深度学习:yolo的使用--图像处理
定义了一个名为 ListDataset 的类,它继承自 PyTorch 的 Dataset 类,这个数据集从一个包含图像文件路径的列表中读取图像和对应的标签文件
class ListDataset(Dataset):def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):with open(list_path, "r") as file:self.img_files = file.readlines()# 找到图片对应的label文件路径,将png和jpg格式变成txt格式self.label_files = [path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt")for path in self.img_files]self.img_size = img_size#存储目标图像尺寸。self.max_objects = 100# 定义了图像中最大对象数量,默认为 100。self.augment = augment #是否进行数据增强self.multiscale = multiscale#是否多尺度训练self.normalized_labels = normalized_labels#是否标签归一化#定义了多尺度训练时图像尺寸的范围。self.min_size = self.img_size - 3 * 32self.max_size = self.img_size + 3 * 32self.batch_count = 0调用函数
dataset = ListDataset(train_path, augment=True, multiscale=opt.multiscale_training)定义了一个名为 collate_fn 的函数,它是 ListDataset 类的一个方法。这个函数用于将一个批次中的多个数据样本合并成一个批次
def collate_fn(self, batch):# 解压批次数据paths, imgs, targets = list(zip(*batch))# Remove empty placeholder targets# 移除空目标targets = [boxes for boxes in targets if boxes is not None]# Add sample index to targets# 添加样本索引到目标for i, boxes in enumerate(targets):boxes[:, 0] = i# 拼接目标targets = torch.cat(targets, 0) #将targets按行进行拼接# Selects new image size every tenth batch# 多尺度训练if self.multiscale and self.batch_count % 10 == 0:self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))# Resize images to input shape# 调整图像尺寸imgs = torch.stack([resize(img, self.img_size) for img in imgs])self.batch_count += 1return paths, imgs, targets调用函数
加载器可以批量加载数据集,并为训练过程提供数据
dataloader = torch.utils.data.DataLoader(dataset,batch_size=opt.batch_size, #1个样本打包成一个batch进行加载shuffle=True, #对数据进行随机打乱,num_workers=opt.n_cpu, #用于指定子进程的数量,用于并行地加载数据。默认情况下,num_workers的值为0,表示没有使用子进程,所有数据都会在主进程中加载。当设置num_workers大于0时,DataLoader会创建指定数量的子进程,每个子进程都会负责加载一部分数据,然后主进程负责从这些子进程中获取数据。# 使用子进程可以加快数据的加载速度,因为每个子进程可以并行地加载一部分数据,从而充分利用多核CPU的计算能力。但是需要注意的是,使用子进程可能会导致数据的顺序被打乱,因此如果需要保持数据的原始顺序,应该将shuffle参数设置为False。# num_workers的值应该根据具体情况进行调整。如果数据集较大,可以考虑增加num_workers的值以充分利用计算机的资源。但是需要注意的是,如果num_workers的值过大,可能会导致内存消耗过大或者CPU负载过重,从而影响程序的性能。因此,需要根据实际情况进行调整。pin_memory=True, #指定是否将加载进内存的数据的指针固定(pin),这个参数在某些情况下可以提高数据加载的速度。# 当设置pin_memory=True时,DataLoader会将加载进内存的数据的指针固定,即不进行移动操作。这样做的目的是为了提高数据传输的效率。因为当数据从磁盘或者网络等地方传输到内存中时,如果指针不固定,可能会导致数据在传输过程中被移动,从而需要重新读取,浪费了时间。而固定指针可以避免这种情况的发生,从而提高了数据传输的效率。# 需要注意的是,pin_memory参数的效果与操作系统和硬件的性能有关。在一些高性能的计算机上,固定指针可能并不会带来太大的性能提升。但是在一些内存带宽较小的计算机上,固定指针可能会显著提高数据加载的效率。因此,需要根据实际情况进行调整。collate_fn=dataset.collate_fn,# collate_fn是一个函数,用于对每个batch的数据进行合并。这个函数的输入是一个batch的数据,输出是一个合并后的数据。# collate_fn函数的主要作用是对每个batch的数据进行预处理,例如将不同数据类型的张量合并成一个张量,或者对序列数据进行padding操作等。这样可以使得每个batch的数据格式一致,便于模型进行训练。# 在默认情况下,collate_fn函数会将每个batch的数据按照第一个元素的张量形状进行合并。例如,如果一个batch的数据中第一个元素的张量形状是[# 3, 224, 224],那么collate_fn函数会将该batch的所有数据都调整为这个形状。)创建了一个名为 optimizer 的优化器对象,用于在训练过程中更新模型的参数。
optimizer = torch.optim.Adam(model.parameters())定义了一个名为 metrics 的列表,其中包含了在目标检测模型训练和评估过程中常用的一系列指标。
metrics = ["grid_size",#表示模型输出的特征图的大小"loss",#损失值"x","y","w","h",#表示目标检测中目标框的中心坐标(x, y)和宽高(w, h)"conf",#置信度"cls",#目标框中目标的类别预测的分数"cls_acc",#目标类别预测的正确率"recall50","recall75",#表示在不同的置信度阈值(通常是 0.5 和 0.75)下的召回率。"precision",#精确度"conf_obj","conf_noobj",#对象置信度和非对象置信度]
pad_to_square 函数是一个用于将图像填充到正方形的函数
