词嵌入(Word Embedding)之Word2Vec、GloVe、FastText
简介:个人学习分享,如有错误,欢迎批评指正。
词嵌入(Word Embedding)是一种将词语映射到低维稠密向量空间的技术,能够捕捉词与词之间的语义关系。Word2Vec、GloVe、FastText 是常见的词嵌入方法,它们各自有不同的原理和特点。
一、Word2Vec
Word2Vec是Google在2013年提出的一种词嵌入(Word Embedding)模型,其核心思想是将词语映射到一个连续的低维向量空间,使得语义相似的词在向量空间中距离更近。通过这种方式,词语的语义关系可以用向量之间的数学运算(如余弦相似度)来度量。
1.基本原理
Word2Vec 的核心思想是基于 分布式假设,即“上下文相似的词语具有相似的语义”。通过大量语料库的训练,Word2Vec 学习到每个词语的向量表示,使得这些向量能够捕捉词语之间的语义关系。
Word2Vec 主要有两种模型架构:
- Continuous Bag-of-Words (CBOW) 模型:
- 目标: 根据上下文预测中心词。
- 原理: 将
上下文词向量求和或平均,输入到神经网络,预测中心词的概率分布。 - 特点: 适合小型数据集,训练速度较快。
- Skip-Gram 模型:
- 目标: 根据中心词预测上下文词。
- 原理:
输入中心词的向量,通过神经网络,预测其周围上下文词的概率分布。 - 特点: 在大型数据集上表现更好,能够捕捉更多的稀有词信息。
向量性质和语义关系
Word2Vec 生成的词向量具有以下特点:
-
相似性捕捉: 语义相似的词语,其向量在空间中距离较近。
-
线性关系: 词向量之间的差异可以反映某些语义关系。 例如:
王国 ⃗ − 男人 ⃗ + 女人 ⃗ ≈ 王后 ⃗ \vec{王国} - \vec{男人} + \vec{女人} \approx \vec{王后} 王国−男人+女人≈王后
- 聚类效果: 同一类别的词语在向量空间中往往形成聚类。
2.模型结构
- CBOW 模型结构
- 输入层: 上下文词的
one-hot 向量表示。 - 投影层: 将
one-hot 向量映射到低维嵌入空间,通常使用嵌入矩阵。 - 隐藏层: 将上下文词的嵌入向量进行
平均求和。 - 输出层: 通过 softmax 函数,
输出中心词的概率分布。
数学公式:
给定上下文词 w c o n t e x t w_{context} wcontext,目标是最大化中心词 w t a r g e t w_{target} wtarget的条件概率:
P ( w t a r g e t ∣ w c o n t e x t ) = s o f t m a x ( v w t a r g e t T h ) P(w_{target} \mid w_{context}) = softmax(v_{w_{target}}^T h) P(wtarget∣wcontext)=softmax(vwtargetTh)
其中, h h h 是上下文词向量的平均值, v w t a r g e t v_{w_{target}} vwtarget 是中心词的输出向量。
- Skip-Gram 模型结构
- 输入层: 中心词的
one-hot 向量表示。 - 投影层: 将
中心词的 one-hot 向量映射到嵌入空间。 - 输出层: 通过 softmax 函数,
预测上下文词的概率分布。
数学公式:
给定中心词 w t a r g e t w_{target} wtarget,目标是最大化其上下文词 w c o n t e x t w_{context} wcontext的条件概率:
P ( w c o n t e x t ∣ w t a r g e t ) = s o f t m a x ( v w c o n t e x t T h ) P(w_{context} \mid w_{target}) = softmax(v_{w_{context}}^T h) P(wcontext∣wtarget)=softmax(vwcontextTh)
其中, h h h 是中心词的嵌入向量, v w c o n t e x t v_{w_{context}} vwcontext 是上下文词的输出向量。
3.训练方法和实践步骤
3.1.训练方法
由于词汇表通常非常大,直接计算 softmax 的代价过高。为此,Word2Vec 引入了两种高效的近似训练方法:
a.负采样 (Negative Sampling)
- 思想: 只更新一小部分负样本的参数,而非整个词汇表。
- 方法: 对于每个正样本(真实的词对),随机采样 k 个负样本(无关的词对),使模型区分正负样本。
负采样的基本原理
负采样通过简化优化目标,减少计算量。它的核心思想是:与其每次计算所有类别的softmax分布,不如仅针对正样本和少量负样本进行计算。这些负样本通过随机采样获得,而正样本是实际存在于数据中的正确标签。
具体步骤如下:
- 正样本(Positive Sample):对于每个输入词语,模型会选择其上下文中的正确词语作为正样本。
- 负样本(Negative
Samples):为了降低计算量,模型随机选择若干个错误的词语作为负样本。负样本来自词汇表中的其他词语,通常是无关词。 - 优化目标:模型不再优化整个词汇表的softmax概率分布,而是仅仅优化正样本与若干负样本的相对概率。
负采样数学表述
在传统的 Skip-Gram 模型中,目标是最大化每对词之间的共现概率:
P ( Context Word ∣ Target Word ) = e v c ⋅ v w ∑ w ′ ∈ V e v c ⋅ v w ′ P(\text{Context Word}|\text{Target Word}) = \frac{e^{v_c \cdot v_w}}{\sum_{w' \in V} e^{v_c \cdot v_{w'}}} P(Context Word∣Target Word)=∑w′∈Vevc⋅vw′evc⋅vw
其中 v c v_c vc 和 v w v_w vw 分别表示上下文词和目标词的词向量, V V V 是词汇表。
负采样优化目标如下:
L = log σ ( v c ⋅ v w ) + ∑ i = 1 k log σ ( − v c ⋅ v n i ) L = \log \sigma(v_c \cdot v_w) + \sum_{i=1}^{k} \log \sigma(-v_c \cdot v_{n_i}) L=logσ(vc⋅vw)+i=1∑klogσ(−vc⋅vni)
其中:
- σ ( x ) \sigma(x) σ(x) 是 sigmoid 函数,用于将输出限制在 (0,1) 之间。
- v n i v_{n_i} vni 是随机采样得到的负样本词向量。
- k k k 是负采样的样本数量,通常取 5 到 20 之间。
b.层次化 Softmax (Hierarchical Softmax)
- 思想: 将 softmax 分解为二叉树的形式,降低计算复杂度。
- 方法: 将词汇表组织成霍夫曼编码的二叉树,预测路径上的二元决策。
3.2.实践步骤
- 语料预处理
- 分词: 将文本切分为单词序列。
- 去除停用词: 可根据需求去除常见但信息量低的词语。
- 建立词汇表: 统计词频,建立词语索引的映射关系。
- 模型训练
- 选择模型架构: CBOW 或 Skip-Gram。
- 设定超参数: 嵌入维度、窗口大小、负采样数量、学习率等。
- 训练参数: 使用优化算法(如 SGD)更新参数。
- 模型评估
- 相似度测试: 计算词向量之间的余弦相似度,验证相似词是否接近。
- 下游任务验证: 将词向量应用于具体任务,评估性能提升。
4.python代码实现
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence# 1. 加载语料
# 假设语料文件为 'corpus.txt',每行一个经过分词的句子,词语用空格分隔
sentences = LineSentence('corpus.txt')# 2. 训练Word2Vec模型
model = Word2Vec(sentences,vector_size=100, # 词向量的维度window=5, # 上下文窗口大小min_count=5, # 词频低于min_count的词将被忽略workers=4, # 使用4个线程进行训练sg=1, # 使用Skip-Gram模型;若为0,则使用CBOW模型negative=5, # 负采样个数sample=1e-3, # 下采样率epochs=5 # 迭代次数
)# 3. 保存模型
model.save('word2vec.model')# 4. 加载模型
model = Word2Vec.load('word2vec.model')# 5. 使用模型# 获取词向量
vector = model.wv['苹果']
print('苹果的词向量:')
print(vector)# 计算两个词的相似度
similarity = model.wv.similarity('苹果', '香蕉')
print(f'苹果和香蕉的相似度:{similarity}')# 找出与某个词最相似的词
similar_words = model.wv.most_similar('苹果', topn=5)
print('与苹果最相似的词:')
for word, score in similar_words:print(f'{word}: {score}')# 6. 词向量的简单运算
result = model.wv.most_similar(positive=['王后', '男人'], negative=['女人'], topn=1)
print('王后 + 男人 - 女人 = ')
print(result)5.总结
优势和局限性
优势:
- 高效性: 相比传统的共现矩阵和 SVD 分解,Word2Vec 在大规模语料上训练速度更快。
- 语义捕捉: 能够有效捕捉词语的语义和语法关系。
局限性:
- 上下文独立: Word2Vec 为每个词生成固定的向量,
无法处理词语的多义性和上下文依赖性。 - 缺乏句子级别表示: 仅对词语进行嵌入,无法直接用于句子或段落的表示。
- 对未登录词的处理: 无法生成未在词汇表中出现的词语的向量。
应用场景
- 词语相似度计算: 通过计算词向量之间的相似度,获取与给定词语语义相近的词。
- 文本分类和聚类: 将文本表示为词向量的组合,用于分类或聚类任务。
- 机器翻译: 通过训练词向量实现词语间的语义映射,辅助翻译。
- 信息检索: 改进搜索引擎的关键词匹配,提升用户查询的匹配质量。
- 情感分析: 捕捉文本中情感信息,应用于情绪监控等领域。
改进和扩展
-
FastText: 将词语分解为字符 n-gram,能够处理未登录词和词语的内部结构。
-
