机器学习基础02
目录
1.特征工程
1.1特征工程概念
1.2特征工程的步骤
1.3特征工程-特征提取
1.3.1字典列表(json)特征提取
1.3.2文本特征提取
英文文本提取
中文文本提取
1.3.3TF-IDF文本特征词的稀有程度特征提取
2.无量纲化
2.1归一化
2.2标准化
2.3fit、fit_transform、transform
3.特征降维
3.1特征选择
3.1.1低方差过滤特征选择
3.1.2相关系数特征选择
3.2主成份分析(PCA)
1.特征工程
1.1特征工程概念
对特征进行相关的处理
特征工程是将任意数据转换为可用于机器学习的数字特征,如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。
1.2特征工程的步骤
(1)特征提取, 如果不是像dataframe那样的数据,要进行特征提取,比如字典特征提取,文本特征提取
(2)无量纲化(预处理)
(3)特征降维
1.3特征工程-特征提取
稀疏矩阵
稀疏矩阵是指一个矩阵中大部分元素为零,只有少数元素是非零的矩阵。
三元组表 (Coordinate List, COO):三元组表就是一种稀疏矩阵类型数据,存储非零元素的行索引、列索引和值:
(行,列) 数据
非稀疏矩阵(稠密矩阵)
非稀疏矩阵,或称稠密矩阵,是指矩阵中非零元素的数量与总元素数量相比接近或相等。
1.3.1字典列表(json)特征提取
- 创建转换器对象
sklearn.feature_extraction.DictVectorizer(sparse=True)
参数:
sparse=True返回类型为csr_matrix的稀疏矩阵
sparse=False表示返回的是数组,数组可调用.toarray()方法将稀疏矩阵转换为数组
-
转换器对象:
transfer=fit_transform(data)
转换器对象调用fit_transform(data)函数,返回转化后的矩阵或数组
- 获取特征名
transfer.get_feature_names_out()
import numpy as np
from sklearn.feature_extraction import DictVectorizer'''
字典列表特征提取
'''
data = [{'city': '成都', 'age': 30, 'temperature': 20},{'city': '重庆', 'age': 33, 'temperature': 60},{'city': '北京', 'age': 42, 'temperature': 80},{'city': '上海', 'age': 22, 'temperature': 70}, ]# 转为稀疏矩阵
transfer = DictVectorizer(sparse=True)
date_new = transfer.fit_transform(data)
print(date_new,'\n')
# 不转成三元组的形式:toarray()
print(date_new.toarray(),'\n')# 不转成三元组表的形式:sparse=False
transfer = DictVectorizer(sparse=False)
# 特征
print(transfer.get_feature_names_out())
date_new = transfer.fit_transform(data)
print(date_new,'\n')
1.3.2文本特征提取
-
英文文本提取
from sklearn.feature_extraction.text import CountVectorizer
transfer = CountVectorizer(stop_words=[ ])
data = transfer.fit_transform(documents)
关键字参数stop_words,表示词的黑名单
fit_transform函数的返回值为稀疏矩阵
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pddocuments = ["This is the first document.","This document is the second document.","And this is the third one.","Is this the first document?"
]# 创建转换器对象
transfer = CountVectorizer(stop_words=['is', 'and'])data = transfer.fit_transform(documents)
# print(data)feature_df = pd.DataFrame(data=data.toarray(),columns=transfer.get_feature_names_out()
)
print(feature_df)-
中文文本提取
下载jiaba
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
API
jieba.cut(str)
import jieba
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pddef chinese_cut(text):data = jieba.cut(text)data_lt = list(data)data_str = " ".join(data_lt)return data_strdocuments = ["这是第一份文件","此文档是第二个文档","这是第三个","这是第一份文件吗 "
]data_new = [chinese_cut(i) for i in documents]
transfer = CountVectorizer(stop_words=[])
data_final = transfer.fit_transform(data_new)df = pd.DataFrame(data=data_final.toarray(),columns=transfer.get_feature_names_out())
print(df)1.3.3TF-IDF文本特征词的稀有程度特征提取
词频(Term Frequency, TF),使词数归一化
TF = 该词在文章中出现的次数 / 文章词总数
逆文档频率(Inverse Document Frequency, IDF), 反映了该词在整个文档集合中的稀有程度
IDF = lg( 文档总数 / 包含该词的文档数+1 )
包含该词的文档数+1:使分母不为0
TF-IDF=TF*IDF
- API
from sklearn.feature_extraction.text import TfidfVectorizer
transfer = TfidfVectorizer(stop_words=[' '])
ti_idf = transfer.fit_transform(data_new)
import jieba
from sklearn.feature_extraction.text import TfidfVectorizerdef chinese_cut(text):data = jieba.cut(text)data_lt = list(data)data_str = " ".join(data_lt)return data_strdocuments = ["这是第一份文件","此文档是第二个文档","这是第三个","这是第一份文件吗 "
]
data_new = [chinese_cut(i) for i in documents]transfer = TfidfVectorizer(stop_words=['这是'])
ti_idf = transfer.fit_transform(data_new)df = pd.DataFrame(data=ti_idf.toarray(),columns=transfer.get_feature_names_out())
print(df)2.无量纲化
无量纲,即没有单位的数据
2.1归一化
公式
将原始数据映射到指定区间(默认为0-1)
x-xmin / xmax-xmin = y-a / b-a
原始数据的数值范围:[xmin,xmax]
指定区间:[a,b]
将原始数据x映射到指定区间的结果为:y
API
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:feature_range默认=(0,1) 为归一化后的值域,可以自定义
fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray, 不可以是稀疏矩阵
fit_transform函数的返回值为ndarray
示例
from sklearn.preprocessing import MinMaxScalerdata = [[2, 5, 4],[6, 1, 9],[3, 0, 7]]transfer = MinMaxScaler(feature_range=(0, 1))scaler_data = transfer.fit_transform(data)
print(scaler_data)缺点
最大值和最小值易受到异常点影响,所以鲁棒性较差。
2.2标准化
在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。