def pad_to_square(img, pad_value):c, h, w = img.shape# 计算高度和宽度之间的差异dim_diff = np.abs(h - w)# 计算高度和宽度差异的一半,以及剩余的部分pad1, pad2 = dim_diff // 2, dim_diff - dim_diff // 2 #dim_diff - dim_diff // 2剩余部分,不一定能被2整除的空间# 根据高度和宽度的比较结果确定填充的方向和大小pad = (0, 0, pad1, pad2) if h <= w else (pad1, pad2, 0, 0) #填充方向(左,右,上,下)# 使用 PyTorch 的 F.pad 函数对图像进行填充img = F.pad(img, pad, "constant", value=pad_value)return img, pad
图像处理:获取图像文件的路径,将图像转换为 PyTorch 张量,并确保图像是 RGB 格式。获取图像的高度和宽度,使用 pad_to_square 函数将图像填充为正方形
def __getitem__(self, index):# ---------# Image图片的处理# ---------# 获取图像文件的路径,并将其拼接为绝对路径img_path = self.img_files[index % len(self.img_files)].rstrip()img_path = r'D:/KECHENG/pythonProject/.venv/Lib/PyTorch-YOLOv3/' + img_path#print (img_path)使用绝对路径,F:\人工智能学习\深度学习课件\代码\第7章yolo\PyTorch-YOLOv3\PyTorch-YOLOv3\data\coco# Extract image as PyTorch tensor# 转换为RGB格式,转换为PyTorch张量。img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))# Handle images with less than three channelsif len(img.shape) != 3:#是为了防止你的图片中存在灰度图,img = img.unsqueeze(0)img = img.expand((3, img.shape[1:]))# 获取图像的高度和宽度_, h, w = img.shapeh_factor, w_factor = (h, w) if self.normalized_labels else (1, 1)# 当尺寸并不是标准的正方形,进行填充0。img, pad = pad_to_square(img, 0)_, padded_h, padded_w = img.shape标签处理:获取标签文件的路径,将其转换为 PyTorch 张量。将标签中的归一化坐标转换回原始图像的坐标系,并根据填充调整坐标,将坐标重新归一化到填充后的图像尺寸。创建 targets 张量,用于存储更新后的标签信息。
# 获取标签文件的路径,并将其拼接为绝对路径。label_path = self.label_files[index % len(self.img_files)].rstrip()label_path = r'D:\KECHENG\pythonProject\.venv\Lib\PyTorch-YOLOv3/' + label_path#print (label_path)F:\人工智能学习\深度学习课件\代码\第7章yolo\PyTorch-YOLOv3\PyTorch-YOLOv3\data\cocotargets = Noneif os.path.exists(label_path):# 读取标签文件内容,并将其转换为PyTorch张量boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))# Extract coordinates for unpadded + unscaled image,# COCO数据集中的.txt文件每个字段的含义:# class_num:类别编号,从1开始。# box_cx:归一化后的中心横坐标,即像素坐标的cx除以图像宽度的结果。# box_cy:归一化后的中心纵坐标,即像素坐标的cy除以图像高度的结果。# box_w:归一化后的标注框宽度,即标注框宽度除以图像宽度的结果。# box_h:归一化后的标注框高度,即标注框高度除以图像高度的结果。x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)#还原回标注框的左上x值y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)# Adjust for added padding# 根据添加的填充调整坐标x1 += pad[0]#图像填充0y1 += pad[2]x2 += pad[1]y2 += pad[3]# Returns (x, y, w, h) 填充后继续还原回原始的值# 将坐标转换回归一化值boxes[:, 1] = ((x1 + x2) / 2) / padded_wboxes[:, 2] = ((y1 + y2) / 2) / padded_hboxes[:, 3] *= w_factor / padded_wboxes[:, 4] *= h_factor / padded_h# 创建targets张量,用于存储更新后的标签信息targets = torch.zeros((len(boxes), 6))targets[:, 1:] = boxes
图像增强
# 应用图像增强if self.augment:if np.random.random() < 0.5:img, targets = horisontal_flip(img, targets)return img_path, img, targets调用函数
for epoch in range(1,opt.epochs+1):model.train()# 记录当前轮次的开始时间start_time = time.time()# 从数据加载器 dataloader 中迭代获取批次数据。for batch_i, (_, imgs, targets) in enumerate(dataloader):# 计算批次完成的总数batches_done = len(dataloader) * epoch + batch_i# 数据移动到设备imgs = Variable(imgs.to(device)) #Variable类是PyTorch中的一个包装器,它将张量和它们的梯度信息封装在一起。当我们对一个张量进行操作时,PyTorch会自动地创建一个对应的Variable对象,其中包含了原始张量、梯度等信息。通过使用Variable,我们可以方便地进行自动微分和优化。targets = Variable(targets.to(device), requires_grad=False)print('imgs',imgs.shape)print('targets',targets.shape)# 模型前向传播和损失计算loss, outputs = model(imgs, targets)loss.backward()相关文章:

深度学习:yolo的使用--图像处理
定义了一个名为 ListDataset 的类,它继承自 PyTorch 的 Dataset 类,这个数据集从一个包含图像文件路径的列表中读取图像和对应的标签文件 class ListDataset(Dataset):def __init__(self, list_path, img_size416, augmentTrue, multiscaleTrue, normalized_labelsT…...
:初始化、类型定义与函数使用)
TypeScript实用笔记(一):初始化、类型定义与函数使用
文章目录 一、ts初始化1. 初始化.json文件一2. 启动方式2.1 直接运行.ts文件2.2 转换运行 二、类型1. 参数类型1.1 常规参数1.2 symbol1.3 数组\[]1.4 元组\[]1.5 用字面量定义数据类型 2. Object3. 枚举类型\[Enum]3.1 数字枚举3.2 字符串枚举 三、 类型别名1. 数组别名使用2.…...
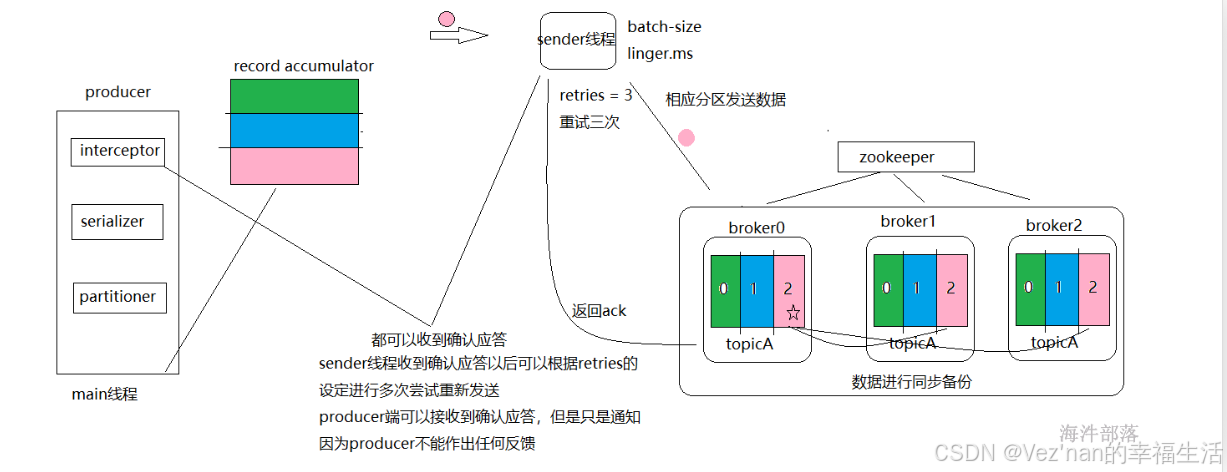
【大数据学习 | kafka】producer之拦截器,序列化器与分区器
1. 自定义拦截器 interceptor是拦截器,可以拦截到发送到kafka中的数据进行二次处理,它是producer组成部分的第一个组件。 public static class MyInterceptor implements ProducerInterceptor<String,String>{Overridepublic ProducerRecord<…...

