Python数据结构day2
一、链表
1.1目的
解决顺序表存储数据有上限,并且插入和删除操作效率低的问题
1.2概念
链表:链式存储的线性表,使用随机物理内存存储逻辑上连续的数据
链表的组成:由一个个结点组成
结点:由数据域和链接域组成,是链表的基本单位
数据域:存储数据元素的区域
链接域:记录下一个结点所在位置的区域
头结点:虚设的一个结点,连接域专门记录链表第一个结点的位置,数据域专门记录链表的长度
1.3链表的种类
单向链表、双向链表、循环链表
二、单向链表
2.1单向链表的概念
只能通过头结点或链表的头,单向的访问后继结点的链表叫单向链表

2.2结点和链表类的格式
1】包含存储数据元素的数据域
2】有一个存储下一个结点的位置域
#封装普通节点的类
class Node:#构造函数,定义结点的属性def __init__(self,data):self.data=data#普通结点的数据域self.next=None#普通结点的连接域,刚构造的结点该位置域为空
#封装链表的类(封装头节点)
class Link_list():def __init__(self,node=None):self.size=0#头结点的数据域为0 链表的长度为0self.head=node#头结点的连接域指向None
2.3单向列表的相关操作(成员函数的封装)
1】单向链表的创建
2】判空
#判空def is_empty(self):return self.head# return self.size==0 或者判断长度是否为零3】头插
函数功能:将一个结点以头插的方式插入到头结点的后面
思路:

参数:self链表,要插入的数据
注意事项:需要申请结点封装数据
插入成功链表长度自增
#头插def add_head(self,value):#创建一个新的结点node=Node(value)node.next=self.headself.head=nodeself.size+=14】尾插

函数功能:将新的节点增加到链表的尾部。思路:(如上图)
函数返回值:无
函数名:符合命名规则
参数列表:self 链表,要插入的数据
注意事项:插入成功,链表自增
#尾插def add_tail(self, value):#创建一个结点nodenode = Node(value)#找最后一个结点# q = self.head# i=1# while i<self.size:# q=q.next# i+=1# q.next=node# self.size+=1#第二种方法q = self.headwhile q.next:q = q.nextq.next = nodeself.size += 1#第三种# while True:# q=q.next# if not q.next:# q.next = node# self.size+=1# break5】任意位置插

函数功能:在指定的位置插入一个节点 思路:如上图
函数返回值:无
函数名:符合命名规则
参数列表:self链表、要插入的位置、要插入的数据
注意事项:1、判断要插入的位置是否合理
2、成功插入 ;链表长度自增
3、如果是第一个位置,做头插
#任意位置插def add_any(self, id, value):node = Node(value)if id == 1:self.add_head(value)elif id == self.size+1:self.add_tail(value)elif id>self.size+1:print('插入失败')returnelse:q = self.headi = 1while i < id - 1:q = q.nexti += 1node.next = q.nextq.next = nodeself.size += 16】头删
#头删def del_head(self):self.head = self.head.nextself.size -= 17】尾删
#尾删def del_tail(self):if self.size==1:self.head=Noneelse:q = self.headfor i in range(self.size - 2):q = q.nextq.next = Noneself.size -= 18】任意位置删
#任意位置删def del_any(self,id):if id==1:self.del_head()else:q = self.headfor i in range(id - 2):q = q.nextq.next = q.next.nextself.size -= 19】遍历

函数功能:从头到尾打印出链表中每个节点的数据域的数据
函数返回值:无
函数名:符合命名规则
参数列表:self 链表
注意事项:判空
#遍历def show(self):#判空if self.is_empty():print('遍历失败')returnelse:q = self.headwhile q :print(q.data,end=' ')q = q.nextprint()相关文章:
Python数据结构day2
一、链表 1.1目的 解决顺序表存储数据有上限,并且插入和删除操作效率低的问题 1.2概念 链表:链式存储的线性表,使用随机物理内存存储逻辑上连续的数据 链表的组成:由一个个结点组成 结点:由数据域和链接域组成&a…...

