浅析InnoDB引擎架构(已完结)
大家好,我是此林。
今天来介绍下InnoDB底层架构。
1. 磁盘架构
我们所有的数据库文件都保存在 /var/lib/mysql目录下。
由于我这边是docker部署的mysql,用如下命令查看mysql数据挂载。
docker inspect mysql-master
如下图,目前只有一个数据库 db_user,数据库本质上是文件夹的形式。

在db_user文件夹下,目前只有一张表,表空间就是idb文件形式。

表空间idb文件以B+树的形式组织存储,其中B+树的非叶子结点存储索引段,叶子结点存储的是数据段。此外还有回滚段。段用来管理多个区。
区是表空间的单元结构,每个区大小为1M,一个区有64个连续的页。
页,是InnoDB存储引擎磁盘管理的最小单元,每个页默认大小为16K。为了保证页的连续性,Inn哦DB存储引擎每次从磁盘申请4-5个区。
行,InnoDB存储引擎数据是按行存放的。
所有文件介绍:
1. db_user:自定义的数据库
2. mysql:mysql自带数据库,包含用户、权限和管理信息表
3. performance_schema、sys:mysql自带数据库,用于mysql性能监控
4. ib_logfile0、ib_logfile1:redo_log(重做日志)
5. binlog.000001、binlog000002:binlog(二进制日志)
6. undo_001、undo_002:undo_log(回滚日志)
2. 内存架构
1. BufferPool
数据表都保存在磁盘文件中,而用户是无法直接操作磁盘文件的,必须先把数据文件加载到内存中,用户对内存中的数据进行增删改操作,最后再以一定的频率把内存中的数据刷新到磁盘中。
InnoDB内存架构中,BufferPool(缓冲区)就是类似的作用。
BufferPool 中,以页(Page)为单位,每次它会去磁盘中加载整页(16K)数据。这样做的好处是减少磁盘IO,相当于缓存的作用。
BufferPool 中的 Page有三种类型:
1. 空页(free page),空闲页,未被使用
2. clean page,被使用的页,但是数据没有被修改过
3. 脏页(dirty page),被使用的page,数据被修改过,也就是和磁盘中数据不一致的页。
2. ChangeBuffer
更改缓冲区(针对非唯一的二级索引),在执行DML语句(增删改语句)时,如果这些这些数据Page不在BufferPool中,不会区操作磁盘,而是先把数据变更存在更改缓冲区中,未来数据被读取时,再将数据合并恢复到BufferPool中,最后再刷新到磁盘。
存在的意义?
和聚簇索引不同,二级索引通常是非唯一的,并且每次以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作一次磁盘IO,会造成大量的磁盘IO,有了ChangeBuffer后,我们可以在缓冲池中进行合并操作,减少磁盘IO。
3. Adaptive Hash Index
InnoDB不支持Hash索引,它只支持B+树索引,我们目前所有的索引,底层结构都是B+树,主要原因是Hash索引虽然快,但是只支持等值匹配,不支持范围查询。
自适应Hash索引,用于优化对BufferPool的查询。InnoDB 存储引擎会监控对表上各个索引页的查询,如果观察到Hash索引可以提升速度,则建立Hash索引。系统自动优化,无需人工干预。
查询参数:
show variables like '%hash%';
默认是开启的。
4. LogBuffer
日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log,undo log)。默认大小为16MB,日志缓冲区的日志会定期刷到磁盘中。
参数:
show variables like 'innodb_log_buffer_size'; # 缓冲区大小
show variables like 'innodb_flush_log_at_trx_commit'; # 日志刷新到磁盘的时机

