【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)
此文章为【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)包括:完整的模型训练套路(一)、完整的模型训练套路(二)、完整的模型训练套路(三)、利用GPU训练(一)、利用GPU训练(二)、完整的模型验证套路、【完结】看看开源项目。
学习系列笔记(已完结):
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(一)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(二)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(三)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(四)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)_耿鬼喝椰汁的博客-CSDN博客
目录
一、完整的模型训练套路(一)
1.model.py 文件代码
2.train.py 文件代码
二、完整的模型训练套路(二)
1.如何知道模型是否训练好,或达到需求?
完整代码
2. 与 TensorBoard 结合
3. 保存每一轮训练的模型
4.正确率的实现(对分类问题)
三、完整的模型训练套路(三)
此章节注意一些细节:
1.train.py 完整代码
2.model.train() 和 model.eval()
3.作用
回顾案例
四、利用GPU训练(一)
1.第一种使用GPU训练的方式
1.网络模型
2.数据(包括输入、标注):
3.损失函数:
2. 比较CPU/GPU训练时间
(1)对于CPU
(2) 对于GPU
(3)查看GPU信息
3.Google Colab
1.如何在Google Colab使用GPU?
五、利用GPU训练(一)
1.第二种使用GPU训练的方式(更常用)
(六)完整的模型验证(测试、demo)套路
1.示例 1
test.py(把训练模型运用到实际环境中)完整代码
2.示例二
(七)、看看开源项目
README.md
train.py
训练参数设置
一、完整的模型训练套路(一)
以 CIFAR10 数据集为例,分类问题(10分类)
pycharm中 在语句后面按 Ctrl + d 可以复制这条语句
此教程搭建的网络模型:
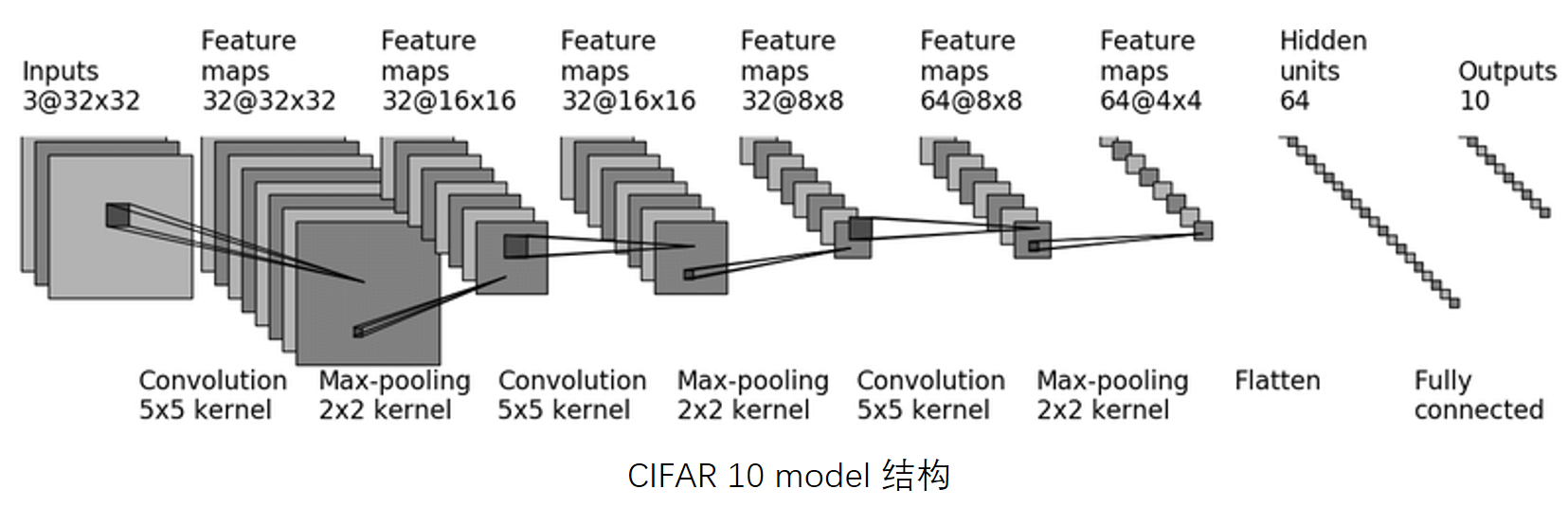
1.model.py 文件代码
import torch
from torch import nn# 搭建神经网络(10分类网络)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# 把网络放到序列中self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), # 展平nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,x):x = self.model(x)return xif __name__ == '__main__':# 测试网络的验证正确性tudui = Tudui()input = torch.ones((64,3,32,32)) # batch_size=64(代表64张图片),3通道,32x32output = tudui(input)print(output.shape)运行结果如下:
![]()
返回64行数据,每一行数据有10个数据,代表每一张图片在10个类别中的概率。
2.train.py 文件代码
(与 model.py 文件必须在同一个文件夹底下)
import torchvision.datasets
from model import *
from torch import nn
from torch.utils.data import DataLoader# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 创建网络模型
tudui = Tudui()# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数for i in range(epoch):print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9# 训练步骤开始for data in train_dataloader: # 从训练的dataloader中取数据imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets)# 优化器优化模型optimizer.zero_grad() # 首先要梯度清零loss.backward() # 反向传播得到每一个参数节点的梯度optimizer.step() # 对参数进行优化total_train_step += 1print("训练次数:{},loss:{}".format(total_train_step,loss.item()))运行结果如下:

print(a) 和 print(a.item()) 的区别
import torch
a = torch.tensor(5)
print(a)
print(a.item())![]()
二、完整的模型训练套路(二)
1.如何知道模型是否训练好,或达到需求?
每次训练完一轮就进行测试,以测试数据集上的损失或正确率来评估模型有没有训练好
测试过程中不需要对模型进行调优,利用现有模型进行测试,所以有以下命令:
with torch.no_grad(): 在上述 train.py 代码后继续写:
# 测试步骤开始total_test_loss = 0with torch.no_grad(): # 无梯度,不进行调优for data in test_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字,所以要.item()一下print("整体测试集上的Loss:{}".format(total_test_loss))结果如下:

此处为了使测试的 loss 结果易找,在 train.py 中添加了一句 if 的代码,使train每训练100轮才打印1次:
if total_train_step % 100 ==0: # 逢百才打印记录print("训练次数:{},loss:{}".format(total_train_step,loss.item()))完整代码
import torchvision.datasets
from model import *
from torch import nn
from torch.utils.data import DataLoader# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 创建网络模型
tudui = Tudui()# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数for i in range(epoch):print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9# 训练步骤开始for data in train_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets)# 优化器优化模型optimizer.zero_grad() # 首先要梯度清零loss.backward() # 反向传播得到每一个参数节点的梯度optimizer.step() # 对参数进行优化total_train_step += 1if total_train_step % 100 ==0: # 逢百才打印记录print("训练次数:{},loss:{}".format(total_train_step,loss.item()))# 测试步骤开始total_test_loss = 0with torch.no_grad(): # 无梯度,不进行调优for data in test_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字print("整体测试集上的Loss:{}".format(total_test_loss))2. 与 TensorBoard 结合
添加TensorBoard后的代码:
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriterfrom model import *
from torch import nn
from torch.utils.data import DataLoader# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 创建网络模型
tudui = Tudui()# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数# 添加tensorboard
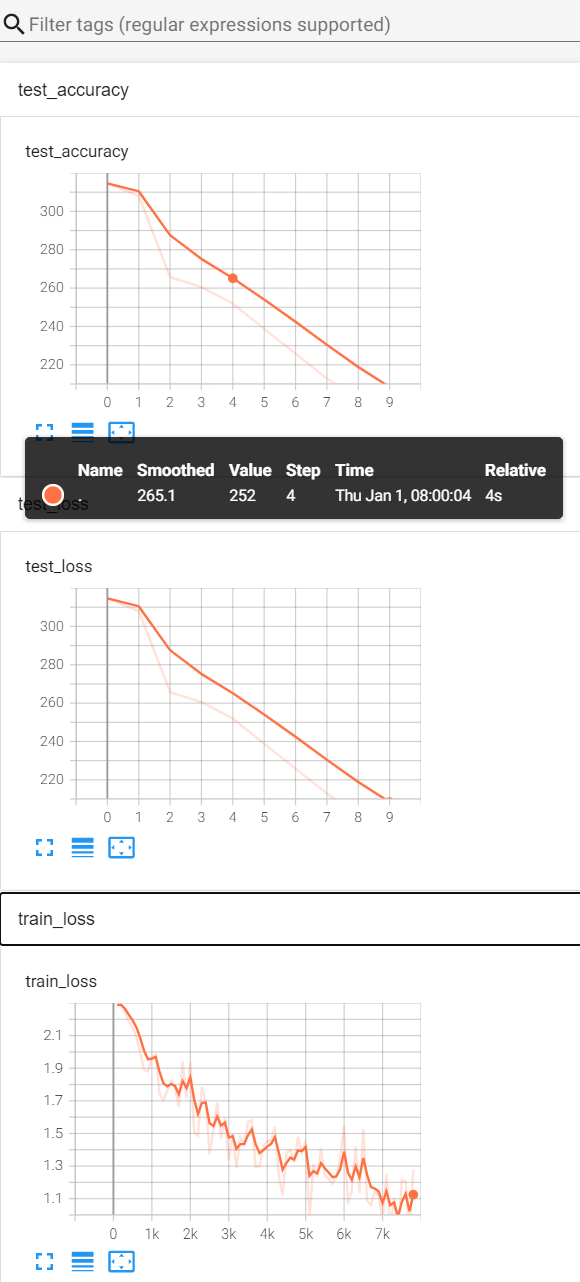
writer = SummaryWriter("../logs_train")for i in range(epoch):print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9# 训练步骤开始for data in train_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets)# 优化器优化模型optimizer.zero_grad() # 首先要梯度清零loss.backward() # 反向传播得到每一个参数节点的梯度optimizer.step() # 对参数进行优化total_train_step += 1if total_train_step % 100 ==0: # 逢百才打印记录print("训练次数:{},loss:{}".format(total_train_step,loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始total_test_loss = 0with torch.no_grad(): # 无梯度,不进行调优for data in test_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字print("整体测试集上的Loss:{}".format(total_test_loss))writer.add_scalar("test_loss",total_test_loss,total_test_step)total_test_step += 1writer.close()运行结果:

在 Terminal 里输入:
tensorboard --logdir=logs_train打开网页后显示图片:

3. 保存每一轮训练的模型
添加两句代码:
torch.save(tudui,"tudui_{}.pth".format(i)) # 每一轮保存一个结果print("模型已保存")writer.close()运行后:
正确率的实现(对分类问题)
4.正确率的实现(对分类问题)
即便得到整体测试集上的 loss,也不能很好说明在测试集上的表现效果
- 在分类问题中可以用正确率表示(下述代码改进)
- 在目标检测/语义分割中,可以把输出放在tensorboard里显示,看测试结果
例子:

第一步:(个人理解:argmax()返回数组中最大值的索引。)
import torchoutputs = torch.tensor([[0.1,0.2],[0.3,0.4]])
print(outputs.argmax(1)) # 0或1表示方向,1为横向比较大小. 运行结果:tensor([1, 1])
第二步:
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
print(preds == targets) # tensor([False, True])
print(sum(preds == targets).sum()) # tensor(1),对应位置相等的个数上例说明了基本用法,现对原问题的代码再进一步优化,计算整体正确率:
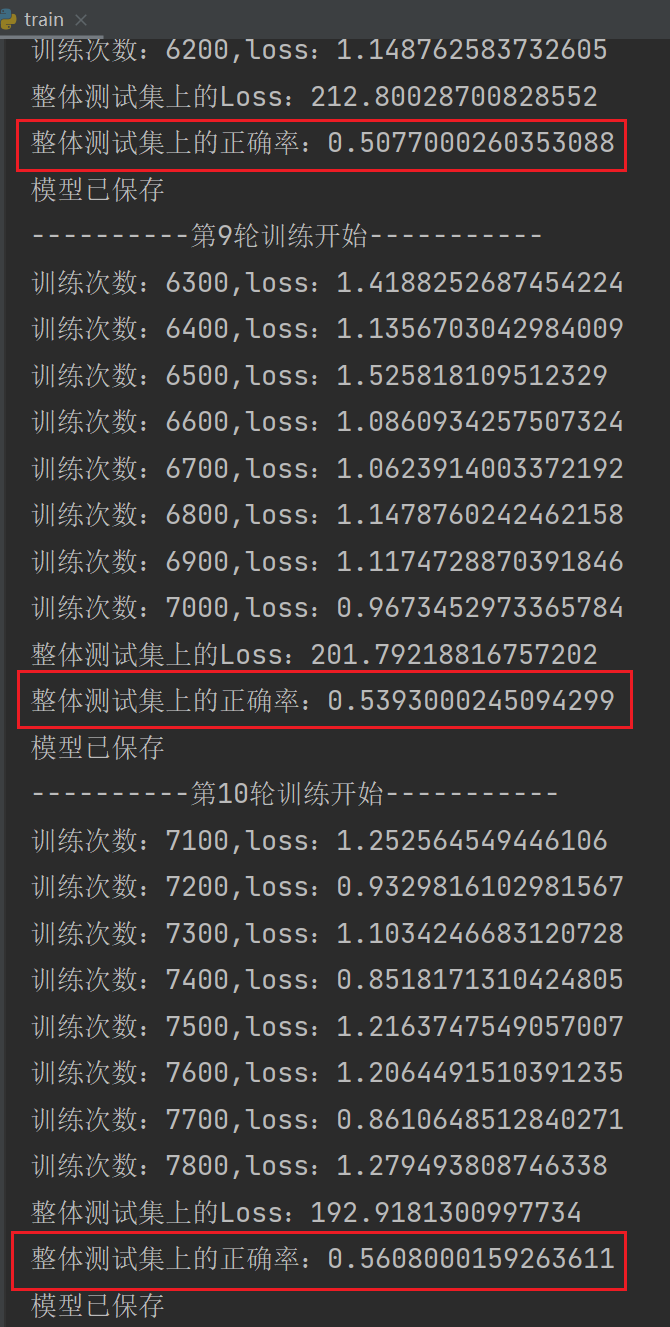
# 测试步骤开始total_test_loss = 0total_accuracy = 0with torch.no_grad(): # 无梯度,不进行调优for data in test_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字# 求整体测试数据集上的误差或正确率accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/imgs.size(0)))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/imgs.size(0),total_test_step)total_test_step += 1torch.save(tudui,"tudui_{}.pth".format(i)) # 每一轮保存一个结果print("模型已保存")writer.close()运行结果:
在 Terminal 里输入:
tensorboard --logdir=logs_train打开网址 :
三、完整的模型训练套路(三)
此章节注意一些细节:
1.train.py 完整代码
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriterfrom model import *
from torch import nn
from torch.utils.data import DataLoader# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 创建网络模型
tudui = Tudui()# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")for i in range(epoch):print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9# 训练步骤开始for data in train_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets)# 优化器优化模型optimizer.zero_grad() # 首先要梯度清零loss.backward() # 反向传播得到每一个参数节点的梯度optimizer.step() # 对参数进行优化total_train_step += 1if total_train_step % 100 ==0: # 逢百才打印记录print("训练次数:{},loss:{}".format(total_train_step,loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始total_test_loss = 0total_accuracy = 0with torch.no_grad(): # 无梯度,不进行调优for data in test_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字# 求整体测试数据集上的误差或正确率accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step += 1torch.save(tudui,"tudui_{}.pth".format(i)) # 每一轮保存一个结果print("模型已保存")writer.close()2.model.train() 和 model.eval()
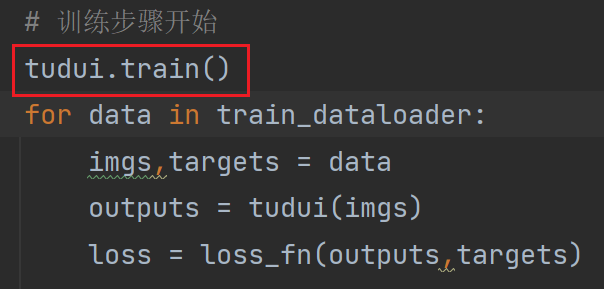
训练步骤开始之前会把网络模型(我们这里的网络模型叫 tudui)设置为train,并不是说把网络设置为训练模型它才能够开始训练

测试网络前写 网络.eval(),并不是说需要这一行才能把网络设置成 eval 状态,才能进行网络测试。
3.作用
这两句不写网络依然可以运行,它们的作用是:

本节写的案例没有 Dropout 层或 BatchNorm 层,所以有没有这两行无所谓
如果有这些特殊层,一定要调用。
回顾案例
首先,要准备数据集,准备对应的 dataloader
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriterfrom model import *
from torch import nn
from torch.utils.data import DataLoader# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)调用
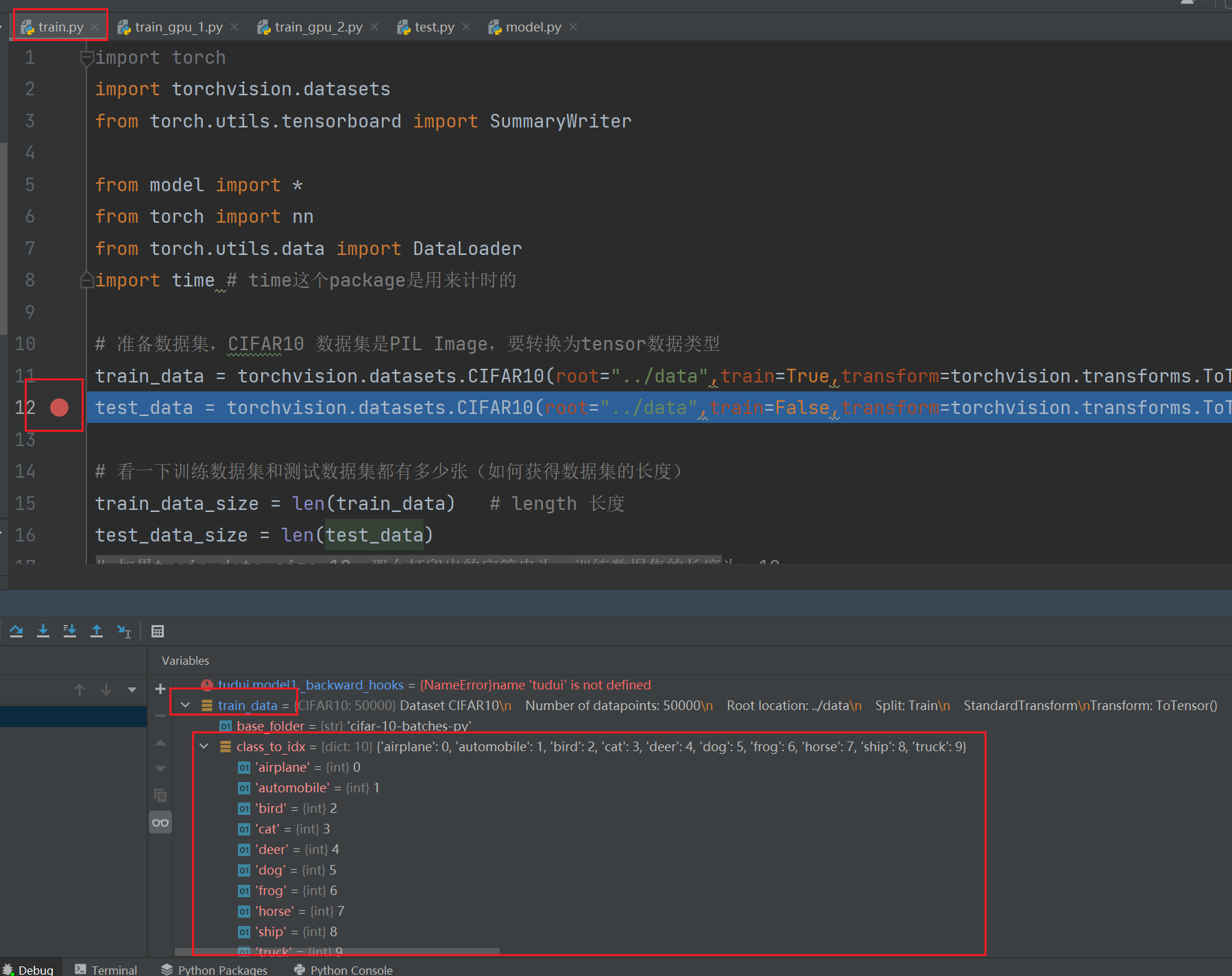
tudui.train() 使网络进入训练状态,从训练的 dataloader 中不断取数据,算出误差,放到优化器中进行优化,采用某种特定的方式展示输出,一轮结束后或特定步数后进行测试
# 训练步骤开始for data in train_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets)# 优化器优化模型optimizer.zero_grad() # 首先要梯度清零loss.backward() # 反向传播得到每一个参数节点的梯度optimizer.step() # 对参数进行优化total_train_step += 1if total_train_step % 100 ==0: # 逢百才打印记录print("训练次数:{},loss:{}".format(total_train_step,loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)测试过程中可以设置
tudui.eval() 要设置
with torch.no_grad(): 让网络模型中的参数都没有,因为我们只需要进行测试,不需要对网络模型进行调整,更不需要利用梯度来优化。
从测试数据集中取数据,计算误差,构建特殊指标显示出来。
for data in test_dataloader:imgs,targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字# 求整体测试数据集上的误差或正确率accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数total_accuracy = total_accuracy + accuracy最后可以通过一些方式来展示一下训练的网络在测试集上的效果
print("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step += 1在特定步数或某一轮可以保存模型,保存模型的方式是之前讲的方式1:
torch.save(tudui,"tudui_{}.pth".format(i))回忆官方推荐的方式2:
torch.save(tudui.state_dict,"tudui_{}.pth".format(i))(将网络模型的状态转化为字典型,展示它的特定保存位置)
四、利用GPU训练(一)
两种方式实现代码在GPU上训练:
1.第一种使用GPU训练的方式

1.网络模型

2.数据(包括输入、标注):

( 训练过程)

( 测试过程)
3.损失函数:

更好的写法:(其他几个地方也可以类似这样写)

其他地方同理加上
这种写法在CPU和GPU上都可以跑,优先在GPU上跑
train_gpu_1 整体完整代码:
import torch
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from torch import nn
from torch.utils.data import DataLoader# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),download=True)# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建网络模型class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4,64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return xtudui = Tudui()
if torch.cuda.is_available():tudui = tudui.cuda()# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
if torch.cuda.is_available():loss_fn = loss_fn.cuda()
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) # SGD 随机梯度下降# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):print("----------第{}轮训练开始-----------".format(i + 1)) # i从0-9# 训练步骤开始for data in train_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = tudui(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad() # 首先要梯度清零loss.backward() # 反向传播得到每一个参数节点的梯度optimizer.step() # 对参数进行优化total_train_step += 1if total_train_step % 100 == 0: # 逢百才打印记录print("训练次数:{},loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始tudui.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad(): # 无梯度,不进行调优for data in test_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = tudui(imgs)loss = loss_fn(outputs, targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字# 求整体测试数据集上的误差或正确率accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)total_test_step += 1torch.save(tudui, "tudui_{}.pth".format(i)) # 每一轮保存一个结果print("模型已保存")writer.close()2. 比较CPU/GPU训练时间
为了比较时间,引入 time 这个 package
(1)对于CPU
1.引用 time 的 package

2.记录开始时间

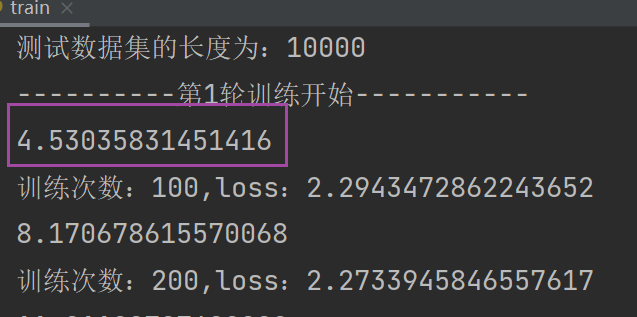
3. 记录截至时间并输出所用时间

4. 运行 train.py,可以看到它的运行时间
(2) 对于GPU
与上面相同的步骤(相同地方引入time)运行后结果如下:

时间竟然比CPU长(我不理解呜呜呜!)
(3)查看GPU信息
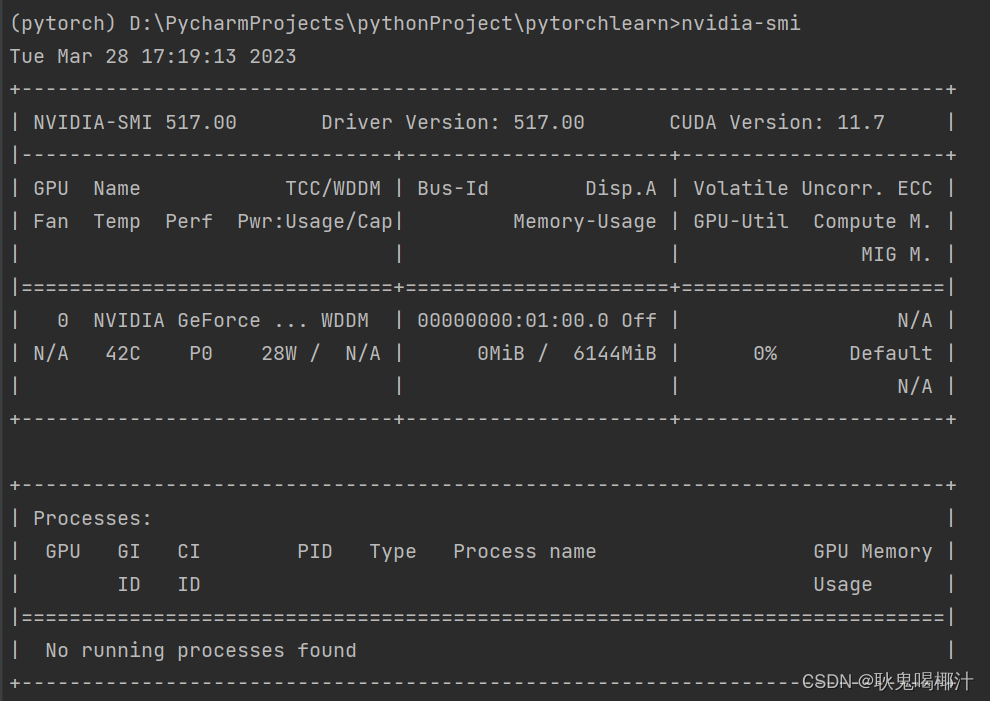
在 Terminal 里输入:
nvidia-smi会出现一些GPU的信息
3.Google Colab
Google 为我们提供了一个免费的GPU,默认提供的环境当中就有Pytorch(使用过程需要魔法tz哦)
colab 网站:https://colab.research.google.com/
进来时候新建笔记本:
输入代码运行后我们发现现在还不能使用GPU:

1.如何在Google Colab使用GPU?
修改 ——> 笔记本设置 ——> 硬件加速器选择GPU(每周免费使用30h)
(使用GPU后会重新启动环境)
设置后对比:
将 train_gpu_1.py 代码复制进去运行,速度很快,结果如下:

查看GPU配置
在 Google Colab 上运行 terminal 中运行的东西,在语句前加 !(感叹号)

五、利用GPU训练(一)
1.第二种使用GPU训练的方式(更常用)

