Python图注意力神经网络GAT与蛋白质相互作用数据模型构建、可视化及熵直方图分析...
全文链接:https://tecdat.cn/?p=38617
本文聚焦于图注意力网络GAT在蛋白质 - 蛋白质相互作用数据集中的应用。首先介绍了研究背景与目的,阐述了相关概念如归纳设置与转导设置的差异。接着详细描述了数据加载与可视化的过程,包括代码实现与分析,如数据集的读取、处理以及图数据加载器的构建等。通过对数据形状和类型的分析,深入理解数据特性。最后强调了在项目开发过程中测试代码以及可视化的重要性,为 GAT 在 数据集上的进一步研究与应用奠定基础(点击文末“阅读原文”获取完整代码数据)。
一、引言
本研究围绕图注意力网络(GAT)展开,重点探讨其在蛋白质相互作用数据集中的应用。GAT 作为一种强大的图神经网络模型,在处理具有复杂结构的数据时展现出独特的优势。本文本旨在解释如何在归纳设置下使用 GAT,并以 数据集为例进行深入研究。通过对 蛋白质 数据集的分析与处理,期望能够为生物信息学等领域的研究提供有力的技术支持与理论依据。
二、相关概念
(一)归纳设置与转导设置
在图神经网络中,归纳设置和转导设置是两种不同的数据处理方式。转导设置通常针对单个图,例如 Cora 数据集,将图中的一些节点(而非图本身)划分为训练、验证和测试集。在训练过程中,仅使用训练节点的标签信息,但在正向传播时,由于空间 GNN 的工作原理,会聚合邻居节点的特征向量,其中部分邻居节点可能属于验证集甚至测试集。这里主要利用了邻居节点的结构信息和特征,而非其标签信息。
而归纳设置则更类似于计算机视觉或自然语言处理中的常见方式。在这种设置下,拥有一组训练图、一组独立的验证图和一组独立的测试图。这种设置使得模型能够在不同的图数据上进行训练和评估,具有更强的泛化能力。
三、数据加载与可视化
(一)数据加载
在数据加载部分,首先定义了一些必要的函数和类。例如,json_read 函数用于读取 JSON 格式的数据:
def json_read(path):with open(path, 'r') as file:data = json.load(file)return data该函数接受一个文件路径作为参数,打开文件并读取其中的 JSON 数据,最后返回读取的数据。load_graph_data 函数则用于加载 蛋白质 数据集的图数据:
if dataset_name == DatasetType.蛋白质.name.lower(): # 蛋白质 - 蛋白质相互作用数据集# 若 蛋白质 数据路径不存在,则首次使用时下载if not os.path.exists(蛋白质_PATH):
os.makedirs(蛋白质_PATH)# 步骤 1:下载 蛋白质.zip(包含 蛋白质 数据集)zip\\\\\\_tmp\\\\\\_path = os.path.join(蛋白质_PATH, '蛋白质.zip')download\\\\\\_url\\\\\\_to\\\\\\_file(蛋白质\\\\\\_URL, zip\\\\\\_tmp\\\\\\_path)# 步骤 2:解压with zipfile.ZipFile(zip\\\\\\_tmp\\\\\\_path) as zf:zf.extractall(path=蛋白质_PATH)print(f'解压至: {蛋白质_PATH} 完成。')# 步骤 3:删除临时资源文件该函数根据配置信息加载 蛋白质 数据集,包括下载数据(若不存在)、读取节点特征、标签和图拓扑结构等,并将数据整理为适合训练的格式,最后返回相应的数据加载器。
GraphD 类用于从分割中获取单个图数据:
class GraphDt(Dataset):def \\\_\\\\\\_init\\\\\\_\\\_(self, node\\\\\\_features\\\\\\_list, node\\\\\\_labels\\\\\\_list, edge\\\\\\_index\\\\\\_list):self.node\\\\\\_features\\\\\\_list = node\\\\\\_features\\\\\\_listself.node\\\\\\_labels\\\\\\_list = node\\\\\\_labels\\\\\\_listself.edge\\\\\\_index\\\\\\_list = edge\\\\\\_index\\\\\\_list# 需定义 len 和 getitem 函数以便 DataLoader 正常工作def \\\_\\\\\\_len\\\\\\_\\\_(self):return len(self.edge\\\\\\_index\\\\\\_list)(二)数据可视化
