华为MRS_HADOOP集群 beeline使用操作
背景
由于项目测试需要,计划在华为hadoop集群hive上创建大量表,并且每表植入10w数据,之前分享过如何快速构造hive大表,感兴趣的可以去找一下。本次是想要快速构造多表并载入一些数据。
因为之前同事在构造相关测试数据时由于创建过多默认textfile格式的测试表,导致存储过载,集群down掉。因而本次采用表为orc格式,通过对比下textfile格式,发现有一倍的存储消耗差距。orc的压缩格式ZLIB较SNAPPY压缩率更高一些。因此采用orc的zlib压缩。
那么如何操作便捷生成大量表呢?原计划有如下两种方式:
方式一 HUE创建复制表
该方式借助hue的hivesql执行窗口,进行单表的创建和多表的复制创建。
首先创建一个orc表
`CREATE TABLE `table_hive_xntest1`(`hylbz` string, `hgjdqlbz` bigint, `hsssqlbz` binary, `cjhjywid` boolean, `cchjywid` decimal(10,0), `gxsjd` date, `sg` string, `zp` string, `csrq` timestamp, `cssj` int, `csdgjdq` int, `csdssxq` double, `csdxz` varchar(200), `dhhm` int, `jhryxm` int, `jgxz` int, `jhryzjzl` int, `jhryzjhm` int, `jhrywwx` int, `jhrywwm` int, `jhrylxdh` int, `jhrezjzl` int, `jhrezjhm` int, `jhrewwx` int, `jhrewwm` int, `jhrelxdh` int, `fqzjzl` int, `fqzjhm` int, `fqwwx` int, `zpid` int, `mlpid` int, `ryid` int, `mlpnbid` int, `yxqxqsrq` string, `yxqxjzrq` string, `qfjgint` varchar(20000))ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS orc tblproperties ("orc.compress"="ZLIB");
然后通过载入文件的方式加载入数据到表空间下(hue、hdfs-webui或者hdfs命令行均可)。
再在hue的hivesql命令行中通过批量复制创建表的方式来创建表。
create table xntest_tb_new_1 as select * from table_hive_xntest1;

在这里插入图片描述
但是执行过程中发现速度远不及预期,单表复制新建耗时约1.5s,但是批量sql执行后,越来越慢,目标需要创建上万数据表,因此速度上不满足使用需求。因此计划使用方式二
方式二 beeline执行hivesql脚本
之前使用过HDP版本的hive和beeline命令,直接在节点服务器上执行命令即可。但是华为集群有其特殊之处。登录节点服务器后。beeline查无此命令,hive命令也是如此。

后面通过请教开发得知,华为集群采kerberos认证方式,需要先安装hive客户端并在每次执行beeline前进行kerberos认证(类似登录)且仅在当前ssh会话中有效,然后再执行相关命令即可。下面介绍下如何安装hive客户端并进行kerberos认证。
第一步、登录华为MRS,下载用户登录凭据,用户需要有hive相关权限。