其中,z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的标准差
API
sklearn.preprocessing.StandardScale
transfer = StandardScaler()
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray
示例
df = pd.DataFrame(data=[[1, 2, 3, 4],[2, 1, 3, 4],[3, 2, 3, 4],[4, 2, 3, 4]]
)
# 实例化一个转换器
transfer = StandardScaler()# DataFrame进行标准化
standard_data = transfer.fit_transform(data)
print(standard_data, '\n')# 将DF转化为list,进行标准化
df_lt = df.values.tolist()
standard_data = transfer.fit_transform(df_lt)
print(standard_data, '\n')# 将DF转化为ndarray,进行标准化
df_arr = df.values
standard_data = transfer.fit_transform(df_arr)
print(standard_data, '\n')2.3fit、fit_transform、transform
fit、fit_transform和transform有不同的作用:
fit:
这个方法用来计算数据的统计信息,比如均值和标准差(在
StandardScaler的情况下)。
fit仅用训练集上。
transform:
这个方法使用已经通过
fit方法计算出的统计信息来转换数据。可以应用于任何数据集,包括训练集、验证集或测试集,
使用的统计信息必须来自于训练集。
fit_transform:
这个方法相当于先调用
fit再调用transform,但是它在内部执行得更高效。仅在训练集上使用
一旦scaler对象在x_train使用fit(),就已经得到统计信息。对于测试集x_test,只需要使用transform方法,因为我们不希望在测试集上重新计算任何统计信息,也不希望测试集的信息影响到训练过程。如果我们对x_test也使用fit_transform,测试集的信息就可能会影响到训练过程。
总结来说:常常是先fit(x_train)然后再transform(x_test,y_test)
3.特征降维
目的:降低数据集的维度,保留重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
-
特征选择
-
从原始特征集中挑选出最相关的特征
-
-
主成份分析(PCA)
-
主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
-
3.1特征选择
3.1.1低方差过滤特征选择
from sklearn.feature_selection import VarianceThreshold
transfer = VarianceThreshold(threshold)
from sklearn.feature_selection import VarianceThresholddf = pd.DataFrame(data=[[1, 2, 5, 4],[2, 1, 3, 6],[3, 2, 3, 4],[4, 2, 3, 4]],columns=['f1', 'f2', 'f3', 'f4'])# 定义一个低方差过滤器
transfer = VarianceThreshold(threshold=0.6)
vt_data = transfer.fit_transform(df)
print(vt_data)3.1.2相关系数特征选择
from scipy.stats import pearsonr
statistic,pvalue=pearsonr(data[" "], data[" "])
from scipy.stats import pearsonrdf = pd.DataFrame(data=[[1, -2, 5, 4],[2, -1, 3, 6],[3, -2, 3, 4],[4, -2, 3, 4]],columns =['f1','f2','f3','f4'])r1 = pearsonr(df['f1'],df['f2'])# 相关性
print(r1.statistic)#皮尔逊相关系数
print(r1.pvalue)#零假设,为非负数,越小越相关
3.2主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。

