【Note5】网络,并发/IO,内存,linux/vi命令,正则,Hash,iNode,文件查找与读取,linux启动/构建
文章目录
- 1.局域网:CSMA/CD
- 2.互联网:ARP,DHCP,NAT
- 3.TCP协议:telnet,tcpdump,syn/accept队列
- 4.HTTPS协议:摘要(sha、md5、crc)。win对文件进行MD5校验用自带的certutil工具:certutil -hashfile a.tar.gz MD5,linux:md5sum a.tar.gz
- 5.线程/协程/异步:并发对应硬件资源是cpu,线程是操作系统如何利用cpu资源的一种抽象
- 6.并发:cpu,线程
- 6.1 可见性:volatile
- 6.2 原子性(读写原子):AtomicInteger/synchronized
- 6.3 CPU:由控制器和运算器组成,通过总线与其他设备连接
- 6.4 应对并发:cdn
- 7.IO多路复用:硬盘和网卡
- 7.1 select:select是系统调用函数,system是一个C/C++的库函数
- 7.2 poll:pollfds数组替代bitmap,阻塞
- 7.3 epoll:epfd是共享内存,不需要用户态切换到内核态
- 7.4 IO模型:阻塞:发起io读取数据的线程中函数不能返回。同步:拿到io读取完的数据之后,对数据的处理是在接收数据线程的上下文后紧接着处理。异步:回调函数中进行数据处理
- 7.5 硬盘,网口,套接字:du,df,fdisk,lsblk,smarctrl -i, blkid
- 8.操作系统内存管理与分类:分页,页大小位数=偏移量
- 8.1 内存条/总线/DMA(硬件):CPU和DMA是同级,两者对总线控制是轮换隔离
- 8.2 用户态和内核态:程序运行过程中可能处于内核态,也可能处于用户态,某一时刻处于用户态,下一时刻可能切换到用户态(但必须有触发条件)
- 8.3 分页:为了减少碎片问题
- 8.4 分段:程序内部的内存管理即分段,堆区和栈区就是程序的段
- 8.5 IPC:进程间通讯
- 8.6 free -h:查看内存条:dmidecode |grep -P -A5 "Memory\s+Device"|grep Size|grep -v Range
- 8.7 brk:用户无法操作硬件如内存条,必须交给内核帮我们操作完了再把结果给我们
- 8.8 mmap:pidstat,缺页缺的是内存还是磁盘
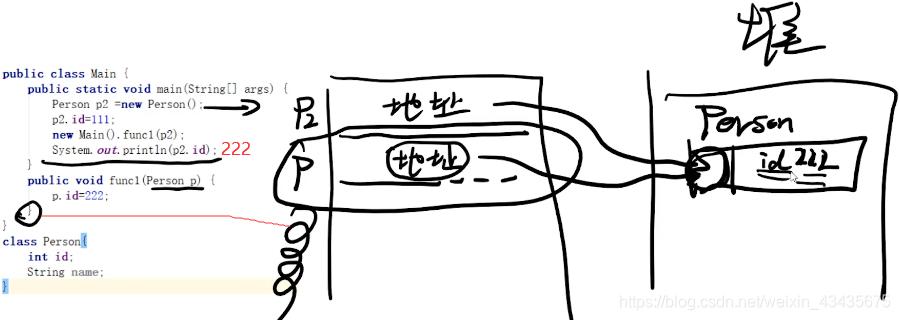
- 9.JVM内存5区:jvm即java二进制字节码的运行环境,好处:一次编写,到处运行。自动内存管理和垃圾回收功能。数组下标越界检查。多态。
- 9.1 栈和栈帧:线程安全
- 9.2 逃逸分析:开启逃逸分析即将最后参数删除,几次GC后停止了。如果不是只在当前函数范围用到的对象不行
- 10.VMware/CentOS/CRT:两个网络适配器是虚拟机的,Linux抄袭unix,Mac os是unix的皮肤
- 10.1 VMware/CentOS:netstat -anp|grep ssh,vi /etc/ssh/sshd_config放开Port 22,service sshd restart,chkconfig可将sshd加入到系统服务中开机后sshd将自动启动:chkconfig sshd on
- 10.2 CRT:netstat -nal | grep 22
- 安装:改注册信息要打开CRT客户端在最上端Help栏中Enter License Data
- 配置:SSH2。Hostname:192....。Port:22。Username:root
- 11.Linux命令:linux组成:内核(就是操作系统,和硬件打交道,驱动)。shell(和用户打交道,用户指令翻译成机器码给内核)。文件系统(文件组织方式,linux没有盘符,有目录/文件/链接link)。应用程序
- 11.1 关机/重启/注销
- 11.2 系统信息和性能
- 11.3 磁盘和分区
- 11.4 用户和用户组
- 11.5 网络和进程管理
- 11.6 系统服务
- 11.7 文件和目录
- 11.8 文件查看和处理
- 11.9 打包和解压
- 11.10 RPM包管理
- 11.11 YUM包管理
- 11.12 DPKG包管理
- 11.13 APT软件工具
- 11.14 用户管理及权限
- 11.15 sed:管道过滤(替换,删除)
- 11.16 awk:-F指定分隔符,-V设置变量,NF列数,$NF是一行数据最后一列的值,多用于对字段(像数据库中的字段)
- 11.17 grep:元字符即\d,\D这些是Perl正则-P,扩展正则-E
- 12.vi命令:三种(命令行[Esc],编辑[i],底行[:wq])模式切换
- 13.正则:\d,?* +这些是[a-z]{m,n}这些的简写
- 14.iNode:磁盘中块和扇区
- 15.文件查找与读取命令:C语言中‘\0’(对应的ASCLL码值为0)表示的空字符
- 15.1 find:找文件
- 15.2 grep:找文件中内容
- 15.3 cat/more:查看文件全部内容
- 15.4 head/tail:查看文件部分内容
- 16.Linux下开机自动重启脚本:/etc/rc.local,Crontab,Systemd
- 17.Linux系统启动过程:ukr,ubuntu开机引导文件/etc/default/grub
- 18.编译u-boot 2019.10和linux-kernel 5.3.6并用busybox打包根文件系统:在全志H5芯片上启动起来
- 18.1 u-boot:._defconfig文件生成.config文件再make编译
- 18.2 kernel:先make config再make生成文件拷进去
- 18.3 busybox:先make config再make,make install,创建文件
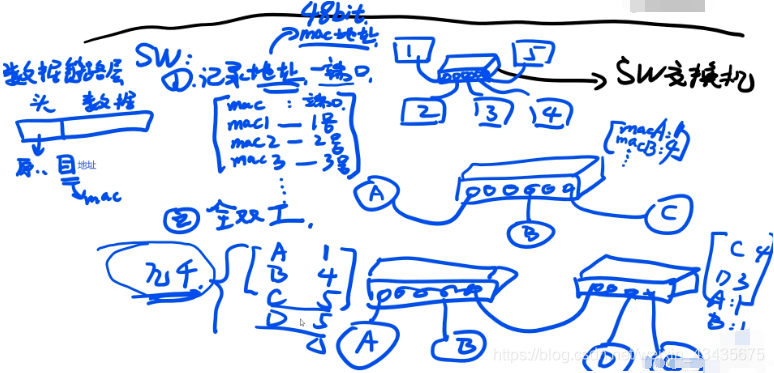
1.局域网:CSMA/CD
1.早期通过双绞线(只能有一台设备进行数据发送),通过10100…高低电平就能表示数据信号。标识:1–>3,3需要表明自己身份是3。
2.通过集线器广播给所有设备,2345自己分辨是我的消费了,不是我的数据包丢弃。如果1,2同时广播,4收到2个消息混合解析不出,导致1,2这两个数据包全没法用。针对上面问题提出CSMA/CD协议:发送前进行载波侦听,检测这链路上有没有其他人正在发送数据,没有的话再进行数据发送防冲突。hub集线器缺点:1.进行数据的广播会导致带宽利用率较低。2.在链路上同时只能有一个设备发送数据,链路利用率低。3.没有标识,只是广播出去,让设备自己判断是不是自己的,工作效率低。

3.如下机器1想发到机器3,通过SW寻址到3号口。SW记录了地址(mac地址)和端口(此处端口不是电脑端口而是交换机端口)的映射关系不用广播(集线器),SW用的是网线,里面有8根线,正常情况至少4根线是在工作的,所以实现全双工。买来交换机里是张空表,怎么建立映射关系?如下机器A插上来后要向B发送数据,发现是空表,确定A是1号口,B找不到就往每个端口发,4号口对B做出了回应,表记录B对应4号口。桥接(如没有映射关系,C和D都对应5,5口转到另一个SW,量大之后不断桥接引起消息洪泛)实现几千条存储,几千条不够至少几十亿。如下mac和端口的映射表不是路由表,局域网(家庭网,校园网等)使用交换机效率高。
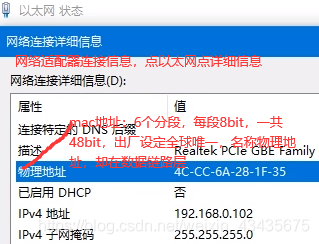
ipconfig /all查看无线或有线网的mac地址。
2.互联网:ARP,DHCP,NAT
SW交换机的映射表只能实现几千存储,如果表中记录满了,新的来会把旧的替代,所以跨网用路由器(也称网关)。如下家庭网是整个网络2,每台机器都有自己的路由表如ubuntu有路由表,路由器也是linux系统也有路由表。本台电脑的路由表会写默认网关是192.168.0.1(这个点在路由器上),本台电脑就会把数据包发到路由器上,这个路由器自己也有路由表路由到1.52这个网卡,1.52和1.254和1.1在同一个网段下很容易找到。路由器的路由表比SW交换机的映射表复杂用到了很多路由算法。


ping 192.168.1.254可通,那么网络内传输如1.52—>1.254即网络内怎么传数据的呢?同一网段一找就找到这样的说法是错的,若是这样为什么有了IP地址还要mac地址呢?ip地址(抽象地址)不能直接通信,只能用mac地址(真实地址)通信,ARP协议广播询问谁的ip是1.254,1.254收到这询问就会回复一下,说我的地址是1.254,我的mac地址是。。。1.52知道了1.254对应的mac地址就会在mac层进行传输。

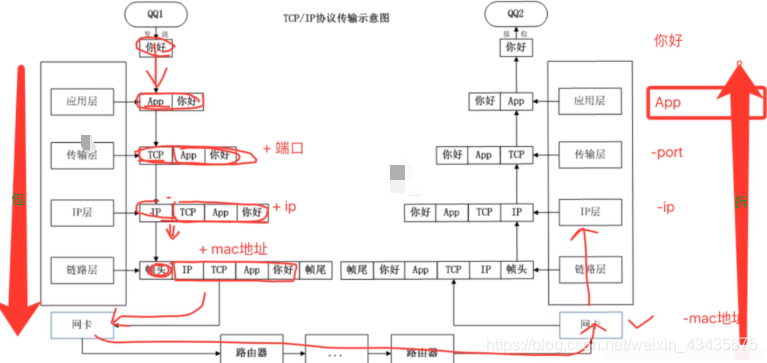
ip的数据包就是mac的数据部分,越往上层(往里)ip层包着还有tcp层,ip数据包里数据部分还会有tcp的头,再往上层(往里)还可能有http的头,最后的数据才是我们要传的数据。
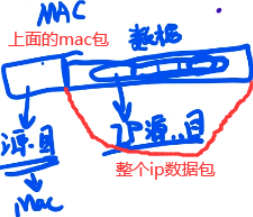
获取mac地址都是通过ARP协议(cat /proc/net/arp),如下ip的源目地址是不变的,一直为0.102和1.254,只有mac地址一直在切换(竖着对比)。有个特例NAT(网络地址转换协议):源地址ip也会进行切换。

ifconfig eth0 hw ether aa:11:22:88:cc:dd #更改mac地址
ifconfig eth0 up
dhclient eth0
# /recipes-plats/network/files/eth1_mac_fixup.sh # Fixup the MAC address for eth0 based on baseboard EEPROM
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bincount=0
while [ $count -lt 3 ]
dostr=$(fruid-util cmm | grep "BMC Base Mac address" | awk -F ":" '{print $2}')str=$(echo $str |sed 's/ //g')if [ ${#str} -ne 12 ];then # 获取字符串长度logger "Loop $count failed to read BMC FRU:$str"count=$(($count + 1))sleep 1continuefimac="${str:0:2}:${str:2:2}:${str:4:2}:${str:6:2}:${str:8:2}:${str:10:2}" #中间有冒号if [ -n "$mac" -a "${mac/X/}" = "${mac}" ]; then # mac有值返回true,不用管Xlogger "Loop $count success to configure BMC MAC: $mac"#ip link set dev eth1 address "$mac" #在/etc/rc.d/rc.local里加上如下三句,reboot后就不怕MAC复原了/sbin/ifdown eth1/sbin/ifconfig eth1 hw ether $mac/sbin/ifup eth1sleep 1exit 0ficount=$(($count + 1))sleep 1
doneif [ $count -ge 3 ]; thenecho "Cannot find out the BMC MAC" 1>&2logger "Error: cannot configure the BMC MAC"exit -1
fi
# config_mac
. /usr/local/bin/openbmc-utils.sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/binprog=$(basename "$0")
usage()
{echo "Usage: $prog <mac>"echoechoecho "Examples:"echo " $prog XX:XX:XX:XX:XX:XX"echoexit 1
}check_parameter()
{mac=$1strlen=${#mac}if [ $# -ne 1 ] ;thenusagefiif [ "$strlen" -ne 17 ] ;thenusagefi
}set_mac()
{mac=$(echo "$mac" | sed 's/://g'| tr '[:a-z:]' '[:A-Z:]')/usr/local/bin/fruid-util base --dump /tmp/base_fru.bin/usr/local/bin/fruid-util base --modify --PCD2 "$mac" /tmp/base_fru.bin > /dev/null 2>&1set_mac_eeprom_wp/usr/local/bin/fruid-util base --write /tmp/base_fru.bin > /dev/null 2>&1reset_mac_eeprom_wp
}check_mac(){fru_mac=$(/usr/local/bin/fruid-util base |grep "Product Custom Data 2" | awk -F ': ' '{print $2}')if [ "$mac" != "$fru_mac" ] ;thenecho "Set mac fail"fi
}check_parameter "$@"
set_mac
check_macroot@bmc:~# fruid-util base
Product Custom Data 2 : 78D4F15F171D
root@bmc:~# ./config_mac 78:D4:F1:5F:17:1a
root@bmc:~# fruid-util base
Product Custom Data 2 : 78D4F15F171A
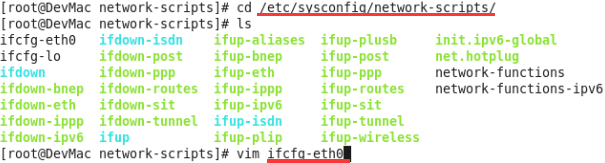
vi /etc/sysconfig/network-scripts/ifcfg-eth0 。MACADDR=00:11:22:33:44:55 。改好执行/etc/init.d/network stop ,/etc/init.d/network start。
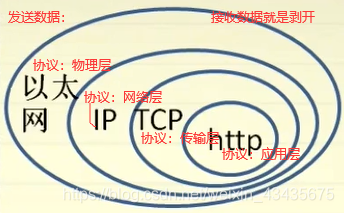
如下TCP/IP架构:以太网协议mac:把cpu想要发送的数据封装为以太网协议(网卡完成这功能)。ip协议:实现路径的管理,传输过程中根据想要发送的目标地址,帮我们的报文在网络中选择一条传输路径(路由器完成这功能)。ip协议针对目标是机器与机器之间通信,平时利用网络过程中需要进程与进程的通信,所以传输层(tcp/udp协议)这层封装有必要,应用层可以自己去定义。
udp:实验室内部交流终端,发信息时效性要高如语音、视频、直播等,丢个一帧两帧影响不大,数据是不停的过来,在ip协议基础上增加了很少一部分功能同时它不是面向连接的,不需要对方给我一个反馈,减少了传输的成本,相对来说时延也小得多。
tcp:传一些重要内容,如发一个公告或给谁发一个文件,这个过程对时效性没那么强,传文件稍微等一会也没事但要求传输的准确不能出错,TCP复杂面向连接。
如下应用层:POST /xxx.html HTTP/1.1。
如下拆包和粘包,Client和Server间的Packet1被拆包,与Packet2粘包:

如下解决粘包拆包:头/定长/分隔符。

如下是第一种方法,粘包还是会出现,但可以区分开。

如下是第三种方法,自定义分隔符。

交换机 ,二层交换机 ,多接口网桥是一个东西。路由器 ,三层交换机 ,网关是一个东西。


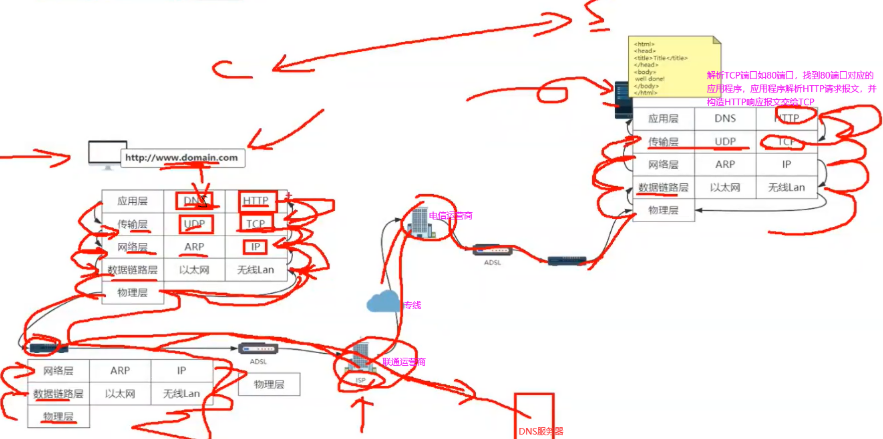
从一个HTTP请求来看网络分层原理:内网里通过网线进行传输,连接到公网的话会通过光纤进行连接。要实现不同介质间信号的转换,还有从光纤到路由器无线脉冲转换,距离远的话还有信号衰减问题。如下把问题分层,不同层间定义标准化接口让它们间可进行数据通信。