innodb_flush_log_at_trx_commit:
1: 日志在每次事务提交时写入并刷新磁盘
0:每秒将日志写入并刷新磁盘一次
2:日志在每次事务提交后写入,并且每秒刷新一次到磁盘中。
3. 后台线程
1. Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲区中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
2. IO Thread
在InnoDB中大量使用AIO(异步非阻塞)来处理IO请求,极大提高数据库性能。
IO Thread主要负责这些IO请求的回调。
命令:
show engine innodb status;
3. Purge Thread
主要用于回收事务已经提交的undo_log,在事务提交之后,undo log已经无用,需要回收。
4. Page Cleaner Thread
协助Master Thread刷新脏页到磁盘的线程,减轻Master Thread的工作压力,减少阻塞。
4. InnoDB 事务原理
事务特性(ACID):
1. 原子性:事务操作不可分割,要么同时成功,要么同时失败。
2. 一致性:事务完成时,所有数据必须保证一致性。
3. 隔离性:数据库系统提供的隔离机制,保证事务在不受外部并发的影响的独立环境下运行。
4. 持久性:事务一旦 提交,对数据库的改变就是永久的。
原子性、一致性由undo_log来实现,
持久性由redo_log来实现,
隔离性由锁和MVCC机制来实现。
1. redo_log重做日志
我们知道,在执行update、delete、insert操作的时候,实际操作的是BufferPool内存中的数据,
但是BufferPool中的数据是由后台线程以一定的频率或由操作系统来决定何时同步到磁盘中的。
若BufferPool数据没来得及刷到磁盘中,服务器宕机,那么就会导致数据丢失。
redo_log出现后,流程变化如下:
1. 变更BufferPool中的数据
2. 数据页变化写入redo_log_buffer(内存)
3. 事务提交后,redo_log_buffer刷新到磁盘(redo_log)中。
4. 之后即使BufferPool没来得及刷新到磁盘,也可以通过redo_log来恢复。
问:redo_log不是多此一举吗?为什么不操作完BufferPool后,直接把脏页刷新到磁盘里?
答:
1. 我们一般在事务操作很多条记录,这些记录一般都是随机操作数据页的,此时将涉及大量的磁盘IO,性能极低。
2. 而redo_log日志文件写入都是追加顺序写入,性能高于随机磁盘IO。这种机制叫WAL(Write-Ahead-logging)——先写日志。
3. 当BufferPool中脏页的数据成功刷新到磁盘中,redo_log日志文件会被定期删除。
2. undo_log 回滚日志
回滚日志,用于记录数据被修改前的信息,作用有两个:
1. 提供回滚
2. MVCC(多版本并发控制)
可以认为当delete一条语句,undo_log中会记录一条对应的insert语句;当update一条语句,undo_log中会记录一条相反的update语句。
事务提交后,undo_log不会被立即删除,因为可能用于多版本并发控制(MVCC)。
3. MVCC 机制
1. 概要
简单来说,要保证并发安全,MYSQL觉得每次读的时候都要加锁,太损耗性能了。所以提出了MVCC机制,是不加锁的快照读(非阻塞读),提升了性能。
1. 当前读:
select ... lock in share mode (读锁)
select ... for update (写锁)
update、insert、delete
以上操作都是当前读,会对读取的记录加锁。
2. 快照读:
简单的select(不加锁)就是快照读。
Read Committed: 每次select,都生成一个快照读。
Repeatable Comitted: 开启事务后第一个select语句就是快照读的地方。
Serializable: 快照读退化成当前读。
2. 实现原理
MVCC的实现依赖数据库的行记录中的三个隐藏字段、undo_log、readView。
- DB_TRX_ID:最近修改的事务ID,记录插入这条数据或最后一次修改该记录的事务ID。
- DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本,用于配合undo_log,指向上一个版本。
- DB_ROW_ID:当表中没有定义主键,MYSQL自动生成此字段作为主键。
查看命令:
idb2sdi table_name.idb当insert的时候,产生的undo_log日志只在回滚时需要,事务提交后可以立即删除。
当update、delete时候,产生的undo_log日志不仅在回滚时需要,在快照读的时候也需要,不能立即删除。
3. 案例分析
来看下面一个案例:

undo_log版本链如下:
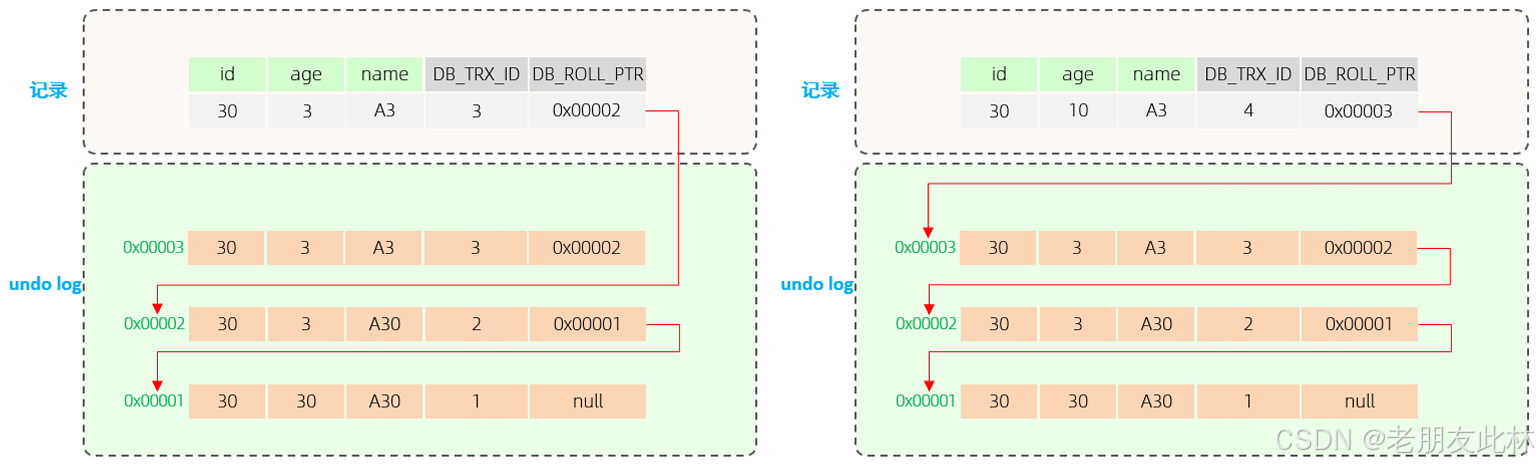
那我select的时候如何知道要访问哪个版本呢?
简单来说,它会拿到当前行的DB_TRX_ID(事务id),逐个和ReadView各个字段做条件判断,满足条件即返回该版本数据;若不满足会通过DB_ROLL_PTR回滚指针继续寻找版本,进行比对。
先看事务5:
假设当前事务隔离级别为RC,即每次select都会生成一个ReadView。
1. 执行第一个查询id为30的记录命令时,生成如下ReadView。读取到的事务2修改的age=10,name=A3。
| m_ids(当前活动事务id) | [3,4,5] |
| min_trx_id(最小活动事务id,事务id时自增的) | 3 |
| max_trx_id(最大活动事务id + 1,预分配的) | 6 |
| creator_trx_id(当前ReadView创建的事务id) | 5 |
2. 执行第二个查询id为30的记录命令时,生成如下ReadView。读取到的是age=3,name=A30。
| m_ids(当前活动事务id) | [4,5] |
| min_trx_id(最小活动事务id,事务id时自增的) | 4 |
| max_trx_id(最大活动事务id + 1,预分配的) | 6 |
| creator_trx_id(当前ReadView创建的事务id) | 5 |
但是当RR隔离级别下,第二个查询id为30的记录 会和 第一个查询id为30的记录 的结果一样,因为用的是同一个ReadView。如果这个时候不想快照读,用select for update可以查到最新的记录,因为这条加锁命令不走MVCC。
4. 总结
综上,MYSQL使用了MVCC和锁机制来保证了事务的四大特性(ACID)。
相关文章:
浅析InnoDB引擎架构(已完结)
大家好,我是此林。 今天来介绍下InnoDB底层架构。 1. 磁盘架构 我们所有的数据库文件都保存在 /var/lib/mysql目录下。 由于我这边是docker部署的mysql,用如下命令查看mysql数据挂载。 docker inspect mysql-master 如下图,目前只有一个数…...
华为云计算HCIE笔记02
第二章:华为云Stack规划设计 交付总流程 准备工作:了解客户的基本现场,并且对客户的需求有基本的认知。 HLD方案BOQ报价设备采购和设备上架 2.安装部署流程 硬件架构设计 硬件设备选配 设备上架与初始化配置 准备相关资料(自动下载…...
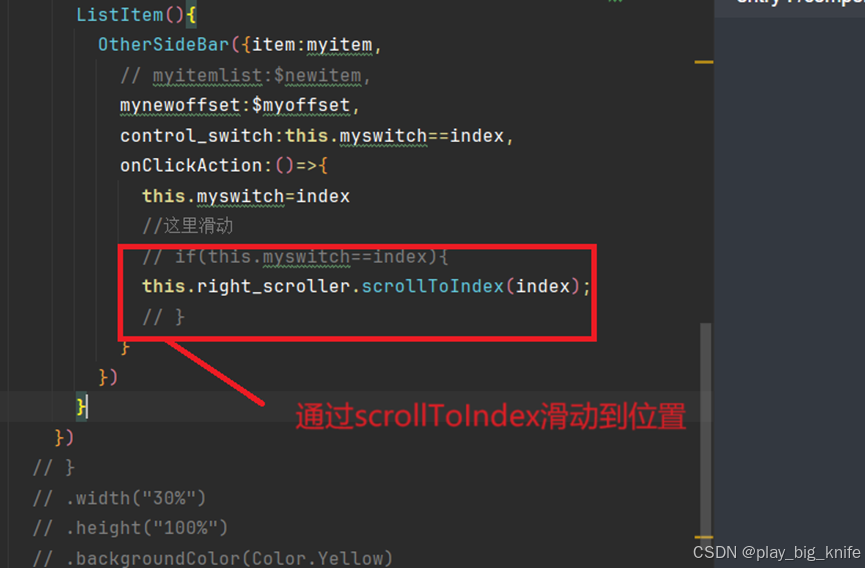
鸿蒙项目云捐助第十讲鸿蒙App应用分类页面二级联动功能实现
鸿蒙项目云捐助第十讲鸿蒙App应用分类页面二级联动功能实现 在之前的教程中完成了分类页面的左右两侧的列表结构,如下图所示。 接下来需要实现左侧分类导航项的点击操作,可以友好的提示用户选择了哪一个文字分类导航项。 一、左侧文字分类导航的处理 …...
STM32低功耗模式结合看门狗
STM32低功耗模式结合看门狗 前言 最近做到一个需求要使用STM32的低功耗模式进行长时间待机应用,每隔十分钟发送一次数据到服务器上,当不发送的时候就处于低功耗模式。在经过一段时间的测试以后发现板子过三四天左右就没有数据上传服务器了,…...
数据迁移工具,用这8种!
前言 最近有些小伙伴问我,ETL数据迁移工具该用哪些。 ETL(是Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业应用来说,我们经常会遇到各种数据的处理、转换、迁移的场景。 今天特地给大家汇总了一些目前…...
Sapro编程软件
Sapro软件是由西门子建筑科技公司开发的一款编程软件,主要用于Climatix控制器的编程、调试及相关功能实现.以下是其具体介绍: • 功能强大:可进行HVAC控制编程,实现设备控制、HMI用户访问和设备集成等功能,满足复杂的…...

