数据迁移工具,用这8种!
前言
最近有些小伙伴问我,ETL数据迁移工具该用哪些。
ETL(是Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业应用来说,我们经常会遇到各种数据的处理、转换、迁移的场景。
今天特地给大家汇总了一些目前市面上比较常用的ETL数据迁移工具,希望对你会有所帮助。
1.Kettle
Kettle是一款国外开源的ETL工具,纯Java编写,绿色无需安装,数据抽取高效稳定 (数据迁移工具)。
Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。
Kettle 中文名称叫水壶,该项目的主程序员 MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。

Kettle 这个 ETL 工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。

Kettle 家族目前包括 4 个产品:Spoon、Pan、CHEF、Kitchen。
-
SPOON:允许你通过图形界面来设计 ETL 转换过程(Transformation)。 -
PAN:允许你批量运行由 Spoon 设计的 ETL 转换 (例如使用一个时间调度器)。Pan 是一个后台执行的程序,没有图形界面。 -
CHEF:允许你创建任务(Job)。任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。任务通过允许每个转换,任务,脚本等等。任务将会被检查,看看是否正确地运行了。 -
KITCHEN:允许你批量使用由 Chef 设计的任务 (例如使用一个时间调度器)。KITCHEN 也是一个后台运行的程序。
2.Datax
DataX是阿里云 DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

设计理念:为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状:DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

DataX 3.0六大核心优势:
-
可靠的数据质量监控
-
丰富的数据转换功能
-
精准的速度控制
-
强劲的同步性能
-
健壮的容错机制
-
极简的使用体验
3.DataPipeline
DataPipeline采用基于日志的增量数据获取技术( Log-based Change Data Capture ),支持异构数据之间丰富、自动化、准确的语义映射构建,同时满足实时与批量的数据处理。
可实现 Oracle、IBM DB2、MySQL、MS SQL Server、PostgreSQL、GoldenDB、TDSQL、OceanBase 等数据库准确的增量数据获取。
平台具备“数据全、传输快、强协同、更敏捷、极稳定、易维护”六大特性。
在支持传统关系型数据库的基础上,对大数据平台、国产数据库、云原生数据库、API 及对象存储也提供广泛的支持,并在不断扩展。
DataPipeline 数据融合产品致力于为用户提供企业级数据融合解决方案,为用户提供统一平台同时管理异构数据节点实时同步与批量数据处理任务,在未来还将提供对实时流计算的支持。
采用分布式集群化部署方式,可水平垂直线性扩展的,保证数据流转稳定高效,让客户专注数据价值释放。

产品特点:
-
全面的数据节点支持:支持关系型数据库、NoSQL数据库、国产数据库、数据仓库、大数据平台、云存储、API等多种数据节点类型,可自定义数据节点。 -
高性能实时处理:针对不同数据节点类型提供TB级吞吐量、秒级低延迟的增量数据处理能力,加速企业各类场景的数据流转。 -
分层管理降本增效:采用“数据节点注册、数据链路配置、数据任务构建、系统资源分配”的分层管理模式,企业级平台的建设周期从三到六个月减少为一周。 -
无代码敏捷管理:提供限制配置与策略配置两大类十余种高级配置,包括灵活的数据对象映射关系,数据融合任务的研发交付时间从2周减少为5分钟。 -
极稳定高可靠:采用分布式架构,所有组件均支持高可用,提供丰富容错策略,应对上下游的结构变化、数据错误、网络故障等突发情况,可以保证系统业务连续性要求。 -
全链路数据可观测:配备容器、应用、线程、业务四级监控体系,全景驾驶舱守护任务稳定运行。自动化运维体系,灵活扩缩容,合理管理和分配系统资源。
4.Talend
Talend (踏蓝) 是第一家针对的数据集成工具市场的 ETL (数据的提取 Extract、传输 Transform、载入 Load) 开源软件供应商。