1.如下右边一个服务器部署了一个静态页面,通过nginx部署在公网上,看下浏览器里有没有域名对应DNS的缓存,有的话直接拿到服务端的ip地址,没有的话去浏览器本地的host文件看有没有配置,没有配置的话才会发起一个DNS请求用来获取服务器ip地址。
2.DNS也是台服务器也有自己的ip地址通常配在自己的操作系统上,这时应用层会构造一个DNS请求报文,应用层会去调用传输层的接口一个socket的API,DNS默认使用UDP实现数据传输,传输层会在DNS请求报文基础上加一个UDP的请求头。传输层将数据交给网络层,网络层同样在UDP请求报文基础上加IP的请求头,网络层会将IP请求报文交给数据链路层,数据链路层会将自己的mac头加上去并把对应的请求报文交给下一个机器的mac地址也会加上去。下一个机器的mac地址通过网络层ARP协议找到,ARP会发送一些请求看下你对应的ip地址的mac地址是多少,最后通过物理层物理介质传出去,通常传到路由器上。
3.路由器是三层设备(从下向上,物理/数据链路/网络)从物理层开始连接,物理层交给数据链路层,数据链路层看下地址是不是给我的,是给我的进行解析,不是给我的就丢弃,报文再传给上面一层网络层,网络层把数据传到下一个路由器的地址是多少,会通过运营商的网络接口传到运营商的路由器上。
4.运营商有自己的DNS服务器,如果配的是运营商自己的DNS服务器的话会直接在这个DNS服务器里找自己对应的域名拿到对应的ip地址,也就是刚请求DNS报文地址,然后原路返回解析直到应用层拿到刚域名对应得ip地址,这样就可以进行HTTP请求报文的发送。再调用传输层协议是TCP参数,同样每到一层加头。
如下名字里有传输但并没有做传输的事情,HTTP协议数据传输交由TCP协议进行的。无状态:本身不会存储用户信息。可扩展:头部字段可扩展给业务带来灵活性。自描述消息格式:消息类型可以是文本也可以是图片音视频类型,根据消息类型知道对应数据是什么类型。

发起HTTP请求是想从服务器上拿到资源或对资源修改。如果返回是HTML,浏览器会构造一个DOM数据结构,会解析HTML里有没有其他网络请求,有其它网络请求会继续向服务端发送网络请求,拿到报文后会渲染页面。HTTPS会有一个TLS握手。
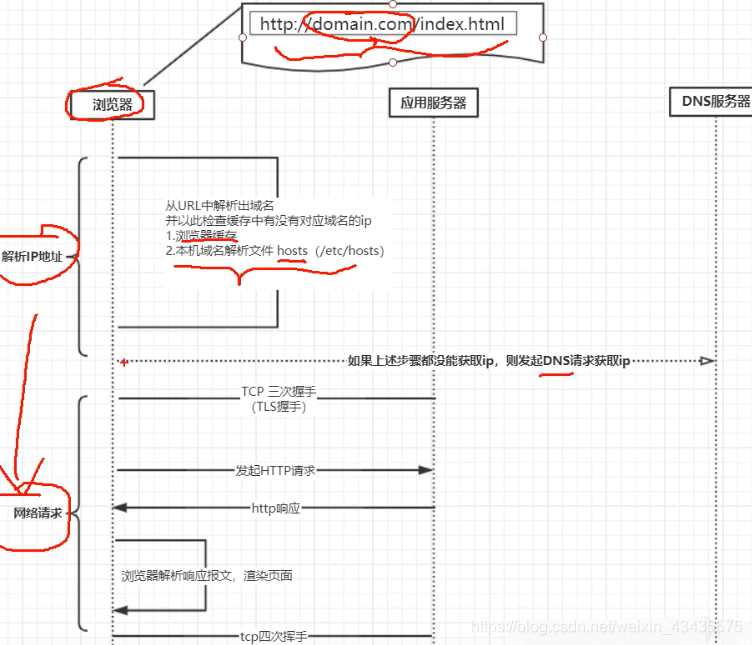
Linux下/etc/hosts文件如下行:主机名(hostname)和域名(domain)的区别在于,主机名通常在局域网内使用,通过hosts文件,主机名就被解析到对应ip。域名通常在internet上使用,但如果本机不想使用internet上的域名解析,这时就可以更改hosts文件,加入自己的域名解析。

3.TCP协议:telnet,tcpdump,syn/accept队列
如下是TCP报文,Source port源端口如果是发送端的话是随机生成的,tcp三次握手之前要知道对方端口目的Dest port,和服务器建立连接web服务一般80端口如nginx。unused保留字段,CWR到FIN是报文标识flag,标识报文什么类型的,如果把syn的bit位设为1的话,当前报文是同步序列号即建立连接的报文,ack的bit为1代表响应报文。Receive window是当前服务器可接受数据大小窗口的值。

如下加上TCP协议头就是五元组,基于TCP的基础上就是四元组。如下三次握手主要做了a和b两件事。

如下服务端先进入listen状态,如nginx的话会监听某个端口(如web服务就是80端口),客户端发送请求前会创建一个数据结构(下面黄色)用来存储要发送的端口号等,客户端报文一发出去,客户端立马进入syn-sent状态,服务端收到syn(Synchronous number,同步序列号)报文时也会在本地创建一个对应的数据结构。
客户端可以发送很多TCP报文,每个报文都有自己的随机生成算法生成自己的序列号,所以x+1是对x这个报文的响应。建立连接会消耗非常多系统资源(create tcb…),所以不用时要关闭(四次挥手)。中间SYN和ACK可以合在一起节省流量,也可以拆分开。

下面通过实验看三次握手怎么进行的:

如下nc命令会发一个TCP三次握手请求,输入服务器地址和端口。
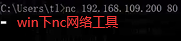

如下查看tcp连接状态,-t参数查看当前tcp连接状态,-p显示进程,-n数字型显示ip和端口。如下就是win系统和linux系统建立的连接。

如下是tcp四次挥手,关闭连接(客户端或服务端都可以直接关,全双工),主动方会进入time_wait状态,MSL是最大的报文生成时间,2MSL就是报文一个来回时间。没有2MSL立马关闭会造成第一(服)个问题:ACK j+1这个报文丢失,服务端没收到ACK会不断重发FIN报文,服务端资源没法释放。第二(客)个问题:关闭连接意味着资源被释放了,那么端口号被其他进程使用,报文到来时根据tcp的四元组恰好碰到刚释放掉那个连接,造成混乱。

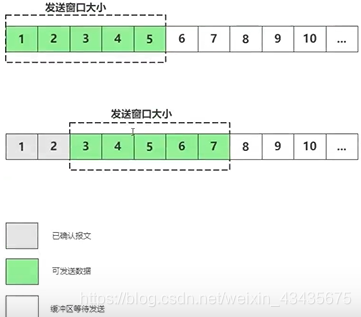
滑动窗口协议与累计确认(延时ack):可延时ack的发送,确认最后一个报文如5就可以。但这样有一个问题如3的报文丢了,这时只能确认1和2连续报文,从3以后的报文全要重传,已确认的报文在缓冲区丢弃掉。
4.HTTPS协议:摘要(sha、md5、crc)。win对文件进行MD5校验用自带的certutil工具:certutil -hashfile a.tar.gz MD5,linux:md5sum a.tar.gz
Hash散列算法(应用于哈希表和摘要密码学),是把任意长度的输入通过特定的算法变换成固定长度的输出,输出的值就是hash值。这个特定的算法就叫hash算法,hash算法并不是一个固定不变的算法。只要是能达到这个目的的算法都可以说hash算法。例如MD5,SHA,String.hashcode()都是hash算法。
不同的输入可能会得出相同的hash值,那么这种现象称为hash碰撞,无论是采用那种hash算法,hash碰撞都是不可避免的,我们只能通过改进hash算法,把出现碰撞的概率降低。hash英语中的意思是剁碎的食物,反应在计算机领域大概就是把任意数据切割打碎,输出固定长度的数据。

先解AES,再用AES解image。


HTTPS利用摘要(也叫hash散列,用于校验信息完整性,确保文件没被修改)和加密(对称【一个密钥】和非对称【2个密钥】)算法完成加密通道。

如下用到的公私钥都存在Server端。

5.线程/协程/异步:并发对应硬件资源是cpu,线程是操作系统如何利用cpu资源的一种抽象
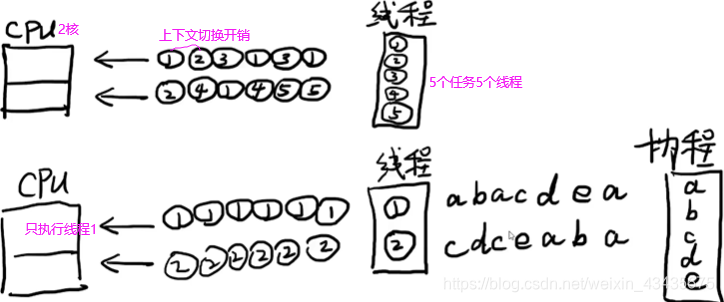
线程想提高效率和io密切相关,程序往往都含有io。CPU上下文切换就是先把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
线程(操作系统级别概念)是cpu调度的最小单位,cpu并不在意是哪个进程,cpu就是轮换着线程来运行并不需要知道这个线程是属于哪个进程的。左边单核cpu(不是单线程),3个线程(任务都是读取文件)交叉运行完。
通过以下两点大大提高了cpu利用率,因而线程想提高效率和io密切相关。
1.DMA过程中cpu一段时间不被线程阻塞。
2.DMA进行数据读取时可复用,因为cpu的总线程具有多条线路,所以DMA可充分利用这些线路,实现并行读取这些文件。

多线程需调用系统底层API才能开辟,在多线程开辟过程中浪费时间,并且在线程运行中上下文切换部分(左边切换多次,右边切换三次)有用户态和内核态转换耗,效率浪费在cpu切换时间点上。所以服务端连接的客户端不活跃多(即io次数少),考虑单线程(io多路复用或nio)或协程。上面的1,2,3线程都有io,所以多线程效率高。
如何利用cpu资源?os给了我们两种抽象即进程和线程。进程是系统资源分配,调度和管理的最小单位,比如去任务管理器查看使用内存时是看的哪个进程或哪个程序使用了多少内存而不是哪个线程,如果是哪个线程根本不知道是哪个程序里的线程,没法管理。一个进程的内存空间是一套完整的虚拟内存地址空间,这个进程中所有线程都共享这一套地址空间。如下线程的5种状态,只有运行中是占用cpu资源的。
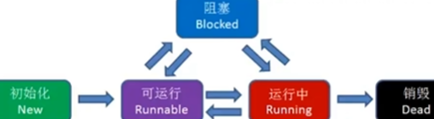
线程执行有性能损耗,这些损耗来自线程的创建销毁和切换,线程本质向cpu申请计算资源,用户态转内核态。
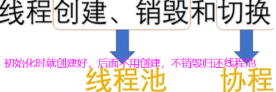
协程是用户自定义线程但与os的线程不同,协程不进入内核态。自己创建一套API,协程利用线程资源。
6.并发:cpu,线程
6.1 可见性:volatile
如下程序一直没结束即while(a)这线程没结束:一个线程对a写了false,但是对另一个线程并不可见。
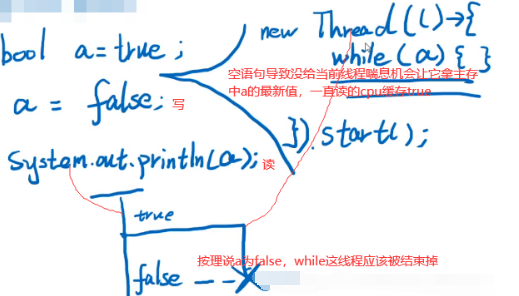
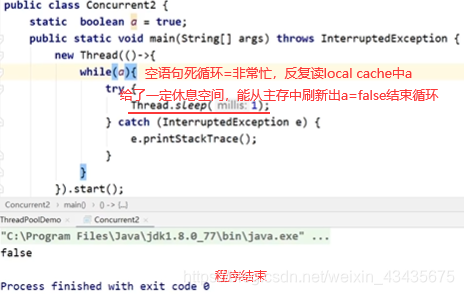
如下第一个core为主线程,第二个core为开辟的线程。
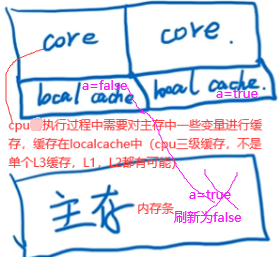
如上线程2不能立即读到线程1写后的最新变量值(线程1写,线程2读),多线程不可见性。如何解决多线程不可见性:加volatile关键字使a在主存和localcache间强制刷新一致。

6.2 原子性(读写原子):AtomicInteger/synchronized
如果线程1和2都进行基于读的变量再对读的变量再进行写,最典型操作i++,T1和T2都进行i++操作。
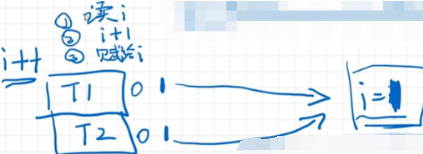
一开始i=0,经过两个线程两次i++操作结果变成了1,这显然是不对的,并且这种情况下不能用volatile保证这样操作的正确性(两个线程既有读操作,又有基于读操作的写操作,可见性只保证一个线程写另一个线程读是正确的,这里可见性不适用)。

现在想做的是将读操作和写操作合为一步,要么同时发生要么同时不发生(原子性)。在保证原子性同时一定以保证可见性为前提(不是并列关系,AtomicInteger类里本质上就是volatile),本身不可见的话没办法保证原子性。

也可用synchronized同步关键字来保证原子性发生,同步关键字同一时间只有一个线程进入代码段。

volatile可见性关键字最轻量级(保证一个线程写,一个线程读能读到最新的值),AtomicInteger(保证既有读操作又有写操作如i++这种场景下能保证操作的原子性)基于volatile,synchronized最重量级(能保证整个代码块中所有操作都是原子性的)。多线程情况下需要自增请使用Atomicxxx类来实现。
6.3 CPU:由控制器和运算器组成,通过总线与其他设备连接

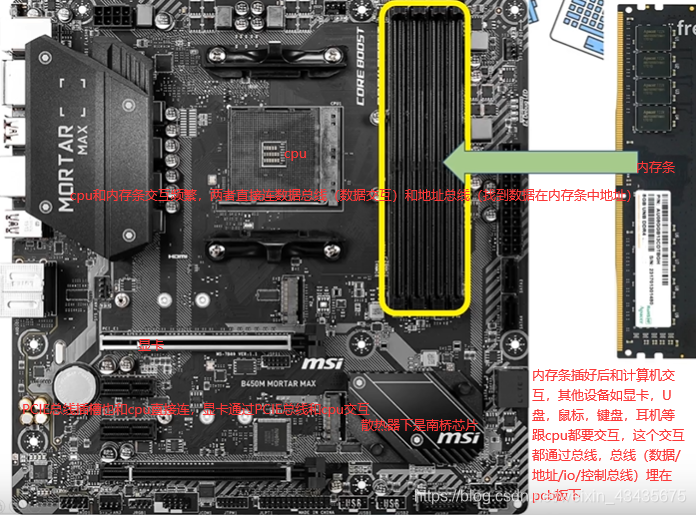
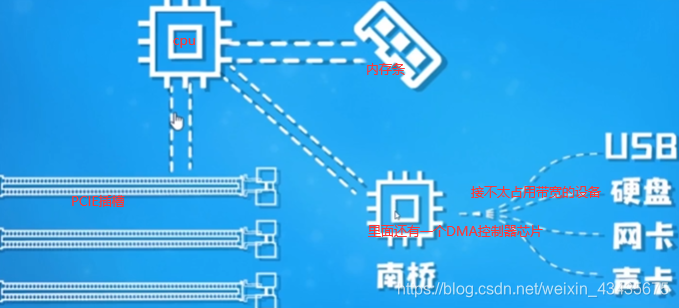
内存,cpu,io是编程中三个最重要的点。南桥(桥就是连接)连接带宽要求低的设备如是一些鼠标键盘硬盘usb设备等。北桥(集成到了cpu内部)负责带宽比较高的设备如pcie显卡,pcie硬盘,内存RAM需高速访问。如下是cpu常见参数,8核16线程(超线程)。

系统架构=处理器指令集,如下常见的6种指令集,X86_64基于X86,ARM不是其他嵌入式类,cortex A系列等。

2个物理cpu,1个物理cpu有38个逻辑核【76个线程/频率/处理单元processor)】。CPU就intel和amd。CPU(S):所有cpu的总逻辑核数。socket:物理cpu数量。top -d 1。

程序一部分在内存中,一部分在SWAP分区(文件系统中,磁盘上)。

6.4 应对并发:cdn
1.动静分离,cdn加速资源。2.水平扩展,nginx集群。3.微服务化,多用多分配资源。4.缓存redis减少io寻找。5.队列,秒杀系统采用。

7.IO多路复用:硬盘和网卡
如下A,B。。都是客户端,方框是服务端。首先想到应对并发,写一个多线程程序,每个传上来的请求都是一个线程,现在很多rpc框架用了这种方式,多线程存在弊端:cpu上下文切换,因而多线程不是最好的解决方案,转回单线程。如下while(1)…for…就是单线程。