API
from sklearn.decomposition import PCA
transfer=PCA(n_components=None)
参数:
n_components:
实参为小数:表示降维后保留百分之多少的信息
实参为整数:表示减少到多少特征
from sklearn.decomposition import PCA
import numpy as npdata =np.random.rand(3,4)
# print(data)transfer = PCA(n_components=2)
data_new = transfer.fit_transform(data)
print(data_new)from sklearn.decomposition import PCA
import numpy as npdata =np.random.rand(3,4)
# print(data)transfer = PCA(n_components=0.8)
data_new = transfer.fit_transform(data)
print(data_new)相关文章:
机器学习基础02
目录 1.特征工程 1.1特征工程概念 1.2特征工程的步骤 1.3特征工程-特征提取 1.3.1字典列表(json)特征提取 1.3.2文本特征提取 英文文本提取 中文文本提取 1.3.3TF-IDF文本特征词的稀有程度特征提取 2.无量纲化 2.1归一化 2.2标准化 2.3fit、fit_transform、transfo…...

element plus的表格内容自动滚动
<el-table:data"tableData"ref"tableRef"borderstyle"width: 100%"height"150"><el-table-column prop"date" label"名称" width"250" /><el-table-column prop"name" label&…...

哈佛商业评论 | 未来商业的技术趋势:百度李彦宏谈技术如何变革商业
在《哈佛商业评论》的HBR IdeaCast节目中,百度联合创始人、首席执行官兼董事长李彦宏分享了他对人工智能(AI)和其他技术趋势的见解。这期节目讨论了百度如何将生成式AI融入业务,以及这些技术如何重塑我们的生活和工作方式。让我们…...

Pytorch如何将嵌套的dict类型数据加载到GPU
在PyTorch中,您可以使用.to(device)方法将嵌套的字典中的所有支持的Tensor对象转移到GPU。以下是一个简单的例子 import torch# 假设您已经有了一个名为device的GPU设备对象 device torch.device("cuda:0" if torch.cuda.is_available() else "cp…...

Shell基础2
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团…...

7z 解压器手机版与解压专家:安卓解压工具对决
7z 解压器手机版和解压专家都是在安卓设备上广受欢迎的解压软件。7z 解压器手机版由深圳乡里云网络科技有限公司开发,大小为 32.8M,支持多种常见的压缩文件格式,如.zip、.rar、.7z 等。 它对安卓操作系统的特性和用户习惯进行了优化…...

C++清除所有输出【DEV-C++】所有编辑器通用 | 算法基础NO.1
各位小伙伴们,上一期的保留小数位数教学够用一辈子,有不错的点赞量,可我连一个粉丝铁粉都没有,你愿意做我的第一个铁粉吗?OK废话不多说,开始! 温故与知心 可能你也学过,且是工作者…...

【Android、IOS、Flutter、鸿蒙、ReactNative 】启动页
Android 设置启动页 自定义 splash.xml 通过themes.xml配置启动页背景图 IOS 设置启动页 LaunchScreen.storyboard 设置为启动页 storyboard页面绘制 Assets.xcassets 目录下导入图片 AppLogo Flutter 设置启动页 Flutter Android 设置启动页 自定义 launch_background.xm…...