Talend 以它的技术和商业双重模式为 ETL 服务提供了一个全新的远景。它打破了传统的独有封闭服务,提供了一个针对所有规模的公司的公开的,创新的,强大的灵活的软件解决方案。
5.DataStage
DataStage,即IBM WebSphere DataStage,是一套专门对多种操作数据源的数据抽取、转换和维护过程进行简化和自动化,并将其输入数据集市或数据仓库目标数据库的集成工具,可以从多个不同的业务系统中,从多个平台的数据源中抽取数据,完成转换和清洗,装载到各种系统里面。
其中每步都可以在图形化工具里完成,同样可以灵活地被外部系统调度,提供专门的设计工具来设计转换规则和清洗规则等,实现了增量抽取、任务调度等多种复杂而实用的功能。其中简单的数据转换可以通过在界面上拖拉操作和调用一些 DataStage 预定义转换函数来实现,复杂转换可以通过编写脚本或结合其他语言的扩展来实现,并且 DataStage 提供调试环境,可以极大提高开发和调试抽取、转换程序的效率。
Datastage 操作界面

-
对元数据的支持:Datastage 是自己管理 Metadata,不依赖任何数据库。
-
参数控制:Datastage 可以对每个 job 设定参数,并且可以 job 内部引用这个参数名。
-
数据质量:Datastage 有配套用的 ProfileStage 和 QualityStage 保证数据质量。
-
定制开发:提供抽取、转换插件的定制,Datastage 内嵌一种类 BASIC 语言,可以写一段批处理程序来增加灵活性。
-
修改维护:提供图形化界面。这样的好处是直观、傻瓜式的;不好的地方就是改动还是比较费事(特别是批量化的修改)。
Datastage 包含四大部件:
-
Administrator:新建或者删除项目,设置项目的公共属性,比如权限。 -
Designer:连接到指定的项目上进行 Job 的设计; -
Director:负责 Job 的运行,监控等。例如设置设计好的 Job 的调度时间。 -
Manager:进行 Job 的备份等 Job 的管理工作。
6.Sqoop
Sqoop 是 Cloudera 公司创造的一个数据同步工具,现在已经完全开源了。
目前已经是 hadoop 生态环境中数据迁移的首选 Sqoop 是一个用来将 Hadoop 和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 :MySQL ,Oracle ,Postgres 等)中的数据导入到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导入到关系型数据库中。

他将我们传统的关系型数据库 | 文件型数据库 | 企业数据仓库 同步到我们的 hadoop 生态集群中。
同时也可以将 hadoop 生态集群中的数据导回到传统的关系型数据库 | 文件型数据库 | 企业数据仓库中。
那么 Sqoop 如何抽取数据呢?

-
首先 Sqoop 去 rdbms 抽取元数据。
-
当拿到元数据之后将任务切成多个任务分给多个 map。
-
然后再由每个 map 将自己的任务完成之后输出到文件。
7.FineDataLink
FineDataLink是国内做的比较好的ETL工具,FineDataLink是一站式的数据处理平台,具备高效的数据同步功能,可以实现实时数据传输、数据调度、数据治理等各类复杂组合场景的能力,提供数据汇聚、研发、治理等功能。
FDL拥有低代码优势,通过简单的拖拽交互就能实现ETL全流程。

FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。
8.canal
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。

早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括:
-
数据库镜像
-
数据库实时备份
-
索引构建和实时维护(拆分异构索引、倒排索引等)
-
业务 cache 刷新
-
带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
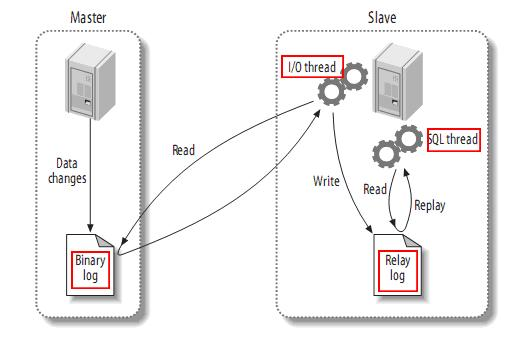
-
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)。
-
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)。
-
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据。
canal 工作原理:
-
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
-
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
-
canal 解析 binary log 对象(原始为 byte 流)
相关文章:
数据迁移工具,用这8种!
前言 最近有些小伙伴问我,ETL数据迁移工具该用哪些。 ETL(是Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业应用来说,我们经常会遇到各种数据的处理、转换、迁移的场景。 今天特地给大家汇总了一些目前…...
Sapro编程软件
Sapro软件是由西门子建筑科技公司开发的一款编程软件,主要用于Climatix控制器的编程、调试及相关功能实现.以下是其具体介绍: • 功能强大:可进行HVAC控制编程,实现设备控制、HMI用户访问和设备集成等功能,满足复杂的…...