为了可视化数据:
if should_visualize:plot\\\\\\_in\\\\\\_out\\\\\\_degree\\\\\\_distributions(edge\\\\\\_index.numpy(), graph.number\\\\\\_of\\\\\\_nodes(), dataset\\\\\\_name)visualize\\\\\\_graph(edge\\\\\\_index.numpy(), node\\\\\\_labels\\\\\\[mask\\\\\\], dataset\\\\\\_name)四、数据形状与类型分析
通过加载数据并获取一批训练数据,对数据的形状和类型进行了分析。以特定的 蛋白质 训练图(批次大小为 1)为例,其具有 3021 个节点,每个节点有 50 个特征,这与 蛋白质 数据集的特性相关,每个节点的特征是多种基因集信息的组合。蛋白质 数据集共有 121 个类别,且每个节点可以关联多个类别,属于多标签分类数据集。该图包含 94359 条边(包括自环),与 Cora 数据集的 13k 条边相比数量较多。此外,边索引的数据类型为 int64,这是由于 PyTorch 中 index_select 函数的要求,而节点标签可以使用 float32 类型,因为 nn.BCEWithLogitsLoss 不需要 long/int64 类型,这样可以节省内存。
基于蛋白质相互作用网络的数据可视化与图注意力网络(GAT)模型研究
接下来聚焦于蛋白质相互作用网络,深入探讨其数据可视化与图注意力网络(GAT)模型的应用。通过详细分析节点度分布、构建并训练 GAT 模型以及对模型进行可视化分析,揭示了 蛋白质 网络的结构特征与 GAT 模型在多标签分类任务中的有效性,为相关领域的研究提供了有价值的参考。
一、引言
在生物信息学领域,蛋白质相互作用网络的研究具有至关重要的意义。理解 蛋白质 网络的结构和特性,有助于深入探究蛋白质的功能以及生物体内的复杂生理过程。本文旨在通过数据可视化和构建图注意力网络(GAT)模型,对 蛋白质 网络进行全面的分析与研究,为相关领域的进一步探索奠定基础。
二、蛋白质 数据可视化
(一)节点度分布可视化
为了初步了解 蛋白质 网络中节点的连接情况,我们首先研究节点的度分布,即节点拥有的输入/输出边的数量,这是衡量图连通性的一个重要指标。
运行以下代码以可视化 蛋白质 的度分布:
num\\\\\\_of\\\\\\_nodes = len(node_labels)
plot\\\\\\_in\\\\\\_out\\\\\\_degree\\\\\\_distributions(edge\\\\\\_index, num\\\\\\_of\\\\\\_nodes, config\\\\\\['dataset\\\\\\_name'\\\\\\])
(二)蛋白质 图可视化
接下来,我们将可视化 蛋白质 图。以下代码用于构建和绘制 蛋白质 图:
dataset\\\\\\_name = config\\\\\\['dataset\\\\\\_name'\\\\\\]
visualization_tool = GraphVisualizationTool.IGRAPH
# 如果 edge_index 是 torch.Tensor 类型,则将其转换为 numpy 数组
if isinstance(edge_index, torch.Tensor):edge\\\\\\_index\\\\\\_np = edge_index.cpu().numpy()
# 如果 node_labels 是 torch.Tensor 类型,则将其转换为 numpy 数组
if isinstance(node_labels, torch.Tensor):
从可视化结果可以得出以下结论:
由于我们将 蛋白质 视为无向图,因此前两个图相同。
与 Cora 相比,更多的节点具有大量的边,但大多数节点的边数仍然较少。
第三个图以直方图的形式清晰地展示了这一点,大多数节点只有 1 - 20 条边(因此在最左侧有峰值),并且与 Cora 相比,分布更为分散。
需要注意的是,我不得不清除此单元格的原始输出,否则文件会非常大。这里仅展示了一个任意的 蛋白质 训练图示例,结果可能会有所不同(共有 20 个训练图)。
点击标题查阅往期内容