GloVe (Global Vectors for Word Representation): 结合全局语料词共现信息,利用矩阵分解的方法生成词向量。
-
ELMo (Embeddings from Language Models): 基于词向量的语言模型,生成上下文敏感的词向量,解决词语的多义性问题。
-
BERT (Bidirectional Encoder Representations from Transformers): 利用 Transformer 架构,生成深度的上下文表示,可用于句子和段落级别的嵌入。
Word2Vec 是自然语言处理领域的重要里程碑,通过将词语映射到连续向量空间,开创了基于分布式表示的词语语义建模方法。虽然存在一些局限,但模型的后续发展(如 FastText、BERT 等)的发展竞相出现。对于从事 NLP 研究和应用的人员,深入理解 Word2Vec 的原理和实现,有助于更好地应用和改进词向量的建模技术。
二、GloVe
GloVe(Global Vectors for Word Representation)是由斯坦福大学的 Jeffrey Pennington、Richard Socher 和 Christopher D. Manning 于 2014 年提出的一种词向量表示模型。GloVe 的主要思想是结合全局的词共现统计信息与局部的上下文窗口信息,通过矩阵分解的方式,生成能够捕捉词语语义和语法特征的高质量词向量。与基于预测的模型(如 Word2Vec)不同,GloVe 直接利用词语的共现概率,旨在更好地捕捉全局语义关系。
1.基本原理
GloVe 模型的核心思想是:词语的语义关系可以通过词共现概率的比值来捕捉。在大规模语料库中,统计词语之间的共现次数,可以得到一个词共现矩阵。GloVe 利用这个矩阵,通过最小化词向量与共现概率对数之间的差异,学习出词向量表示。
词共现矩阵
- 定义: 在给定语料库中,统计每个词对 ( ( i , j ) ) ((i,j)) ((i,j)) 共同出现的次数 X i j X_{ij} Xij,形成词共现矩阵 X X X。
- 共现概率: 词 j j j 在给定词 i i i 的条件下出现的概率为:
P i j = X i j X i P_{ij} = \frac{X_{ij}}{X_i} Pij=XiXij
其中, X i = ∑ k X i k X_i = \sum_k X_{ik} Xi=∑kXik 是词 i i i 出现时所有共现词的总次数。
损失函数的构建
GloVe 的目标是找到一个映射,使得词向量之间的关系能够反映词语的共现概率。具体来说,模型希望满足以下关系:
w i T w j + b i + b j = log ( X i j ) w_i^T w_j + b_i + b_j = \log(X_{ij}) wiTwj+bi+bj=log(Xij)
其中:
- w i w_i wi 和 w j w_j wj 分别是词 i i i 和词 j j j 的词向量。
- b i b_i bi 和 b j b_j bj 是对应的偏置项。
为了实现这一目标,GloVe 定义了以下损失函数:
J = ∑ i , j = 1 V f ( X i j ) ( w i T w j + b i + b j − log X i j ) 2 J = \sum_{i,j=1}^{V} f(X_{ij}) \left( w_i^T w_j + b_i + b_j - \log X_{ij} \right)^2 J=i,j=1∑Vf(Xij)(wiTwj+bi+bj−logXij)2
其中:
- V V V 是词汇表的大小。
- f ( X i j ) f(X_{ij}) f(Xij) 是权重函数,控制不同频次的词对对损失的贡献。
权重函数
为了避免高频词对损失函数的主导,同时又不忽略低频词,GloVe 采用如下的权重函数:
f ( x ) = { ( x x max ) α if x < x max 1 if x ≥ x max f(x) = \begin{cases} \left( \frac{x}{x_{\text{max}}} \right)^\alpha & \text{if } x < x_{\text{max}} \\ 1 & \text{if } x \geq x_{\text{max}} \end{cases} f(x)={(xmaxx)α1if x<xmaxif x≥xmax
常用的参数取值为 α = 0.75 \alpha = 0.75 α=0.75, x max = 100 x_{\text{max}} = 100 xmax=100。
2.训练方法和实践步骤
模型训练步骤
- 数据预处理: 对语料库进行分词,去除停用词等预处理操作。
- 构建词共现矩阵: 设定窗口大小 w w w,统计词对共现次数 X i j X_{ij} Xij。
- 初始化参数: 随机初始化词向量 w i w_i wi, w j w_j wj 以及偏置项 b i b_i bi, b j b_j bj。
- 定义损失函数: 使用上述损失函数 J J J。
- 优化损失函数: 采用 AdaGrad 等优化算法,最小化损失函数 J J J。
- 获取最终词向量: 训练完成后,通常将 w i w_i wi 和 w j w_j wj 相加或取平均,作为词 i i i 的最终表示。
优化算法
- AdaGrad: 自适应学习率优化算法,适合处理稀疏数据和大规模数据集。
- 并行化: GloVe 的训练过程中可以进行并行化,加速模型的训练。
实践指南