Python图注意力神经网络GAT与蛋白质相互作用数据模型构建、可视化及熵直方图分析...
全文链接:https://tecdat.cn/?p38617 本文聚焦于图注意力网络GAT在蛋白质 - 蛋白质相互作用数据集中的应用。首先介绍了研究背景与目的,阐述了相关概念如归纳设置与转导设置的差异。接着详细描述了数据加载与可视化的过程,包括代码实现与分析…...

2024年图像处理、多媒体技术与机器学习
重要信息 官网:www.ipmml.org 时间:2024年12月27-29日 地点:中国-大理 简介 2024年图像处理、多媒体技术与机器学习(CIPMT 2024)将于2024年12月27-29日于中国大理召开。将围绕图像处理与多媒体技术、机器学习等在…...
java 1.8+springboot文件上传+vue3+ts+antdv
1.参考 使用SpringBoot优雅的实现文件上传_51CTO博客_springboot 上传文件 2.postman测试 报错 :postman调用时body参数中没有file单词 Resolved [org.springframework.web.multipart.support.MissingServletRequestPartException: Required request part file is…...
【机器人】机械臂轨迹和转矩控制对比
动力学控制和轨迹跟踪控制是机器人控制中的两个概念,它们在目标、方法和应用上有所不同,但也有一定关联。以下是它们的区别和联系: 1. 动力学控制 动力学控制是基于机器人动力学模型的控制方法,目标是控制机器人关节力矩或力&…...

如何利用矩阵化简平面上的二次型曲线
二次型曲线的定义 在二维欧式平面上,一个二次型曲线都可以写成一个关于 x , y x,y x,y的二元二次多项式: F ( x , y ) a 11 x 2 2 a 12 x y a 22 y 2 2 a 1 x 2 a 2 y a 0 0 \begin{equation} F(x,y)a_{11}x^22a_{12}xya_{22}y^22a_1x2a_2ya_00…...
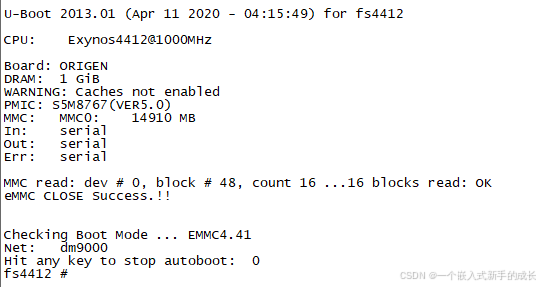
【系统移植】制作SD卡启动——将uboot烧写到SD卡
在开发板上启动Linux内核,一般有两种方法,一种是从EMMC启动,还有一种就是从SD卡启动,不断哪种启动方法,当开发板上电之后,首先运行的是uboot。 制作SD卡启动,首先要将uboot烧写到SD卡ÿ…...
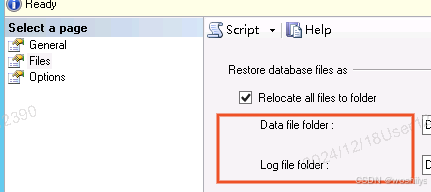
sql server 数据库还原,和数据检查
右键数据库选择还原, 还原的备份文件必须选择在本地的文件(远程文件没有试过)还原数据库名字可以修改,然后file选择中有个2个目录data file 的目录 ,和log data 的目录都可以重新选择还原到的新的目录,不要…...
工业大数据分析算法实战-day12
文章目录 day12时序分解STL(季节性趋势分解法)奇异谱分析(SSA)经验模态分解(EMD) 时序分割ChangpointTreeSplitAutoplait有价值的辅助 时序再表征 day12 今天是第12天,昨天主要是针对信号处理算…...
Hive其一,简介、体系结构和内嵌模式、本地模式的安装
目录 一、Hive简介 二、体系结构 三、安装 1、内嵌模式 2、测试内嵌模式 3、本地模式--最常使用的模式 一、Hive简介 Hive 是一个框架,可以通过编写sql的方式,自动的编译为MR任务的一个工具。 在这个世界上,会写SQL的人远远大于会写ja…...
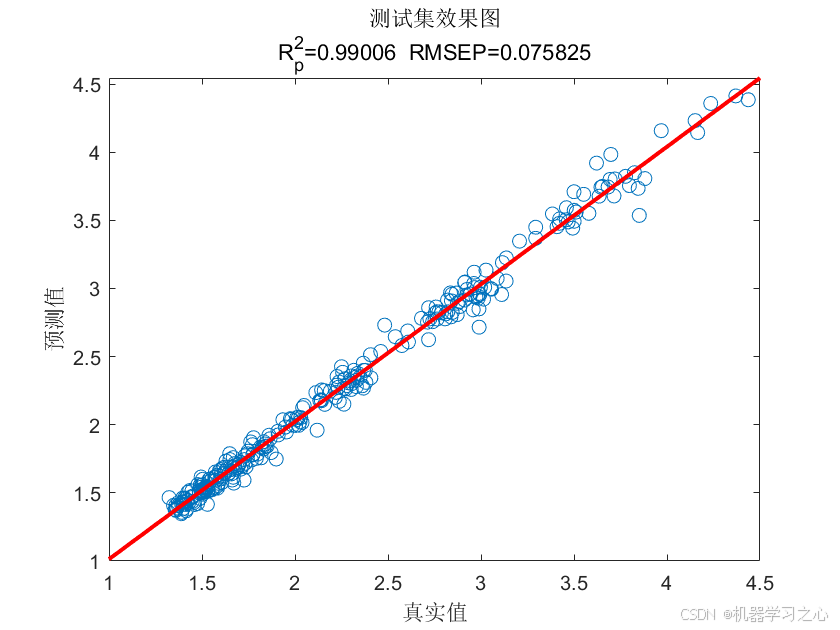
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测 目录 LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.LSTM-SVM时序预测 | Matlab基于LSTM…...