第二步 下载完整的hive客户端。平台类型和hadoop节点上的物理架构一致,hive客户端建议安装在集群节点上()安装在集群节点外可能需要修改一些ip映射满足host访问)
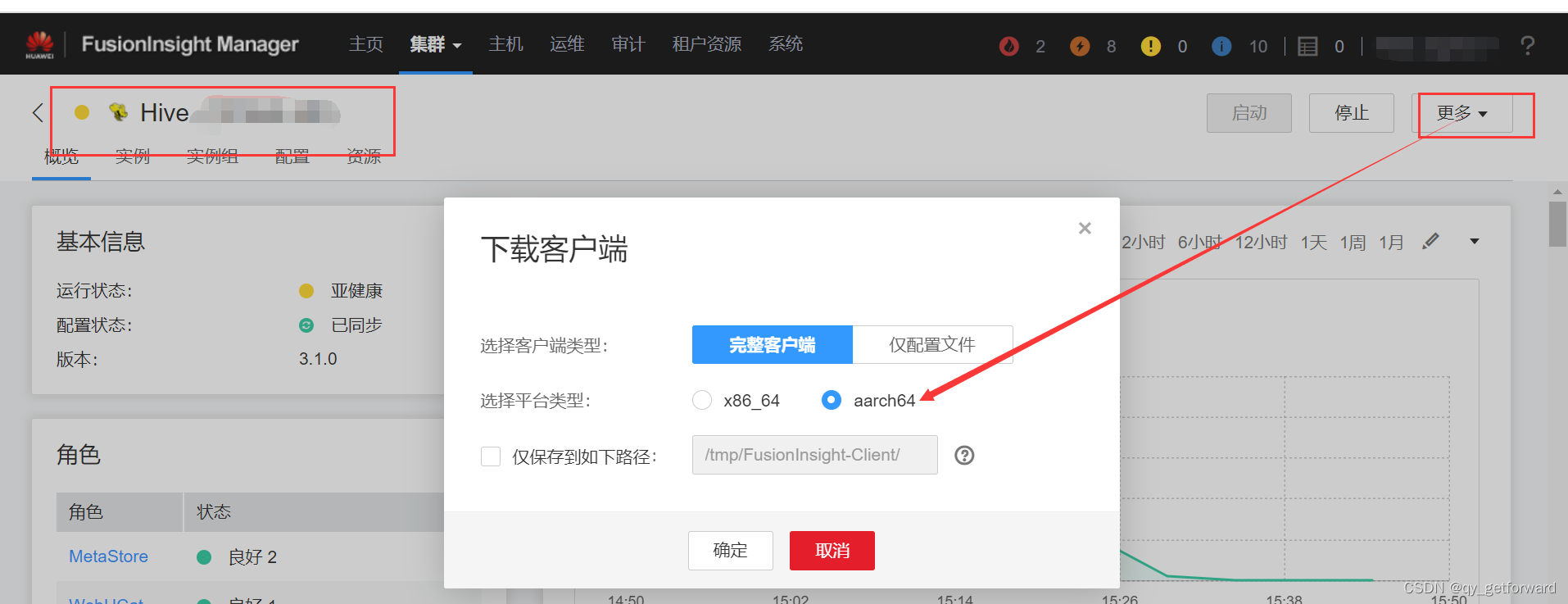
第三步 上传前两步文件到节点服务器并解压
进入hive客户端解压目录内执行安装命令,命令行参数为安装的hive客户端的路径,会自动创建
[root@HD01 FusionInsight_Cluster_1_Hive_ClientConfig]# ./install.sh /opt/hiveclient
安装成功后进入安装目录内执行环境变量初始化:
[root@HD01 hiveclient]# source bigdata_env ```到这里beeline命令已经可以执行了,但是因为没有完成认证,是无法操作hive的。
还需要执行kinit命令,使用第一步下载的认证凭据进行认证。命令如下:
kinit -kt youpath/user.keytab you_hw_username
认证完成之后,直接beeline命令即可访问执行hivesql了。通过将批量执行复制创建表的hivesql,全部存储到一个文件中去,然后beeline -f hivesql.file 即可,命令如下:
nohup beeline -f ./tc_3w.sql &
以上命令将执行进程放到后台执行,进度状态查看当前所在路径下的nohup.out实时打印输出即可。
通过查看nohup输出,基本2s复制创建完成一个表,速度基本满足需要,后台运行等待完成即可。
相关文章:
华为MRS_HADOOP集群 beeline使用操作
背景 由于项目测试需要,计划在华为hadoop集群hive上创建大量表,并且每表植入10w数据,之前分享过如何快速构造hive大表,感兴趣的可以去找一下。本次是想要快速构造多表并载入一些数据。 因为之前同事在构造相关测试数据时由于创建…...
PCB模块化设计10——PCI-E高速PCB布局布线设计规范
目录PCB模块化设计10——PCI-E高速PCB布局布线设计规范1、PCI-E管脚定义2、PCI-E叠层和参考平面3、 PCB设计指南1、阻抗要求2、线宽线距3、长度匹配4、走线弯曲角度5、测试点、过孔、焊盘6、AC去耦电容放置方法7、金手指和连接器的注意事项8、其他的注意事项PCB模块化设计10——…...