MATLAB图注意力网络GAT多标签图分类预测可视化

左右滑动查看更多
01

02

03

04

GAT 模型理解
GAT 模型类定义
首先创建一个高级类,用于构建 GAT 模型。该类主要将各层堆叠到对象中,并将数据(特征、边索引)打包成元组。
class GAT(torch.nn.Module):"""最有趣且最具挑战性的实现是实现 #3。Imp1 和 imp2 在细节上有所不同,但基本相同。"""def \\\_\\\\\\_init\\\\\\_\\\_(self, num\\\\\\_of\\\\\\_layers, num\\\\\\_heads\\\\\\_per\\\\\_layer, num\\\\GAT 层定义
接下来定义 GATLayer 类,该类是 GAT 模型的核心组成部分。
# 源节点在边索引中的维度位置src\\\\\\_nodes\\\\\\_dim = 0# 目标节点在边索引中的维度位置trg\\\\\\_nodes\\\\\\_dim = 1# 节点维度(在张量中 "N" 的位置,axis 可能是更熟悉的术语)nodes_dim = 0# 注意力头维度head_dim = 1def \\\_\\\\\\_init\\\\\\_\\\_(self, num\\\\\\_in\\\\\\_features, num\\\\\\_out\\\\\\_features, num\\\\\\_of\\\\\\_heads, concat=True, activation=nn.ELU(),dropout\\\\\\_prob=0.6, add\\\\\\_skip\\\\\\_connection=True, bias=True, log\\\\\\_attention_weights=False):super().\\\_\\\\\\_init\\\\\\_\\\_()self.num\\\\\\_of\\\\\\_heads = num\\\\\\_of\\\\\\_heads训练 GAT 模型(蛋白质 多标签分类)
相关常量定义
首先定义一些训练相关的常量,包括训练阶段枚举、日志记录器、早停相关变量以及模型保存路径等。
from torch.utils.tensorboard import SummaryWriter
# 3 种不同的模型训练/评估阶段,用于 train.py
class LoopPhase(enum.Enum):TRAIN = 0,基于图注意力网络(GAT)的模型训练与可视化分析
接下来我们详细阐述了图注意力网络(GAT)在特定数据集(如 蛋白质)上的训练过程及相关可视化分析。通过定义一系列实用函数来构建训练模型所需的组件,包括数据加载、模型架构定义、训练循环设置等,并对训练得到的模型进行注意力和熵可视化,以深入理解 GAT 模型的学习效果与特性。
一、引言
图注意力网络(GAT)在处理图结构数据方面具有重要意义。在本文中,我们将深入探讨其在 蛋白质 数据集上的应用,涵盖从模型训练到可视化分析的完整流程,旨在揭示 GAT 模型在该数据集上的表现及内在机制。
二、模型训练相关函数定义
(一)获取训练状态函数
import git
import re # 正则表达式模块
def get\\\\\\_training\\\\\\_state(training_config, model):training_state = {# 获取代码仓库的提交哈希值"commit\\\\\\_hash": git.Repo(search\\\\\\_parent_directories=True).head.object.hexsha,该函数用于收集训练过程中的重要信息,包括代码版本信息(通过提交哈希值体现)、训练数据集名称、训练轮数、测试性能指标以及模型的结构和参数状态等。这些信息对于后续的模型分析、比较和复现具有重要价值。
(二)打印模型元数据函数