零基础学西班牙语,柯桥专业小语种培训泓畅学校
No te comas el coco, seguro que te ha salido bien la entrevista. Ya te llamarn. 别瞎想了!我保证你的面试很顺利。他们会给你打电话的。 这里的椰子是"头"的比喻。在西班牙的口语中,我们也可以听到其他同义表达,比如&#x…...
)
C++学习:类和对象(三)
一、深入讲解构造函数 1. 什么是构造函数? 构造函数(Constructor)是在创建对象时自动调用的特殊成员函数,用于初始化对象的成员变量。构造函数的名称与类名相同,没有返回类型 2. 构造函数的类型 (1&…...
高阶数据结构--图(graph)
图(graph) 1.并查集1. 并查集原理2. 并查集实现3. 并查集应用 2.图的基本概念3. 图的存储结构3.1 邻接矩阵3.2 邻接矩阵的代码实现3.3 邻接表3.4 邻接表的代码实现 4. 图的遍历4.1 图的广度优先遍历4.2 广度优先遍历的代码 1.并查集 1. 并查集原理 在一…...
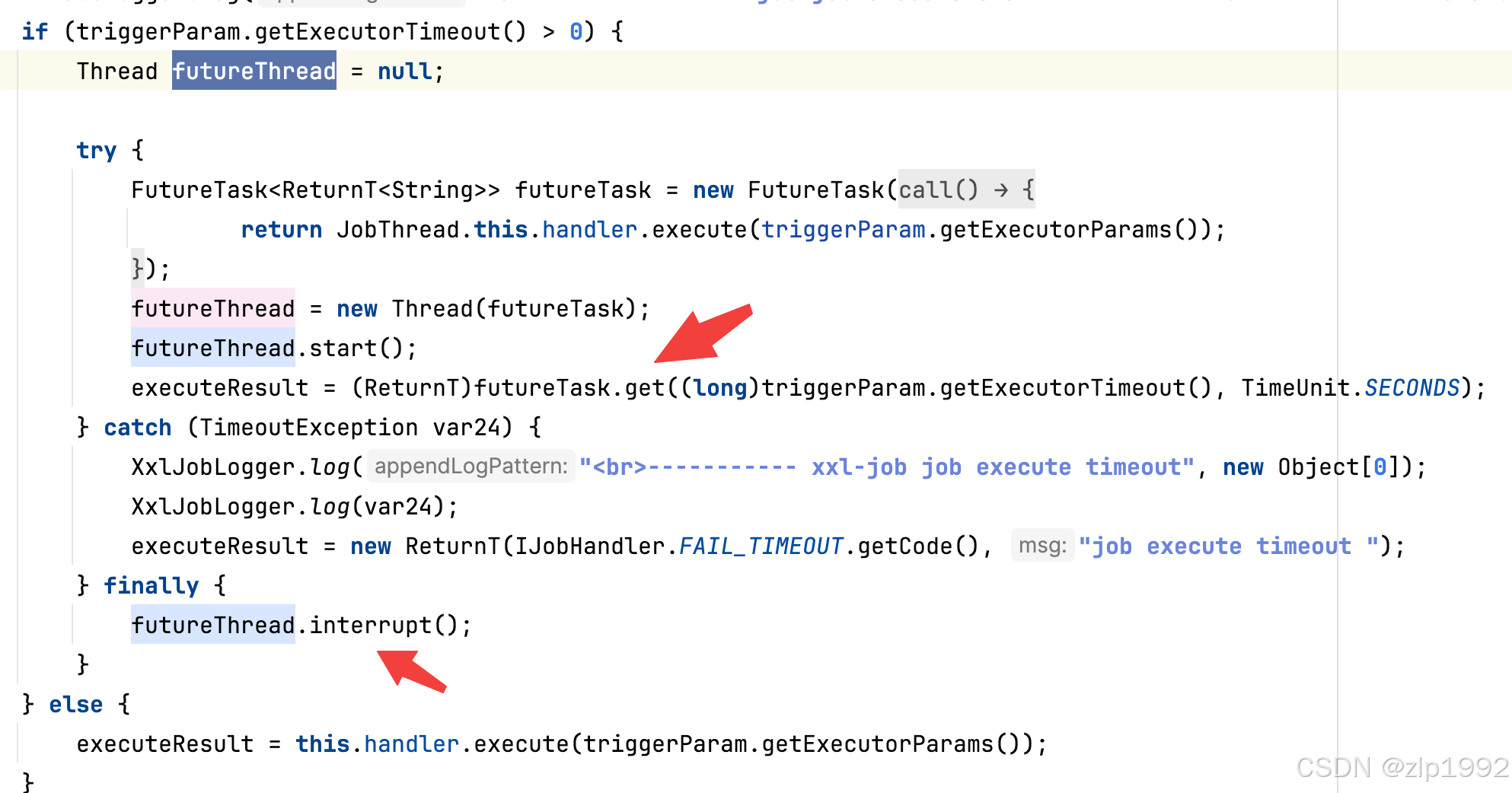
