牌。 推倒所有多米诺骨牌的关键就是推倒第一块,以及确保第一块倒下后会带动第二块,第二块带动第三块,以此类推,也就是可以递推。由此我们可以归纳出所有的多米诺骨牌都可…...

模拟自然的本质:与IBM量子计算研究的问答
量子计算可能是计算领域的下一个重大突破,但它的一般概念仍然处于炒作和猜测的现状?它能破解所有已知的加密算法吗?它能设计出治愈所有疾病的新分子吗?它能很好地模拟过去和未来,以至于尼克奥弗曼能和他死去的儿子说话…...

Robot Operating System——带有时间戳和坐标系信息的多边形信息
大纲 应用场景1. 机器人导航场景描述具体应用 2. 环境建模场景描述具体应用 3. 路径规划场景描述具体应用 4. 无人机飞行控制场景描述具体应用 5. 机械臂运动控制场景描述具体应用 6. 自动驾驶车辆控制场景描述具体应用 定义字段解释 案例 geometry_msgs::msg::PolygonStamped …...

内网穿透(当使用支付宝沙箱的时候需要内网穿透进行回调)
内网穿透 一、为什么要使用内网穿透: 内网穿透也称内网映射,简单来说就是让外网可以访问你的内网:把自己的内网(主机)当做服务器,让外网访问 二、安装路由侠 路由侠-局域网变公网 (luyouxia.com) 安装成功如下: 三…...

Contact Form 7最新5.9.8版错误修复方案
最近有多位用户反应Contact Form 7最新5.9.8版的管理页面有错误如下图所示 具体错误文件的路径为wp-content\plugins\contact-form-7\admin\includes\welcome-panel.php on line 153 找到welcome-panel.php这个文件编辑它,将如下图选中的部分删除 删除以后…...

【第十一章:Sentosa_DSML社区版-机器学习之分类】
目录 11.1 逻辑回归分类 11.2 决策树分类 11.3 梯度提升决策树分类 11.4 XGBoost分类 11.5 随机森林分类 11.6 朴素贝叶斯分类 11.7 支持向量机分类 11.8 多层感知机分类 11.9 LightGBM分类 11.10 因子分解机分类 11.11 AdaBoost分类 11.12 KNN分类 【第十一章&…...

kafka3.8的基本操作
Kafka基础理论与常用命令详解(超详细)_kafka常用命令和解释-CSDN博客 [rootk1 bin]# netstat -tunlp|grep 90 tcp6 0 0 :::9092 :::* LISTEN 14512/java [rootk1 bin]# ./kafka-topics.s…...

如何检测并阻止机器人活动
恶意机器人流量逐年增加,占 2023 年所有互联网流量的近三分之一。恶意机器人会访问敏感数据、实施欺诈、窃取专有信息并降低网站性能。新技术使欺诈者能够更快地发动攻击并造成更大的破坏。机器人的无差别和大规模攻击对所有行业各种规模的企业都构成风险。 但您的…...

《linux系统》基础操作
二、综合应用题(共50分) 随着云计算技术、容器化技术和移动技术的不断发展,Unux服务器已经成为全球市场的主导者,因此具备常用服务器的配置与管理能力很有必要。公司因工作需要,需要建立相应部门的目录,搭建samba服务器和FTP服务器,要求将销售部的资料存放在samba服务器…...

EMT-LTR--学习任务间关系的多目标多任务优化
EMT-LTR–学习任务间关系的多目标多任务优化 title: Learning Task Relationships in Evolutionary Multitasking for Multiobjective Continuous Optimization author: Zefeng Chen, Yuren Zhou, Xiaoyu He, and Jun Zhang. journal: IEE…...