MacPorts 中安装高/低版本软件方式,以 RabbitMQ 为例
查询信息 这里以 RabbitMQ 为例,通过搜索得到默认安装版本信息: port search rabbitmq-server结果 ~/Downloads> port search rabbitmq-server rabbitmq-server 3.11.15 (net)The RabbitMQ AMQP Server ~/Downloads>获取二进制文件 但当前官网…...
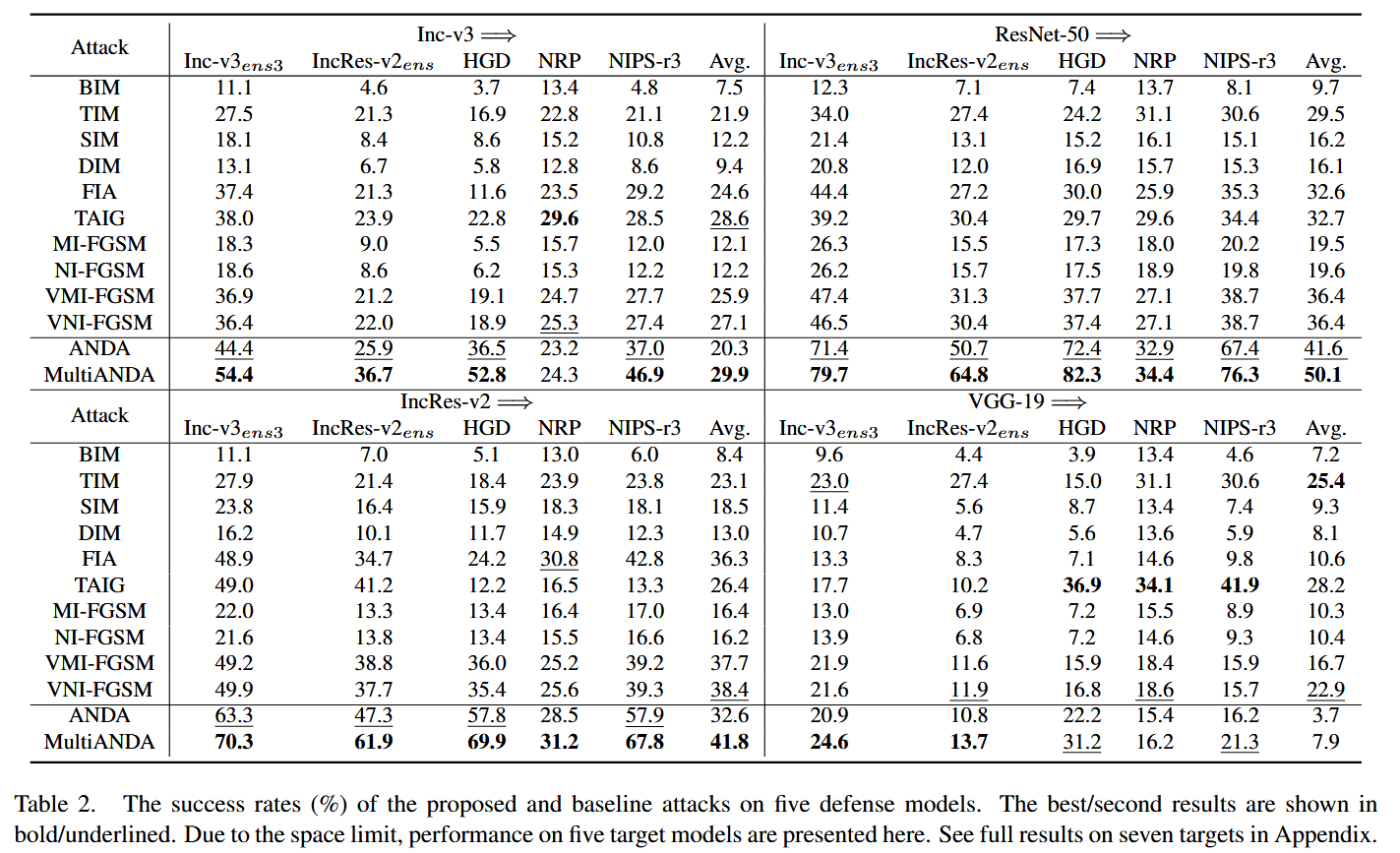
CVPR2024 | 通过集成渐近正态分布学习实现强可迁移对抗攻击
Strong Transferable Adversarial Attacks via Ensembled Asymptotically Normal Distribution Learning 摘要-Abstract引言-Introduction相关工作及前期准备-Related Work and Preliminaries1. 黑盒对抗攻击2. SGD的渐近正态性 提出的方法-Proposed Method随机 BIM 的渐近正态…...