Python图注意力神经网络GAT与蛋白质相互作用数据模型构建、可视化及熵直方图分析...
全文链接:https://tecdat.cn/?p38617 本文聚焦于图注意力网络GAT在蛋白质 - 蛋白质相互作用数据集中的应用。首先介绍了研究背景与目的,阐述了相关概念如归纳设置与转导设置的差异。接着详细描述了数据加载与可视化的过程,包括代码实现与分析…...

2024年图像处理、多媒体技术与机器学习
重要信息 官网:www.ipmml.org 时间:2024年12月27-29日 地点:中国-大理 简介 2024年图像处理、多媒体技术与机器学习(CIPMT 2024)将于2024年12月27-29日于中国大理召开。将围绕图像处理与多媒体技术、机器学习等在…...
java 1.8+springboot文件上传+vue3+ts+antdv
1.参考 使用SpringBoot优雅的实现文件上传_51CTO博客_springboot 上传文件 2.postman测试 报错 :postman调用时body参数中没有file单词 Resolved [org.springframework.web.multipart.support.MissingServletRequestPartException: Required request part file is…...
【机器人】机械臂轨迹和转矩控制对比
动力学控制和轨迹跟踪控制是机器人控制中的两个概念,它们在目标、方法和应用上有所不同,但也有一定关联。以下是它们的区别和联系: 1. 动力学控制 动力学控制是基于机器人动力学模型的控制方法,目标是控制机器人关节力矩或力&…...