以下两种写法对于单显卡来说等价:
device = torch.device("cuda")device = torch.device("cuda:0")1.定义训练的设备
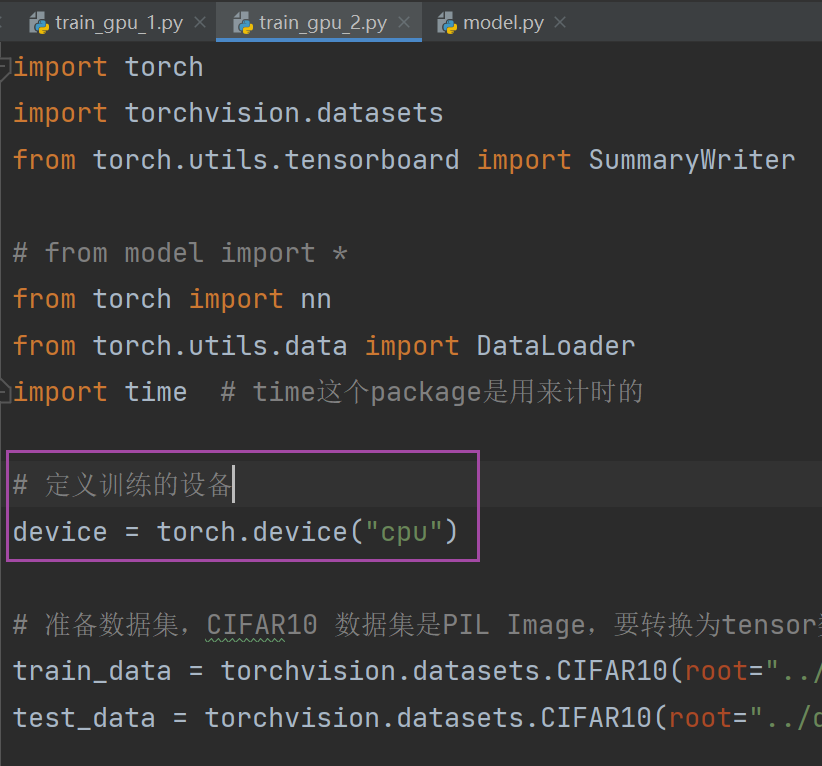
(通过这个变量可以控制是在CPU上运行还是GPU(改成 "cuda" 或 "cuda:0" )上运行)
2.模型
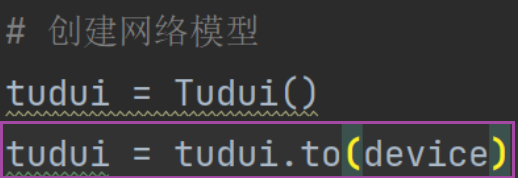
(这里第二句可以不用再赋值给 tudui,直接 tudui.to(device) 也可以)
3.损失函数

4.输入输出数据(必须要赋值)
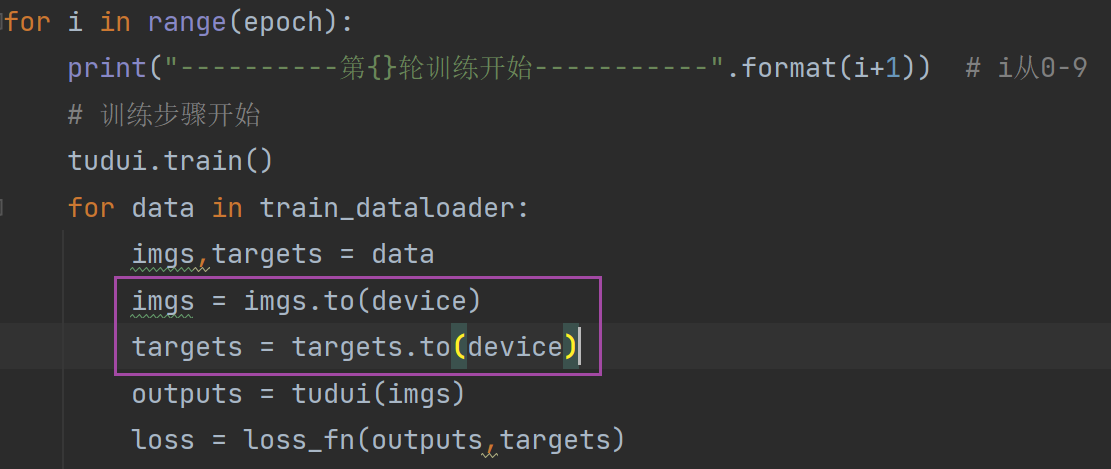

网络模型、损失函数都不需要另外赋值,直接 .to(device) 就可以
但是数据(图片、标注)需要另外转移之后再重新赋值给变量
语法糖(一种语法的简写),程序在 CPU 或 GPU/cuda 环境下都能运行:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")(六)完整的模型验证(测试、demo)套路
核心:利用已经训练好的模型,给它提供输入进行测试(类似之前案例中测试集的测试部分)

pytorch-CycleGAN-and-pix2pix
1.示例 1
Resize():

随便在网络上找图片,通过 Resize() 使图片符合模型
# 如何从test.py文件去找到dog文件(相对路径)
import torch
import torchvision.transforms
from PIL import Image
from torch import nnimage_path = "../imgs/dog.png" # 或右键-> Copy Path-> Absolute Path(绝对路径)
# 读取图片(PIL Image),再用ToTensor进行转换
image = Image.open(image_path) # 现在的image是PIL类型
print(image) # <PIL.PngImagePlugin.PngImageFile image mode=RGB size=430x247 at 0x1DF29D33AF0># image = image.convert('RGB')
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片# 该image大小为430x247,网络模型的输入只能是32x32,进行一个Resize()
# Compose():把transforms几个变换联立在一起
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), # 32x32大小的PIL Imagetorchvision.transforms.ToTensor()]) # 转为Tensor数据类型
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])# 加载网络模型(之前采用的是第一种方式保存,故需要采用第一种方式加载)
# 首先搭建神经网络(10分类网络)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# 把网络放到序列中self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), # 展平nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,x):x = self.model(x)return x
# 然后加载网络模型
model = torch.load("tudui_0.pth") # 因为test.py和tudui_0.pth在同一个层级下,所以地址可以直接写
print(model)output = model(image)
print(output)运行会报错,报错提示如下:
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [32, 3, 5, 5], but got 3-dimensional input of size [3, 32, 32] instead
原因:要求是四维的输入 [batch_size,channel,length,width],但是获得的图片是三维的 —— 图片没有指定 batch_size(网络训练过程中是需要 batch_size 的,而图片输入是三维的,需要reshape() 一下)
解决:torch.reshape() 方法
在上述代码后面加上:
image = torch.reshape(image,(1,3,32,32))
model.eval() # 模型转化为测试类型
with torch.no_grad(): # 节约内存和性能output = model(image)
print(output)运行结果:

1.3220 概率最大,预测的是第六类
print(output.argmax(1))CIFAR10 对应的真实类别:

怎么找到?
第六类对应的是 frog(青蛙)
预测错误的原因可能是训练次数不够多,在 Google Colab 里,将训练轮数 epoch 改为 30 次,完整代码(train.py):
import torch
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter# from model import *
from torch import nn
from torch.utils.data import DataLoader
import time # time这个package是用来计时的# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
device = torch.device("cuda")
print(device)
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化,把format中的变量替换{}
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 搭建神经网络(10分类网络)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# 把网络放到序列中self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), # 展平nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,x):x = self.model(x)return x# 创建网络模型
tudui = Tudui()
tudui.to(device)# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
loss_fn.to(device)# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 30 # 训练轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time() # 记录下此时的时间,赋值给开始时间for i in range(epoch):print("----------第{}轮训练开始-----------".format(i+1)) # i从0-9# 训练步骤开始tudui.train()for data in train_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs,targets)# 优化器优化模型optimizer.zero_grad() # 首先要梯度清零loss.backward() # 反向传播得到每一个参数节点的梯度optimizer.step() # 对参数进行优化total_train_step += 1if total_train_step % 100 ==0: # 逢百才打印记录end_time = time.time()print(end_time - start_time) # 第一次训练100次所花费的时间print("训练次数:{},loss:{}".format(total_train_step,loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始tudui.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad(): # 无梯度,不进行调优for data in test_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型# 求整体测试数据集上的误差或正确率total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size)) # 正确率为预测对的个数除以测试集长度writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_test_loss,total_test_step,total_test_step)total_test_step += 1torch.save(tudui,"tudui_{}_gpu.pth".format(i)) # 每一轮保存一个结果print("模型已保存")writer.close()运行结果:
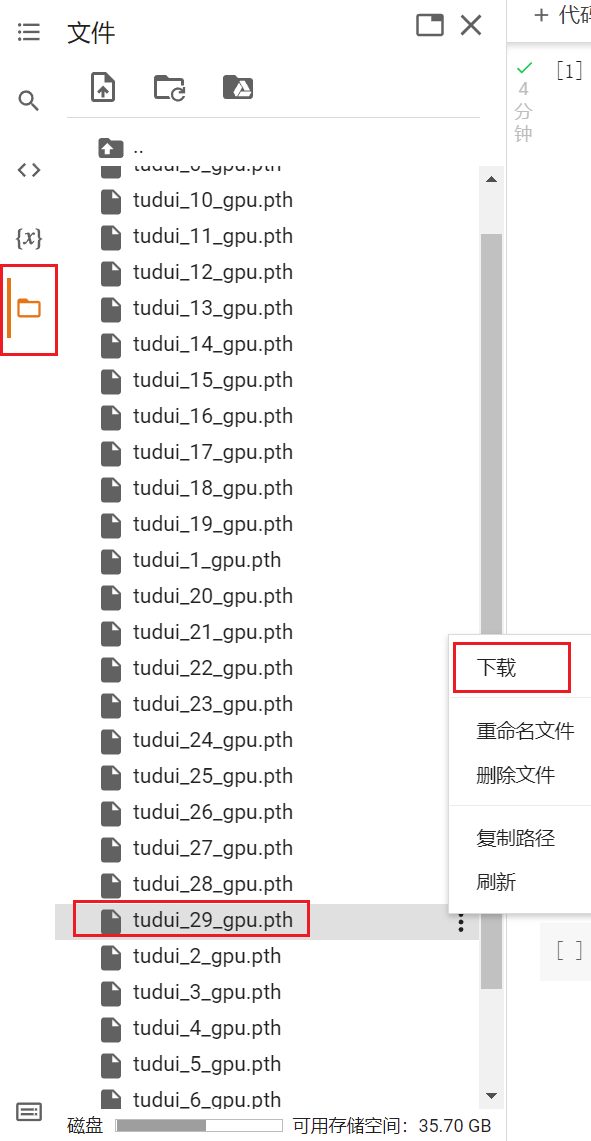
下载后复制到 PyCharm 中 Learn_Torch 的 src 文件夹下,然后将之前 test.py 中的路径修改为:
model = torch.load("tudui_29_gpu.pth")运行后报错,报错提示:
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor原因:采用GPU训练的模型,在CPU上加载,要从GPU上映射到CPU上(在不同环境中加载已经训练好的模型,需要经过映射)
解决:
model = torch.load("tudui_29_gpu.pth",map_location=torch.device('cpu'))test.py(把训练模型运用到实际环境中)完整代码
# 如何从test.py文件去找到dog文件(相对路径)
import torch
import torchvision.transforms
from PIL import Image
from torch import nnimage_path = "../imgs/airplane.png" # 或右键-> Copy Path-> Absolute Path(绝对路径)
# 读取图片(PIL Image),再用ToTensor进行转换
image = Image.open(image_path) # 现在的image是PIL类型
print(image) # <PIL.PngImagePlugin.PngImageFile image mode=RGB size=430x247 at 0x1DF29D33AF0># image = image.convert('RGB')
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片# 该image大小为430x247,网络模型的输入只能是32x32,进行一个Resize()
# Compose():把transforms几个变换联立在一起
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), # 32x32大小的PIL Imagetorchvision.transforms.ToTensor()]) # 转为Tensor数据类型
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])# 加载网络模型(之前采用的是第一种方式保存,故需要采用第一种方式加载)
# 首先搭建神经网络(10分类网络)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# 把网络放到序列中self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), # 展平nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,x):x = self.model(x)return x
# 然后加载网络模型
model = torch.load("tudui_29_gpu.pth",map_location=torch.device('cpu')) # 因为test.py和tudui_0.pth在同一个层级下,所以地址可以直接写
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval() # 模型转化为测试类型
with torch.no_grad():output = model(image)
print(output)
print(output.argmax(1))2.示例二
再以飞机的图片为例(airplane.png 保存在 imgs 文件夹里)
# 如何从test.py文件去找到dog文件(相对路径)
import torch
import torchvision.transforms
from PIL import Image
from torch import nnimage_path = "../imgs/airplane.png" # 或右键-> Copy Path-> Absolute Path(绝对路径)
# 读取图片(PIL Image),再用ToTensor进行转换
image = Image.open(image_path) # 现在的image是PIL类型
print(image) # <PIL.PngImagePlugin.PngImageFile image mode=RGB size=430x247 at 0x1DF29D33AF0># image = image.convert('RGB')
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片# 该image大小为430x247,网络模型的输入只能是32x32,进行一个Resize()
# Compose():把transforms几个变换联立在一起
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), # 32x32大小的PIL Imagetorchvision.transforms.ToTensor()]) # 转为Tensor数据类型
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])# 加载网络模型(之前采用的是第一种方式保存,故需要采用第一种方式加载)
# 首先搭建神经网络(10分类网络)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# 把网络放到序列中self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), # 展平nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,x):x = self.model(x)return x
# 然后加载网络模型
model = torch.load("tudui_29_gpu.pth",map_location=torch.device('cpu')) # 因为test.py和tudui_0.pth在同一个层级下,所以地址可以直接写
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval() # 模型转化为测试类型
with torch.no_grad():output = model(image)
print(output)
print(output.argmax(1)) # 把输出转换为一种利于解读的方式运行结果:
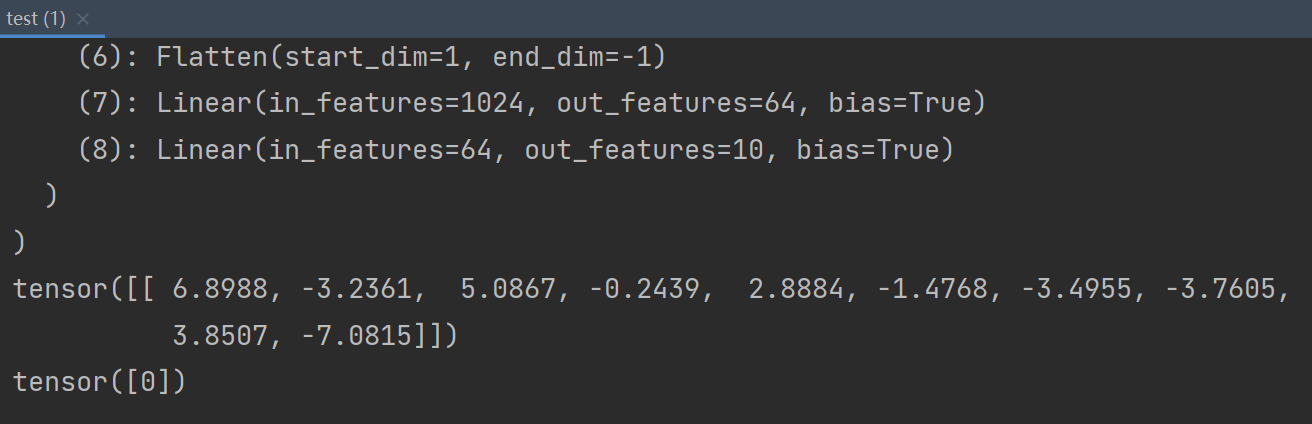
第 0 类就是 airplane,预测正确
注意:
model.eval() # 模型转化为测试类型
with torch.no_grad():(这两行不写也可以,但为了养成良好的代码习惯,最好写上。如果网络模型中正好有 Dropout 或 BatchNorm 时,不写的话预测就会有问题)
(七)、看看开源项目
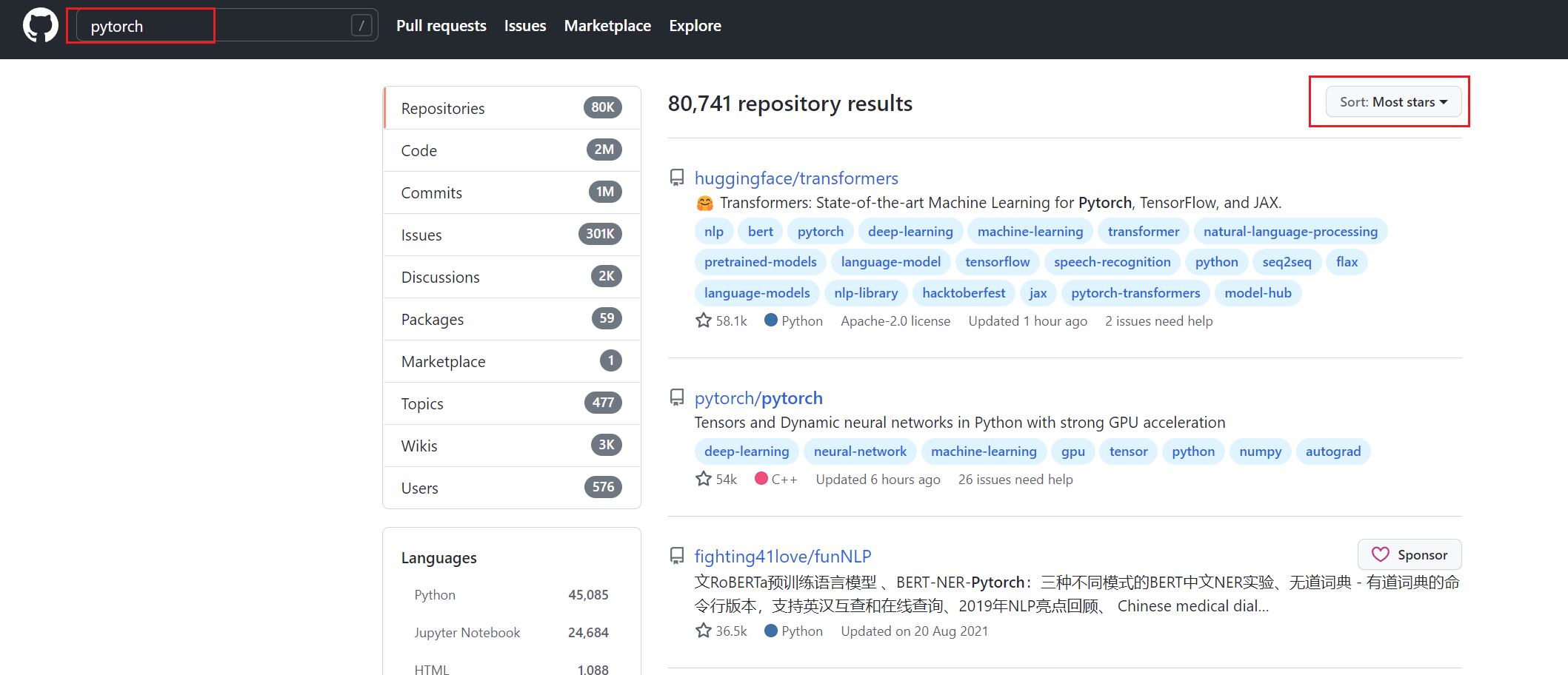
网站地址:GitHub - junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch
README.md
先读 README.md(怎么安装、注意事项)
train.py
"""General-purpose training script for image-to-image translation.
This script works for various models (with option '--model': e.g., pix2pix, cyclegan, colorization) and
different datasets (with option '--dataset_mode': e.g., aligned, unaligned, single, colorization).
You need to specify the dataset ('--dataroot'), experiment name ('--name'), and model ('--model').
It first creates model, dataset, and visualizer given the option.
It then does standard network training. During the training, it also visualize/save the images, print/save the loss plot, and save models.
The script supports continue/resume training. Use '--continue_train' to resume your previous training.
Example:Train a CycleGAN model:python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_ganTrain a pix2pix model:python train.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoA
See options/base_options.py and options/train_options.py for more training options.