Java简介
Java简介 Java是一种面向对象的编程语言,由Sun Microsystems于1995年发布。Java设计的初衷是为了开发可移植、高性能的应用程序。Java代码可以在不同的操作系统上运行,包括Windows、Linux、Mac等。 Java是一种广泛使用的编程语言,用于开发各…...

python框架有哪些,常用的python框架代码
Python的应用已经相当广泛了,可以做很多事情,而 Python本身就是一个应用程序,我们也可以说 Python是一个高级语言。由于 Python有很多包,所以我们不能把所有的 Python包都了解一下,也不能把所有的包都读一遍࿰…...

jsp设计简单的购物车应用案例
代码解释 <%request.setCharacterEncoding("UTF-8");if (request.getParameter("c1")!null)session.setAttribute("s1",request.getParameter("c1"));if (request.getParameter("c2")!null)session.setAttribute("…...
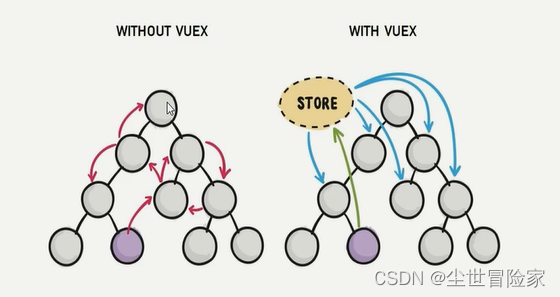
VueX是什么?好处?何时使用?
VueX相关1、VueX是什么?2、使用VueX统一管理状态的好处3、什么样的数据适合存储到Vuex中?1、VueX是什么? VueX是实现组件全局状态(数据)管理的一种机制,可以方便的实现组件之间数据的共享。 如果没有VueX…...
)
第2章 封装组件初级篇(上)
1.环境搭建,在 vite 脚手架基础上集成 typescript 和 element-plus https://cn.vitejs.dev/guide/ 以下是开发过程中过使用到的包和版本号:package.json {"name": "m-components","version": "0.0.0","…...

uniapp image标签图片跑偏终极解决办法
目录uniapp image 的mode常用属性aspectFit 缩放显示图片全部aspectFill 缩放填满容器,但是图片可能显示不全widthFix 以宽度为基准,等比缩放长heightFix 以高度为基准,等比缩放宽uniapp image 的mode常用属性 uniapp当中,在imag…...

SpringMVC的响应处理
文章目录一、传统同步业务数据响应1. 请求资源转发2. 请求资源重定向3. 响应模型数据4. 直接回写数据二、前后端分离异步业务数据响应一、传统同步业务数据响应 Spring响应数据给客户端,主要分为两大部分: ⚫ 传统同步方式:准备好模型数据&am…...