def print\\\\\\_model\\\\\\_metadata(training_state):# 构建打印头部信息header = f'\\\\\n{"*"\\\\\\*5} Model training metadata: {"\\\\\\*"*5}'print(header)for key, value in training_state.items():# 不打印模型参数字典,因为其内容为大量数字if key!= 'state_dict':
print(f'{key}: {value}')print(f'{"*" * len(header)}\\\\\n')此函数用于以清晰的格式打印模型训练的元数据,除了模型参数字典外,将其他关键信息如数据集名称、训练轮数等展示出来,方便用户快速了解模型训练的基本情况。
三、命令行参数解析函数
此函数利用 argparse 模块解析命令行参数,涵盖训练过程中的各种设置,如训练轮数、学习率、是否使用 GPU 等,同时也包括数据集相关和日志记录相关的参数。通过合理设置这些参数,可以灵活地调整模型训练过程,满足不同的实验需求。
四、GAT 模型训练函数
\['force\\\\\_cpu'\\\\\\] else "cpu")# 步骤 1:准备数据加载器data\\\\\\_loader\\\\\\_train, data\\\\\\_loader\\\\\\_val, data\\\\\\_loader\\\\\\_test = load\\\\\\_graph\\\\\\_data(config, device)# 步骤 2:准备模型gat = GAT(num\\\\\\_of\\\\\\_layers=config\\\\\\['num\\\\\\_of\\\\\\_layers'\\\\\\],num\\\\\\_heads\\\\\\_per\\\\\\_layer=config\\\\\\['num\\\\\\_heads\\\\\\_per\\\\\\_layer'\\\\\\],num\\\\\\_features\\\\\\_per\\\\\\_layer=config\\\\\\['num\\\\\\_features\\\\\\_per\\\\\\_layer'\\\\\\],该函数是 GAT 模型在 蛋白质 数据集上的训练主函数,按照特定的步骤进行操作。首先根据设备情况(GPU 或 CPU)准备数据加载器,然后构建 GAT 模型并定义损失函数和优化器,接着通过装饰器函数简化训练和验证循环,最后在训练过程中进行训练循环、验证循环,并根据需要进行测试,最终将训练得到的模型状态保存下来。
图注意力网络(GAT)的熵直方图可视化分析
摘要: 接下来聚焦于图注意力网络(GAT)中熵直方图的可视化研究。阐述了熵概念在 GAT 模型分析中的引入缘由,详细介绍了相关函数的构建与作用,包括绘制熵直方图函数以及整体可视化函数。通过在 蛋白质 数据集上的应用与结果展示,深入探讨了 GAT 模型学习到的注意力模式与均匀注意力模式的差异,为理解 GAT 模型的学习效果提供了重要视角。
熵直方图可视化原理
在 GAT 模型的研究中,熵直方图可视化是一种重要的分析手段。当提及“熵”时,人们可能会疑惑它在此处的作用。事实上,这并不复杂。在 GAT 模型中,注意力系数总和为 1,这就形成了一种概率分布。而有概率分布就可以计算熵,熵能够量化分布中的信息量(对于专业人士而言,它是自信息的期望值)。若对熵的概念不熟悉,可参考精彩视频,不过在理解本研究的可视化目的时,并不需要深入掌握熵的理论。
其核心思想如下:假设有一个“假设性的”GAT 模型,它对每个节点的邻域具有恒定的注意力(即所有分布是均匀的),我们计算每个邻域的熵,并根据这些熵值绘制直方图。然后将其与我们训练得到的 GAT 模型的直方图进行比较,观察两者的差异。如果两个直方图完全重叠,意味着我们的 GAT 模型具有均匀的注意力模式;重叠越小,则分布越不均匀。在此,我们关注的并非信息本身,而是直方图的匹配程度。这有助于清晰地了解 GAT 模型学习到的注意力模式是否有意义。若 GAT 学习到的是恒定注意力,那么使用 GCN 或更简单的模型可能就足够了。
实验运行与结果分析
最后运行 函数:
visualize\\\\\\_entropy\\\\\\_histograms(model_name,dataset_name,
)得到的结果如以下图片所示:



从结果可以看出,浅蓝色直方图(训练后的 GAT)与橙色直方图(均匀注意力 GAT)相比发生了倾斜。并且由于均匀分布具有最高的熵,所以它们向左倾斜,这是符合预期的。如果之前通过边厚度绘制的可视化结果未能使您信服,那么熵直方图的结果将更具说服力。通过熵直方图可视化,我们能够更深入地理解 GAT 模型在 蛋白质 数据集上学习到的注意力模式与均匀注意力模式的差异,从而评估 GAT 模型的有效性和独特性,为进一步优化和应用 GAT 模型提供有力的依据。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python图注意力神经网络GAT与蛋白质相互作用数据模型构建、可视化及熵直方图分析》。
点击标题查阅往期内容
【视频讲解】Python深度神经网络DNNs-K-Means(K-均值)聚类方法在MNIST等数据可视化对比分析
MATLAB用CNN-LSTM神经网络的语音情感分类深度学习研究
Python用CEEMDAN-LSTM-VMD金融股价数据预测及SVR、AR、HAR对比可视化
Python注意力机制Attention下CNN-LSTM-ARIMA混合模型预测中国银行股票价格|附数据代码
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用CNN-LSTM、ARIMA、Prophet股票价格预测的研究与分析|附数据代码
【视频讲解】线性时间序列原理及混合ARIMA-LSTM神经网络模型预测股票收盘价研究实例
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类



![]()

相关文章:
Python图注意力神经网络GAT与蛋白质相互作用数据模型构建、可视化及熵直方图分析...
全文链接:https://tecdat.cn/?p38617 本文聚焦于图注意力网络GAT在蛋白质 - 蛋白质相互作用数据集中的应用。首先介绍了研究背景与目的,阐述了相关概念如归纳设置与转导设置的差异。接着详细描述了数据加载与可视化的过程,包括代码实现与分析…...

2024年图像处理、多媒体技术与机器学习
重要信息 官网:www.ipmml.org 时间:2024年12月27-29日 地点:中国-大理 简介 2024年图像处理、多媒体技术与机器学习(CIPMT 2024)将于2024年12月27-29日于中国大理召开。将围绕图像处理与多媒体技术、机器学习等在…...
java 1.8+springboot文件上传+vue3+ts+antdv
1.参考 使用SpringBoot优雅的实现文件上传_51CTO博客_springboot 上传文件 2.postman测试 报错 :postman调用时body参数中没有file单词 Resolved [org.springframework.web.multipart.support.MissingServletRequestPartException: Required request part file is…...
【机器人】机械臂轨迹和转矩控制对比
动力学控制和轨迹跟踪控制是机器人控制中的两个概念,它们在目标、方法和应用上有所不同,但也有一定关联。以下是它们的区别和联系: 1. 动力学控制 动力学控制是基于机器人动力学模型的控制方法,目标是控制机器人关节力矩或力&…...

如何利用矩阵化简平面上的二次型曲线
二次型曲线的定义 在二维欧式平面上,一个二次型曲线都可以写成一个关于 x , y x,y x,y的二元二次多项式: F ( x , y ) a 11 x 2 2 a 12 x y a 22 y 2 2 a 1 x 2 a 2 y a 0 0 \begin{equation} F(x,y)a_{11}x^22a_{12}xya_{22}y^22a_1x2a_2ya_00…...
【系统移植】制作SD卡启动——将uboot烧写到SD卡
在开发板上启动Linux内核,一般有两种方法,一种是从EMMC启动,还有一种就是从SD卡启动,不断哪种启动方法,当开发板上电之后,首先运行的是uboot。 制作SD卡启动,首先要将uboot烧写到SD卡ÿ…...
sql server 数据库还原,和数据检查
右键数据库选择还原, 还原的备份文件必须选择在本地的文件(远程文件没有试过)还原数据库名字可以修改,然后file选择中有个2个目录data file 的目录 ,和log data 的目录都可以重新选择还原到的新的目录,不要…...
工业大数据分析算法实战-day12
文章目录 day12时序分解STL(季节性趋势分解法)奇异谱分析(SSA)经验模态分解(EMD) 时序分割ChangpointTreeSplitAutoplait有价值的辅助 时序再表征 day12 今天是第12天,昨天主要是针对信号处理算…...
Hive其一,简介、体系结构和内嵌模式、本地模式的安装
目录 一、Hive简介 二、体系结构 三、安装 1、内嵌模式 2、测试内嵌模式 3、本地模式--最常使用的模式 一、Hive简介 Hive 是一个框架,可以通过编写sql的方式,自动的编译为MR任务的一个工具。 在这个世界上,会写SQL的人远远大于会写ja…...
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测 目录 LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.LSTM-SVM时序预测 | Matlab基于LSTM…...