如何利用矩阵化简平面上的二次型曲线
二次型曲线的定义 在二维欧式平面上,一个二次型曲线都可以写成一个关于 x , y x,y x,y的二元二次多项式: F ( x , y ) a 11 x 2 2 a 12 x y a 22 y 2 2 a 1 x 2 a 2 y a 0 0 \begin{equation} F(x,y)a_{11}x^22a_{12}xya_{22}y^22a_1x2a_2ya_00…...
【系统移植】制作SD卡启动——将uboot烧写到SD卡
在开发板上启动Linux内核,一般有两种方法,一种是从EMMC启动,还有一种就是从SD卡启动,不断哪种启动方法,当开发板上电之后,首先运行的是uboot。 制作SD卡启动,首先要将uboot烧写到SD卡ÿ…...
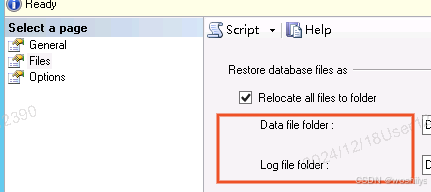
sql server 数据库还原,和数据检查
右键数据库选择还原, 还原的备份文件必须选择在本地的文件(远程文件没有试过)还原数据库名字可以修改,然后file选择中有个2个目录data file 的目录 ,和log data 的目录都可以重新选择还原到的新的目录,不要…...
工业大数据分析算法实战-day12
文章目录 day12时序分解STL(季节性趋势分解法)奇异谱分析(SSA)经验模态分解(EMD) 时序分割ChangpointTreeSplitAutoplait有价值的辅助 时序再表征 day12 今天是第12天,昨天主要是针对信号处理算…...
Hive其一,简介、体系结构和内嵌模式、本地模式的安装
目录 一、Hive简介 二、体系结构 三、安装 1、内嵌模式 2、测试内嵌模式 3、本地模式--最常使用的模式 一、Hive简介 Hive 是一个框架,可以通过编写sql的方式,自动的编译为MR任务的一个工具。 在这个世界上,会写SQL的人远远大于会写ja…...
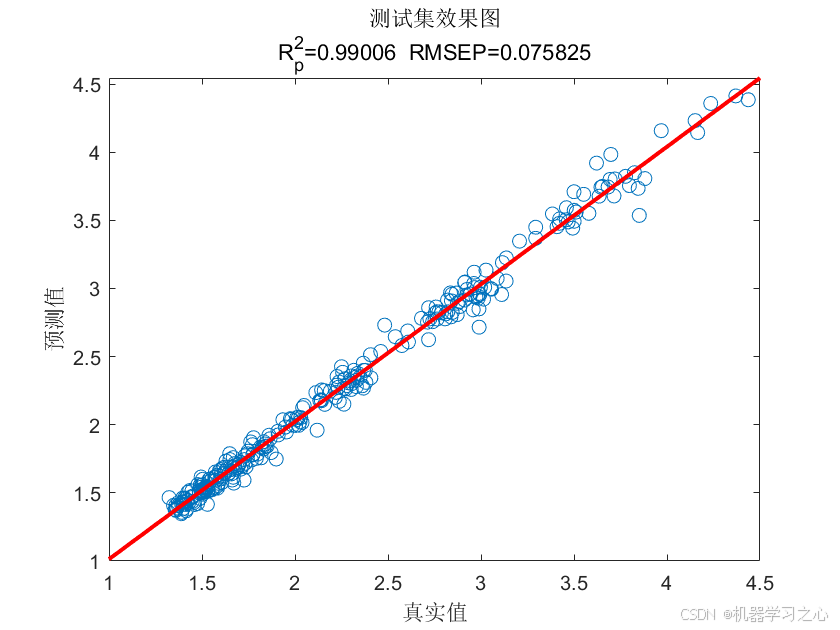
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测 目录 LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.LSTM-SVM时序预测 | Matlab基于LSTM…...