- 数据准备
- 收集语料: 获取大规模、多样性的文本数据集,如维基百科、新闻语料等。
- 数据预处理: 清除噪声,去除标点、统一大小写等。
- 分词处理: 对文本进行分词,进行去除停用词操作。
- 构建词共现矩阵
- 设定窗口大小: 通常选择 5 到 10。
- 统计词共现次数: 统计词对共现次数,并构造词语之间的共现矩阵。
- 模型训练
- 设置超参数: 选择词向量维度(如 50、100、300)、学习率等。
- 选择优化算法: 选择常用的 AdaGrad 等优化算法。
- 训练模型: 优化损失函数,最小化目标函数。
- 模型评估
- 相似度测试: 测试词向量之间的余弦相似度是否能反映语义关系上的相近性。
- 下游任务应用: 在具体任务中进行验证和测试,评估性能表现。
3.python代码实现
from glove import Corpus, Glove# 准备语料
sentences = [['我', '喜欢', '自然', '语言', '处理'],['词向量', '是', 'NLP', '的重要', '组成部分'],['GloVe', '模型', '利用', '词共现', '统计信息']
]# 构建词共现矩阵
corpus = Corpus()
corpus.fit(sentences, window=5)# 训练 GloVe 模型
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus.matrix, epochs=20, no_threads=4, verbose=True)
glove.add_dictionary(corpus.dictionary)# 获取词向量
vector = glove.word_vectors[glove.dictionary['自然']]# 查找相似词
similar = glove.most_similar('自然', number=5)
print(similar)4.总结
4.1. 优势和局限性
优势
- 全局统计信息: 利用全局共现统计信息,能更精确捕捉更丰富的语义关系。
- 高效性: 在小样本数据的高频训练下表现优秀,内存利用率较高,适用于大规模数据。
- 稀疏性处理: 能够较好地处理稀疏性信息。
局限性
- 内存消耗较大: 构建矩阵时内存开销较大,适合离线处理。
- 上下文独立: 与 Word2Vec 一样,无法处理词语的多义性和上下文变化。
- 数据依赖: GloVe 依赖于全局的词共现矩阵,无法动态更新词向量。
4.2. 与 Word2Vec 的比较
-
信息利用方式:
- Word2Vec: 基于局部上下文的预测,利用滑动窗口中的词语共现信息。
- GloVe: 结合全局的词共现统计信息,更全面地捕捉词语之间的关系。
-
模型基本原理:
- Word2Vec: 属于预测型模型,基于神经网络。
- GloVe: 属于基于计数的模型,进行矩阵分解。
-
训练效率:
- Word2Vec: 在大规模语料上训练速度较快,但需要高频迭代多个训练次数。
- GloVe: 预先构造词共现矩阵,训练次数较少但构造成本高。
-
性能差异:
- 词类比任务: 两者性能相近,GloVe 有时表现更好。
- 计算复杂性: GloVe 由于依赖共现矩阵,Word2Vec 更节省内存。
4.3. 应用场景
- 词语相似度计算: 评估词语之间的相似性和关联性。
- 文本分类和聚类: 将文本表示为词向量的组合,用于分类或聚类任务。
- 机器翻译: 通过捕捉语义关系,辅助机器翻译任务。
- 信息检索和问答系统: 改进搜索结果的相关性,提升用户体验。
- 情感分析: 捕捉文本中的情感倾向,应用于舆情监控等领域。
GloVe 模型通过融合全局的词共现统计信息,为词向量表示提供了强有力的工具。它在捕捉词语的语义和语法关系方面表现出色,已成为自然语言处理领域的重要方法之一。尽管存在内存需求大、无法处理上下文等局限,但通过改进和扩展,GloVe 仍具有广阔的应用前景。深入理解 GloVe 的原理和实现,有助于更好地应用词向量技术,解决实际的 NLP 问题。
三、FastText
FastText 是由 Facebook 的研究团队于 2016 年提出的一种用于高效学习词向量和文本分类的模型。它在 Word2Vec 的基础上进行了改进,能够处理未登录词(out-of-vocabulary words)和捕捉词语内部的形态信息。FastText 将每个词表示为字符 n-gram 的集合,从而可以更好地捕捉词的拼写和形态学特征,特别适用于处理大量的词汇和罕见词。
1.基本原理
- 词表示方式
FastText 的核心思想是将每个词表示为其字符 n-gram 的集合,并将词本身也视为一个特殊的 n-gram。具体来说:
- 字符 n-gram: 将一个词分解为所有可能的 n-gram,通常 n n n 的取值范围为 3 到 6。
- 词的表示: 一个词的向量表示是其所有 n-gram 向量的和或平均。
示例:
对于词 “apple”,取 n = 3 n=3 n=3,则其字符 3-gram 有:
<ap, app, ppl, ple, le>
这里,< 和 > 分别表示词的开始和结束。
2.模型结构
FastText 的模型架构与 Word2Vec 的 Skip-Gram 模型类似,但在输入层处理上有所不同:
- 输入层: 词由字符 n-gram 的集合表示。
- 隐藏层: 将 n-gram 向量投影到隐藏层。
- 输出层: 通过
softmax 或近似方法,预测上下文词。