静态词向量预训练模型
1、神经网络语言模型从语言模型的角度来看,N 元语言模型存在明显的缺点。首先,模型容易受到数据稀疏的影响,一般需要对模型进行平滑处理;其次,无法对长度超过 N 的上下文依赖关系进行建模。神经网络语言模型 (Neural N…...
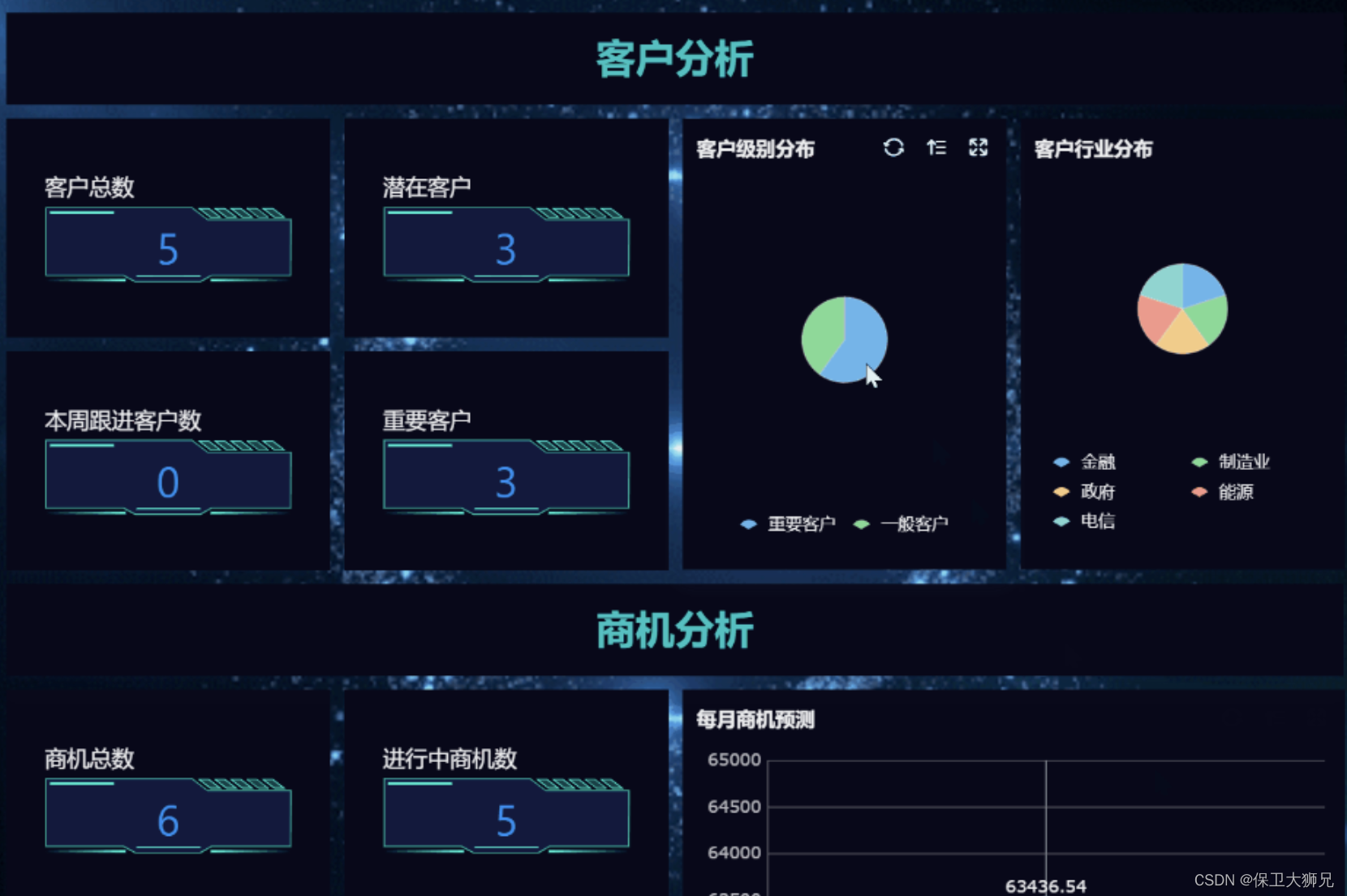
永久免费CRM怎么选?有什么好用的功能?
在当今商业环境下,企业经营者们都希望能够找到一种方法来提高自己的生产力和盈利能力。一种非常有效的方法就是实现客户关系管理(CRM)。然而,由于很多传统的CRM解决方案价格昂贵,小企业和创业公司很难承担。那么&#…...
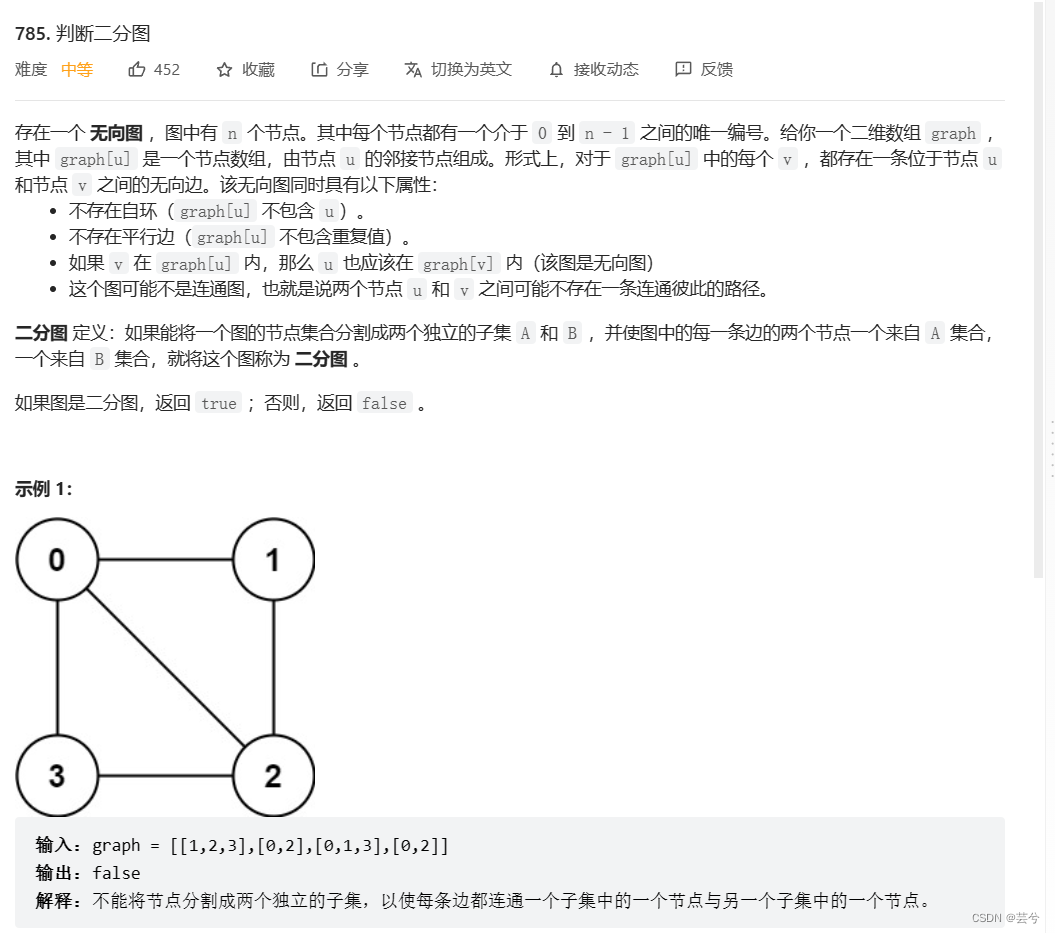
leetcode重点题目分类别记录(二)基本算法:二分,位图,回溯,动态规划,图论基础,拓扑排序
layout: post title: leetcode重点题目分类别记录(二)基本算法:二分,位图,回溯,动态规划,拓扑排序 description: leetcode重点题目分类别记录(二)基本算法:二…...