MacPorts 中安装高/低版本软件方式,以 RabbitMQ 为例
查询信息 这里以 RabbitMQ 为例,通过搜索得到默认安装版本信息: port search rabbitmq-server结果 ~/Downloads> port search rabbitmq-server rabbitmq-server 3.11.15 (net)The RabbitMQ AMQP Server ~/Downloads>获取二进制文件 但当前官网…...
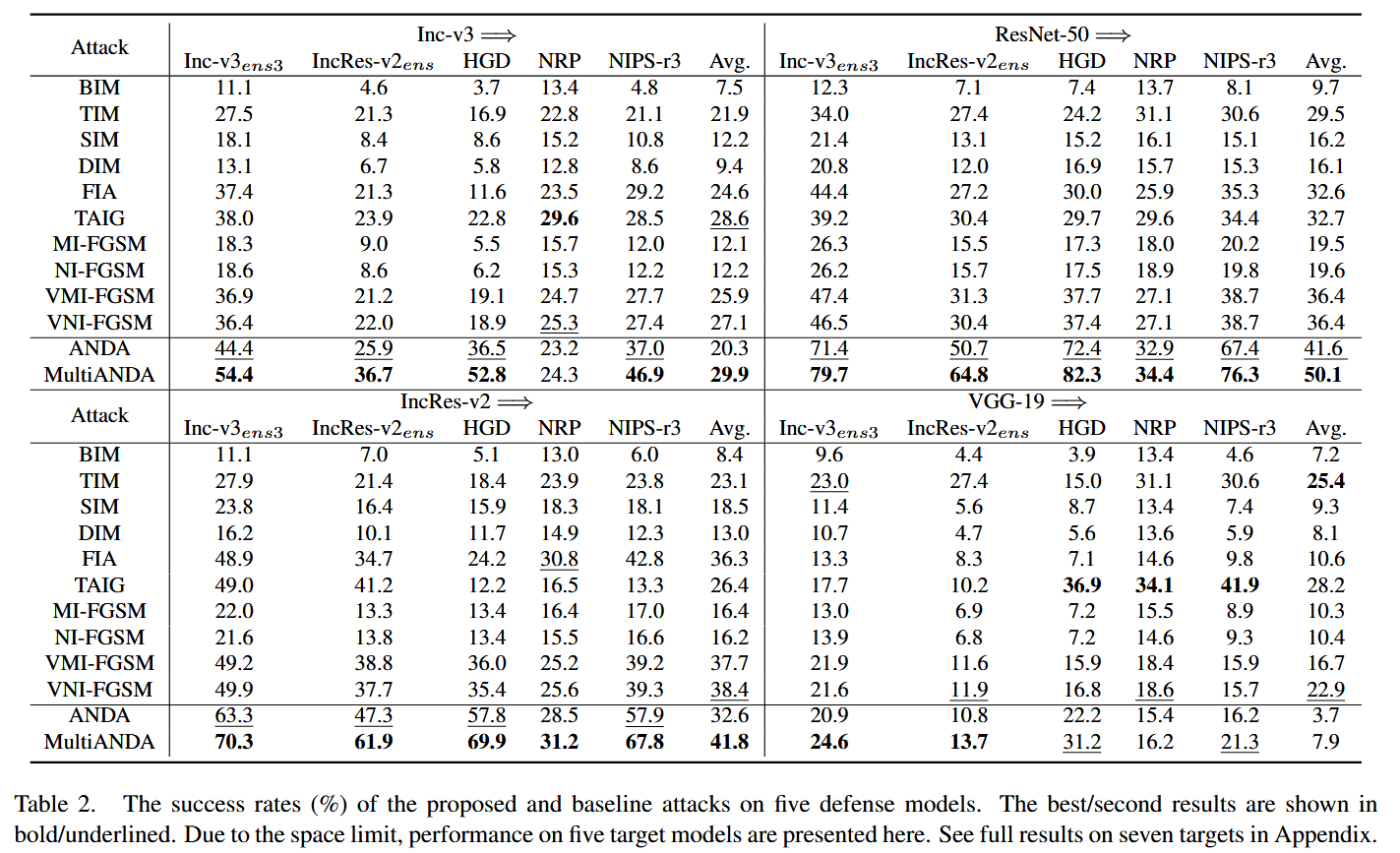
CVPR2024 | 通过集成渐近正态分布学习实现强可迁移对抗攻击
Strong Transferable Adversarial Attacks via Ensembled Asymptotically Normal Distribution Learning 摘要-Abstract引言-Introduction相关工作及前期准备-Related Work and Preliminaries1. 黑盒对抗攻击2. SGD的渐近正态性 提出的方法-Proposed Method随机 BIM 的渐近正态…...