建投数据与腾讯云数据库TDSQL完成产品兼容性互认证
近日,经与腾讯云联合测试,建投数据自主研发的人力资源信息管理系统V3.0、招聘管理系统V3.0、绩效管理系统V2.0、培训管理系统V3.0通过腾讯云数据库TDSQL的技术认证,符合腾讯企业标准的要求,产品兼容性良好,性能卓越。 …...

群晖利用acme.sh自动申请证书并且自动重载证书的问题解决
前言 21年的时候写了一个在群晖(黑群晖)下利用acme.sh自动申请Let‘s Encrypt的脚本工具 群晖使用acme自动申请Let‘s Encrypt证书脚本,自动申请虽然解决了,但是自动重载一直是一个问题,本人也懒,一想到去…...

质量小议51 - 茧房
茧房:茧房是指蚕茧所建的住所或空间,由一个蚕丝囊完全包裹住的一个密封的空间。 -- CSDN创作助手 信息茧房 - 指通过互联网和数字技术,将个人封闭在一个虚拟的信息环境中,使其只接收来自特定渠道的信息,而屏蔽其他信息…...

【C++图论】2359. 找到离给定两个节点最近的节点|1714
本文涉及知识点 C图论 打开打包代码的方法兼述单元测试 LeetCode2359. 找到离给定两个节点最近的节点 给你一个 n 个节点的 有向图 ,节点编号为 0 到 n - 1 ,每个节点 至多 有一条出边。 有向图用大小为 n 下标从 0 开始的数组 edges 表示,…...