后台通用tag面包屑
思路:要实现点击左侧菜单栏,页面跳转且显示面包屑(本文用的是TSVue3) 功能点: 最多显示5个标签超过5个时,自动移除最早的标签至少保留1个标签支持标签关闭功能 首先在store.ts 处理路由(点击过的路由,当前…...

oracle数据恢复—通过拼接数据库碎片的方式恢复Oracle数据的案例
Oracle数据库故障: 存储掉盘超过上限,lun无法识别。管理员重组存储的位图信息并导出lun,发现linux操作系统上部署的oracle数据库中有上百个数据文件的大小变为0kb。数据库的大小缩水了80%以上。 取出&并分析oracle数据库的控制文件。重组…...

node.js fluent-ffmpeg 桌面推流
1,安装fluent-ffmpeg,npm install fluent-ffmpeg 2,推流代码: //stream.js const ffmpeg require(fluent-ffmpeg); const rtmpUrl "rtmp://localhost:1935/live/desktop"; //ffmpeg -f gdigrab -i desktop -vcode…...

AWS的流日志
文章目录 一、aws如何观察vpc的日志?二、aws观测其vpc的入口日志三、 具体配置3.1、配置你的存储神器 S33.2、建立子网的流日志 一、aws如何观察vpc的日志? 排查问题的时候除了去抓包看具体的端口信息的时候,还可以根据其所在的vpc的子网信息…...

大数据新视界 -- 大数据大厂之 Hive 数据导入:多源数据集成的策略与实战(上)(3/ 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

Qt入门1——认识Qt的几个常用头文件和常用函数
1.头文件 ① #include <QPushButton>——“按钮”头文件; ② #include <QLabel>——“标签”头文件; ③ #include <QFont>——“字体”头文件; ④#include <QDebug>——输出相关信息; 2. 常用函数/类的基…...
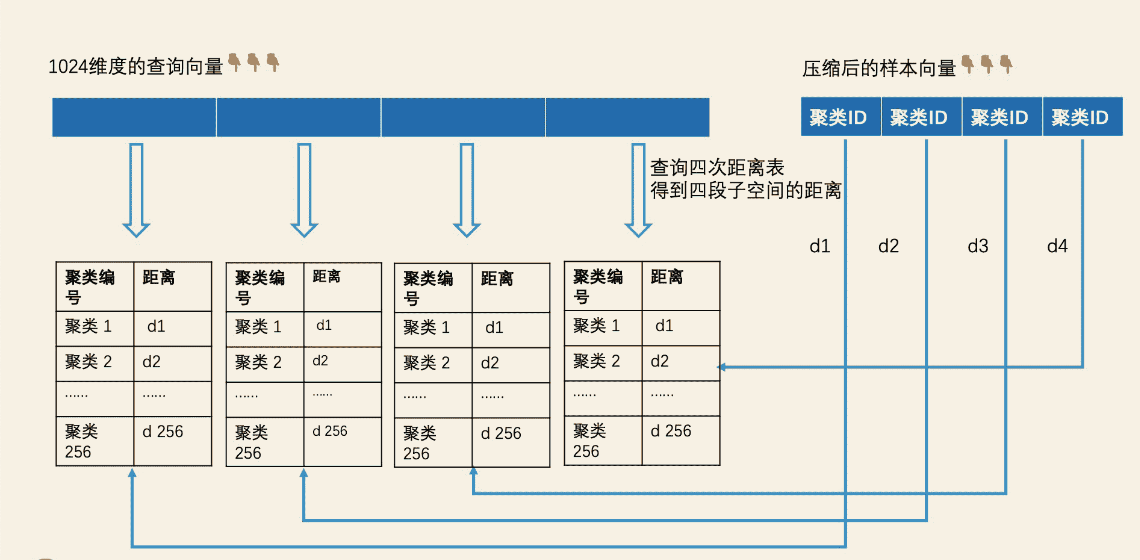
ElasticSearch学习篇17_《检索技术核心20讲》最邻近检索-局部敏感哈希、乘积量化PQ思路
目录 场景在搜索引擎和推荐引擎中,对相似文章去重是一个非常重要的环节,另外是拍照识花、摇一摇搜歌等场景都可以使用它快速检索。 基于敏感性哈希的检索更擅长处理字面上的相似而不是语义上的相似。 向量空间模型ANN检索加速思路 局部敏感哈希编码 随…...

在 Sublime Text 中直接预览 Markdown 文件
在 Sublime Text 中直接预览 Markdown 文件需要借助插件实现。以下是详细步骤: 1. 安装 Markdown Preview 插件 按下快捷键 CtrlShiftP (或 macOS 上的 CmdShiftP),打开命令面板。输入 Install Package 并选择 Package Control: Install Package。等待包…...

分词器的概念(通俗易懂版)
什么是分词器?简单点说就是将字符序列转化为数字序列,对应模型的输入。 通常情况下,Tokenizer有三种粒度:word/char/subword word: 按照词进行分词,如: Today is sunday. 则根据空格或标点进行分割[today, is, sunda…...