建投数据与腾讯云数据库TDSQL完成产品兼容性互认证
近日,经与腾讯云联合测试,建投数据自主研发的人力资源信息管理系统V3.0、招聘管理系统V3.0、绩效管理系统V2.0、培训管理系统V3.0通过腾讯云数据库TDSQL的技术认证,符合腾讯企业标准的要求,产品兼容性良好,性能卓越。 …...

群晖利用acme.sh自动申请证书并且自动重载证书的问题解决
前言 21年的时候写了一个在群晖(黑群晖)下利用acme.sh自动申请Let‘s Encrypt的脚本工具 群晖使用acme自动申请Let‘s Encrypt证书脚本,自动申请虽然解决了,但是自动重载一直是一个问题,本人也懒,一想到去…...

质量小议51 - 茧房
茧房:茧房是指蚕茧所建的住所或空间,由一个蚕丝囊完全包裹住的一个密封的空间。 -- CSDN创作助手 信息茧房 - 指通过互联网和数字技术,将个人封闭在一个虚拟的信息环境中,使其只接收来自特定渠道的信息,而屏蔽其他信息…...

【C++图论】2359. 找到离给定两个节点最近的节点|1714
本文涉及知识点 C图论 打开打包代码的方法兼述单元测试 LeetCode2359. 找到离给定两个节点最近的节点 给你一个 n 个节点的 有向图 ,节点编号为 0 到 n - 1 ,每个节点 至多 有一条出边。 有向图用大小为 n 下标从 0 开始的数组 edges 表示,…...

重拾设计模式-外观模式和适配器模式的异同
文章目录 目的不同适配器模式:外观模式: 结构和实现方式不同适配器模式:外观模式: 对客户端的影响不同适配器模式:外观模式: 目的不同 适配器模式: 主要目的是解决两个接口不兼容的问题&#…...

51c自动驾驶~合集42
我自己的原文哦~ https://blog.51cto.com/whaosoft/12888355 #DriveMM 六大数据集全部SOTA!最新DriveMM:自动驾驶一体化多模态大模型(美团&中山大学) 近年来,视觉-语言数据和模型在自动驾驶领域引起了广泛关注…...