7.1 select:select是系统调用函数,system是一个C/C++的库函数
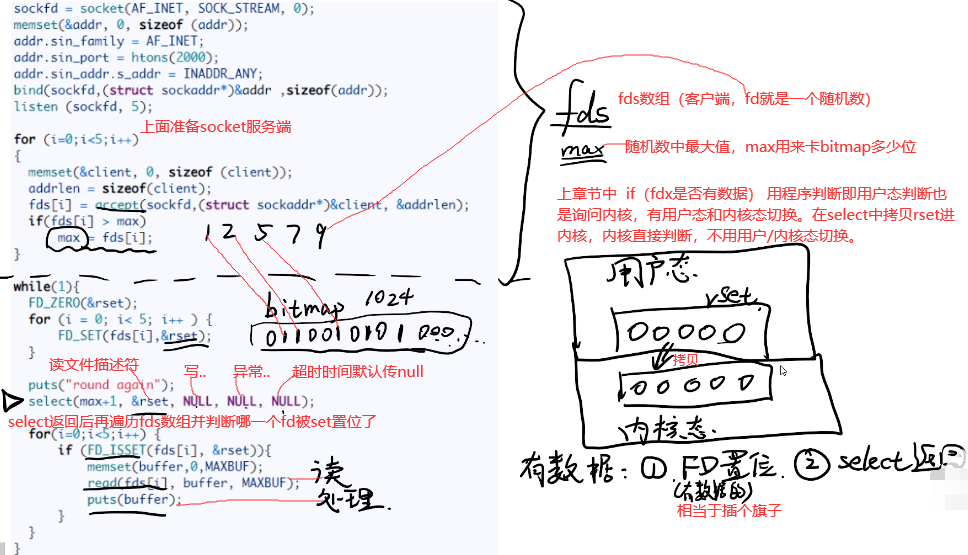
while(1)中FD_ZERO将rset初始化0,用FD_SET将有数据的fd插个旗子,并赋给reset。

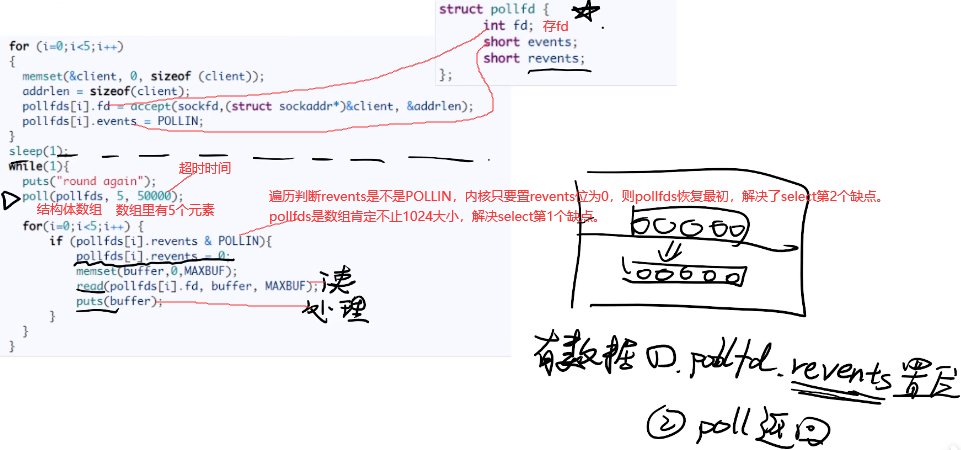
7.2 poll:pollfds数组替代bitmap,阻塞
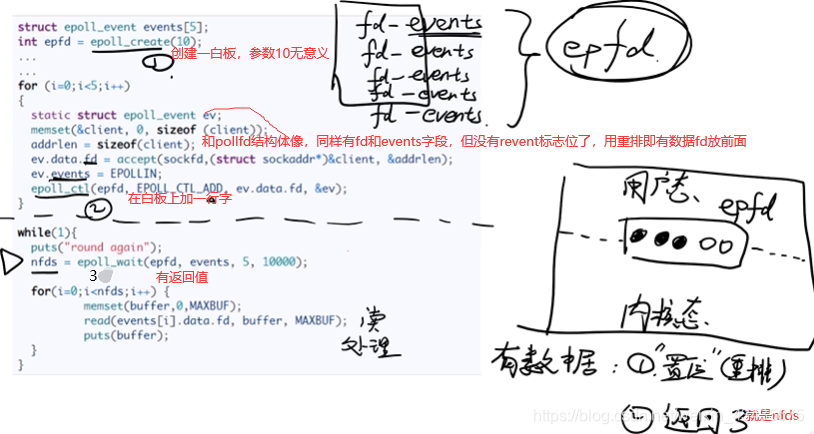
7.3 epoll:epfd是共享内存,不需要用户态切换到内核态
epoll_wait和前面select和poll不一样,有返回值。最后只遍历nfds,不需要轮询,时间复杂度为O(1)。epoll解决select的4个缺点。redis,nginx,javaNIO/AIO都用的是epoll,多路io复用借助了硬件上优势DMA。
7.4 IO模型:阻塞:发起io读取数据的线程中函数不能返回。同步:拿到io读取完的数据之后,对数据的处理是在接收数据线程的上下文后紧接着处理。异步:回调函数中进行数据处理
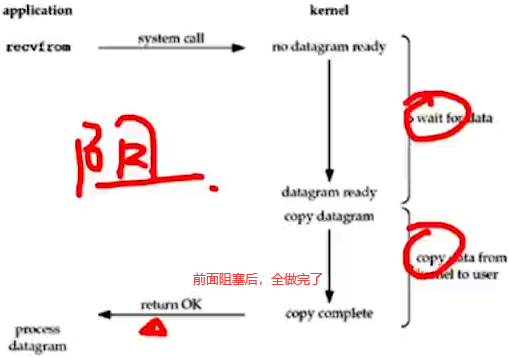
如下是BIO,NIO,AIO的说明。
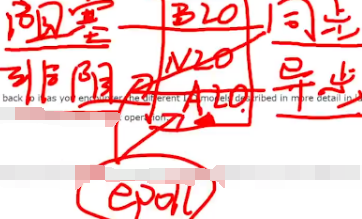
1.blocking I/O(BIO):wait和copy data。
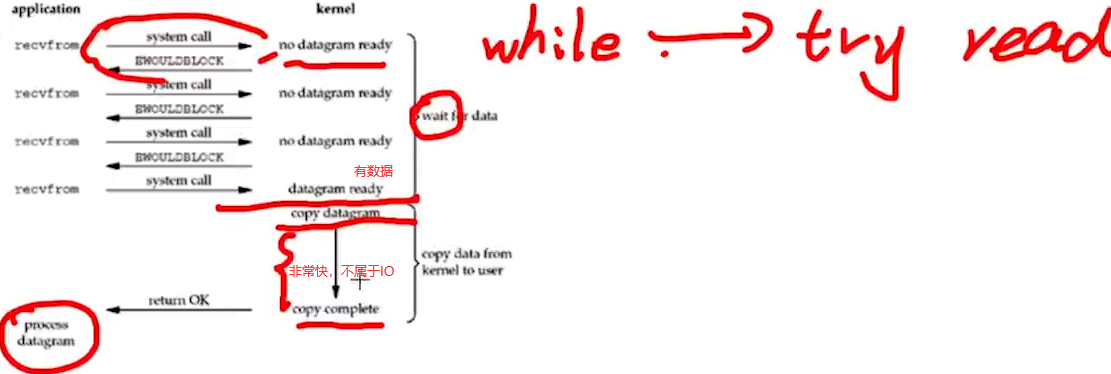
2.nonblocking I/O(NIO):如调用read函数,一调用立马返回。
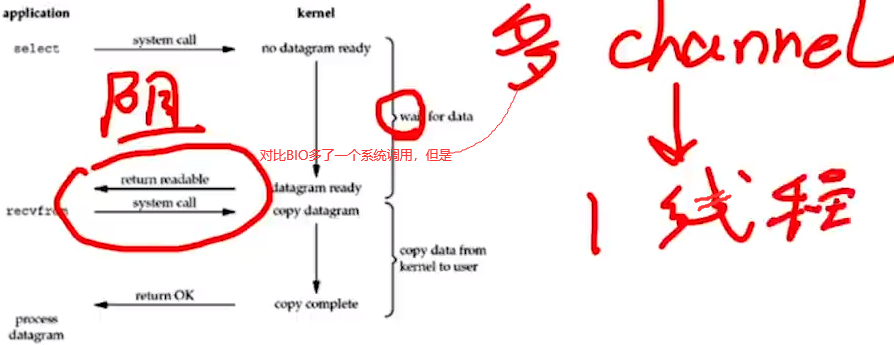
3.I/O多路复用:多路多channel的数据放入一个线程中去处理。
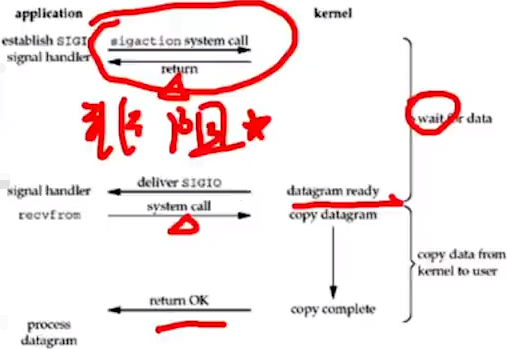
4.信号I/O:kernel即os发送SIGIO给应用层,应用层需编写监听SIGIO中断信号函数进行数据处理。
5.asynchronous I/O(AIO):收到aio_read信号后就可在回调函数中处理了。
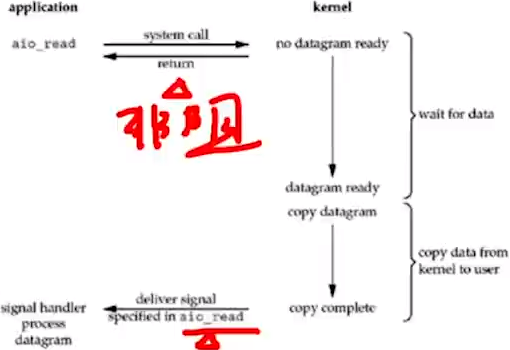
7.5 硬盘,网口,套接字:du,df,fdisk,lsblk,smarctrl -i, blkid
如下是硬盘(块,扇区,文件管理中inode记录的内容)

如下是网卡。


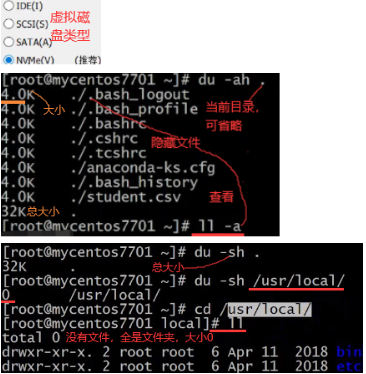
df:如果你想知道某个文件夹或文件大小用du,磁盘相关使用和挂载用df。lsblk和fdisk -l查看分区。blkid查看当前系统用的哪个盘文件系统。如下Type一列是查看文件系统的格式,还有cat /etc/fstab也可以。

fdisk /dev/sda:(d,4)删除sda4分区,(n,4,+408G)新建408G的sda4,(w)保存退出。
mkfs.ext4 /dev/sda4 : 格式化并建文件系统,后面可进行mount挂载,df -h查看。



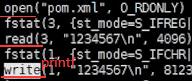
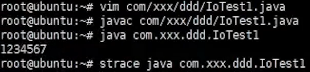
如上看出java比C语言系统调用多的多,因为java要启动jvm虚拟机,jvm要读jdk的lib库等很多操作。如上并没有发现open…xml操作,因为java程序主要启动jvm进程,jvm进程可能又起了很多线程去真正运行main函数,所以加-f。

8.操作系统内存管理与分类:分页,页大小位数=偏移量
8.1 内存条/总线/DMA(硬件):CPU和DMA是同级,两者对总线控制是轮换隔离
io总线 (包括PCIE总线)最常见的USB(通用串行总线)。
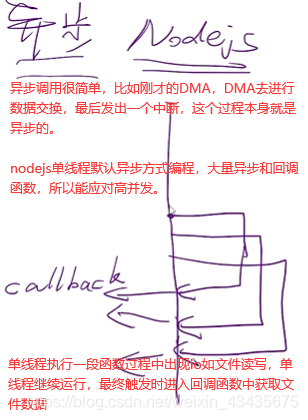
Nodejs是单线程,但在读文件时,文件还没读完却可以执行下面几行程序,文件读完后触发一个回调。因为单线程按理来说cpu直接读磁盘中文件的话,应该一直读取这文件,读完前不能进行其他操作,它怎么做到执行其他操作的呢?需要有硬件支持即DMA,读文件操作是非常机械劳动,cpu资源宝贵不能干这种活,下面xxx是内存地址。

8.2 用户态和内核态:程序运行过程中可能处于内核态,也可能处于用户态,某一时刻处于用户态,下一时刻可能切换到用户态(但必须有触发条件)
读写文件和申请内存是用户态转内核态的两个例子。malloc的两种实现方式brk和mmap,两者只选一种。brk和mmap申请的都是虚拟内存,不是物理内存,想真拿到物理内存空间还要第一次访问时发现虚拟内存地址未映射到物理内存地址,于是促发一个缺页中断(也叫缺页异常,os中异常和中断有很多类似地方)。C语言是malloc,而java和c++中new对象申请内存空间,也是经过这么过程。
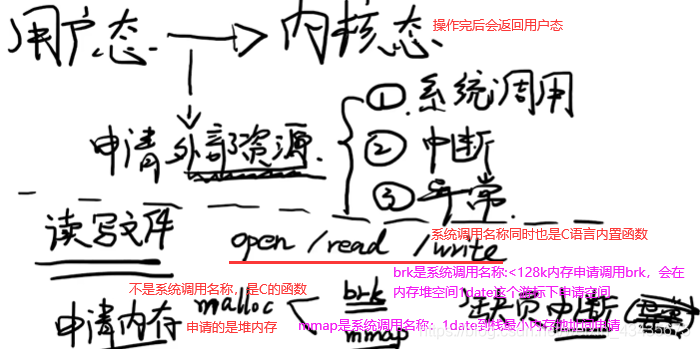
查看linux内核中有多少系统调用:man syscalls如下。第四类信息相关,如获取cpu信息等。管道pipe是进程间通信。open,read,write是文件相关,同时也是对磁盘操作,也可归到设备这类。mmap是文件和内存的映射,mmap申请内存也是对磁盘设备操作,也可属于第三类。

逻辑地址(逻辑/虚拟/进程内存):程序自身看到的内存地址空间,是抽象地址。逻辑地址需映射到物理内存才能完成对内存操作,那为什么程序操作是虚拟的逻辑地址,不能直接操作物理地址即对内存条操作?因为程序是写死的(操作的地址是固定的),而硬件内存条哪些地址被占用了一直变化,因为os是多进程的,当前进程需要操作的地址,其他进程在使用,这样不能使用这块地址了,所以说除非是单进程机器,否则为了进程安全必须做出逻辑地址和物理地址的映射。
所以必须要有逻辑地址,必须要有映射。如何映射?如下固定偏移量映射:程序1的偏移量(初始位置)是0,程序2的偏移量(初始位置)200:如果程序1操作的逻辑地址是100,那么映射的物理地址也100(因为偏移量0);如果程序2操作的逻辑地址是50,映射到物理内存250(因为偏移量200)。
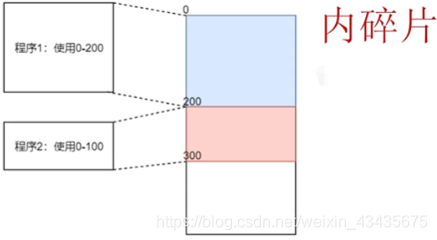
如上看上去简单高效,但存在两个缺陷,第一个缺陷:程序使用的内存无法计算的,随时间推移,进程使用的内存不断变化。这里我们说程序1使用200的内存,这种说法本身不太对的,因为我们没法去限定一个程序使用的内存大小,当然你可以说我估算了这程序使用的最大内存就是200,但这也代表整个200的一段内存中,程序使用的内存绝大多数时间都小于200。蓝色区域中内存使用率并不高,其中存在很多没有利用起来的内存,我们把没利用起来的内存叫内碎片。
第二个缺陷:当程序运行完,内存被释放,比如程序1执行完后,0-200这块地址被释放出来了,此时程序3使用了内存大小是201,这时程序3没法直接使用0-200这段内存了,假设很长一段时间内都没有占用200以内的内存这样的程序被创建,那么0-200一直被闲置,称这段内存为外碎片。
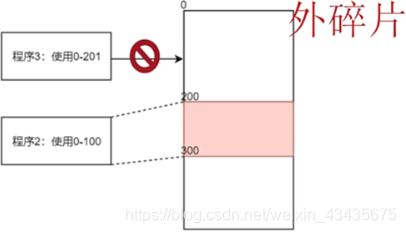
8.3 分页:为了减少碎片问题
将内存空间包括逻辑内存(左,页,地址连续)和物理内存(右,帧,地址不连续)都进行切分,分成固定大小很多片,每一片称它为页。页到帧的映射需要有个表来维系,这个表就叫页表即pagetable(pagetable不仅存了页号帧号,还存了当前这一页读写权限等等)。
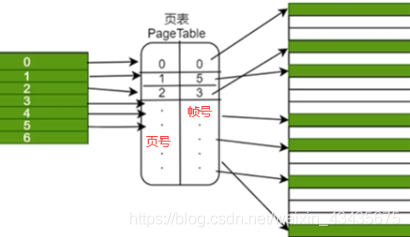
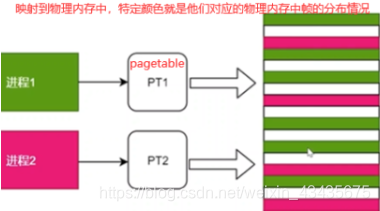
页表是每个进程都需要维护的,因为每个进程映射关系是互相独立的,所以不能共用映射表,每个进程有自己的pagetable。
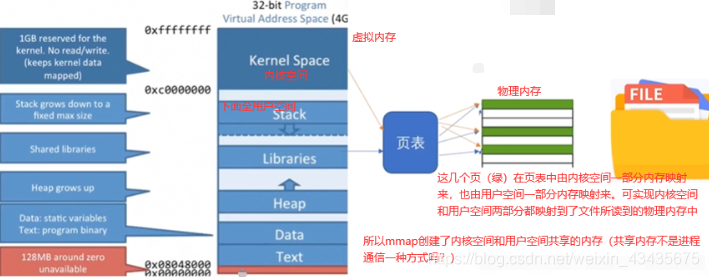
32位os物理地址有2的32次方个即4000000000个地址(内存的一个地址里住着一字节Byte数据)即4GB。32位程序以为自己拥有4GB内存,如两个32位程序,一个使用了2GB内存,另一个使用了3GB内存。但整个物理机只有4GB内存,造成虚拟地址可能比物理地址大,多出来部分可将虚拟地址的页映射到磁盘上。但映射到磁盘上导致下一次读映射到磁盘上这一页内存时会触发一个缺页中断进入到内核态,整个会产生一个大(major)错误。linux下这磁盘部分又叫swapping(与物理帧交换)。
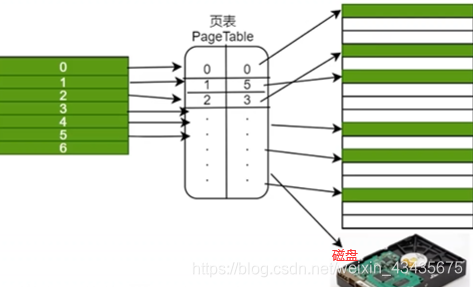
分页小结:1.分页使得每个程序都有很大的逻辑地址空间,通过映射磁盘和高效置换算法,使得内存无限大。
2.分页使不同进程的内存隔离,保证了安全(不同进程各自维系了一个页表,只要页表中value即帧号这一栏不互相冲突,保证不同程序间内存隔离,保证安全性)。
3.分页降低了内存碎片问题。
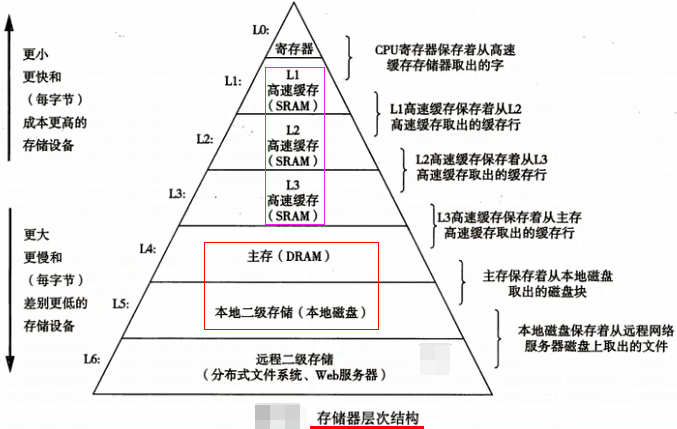
4.缺点:页表存在我们主存中即存在内存中,如果我们要对某一个内存进行访问的话其实要读取两次内存。因为先读取页表,从页表中拿到对应帧号,再拿帧号去内存中再查询一遍,对内存操作有两次读取【时间上要优化(快表)】。页表存在主存中占空间【空间上要优化(多级页表)】。