See training and test tips at: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/docs/tips.md
See frequently asked questions at: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/docs/qa.md
"""
import time
from options.train_options import TrainOptions
from data import create_dataset
from models import create_model
from util.visualizer import Visualizerif __name__ == '__main__':opt = TrainOptions().parse() # get training optionsdataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other optionsdataset_size = len(dataset) # get the number of images in the dataset.print('The number of training images = %d' % dataset_size)model = create_model(opt) # create a model given opt.model and other optionsmodel.setup(opt) # regular setup: load and print networks; create schedulersvisualizer = Visualizer(opt) # create a visualizer that display/save images and plotstotal_iters = 0 # the total number of training iterationsfor epoch in range(opt.epoch_count, opt.n_epochs + opt.n_epochs_decay + 1): # outer loop for different epochs; we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>epoch_start_time = time.time() # timer for entire epochiter_data_time = time.time() # timer for data loading per iterationepoch_iter = 0 # the number of training iterations in current epoch, reset to 0 every epochvisualizer.reset() # reset the visualizer: make sure it saves the results to HTML at least once every epochmodel.update_learning_rate() # update learning rates in the beginning of every epoch.for i, data in enumerate(dataset): # inner loop within one epochiter_start_time = time.time() # timer for computation per iterationif total_iters % opt.print_freq == 0:t_data = iter_start_time - iter_data_timetotal_iters += opt.batch_sizeepoch_iter += opt.batch_sizemodel.set_input(data) # unpack data from dataset and apply preprocessingmodel.optimize_parameters() # calculate loss functions, get gradients, update network weightsif total_iters % opt.display_freq == 0: # display images on visdom and save images to a HTML filesave_result = total_iters % opt.update_html_freq == 0model.compute_visuals()visualizer.display_current_results(model.get_current_visuals(), epoch, save_result)if total_iters % opt.print_freq == 0: # print training losses and save logging information to the disklosses = model.get_current_losses()t_comp = (time.time() - iter_start_time) / opt.batch_sizevisualizer.print_current_losses(epoch, epoch_iter, losses, t_comp, t_data)if opt.display_id > 0:visualizer.plot_current_losses(epoch, float(epoch_iter) / dataset_size, losses)if total_iters % opt.save_latest_freq == 0: # cache our latest model every <save_latest_freq> iterationsprint('saving the latest model (epoch %d, total_iters %d)' % (epoch, total_iters))save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'model.save_networks(save_suffix)iter_data_time = time.time()if epoch % opt.save_epoch_freq == 0: # cache our model every <save_epoch_freq> epochsprint('saving the model at the end of epoch %d, iters %d' % (epoch, total_iters))model.save_networks('latest')model.save_networks(epoch)print('End of epoch %d / %d \t Time Taken: %d sec' % (epoch, opt.n_epochs + opt.n_epochs_decay, time.time() - epoch_start_time))
训练参数设置
from .base_options import BaseOptionsclass TrainOptions(BaseOptions):"""This class includes training options.It also includes shared options defined in BaseOptions."""def initialize(self, parser):parser = BaseOptions.initialize(self, parser)# visdom and HTML visualization parametersparser.add_argument('--display_freq', type=int, default=400, help='frequency of showing training results on screen')parser.add_argument('--display_ncols', type=int, default=4, help='if positive, display all images in a single visdom web panel with certain number of images per row.')parser.add_argument('--display_id', type=int, default=1, help='window id of the web display')parser.add_argument('--display_server', type=str, default="http://localhost", help='visdom server of the web display')parser.add_argument('--display_env', type=str, default='main', help='visdom display environment name (default is "main")')parser.add_argument('--display_port', type=int, default=8097, help='visdom port of the web display')parser.add_argument('--update_html_freq', type=int, default=1000, help='frequency of saving training results to html')parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')parser.add_argument('--no_html', action='store_true', help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')# network saving and loading parametersparser.add_argument('--save_latest_freq', type=int, default=5000, help='frequency of saving the latest results')parser.add_argument('--save_epoch_freq', type=int, default=5, help='frequency of saving checkpoints at the end of epochs')parser.add_argument('--save_by_iter', action='store_true', help='whether saves model by iteration')parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')parser.add_argument('--epoch_count', type=int, default=1, help='the starting epoch count, we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>, ...')parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')# training parametersparser.add_argument('--n_epochs', type=int, default=100, help='number of epochs with the initial learning rate')parser.add_argument('--n_epochs_decay', type=int, default=100, help='number of epochs to linearly decay learning rate to zero')parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')parser.add_argument('--gan_mode', type=str, default='lsgan', help='the type of GAN objective. [vanilla| lsgan | wgangp]. vanilla GAN loss is the cross-entropy objective used in the original GAN paper.')parser.add_argument('--pool_size', type=int, default=50, help='the size of image buffer that stores previously generated images')parser.add_argument('--lr_policy', type=str, default='linear', help='learning rate policy. [linear | step | plateau | cosine]')parser.add_argument('--lr_decay_iters', type=int, default=50, help='multiply by a gamma every lr_decay_iters iterations')self.isTrain = Truereturn parser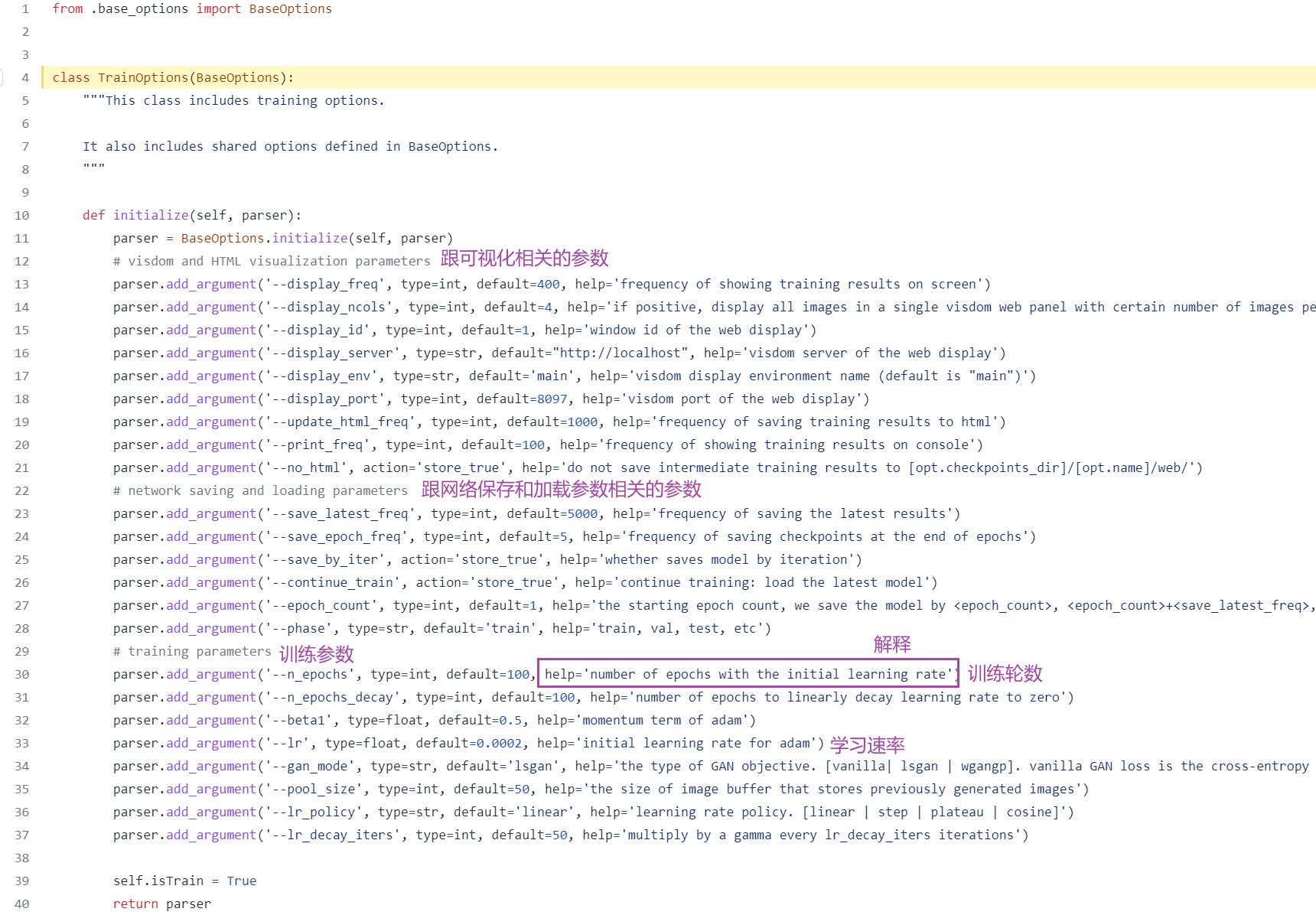
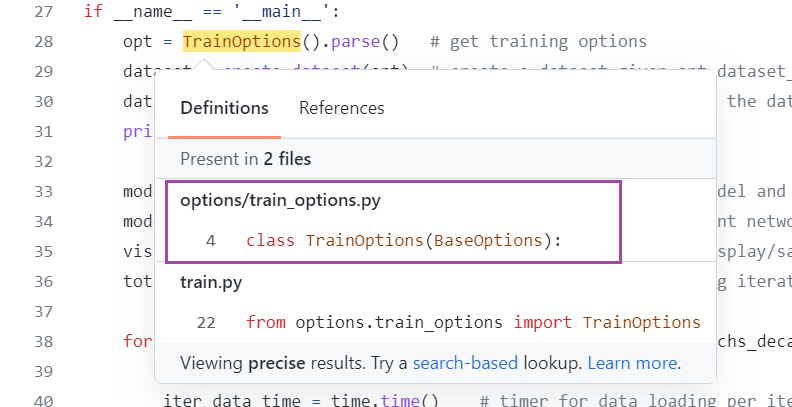
没有dataroot
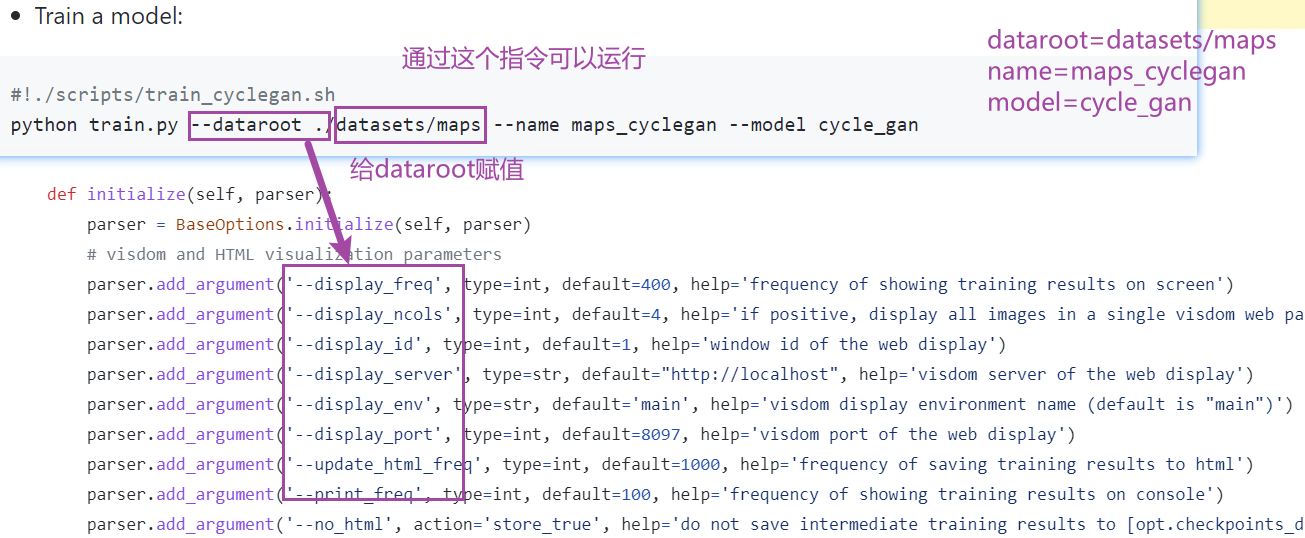
点进其继承的父类查看,可以看到有dataroot