【JaveEE】多线程之定时器(Timer)
目录 1.定时器的定义 2.标准库中的定时器 2.1构造方法 2.2成员方法 3.模拟实现一个定时器 schedule()方法 构造方法 4.MyTimer完整代码 1.定时器的定义 定时器也是软件开发中的一个重要组件. 类似于一个 "闹钟". 达到一个设定的时间之后, 就执行某个指…...
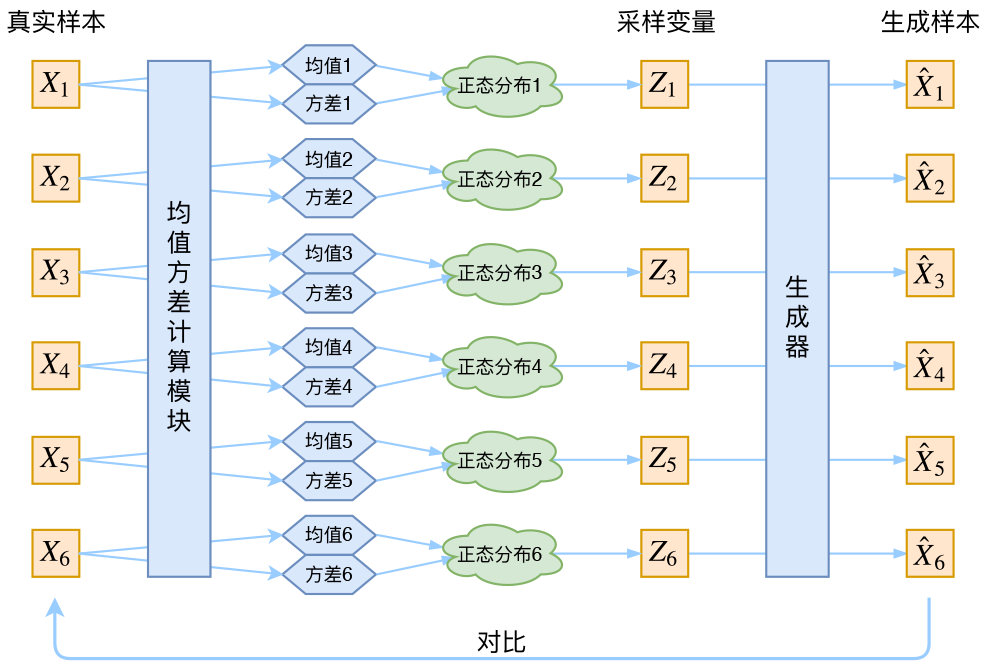
【理论推导】变分自动编码器 Variational AutoEncoder(VAE)
变分推断 (Variational Inference) 变分推断属于对隐变量模型 (Latent Variable Model) 处理的一种技巧,其概率图如下所示 我们将 X{x1,...xN}X\{ x_1,...x_N \}X{x1,...xN} 看作是每个样本可观测的一组数据,而将对应的 Z{z1,...,zN}Z\{z_1,...,z_N…...