FastText 旨在最大化输入词与上下文词之间的共现概率。其损失函数与 Skip-Gram 模型类似,但在词向量表示上使用了 n-gram 的集合。
3.训练方法和实践步骤
3.1. 模型训练
- 数据预处理
- 分词: 将语料库切分为词词序列。
- 生成 n-gram: 对于每个词,生成对应的字符 n-gram 集合。
- 训练过程
- 输入表示: 对于中心词,获取其所有的字符 n-gram,并查找对应的 n-gram 向量。
- 上下文预测: 利用中心词的 n-gram 向量,预测上下文词的概率分布。
- 优化目标: 最小化负对数似然损失,或使用负采样进行高效训练。
- 采用优化技术
- 负采样 (Negative Sampling): 减少计算复杂度,提高清训练速度。
- 分层 softmax (Hierarchical Softmax): 对大型词汇表进行高效的概率计算。
4.python代码实现
使用 Python 接口
import fasttext# 训练词向量模型
model = fasttext.train_unsupervised('corpus.txt', model='skipgram', dim=100, minn=3, maxn=6)# 获取词向量
vector = model.get_word_vector('自然语言处理')# 查找相似词
similar_words = model.get_nearest_neighbors('自然语言处理', k=5)
print(similar_words)文本分类示例
import fasttext# 训练文本分类模型
model = fasttext.train_supervised('train.txt', label_prefix='__label__', epoch=5, lr=0.1)# 模型评估
result = model.test('test.txt')
print('Precision:', result.precision)
print('Recall:', result.recall)# 预测新样本
labels, probabilities = model.predict('这是一个新的评论', k=2)
print(labels, probabilities)5.总结
优势
- 处理未登录词
由于 FastText 使用了字符 n-gram,当遇到未出现在训练集中出现的词时,仍然可以通过其字符 n-gram 获取词向量。这使得模型在处理罕见词或新词时表现更佳。
- 捕捉词形信息
字符 n-gram 能够捕捉到前缀、后缀和词根等信息,处理形态丰富的语言(如法语、德语等)尤为有利。
- 高效性
FastText 在保持高性能的同时,具有较快的训练速度和较低的内存占用,适合大规模数据训练。
应用场景
- 词向量表示
- 语义相似度计算:获取词语的向量表示,计算词语之间的相似度。
- 文本表示:将句子或文档表示为词向量的组合,用于各种 NLP 任务。
- 文本分类
- 监督学习:FastText 提供了高效的文本分类算法,适用于情感分析、主题分类等任务。
- 多语言支持:在多语言环境下,FastText 能够高效处理多种语言的文本分类。
- 命名实体识别和词性标注
- 利用词的形态特征:通过字符 n-gram,模型能够更好地识别词的类型和特征。
FastText 通过引入字符 n-gram,将词的内部结构纳入模型,有效地解决了未登录词和低频词的表示问题。其高效性和易用性使其在自然语言处理的多个领域得到了广泛应用。对于需要处理大量文本数据的任务,FastText 是一个强大的工具。通过深入理解其原理和实践方法,能够更好地应用 FastText,提高 NLP 模型的性能。
四、对比总结
| 特性 | Word2Vec | GloVe | FastText |
|---|---|---|---|
| 训练原理 | 基于局部上下文窗口 | 基于全局词共现矩阵 | 基于局部上下文窗口 + 子词信息 |
| 处理多义词 | 无法处理 | 无法处理 | 有一定能力处理(基于子词) |
| 未见词处理 | 无法处理 | 无法处理 | 可以通过子词 n-grams 处理 |
| 计算效率 | 高效(负采样) | 计算复杂度较高 | 训练相对慢,但推理时效率高 |
| 语义捕捉能力 | 强(依赖上下文) | 强(依赖全局信息) | 较弱,特别适合低资源语言 |
| 适用场景 | 适合大规模语料,常见语言 | 适合大规模语料,需要全局语义的场景 | 适合多语言任务,低资源语言或未见词场景 |
- Word2Vec 适合在大规模语料上快速训练词向量,能够很好地捕捉词的局部语义关系,但对多义词和未见词无能为力。
- GloVe 则侧重于全局的语料统计信息,适合需要全局语义关系的任务,然而其计算代价较高且在未见词处理方面存在局限。
- FastText 通过子词的 n-grams 技术,能很好地处理形态丰富语言和未见词问题,是一个兼顾效率和表现的改进模型。
结~~~
相关文章:
之Word2Vec、GloVe、FastText)
词嵌入(Word Embedding)之Word2Vec、GloVe、FastText
简介:个人学习分享,如有错误,欢迎批评指正。 词嵌入(Word Embedding)是一种将词语映射到低维稠密向量空间的技术,能够捕捉词与词之间的语义关系。Word2Vec、GloVe、FastText 是常见的词嵌入方法,…...