重拾设计模式-外观模式和适配器模式的异同
文章目录 目的不同适配器模式:外观模式: 结构和实现方式不同适配器模式:外观模式: 对客户端的影响不同适配器模式:外观模式: 目的不同 适配器模式: 主要目的是解决两个接口不兼容的问题&#…...

51c自动驾驶~合集42
我自己的原文哦~ https://blog.51cto.com/whaosoft/12888355 #DriveMM 六大数据集全部SOTA!最新DriveMM:自动驾驶一体化多模态大模型(美团&中山大学) 近年来,视觉-语言数据和模型在自动驾驶领域引起了广泛关注…...

如何用轻量级工具解决Windows运行Android应用难题?2024最新6种方案深度测评
如何用轻量级工具解决Windows运行Android应用难题?2024最新6种方案深度测评 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在数字化办公与娱乐深度融合的今…...

从零开始:使用ecCodes库高效解析GRIB文件
1. 为什么需要ecCodes库处理GRIB文件 第一次接触气象数据时,我被GRIB文件搞得一头雾水。这种二进制格式就像个黑盒子,明明知道里面装着宝贵的温度、气压、风速数据,却不知道怎么取出来。后来发现ecCodes库就像开罐器,能轻松打开这…...

零基础玩转AI绘画:WuliArt Qwen-Image Turbo快速入门指南
零基础玩转AI绘画:WuliArt Qwen-Image Turbo快速入门指南 1. 为什么选择WuliArt Qwen-Image Turbo? AI绘画领域近年来发展迅猛,但对于普通用户而言,最大的痛点不是模型能力不足,而是难以在个人设备上稳定运行。WuliA…...

火影迷的AI绘画神器:忍者绘卷Z-Image Turbo零基础入门实战
火影迷的AI绘画神器:忍者绘卷Z-Image Turbo零基础入门实战 1. 前言:当火影忍者遇上AI绘画 作为一名火影迷,你是否曾经幻想过自己也能创造出独特的忍者世界角色?现在,借助"忍者绘卷Z-Image Turbo"这款专为火…...

大多数人手动给Agent加记忆 Meta HyperAgents却让AI自己发明了完整记忆系统
你是不是也这样造Agent:先搭好任务执行模块,再手动塞一个向量数据库或RAG当记忆,最后发现跨轮迭代时效果还是“每次从零开始”?性能没 compounding,跨任务迁移更是一团乱麻。明明AI已经能自我迭代了,为什么…...
分布图)
LingBot-Depth效果实测:与传感器原生深度对比的绝对误差(mm)分布图
LingBot-Depth效果实测:与传感器原生深度对比的绝对误差(mm)分布图 1. 引言:当深度图遇上“脑补”大师 想象一下,你手里有一张用深度相机拍出来的照片,它告诉你每个像素离相机有多远。但问题是࿰…...

写段代码教会你什么是HOOK技术?HOOK技术能干什么?
起因是我想在搞一些操作windows进程的事情时,老是需要右键以管理员身份运行,感觉很麻烦。就研究了一下怎么提权,顺手瞄了一眼Windows下用户态权限分配,然后也是感谢《深入解析Windows操作系统》这本书给我偷令牌的灵感吧ÿ…...

AI写论文超厉害!4款AI论文生成工具,解决毕业论文写作难题!
还在为撰写期刊论文而烦恼吗?面对成堆的文献、复杂的格式要求以及无休止的修改,许多学术人员常常感到效率低下。这并不奇怪!不过,不必太担心,以下将推荐4款实测有效的AI论文写作工具,它们能帮助你在论文文献…...

网盘直链下载助手终极指南:3步实现高速下载新时代
网盘直链下载助手终极指南:3步实现高速下载新时代 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

STM32duino多传感器库:X-NUCLEO-IKS01A2驱动详解
1. 项目概述STM32duino X-NUCLEO-IKS01A2 是一个面向 Arduino 兼容生态(特别是基于 STM32 的开发板,如 NUCLEO-F401RE、NUCLEO-F411RE、NUCLEO-L476RG 等)的硬件抽象库,专为驱动 STMicroelectronics 官方推出的 X-NUCLEO-IKS01A2 …...