SpringBoot 2.2.10 无法执行Test单元测试
很早之前的项目今天clone现在,想执行一个业务订单的检查,该检查的代码放在test单元测试中,启动也是好好的,当点击对应的方法执行Test的时候就报错 tip:已添加spring-boot-test-starter 所以本身就引入了junit5的库 No…...
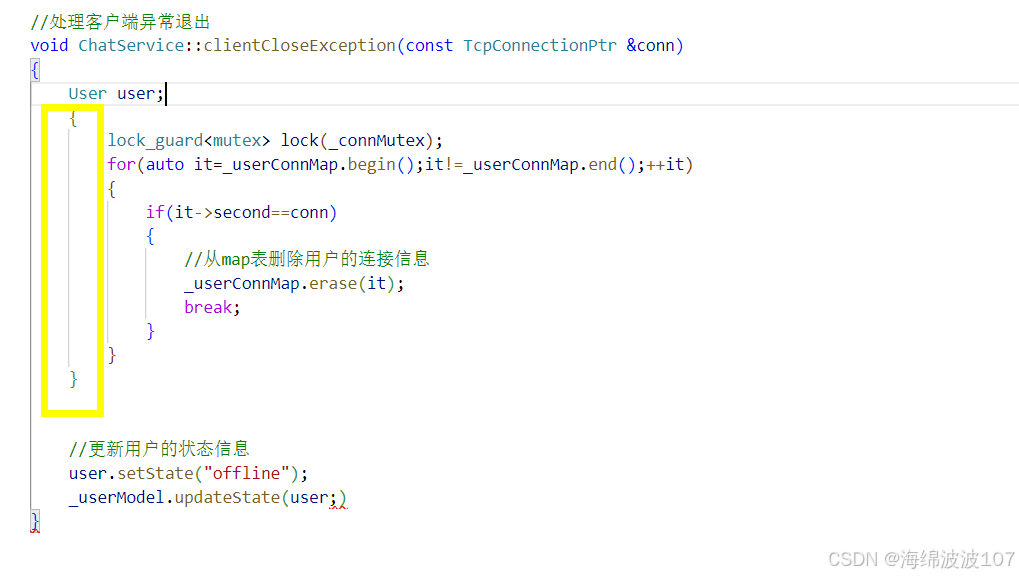
聊天服务器(8)用户登录业务
目录 登录状态业务层代码数据模型层代码记录用户的连接信息以及线程安全问题客户端异常退出业务 登录状态 登录且状态变为online 业务层代码 #include "chatservice.hpp" #include "public.hpp" #include <string> #include <muduo/base/Loggi…...

stm32在linux环境下的开发与调试
环境安装 注:文末提供一键脚本 下载安装stm32cubeclt 下载地址为:https://www.st.com/en/development-tools/stm32cubeclt.html 选择 linux版本下载安装 安装好后默认在家目录st下 > $ ls ~/st/stm32cubeclt_1.16.0 …...

flinkOnYarn并配置prometheus+grafana监控告警
flinkOnYarn并配置prometheusgrafana监控告警 一、相关服务版本: flink版本:1.17.2 pushgateway版本:1.10.0 prometheus版本:3.0.0 grafana-v11.3.0参考了网上的多个文档以及学习某硅谷的视频,总结了一下文档&#x…...

麒麟系统下docker搭建jenkins
首先我们需要创建宿主机挂载路径,我这里放在本地的/data/henkins/home,然后赋予权限,命令如下: mkdir -p /data/jenkins/home chown -R 1000:1000 /data/jenkins/home chmod -R 777 /data/jenkins/homedocker run -d --restart …...

论文阅读 - Causally Regularized Learning with Agnostic Data Selection
代码链接: GitHub - HMTTT/CRLR: CRLR尝试实现 https://arxiv.org/pdf/1708.06656v2 目录 摘要 INTRODUCTION 2 RELATED WORK 3 CAUSALLY REGULARIZED LOGISTIC REGRESSION 3.1 Problem Formulation 3.2 Confounder Balancing 3.3 Causally Regularized Lo…...