Vue82 路由器的两种工作模式 以及 node express 部署前端
笔记 对于一个url来说,什么是hash值?—— #及其后面的内容就是hash值。hash值不会包含在 HTTP 请求中,即:hash值不会带给服务器。hash模式: 地址中永远带着#号,不美观 。若以后将地址通过第三方手机app分享…...
[C#]使用纯opencvsharp部署yolov11-onnx图像分类模型
【官方框架地址】 https://github.com/ultralytics/ultralytics.git 【算法介绍】 使用纯OpenCvSharp部署YOLOv11-ONNX图像分类模型是一项复杂的任务,但可以通过以下步骤实现: 准备环境:首先,确保开发环境已安装OpenCvSharp和必…...

【机器学习-无监督学习】概率图模型
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,…...

每日学习一个数据结构-AVL树
文章目录 概述一、定义与特性二、平衡因子三、基本操作四、旋转操作五、应用场景 Java代码实现 概述 AVL树是一种自平衡的二叉查找树,由两位俄罗斯数学家G.M.Adelson-Velskii和E.M.Landis在1962年发明。想了解树的相关概念,请点击这里。以下是对AVL树的…...
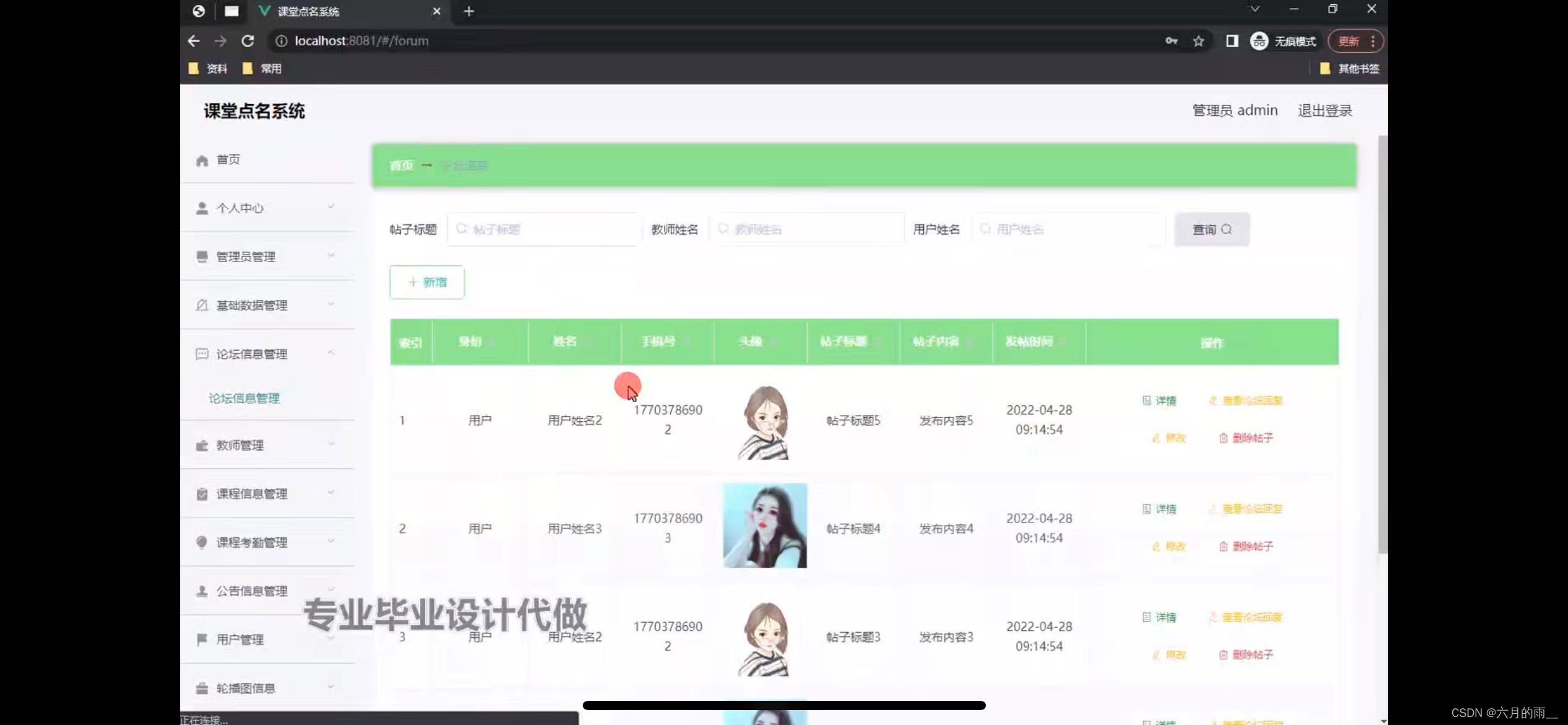
课堂点名系统小程序的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,论坛信息管理,基础数据管理,课程信息管理,课程考勤管理,轮播图信息 微信端账号功能包括:系统首页,论坛信…...
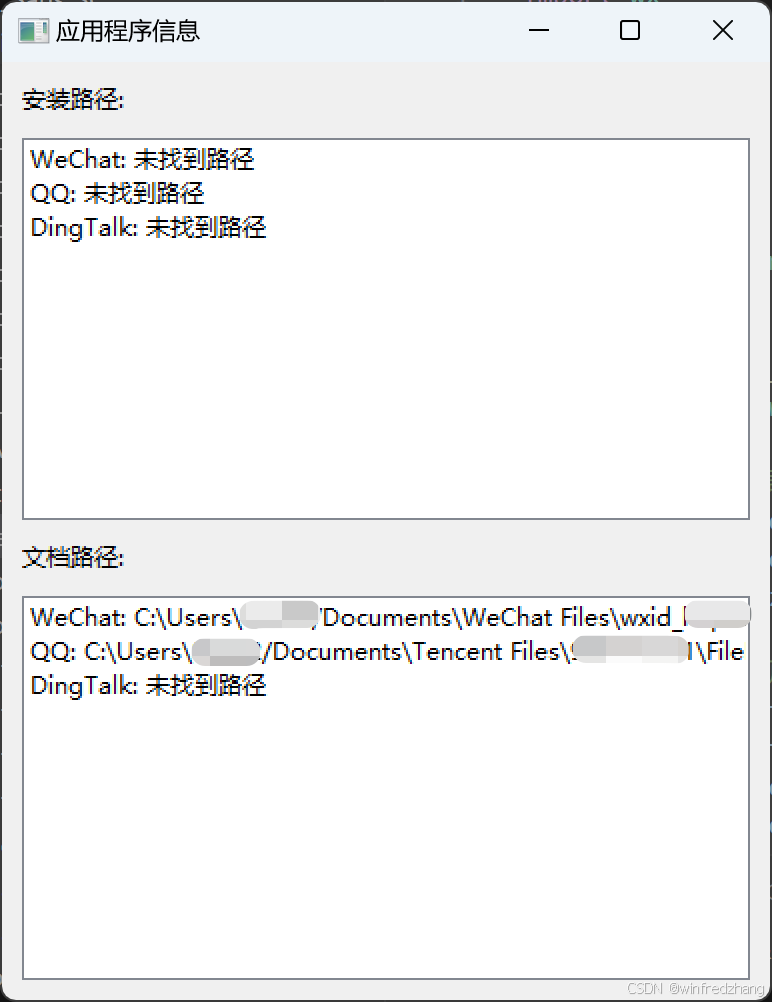
使用Python查找WeChat和QQ的安装路径和文档路径
在日常工作和生活中,我们经常需要查找某些应用程序的安装位置或者它们存储文件的位置。特别是对于像WeChat(微信)和QQ这样的即时通讯软件,了解它们的文件存储位置可以帮助我们更好地管理我们的聊天记录和共享文件。今天࿰…...