xxl-job java.sql.SQLException: interrupt问题排查
近期生产环境固定凌晨报错,提示 ConnectionManager [Thread-23069] getWriteConnection db:***,pattern: error, jdbcUrl: jdbc:mysql://***:3306/***?connectTimeout3000&socketTimeout180000&autoReconnecttrue&zeroDateTimeBehaviorCONVERT_TO_NUL…...
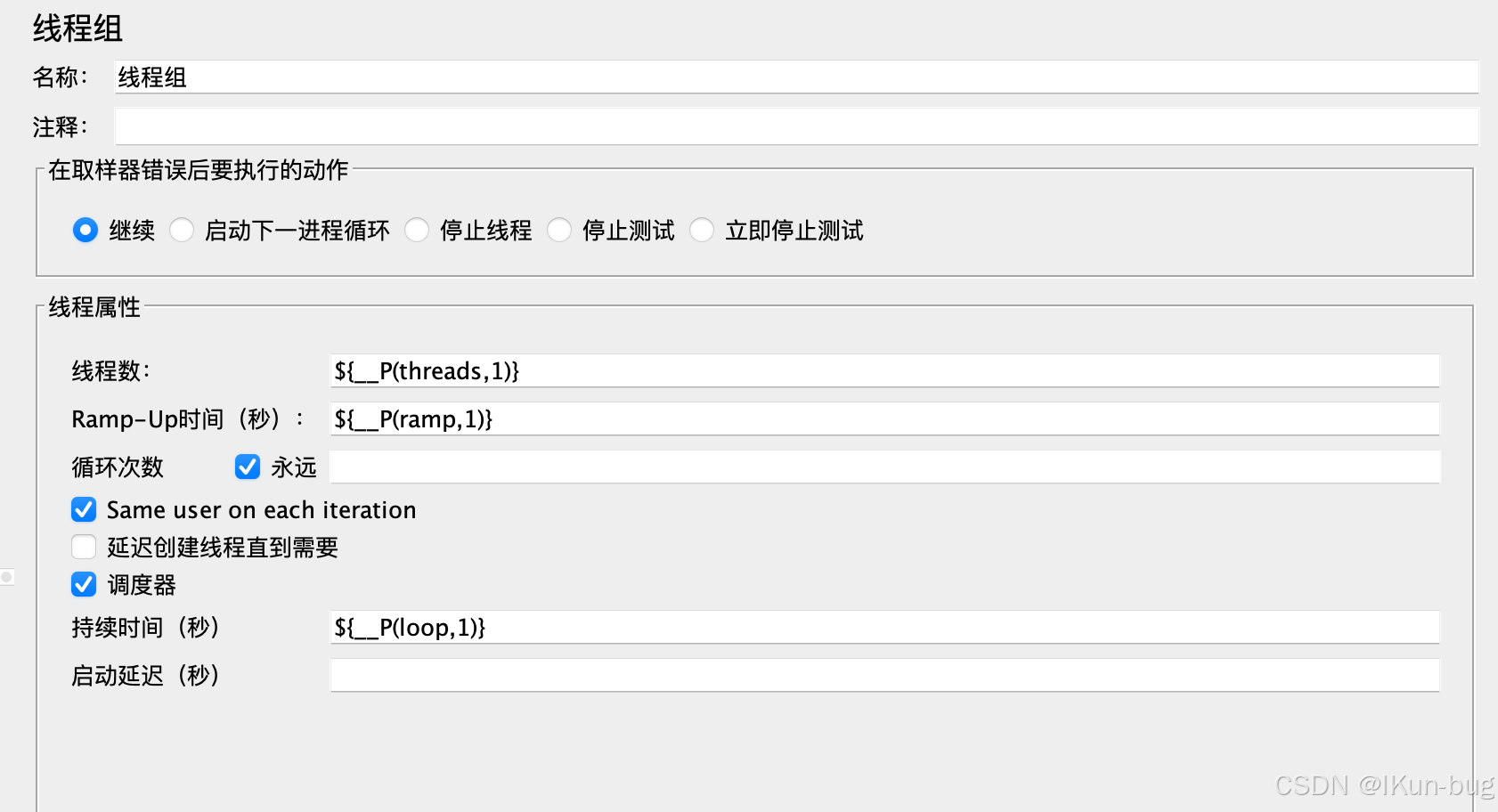
jmeter压测工具环境搭建(Linux、Mac)
目录 java环境安装 1、anaconda安装java环境(推荐) 2、直接在本地环境安装java环境 yum方式安装jdk 二进制方式安装jdk jmeter环境安装 1、jmeter单机安装 启动jmeter 配置环境变量 jmeter配置中文 2、jmeter集群搭建 多台机器部署jmeter集群…...