下载代码用 PyCharm 打开后,查看代码里有没有 required=True,若有,删掉 required=True ,加一个默认值 default="./dataset/maps" ,就可以在 PyCharm 里右键运行了
即找到所有 required=True 的参数,将它删去并添加上默认值default 。
这篇课程的学习和总结到这里就结束啦,如果有什么问题可以在评论区留言呀~
如果帮助到大家,可以一键三连+关注支持下~
学习系列笔记(已完结):
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(一)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(二)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(三)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(四)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)_耿鬼喝椰汁的博客-CSDN博客
相关文章:
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)
此文章为【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)包括:完整的模型训练套路(一)、完整的模型训练套路(二)、完整的模型训练套路(三)、利用GPU训练(…...

JUC篇:CopyOnWriteArrayList的应用与原理
系列文章目录 JUC篇:volatile可见性的实现原理 JUC篇:synchronized的应用和实现原理 JUC篇:用Java实现一个简单的线程池 JUC篇:java中的线程池 JUC篇:ThreadLocal的应用与原理 JUC篇:Java中的并发工具类 文…...
【总结】爬虫1-requests
爬虫1-requests 1. requests的基本用法 requests需要提前导入,才能使用 1.1 请求网络数据:requests.get(请求地址) response requests.get(https://cd.zu.ke.com/zufang)1.2 设置解码方法(罗马的是需要设置 - 一定要在获取请求结果之前设…...
基于springboot实现学生综合成绩测评系统【源码】分享
基于springboot实现学生综合成绩测评系统演示开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包…...
uniapp初体验———uView组件库的使用与钉钉小程序的运行
这周学长给了我一个校企合作的项目,要求是用uniapp开发,最终打包成钉钉小程序,不过我并不会uniapp,也是学了一段时间,开始写项目,中间也遇到过很多问题,比如开发者工具还有如何运行到开发者工具…...

初始Go语言2【标识符与关键字,操作符与表达式,变量、常量、字面量,变量作用域,注释与godoc】
文章目录Go语言基础语法标识符与关键字操作符与表达式变量、常量、字面量变量类型变量声明变量初始化常量字面量变量作用域注释与godoc注释的形式注释的位置go docgodocGo语言基础语法 标识符与关键字 go变量、常量、自定义类型、包、函数的命名方式必须遵循以下规则ÿ…...

Vue计算属性详解
目录 编辑 1、什么是计算属性 2、为什么要有计算属性 1. 为什么不是使用模板语法 2. 为什么不是使用method对于复杂逻辑 3. 什么时候要用计算属性 4. 定义计算属性fullName 5. 计算属性的配置项 1、什么是计算属性 写在computed对象中的属性,本质上是…...

rk3568-AD按键驱动调试
rk3568-AD按键驱动调试转载请备注:daisy.skye的博客_CSDN博客-Qt,嵌入式,Linux领域博主dts设备树节点 /rk356x_linux_220118/kernel/arch/arm64/boot/dts/rockchip/rk3568.dtsi 板级设备树dts /home/scooper/jkD7/20221221/ido_evb3568_v2_android11_sdk/kernel/…...
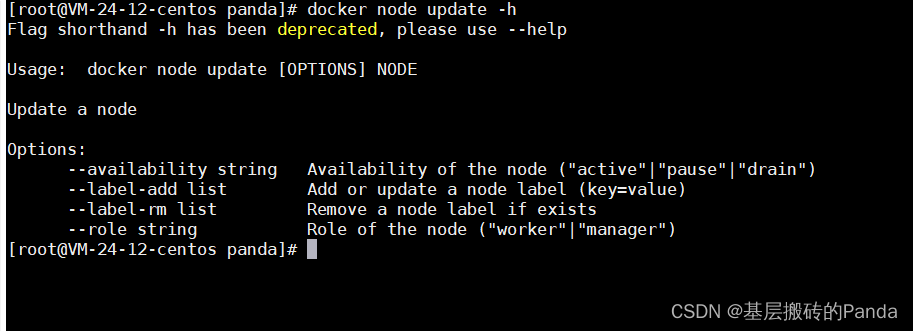
Docker三剑客之swarm
一、什么是docker swarm Swarm是Docker公司推出的用来管理docker集群的平台,几乎全部用GO语言来完成的开发的,代码开源在https://github.com/docker/swarm, 它是将一群Docker宿主机变成一个单一的虚拟主机,Swarm使用标准的Docker…...
Lucene Solr Elasticsearch三者之间的关系,怎么选?
Lucene简介: Lucene主要用于构建文本搜索应用程序,包括Web搜索引擎、桌面搜索工具和商业应用程序。它提供了诸如单词分析、查询解析、搜索结果排序等功能,可以轻松地在大量文档中快速搜索和查找相关信息。 Lucene具有以下特点: …...