MySQL record 08 part
数据库连接池: Java DataBase Connectivity(Java语言连接数据库) 答: 使用连接池能解决此问题, 连接池,自动分配连接对象,并对闲置的连接进行回收。 常用的数据库连接池: 建立数…...
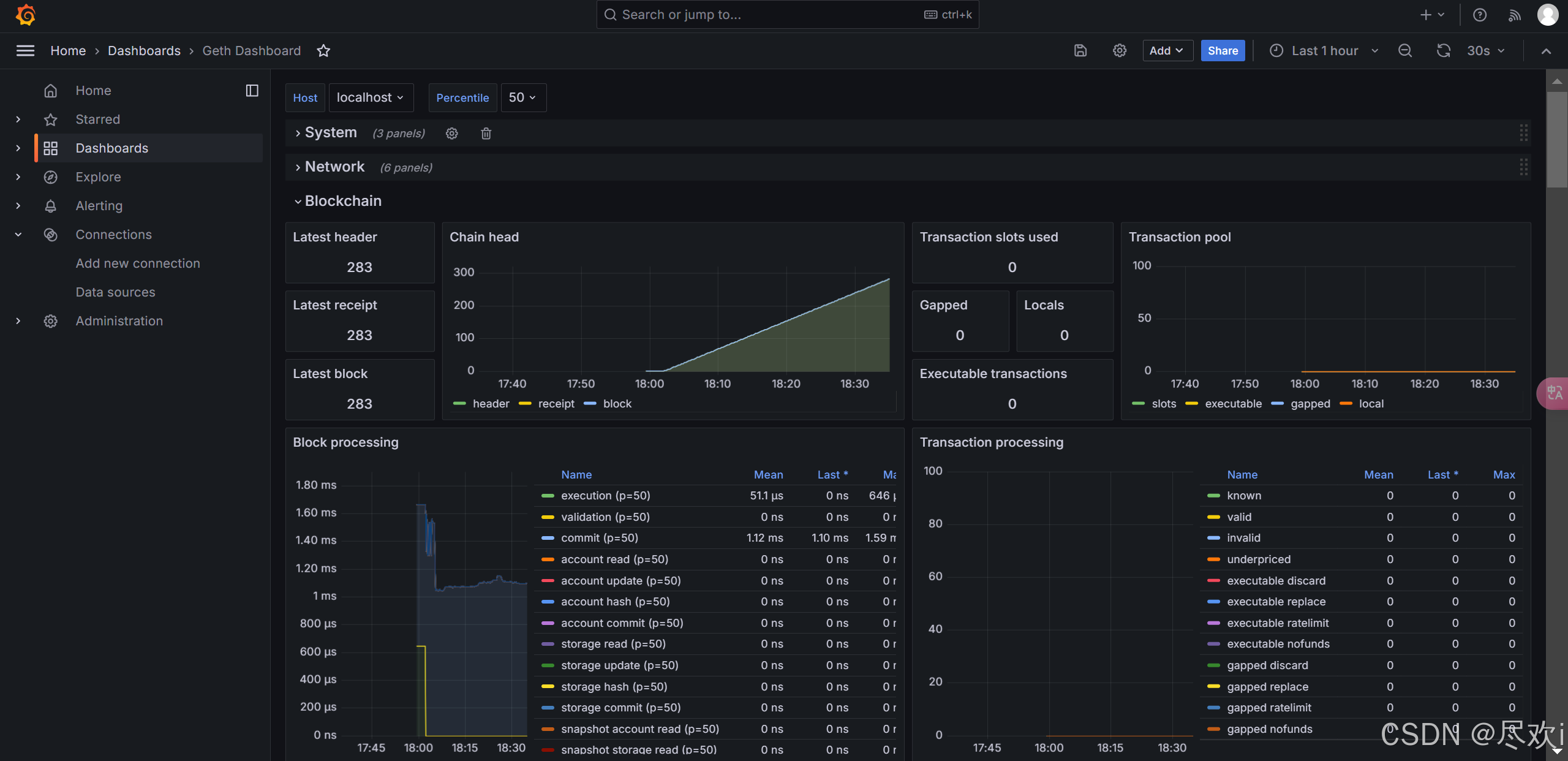
打造以太坊数据监控利器:InfluxDB与Grafana构建Geth可视化分析平台
前言 以太坊客户端收集大量数据,这些数据可以按时间顺序数据库的形式读取。为了简化监控,这些数据可以输入到数据可视化软件中。在此页面上,将配置 Geth 客户端以将数据推送到 InfluxDB 数据库,并使用 Grafana 来可视化数据。 一…...
)
从YOLOv5到昇腾NPU:一份避坑无数的PyTorch模型迁移实战笔记(含性能调优)
从YOLOv5到昇腾NPU:一份避坑无数的PyTorch模型迁移实战笔记(含性能调优) 去年接手一个工业质检项目时,客户要求在昇腾NPU上部署YOLOv5模型。本以为只是简单的环境适配,没想到从驱动安装到性能调优,整整踩了…...
)
FreeRTOS移植避坑指南:当你的芯片不在官方支持列表时(以S3C2440为例)
FreeRTOS移植实战:非官方支持芯片的定制化开发方法论 当你的项目需要将FreeRTOS移植到非官方支持芯片时,整个过程就像在未知海域航行——没有现成的海图,但掌握正确的导航方法同样能到达目的地。以经典的ARM9芯片S3C2440为例,这种…...