docker设置加速
sudo tee /etc/docker/daemon.json <<-‘EOF’ { “registry-mirrors”: [ “https://register.liberx.info”, “https://dockerpull.com”, “https://docker.anyhub.us.kg”, “https://dockerhub.jobcher.com”, “https://dockerhub.icu”, “https://docker.awsl95…...

使用requestAnimationFrame写防抖和节流
debounce.ts 防抖工具函数: function Animate() {this.timer null; }Animate.prototype.start function (fn) {if (!fn) {throw new Error(需要执行函数);}if (this.timer) {this.stop();}this.timer requestAnimationFrame(fn); }Animate.prototype.stop function () {i…...

Puppeteer 与浏览器版本兼容性:自动化测试的最佳实践
Puppeteer 支持的浏览器版本映射:从 v20.0.0 到 v23.6.0 自 Puppeteer v20.0.0 起,这个强大的自动化库开始支持与 Chrome 浏览器的无头模式和有头模式共享相同代码路径,为自动化测试带来了更多便利。从 v23.0.0 开始,Puppeteer 进…...

Java方法重写
在Java中,方法重写是指在子类中重新定义父类中已经定义的方法。以下是Java方法重写的基本原则: 子类中的重写方法必须具有相同的方法签名(即相同的方法名、参数类型和返回类型)。子类中的重写方法不能比父类中的原方法具有更低的…...
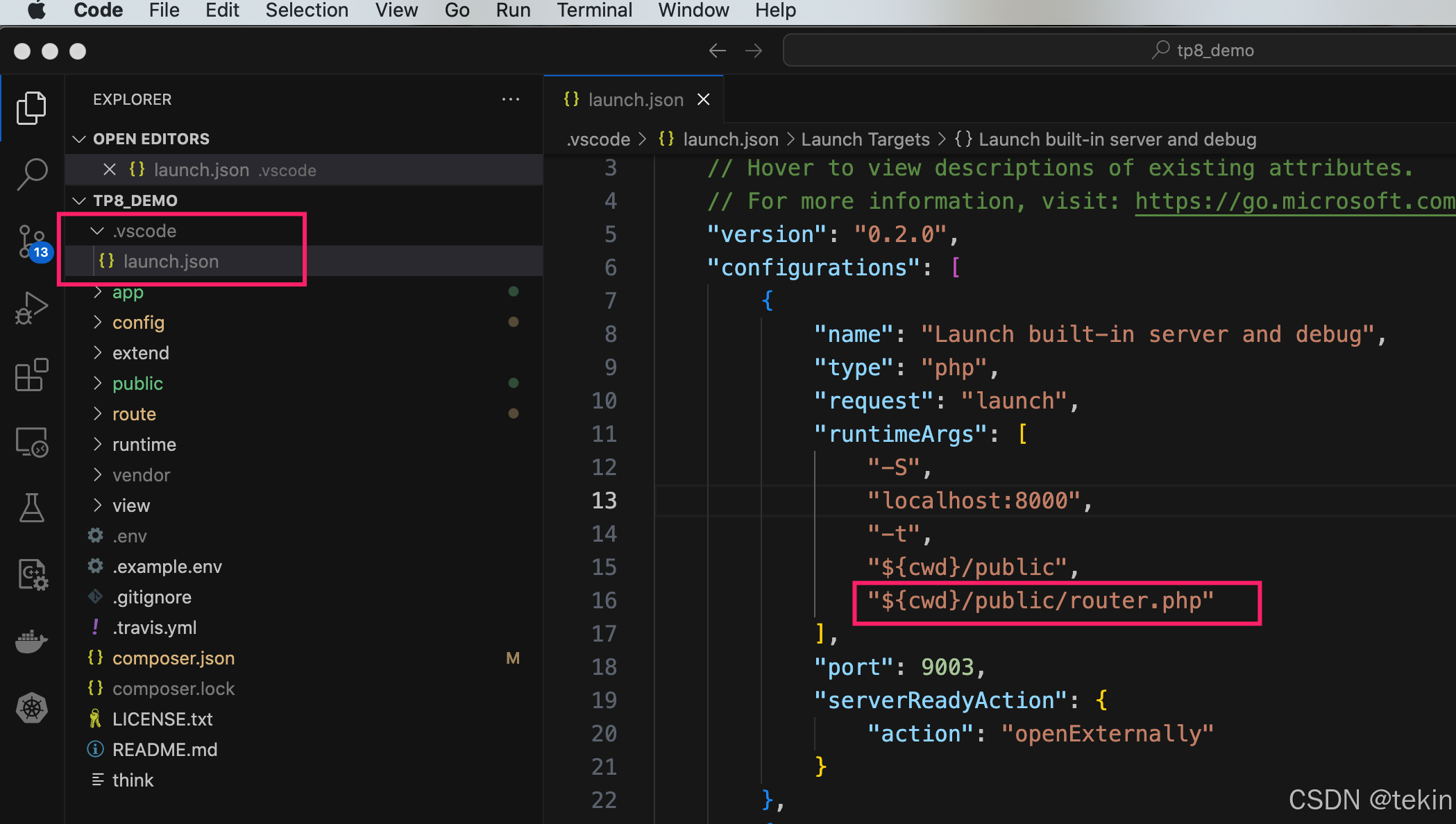
vscode通过.vscode/launch.json 内置php服务启动thinkphp 应用后无法加载路由解决方法
我们在使用vscode的 .vscode/launch.json Launch built-in server and debug 启动thinkphp应用后默认是未加载thinkphp的路由文件的, 这个就导致了,某些thinkphp的一些url路由无法访问的情况, 如http://0.0.0.0:8000/api/auth.admin/info这…...
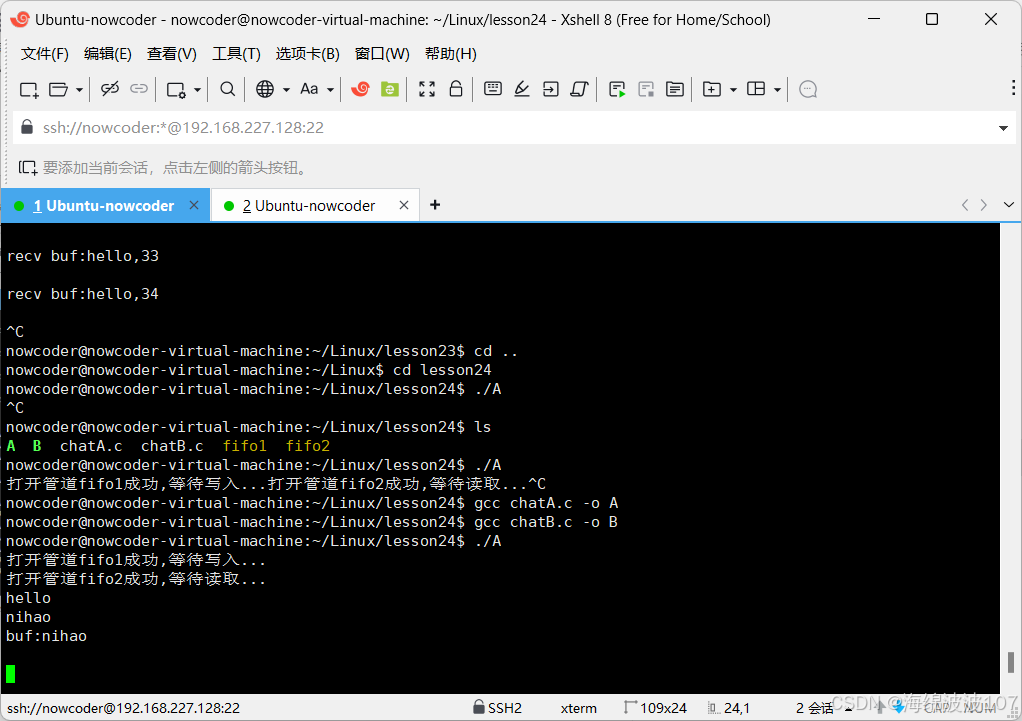
Webserver(2.6)有名管道
目录 有名管道有名管道使用有名管道的注意事项读写特性有名管道实现简单版聊天功能拓展:如何解决聊天过程的阻塞 有名管道 可以用在没有关系的进程之间,进行通信 有名管道使用 通过命令创建有名管道 mkfifo 名字 通过函数创建有名管道 int mkfifo …...
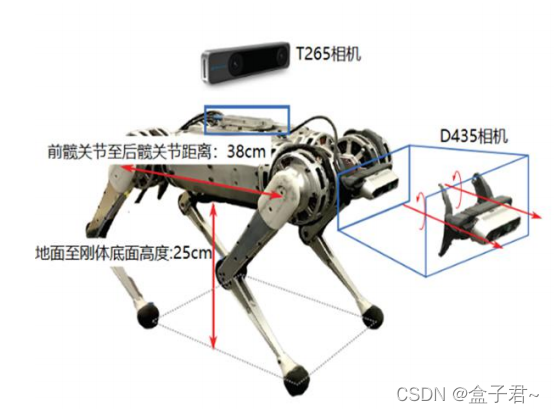
四足机器人实战篇之一:波士顿spot机器人工程实现分析
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 TODO:写完再整理 文章目录 系列文章目录前言一、机器人发展历史二、硬件系统及电机执行器篇硬件系统电机执行器传感器机处理器电气连接三、感知(视觉点云、局部地图、定位)篇1.深度相机获取…...