8.4 分段:程序内部的内存管理即分段,堆区和栈区就是程序的段
分段现在不太存在了,X86_64这些架构的cpu种不再使用这种段页结合式,只使用分页。但现在还听到和段相关如:C语言中段错误,如写程序中用到堆栈这样的段概念,这是为什么呢?原来段保留了逻辑上意义但并不在内存管理中起作用。
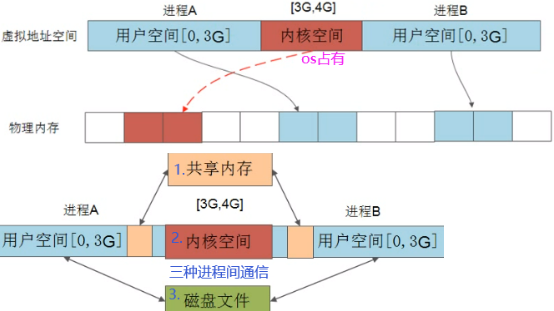
如下图是C语言分段形式,分段就是对虚拟地址分成多个段。不同程序共享内核(kernel space)这1G空间的。最下面有两个段是text(代码段,存程序本身二进制字节码),data(数据段,存程序中一些静态的变量)。堆Heap地址往上增长,栈stack(每个程序都有自己的栈,不共享)地址从高往低增长。
中间是Libraries函数库区,如linux中C常见的函数库so文件,windows下的dll动态链接库都放到堆和栈中间一段区域。进程是可共享这段Libraries函数库,这就是进程间通信的共享内存(如windows下选择文件的对话框即显示很多文件,选中哪一个点击打开)方式。
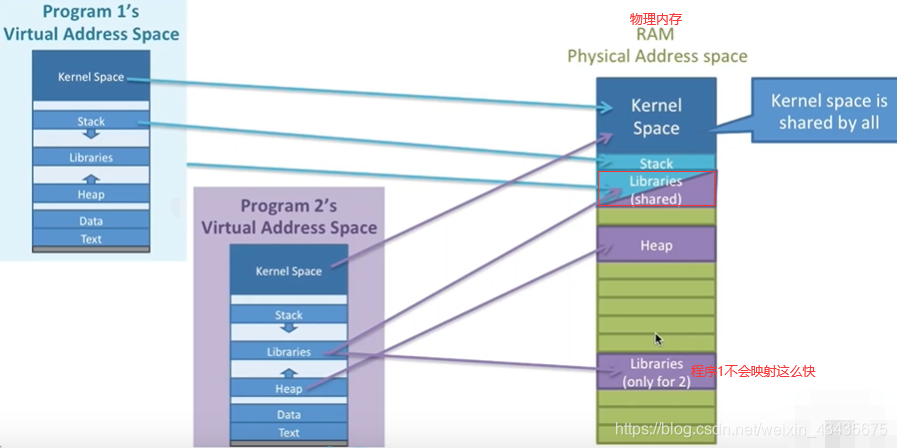
栈和堆是程序中最重要的两种内存形式:栈是连续内存地址,内存创建寻址效率都很高,函数调用栈遵循先入后出的原则,最后调用的函数最先释放栈内存。
函数参数传递是复制传递即将实参复制一份给形参,因而形参的改变不会影响实参,但是如果参数是指针,那么复制的就是地址的值,通过星号下钻该地址就能修改地址内变量的值。我们把包括结构体在内的基础类型传参称为值传递,而指针的传递称为引用传递。
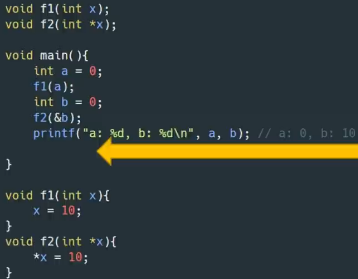
像c、golang是有指针和地址概念,而对于java、python、js等语言,对象的变量名本身就是个指针,因而传递对象就是引用传递。
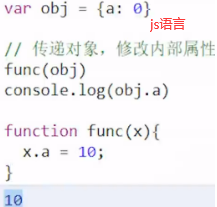
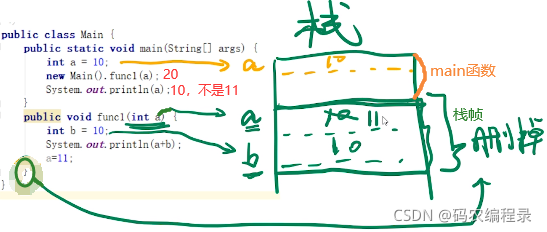
父函数main()在子函数f()入栈之前会留出子函数f()返回值的内存空间,子函数返回值与父函数的入参(这里父函数没有入参,打比方)一样是复制传递。
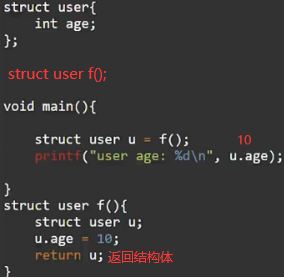
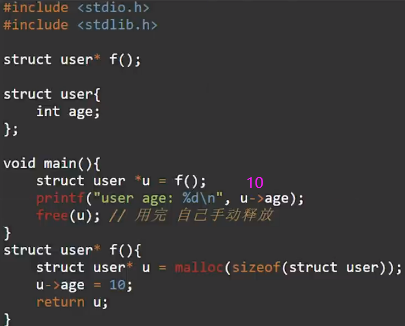
但是返回值如果是指针,可能会导致父函数调用该地址内变量时,子函数已经出栈,导致访问错误。同情况也会出现在全局变量属性赋值时,这些都属于变量逃逸,像go、rust、java会自动进行逃逸分析,将逃逸的变量创建到所有函数共享的全局空间中,这就是堆(heap)。

堆内存的释放复杂,像c语言需手动释放,忘记或多次释放都会带来问题,而像java、golang、js、python等是有gc机制能定期自动释放,这会导致性能下降,无法胜任系统级别和硬件编程。
8.5 IPC:进程间通讯

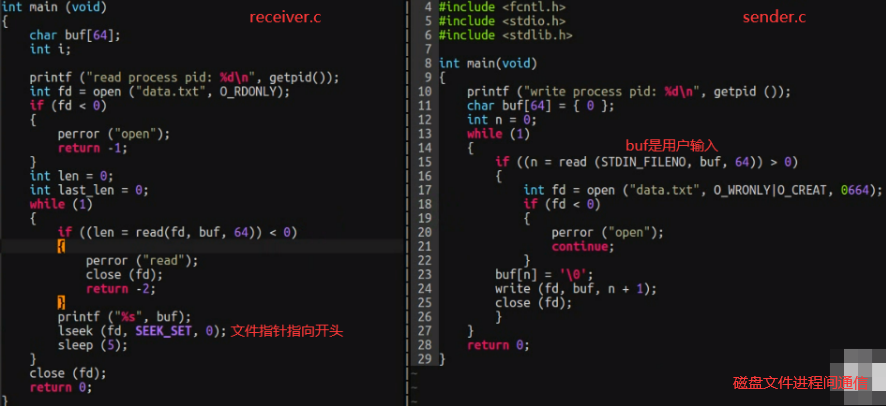

开机shift+f10,taskmgr:图形界面任务管理器。win下tasklist = linux下ps。

STAT就是状态state。


进程分类:实时/普通(压缩文件)进程。上下文切换:P1进程还没运行完,其中一些信息如程序计数器、变量、程序运行到哪了即context(执行环境,上下文)保存到内核的栈,P2再加载进来运行。调度算法:FIFO(first in first out)非抢占式,谁先来谁先被调度,缺点需等待长时间的进程执行完,其他进程才能分到CPU。STF(short time first)非抢占式,谁的进程时间短,谁先被调度,需要同时到达,不然缺点是长时间进程先到达,后面进程也要等待。STCF(short time complete first)抢占式,谁时间短先被执行,再切回去执行时间长的,缺点是如1000ms的进程一直被抢占导致3000ms才执行完,响应时间太长。RR轮询即cpu将1s分成很多时间片,把这些时间片分给每一个进程,1s多个进程是在并行的。
一个cpu多个进程,这些进程放在哪?用什么数据结构存储?进程队列:

进程优先级:不是每一个进程都有相同优先级。
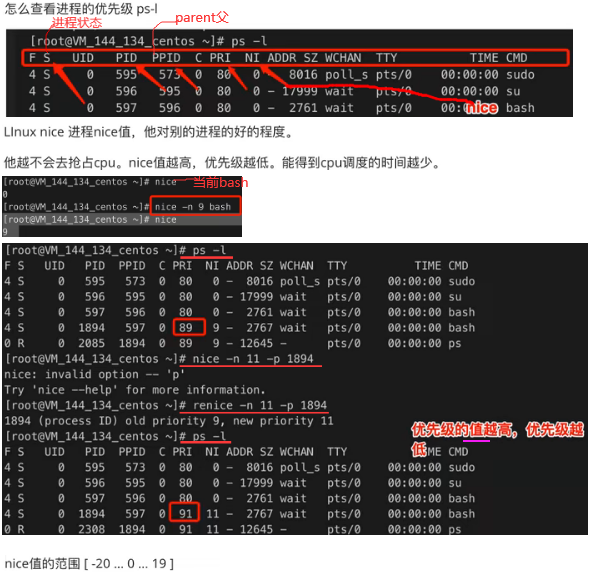

linux调度器:O(n)调度器即遍历进程队列,找到优先级最高的进程。O(1)调度器即优先级0-139映射成140个格子即0或1的bitmap,cpu找到1的格子去执行进程队列(链表或其他数据结构),和hashmap一样。
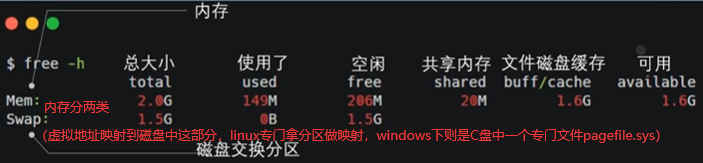
8.6 free -h:查看内存条:dmidecode |grep -P -A5 “Memory\s+Device”|grep Size|grep -v Range
如下free206M和available1.6G能用的是哪个?是1.6G。used包含shared,free是真正的空闲,没有任何东西在使用的大小。文件磁盘缓存指读过的文件暂时帮我们缓存到内存中下次再读的时候直接从内存中拿出来就能加速对文件读写操作。比如说现在free的空间只有206M,我有个程序要用1G内存,能用吗?能,buffer/cache这边1.6G中有800M扔出去释放掉+206M=1G给程序。
buff/cache中间为什么有个/,较早内核中free-h看分buffcache(以磁盘扇区为单位直接对磁盘缓存,从硬件扇区看缓存)和pagecache(以页为单位对磁盘文件缓存,从文件系统看缓存)两项。两项有重复的地方,文件本质也是磁盘,如缓存一文件,如果有buffercache再缓存pagecache重复,所以较新的内核中看就是合起来的buff/cache。
上面是linux内存,下面看window内存,34+29.4=63.4约64G。jprofiler监控java程序,也有Used size(如下红线)。分页缓冲池和非分页缓冲池(必须存在物理内存中,不能进行分页,也不能映射到磁盘的内存大小)是内核和一些驱动设备专用空间。
虚拟内存映射到物理内存,也能映射到磁盘中(linux中看到的mem和swap两个分区),这里已提交的69.2G=mem(物理内存64G)+swap(windows下不是swap分区,而是.sys文件,文件管理器下看不到,受系统保护)。
已提交:目前电脑上运行的所有程序向操系os申请了58G内存,但使用只有34G,原因:你申请了这么多,OS不一定给你这么多,比如C用malloc申请1G内存,假如只使用了1M,这时程序实际占用内存就是1M,剩下1023M你用到再给你,所以已提交大于使用中量,甚至说已提交的量可以大于整个OS内存大小如已提交1T(物理内存一共才64G),因为OS不会立即给你1T内存。
已缓冲:对应linux中buffer/cache即对文件的缓冲,已缓冲29.4G等于已缓冲上行可用的29.4G,可用的内存全用来缓冲磁盘的文件了。

8.7 brk:用户无法操作硬件如内存条,必须交给内核帮我们操作完了再把结果给我们
C语言中有sbrk库函数是对brk的一个封装,如下brk申请内存,内存是连续的,并不是说在堆空间随便找内存就把空间给你。
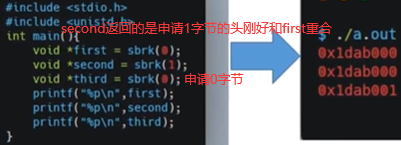
当前我们对第5,6,7,8四个字节赋int值123。只有第一个字节通brk申请出,却给第5-8字节赋值,这样会不会报错呢?不会,主要原因是在上节讲到的操系内存的分页管理所导致的,也就是说brk申请内存申请最小单位为1页,一般系统中页大小4k,所以brk看似申请1字节其实申请了一页(4096个字节),所以第5-8字节也属于4096字节里,也是当前进程所能支配的内存,所以不报错。
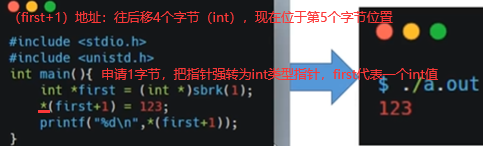
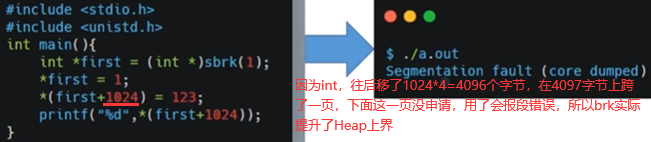
如下+号相当于向后移动1024个int,如下报段错误。
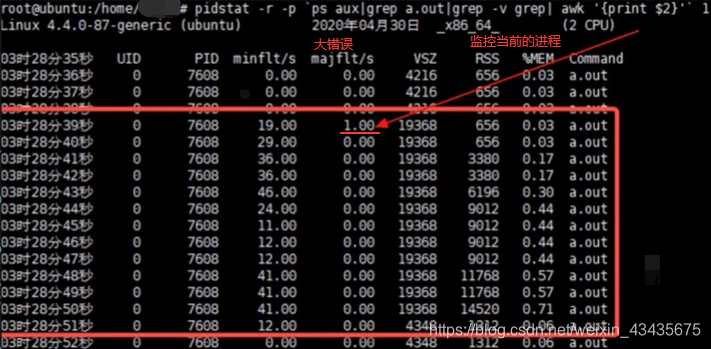
8.8 mmap:pidstat,缺页缺的是内存还是磁盘
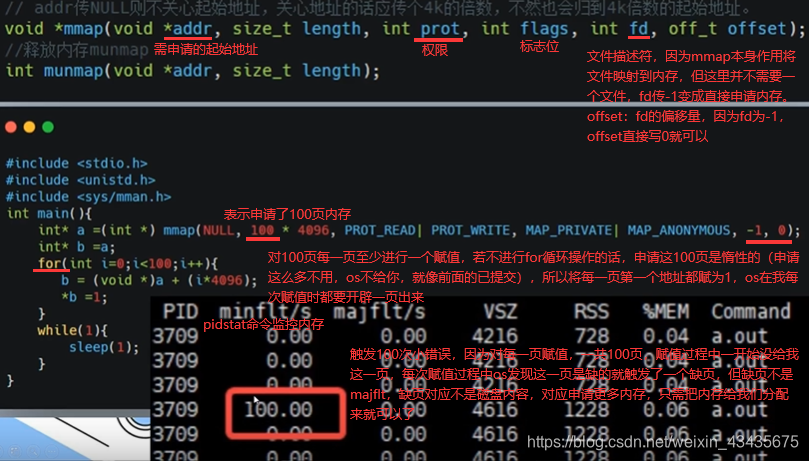
mmap还有直接将磁盘文件映射到内存作用,类似read,不是malloc。
如下触发大错误因为对文件的映射,将文件映射到内存,也是惰性的,这文件没有直接读到内存里,而是当真正需读文件里内容时才会映射到内存里。第一次触发是上面for循环里打印文件内容时到内存中读,发现这一页在查页表时对应是磁盘就触发一个缺页错误,对应是磁盘,触发majflt,将磁盘内容加载到内存中,之后就是一些小错误了。-p:指定进程号。-r:显示各个进程的内存使用统计。grep -v grep过滤掉包含grep的行。最后1是输出1次信息。
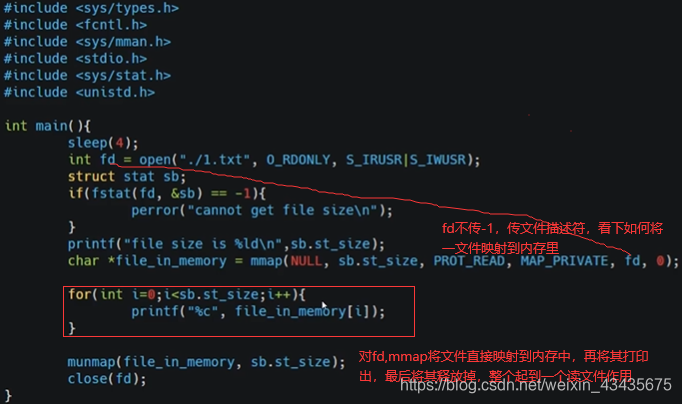
mmap和普通的fread(库函数)或read(系统调用)读文件有什么区别呢?read系统调用进入内核态,内核态将文件内容加载到内核空间(如下kernel space),内核空间给它复制到用户空间,再从内核态切换到用户态,然后用户的程序就可读到文件的内容了,有个文件-内核空间-用户空间周转过程。
mmap直接将文件进行了映射,一开始在页表中填充的是磁盘disk即FILE文件,一开始mmap是惰性的直接对应磁盘文件,真正读取时触发缺页将文件加载到内存。mmap是实现0拷贝技术一种方式(sendfile系统调用也是0拷贝)。这里的共享是简单的共享,只是说内核空间对应页表中的k对应value和用户空间k对应value是同一个值且都映射文件所对应的物理内存,看似达到共享效果但跟进程间共享内存不是一个东西。
mmap这么牛干嘛还用read函数?mmap虽减少了内核空间到用户空间拷贝,但mmap没法利用前面讲的buffer/cache对文件缓冲这么一块空间,而且mmap第一次触发的缺页异常耗时不一定比read少。
9.JVM内存5区:jvm即java二进制字节码的运行环境,好处:一次编写,到处运行。自动内存管理和垃圾回收功能。数组下标越界检查。多态。