34 Opencv 自定义角点检测
文章目录 cornerEigenValsAndVecscornerMinEigenVal示例 cornerEigenValsAndVecs void cornerEigenValsAndVecs(InputArray src, --单通道输入8位或浮点图像OutputArray dst, --输出图像,同源图像或CV_32FC(6)int blockSize, --邻域大小值int ape…...

信创技术栈发展现状与展望:机遇与挑战并存
一、引言 在信息技术应用创新(信创)战略稳步推进的大背景下,我国信创技术栈已然在诸多关键层面收获了亮眼成果,不过也无可避免地遭遇了一系列亟待攻克的挑战。信创产业作为我国达成信息技术自主可控这一目标的关键一招,…...

douyin-downloader:抖音音频高效提取全攻略
douyin-downloader:抖音音频高效提取全攻略 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批…...

Krita AI Diffusion IP-Adapter功能异常深度排查与解决方案
Krita AI Diffusion IP-Adapter功能异常深度排查与解决方案 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitcode.com/g…...

张量维度操控心法:从reshape到升维降维,吃透PyTorch形状操作的底层逻辑
✨ 张量维度操控心法:从reshape到升维降维,吃透PyTorch形状操作的底层逻辑🔐 张量形状操作的黄金法则:形状是视角,内容是本质🔧 reshape函数:零侵入的形状重塑神器核心原理与执行规则实操代码与…...

基于Phi-4-mini-reasoning的智能运维异常检测系统
基于Phi-4-mini-reasoning的智能运维异常检测系统 1. 运维监控的痛点与智能化需求 运维团队每天都要面对海量的日志数据、监控指标和系统告警。传统监控系统往往只能做到简单的阈值告警,当系统出现异常时,运维人员需要手动翻阅成千上万条日志ÿ…...
)
河海大学材料科学与工程及材料与化工专业考研复试资料(含《材料分析方法》笔试专项)
温馨提示:文末有联系方式河海大学材料类考研复试资料全面升级 本套资料专为报考河海大学材料科学与工程、材料与化工两个硕士专业的考生设计,聚焦复试核心笔试科目——《材料分析方法》,助力精准高效备考。由2025届一志愿录取考生权威整理 所…...

重组胶原蛋白 | 可溶性蛋白 | 蛋白纯化 | 原核与真核系统
在生命科学研究中,重组胶原蛋白(Recombinant Collagen)作为一种关键的生物大分子,因其独特的结构特点和在细胞外基质研究中的重要性而被广泛关注。一、胶原蛋白分子构成与分类胶原蛋白(Collagen)是动物体内…...

跨平台部署YOLOv5的路径陷阱:从WindowsPath错误看Python pathlib的兼容性设计
1. 当WindowsPath遇上Linux:YOLOv5部署的路径陷阱 最近帮朋友调试一个YOLOv5模型部署问题,场景特别典型:在Windows训练好的目标检测模型,迁移到Linux服务器就报错。错误信息直指一个看似简单的路径问题:"NotImple…...
并启动API服务)
PyTorch 2.8镜像快速部署:5分钟验证torch.cuda.is_available()并启动API服务
PyTorch 2.8镜像快速部署:5分钟验证torch.cuda.is_available()并启动API服务 1. 镜像概述与环境准备 PyTorch 2.8深度学习镜像是一个开箱即用的高性能计算环境,专为现代AI工作负载优化。这个预配置环境能让你跳过繁琐的安装过程,直接进入模…...

基于大数据 Spark+Hadoop+Hive的中国不同城市奶茶品牌的影响力分析
前言现如今在中国市场中,奶茶行业以其别具一格的魅力和庞大的年轻消费群体,具备一些研究价值。伴随着消费者需求的日益多样化和市场竞争的逐步激烈,奶茶品牌在中国不同城市的影响力呈现出显著的差异。本研究基于这一背景,以中国不…...

如何通过炉石传说自动化工具实现游戏效率提升?
如何通过炉石传说自动化工具实现游戏效率提升? 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本)(2024.01.25停更至国服回归) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Scrip…...