TensorFlow 预训练目标检测模型集合
Tensorflow 提供了一系列在不同数据集上预训练的目标检测模型,包括 COCO 数据集、Kitti 数据集、Open Images 数据集、AVA v2.1 数据集、iNaturalist 物种检测数据集 和 Snapshot Serengeti 数据集。这些模型可以直接用于推理,特别是当你对这些数据集中已…...

字符串的区别
C 和 Java 字符串的区别 最近 C 和 Java 在同步学习,都有个字符串类型,但二者不太一样,于是就做了些许研究。 在编程中,字符串作为数据类型广泛应用于不同的场景。虽然 C 和 Java 都允许我们处理字符串,但它们在字符…...

EMR Serverless Spark:一站式全托管湖仓分析利器
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人: 李钰(绝顶) | 阿里云智能集团资深技术专家,阿里云 EMR 团队负责人 活动: 2024 云栖大会 AI - 开源大数据专场 数据平台技术演变 …...

Linux find 匹配文件内容
在Linux中,你可以使用find命令结合-exec或者-execgrep来查找匹配特定内容的文件。以下是一些示例: 查找当前目录及其子目录下所有文件内容中包含"exampleText"的文件: find . -type f -exec grep -l "exampleText" {} \…...
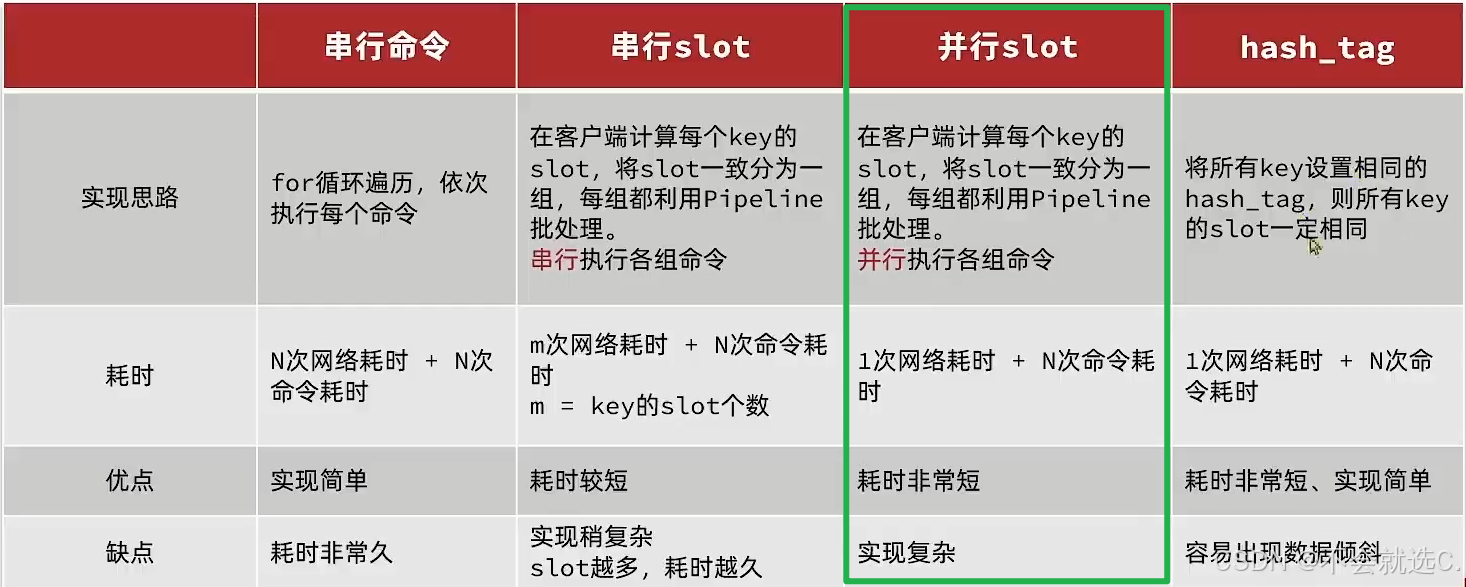
【Redis优化——如何优雅的设计key,优化BigKey,Pipeline批处理Key】
Redis优化——如何优雅的设计key,优化BigKey,Pipeline批处理Key 一、Key的设计1. 命名规范2. 长度限制在44字节以内 二、BigKey优化1. 查找bigkey2. 删除BigKey3. 优化BigKey 三、Pipeline批处理Key1. 单节点的Pipeline2. 集群下的Pipeline 一、Key的设计…...