9.1 栈和栈帧:线程安全
栈内存就是一次次方法调用产生的栈帧内存,栈帧内存在每次方法结束后被弹出栈自动回收掉,不需要垃圾回收管理栈内存,垃圾回收只回收堆内存中无用对象。栈内存大小可通过运行代码时虚拟机参数指定,栈内存划的越大反而让线程数变少,因为物理内存大小一定的,一般采用系统默认栈内存大小。

如下一个线程对应一个栈桢,不会产生安全问题。


如下不加线程保护的话会产生安全问题。

如下只有第一个线程安全。

栈帧过多(内存溢出):方法的递归调用没有设置正确的计数条件导致递归爆栈。栈帧过大(很少出现):栈帧里都是些局部变量,方法参数,占用的内存都很小(一个int变量4字节,默认栈大小1M左右)。

9.2 逃逸分析:开启逃逸分析即将最后参数删除,几次GC后停止了。如果不是只在当前函数范围用到的对象不行
堆:new的对象一般在堆上创建。特例:逃逸分析:jvm在分析代码后发现一个对象在声明后只有在当前运行的函数中调用,那么就会将这个对象在栈上申请空间而不是在堆上,这就是jdk6出的逃逸分析。因为在栈上申请的对象,函数执行完后会直接清理,这样大大减轻了GC的压力。


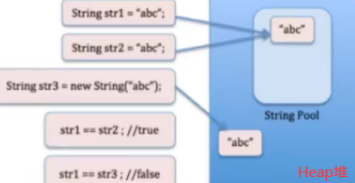
Boolean、Byte的所有对象,都是预先创建好的(类加载的时候)。Character、Short、Integer、Long是-128~127的对象是预先创建好的(Character没有负数)。
现象:new Integer(1)则是从创建好的缓存中,直接拿出,因而是同一个:错,new的是新的对象,原因:为了节省内存,这些数字使用概率很高,早就创建好,之后都用同一个,是提高效率的做法。

如下是值传递(复制一份值一样的)相关的函数运行过程和内存调用,main函数在栈底。
如下是对象类型。func1结束后栈上清空了,但是堆上怎么清空呢?引出GC。main函数静态存方法区。java基础数据类型都是值类型,指针也是值类型,因而直接存到内存,不是存地址去寻址。

如下引用类型传地址,和上面形参a不同。
如下VRD。DOS窗口是win下黑窗口,查看当前目录(文件夹)下所有内容dir,清除控制台cls。

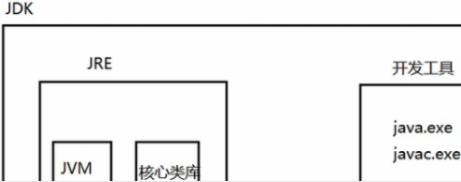
10.VMware/CentOS/CRT:两个网络适配器是虚拟机的,Linux抄袭unix,Mac os是unix的皮肤
10.1 VMware/CentOS:netstat -anp|grep ssh,vi /etc/ssh/sshd_config放开Port 22,service sshd restart,chkconfig可将sshd加入到系统服务中开机后sshd将自动启动:chkconfig sshd on
VMware15和CentOS6.9:链接:https://pan.baidu.com/s/1HV6WqUTAwlOSjWkLXVrCRw ,提取码:1x8e 。VMware15【CG392-4PX5J-H816Z-HYZNG-PQRG2】直接下一步安装。右击图标属性-兼容性-更改所有用户的设置-勾上以管理员身份运行此程序。仅主机模式(Host-only)网卡默认192.168.56…,NAT网卡默认10.0.2…。
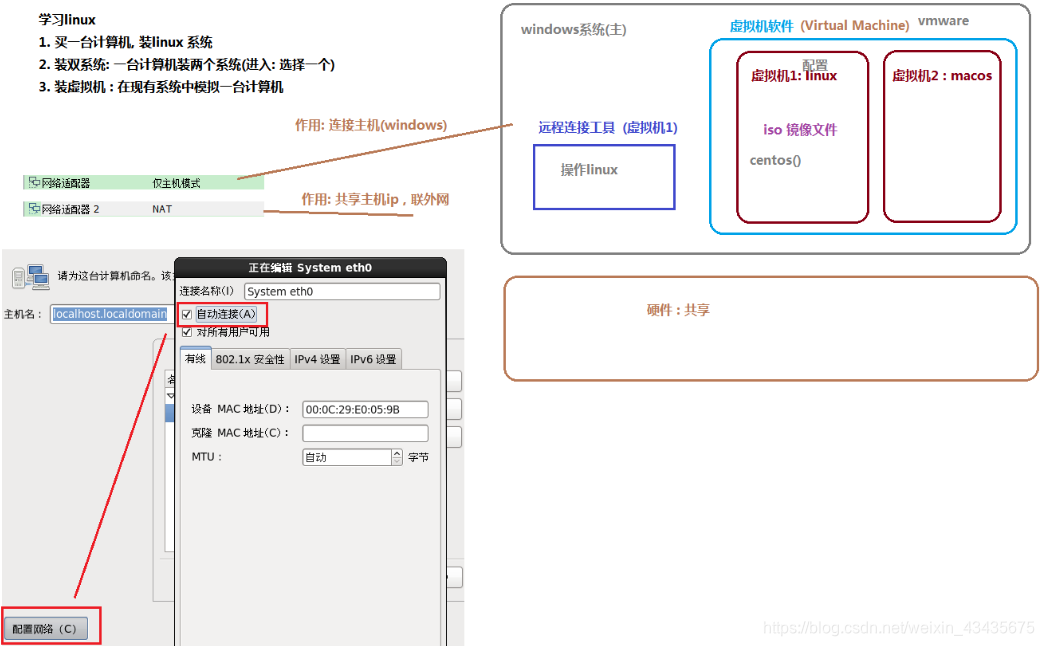
1.点击创建新的虚拟机:自定义(高级)-稍后安装操作系统-linux-版本centos6 64位-D:\vm.\cent0s6-使用仅主机模式网络-将虚拟磁盘存储为单个文件(动态分配20G硬盘)。
2.编辑虚拟机设置:选中网络适配器添加-CD/DVD使用CentOS6的iso文件(开启此虚拟机出问题:控制面板-卸载程序-Microsoft Visual C++的两个x64和x86文件右击卸载,不点卸载,点修复再重启计算机)。
3.开启虚拟机安装操系:默认第一个install,方向键选择红色的Skip(跳过)回车。两个网卡注意要配置网络自动连接。使用所有空间-将修改写入磁盘-Basic Server。鼠标退出虚拟机用ctrl+alt,将一个小窗口移至虚拟机前就可以用QQ截图。
NAT网络模式:多台虚拟机和宿主组成一个小局域网,之间都可互相通信,虚拟机也可访问外网,如搭建hadoop 集群,分布式服务。桥接网络模式:只需要一台虚拟机可以和宿主互通,并可以访问外网。如果不需要锁定静态IP(如hadoop不锁定IP很麻烦),那跳过下面步骤。如下同理本地回环配置文件 /etc/sysconfig/network-scriptis/ifcfg-lo。ifdown/ifup关闭/启动etho网卡。



10.2 CRT:netstat -nal | grep 22
安装:改注册信息要打开CRT客户端在最上端Help栏中Enter License Data
ssh客户端软件SecureCRT8.5:链接:https://pan.baidu.com/s/1Y74YVz2ysQ3rFjGjnthb1Q ,提取码:l8gb 。解压后如下所示:
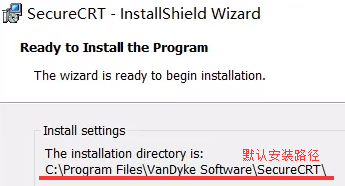
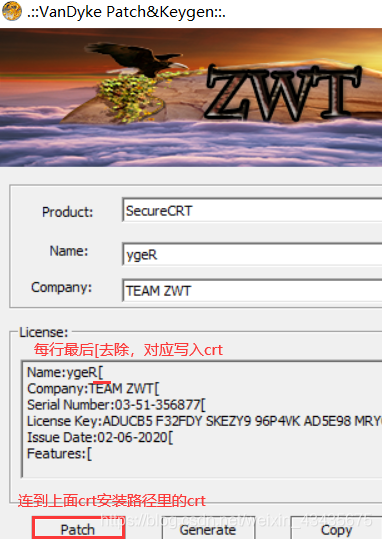
右击以管理员身份运行上图的scrt…exe文件,安装完后桌面出现图标先不要点击运行,将上图注册机文件夹里的keygen.exe复制到下图默认安装路径文件夹中,并右击以管理员打开keygen.exe出现如下图黄色窗口。
在如下License中不用去除中括号,写入SecureCRT.exe中去除,Patch连到SecureCRT.exe和LicenseHelper.exe。
第一次打开下图进行填写注册信息按照上图黄色窗口对应写入,上面patch到就是下面这个.exe文件。
配置:SSH2。Hostname:192…。Port:22。Username:root
配置会话的属性,在会话上点击属标右键,选择Properties的Terminal。每30秒向服务器发送一次心跳。

分清Hostname,Username,Name。
修改Centos的字符集,增加对中文的支持: 登录服务器,输入 su – root 回车后再输入密码,切换到root用户(超级用户,有的远程服务器没权限)。修改字符集:echo LANG="zh_CN.gbk" > /etc/sysconfig/i18n。export LANG="en_US";export LANGUAGE="en_US";export LC_ALL="en_US";。
修改时区为亚州上海时间,在root下执行并输入y:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime。date (不是data)查看系统时间:date -s修改时间,date -s 2019/07/31,date -s 10:24:00 。date -s ‘2020-01-01 11:11:11’。
11.Linux命令:linux组成:内核(就是操作系统,和硬件打交道,驱动)。shell(和用户打交道,用户指令翻译成机器码给内核)。文件系统(文件组织方式,linux没有盘符,有目录/文件/链接link)。应用程序
win下任务管理器中explorer.exe进程(是Windows程序管理器或文件资源管理器,它用于管理Windows图形壳,包括桌面和文件管理。删除该程序会导致Windows图形界面无法使用)kill掉就不用重启安装软件时,cmd重新explorer.exe执行。
/usr/bin里是系统预装的可执行程序,会随着系统升级而改变。/usr/local/bin是给用户放置自己的可执行程序的地方,推荐放在这里,不会被系统升级而覆盖同名文件。/etc存放的是管理文件用的相关配置文件,比较重要的 /etc/rc,用户信息文件/etc/passwd:
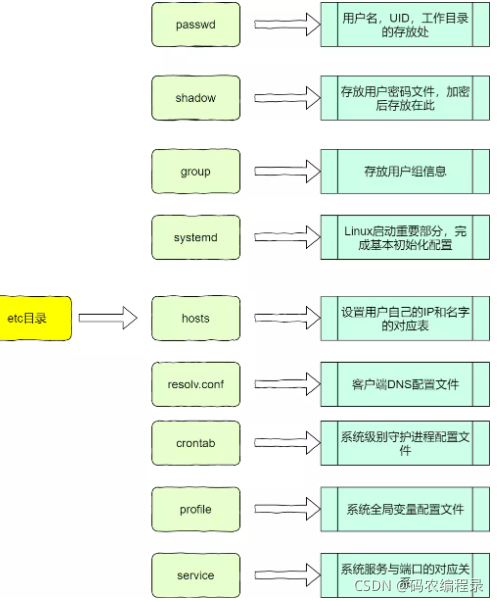
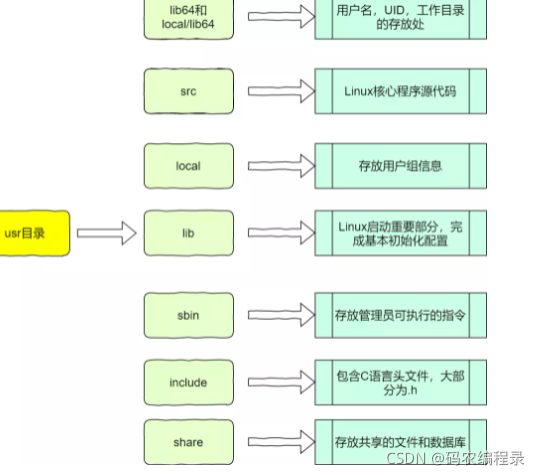
/usr(Unix System Resource,不是User)放的是应用程序和文件,如果在安装软件的时候,选择默认安装的位置,通常就会默认在这个位置:
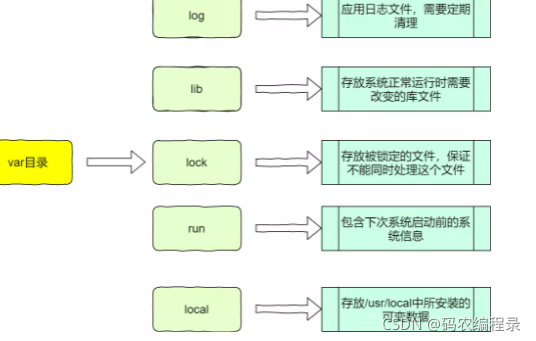
/var用来存放系统运行的日志文件:
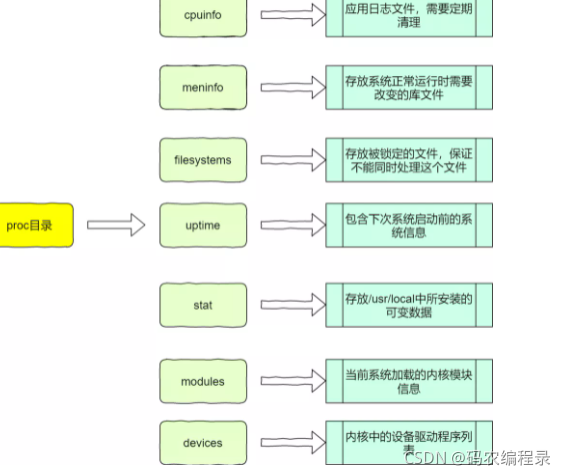
/dev包含所有的设备文件。/proc是虚拟目录,主要存放的是内存的映射,通过这个目录和内核的数据结构打交道比如修改内核参数,获取进程的相关信息:
/boot存放了启动 Linux 的核心文件,包含镜像文件和链接文件,破坏后系统基本上就不能启动。/mnt是移动设备文件系统的挂点。
/bin/sbin当你装相关的软件或者安装包后,很多时候都会链接在这个目录下面,另外这里也存放了平时我们用的各种shell命令如 cp,ls,dd等。对于sbin,这里的s是super 的意思,意味着需要超级用户才能执行的命令。常见磁盘分区fdisk,创建文件系统的mkfs就在这里。
/lib开发过程中,共享库文件等很多放在这里,这个目录会包含引导进程所需要的静态库文件,对于用户和系统来说“必需”的库(二进制文件)。/usr/lib一般存放的只是对用户和系统来说“不是必需的”库(二进制文件)。
/lost+found保存丢失的文件。什么意思,如果我们不恰当的关机操作,可能导致一些文件丢失,这些丢失的临时文件可能就会存放在这里。当重新启动的时候,引导程序就会运行 fsck程序并发现这个文件。
11.1 关机/重启/注销