MacPorts 中安装高/低版本软件方式,以 RabbitMQ 为例
查询信息 这里以 RabbitMQ 为例,通过搜索得到默认安装版本信息: port search rabbitmq-server结果 ~/Downloads> port search rabbitmq-server rabbitmq-server 3.11.15 (net)The RabbitMQ AMQP Server ~/Downloads>获取二进制文件 但当前官网…...
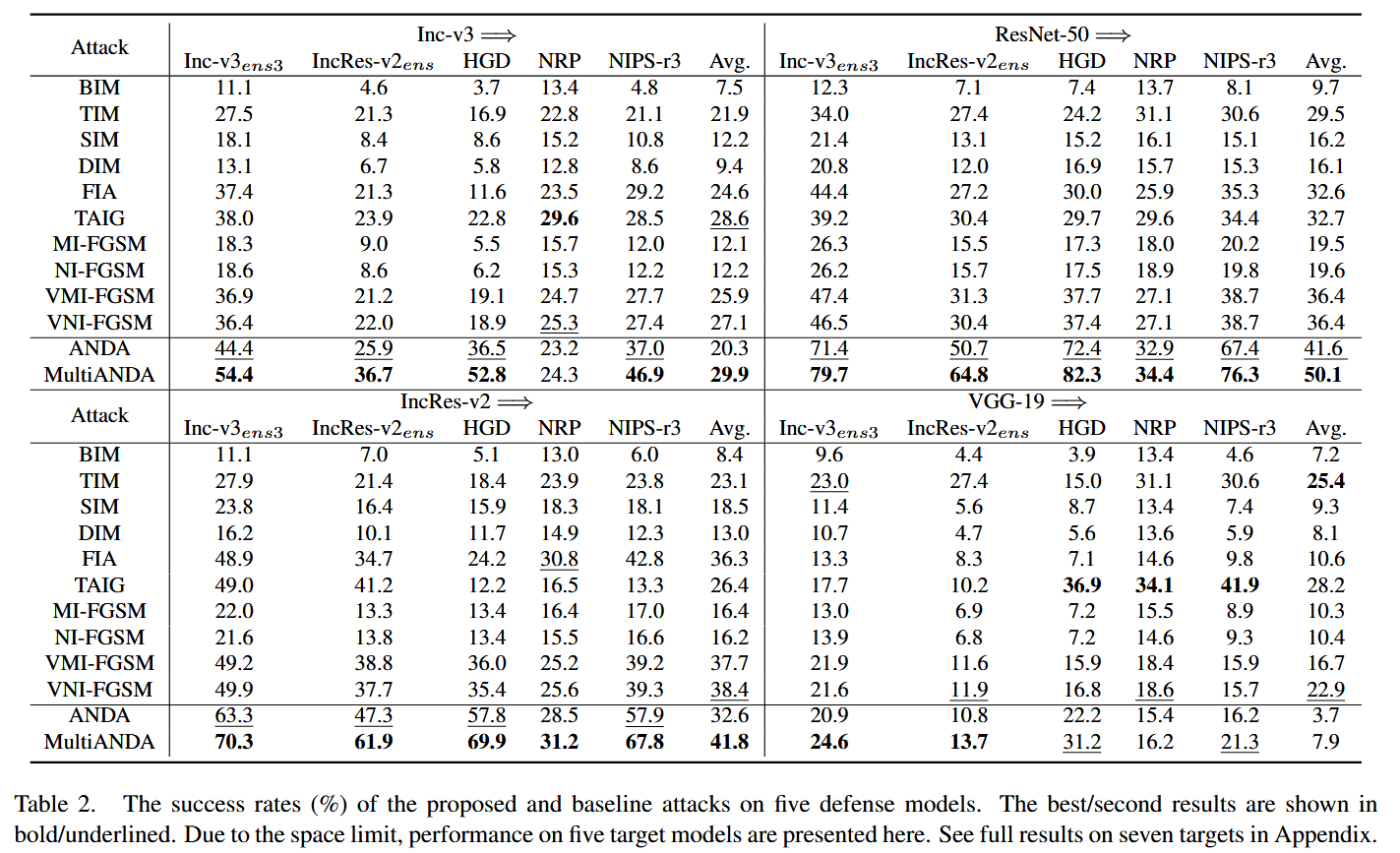
CVPR2024 | 通过集成渐近正态分布学习实现强可迁移对抗攻击
Strong Transferable Adversarial Attacks via Ensembled Asymptotically Normal Distribution Learning 摘要-Abstract引言-Introduction相关工作及前期准备-Related Work and Preliminaries1. 黑盒对抗攻击2. SGD的渐近正态性 提出的方法-Proposed Method随机 BIM 的渐近正态…...