为你的网站加上Loading等待加载效果吧 | Loading页面加载添加教程
为你的网站加上Loading等待加载效果吧 | Loading页面加载添加教程 效果图 : 教程开始 新建一个loading样式css 将以下代码放进去 然后引用这个文件 code #Loadanimation{ background-color:#fff; height:100%; width:100%; position:fixed; z-index:1; ma…...
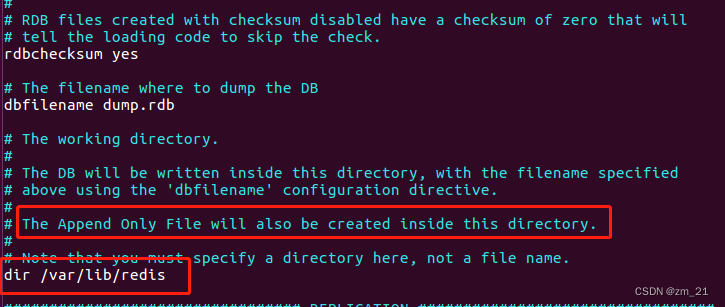
Redis安装和配置
网上有海量的Redis文章,写的都很详细。这里就是简单记录一下自己查aof问题过程中遇到的问题,主要是aof文件所在目录在redis.conf里的位置 1。在ubuntu16上安装Redis sudo apt-get install -y redis-server 2。修改redis配置 sudo vim /etc/redis/re…...

MobTech|如何使用秒验
什么是秒验? 秒验是MobTech公司提供的一款实现一键验证功能的产品,从根源上降低企业验证成本,有效提高拉新转化率,降低因验证带来的流失率,3秒完成手机号验证(一键登录)。 秒验主要整合了三大…...

CSS实现自动分页打印同时每页保留重复的自定义内容
当需要打印的内容过长时系统会产生自动分割页面,造成样式不太美观。使用CSS的 media print 结合 <table> 可以实现对分页样式的可控。效果如下: 假设有50条数据,打印时系统会自动分成两页,同时每页保留自定义的header和foo…...

基于prometheus的监控告警怎么实现?
基于 Prometheus 的监控告警实现一般需要以下几个步骤: 安装和配置 Prometheus:安装 Prometheus 并配置好需要监控的目标。可以使用 Prometheus 的配置文件(prometheus.yml)来指定需要监控的目标,例如服务、主机、容器…...

2007年4月全国计算机等级考试二级JAVA笔试试题及答案
2007年4月全国计算机等级考试二级JAVA笔试试题及答案 一、选择题 (1)已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为 A.GEDHFBCA B.DGEBHFCA C.ABCDEFGH D.…...
)
灌水玩玩 ChatGPT AIGC生成的有栈协同程序实现(例子)
CO: 你是一名 C/C 高级软件工程师。 请使用 stackful 协程,实现一个 Sleep 随眠的协同程序,注意并非 stackless 协程,不允许使用 C/C 17 以上的语言标准实现,允许使用 boost 基础框架类库。 ChatGPT: 好的…...

【砝码称重】暴力DFS(一半分)+ dp(可AC)
题目描述: 题目分析: 我也没有完全搞太明白,简单说说我的理解 1.dp【i】【j】表示前 i 个砝码,是否可以称出来重量为 j 的物品,如果可以的话,值为1,不可以 为0; 2.针对当前第 i 个…...
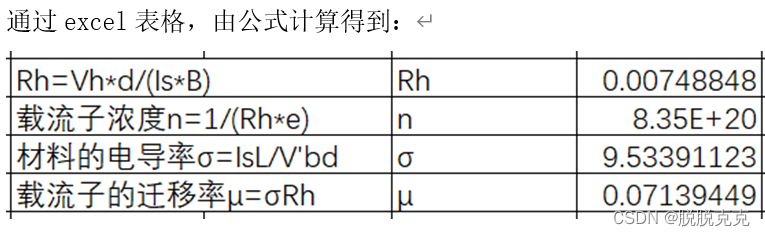
科大奥瑞物理实验——霍尔效应实验
实验名称:霍尔效应实验 1. 实验目的: 了解霍尔效应测量磁场的原理和方法;观察磁电效应现象;学会用霍尔元件测量磁场及元件参数的基本方法。 2. 实验器材: QS-H型霍尔效应实验仪 磁针 QS-H型霍尔效应测试仪 双刀开关…...
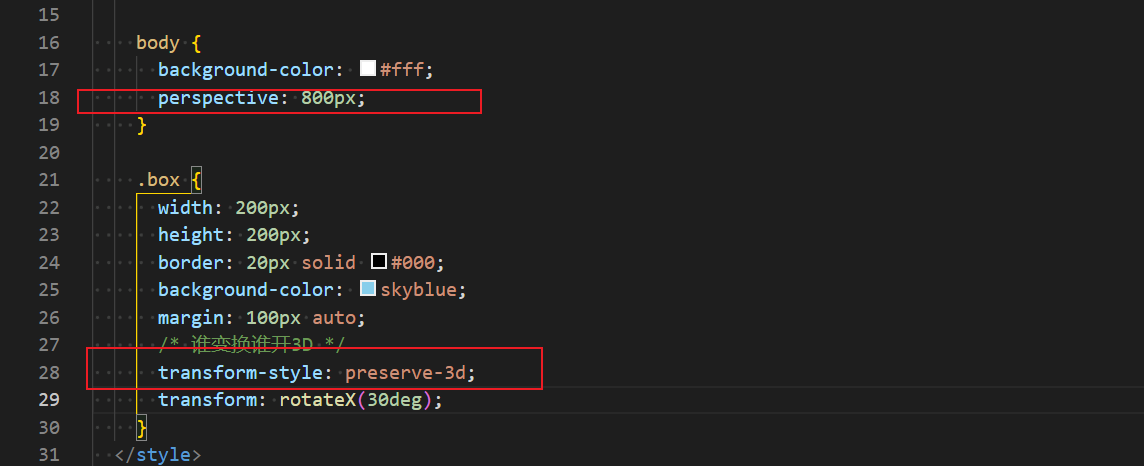
2023_深入学习HTML5
H5 基于html5和 css3和一部分JS API 结合的开发平台(环境) 语义化标签 header : 表示头部,块级元素 footer : 表示底部,块级元素 section :区块 nav : 表示导航链接 aside : 表示侧边栏 output &am…...

抖音本地生活运营4大核心秘籍
最近参加了一场 抖音本地生活全域运营实战特训营,两天一夜,从理论到实操。把最核心的 4 个模块整理出来,分享给想做本地生活的技术/运营同学。一、账号主页:让抖音自动帮你获客抖音主页就是你的线上门头。很多商家挂个风景图&…...

FastbootEnhance:一款强大的Windows平台Fastboot工具箱与Payload提取器
FastbootEnhance:一款强大的Windows平台Fastboot工具箱与Payload提取器 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 你是否曾经为A…...

Circuit Playground Express 硬件解析与四步编程实战:从创客入门到项目开发
1. 项目概述:为什么选择 Circuit Playground Express 作为创客起点 如果你对硬件编程、物联网或者智能设备感兴趣,但又被 Arduino Uno 上密密麻麻的杜邦线和面包板劝退,或者觉得树莓派 Zero 的 Linux 系统门槛太高,那么 Adafruit…...

在自动化部署流程中集成 TaoToken 大模型 API 调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化部署流程中集成 TaoToken 大模型 API 调用 将大模型能力融入自动化部署流程,正成为提升 DevOps 效率的新范式。…...

QMCDump终极指南:3分钟学会QQ音乐加密文件转换,解锁你的音乐自由
QMCDump终极指南:3分钟学会QQ音乐加密文件转换,解锁你的音乐自由 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/…...

从PyAutoGUI到OpenClaw:构建健壮桌面自动化的状态驱动技能库
1. 项目概述:当自动化脚本拥有“鹰爪”最近在GitHub上看到一个挺有意思的项目,叫Ikaros-521/openclaw-pyautogui-skill。光看名字,就透着一股“硬核”和“实用”的气息。Ikaros(伊卡洛斯)是希腊神话里那位用蜡和羽毛造…...

通用 Agent 与领域 Agent 的架构差异
从GPT-4o到AI程序员助手:通用Agent与领域Agent的核心架构差异及选型指南 摘要/引言 你有没有试过同时用两款截然不同的AI工具帮你干活?比如前一秒用GPT-4o对着一张写满Python报错的截图问“为什么我的分布式爬虫在Kubernetes集群里总是崩溃”,后一秒打开Cursor编辑器的AI助…...

终极指南:3分钟掌握Switch游戏安装的完整解决方案
终极指南:3分钟掌握Switch游戏安装的完整解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为Nintendo S…...

米尔MA35D1核心板512MB DDR升级:工业边缘计算性能跃迁与开发实战
1. 项目概述:MA35D1核心板512M DDR配置的发布意味着什么?最近,米尔电子发布了其基于新唐MA35D1处理器的核心板新配置——512MB DDR。这个消息在工业控制和边缘计算圈子里引起了不少讨论。对于很多正在评估或已经使用MA35D1方案的朋友来说&…...

嵌入式硬件设计中的“隐形保镖”:电压跟随电路如何让你的系统更稳定?
嵌入式硬件设计中的“隐形保镖”:电压跟随电路如何让你的系统更稳定? 在复杂的嵌入式系统中,信号链的完整性往往决定了整个产品的可靠性。想象一下,当你精心设计的传感器数据经过长距离传输后,最终到达MCU时却出现了严…...