计算机网络之会话层
一、会话层的核心功能 会话层作为OSI模型的第五层,不仅承担着建立、管理和终止通信会话的基本任务,还隐含着许多复杂且关键的功能,这些功能共同确保了网络通信的高效、有序和安全。 1. 会话建立与连接管理: 身份验证与授权&…...

blind-watermark - 水印绑定
文章目录 一、关于 blind-watermark安装 二、bash 中使用三、Python 调用1、基本使用2、attacks on Watermarked Image3、embed images4、embed array of bits 四、并发五、相关 Project 一、关于 blind-watermark Blind watermark 基于 DWT-DCT-SVD. github : https://githu…...

reduce-scatter:适合分布式计算;Reduce、LayerNorm和Broadcast算子的执行顺序对计算结果的影响,以及它们对资源消耗的影响
目录 Gather Scatter Reduce reduce-scatter:适合分布式计算 Reduce、LayerNorm和Broadcast算子的执行顺序对计算结果的影响,以及它们对资源消耗的影响 计算结果理论正确性 资源消耗方面 Gather 这个也很好理解,就是把多个进程的数据拼凑在一起。 Scatter 不同于Br…...
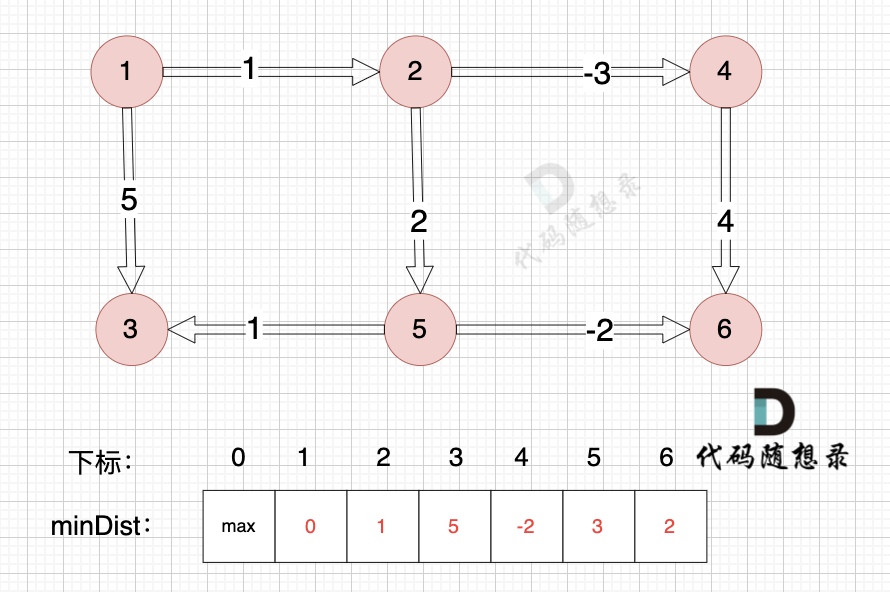
DAY64||dijkstra(堆优化版)精讲 ||Bellman_ford 算法精讲
dijkstra(堆优化版)精讲 题目如上题47. 参加科学大会(第六期模拟笔试) 邻接表 本题使用邻接表解决问题。 邻接表的优点: 对于稀疏图的存储,只需要存储边,空间利用率高遍历节点链接情况相对容…...

使用Git工具在GitHub的仓库中上传文件夹(超详细)
如何使用Git工具在GitHub的仓库中上传文件夹? 如果觉得博主写的还可以,点赞收藏关注噢~ 第一步:拥有一个本地的仓库 可以fork别人的仓库或者自己新创建 fork别人的仓库 或者自己创建一个仓库 按照要求填写完成后,点击按钮创建…...