11.2 系统信息和性能

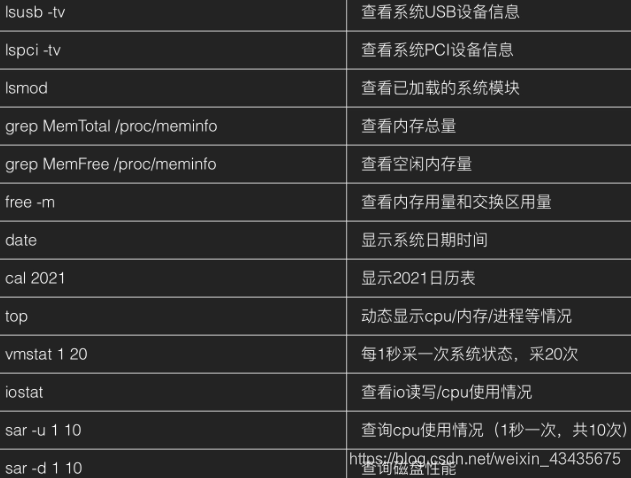
11.3 磁盘和分区

11.4 用户和用户组
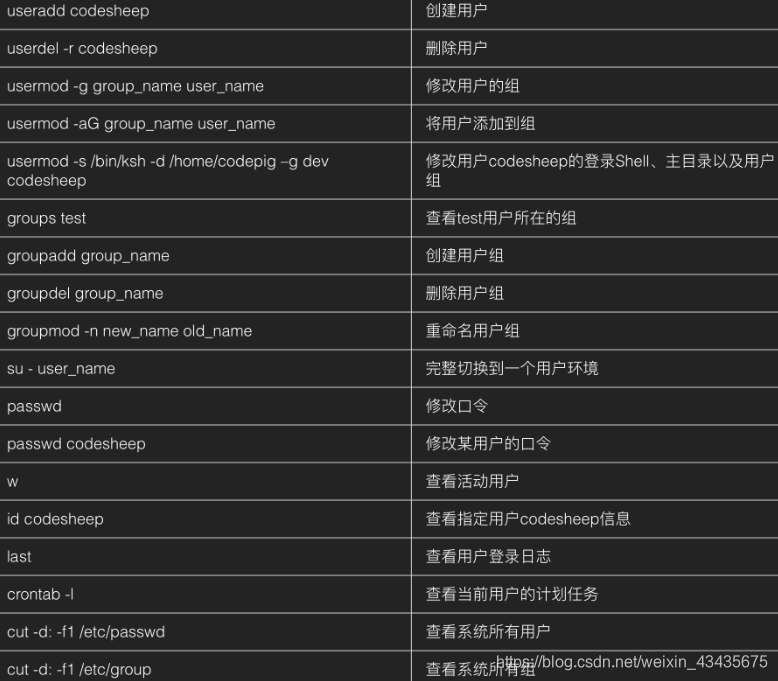
11.5 网络和进程管理
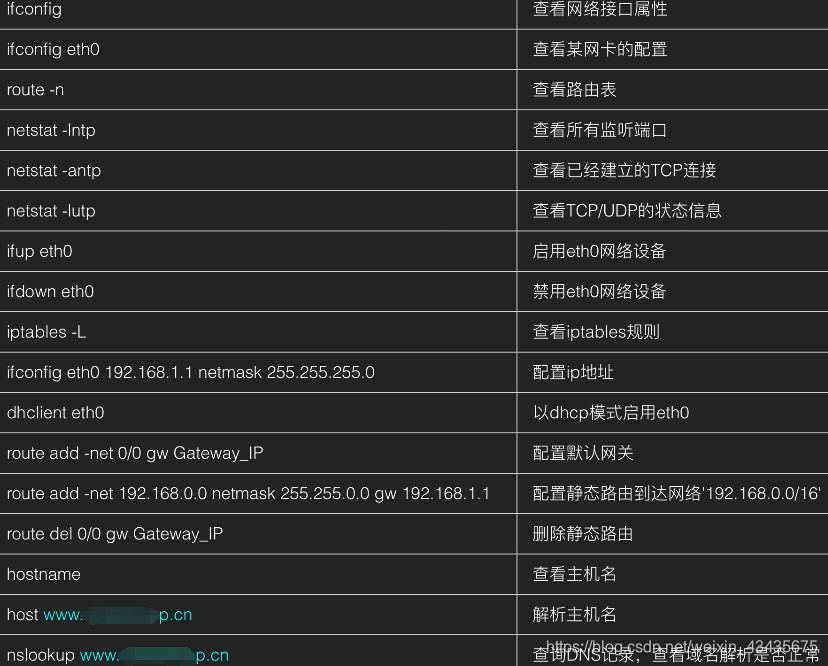
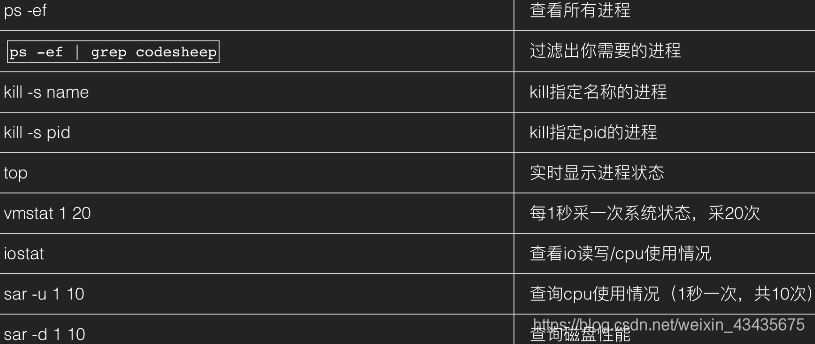
11.6 系统服务



11.7 文件和目录
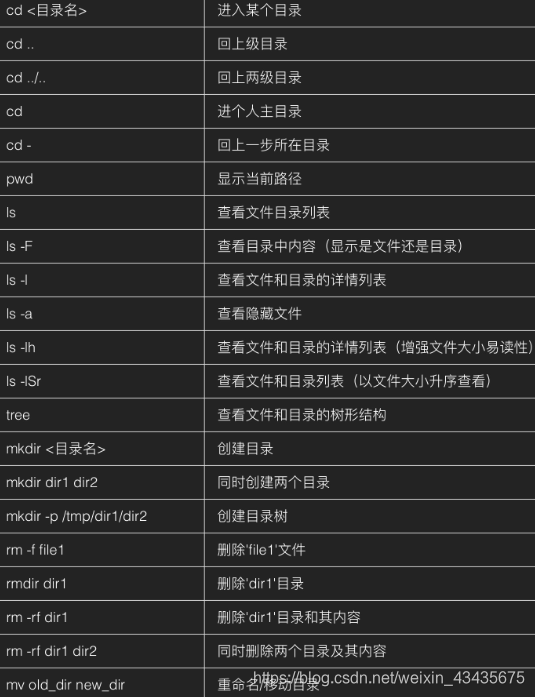

11.8 文件查看和处理
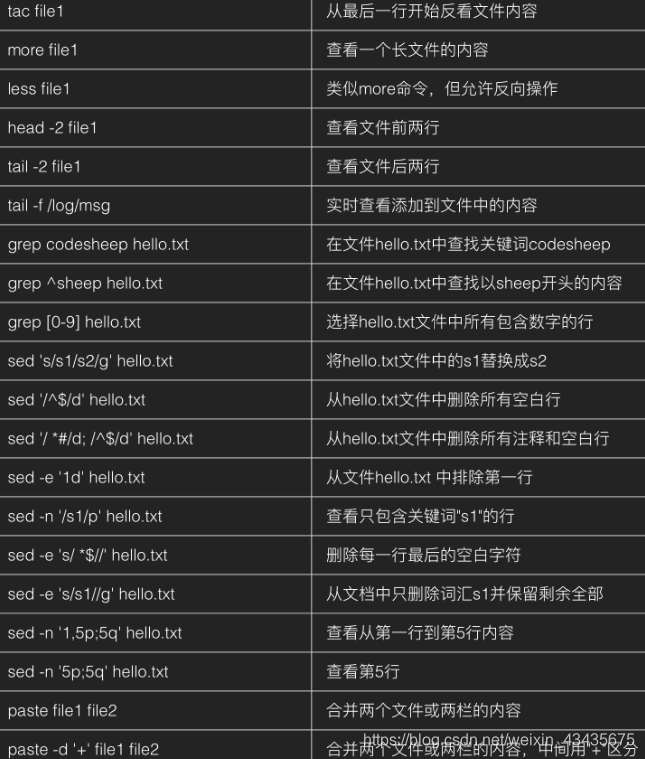
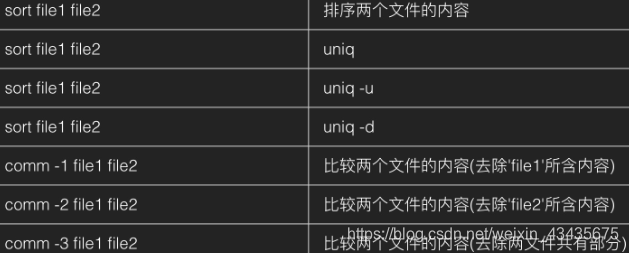
11.9 打包和解压
tar只是打包,并不压缩或解压。
-c: 建立压缩档案
-x:解压
-t:查看内容
-j, --bzip2
-z, --gzip, --gunzip --ungzip
-v, --verbose 详细列出处理过的文件
-f, --file ARCHIVE 使用存档文件或设备存档(指定存档文件),切记,这个参数是最后一个参数,后面只能接档案名。tar命令必须和-f命令连用, 在选项f之后的文件档名是自己取的,习惯用.tar 来作为辨识。 如果加z选项,则以.tar.gz或.tgz来代表gzip压缩过的tar包。
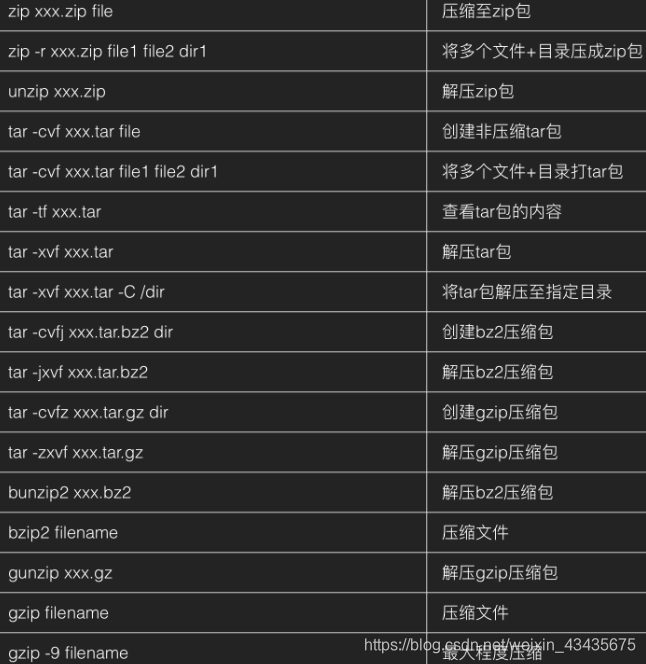
11.10 RPM包管理
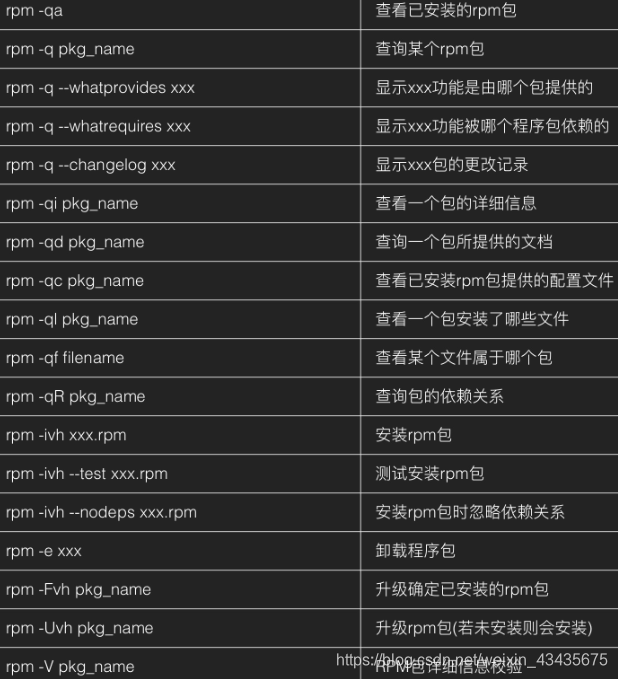
11.11 YUM包管理

11.12 DPKG包管理

11.13 APT软件工具

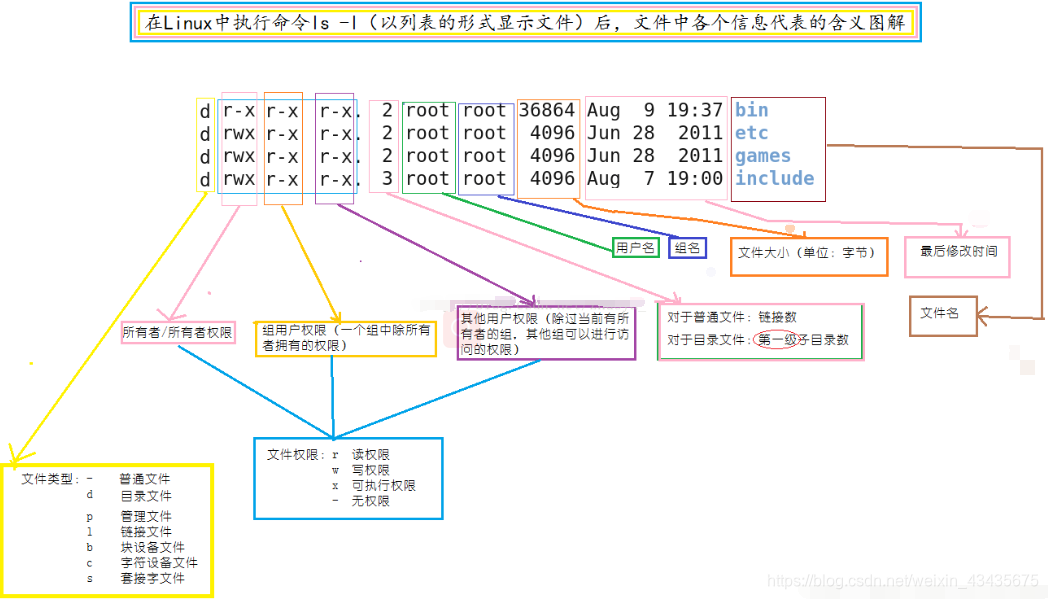
11.14 用户管理及权限
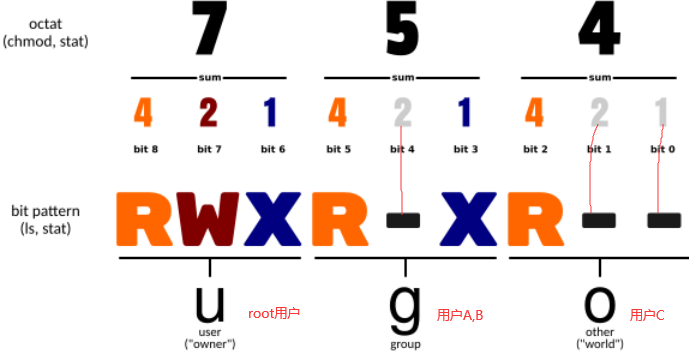
如下文件类型p是指管道文件。
查看几个文件的内容差异:diff -c file1 file2。
将a.txt每5行分割为一个文件:split -5 a.txt。
nohup java -jar a.jar & ( jobs命令查看这个后台任务的编号 )。
netstat -ntlp查看运行程序的端口。
kill -9 %1(这个1就是jobs命令的1编号)。
tcpdump数据包获取,nc网络调试,vmstat进程信息和内存使用。
11.15 sed:管道过滤(替换,删除)
如下将逗号替换为空格。s表示替换,g表示全局,即行中所有匹配项都被替换。sed -i ‘s/sys_led/sys_url/g’ /home/sysfs1/s3ip_sysfs_frame/sysurl_sysfs.c。

^匹配行首,$匹配行尾,如下d删除空行或只包含空格的行(因为行首行尾中间为空)。

sed常用于管道过滤,如下把x替换成y。

如下-r打开扩展正则,将逗号换成TAB。

11.16 awk:-F指定分隔符,-V设置变量,NF列数,$NF是一行数据最后一列的值,多用于对字段(像数据库中的字段)
如下按逗号分隔并打印分割后的第三列和第四列。

如下BEGIN指定了处理文本之前需要执行的操作。END指定了处理完所有行之后所需要执行的操作。

如下按逗号分隔并打印最后一列内容。

对比上面,如下一行一行读取并打印,列数>0打印。


如下-c统计个数。

2是个数,不是序号。


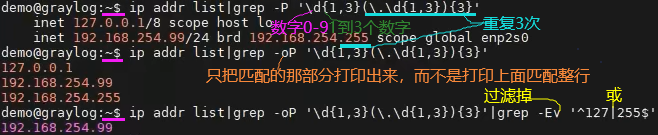
11.17 grep:元字符即\d,\D这些是Perl正则-P,扩展正则-E

如下.中的\是转义符,.168这样重复3次(注意168前面有.)。

12.vi命令:三种(命令行[Esc],编辑[i],底行[:wq])模式切换
1.插入:以下命令都在命令行模式下。

2.上下左右:j下,k上,h左,l右。
3.翻页:

4.跳光标:


5.删字符和行:


6.复制粘贴:


7.替换:


8.撤,接:


9.行,找:



10.重复,大小写:

11.存盘:


12.列操作::%d删除文件整个内容。

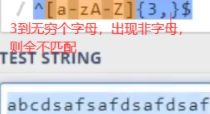
13.正则:\d,?* +这些是[a-z]{m,n}这些的简写
^:整段字符串开头。$:整段字符串结束。^[]$:中括号内部可匹配一个字符。
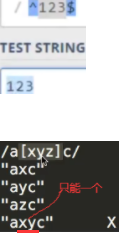
如下自己输入1,1蓝色阴影则匹配。
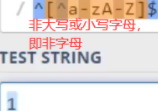
\d:相等于[0- 9],中括号里是什么或什么。
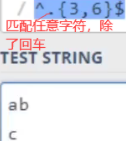
\D:相等于[^0- 9],除了0到9外的任意字符。如下匹配 数字\d 或 数字外任意字符\D,也就是匹配任意字符。
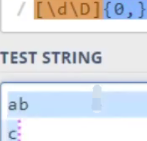
\w:字母,数字或下划线,常用于互联网用户名的命名上。