速通前端篇 —— CSS
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程程(ಥ_ಥ)-CSDN博客 所属专栏:速通前端 目录 CSS的介绍 基本语法规范 CSS选择器 标签选择器 class选择器 id选择器 复合选择器 通配符选择器 CSS常见样式 颜…...

数据库表设计范式
华子目录 MYSQL库表设计:范式第一范式(1NF)第二范式(2NF)第三范式(3NF)三范式小结巴斯-科德范式(BCNF)第四范式(4NF)第五范式(5NF&…...
经济增长初步
1.人均产出 人均产出,通常指的是一个国家、地区或组织在一定时期内,每个劳动人口平均创造的生产总值。它是衡量一个地区或国家经济效率和劳动生产率的重要指标。具体来说,人均产出可以通过以下公式计算: 人均产出总产出/劳动人口…...

【架构】主流企业架构Zachman、ToGAF、FEA、DoDAF介绍
文章目录 前言一、Zachman架构二、ToGAF架构三、FEA架构四、DoDAF 前言 企业架构(Enterprise Architecture,EA)是指企业在信息技术和业务流程方面的整体设计和规划。 最近接触到“企业架构”这个概念,转念一想必定和我们软件架构…...

时间请求参数、响应
(7)时间请求参数 1.默认格式转换 控制器 RequestMapping("/commonDate") ResponseBody public String commonDate(Date date){System.out.println("默认格式时间参数 date > "date);return "{module : commonDate}"; }…...

PyTorch图像预处理:计算均值和方差以实现标准化
在深度学习中,图像数据的预处理是一个关键步骤,它直接影响模型的训练效果和收敛速度。PyTorch提供的transforms.Normalize()函数允许我们对图像数据进行标准化处理,即减去均值并除以方差。这一步骤对于提高模型性能至关重要。 为什么需要标准…...
slice介绍slice查看器
Android Jetpack架构组件(十)之Slices - 阅读清单 - 腾讯云开发者社区-腾讯云 slice 查看器apk 用adb intall 安装 Releases android/user-interface-samples GitHubMultiple samples showing the best practices in the user interface on Android. - Releases android/u…...

Android音频采集
在 Android 开发领域,音频采集是一项非常重要且有趣的功能。它为各种应用程序,如语音聊天、音频录制、多媒体内容创作等提供了基础支持。今天我们就来深入探讨一下 Android 音频采集的两大类型:Mic 音频采集和系统音频采集。 1. Mic音频采集…...
通过轻易云平台实现聚水潭数据高效集成到MySQL的技术方案
聚水潭数据集成到MySQL的技术案例分享 在本次技术案例中,我们将详细探讨如何通过轻易云数据集成平台,将聚水潭的数据高效、可靠地集成到MySQL数据库中。具体方案为“聚水谭-店铺查询单-->BI斯莱蒙-店铺表”。这一过程不仅需要处理大量数据的快速写入…...

类和对象( 中 【补充】)
目录 一 . 赋值运算符重载 1.1 运算符重载 1.2 赋值运算符重载 1.3 日期类实现 1.3.1 比较日期的大小 : 1.3.2 日期天数 : 1.3.3 日期 - 天数 : 1.3.4 前置/后置 1.3.5 日期 - 日期 1.3.6 流插入 << 和 流提取 >> 二 . 取地址运算符重载 2.1 const…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器
3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经想要修改Minecraf…...

基于Arduino Uno与MQ-2传感器的智能气体检测报警系统DIY全攻略
1. 项目概述与核心思路最近在捣鼓家里的智能安防,琢磨着能不能自己做一个成本可控、反应灵敏的气体检测报警装置。市面上成品烟雾报警器虽然成熟,但要么功能单一,要么价格不菲,而且很难根据自己的需求进行定制化调整,比…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...

终极指南:使用MuSiC单细胞反卷积工具解密组织细胞组成
终极指南:使用MuSiC单细胞反卷积工具解密组织细胞组成 【免费下载链接】MuSiC Multi-subject Single Cell Deconvolution 项目地址: https://gitcode.com/gh_mirrors/music2/MuSiC 还在为复杂的组织样本分析而困惑吗?想要从批量RNA测序数据中精确…...

终极鼠标连点器MouseClick:5分钟免费获取完整使用指南
终极鼠标连点器MouseClick:5分钟免费获取完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...