【AI大模型】深入Transformer架构:编码器部分的实现与解析(下)
目录 🍔 编码器介绍 🍔 前馈全连接层 2.1 前馈全连接层 2.2 前馈全连接层的代码分析 2.3 前馈全连接层总结 🍔 规范化层 3.1 规范化层的作用 3.2 规范化层的代码实现 3.3 规范化层总结 🍔 子层连接结构 4.1 子层连接结…...

【数据结构】【栈】算法汇总
一、顺序栈的操作 1.准备工作 #define STACK_INIT_SIZE 100 #define STACKINCREMENT 10 typedef struct{SElemType*base;SElemType*top;int stacksize; }SqStack; 2.栈的初始化 Status InitStack(SqStack &S){S.base(SElemType*)malloc(MAXSIZE*sizeof(SElemType));if(…...

如何训练自己的大模型,答案就在这里。
训练自己的AI大模型是一个复杂且资源密集型的任务,涉及多个详细步骤、数据集需求以及计算资源要求。以下是根据搜索结果提供的概述: 详细步骤 \1. 设定目标: - 首先需要明确模型的应用场景和目标,比如是进行分类、回归、生成文本…...

React18新特性
React 18新特性详解如下: 并发渲染(Concurrent Rendering): React 18引入了并发渲染特性,允许React在等待异步操作(如数据获取)时暂停和恢复渲染,从而提供更平滑的用户体验。 通过时…...

汽车发动机系统EMS详细解析
汽车发动机系统EMS,全称Engine-Management-System(发动机管理系统),是现代汽车电子控制技术的重要组成部分。以下是对汽车发动机系统EMS的详细解析,涵盖其定义、工作原理、主要组成、功能特点、技术发展以及市场应用等…...
【社保通-注册安全分析报告-滑动验证加载不正常导致安全隐患】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

初学Vue(2)
文章目录 监视属性 watch深度监视computed 和 watch 之间的区别 绑定样式(class style)条件渲染列表渲染基本列表key的原理列表过滤列表排序收集表单中的数据 v-model过滤器(Vue3已移除) 监视属性 watch 当被监视的属性变化时&am…...

ThinkPHP5基础入门
文章目录 ThinkPHP5基础入门一、引言二、环境搭建1、前期准备2、目录结构 三、快速上手1、创建模块2、编写控制器3、编写视图4、编写模型 四、调试与部署1、调试模式2、关闭调试模式3、隐藏入口文件 五、总结 ThinkPHP5基础入门 一、引言 ThinkPHP5 是一个基于 MVC 和面向对象…...

Metal 之旅之MTLLibrary
什么是MSL? MSL是Metal Shading Language 的简称,为了更好的在GPU执行程序,苹果公司定义了一套类C的语言(Metal Shading Language ),在GPU运行的程序都是用这个语言来编写的。 什么是MTLLibrary? .metal后缀的文件…...
)
第十二章 Redis短信登录实战(基于Session)
目录 一、User类 二、ThreadLocal类 三、用户业务逻辑接口 四、用户业务逻辑接口实现类 五、用户控制层 六、用户登录拦截器 七、拦截器配置类 八、隐藏敏感信息的代码调整 完整的项目资源共享地址,当中包含了代码、资源文件以及Nginx(Wi…...

华为OD机试 - 九宫格游戏(Python/JS/C/C++ 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…...
详解)
Pytorch库中torch.normal()详解
torch.normal()用法 torch.normal()函数,用于生成符合正态分布(高斯分布)的随机数。在 PyTorch 中,这个函数通常用于生成 Tensor。 该函数共有四个方法: overload def normal(mean: Tensor, std: Tensor, *, generat…...
atcoder-374(a-e)
atcoder-374 文章目录 atcoder-374ABC简洁的写法正解 D正解 E A #include<bits/stdc.h>using namespace std;signed main() {string s;cin>>s;string strs.substr(s.size()-3);if(str "san") puts("Yes");else puts("No");return 0…...

AI智能体编排平台:从任务自动化到生态协作的架构与实践
1. 项目概述:一个面向AI编排与技能提升的生态协作平台最近在和一些做AI应用开发的朋友聊天,大家普遍有个痛点:现在AI工具和模型太多了,从大语言模型到图像生成,再到各种自动化脚本,每个都很强大,…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

NVIDIA Profile Inspector完整指南:200+隐藏设置解锁显卡极致性能
NVIDIA Profile Inspector完整指南:200隐藏设置解锁显卡极致性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏画面撕裂、输入延迟过高而烦恼吗?想要彻底掌控NVIDIA…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南
如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏卡顿和掉帧?OpenSpeedy是一款…...

Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案
Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Tre…...

BiscuitLang:专为Web业务逻辑设计的轻量级脚本语言
1. 项目概述:一个为现代Web开发而生的轻量级语言如果你和我一样,长期在Web前端和全栈开发的泥潭里摸爬滚打,那你一定对JavaScript生态的“臃肿”与“复杂”深有体会。一个简单的项目动辄node_modules文件夹体积惊人,工具链配置繁琐…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...

3个技巧让SD-PPP插件提升Photoshop设计效率300%
3个技巧让SD-PPP插件提升Photoshop设计效率300% 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 还在为Photoshop和AI工具之间的频繁切换而烦恼吗?每次都要导出PSD、上传到AI平台、等待生成、再导回Phot…...

汽车该多久换一代
汽车该多久换一代 买车的人其实不怕四年换代,怕的是刚提车半年就被新款打成旧款。李想这句话能引起讨论,原因也在这里:车企说的是研发验证周期,车主感受到的是价格、配置和二手残值。 汽车确实没法完全照着手机节奏跑。手机坏了可…...