如下两个等价。
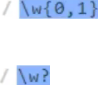
如下两个等价。
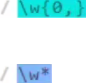
如下两个等价。
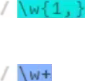
如下是邮箱的匹配规则。
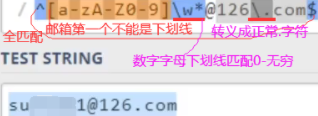
组group:如上只想获取@前面的用户名,上面中括号,大括号都出现了,就差小括号
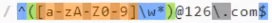
如下1就是组1。

如下first就是组名,右边是js语法,groups显示underfined因为没命名。
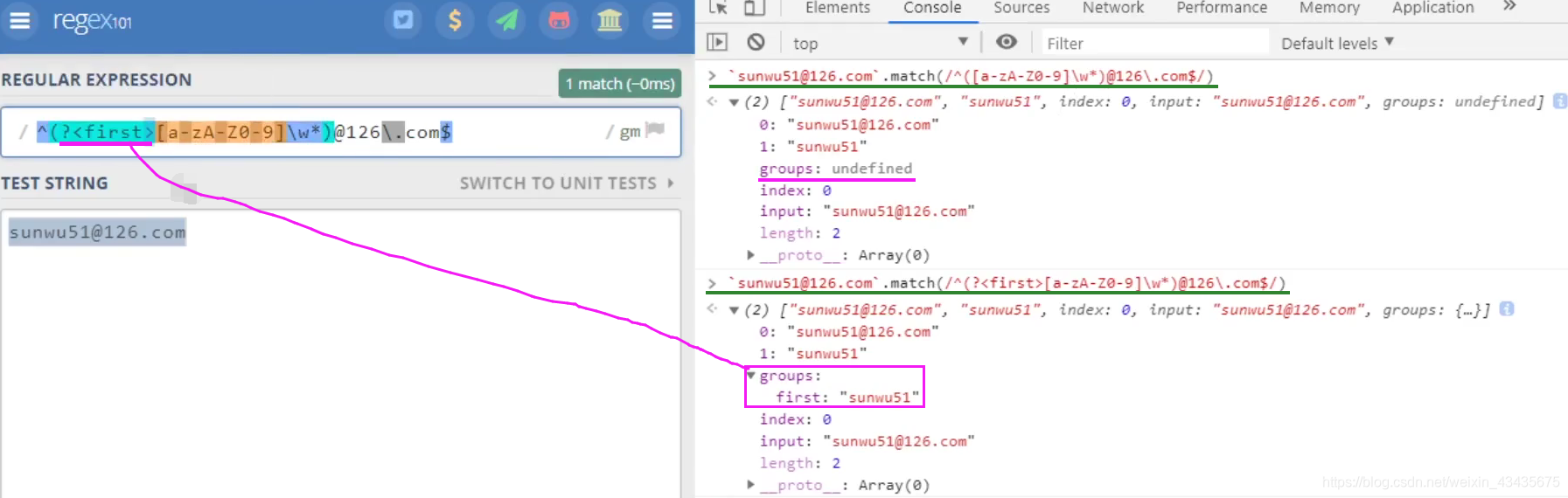

b = ‘hello good fine’,group(1)会返回正则表达式中第一个括号内的内容,group(2)第二个括号。
14.iNode:磁盘中块和扇区
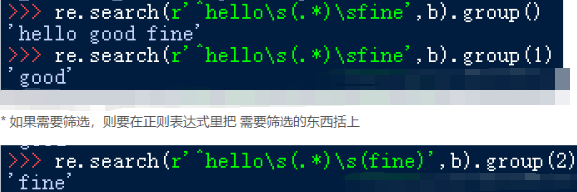
linux文件系统中iNode用来存储文件原数据信息,不存储文件内容,原数据信息包括:
类型:这个文件是个目录还是普通文件。
拥有者:这个文件是owner还是group owner。
时间:ctime:上次inode变动时间。atime:上次访问时间。mtime:上次文件内容发生变动时间。
连接数:有多少文件名同时指向inode。一个文件名只对应一个inode,但一个inode可能被多个文件名同时指向。
文件内容所在的位置:文件真正内容所在磁盘块的标号。
1.文件系统fs在格式化好后,inode以什么样格式存储的呢?整个inode以数组形式存储,每个元素是一个inode,每个inode大小根据当前文件系统以及整个磁盘大小,inode会有一个固定128或256字节大小。
2.除了inode数组,fs初始化好后还会生成一个Map映射关系表(存储filename和inode index)。现在要读取/ect/1.txt,整个过程怎么样?先根据文件名到Map中找到inode index,找到下标为假如是3的inode后拿出来如下图左边整个框。当前在读取/ect/1.txt,所以查看是否有读权限,如果有读权限就继续往下,找到文件内容所在位置(磁盘上块的下标)。
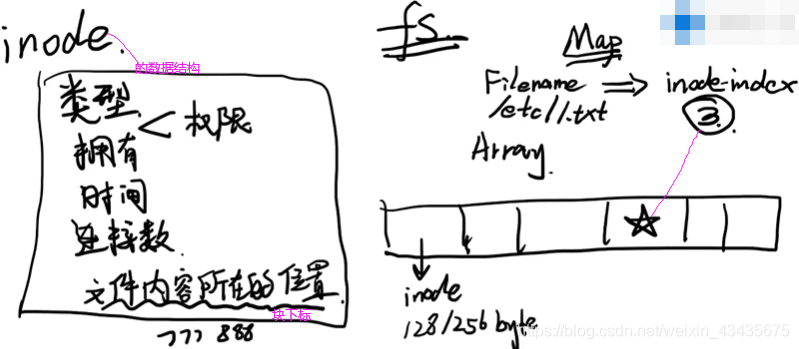
文件内容在磁盘中存储区域如下:以块进行分隔,每个块大小也是根据当前fs和整个磁盘大小决定,并不是一个特定大小【扇区在磁盘生产时有多少个扇区,每个大小是定的,早期扇区512byte,现在4k】。文件系统fs在文件访问过程中不可能直接使用扇区,扇区是硬件的概念,所以抽象出一个概念:fs角度去看最小文件存储单元就是块,一个块可以有一个或多个扇区组成(2的幂次方即1,2,4…个扇区)。

一个块采用多少扇区也是有权衡的,比如一个块有好几兆,存一个1k文件也要占一个文件块,造成磁盘空间浪费。块选择过小的话也不好,如果一个块大小1bit,导致一个文件假如是1kb,它所在的块由1千个块组成,在inode中存储文件内容所在位置这个字段时候造成存1千个块信息(1千个块下标),一个inode(存1千个块下标)不可能128/256字节大小了,一个inode会很大,进而导致inode数组会很大,整个inode区大,这样导致磁盘损耗大量空间存储inode信息,较少的空间存储真正文件内容。
即使进行权衡,目前存在问题,如经常听到inode用完了即inode数组初始化大小用完了,声明完数组大小后不能增加或减少了。inode数组用完了即使磁盘还有额外空间也不能存储文件了,常见特别零碎文件数量又特别多占据磁盘大量inode导致整个inode用完。如早期docker采用overlay文件存储格式导致镜像的碎文件很多,导致inode用尽这样问题,后面采用overlay2文件存储格式一定程度上解决了这问题。
查看linux系统中inode数组以及每个文件所对应inode标号:df -i(inode),查看当前文件夹下文件所在的inode标号是什么ls -il。访问1.txt先查文件名和inode标号映射即Map,1.txt能找到270306这个标号。根据这个标号到1183200这个数组中拿取第270306个标号的inode。根据这个inode信息查看权限,最终找到1.txt在磁盘中存储位置,最后把这些磁盘块进行读取,最终读取到1.txt这个文件。
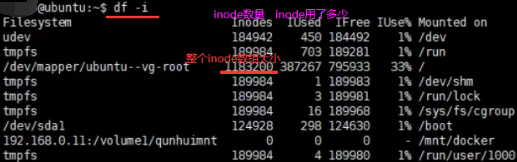
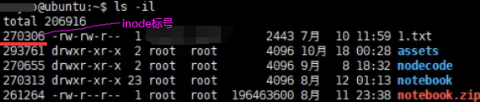
如果是一块移动硬盘,在其他设备上创建了文件 把这个移动硬盘拿到linux上面,有没有inode呢?
1.os可以支持多种fs。2.inode是在ext2/3/4等linux支持的文件系统(fs)有的。所以移动硬盘看是什么文件系统了,如果是ntfs或者exfat、fat32等等就是另一种访问形式了,inode其实是文件系统里的概念,而不是linux的概念。
15.文件查找与读取命令:C语言中‘\0’(对应的ASCLL码值为0)表示的空字符
15.1 find:找文件
过滤一下看文件大小:-print0将如上三行打印为1行并用null即‘\0’隔开,再用xargs -0即用‘\0’再分开(原因是默认管道到下一个里面空格会出错)。

如上/是整个系统搜索慢,如下是当前路径搜索快。

日志文件没清空非常大,要找到删除,如下找系统中大文件,超过10M。

如下查找文件夹,文件夹有相应名字或大小属性。

如下基于修改时间,time是天。-1:今天一天之内。1:1天前这一天。+1:1天前。



如下指定最大文件深度。

如下是find指令总结。

15.2 grep:找文件中内容
echo “aa” >> 1.txt,追加内容。cat -n 1.txt(行号:number)。grep “a” 1.txt。

如下* 可换成 * .txt。

-r:递归子路径,-n:显示行号。-i:忽略大小写。

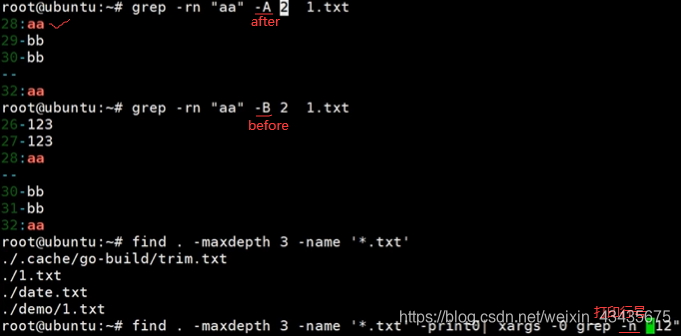
如下用于java日志文件非常大,要grep出某个异常如ioexception,且需要打印出exception下面几行看什么出了错。
15.3 cat/more:查看文件全部内容
cat的文件非常大,非常占用cpu和内存,这时候可以每次读取一小部分。
如下通过空格往后翻页。

如下指定从第四行开始读。

如下查看前后10行。
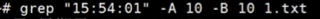

15.4 head/tail:查看文件部分内容

如下打印文件最后两行,tail -f 阻塞监控。

df -h查看磁盘使用,占用率太高就需要使用前面find,grep指令并进行删除。
如上找出占空间的文件夹再去里面找。

题目:输出当前路径及当前路径子路径下所有.txt文件,要求大小超过1M,并且按照从大到小顺序进行排序输出前10个?
先通过find . -name '*.txt' -size +1M -type f 查看是否有大于1M的txt文件,没有的话就不用继续了。
再通过find . -name '*.txt' -size +1M -type f -print0|xargs -0 du -m|sort -nr|head -10。
16.Linux下开机自动重启脚本:/etc/rc.local,Crontab,Systemd
$ crontab -e:@reboot sleep 300 && /home/wwwjobs/clean-static-cache.sh(在启动 5 分钟后运行指定脚本)
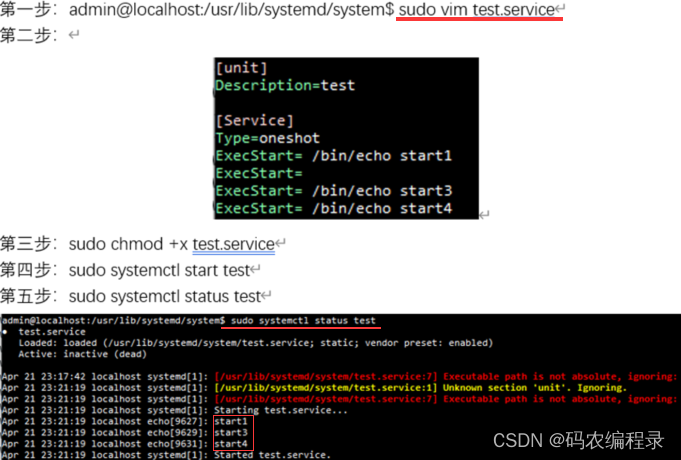
update-rc.d管理: mv new_service.sh /etc/init.d/,cd /etc/init.d/,sudo update-rc.d new_service.sh defaults 90(90表明一个优先级,越高表示执行的越晚)。在/etc/init.d目录下的可执行程序的优先级会高于/etc/systemd/system/下的.service文件(如果同时存在)。
serivice xxxx start|stop|restart相当于是对/etc/init.d下的xxxx的封装,相当于是一个管理命令,实际执行的是/etc/init.d下的可执行程序。如果/etc/init.d下没有该服务的可执行程序,则使用.service文件。
# 做了一个可执行脚本(xxxx),将它放到了/etc/init.d/目录下, $ sudo /usr/sbin/update-rc.d -f xxxx defaults# 提示:
# perl: warning: Setting locale failed.
# perl: warning: Please check that your locale settings:
# LANGUAGE = "en",
# LC_ALL = (unset),
# LC_CTYPE = "zh_CN.UTF-8",
# LANG = "en_US.UTF-8"
# are supported and installed on your system.
# perl: warning: Falling back to the standard locale ("C").
# Adding system startup for /etc/init.d/xxxx ...
# /etc/rc0.d/K20xxxx -> ../init.d/xxxx
# /etc/rc1.d/K20xxxx -> ../init.d/xxxx
# /etc/rc6.d/K20xxxx -> ../init.d/xxxx
# /etc/rc2.d/S20xxxx -> ../init.d/xxxx
# /etc/rc3.d/S20xxxx -> ../init.d/xxxx
# /etc/rc4.d/S20xxxx -> ../init.d/xxxx
# /etc/rc5.d/S20xxxx -> ../init.d/xxxx# 重启系统后发现脚本没有自动执行,还是要手动
# /etc/init.d/xxxx start# 解决:自己的东西。最好rcS.d里面
17.Linux系统启动过程:ukr,ubuntu开机引导文件/etc/default/grub
如下cpu发出mov指令告诉内存把300那地方的东西取出来放到777显存地址上。
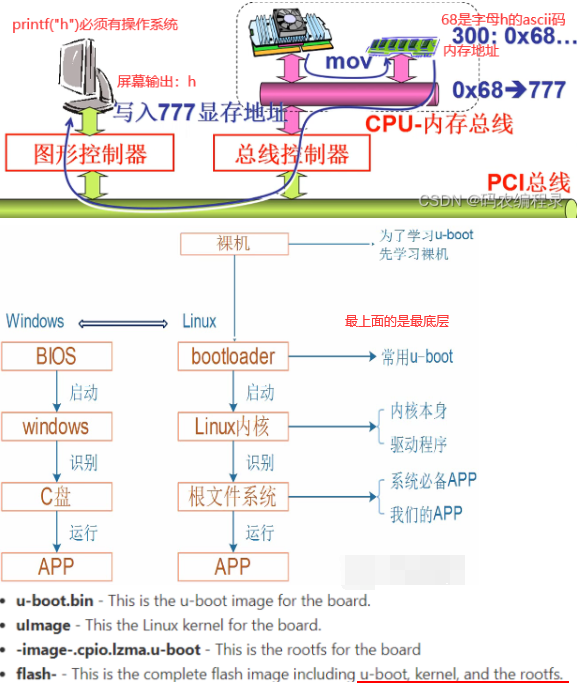
内核(=操作系统)怎样启动第一个应用程序:1.open(dev/console,printf/scanf/err)等设备文件,2.run_init_process函数如下。
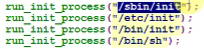
init进程:是加载内核镜像文件后第一个进程,是Linux的根进程,所有的系统进程都是它的子进程。运行级别:0(init0关机),1(单用户模式,只允许root用户对系统维护),2到5(多用户模式,3为字符界面,5为图形界面),6(init6重启)。
busybox:ls这些命令相当于应用程序(可执行二进制文件),成千上百个命令,源码找来再编译,显然很费事。busybox是这些命令的组合。想确定init进程做了什么事就要看busybox的源码。在kernel挂载根文件系统后,运行的第一个程序是根目录下的linuxrc,实际是一个指向/bin/busybox的链接, 也就是说系统起来后运行的第一个程序是busybox本身。busybox首先解析/etc/inittab这个进行初始化的配置文件, 然后调用/etc/init.d/rcS, 最后是执行/etc/profile(/etc/profile.d , ~/.bashrc , ~/.bash_file)。


18.编译u-boot 2019.10和linux-kernel 5.3.6并用busybox打包根文件系统:在全志H5芯片上启动起来

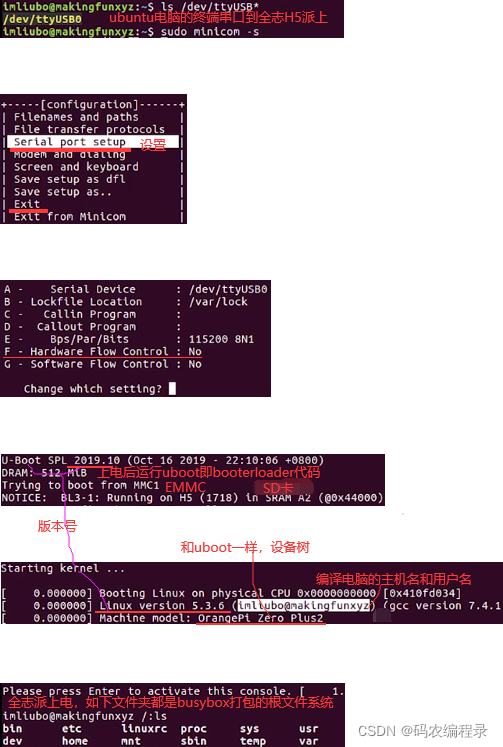
18.1 u-boot:._defconfig文件生成.config文件再make编译