【哈希表:哈希函数构造方法、哈希冲突的处理】
预测未来的最好方法就是创造它💦 目录 一、什么是Hash表 二、Hash冲突 三、Hash函数的构造方法 1. 直接定址法 2. 除余法 3. 基数转换法 4. 平方取中法 5. 折叠法 6. 移位法 7. 随机数法 四、处理冲突方法 1. 开放地址法 • 线性探测法 …...

HTML5 应用程序缓存
HTML5 应用程序缓存 使用 HTML5,通过创建 cache manifest 文件,可以轻松地创建 web 应用的离线版本。这意味着,你可以在没有网络连接的情况下进行访问。 什么是应用程序缓存(Application Cache)? HTML5 引…...

全国计算机等级考试三级网络技术选择题考点
目录 第一章 网络系统结构与设计的基本原则 第二章 中小型网络系统总体规划与设计方法 第三章 IP地址规划技术 第四章 路由设计基础 第五章 局域网技术基础应用 第六/七章 交换机/路由器及其配置 第八章 无线局域网技术 第九章 计算机网络信息服务系统的安装与…...

Python和VC代码实现希尔伯特变换(Hilbert transform)
文章目录前言一、希尔伯特变换是什么?二、VC中的实现原理及代码示例三、用Python代码实现总结前言 在数学和信号处理中,**希尔伯特变换(Hilbert transform)**是一个对函数产生定义域相同的函数的线性算子。 希尔伯特变换在信号处…...

嵌入式C语言语法概述
1.gcc概述 GCC全称是GUN C Compiler 随着时代的发展GCC支持的语言越来越多,它的名称变成了GNU Compiler Collection gcc的作用相当于翻译官,把程序设计语言翻译成计算机能理解的机器语言。 (1)gcc -o gcc -o (其…...
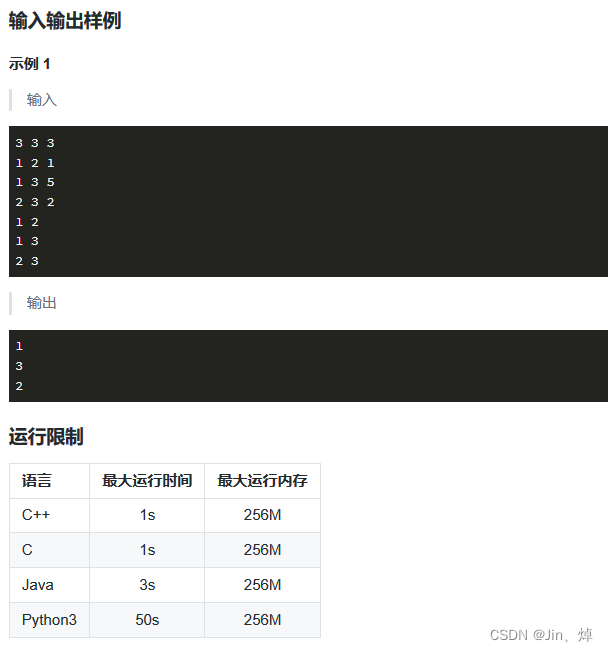
蓝桥杯第19天(Python)(疯狂刷题第3天)
题型: 1.思维题/杂题:数学公式,分析题意,找规律 2.BFS/DFS:广搜(递归实现),深搜(deque实现) 3.简单数论:模,素数(只需要…...