OpenHTMLtoPDF:Java生态下的专业级HTML转PDF解决方案
OpenHTMLtoPDF:Java生态下的专业级HTML转PDF解决方案 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF…...

如何扩展Noisereduce:自定义降噪算法的开发指南
如何扩展Noisereduce:自定义降噪算法的开发指南 【免费下载链接】noisereduce Noise reduction in python using spectral gating (speech, bioacoustics, audio, time-domain signals) 项目地址: https://gitcode.com/gh_mirrors/no/noisereduce Noisereduc…...

ROS2 Humble下colcon编译实战:从创建workspace到运行自定义节点
ROS2 Humble下colcon编译实战:从创建workspace到运行自定义节点 在机器人开发领域,ROS2已经成为事实上的标准框架,而colcon作为其官方推荐的构建工具,掌握它的使用技巧能显著提升开发效率。本文将带您完成一个完整的ROS2项目构建流…...

5分钟掌握AMD处理器调优:新手也能轻松上手的硬件调试完整教程
5分钟掌握AMD处理器调优:新手也能轻松上手的硬件调试完整教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: htt…...

从环境变量到Git Bash:给Plink找个‘家’,让你的遗传数据分析命令随处可跑
从环境变量到Git Bash:打造遗传数据分析的高效工作流 在遗传数据分析的日常工作中,Plink作为核心工具几乎出现在每个分析流程中。但许多研究者都会遇到这样的困扰:每次打开新的终端窗口,要么需要反复输入冗长的路径,要…...

蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 [特殊字符]
蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 🚀 【免费下载链接】mogu_blog_v2 蘑菇博客(MoguBlog),一个基于微服务架构的前后端分离博客系统。Web端使用Vue Element , 移动端使用uniapp和ColorUI。后端使用Spring cloud Spr…...

电铲自主行走多耦合行为及轨迹控制技术【附代码】
✨ 长期致力于电铲、自主行走、多耦合行为、离散元法、反演滑模控制、轨迹控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)机电-离散元多体耦合动…...

从零封装一个MCP4728的C语言驱动库:支持STM32/HAL库,含EEPROM读写状态处理
构建高可靠MCP4728驱动库:STM32 HAL库实战与EEPROM状态管理 在嵌入式开发中,DAC(数模转换器)是连接数字世界与模拟世界的关键桥梁。MCP4728作为Microchip公司推出的4通道12位I2C接口DAC芯片,凭借其内置EEPROM存储和灵活…...
)
【Perplexity词组搭配查询权威基准测试】:覆盖医学/法律/工程三大垂直领域,17项指标碾压传统n-gram方法(数据已通过ACL评审)
更多请点击: https://intelliparadigm.com 第一章:Perplexity词组搭配查询权威基准测试概览 Perplexity(困惑度)作为衡量语言模型预测能力的核心指标,其在词组搭配(collocation)查询任务中的表…...

告别传统打捞船:浅析‘子母船’协同算法如何解决水库、湖泊的浅水区垃圾清理难题
水域清洁革命:子母船协同算法如何重塑浅水区垃圾治理格局 清晨的阳光洒在湖面上,波光粼粼中却漂浮着刺眼的塑料瓶和食品包装——这是全球水库、湖泊管理者每天都要面对的环保噩梦。传统清漂方式在浅水区域显得力不从心,而一种融合了分布式机…...