英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南
英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基于…...

Perplexity搜索响应延迟突增2100ms?内部API调用链路拆解,开发者必看避坑清单
更多请点击: https://codechina.net 第一章:Perplexity搜索响应延迟突增2100ms?现象复现与影响定性 近期监控系统捕获到Perplexity搜索API端点( /v1/search)在UTC时间2024-06-12T08:14:22Z起出现持续约17分钟的P99延迟…...

主从结合,安全互联:Anybus工业通信解决方案全栈升级
HMS亮相2026 PROFINET技术路演杭州站,展出全新Anybus SoM及全栈PROFINET方案,助力设备商应对CRA与机械法规双重合规挑战。 5月14日,由PI China主办的2026 PROFINET技术路演(杭州站)在西玥酒店圆满举行。HMS华东区OEM销…...
)
Perplexity引用格式设置全链路解析(含BibTeX/CSL/DOI自动映射底层逻辑)
更多请点击: https://kaifayun.com 第一章:Perplexity引用格式设置全链路解析(含BibTeX/CSL/DOI自动映射底层逻辑) Perplexity 在学术写作支持中并非原生集成引文管理,但其底层可对接外部文献元数据服务,实…...

压接 vs 焊接:高速连接器组装工艺的选型指南与实战对比
摘要/前言在通信设备、工业控制及数据中心硬件设计中,连接器的组装工艺选择直接影响产品的可靠性、可维护性与生产良率。压接(Press-Fit)与焊接(Soldering)是当前通孔连接器最主要的两种电气互连方式。压接依靠过盈配合…...

告别文档踩坑:手把手教你用OkHttp和Gson解析OneNET API返回的复杂JSON数据
告别文档踩坑:手把手教你用OkHttp和Gson解析OneNET API返回的复杂JSON数据 在Android开发中,处理网络请求和JSON数据解析是每个开发者都必须掌握的基本技能。然而,当面对像OneNET这样的物联网平台返回的复杂嵌套JSON结构时,即使是…...

别再傻傻重启了!用JRebel给IDEA装上‘秒级热更新’,Spring Boot开发效率翻倍
告别低效重启:用JRebel解锁Spring Boot开发的终极热更新体验 每次修改几行代码就要等待漫长的应用重启?Spring Boot DevTools的热加载功能已经无法满足你对开发效率的极致追求?作为长期奋战在Java开发一线的工程师,我深知这种重复…...
的四种“平替”方案全解析(含代码对比))
从《GPU Gems》到实战:次表面散射(SSS)的四种“平替”方案全解析(含代码对比)
从《GPU Gems》到实战:次表面散射(SSS)的四种“平替”方案全解析(含代码对比) 在实时渲染领域,次表面散射(Subsurface Scattering,简称SSS)一直是提升材质真实感的关键技…...