Linux应用层直接操作硬件寄存器:原理、实现与安全实践
1. 项目概述:为什么要在应用层操作寄存器? 在嵌入式Linux开发或者驱动调试的日常工作中,我们常常会遇到一个看似“越界”的需求:在用户空间的应用层程序里,直接去读写某个硬件寄存器的值。这听起来有点“离经叛道”&am…...

直播抠图技术100谈之25---调色中曲线是最优解
为什么曲线调色是最优解 蓝松抠图在即将发布的版本中特意重写了曲线调节,把达芬奇的二级曲线重新做了一遍,并模仿达芬奇的节点图做了自己的节点图。我们为什么要重新设计曲线,因为我们认为调色中曲线是最优解; 结论 在所有调色手段…...

从Halo部署到公网访问:手把手教你用Nginx反代搞定域名、HTTPS与安全配置
从Halo部署到公网访问:Nginx反代全流程实战指南 当你成功在本地服务器上部署了Halo博客系统,看着8080端口的测试页面时,是否思考过如何让它成为真正的互联网站点?本文将带你跨越从本地测试到公网可访问的最后一道鸿沟,…...

Oto 核心架构深度解析:Context 与 Player 的设计哲学
Oto 核心架构深度解析:Context 与 Player 的设计哲学 【免费下载链接】oto ♪ A low-level library to play sound on multiple platforms ♪ 项目地址: https://gitcode.com/gh_mirrors/ot/oto Oto 是一个跨平台的低级音频播放库,其核心架构围绕…...

基于RAG的智能文档问答系统:从原理到实践
1. 项目概述与核心价值如果你是一名开发者,或者经常需要处理各种技术文档、API参考、项目说明,那么你一定对“信息孤岛”深有体会。代码在一个仓库里,设计文档在另一个云盘,会议记录在Notion,而临时的讨论和决策可能散…...
)
Qt + OpenGL实战:手把手教你打造一个可交互的3D点云数据查看器(附CSV加载)
Qt OpenGL实战:打造工业级3D点云可视化工具全流程解析 在激光雷达测绘、三维重建和工业检测领域,点云数据的可视化一直是工程师面临的痛点。传统方案要么依赖昂贵的专业软件,要么需要从零造轮子实现OpenGL底层渲染。本文将展示如何基于Qt和…...

专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案
专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案 【免费下载链接】glogg A fast, advanced log explorer. 项目地址: https://gitcode.com/gh_mirrors/gl/glogg 在当今的分布式系统和微服务架构中,日志分析已成为系统运维、故障排…...

轻量级推荐系统MiniOneRec:从协同过滤到服务部署的实践指南
1. 项目概述:一个轻量级、高可用的推荐系统引擎在数据驱动的今天,推荐系统早已不是大型互联网公司的专属。无论是电商平台、内容社区,还是企业内部的知识库、工具集,个性化推荐都已成为提升用户体验和业务效率的核心能力。然而&am…...
)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南) 在电子工程领域,精确测量电容值是一项基础却极具挑战性的任务。无论是研发高频电路的设计师,还是调试精密仪表的工程师,亦或是研究…...

Gemini3.1Pro评估ViT平移不变性:4周MVP路线图
利用 Gemini 3.1 Pro 评估视觉 Transformer 的平移不变性:从机制刻画、对照验证到门控降级与4周MVP路线图“平移不变性(Translation Invariance)”是视觉 Transformer(ViT 等)稳健性的核心指标之一:当图像在…...