建投数据与腾讯云数据库TDSQL完成产品兼容性互认证
近日,经与腾讯云联合测试,建投数据自主研发的人力资源信息管理系统V3.0、招聘管理系统V3.0、绩效管理系统V2.0、培训管理系统V3.0通过腾讯云数据库TDSQL的技术认证,符合腾讯企业标准的要求,产品兼容性良好,性能卓越。 …...

群晖利用acme.sh自动申请证书并且自动重载证书的问题解决
前言 21年的时候写了一个在群晖(黑群晖)下利用acme.sh自动申请Let‘s Encrypt的脚本工具 群晖使用acme自动申请Let‘s Encrypt证书脚本,自动申请虽然解决了,但是自动重载一直是一个问题,本人也懒,一想到去…...
)
Neo4j关系创建失败?手把手教你处理GraphRAG生成的异常ID格式(含正则清洗技巧)
Neo4j关系创建失败?手把手教你处理GraphRAG生成的异常ID格式(含正则清洗技巧) 当你满怀期待地将GraphRAG生成的知识图谱数据导入Neo4j,准备欣赏可视化成果时,却发现关系创建失败——这可能是每个数据工程师都经历过的噩…...

ClawdBot优化升级:如何配置国内大模型,提升响应速度与效果
ClawdBot优化升级:如何配置国内大模型,提升响应速度与效果 1. 项目概述 ClawdBot(现更名为MoltBot)是一款开源的个人AI助手工具,它能够在本地设备上运行,通过vLLM提供后端模型能力。这个工具特别适合开发…...

新手也能看懂!5分钟搞懂图像频谱图:用MATLAB的fft2和fftshift分析图片细节
图像频谱图解析:用MATLAB透视照片的隐藏密码 想象一下,如果每张照片都能像X光片一样被"透视",让我们看到它内部隐藏的结构特征,那会怎样?这就是图像频谱图的魔力所在。不同于我们日常看到的像素排列…...

从GlobeLand30数据到统计报表:QGIS分区统计+Excel,打造你的地表覆盖分析工作流
从GlobeLand30到专业报表:QGISExcel高效地表覆盖分析全流程 地表覆盖数据是理解区域生态环境、规划土地利用的重要基础。GlobeLand30作为30米分辨率的全球地表覆盖数据集,为研究者提供了高精度的分析素材。但如何将这些数据转化为可操作的见解࿱…...

如何让微信聊天记录永久留存?WeChatMsg为你打造个人数字档案馆
如何让微信聊天记录永久留存?WeChatMsg为你打造个人数字档案馆 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...

Gemini 3.1镜像实战:用三层思考架构与多模态引擎解决视频内容生产
谷歌2026年初发布的Gemini 3.1 Pro,凭借可配置的三层思考架构(低/中/高推理深度)和集成Veo视频引擎、Lyria 3音频引擎的多模态能力,为实际业务问题提供了全新的解决范式。国内开发者和内容创作者可通过聚合平台RskAi(w…...

多模态学习:结合文本和图像的旋转判断
多模态学习:结合文本和图像的旋转判断 1. 引言 你有没有遇到过这样的情况:拍了一张带文字的图片,结果发现方向不对,需要手动旋转才能正常阅读?传统的图像旋转判断方法往往只依赖视觉特征,对于包含文字的图…...
Hunyuan-MT-7B翻译终端效果展示:Pixel Language Portal长文本段落对齐精度对比
Hunyuan-MT-7B翻译终端效果展示:Pixel Language Portal长文本段落对齐精度对比 1. 产品概览:像素语言冒险工坊 **像素语言跨维传送门(Pixel Language Portal)**是一款基于腾讯Hunyuan-MT-7B核心引擎构建的创新翻译终端。与传统翻译工具不同,…...

3分钟夺回你的数字音乐资产:Unlock Music浏览器解密全攻略 [特殊字符]
3分钟夺回你的数字音乐资产:Unlock Music浏览器解密全攻略 🎵 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...

eSearch一站式屏幕效率工具安装指南
eSearch一站式屏幕效率工具安装指南 【免费下载链接】eSearch 截屏 离线OCR 搜索翻译 以图搜图 贴图 录屏 万向滚动截屏 屏幕翻译 Screenshot Offline OCR Search Translate Search for picture Paste the picture on the screen Screen recorder Omnidirectional scrolling sc…...