Python酷库之旅-第三方库Pandas(218)
目录 一、用法精讲 1021、pandas.DatetimeIndex.inferred_freq属性 1021-1、语法 1021-2、参数 1021-3、功能 1021-4、返回值 1021-5、说明 1021-6、用法 1021-6-1、数据准备 1021-6-2、代码示例 1021-6-3、结果输出 1022、pandas.DatetimeIndex.indexer_at_time方…...
)
环境科学家都在偷偷用的NotebookLM技巧(2024中科院实测TOP5插件清单)
更多请点击: https://codechina.net 第一章:NotebookLM在环境科学研究中的范式变革 传统环境科学研究长期受限于多源异构数据整合困难、跨学科知识理解门槛高、因果推断缺乏可解释性支持等瓶颈。NotebookLM 作为基于用户自有文档构建的语义增强型AI协作…...
)
单卡训练mmsegmentation模型?先把这个SyncBN改成BN(附完整配置文件修改指南)
单卡训练mmsegmentation模型?先解决SyncBN这个关键配置 当你第一次在个人电脑或实验室的单一GPU设备上运行mmsegmentation训练脚本时,屏幕上突然弹出的SyncBN相关错误信息可能会让兴奋的心情瞬间跌入谷底。这个看似简单的配置问题,实际上反映…...

TypeScript + Next.js + Tailwind CSS 现代Web开发最佳实践模板解析
1. 项目概述:一个现代Web开发的“瑞士军刀”如果你最近在考虑启动一个Next.js项目,并且希望它从一开始就具备现代化的技术栈、清晰的代码结构和高效的开发体验,那么你很可能已经听说过或者正在寻找一个合适的“启动器”。theodorusclarence/t…...
)
手把手教你用kafka-storage.sh修复Kafka KRaft模式启动报错(附UUID生成与格式化全流程)
手把手教你用kafka-storage.sh修复Kafka KRaft模式启动报错(附UUID生成与格式化全流程) 当Kafka集群从ZooKeeper模式迁移到KRaft模式时,技术人员常会遇到因元数据问题导致的启动失败。本文将深入解析kafka-storage.sh工具的核心功能ÿ…...

个人开发者对比使用Taotoken前后在模型API管理与调用上的效率变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者使用 Taotoken 前后在模型 API 管理与调用上的效率变化 作为一名个人开发者,在探索和应用大模型能力时&…...

Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器
Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器 在仓储巡检、展厅导览等场景中,机器人需要频繁执行多目标点任务序列。传统编程方式每次修改路径都需要重新编译代码,而Rviz的Publish Point功能配合定制化开发,可以将…...

如何用MGit在Android手机上轻松管理Git仓库:完整指南
如何用MGit在Android手机上轻松管理Git仓库:完整指南 【免费下载链接】MGit A Git client for Android. 项目地址: https://gitcode.com/gh_mirrors/mg/MGit 你是否曾经希望在Android手机上也能像在电脑上一样轻松管理Git仓库?MGit就是为你量身打…...

Manage Buddy:轻量自托管团队协作工具的设计、部署与实战
1. 项目概述与核心价值最近在梳理团队内部工具链时,我重新审视了一个我们重度依赖的开源项目——maziminds/manage-buddy。这并非一个广为人知的明星项目,但在中小型技术团队,尤其是追求敏捷与效率的研发团队中,它扮演着“隐形冠军…...

Keil5编译报错‘Target not created’?别急着重装,先试试这几招排查思路
Keil5编译报错‘Target not created’的深度排查指南 当你满怀期待地点击Keil5的编译按钮,却看到冰冷的"Target not created"提示时,那种挫败感我深有体会。这个报错就像一扇紧闭的门,背后可能藏着各种原因——从简单的语法错误到复…...

YOLO26可运行项目,有上百个模块,都是我自己之前发SCI二区时,集成的一些模块,适合需要算法创新,模块改进的朋友。
智慧改进巡检-YOLO26可运行项目,有上百个模块,发SCI二区时,集成的一些模块,适合需要算法创新,模块改进的朋友。 目标检测,语义分割,关键点识别通用项目。 项目中的所有改进已经按功能类别进…...