如下链接是gcc(用来编译uboot)。


nano .bashrc

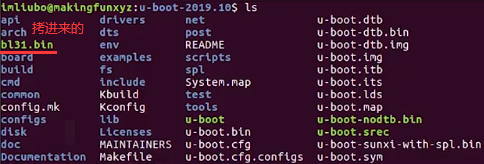





执行如上后,把SD卡从读卡器拔下插到派上。
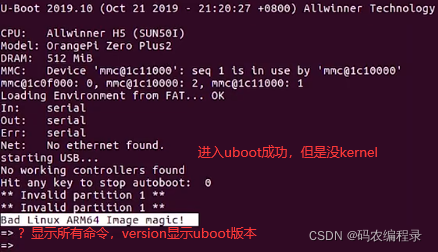
18.2 kernel:先make config再make生成文件拷进去
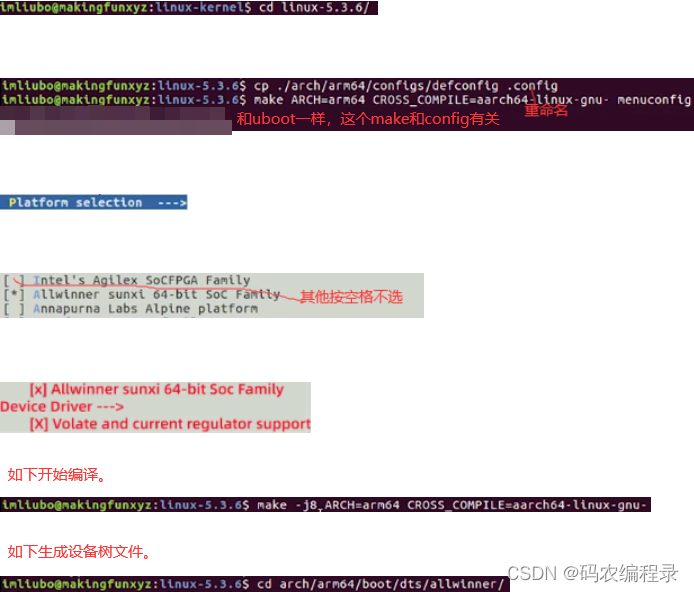
如下.dtb就是设备树文件,是编译出来的,.dts是原文件。




18.3 busybox:先make config再make,make install,创建文件







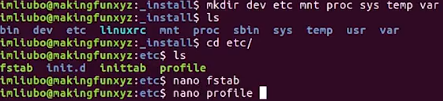
如上创建了文件夹,把所有东西打包进来。



如下etc文件夹里都是自己创建的。








如上拔出SD卡,插入到派上。



相关文章:
【Note5】网络,并发/IO,内存,linux/vi命令,正则,Hash,iNode,文件查找与读取,linux启动/构建
文章目录1.局域网:CSMA/CD2.互联网:ARP,DHCP,NAT3.TCP协议:telnet,tcpdump,syn/accept队列4.HTTPS协议:摘要(sha、md5、crc)。win对文件进行MD5校验用自带的c…...
华为MRS_HADOOP集群 beeline使用操作
背景 由于项目测试需要,计划在华为hadoop集群hive上创建大量表,并且每表植入10w数据,之前分享过如何快速构造hive大表,感兴趣的可以去找一下。本次是想要快速构造多表并载入一些数据。 因为之前同事在构造相关测试数据时由于创建…...
PCB模块化设计10——PCI-E高速PCB布局布线设计规范
目录PCB模块化设计10——PCI-E高速PCB布局布线设计规范1、PCI-E管脚定义2、PCI-E叠层和参考平面3、 PCB设计指南1、阻抗要求2、线宽线距3、长度匹配4、走线弯曲角度5、测试点、过孔、焊盘6、AC去耦电容放置方法7、金手指和连接器的注意事项8、其他的注意事项PCB模块化设计10——…...

Java简介
Java简介 Java是一种面向对象的编程语言,由Sun Microsystems于1995年发布。Java设计的初衷是为了开发可移植、高性能的应用程序。Java代码可以在不同的操作系统上运行,包括Windows、Linux、Mac等。 Java是一种广泛使用的编程语言,用于开发各…...

python框架有哪些,常用的python框架代码
Python的应用已经相当广泛了,可以做很多事情,而 Python本身就是一个应用程序,我们也可以说 Python是一个高级语言。由于 Python有很多包,所以我们不能把所有的 Python包都了解一下,也不能把所有的包都读一遍࿰…...

jsp设计简单的购物车应用案例
代码解释 <%request.setCharacterEncoding("UTF-8");if (request.getParameter("c1")!null)session.setAttribute("s1",request.getParameter("c1"));if (request.getParameter("c2")!null)session.setAttribute("…...
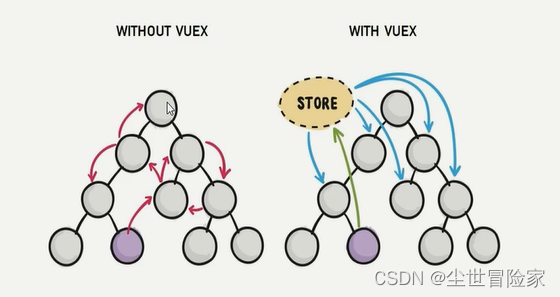
VueX是什么?好处?何时使用?
VueX相关1、VueX是什么?2、使用VueX统一管理状态的好处3、什么样的数据适合存储到Vuex中?1、VueX是什么? VueX是实现组件全局状态(数据)管理的一种机制,可以方便的实现组件之间数据的共享。 如果没有VueX…...
)
第2章 封装组件初级篇(上)
1.环境搭建,在 vite 脚手架基础上集成 typescript 和 element-plus https://cn.vitejs.dev/guide/ 以下是开发过程中过使用到的包和版本号:package.json {"name": "m-components","version": "0.0.0","…...

uniapp image标签图片跑偏终极解决办法
目录uniapp image 的mode常用属性aspectFit 缩放显示图片全部aspectFill 缩放填满容器,但是图片可能显示不全widthFix 以宽度为基准,等比缩放长heightFix 以高度为基准,等比缩放宽uniapp image 的mode常用属性 uniapp当中,在imag…...

SpringMVC的响应处理
文章目录一、传统同步业务数据响应1. 请求资源转发2. 请求资源重定向3. 响应模型数据4. 直接回写数据二、前后端分离异步业务数据响应一、传统同步业务数据响应 Spring响应数据给客户端,主要分为两大部分: ⚫ 传统同步方式:准备好模型数据&am…...

静态词向量预训练模型
1、神经网络语言模型从语言模型的角度来看,N 元语言模型存在明显的缺点。首先,模型容易受到数据稀疏的影响,一般需要对模型进行平滑处理;其次,无法对长度超过 N 的上下文依赖关系进行建模。神经网络语言模型 (Neural N…...
永久免费CRM怎么选?有什么好用的功能?
在当今商业环境下,企业经营者们都希望能够找到一种方法来提高自己的生产力和盈利能力。一种非常有效的方法就是实现客户关系管理(CRM)。然而,由于很多传统的CRM解决方案价格昂贵,小企业和创业公司很难承担。那么&#…...
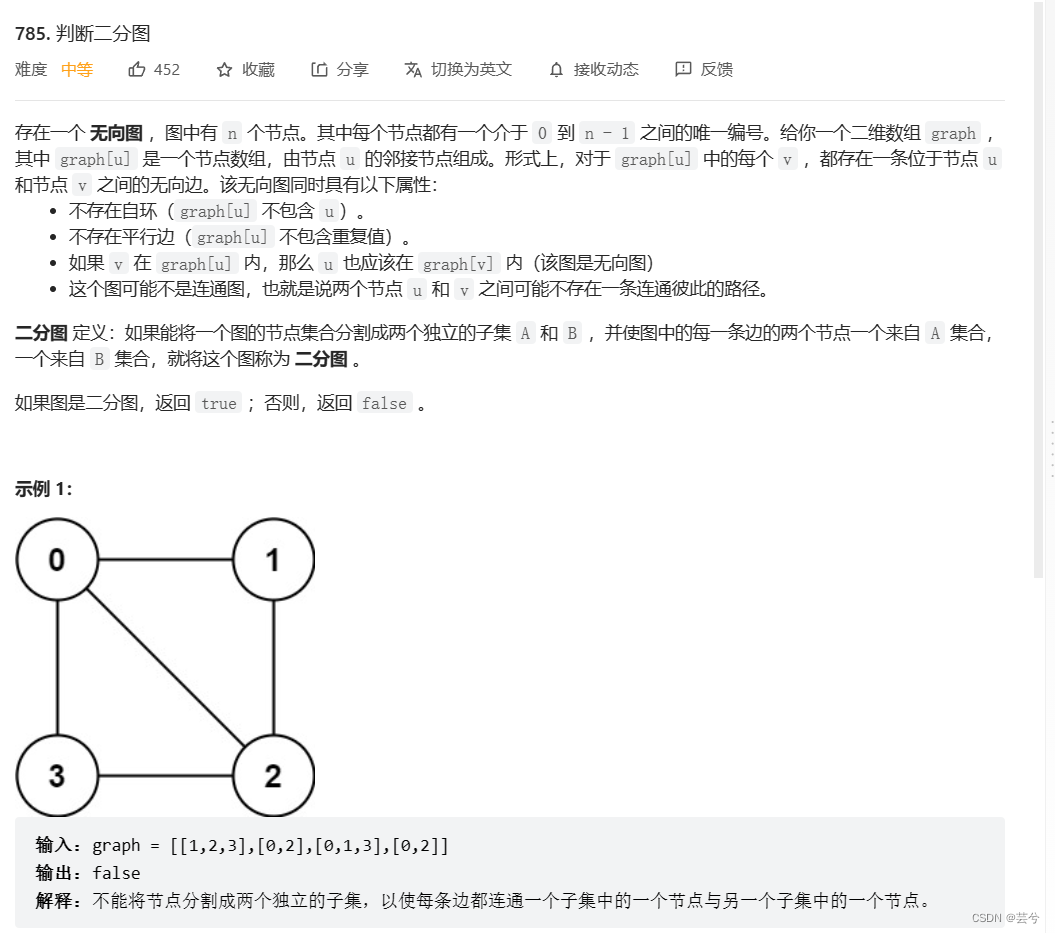
leetcode重点题目分类别记录(二)基本算法:二分,位图,回溯,动态规划,图论基础,拓扑排序
layout: post title: leetcode重点题目分类别记录(二)基本算法:二分,位图,回溯,动态规划,拓扑排序 description: leetcode重点题目分类别记录(二)基本算法:二…...

【JaveEE】多线程之定时器(Timer)
目录 1.定时器的定义 2.标准库中的定时器 2.1构造方法 2.2成员方法 3.模拟实现一个定时器 schedule()方法 构造方法 4.MyTimer完整代码 1.定时器的定义 定时器也是软件开发中的一个重要组件. 类似于一个 "闹钟". 达到一个设定的时间之后, 就执行某个指…...
【理论推导】变分自动编码器 Variational AutoEncoder(VAE)
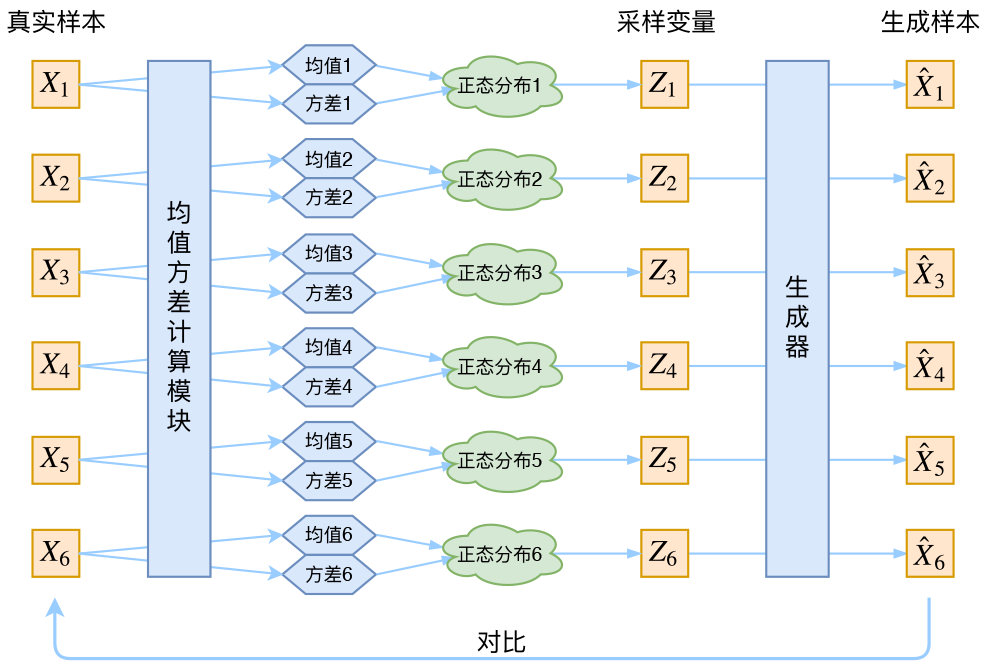
变分推断 (Variational Inference) 变分推断属于对隐变量模型 (Latent Variable Model) 处理的一种技巧,其概率图如下所示 我们将 X{x1,...xN}X\{ x_1,...x_N \}X{x1,...xN} 看作是每个样本可观测的一组数据,而将对应的 Z{z1,...,zN}Z\{z_1,...,z_N…...

【哈希表:哈希函数构造方法、哈希冲突的处理】
预测未来的最好方法就是创造它💦 目录 一、什么是Hash表 二、Hash冲突 三、Hash函数的构造方法 1. 直接定址法 2. 除余法 3. 基数转换法 4. 平方取中法 5. 折叠法 6. 移位法 7. 随机数法 四、处理冲突方法 1. 开放地址法 • 线性探测法 …...

HTML5 应用程序缓存
HTML5 应用程序缓存 使用 HTML5,通过创建 cache manifest 文件,可以轻松地创建 web 应用的离线版本。这意味着,你可以在没有网络连接的情况下进行访问。 什么是应用程序缓存(Application Cache)? HTML5 引…...

全国计算机等级考试三级网络技术选择题考点
目录 第一章 网络系统结构与设计的基本原则 第二章 中小型网络系统总体规划与设计方法 第三章 IP地址规划技术 第四章 路由设计基础 第五章 局域网技术基础应用 第六/七章 交换机/路由器及其配置 第八章 无线局域网技术 第九章 计算机网络信息服务系统的安装与…...

Python和VC代码实现希尔伯特变换(Hilbert transform)
文章目录前言一、希尔伯特变换是什么?二、VC中的实现原理及代码示例三、用Python代码实现总结前言 在数学和信号处理中,**希尔伯特变换(Hilbert transform)**是一个对函数产生定义域相同的函数的线性算子。 希尔伯特变换在信号处…...

嵌入式C语言语法概述
1.gcc概述 GCC全称是GUN C Compiler 随着时代的发展GCC支持的语言越来越多,它的名称变成了GNU Compiler Collection gcc的作用相当于翻译官,把程序设计语言翻译成计算机能理解的机器语言。 (1)gcc -o gcc -o (其…...

别再只盯着NXP和Impinj了!盘点5款国产超高频RFID芯片的‘独门绝技’
国产超高频RFID芯片的五大技术突围路径 在供应链安全与核心技术自主可控的背景下,国产超高频RFID芯片正从"能用"向"好用"快速演进。不同于早期简单模仿进口芯片的方案,如今头部厂商已形成独特的技术路线——有的在抗金属性能上实现突…...

终极Windows更新修复指南:用Reset-Windows-Update-Tool一键解决所有更新问题
终极Windows更新修复指南:用Reset-Windows-Update-Tool一键解决所有更新问题 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-…...

Audacity音频编辑:从新手到专业创作者的免费音频处理方案
Audacity音频编辑:从新手到专业创作者的免费音频处理方案 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 你是否曾经想过编辑一段音频,却因为昂贵的软件而却步?或者想要录制播客…...

magnetW磁力聚合搜索工具:一站式资源发现神器
magnetW磁力聚合搜索工具:一站式资源发现神器 【免费下载链接】magnetW [已失效,不再维护] 项目地址: https://gitcode.com/gh_mirrors/ma/magnetW 磁力搜索工具magnetW是一款基于Electron框架开发的跨平台桌面应用,专为技术爱好者和普…...

机器学习工作流编排利器:machiney-engine 轻量级流水线引擎详解
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫Reidston/machiney-engine。光看名字,你可能会觉得这又是一个“机器学习引擎”或者“AI框架”,市面上这类项目多如牛毛,从TensorFlow、PyTorch这样的巨头࿰…...

《如何追上那只乌龟》阅读指北
《如何追上那只乌龟》是一本以“芝诺悖论”为引子的漫画科普书,用轻松方式讲解微积分核心概念。它通过“阿基里斯追乌龟”这一哲学难题,带领读者从古希腊思辨走向现代数学工具,理解“无穷”“极限”“微分与积分”等抽象概念如何被一步步构…...

如何将AI 3D模型生成工具集成到你的开发工作流
如何将AI 3D模型生成工具集成到你的开发工作流 【免费下载链接】Unique3D [NeurIPS 2024] Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image 项目地址: https://gitcode.com/gh_mirrors/un/Unique3D 在当今快速发展的数字内容创作领域&…...

array_partition 怎么解决 Bank 冲突
1. complete 完全分区 把数组彻底打散,每个元素独立寄存器,不再占用 BRAM、无 Bank 概念,彻底消除冲突。 适合:小数组、高并行、要求 II1。 2. block 块分区 把数组平均切成若干大块,每块映射到独立 Bank,跨…...

NCM解密终极指南:3步释放网易云音乐到任何播放器
NCM解密终极指南:3步释放网易云音乐到任何播放器 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在特定应用中播放?当你想要将音乐迁移到其他设…...

FastbootEnhance:面向Windows用户的终极Fastboot工具箱与Payload提取器指南
FastbootEnhance:面向Windows用户的终极Fastboot工具箱与Payload提取器指南 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance FastbootE…...